开篇词|让Rust成为你的下一门主力语言
你好,我是陈天,目前是北美最大的免费流媒体服务TubiTV的研发副总裁,也是公众号程序人生和知乎专栏迷思的作者。
十八年以来,我一直从事高性能系统的研发工作,涵盖网络协议、网络安全、服务端架构、区块链以及云服务等方向。
因为 喜欢使用合适的工具解决合适的问题,在职业生涯的不同阶段,我深度使用过形态和机理都非常不同的开发语言。
我用 C 和汇编打造过各种网络协议,维护过在网络安全领域非常知名的嵌入式操作系统 ScreenOS;用 Python/JavaScript 撰写过我曾经的创业项目途客圈;用 Node.js/Elixir 打造过 TubiTV 高并发的后端核心;用 Elixir 打造过区块链框架 Forge,也研究过 Haskell/F#、Clojure/Racket、Swift、Golang 和 C#等其他语言。
2018年起,我开始关注Rust。当时我正在开发 Forge ,深感 Elixir 处理计算密集型功能的无力,在汉东,也是《Rust编程之道》作者的介绍下,我开始学习和使用 Rust。
也正是因为之前深度使用了很多开发语言,当我一接触到 Rust,就明白它绝对是面向未来的利器。
首先,你使用起来就会感受到,Rust是一门非常重视开发者用户体验的语言。如果做一个互联网时代的编程语言用户体验的排行,Rust 绝对是傲视群雄的独一档。
你无法想象一门语言的编译器在告知你的代码错误的同时,还会极尽可能,给你推荐正确的代码。这就好比在你开发的时候,旁边坐着一个无所不知还和蔼可亲的大牛,在孜孜不倦地为你审阅代码,帮你找出问题所在。
比如下面的代码,我启动了一个新的线程引用当前线程的变量( 代码):
#![allow(unused)] fn main() { let name = "Tyr".to_string(); std::thread::spawn(|| { println!("hello {}", name); }); }
这段代码极其简单,但它隐含着线程不安全的访问。当前线程持有的变量 name 可能在新启动的线程使用之前就被释放,发生 use after free 错误。
Rust 编译器,不仅能够通过类型安全在编译期检测出这一错误,告诉你这个错误产生的原因:“may outlive borrowed value”(我们暂且不管它是什么意思),并且,它还进一步推荐你加入 “move” 解决这个错误。为了方便你进一步了解错误详情,它还贴心地给出一个命令行 “rustc --explain E0373”,让你可以从知识库中获取更多的信息:
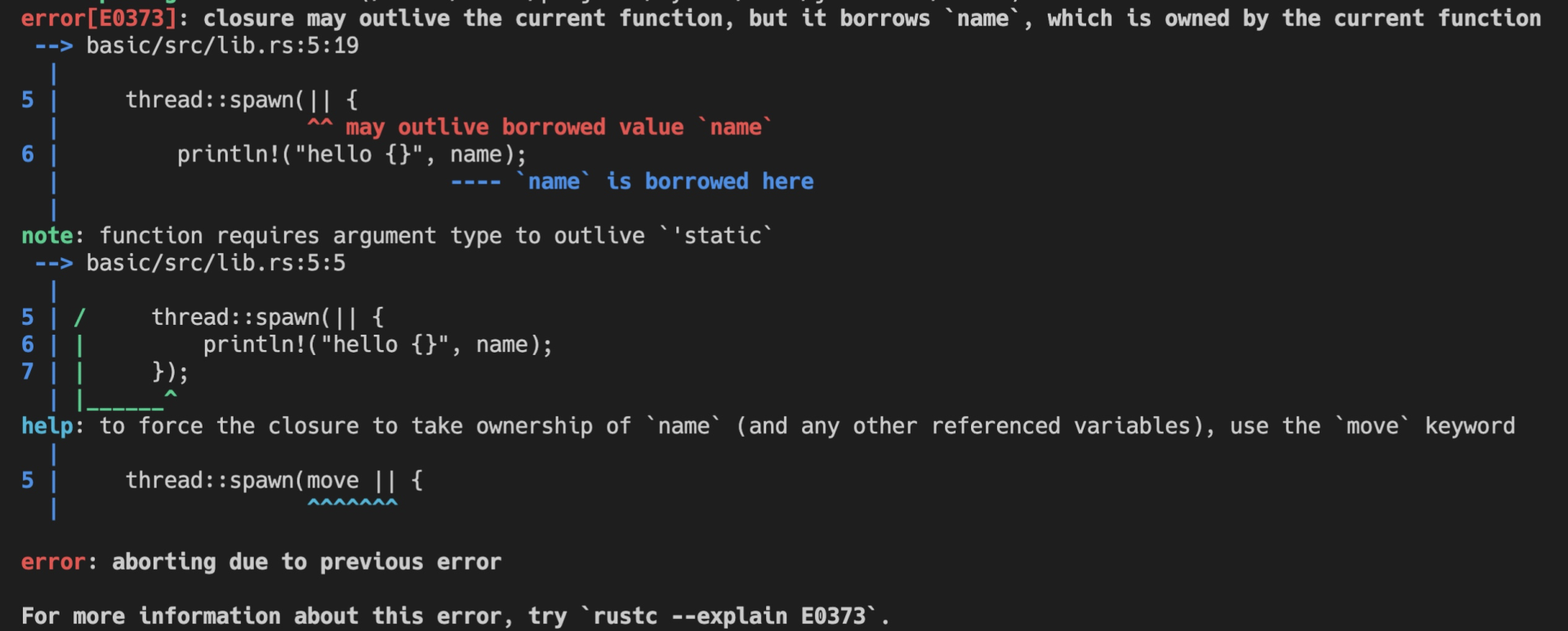
这种程度的体验,一旦你适应了 Rust,就很难离得开。Rust 语言的这种极致用户体验不仅仅反映在编译器上,整个语言的工具链包括 rustup、cargo 等,都是如此简单易用、善解人意。
其次,众所周知的优异性能和强大的表现力,让Rust在很多场合都能够施展拳脚。
截止 2021 年,主流的互联网公司都把 Rust 纳入主力语言,比如开发操作系统 Redox/Fuchsia、高性能网络 Tokio、应用的高并发后端 TiKV,甚至客户端软件本身(飞书)。我们欣喜地看到,Rust 除了在其传统的系统开发领域,如操作系统、设备驱动、嵌入式等方向高歌猛进之外,还在服务端高性能、高并发场景遍地开花。
最近两年,几乎每隔一段时间我们就能听到很多知名互联网企业用 Rust 重构其技术栈的消息。比如 Dropbox 用 Rust 重写文件同步引擎、Discord 用 Rust 重写其状态服务。其实, 这些公司都是业务层面驱动自然使用到Rust的。
比如 Discord原先使用 Golang 的状态服务,一来会消耗大量的内存,二来在高峰期时不时会因为垃圾回收导致巨大的延迟,痛定思痛后,他们选用 Rust 重写。按照 Discord 的官方说法,Rust 除了带来性能上的提升外,还让随着产品迭代进行的代码重构变得举重若轻。
Along with performance, Rust has many advantages for an engineering team. For example, its type safety and borrow checker make it very easy to refactor code as product requirements change or new learnings about the language are discovered. Also, the ecosystem and tooling are excellent and have a significant amount of momentum behind them.
最后,是我自己的使用感觉,Rust会越用越享受。以我个人的开发经验看,很多语言你越深入使用或者越广泛使用,就越会有“怒其不争”的感觉,因为要么掣肘很多,无法施展;要么繁文缛节太多,在性能和简洁之间很难二选一。
而我在使用 Rust 的时候,这样的情况很少见。操作简单的 bit 、处理大容量的 parquet、直面 CPU 乱序指令的 atomics,乃至像 Golang 一样高级封装的 channel,Rust 及其生态都应有尽有,让你想做什么的时候不至于“拔剑四顾心茫然”。
学习 Rust 的难点
在体验了 Rust 的强大和美妙后,2019 年,我开办了一系列讲座向我当时的团队普及 Rust,以便于处理 Elixir 难以处理的计算密集型的任务。但在这个过程中,我也深深地感受到把 Rust 的核心思想教给有经验开发者的艰辛。
Rust 被公认是很难学的语言,学习曲线很陡峭。
作为一门有着自己独特思想的语言,Rust 采百家之长,从 C++ 学习并强化了 move 语义和 RAII,从 Cyclone 借鉴和发展了生命周期,从 Haskell 吸收了函数式编程和类型系统等。
所以如果你想从其他语言迁移到 Rust,必须要经过一段时期的思维转换(Paradigm Shift)。
从命令式(imperative)编程语言转换到函数式(functional)编程语言、从变量的可变性(mutable)迁移到不可变性(immutable)、从弱类型语言迁移到强类型语言,以及从手工或者自动内存管理到通过生命周期来管理内存,难度是多重叠加。
而 Rust 中最大的思维转换就是 变量的所有权和生命周期,这是几乎所有编程语言都未曾涉及的领域。
但是你一旦拿下这个难点,其他的知识点就是所有权和生命周期概念在不同领域的具体使用,比如,所有权和生命周期如何跟类型系统结合起来保证并发安全、生命周期标注如何参与到泛型编程中等等。
学习过程中,在所有权和生命周期之外,语言背景不同的工程师也会有不同难点,你可以重点学习:
- C 开发者,难点是类型系统和泛型编程;
- C++ 开发者,难点主要在类型系统;
- Python/Ruby/JavaScript 开发者,难点在并发处理、类型系统及泛型编程;
- Java 开发者,难点在异步处理和并发安全的理解上;
- Swift 开发者,几乎没有额外的难点,深入理解 Rust 异步处理即可。
只要迈过这段艰难的思维转换期,你就会明白,Rust 确实是一门从内到外透着迷人光芒的语言。
从语言的内核来看,它重塑了我们对一些基本概念的理解。比如 Rust 清晰地定义了变量在一个作用域下的生命周期,让开发者在摒弃垃圾回收(GC)这样的内存和性能杀手的前提下,还能够无需关心手动内存管理, 让内存安全和高性能二者兼得。
从语言的外观来看,它使用起来感觉很像 Python/TypeScript 这样的高级语言,表达能力一流,但性能丝毫不输于 C/C++, 从而让表达力和高性能二者兼得。
这种集表达力、高性能、内存安全于一身的体验,让 Rust 在 1.0 发布后不久就一路高飞猛进,从 16 年起,连续六年成为 Stack Overflow 用户评选出来的最受喜爱的语言。
如何学好 Rust?
Rust 如此受人喜爱,有如此广泛的用途,且当前各大互联网厂商都在纷纷接纳 Rust,那么我们怎样尽可能顺利地度过艰难的思维转换期呢?
在多年编程语言的学习和给团队传授经验的过程中,我总结了一套从入门到进阶的有效学习编程语言的方法,对 Rust 也非常适用。
我认为,任何语言的学习离不开 精准学习+刻意练习。
所谓 精准学习,就是深挖一个个高大上的表层知识点,回归底层基础知识的本原,再使用类比、联想等方法,打通涉及的基础知识;然后从底层设计往表层实现,一层层构建知识体系,这样“撒一层土,夯实,再撒一层”,让你对知识点理解得更透彻、掌握得牢固。
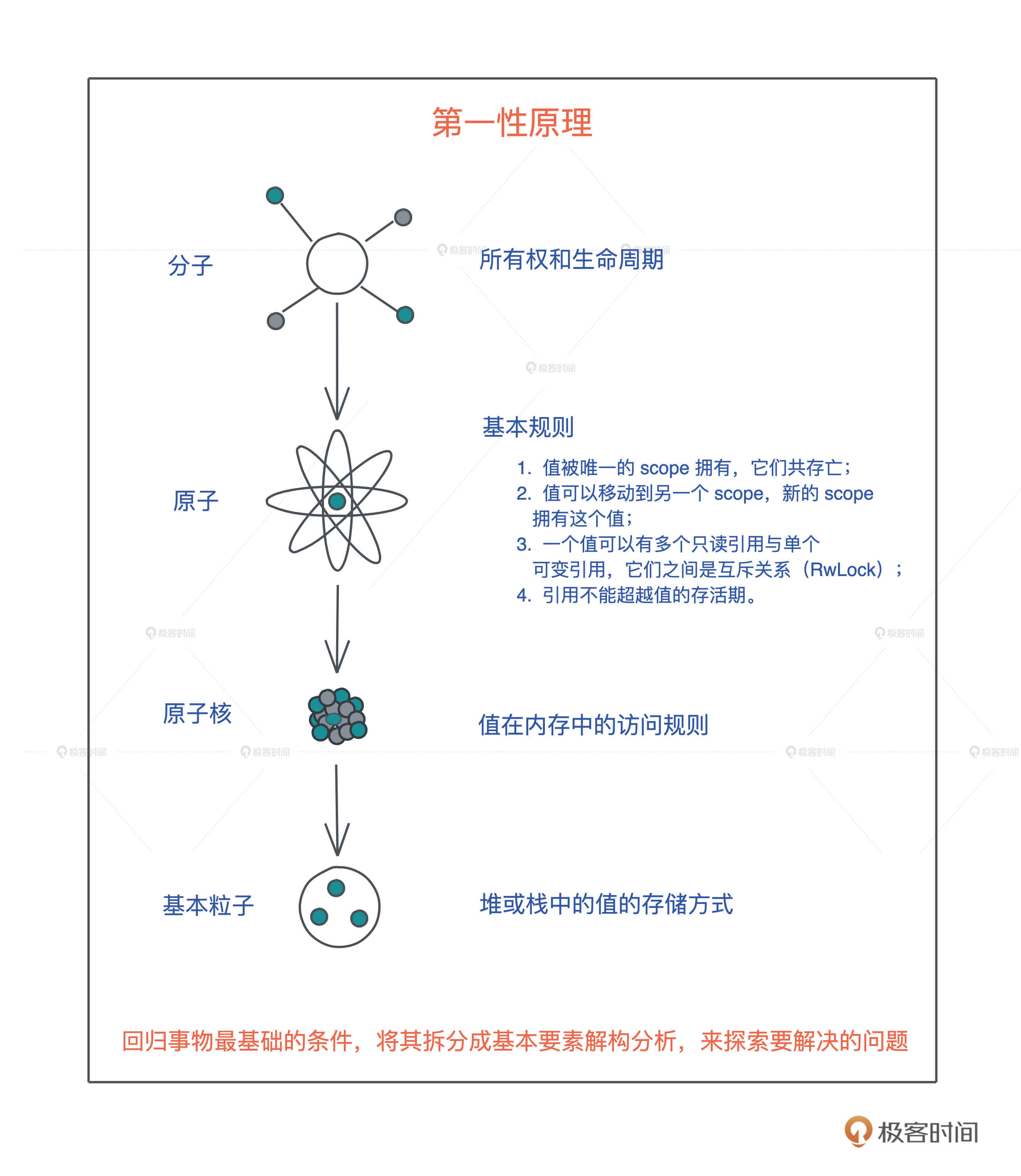
比如 Rust 中的所有权和生命周期,很多同学说自己看书或者看其他资料,这部分都学得云里雾里的,即便深入逐一理解了几条基本规则,也依旧似懂非懂。
但我们进一步思考“值在内存中的访问规则”,最后回归到堆和栈这些最基础的软件开发的概念,重新认识堆栈上的值的存储方式和生命周期之后,再一层层往上,我们就会越学越明白。
这就是回归本原的重要性,也就是常说的第一性原理:回归事物最基础的条件,将其拆分成基本要素解构分析,来探索要解决的问题。
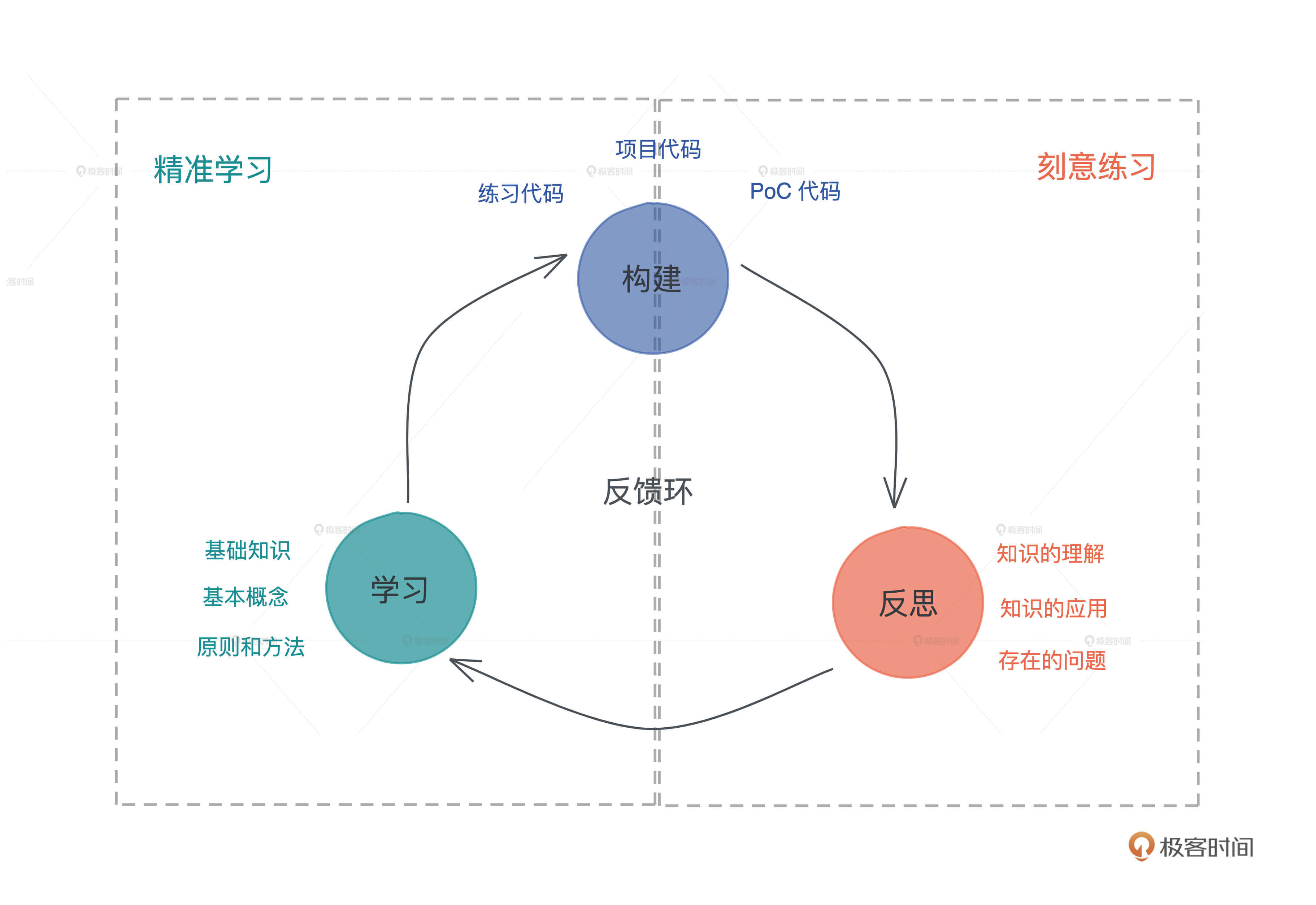
精准学习之后,我们就需要 刻意练习 了。刻意练习,就是用精巧设计的例子,通过练习进一步巩固学到的知识,并且在这个过程中尝试发现学习过程中的不自知问题,让自己从“我不知道我不知道”走向“我知道我不知道”,最终能够在下一个循环中弥补知识的漏洞。
这个过程就像子思在《中庸》里谈治学的方法:博学之,审问之,慎思之,明辨之,笃行之。我们学习就要这样,学了没有学会绝不罢休,不断在学习 - 构建 - 反思这个循环中提升自己。Rust 的学习,也是如此。
根据这种学习思路,在这个专栏里,我会带着你循序渐进地探索 Rust 的基本概念和知识、开发的原则和方法,力求掌握 Rust 开发的精髓;同时,每一部分内容,都用一个或多个实操项目帮你巩固知识、查漏补缺。
具体来看,整个专栏会分成五个模块:
- 前置知识篇
在正式学习 Rust 之前,先来回顾一下软件开发的基础概念:堆、栈、函数、闭包、虚表、泛型、同步和异步等。你要知道,想要学好任意一门编程语言,首先要吃透涉及的概念, 因为编程语言,不过是这些概念的具体表述和载体。
- 基础知识篇
我们会先来一个get hands dirty周,从写代码中直观感受Rust到底魅力在哪里,能怎么用,体会编程的快乐。
然后回归理性,深入浅出地探讨 Rust 变量的 所有权和生命周期,并对比几种主流的内存管理方式,包括,Rust 的内存管理方式、C 的手工管理、Java 的 GC、Swift 的 ARC 。之后围绕着所有权和生命周期,来讨论 Rust 的几大语言特性:函数式编程特性、类型系统、泛型编程以及错误处理。
- 进阶篇
Pascal 之父,图灵奖得主尼古拉斯·沃斯(Niklaus Wirth)有一个著名的公式:算法+数据结构=程序。 想随心所欲地使用Rust 为你的系统构建数据结构,深度掌握类型系统必不可少。
在 Rust 里,你可以使用 Trait 做接口设计、使用泛型做编译期多态、使用 Trait Object 做运行时多态。在你的代码里用好 Trait 和泛型,可以非常高效地解决复杂的问题。
随后我们会介绍 unsafe rust,不要被这个名字吓到。所谓 unsafe,不过是把 Rust 编译器在编译器做的严格检查退步成为 C++ 的样子,由开发者自己为其所撰写的代码的正确性做担保。
最后我们还会讲到 FFI,这是 Rust 和其它语言互通操作的桥梁。掌握好 FFI,你就可以用 Rust 为你的 Python/JavaScript/Elixir/Swift 等主力语言在关键路径上提供更高的性能,也能很方便地引入 Rust 生态中特定的库。
- 并发篇
从没有一门语言像 Rust 这样,在提供如此广博的并发原语支持的前提下,还能保证并发安全,所以 Rust 敢自称 无畏并发(Fearless Concurrency)。在并发篇,我带你从 atomics 一路向上,历经 Mutex、Semaphore、Channel,直至 actor model。其他语言中被标榜为实践典范的并发手段,在 Rust 这里,只不过是一种并发工具。
Rust 还有目前最优秀的异步处理模型,我相信假以时日,这种用状态机巧妙实现零成本抽象的异步处理机制,必然会在更多新涌现出来的语言中被采用。
在并发处理这个领域,Rust 就像天秤座圣衣,刀枪剑戟斧钺钩叉,十八般兵器都提供给你,让你用最合适的工具解决最合适的问题。
- 实战篇
掌握一门语言的特性,能应用这些特性,写出解决一些小问题的代码,算是初窥门径,就像在游泳池里练习冲浪, 想真正把语言融会贯通,还要靠大风大浪中的磨炼。在这篇中,我们会学习如何把 Rust 应用在生产环境中、如何使用 Rust 的编程思想解决实际问题,最后谈谈如何用 Rust 构建复杂的软件系统。
整个专栏,我会把内容尽量写得通俗易懂,并把各个知识点类比到不同的语言中,力求让你理解 Rust 繁多概念背后的设计逻辑。每一讲我都会画出重点,理清知识脉络,再通过一个个循序渐进的实操项目,让你把各个知识点融会贯通。
我衷心希望,通过这个专栏的学习, 你可以从基本概念出发,一步步跨过下图的愚昧之巅,越过绝望之谷,向着永续之原进发!通过一定的努力,最终自己也可以用 Rust 构建各种各样的系统,让自己职业生涯中多一门面向未来的利器。
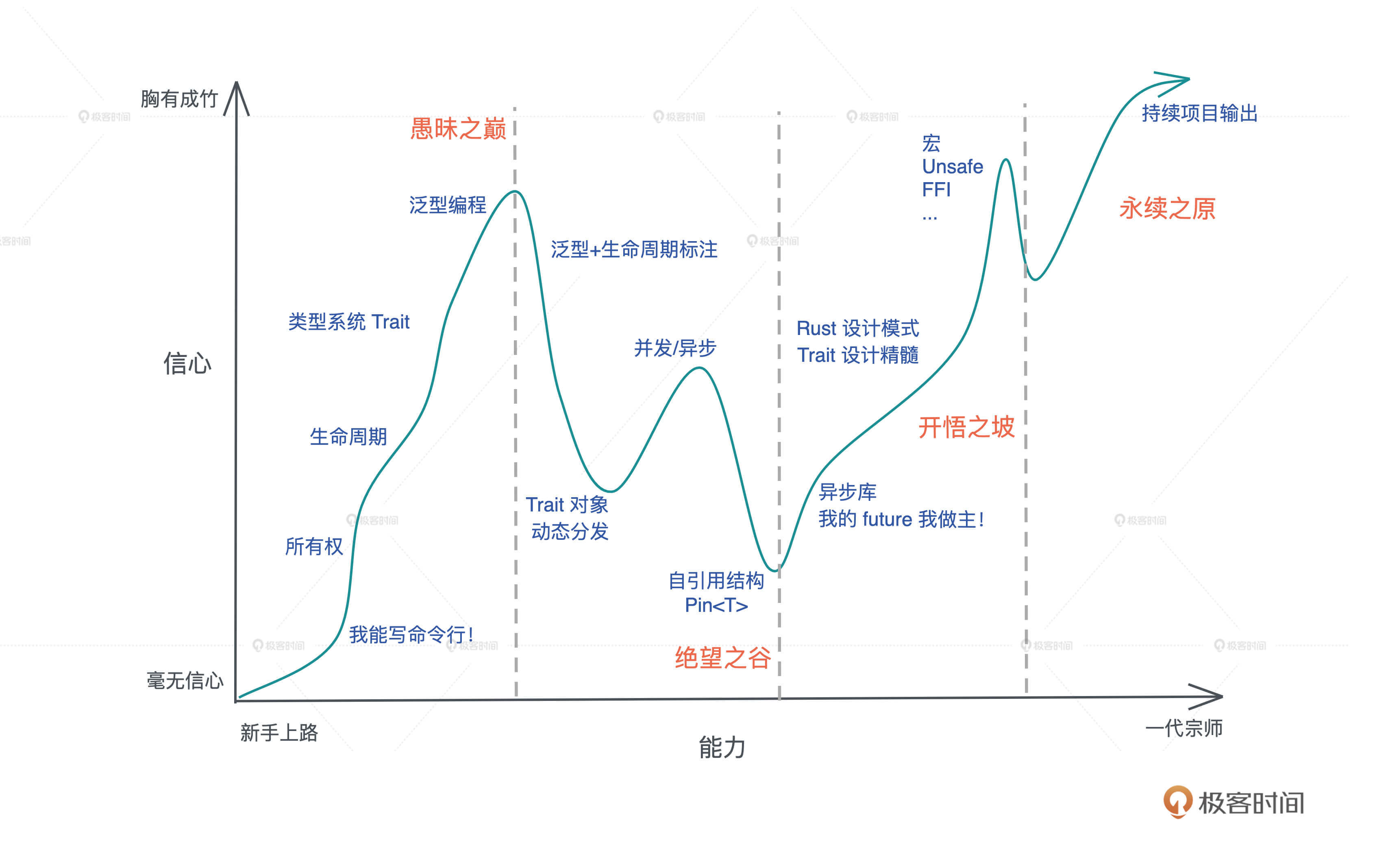
我非常希望你能坚持学下去,和我一直走到最后一讲。这中间,你如果有想不明白的地方,可以先多思考多琢磨,如果还有困惑,欢迎你在留言区问我。
在具体写代码的时候,你可以多举一反三,不必局限于我给的例子,可以想想工作生活中的产品场景,思考如何用 Rust 来实现。
每讲的思考题,也希望你尽量完成,记录分享你的分析步骤和思路。有需要进一步总结提炼的知识点,你也可以记录下来,与我与其他学友分享。毕竟,大物理学家费曼总结过他的学习方法,评价和分享/教授给别人是非常重要的步骤,能让你进一步巩固自己学到的知识和技能。
如果想找找参考思路,也可以看我在 GitHub 上的思考题答案点拨,之后文章里的代码也都整理到这里了,依赖相应版本都会更新(另外,课程里的图片都是用 excalidraw 绘制的)。
最后,你可以自己立个 Flag, 哪怕只是在留言区打卡你的学习天数或者Rust代码行数,我相信都是会有效果的。3 个月后,我们再来一起验收。
总之,让我们携手,为自己交付 “Rust 开发” 这个大技能,让 Rust 成为你的下一门主力语言!
订阅后, 戳这里加入“Rust语言入门交流群”,一起来学习Rust。
内存:值放堆上还是放栈上,这是一个问题
你好,我是陈天。今天我们打卡Rust学习的第一讲。
你是不是已经迫不及待想要了解Rust了,但是别着急,我们不会按常规直接开始介绍语法, 而会先来回顾那些你平时认为非常基础的知识,比如说内存、函数。
提到基础知识,你是不是已经有点提不起兴趣了,这些东西我都知道,何必浪费时间再学一次呢?其实不然,这些年我接触过的资深工程师里,基础知识没学透,工作多年了,还得回来补课的大有人在。
以最基础的内存为例,很多人其实并没有搞懂什么时候数据应该放在栈上,什么时候应该在堆上,直到工作中实际出现问题了,才意识到数据的存放方式居然会严重影响并发安全,无奈回头重新补基础,时间精力的耗费都很大。
其实作为开发者,我们一辈子会经历很多工具、框架和语言,但是这些东西无论怎么变,底层逻辑都是不变的。
所以今天我们得 回头重新思考,编程中那些耳熟能详却又似懂非懂的基础概念,搞清楚底层逻辑。而且这些概念,对我们后面学习和理解 Rust 中的知识点非常重要,之后,我们也会根据需要再穿插深入讲解。
代码中最基本的概念是变量和值,而存放它们的地方是内存,所以我们就从内存开始。
内存
我们的程序无时无刻不在跟内存打交道。在下面这个把 “hello world!” 赋值给 s 的简单语句中,就跟只读数据段(RODATA)、堆、栈分别有深度交互:
#![allow(unused)] fn main() { let s = "hello world".to_string(); }
你可以使用 Rust playground 里这个 代码片段 感受一下字符串的内存使用情况。
首先,“hello world” 作为一个字符串常量(string literal),在编译时被存入可执行文件的 .RODATA 段(GCC)或者 .RDATA 段(VC++),然后在程序加载时,获得一个固定的内存地址。
当执行 “hello world”.to_string() 时,在堆上,一块新的内存被分配出来,并把 “hello world” 逐个字节拷贝过去。
当我们把堆上的数据赋值给 s 时,s 作为分配在栈上的一个变量,它需要知道堆上内存的地址,另外由于堆上的数据大小不确定且可以增长,我们还需要知道它的长度以及它现在有多大。
最终, 为了表述这个字符串,我们使用了三个 word:第一个表示指针、第二个表示字符串的当前长度(11)、第三个表示这片内存的总容量(11)。在 64 位系统下,三个 word 是 24 个字节。
你也可以看下图,更直观一些: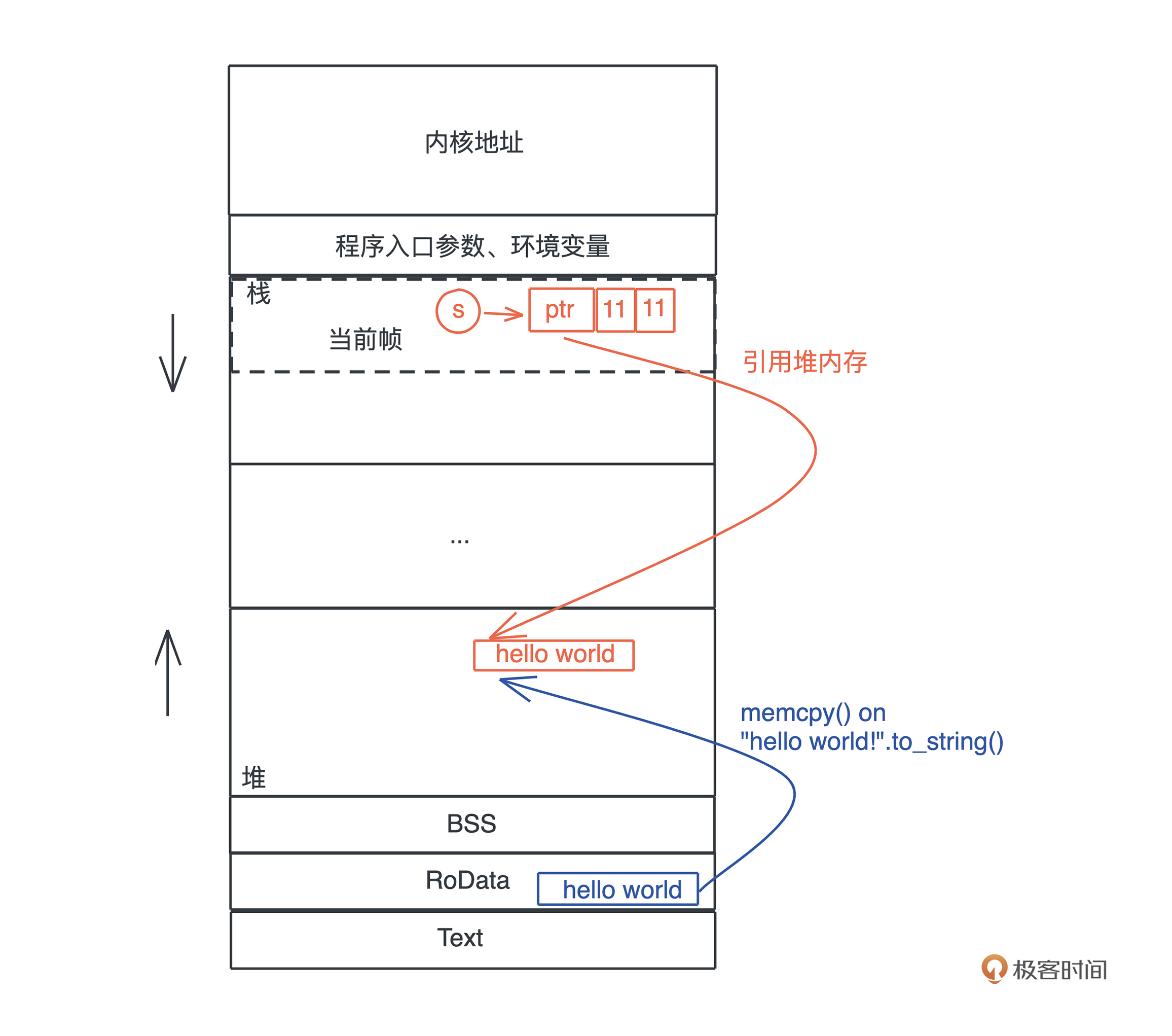
刚才提到字符串的内容在堆上,而指向字符串的指针等信息在栈上,现在就是检验你内存基础知识是否扎实的时候了: 数据什么时候可以放在栈上,什么时候需要放在堆上呢?
这个问题,很多使用自动内存管理语言比如 Java/Python 的开发者,可能有一些模糊的印象或者规则:
- 基本类型(primitive type)存储在栈上,对象存储在堆上;
- 少量数据存储在栈上,大量的数据存储在堆上。
这些虽然对,但并没有抓到实质。如果你在工作中只背规则套公式,一遇到特殊情况就容易懵,但是如果明白公式背后的推导逻辑,即使忘了,也很快能通过简单思考找到答案,所以接下来我们深挖堆和栈的设计原理,看看它们到底是如何工作的。
栈
栈是程序运行的基础。每当一个函数被调用时,一块连续的内存就会在栈顶被分配出来,这块内存被称为帧(frame)。
我们知道,栈是自顶向下增长的,一个程序的调用栈最底部,除去入口帧(entry frame),就是 main() 函数对应的帧,而随着 main() 函数一层层调用,栈会一层层扩展;调用结束,栈又会一层层回溯,把内存释放回去。
在调用的过程中, 一个新的帧会分配足够的空间存储寄存器的上下文。在函数里使用到的通用寄存器会在栈保存一个副本,当这个函数调用结束,通过副本,可以恢复出原本的寄存器的上下文,就像什么都没有经历一样。此外,函数所需要使用到的局部变量,也都会在帧分配的时候被预留出来。
整个过程你可以再看看这张图辅助理解:
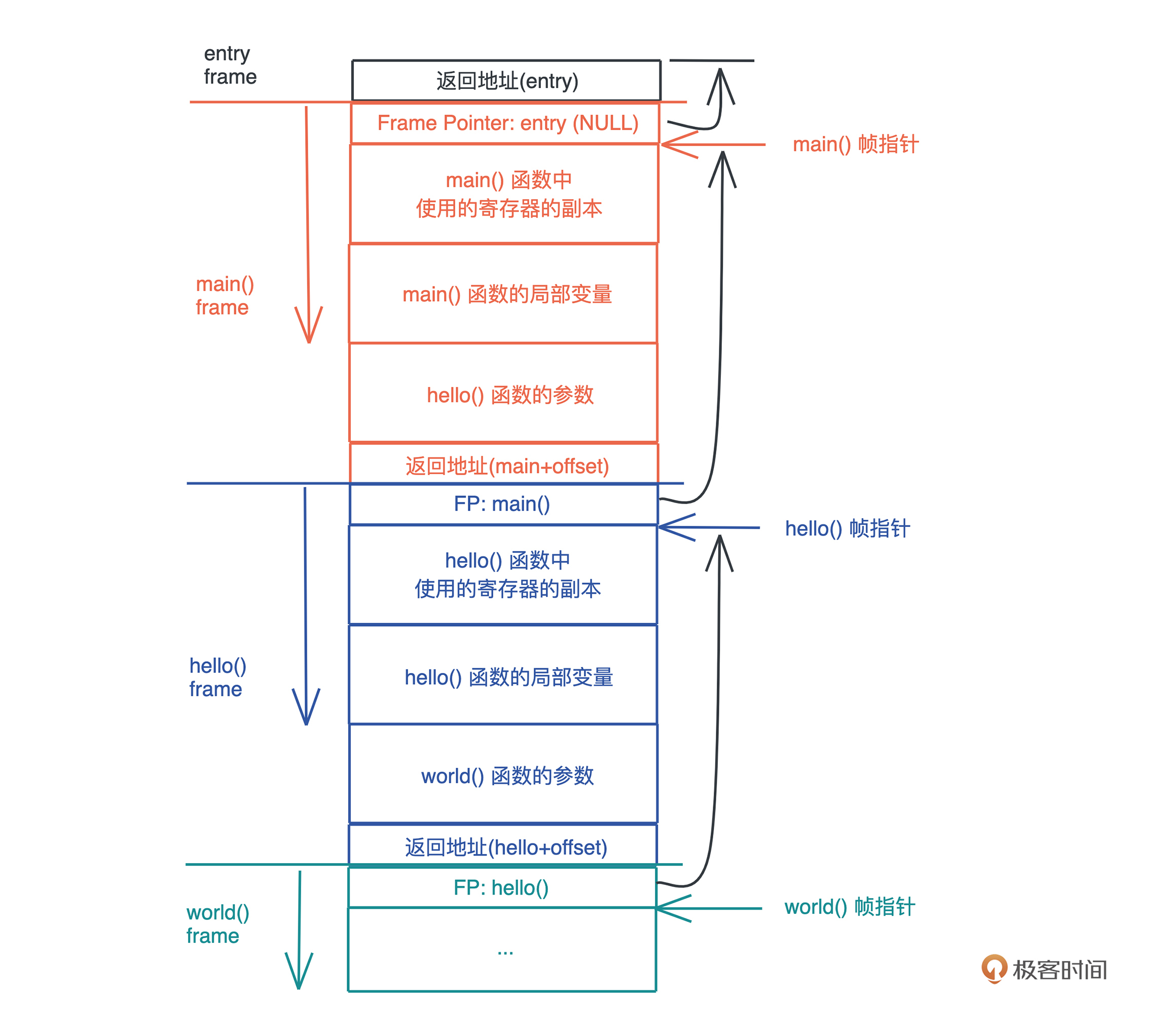
那一个函数运行时, 怎么确定究竟需要多大的帧呢?
这要归功于编译器。在编译并优化代码的时候,一个函数就是一个最小的编译单元。
在这个函数里,编译器得知道要用到哪些寄存器、栈上要放哪些局部变量,而这些都要在编译时确定。所以编译器就需要明确每个局部变量的大小,以便于预留空间。
这下我们就明白了: 在编译时,一切无法确定大小或者大小可以改变的数据,都无法安全地放在栈上,最好放在堆上。比如一个函数,参数是字符串:
fn say_name(name: String) {}
// 调用
say_name("Lindsey".to_string());
say_name("Rosie".to_string());
字符串的数据结构,在编译时大小不确定,运行时执行到具体的代码才知道大小。比如上面的代码,“Lindsey” 和 “Rosie” 的长度不一样,say_name() 函数只有在运行的时候,才知道参数的具体的长度。
所以,我们无法把字符串本身放在栈上,只能先将其放在堆上,然后在栈上分配对应的指针,引用堆上的内存。
放栈上的问题
从刚才的图中你也可以直观看到,栈上的内存分配是非常高效的。只需要改动栈指针(stack pointer),就可以预留相应的空间;把栈指针改动回来,预留的空间又会被释放掉。预留和释放只是动动寄存器,不涉及额外计算、不涉及系统调用,因而效率很高。
所以理论上说,只要可能,我们应该把变量分配到栈上,这样可以达到更好的运行速度。
那为什么在实际工作中,我们又要避免把大量的数据分配在栈上呢?
这主要是考虑到调用栈的大小,避免栈溢出(stack overflow)。一旦当前程序的调用栈超出了系统允许的最大栈空间,无法创建新的帧,来运行下一个要执行的函数,就会发生栈溢出,这时程序会被系统终止,产生崩溃信息。
过大的栈内存分配是导致栈溢出的原因之一,更广为人知的原因是递归函数没有妥善终止。一个递归函数会不断调用自己,每次调用都会形成一个新的帧,如果递归函数无法终止,最终就会导致栈溢出。
堆
栈虽然使用起来很高效,但它的局限也显而易见。 当我们需要动态大小的内存时,只能使用堆,比如可变长度的数组、列表、哈希表、字典,它们都分配在堆上。
堆上分配内存时,一般都会预留一些空间,这是最佳实践。
比如你创建一个列表,并往里添加两个值:
#![allow(unused)] fn main() { let mut arr = Vec::new(); arr.push(1); arr.push(2); }
这个列表实际预留的大小是 4,并不等于其长度 2。这是因为堆上内存分配会使用 libc 提供的 malloc() 函数,其内部会请求操作系统的系统调用,来分配内存。系统调用的代价是昂贵的,所以我们要避免频繁地 malloc()。
对上面的代码来说,如果我们需要多少就分配多少,那列表每次新增值,都要新分配一大块的内存,先拷贝已有数据,再把新的值添加进去,最后释放旧的内存,这样效率很低。所以在堆内存分配时,预留的空间大小 4 会大于需要的实际大小 2 。
除了动态大小的内存需要被分配到堆上外, 动态生命周期的内存也需要分配到堆上。
上文中我们讲到,栈上的内存在函数调用结束之后,所使用的帧被回收,相关变量对应的内存也都被回收待用。所以栈上内存的生命周期是不受开发者控制的,并且局限在当前调用栈。
而堆上分配出来的每一块内存需要显式地释放, 这就使堆上内存有更加灵活的生命周期,可以在不同的调用栈之间共享数据。
如下图所示:
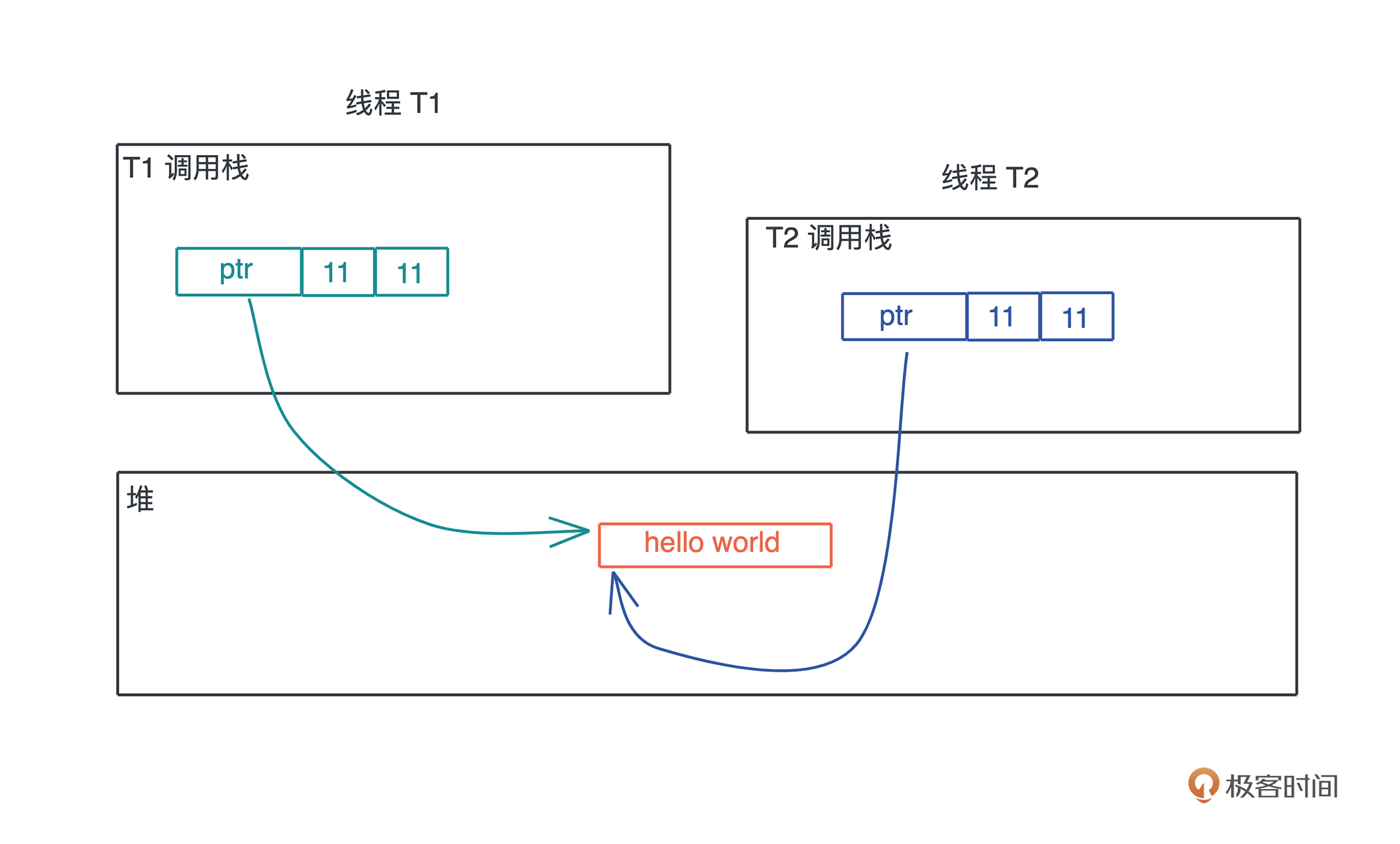
放堆上的问题
然而,堆内存的这种灵活性也给内存管理带来很多挑战。
如果手工管理堆内存的话,堆上内存分配后忘记释放,就会造成 内存泄漏。一旦有内存泄漏,程序运行得越久,就越吃内存,最终会因为占满内存而被操作系统终止运行。
如果堆上内存被多个线程的调用栈引用,该内存的改动要特别小心,需要加锁以独占访问,来避免潜在的问题。比如说,一个线程在遍历列表,而另一个线程在释放列表中的某一项,就可能访问野指针,导致 堆越界(heap out of bounds)。而堆越界是第一大内存安全问题。
如果堆上内存被释放,但栈上指向堆上内存的相应指针没有被清空,就有可能 发生使用已释放内存(use after free)的情况,程序轻则崩溃,重则隐含安全隐患。根据 微软安全反应中心(MSRC)的研究,这是第二大内存安全问题。
GC、ARC如何解决
为了避免堆内存手动管理造成的这些问题,以 Java 为首的一系列编程语言,采用了追踪式垃圾回收( Tracing GC)的方法,来自动管理堆内存。这种方式通过定期标记(mark)找出不再被引用的对象,然后将其清理(sweep)掉,来自动管理内存,减轻开发者的负担。
而 ObjC 和 Swift 则走了另一条路:自动引用计数( Automatic Reference Counting)。在编译时,它为每个函数插入 retain/release 语句来自动维护堆上对象的引用计数,当引用计数为零的时候,release 语句就释放对象。
我们来对比一下这两个方案。
从效率上来说,GC 在内存分配和释放上无需额外操作,而 ARC 添加了大量的额外代码处理引用计数,所以 GC 效率更高,吞吐量(throughput)更大。
但是,GC 释放内存的时机是不确定的,释放时引发的 STW(Stop The World),也会导致代码执行的延迟(latency)不确定。 所以一般携带 GC 的编程语言,不适于做嵌入式系统或者实时系统。当然, Erlang VM 是个例外, 它把 GC 的粒度下放到每个 process,最大程度解决了 STW 的问题。
我们使用 Android 手机偶尔感觉卡顿,而 iOS 手机却运行丝滑,大多是这个原因。而且做后端服务时,API 或者服务响应时间的 p99(99th percentile)也会受到 GC STW 的影响而表现不佳。
说句题外话,上面说的GC性能和我们常说的性能,涵义不太一样。常说的性能是吞吐量和延迟的总体感知,和实际性能是有差异的,GC 和 ARC 就是典型例子。GC 分配和释放内存的效率和吞吐量要比 ARC 高, 但因为偶尔的高延迟,导致被感知的性能比较差,所以会给人一种 GC 不如 ARC 性能好的感觉。
小结
今天我们重新回顾基础概念,分析了栈和堆的特点。
对于 存入栈上的值,它的大小在编译期就需要确定。栈上存储的变量生命周期在当前调用栈的作用域内,无法跨调用栈引用。
堆可以存入大小未知或者动态伸缩的数据类型。堆上存储的变量,其生命周期从分配后开始,一直到释放时才结束,因此堆上的变量允许在多个调用栈之间引用。但也导致堆变量的管理非常复杂,手工管理会引发很多内存安全性问题,而自动管理,无论是 GC 还是 ARC,都有性能损耗和其它问题。
一句话对比总结就是: 栈上存放的数据是静态的,固定大小,固定生命周期;堆上存放的数据是动态的,不固定大小,不固定生命周期。
下一讲我们会讨论基础概念,比如值和类型、指针和引用、函数、方法和闭包、接口和虚表、并发与并行、同步和异步,以及 Promise/async/await ,这些我们学习 Rust 或者任何语言都会接触到。
思考题
最后,是课后练习题环节,欢迎在留言区分享你的思考。
1.如果有一个数据结构需要在多个线程中访问,可以把它放在栈上吗?为什么?
2.可以使用指针引用栈上的某个变量吗?如果可以,在什么情况下可以这么做?
另外,文中出现的所有参考资料链接,我都会再统一整理到文末的“拓展阅读”板块,所以非常推荐你先跟着文章的思路走,学完之后如果有兴趣,可以看看我分享给你的其他资料。
如果你觉得有收获,也欢迎你分享给身边的朋友,邀TA一起讨论。我们下一讲见!
拓展阅读
5.课程的 GitHub仓库,内含后续思考题参考思路及项目的完整代码
串讲:编程开发中,那些你需要掌握的基本概念
你好,我是陈天。
上一讲我们了解了内存的基本运作方式,简单回顾一下:栈上存放的数据是静态的,固定大小,固定生命周期;堆上存放的数据是动态的,不固定大小,不固定生命周期。
今天我们来继续梳理,编程开发中经常接触到的其它基本概念。需要掌握的小概念点比较多,为了方便你学习,我把它们分为四大类来讲解: 数据(值和类型、指针和引用)、 代码(函数、方法、闭包、接口和虚表)、 运行方式(并发并行、同步异步和 Promise / async / await ),以及 编程范式(泛型编程)。

希望通过重温这些概念,你能够夯实软件开发领域的基础知识,这对你后续理解 Rust 里面的很多难点至关重要,比如所有权、动态分派、并发处理等。
好了,废话不多说,我们马上开始。
数据
数据是程序操作的对象,不进行数据处理的程序是没有意义的,我们先来重温和数据有关的概念,包括值和类型、指针和引用。
值和类型
严谨地说,类型是对值的区分,它包含了值在内存中的 长度、 对齐以及值可以进行的操作等信息。一个值是符合一个特定类型的数据的某个实体。比如 64u8,它是 u8 类型,对应一个字节大小、取值范围在 0~255 的某个整数实体,这个实体是 64。
值以类型规定的表达方式(representation)被存储成一组字节流进行访问。比如 64,存储在内存中的表现形式是 0x40,或者 0b 0100 0000。
这里你要注意, 值是无法脱离具体的类型讨论的。同样是内存中的一个字节 0x40,如果其类型是 ASCII char,那么其含义就不是 64,而是 @ 符号。
不管是强类型的语言还是弱类型的语言,语言内部都有其类型的具体表述。一般而言,编程语言的类型可以分为原生类型和组合类型两大类。
原生类型(primitive type)是编程语言提供的最基础的数据类型。比如字符、整数、浮点数、布尔值、数组(array)、元组(tuple)、指针、引用、函数、闭包等。 所有原生类型的大小都是固定的,因此它们可以被分配到栈上。
组合类型(composite type)或者说复合类型,是指由一组原生类型和其它类型组合而成的类型。组合类型也可以细分为两类:
- 结构体(structure type): 多个类型组合在一起共同表达一个值的复杂数据结构。比如 Person 结构体,内部包含 name、age、email 等信息。用代数数据类型(algebraic data type)的说法,结构体是 product type。
- 标签联合(tagged union):也叫不相交并集(disjoint union), 可以存储一组不同但固定的类型中的某个类型的对象,具体是哪个类型由其标签决定。比如 Haskell 里的 Maybe 类型,或者 Swift 中的 Optional 就是标签联合。用代数数据类型的说法,标签联合是 sum type。
另外不少语言不支持标签联合,只取其标签部分,提供了枚举类型(enumerate)。枚举是标签联合的子类型,但功能比较弱,无法表达复杂的结构。
看定义可能不是太好理解,你可以看这张图:
指针和引用
在内存中,一个值被存储到内存中的某个位置,这个位置对应一个内存地址。而指针是一个持有内存地址的值,可以通过解引用(dereference)来访问它指向的内存地址,理论上可以解引用到任意数据类型。
引用(reference)和指针非常类似,不同的是, 引用的解引用访问是受限的,它只能解引用到它引用数据的类型,不能用作它用。比如,指向 42u8 这个值的一个引用,它解引用的时候只能使用 u8 数据类型。
所以,指针的使用限制更少,但也会带来更多的危害。如果没有用正确的类型解引用一个指针,那么会引发各种各样的内存问题,造成系统崩溃或者潜在的安全漏洞。
刚刚讲过, 指针和引用是原生类型,它们可以分配在栈上。
根据指向数据的不同,某些引用除了需要一个指针指向内存地址之外,还需要内存地址的长度和其它信息。
如上一讲提到的指向 “hello world” 字符串的指针,还包含字符串长度和字符串的容量,一共使用了 3 个 word,在 64 位 CPU 下占用 24 个字节,这样 比正常指针携带更多信息的指针,我们称之为胖指针(fat pointer)。很多数据结构的引用,内部都是由胖指针实现的。
代码
数据是程序操作的对象,而代码是程序运行的主体,也是我们开发者把物理世界中的需求转换成数字世界中逻辑的载体。我们会讨论函数和闭包、接口和虚表。
函数、方法和闭包
函数是编程语言的基本要素,它是对完成某个功能的一组相关语句和表达式的封装。 函数也是对代码中重复行为的抽象。在现代编程语言中,函数往往是一等公民,这意味着函数可以作为参数传递,或者作为返回值返回,也可以作为复合类型中的一个组成部分。
在面向对象的编程语言中,在类或者对象中定义的函数,被称为方法(method)。方法往往和对象的指针发生关系,比如 Python 对象的 self 引用,或者 Java 对象的 this 引用。
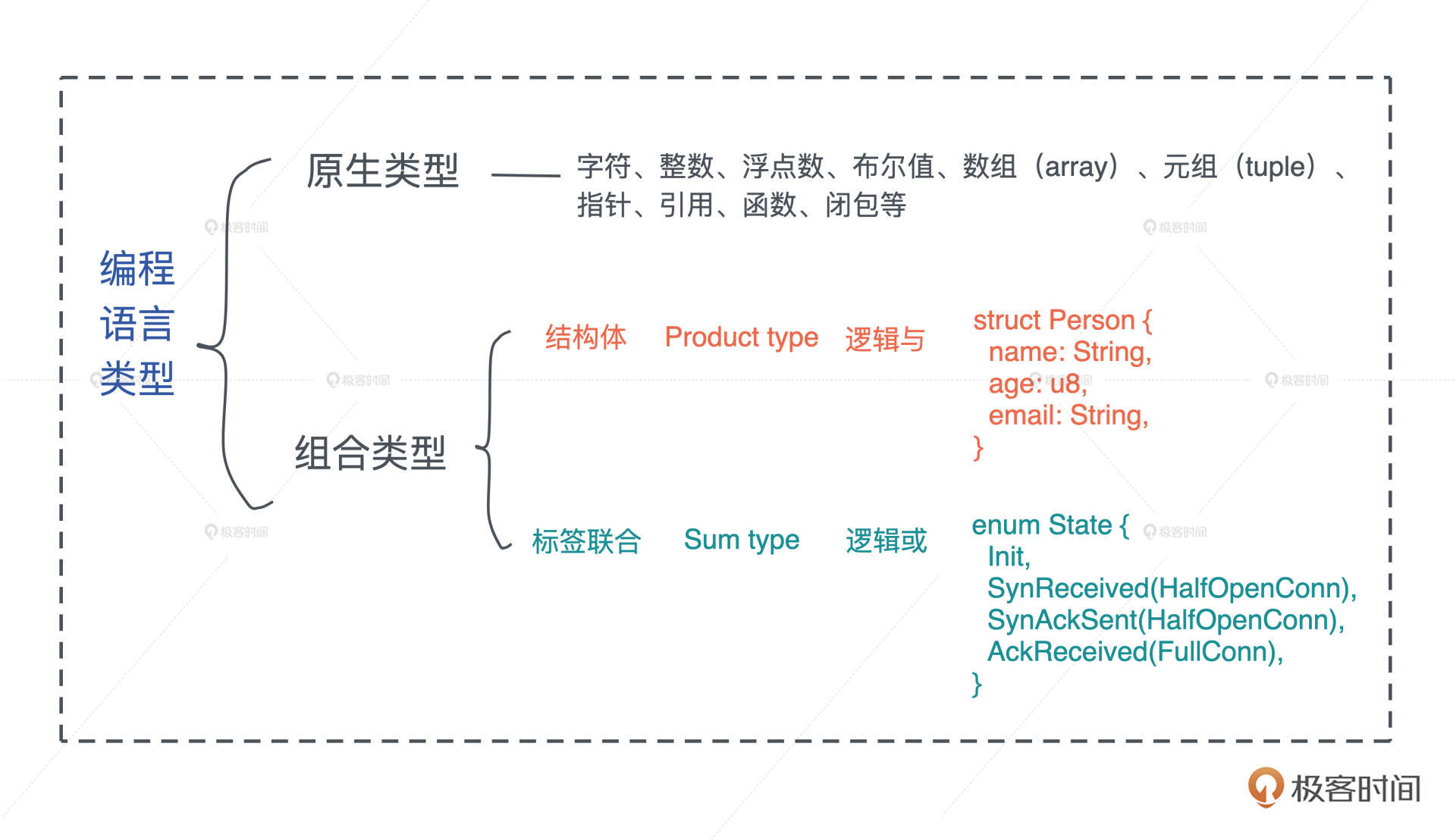
而闭包是将函数,或者说代码和其环境一起存储的一种数据结构。 闭包引用的上下文中的自由变量,会被捕获到闭包的结构中,成为闭包类型的一部分。
一般来说,如果一门编程语言,其函数是一等公民,那么它必然会支持闭包(closure),因为函数作为返回值往往需要返回一个闭包。
你可以看这张图辅助理解,图中展示了一个闭包对上下文环境的捕获。可以 在这里 运行这段代码:
接口和虚表
接口是一个软件系统开发的核心部分,它反映了系统的设计者对系统的抽象理解。 作为一个抽象层,接口将使用方和实现方隔离开来,使两者不直接有依赖关系,大大提高了复用性和扩展性。
很多编程语言都有接口的概念,允许开发者面向接口设计,比如 Java 的 interface、Elixir 的 behaviour、Swift 的 protocol 和 Rust 的 trait。
比如说,在 HTTP 中,Request/Response 的服务处理模型其实就是一个典型的接口,我们只需要按照服务接口定义出不同输入下,从 Request 到 Response 具体该如何映射,通过这个接口,系统就可以在合适的场景下,把符合要求的 Request 分派给我们的服务。
面向接口的设计是软件开发中的重要能力,而 Rust 尤其重视接口的能力。在后续讲到 Trait 的章节,我们会详细介绍如何用 Trait 来进行接口设计。
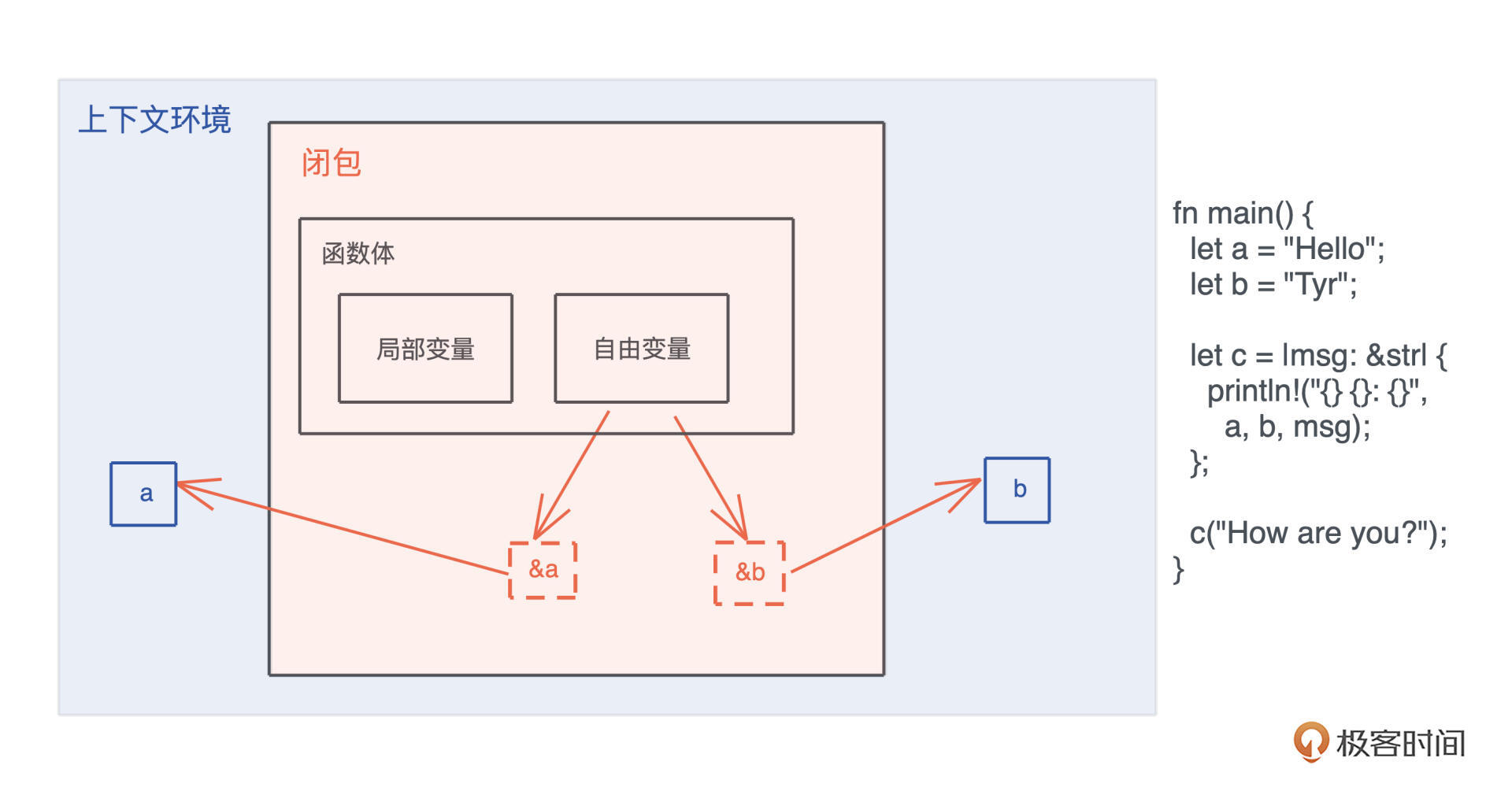
当我们在运行期使用接口来引用具体类型的时候,代码就具备了运行时多态的能力。但是,在运行时,一旦使用了关于接口的引用,变量原本的类型被抹去,我们无法单纯从一个指针分析出这个引用具备什么样的能力。
因此, 在生成这个引用的时候,我们需要构建胖指针,除了指向数据本身外,还需要指向一张涵盖了这个接口所支持方法的列表。这个列表,就是我们熟知的虚表(virtual table)。
下图展示了一个 Vec 数据在运行期被抹去类型,生成一个指向 Write 接口引用的过程:
由于虚表记录了数据能够执行的接口,所以在运行期,我们想对一个接口有不同实现,可以根据上下文动态分派。
比如我想为一个编辑器的 Formatter 接口实现不同语言的格式化工具。我们可以在编辑器加载时,把所有支持的语言和其格式化工具放入一个哈希表中,哈希表的 key 为语言类型,value 为每种格式化工具 Formatter 接口的引用。这样,当用户在编辑器打开某个文件的时候,我们可以根据文件类型,找到对应 Formatter 的引用,来进行格式化操作。
运行方式
程序在加载后, 代码以何种方式运行,往往决定着程序的执行效率。所以我们接下来讨论并发、并行、同步、异步以及异步中的几个重要概念 Promise/async/await。
并发(concurrency)与并行(parallel)
并发和并行是软件开发中经常遇到的概念。
并发是同时与多件事情打交道的能力,比如系统可以在任务 1 做到一定程度后,保存该任务的上下文,挂起并切换到任务 2,然后过段时间再切换回任务 1。
并行是同时处理多件事情的手段。也就是说,任务 1 和任务 2 可以在同一个时间片下工作,无需上下文切换。下图很好地阐释了二者的区别:
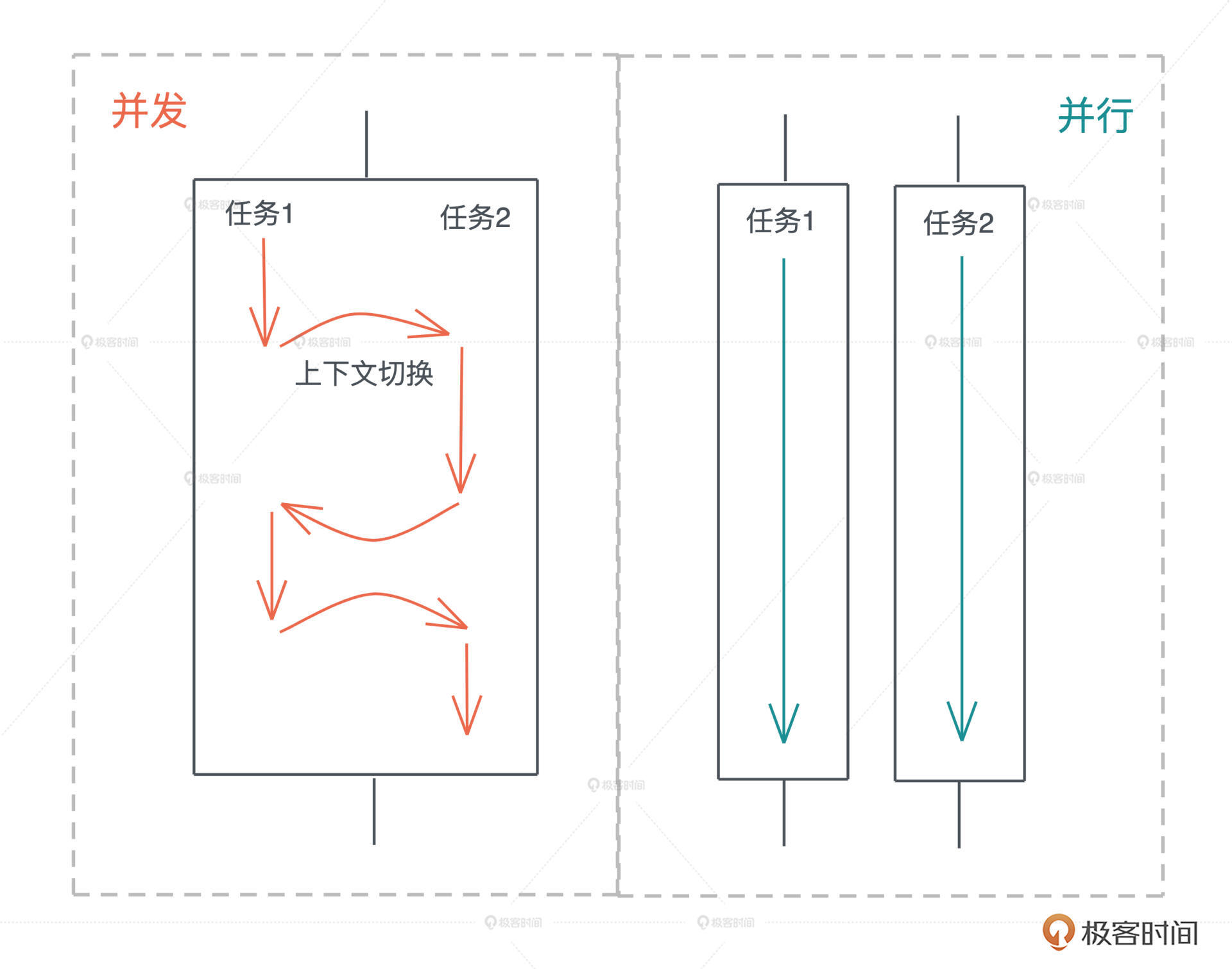
并发是一种能力,而并行是一种手段。当我们的系统拥有了并发的能力后,代码如果跑在多个 CPU core 上,就可以并行运行。所以我们平时都谈论高并发处理,而不会说高并行处理。
很多拥有高并发处理能力的编程语言,会在用户程序中嵌入一个 M:N 的调度器,把 M 个并发任务,合理地分配在 N 个 CPU core 上并行运行,让程序的吞吐量达到最大。
同步和异步
同步是指一个任务开始执行后,后续的操作会阻塞,直到这个任务结束。在软件中,我们大部分的代码都是同步操作,比如 CPU,只有流水线中的前一条指令执行完成,才会执行下一条指令。一个函数 A 先后调用函数 B 和 C,也会执行完 B 之后才执行 C。
同步执行保证了代码的因果关系(causality),是程序正确性的保证。
然而在遭遇 I/O 处理时,高效 CPU 指令和低效 I/O 之间的巨大鸿沟,成为了软件的性能杀手。下图 对比了 CPU、内存、I/O 设备、和网络的延迟:
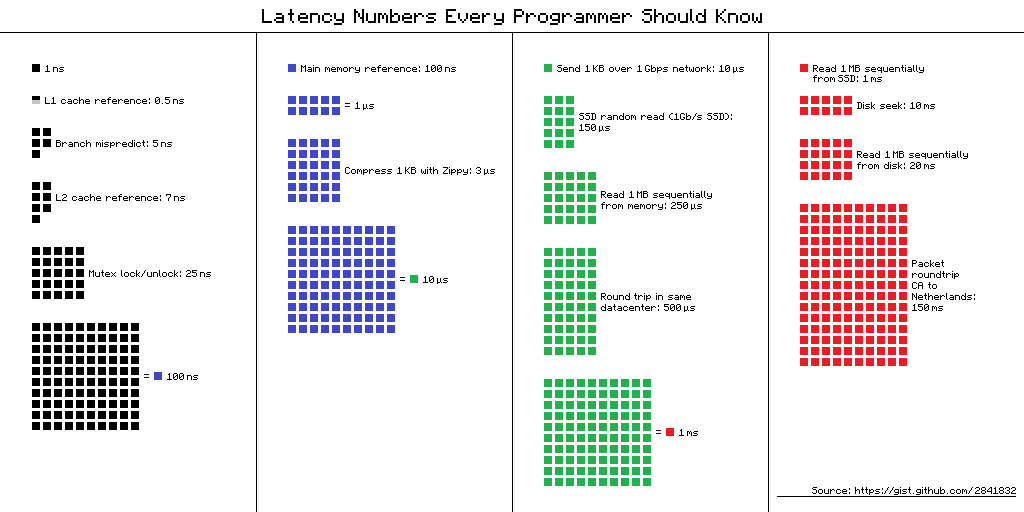
我们可以看到和内存访问相比,I/O 操作的访问速度低了两个数量级,一旦遇到 I/O 操作,CPU 就只能闲置来等待 I/O 设备运行完毕。因此,操作系统为应用程序提供了异步 I/O,让应用可以在当前 I/O 处理完毕之前,将 CPU 时间用作其它任务的处理。
所以, 异步是指一个任务开始执行后,与它没有因果关系的其它任务可以正常执行,不必等待前一个任务结束。
在异步操作里,异步处理完成后的结果,一般用 Promise 来保存,它是一个对象,用来描述在未来的某个时刻才能获得的结果的值,一般存在三个状态;
- 初始状态,Promise 还未运行;
- 等待(pending)状态,Promise 已运行,但还未结束;
- 结束状态, Promise 成功解析出一个值,或者执行失败。
如果你对 Promise 这个词不太熟悉,在很多支持异步的语言中,Promise 也叫 Future / Delay / Deferred 等。除了这个词以外,我们也经常看到 async/await 这对关键字。
一般而言, async 定义了一个可以并发执行的任务,而 await 则触发这个任务并发执行。大多数语言中,async/await 是一个语法糖(syntactic sugar),它使用状态机将 Promise 包装起来,让异步调用的使用感觉和同步调用非常类似,也让代码更容易阅读。
编程范式
为了在不断迭代时,更好地维护代码,我们还会 引入各种各样的编程范式,来提升代码的质量。所以最后来谈谈泛型编程。
如果你来自于弱类型语言,如 C / Python / JavaScript,那泛型编程是你需要重点掌握的概念和技能。泛型编程包含两个层面,数据结构的泛型和使用泛型结构代码的泛型化。
数据结构的泛型
首先是数据结构的泛型,它也往往被称为参数化类型或者参数多态,比如下面这个数据结构:
#![allow(unused)] fn main() { struct Connection<S> { io: S, state: State, } }
它有一个参数 S,其内部的域 io 的类型是 S,S 具体的类型只有在使用 Connection 的上下文中才得到绑定。
你可以把参数化数据结构理解成一个产生类型的函数, 在“调用”时,它接受若干个使用了具体类型的参数,返回携带这些类型的类型。比如我们为 S 提供 TcpStream 这个类型,那么就产生 Connection 这个类型,其中 io 的类型是 TcpStream。
这里你可能会疑惑,如果 S 可以是任意类型,那我们怎么知道 S 有什么行为?如果我们要调用 io.send() 发送数据,编译器怎么知道 S 包含这个方法?
这是个好问题, 我们需要用接口对 S 进行约束。所以我们经常看到,支持泛型编程的语言,会提供强大的接口编程能力,在后续的课程中在讲 Rust 的 trait 时,我会再详细探讨这个问题。
数据结构的泛型是一种高级抽象,就像我们人类用数字抽象具体事物的数量,又发明了代数来进一步抽象具体的数字一样。它带来的好处是我们可以延迟绑定,让数据结构的通用性更强,适用场合更广阔;也大大减少了代码的重复,提高了可维护性。
代码的泛型化
泛型编程的另一个层面是使用泛型结构后代码的泛型化。当我们使用泛型结构编写代码时,相关的代码也需要额外的抽象。
这里用我们熟悉的二分查找的例子解释会比较清楚:
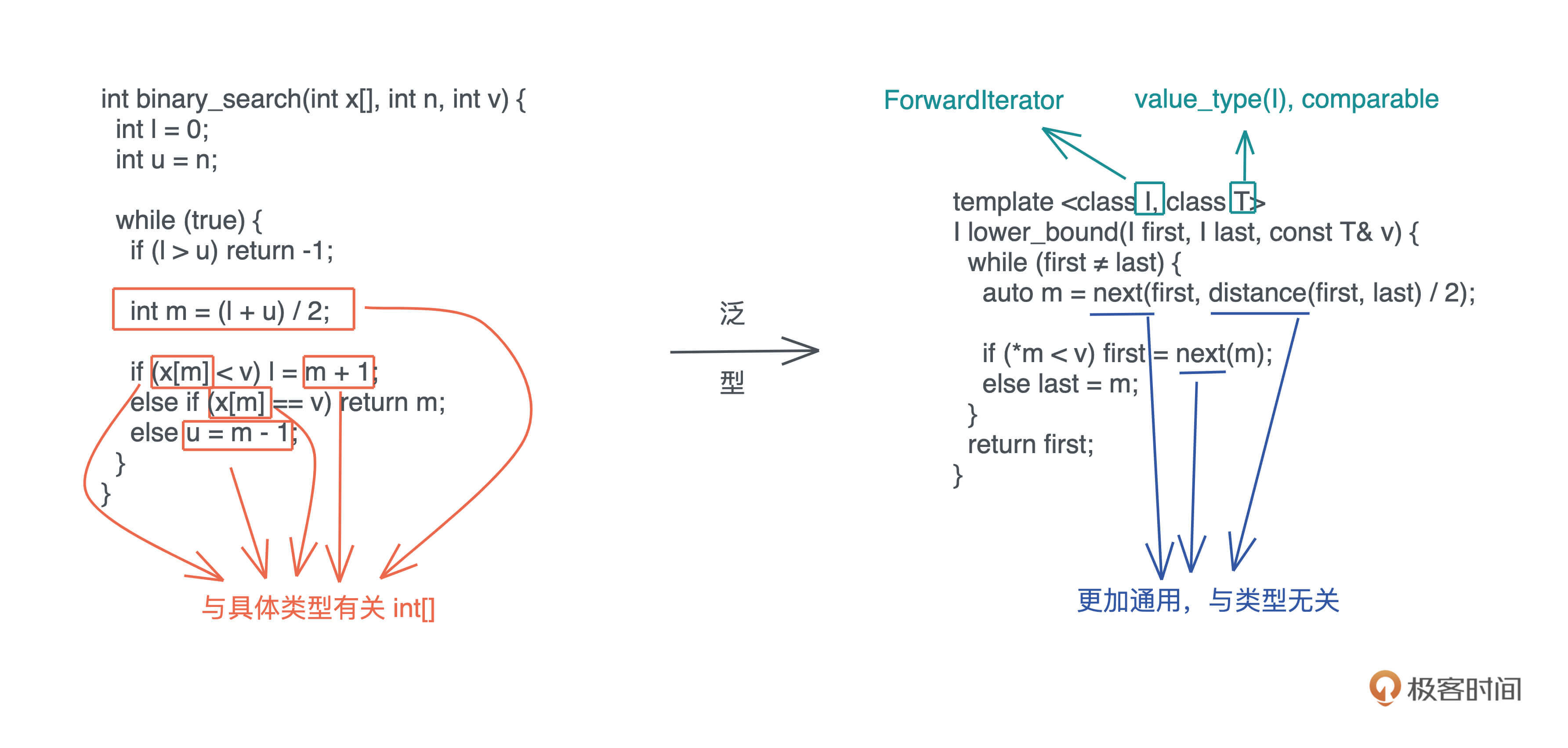
左边用 C 撰写的二分查找,标记的几处操作隐含着和 int[] 有关,所以如果对不同的数据类型做二分查找,实现也要跟着改变。右边 C++ 的实现,对这些地方做了抽象,让我们可以用同一套代码二分查找迭代器(iterator)的数据类型。
同样的,这样的代码可以在更广阔的场合使用,更简洁容易维护。
小结
今天我们讨论了四大类基础概念:数据、代码、运行方式和编程范式。
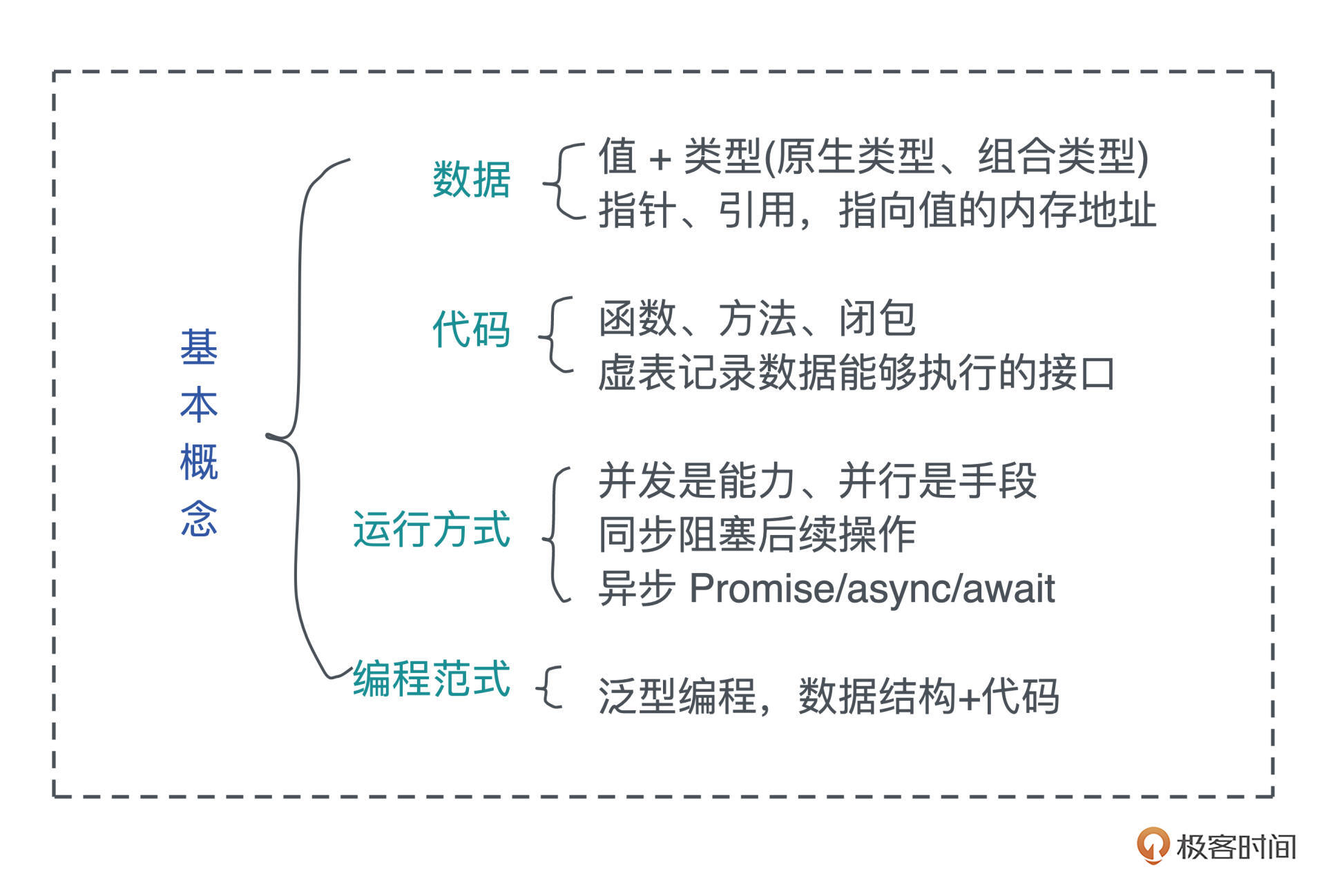
值 无法离开类型单独讨论, 类型 一般分为原生类型和组合类型。 指针和引用 都指向值的内存地址,只不过二者在解引用时的行为不一样。引用只能解引用到原来的数据类型,而指针没有这个限制,然而,不受约束的指针解引用,会带来内存安全方面的问题。
函数 是代码中重复行为的抽象, 方法 是对象内部定义的函数,而 闭包 是一种特殊的函数,它会捕获函数体内使用到的上下文中的自由变量,作为闭包成员的一部分。
而 接口 将调用者和实现者隔离开,大大促进了代码的复用和扩展。面向接口编程可以让系统变得灵活,当使用接口去引用具体的类型时,我们就需要 虚表 来辅助运行时代码的执行。有了虚表,我们可以很方便地进行动态分派,它是运行时多态的基础。
在代码的运行方式中, 并发 是 并行 的基础,是同时与多个任务打交道的能力;并行是并发的体现,是同时处理多个任务的手段。 同步 阻塞后续操作, 异步 允许后续操作。被广泛用于异步操作的 Promise 代表未来某个时刻会得到的结果,async/await 是 Promise 的封装,一般用状态机来实现。
泛型编程 通过参数化让数据结构像函数一样延迟绑定,提升其通用性,类型的参数可以用接口约束,使类型满足一定的行为,同时,在使用泛型结构时,我们的代码也需要更高的抽象度。
这些基础概念,这对于后续理解 Rust 的很多概念至关重要。如果你对某些概念还是有些模糊,务必留言,我们可以进一步讨论。
思考题
(现在我们还没有讲到 Rust 的具体语法,所以你可以用自己平时常用的语言来思考这几道题,巩固你对基本概念的理解)
1.有一个指向某个函数的指针,如果将其解引用成一个列表,然后往列表中插入一个元素,请问会发生什么?(对比不同语言,看看这种操作是否允许,如果允许会发生什么)
2.要构造一个数据结构 Shape,可以是 Rectangle、 Circle 或是 Triangle,这三种结构见如下代码。请问 Shape 类型该用什么数据结构实现?怎么实现?
#![allow(unused)] fn main() { struct Rectangle { a: f64, b: f64, } struct Circle { r: f64, } struct Triangle { a: f64, b: f64, c: f64, } }
3.对于上面的三种结构,如果我们要定义一个接口,可以计算周长和面积,怎么计算?
欢迎在留言区分享你的思考。今天是我们打卡学习的第二讲,如果你觉得有收获,也欢迎你分享给你身边的朋友,邀TA一起讨论。
参考资料
Latency numbers every programmer should know, 对比了 CPU、内存、I/O 设备、和网络的延迟
加餐|这个专栏你可以怎么学,以及Rust是否值得学?
你好,我是陈天。
离课程上线到现在,确实没有想到有这么多的同学想要学习 Rust,首先谢谢你的支持、鼓励和反馈。
这两天处理留言,有好多超出我预期的深度发言和问题,比如说 @pedro @有铭 @f 等等同学,不仅让我实实在在地感受到了你们的热情,也让我更加坚定了要教好这门课的决心。正好在这篇加餐中,我来详细谈谈同学们比较关心的一些问题。
首先会从控制代码缺陷的角度,聊一聊为什么说 Rust 解决了我们开发者在实践过程中遇到的很多问题,而这些问题目前大部分语言都没有很好地解决;然后我们会再讲讲为什么 Rust 未来可期,顺便比较一下 Rust 和 Golang,这是留言里问的比较多的;最后还会分享一些 Rust 的学习资料。
代码缺陷
从软件开发的角度来看,一个软件系统想要提供具有良好用户体验的功能, 最基本的要求就是控制缺陷。为了控制缺陷,在软件工程中,我们定义了各种各样的流程,从代码的格式,到 linting,到 code review,再到单元测试、集成测试、手工测试。
所有这些手段就像一个个漏斗,不断筛查代码,把缺陷一层层过滤掉,让软件在交付到用户时尽善尽美。我画了一张图,将在开发过程中可能出现的缺陷分了类,从上往下看:
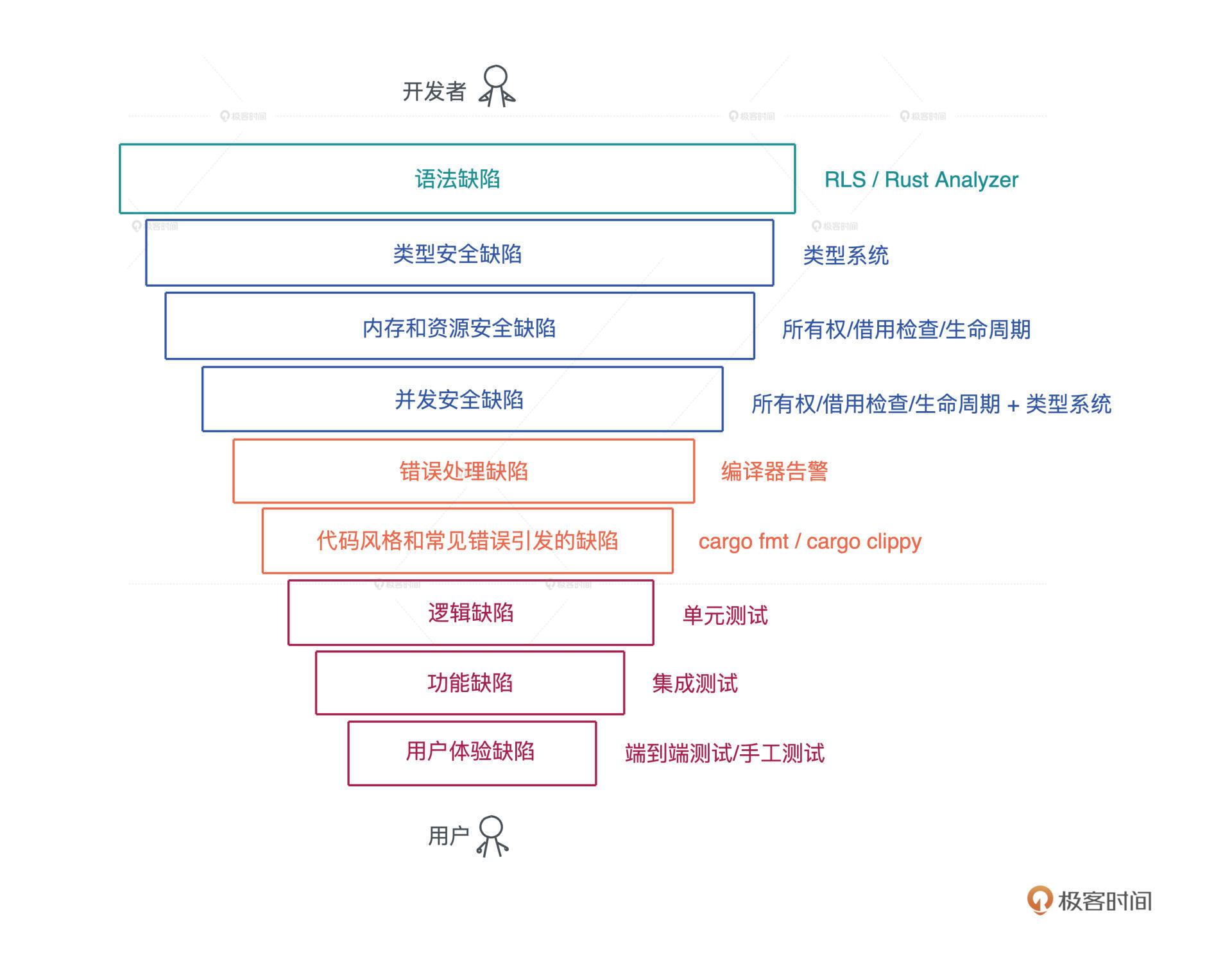
(课程里的图片都是用 excalidraw 绘制的)
语法缺陷
首先在我们开始写代码的时候,在语法层面可能会出现小问题,比如说初学者会对某些语法点不太熟悉,资深工程师在用一些不常用的语法时也会出现语法缺陷。
对于这个缺陷,目前大部分的编程语言都会在你写代码的时候,给到详尽的提示,告诉你语法错误出现在哪里。
对 Rust 来说,它提供了 Rust Language Server / Rust Analyzer 第一时间报告语法错误,如果你用第三方 IDE 如 VSCode,会有这些工具的集成。
类型安全缺陷
然后就是类型方面的缺陷,这类缺陷需要语言本身的类型系统,帮助你把缺陷找出来,所以大部分非类型安全的语言,对这类错误就束手无策了。
以Python/Elixir为例,如果你期望函数的参数使用类型A,但是实际用了类型B,这种错误只有你的代码在真正运行的时候才能被检查出来,相当于把错误发现的时机大大延后了。
所以现在很多脚本语言也倾向尽可能让开发者多写一些类型标注,但因为它不是语言原生的部分,所以也很难强制,在实际写脚本语言的代码时,你需要特别注意类型安全。
内存和资源安全缺陷
几乎所有的语言中都会有内存安全问题。
对于内存自动管理的语言来说,自动管理机制可以帮你解决大部分内存问题,不会出现内存使用了没有释放、使用了已释放内存、使用了悬停指针等等情况。
我们之前也讲到了,大部分语言,如 Java / Python / Golang / Elixir 等,他们通过语言的运行时解决了内存安全问题。
但是这只是大部分被解决了,还有比如逻辑上存在的内存泄漏的问题,比如一个带 TTL 的缓存,如果没设计好,表中的内容超时后并没有被删除,就会导致内存使用一直增长。这种因为设计缺陷导致的内存泄漏,现在所有语言都没有能够解决这个问题,只能说尽可能地解决。
资源安全缺陷也是大部分语言都会有的问题,诸如文件/socket 这样的资源,如果分配出来但没有很好释放,就会带来资源的泄漏,支持 GC 的语言对此也无能为力,很多时候只能靠程序员手工释放。
然而资源的释放并不简单,尤其是在做异常处理或者非正常流程的时候,很容易忘记要释放已经分配的资源。
Rust 可以说基本上解决了主要的内存和资源的安全问题,通过所有权、借用检查和生命周期检查,来保证内存和资源一旦被分配,在其生命周期结束时,会被释放掉。
并发安全缺陷
 这个问题发生在支持多线程的语言中,比如说两个线程间访问同一个变量,如果没有做合适的临界区保护,就很容易发生并发安全问题。
这个问题发生在支持多线程的语言中,比如说两个线程间访问同一个变量,如果没有做合适的临界区保护,就很容易发生并发安全问题。
Rust 通过所有权规则和类型系统,主要是两个 trait:Send/Sync 来解决这个问题。
很多高级语言会把线程概念屏蔽掉,只允许开发者使用语言提供的运行时来保证并发安全,比如Golang 要使用 channel 和 Goroutine 、Erlang 只能用 Erlang process,只要你在它这个框架下,并发处理就是安全的。
这样可以处理绝大多数并发场景,但遇到某些情况就容易导致效率不高,甚至阻塞其它并发任务。比如当有一个长时间运行的 CPU 密集型任务,使用单独的线程来处理要好得多。
处理并发有很多手段,但是大部分语言为了并发安全,把不少手段都屏蔽了,开发者无法接触到,但是Rust都提供给你,同时还提供了很好的并发安全保障,让你可以在合适的场景,安全地使用合适的工具。
错误处理缺陷
错误处理作为代码的一个分支,会占到代码量的30%甚至更多。在实际工程中,函数频繁嵌套的时候,整个过程会变得非常复杂,一旦处理不好就会引入缺陷。常见的问题是系统出错了,但抛出的错误并没有得到处理,导致程序在后续的运行中崩溃。
很多语言并没有强制开发者一定要处理错误,Rust 使用 Result<T, E> 类型来保证错误的类型安全,还强制你必须处理这个类型返回的值,避免开发者丢弃错误。
代码风格和常见错误引发的缺陷
很多语言都会提供代码格式化工具和 linter 来消灭这类缺陷。Rust 有内置的 cargo fmt 和 cargo clippy 来帮助开发者统一代码风格,来避免常见的开发错误。
再往下的三类缺陷是语言和编译器无法帮助解决的。
- 对于逻辑缺陷,我们需要有不错的单元测试覆盖率;
- 对于功能缺陷,需要通过足够好的集成测试,把用户主要使用的功能测试一遍;
- 对于用户体验缺陷,需要端到端的测试,甚至手工测试,才能发现。
从上述介绍中你可以看到,Rust 帮我们 把尽可能多的缺陷扼杀在摇篮中。Rust 在编译时解决掉的很多缺陷,如资源释放安全、并发安全和错误处理方面的缺陷,在其他大多数语言中并没有完整的解决方案。
所以 Rust 这门语言,让开发者的时间和精力都尽可能的放在对逻辑、功能、用户体验缺陷的优化上。
引入缺陷的代价
我们再来从引入缺陷的代价这个角度来看,Rust 这样的处理方式到底有什么好处。
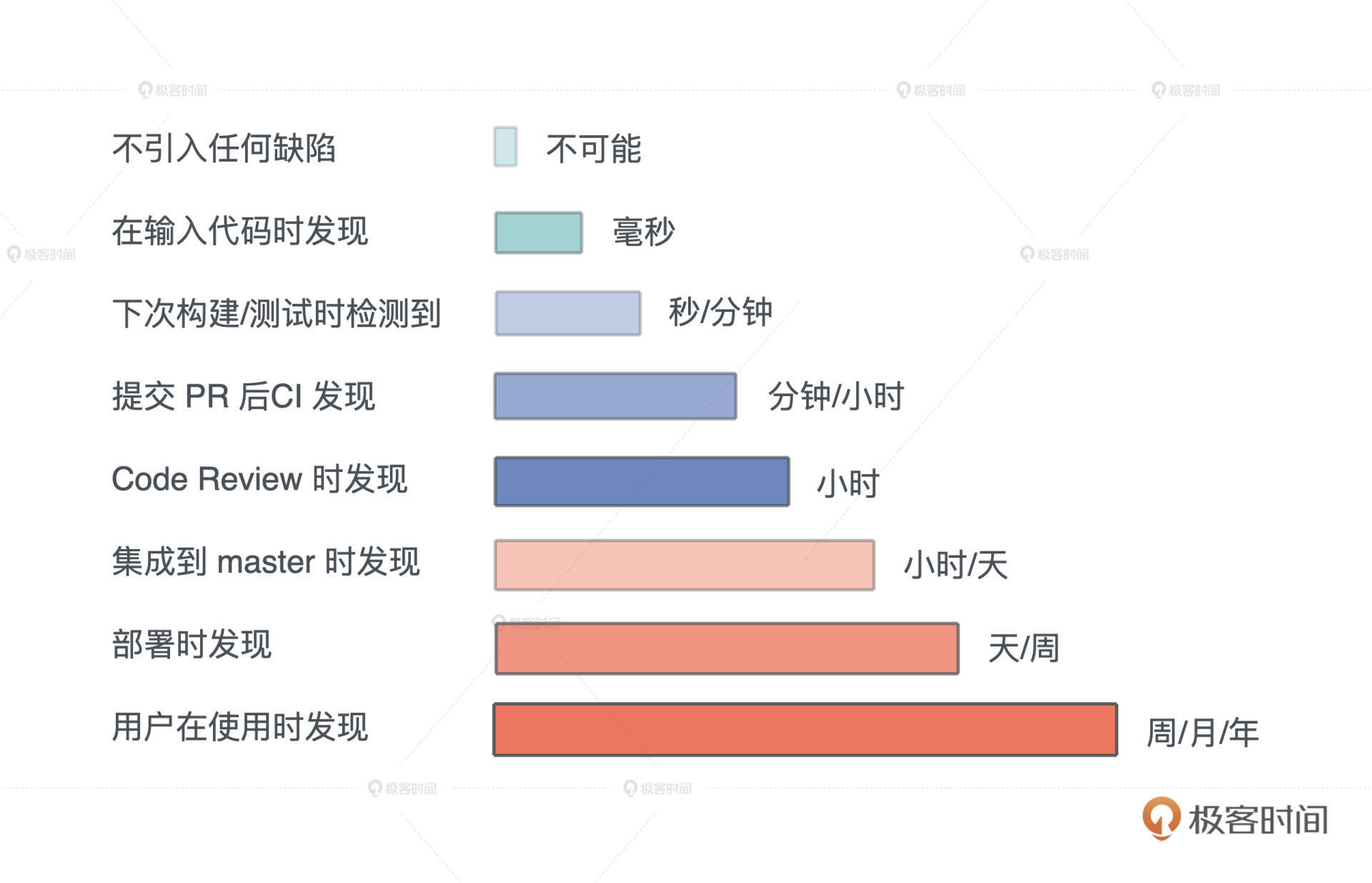
首先,任何系统不引入缺陷是不可能的。
如果在写代码的时候就发现缺陷,纠正的时间是毫秒到秒级;如果在测试的时候检测出来,那可能是秒到分钟级。以此类推,如果缺陷在从code review 到集成到master才被发现,那时间就非常长。
如果一直到用户使用的时候才发现,那可能是以周、月,甚至以年为单位。我之前做防火墙系统时,一个新功能的 bug 往往在一年甚至两年之后,才在用户的生产环境中被暴露出来,这个时候再去解决缺陷的代价就非常大。
所以Rust在设计之初, 尽可能把大量缺陷在编译期,在秒和分钟级就替你检测出来,让你修改,不至于把缺陷带到后续环境,最大程度的保证代码质量。
这也是为什么虽然 Rust 初学者前期需要和编译器做艰难斗争,但这是非常值得的,只要你跨过了这道坎,能够让代码编译通过,基本上你代码的安全性没有太大问题。
语言发展前景判断
有很多同学比较关心 Rust 的发展前景,留言问 Rust 和其他语言的对比,经常会聊现在或者未来什么语言会被Rust替代、Rust会不会一统前后端天下等等。我觉得不会。
每种语言都有它们各自的优劣和适用场景,谈不上谁一定取代谁。社区的形成、兴盛和衰亡是一个长久的过程,就像“世界上最好的语言 PHP”也还在顽强地生长着。
那么如何判断一门新的语言的发展前景呢?下图是我用 pandas 处理过的 modulecounts 的数据,这个数据统计了主流语言的库的数量。可以看到 2019 年初 Rust crates 的起点并不高,只有两万出头,两年后就有六万多了。
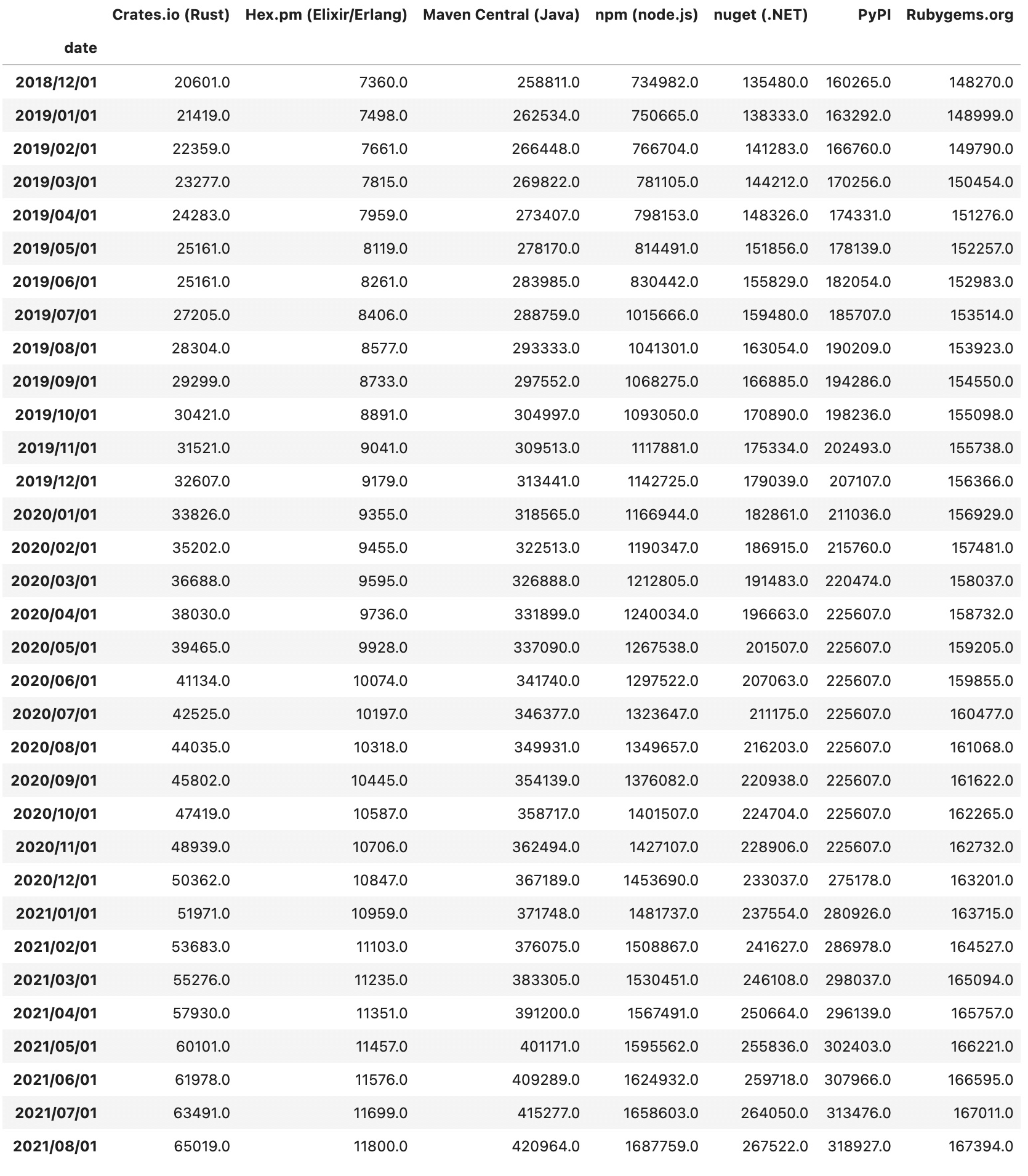
作为一门新的语言,Rust 生态虽然绝对数量不高,但增长率一直遥遥领先,过去两年多的增长速度差不多是第二名 NPM 的两倍。很遗憾,Golang 的库没有一个比较好的统计渠道,所以这里没法比较 Golang 的数据。但和 JavaScript / Java / Python 等语言的对比足以说明 Rust 的潜力。
Rust 和 Golang
很多同学关心 Rust 和 Golang 的对比,其实网上有很多详尽的分析, 这一篇 比较不错可以看看。我这里也简单说一下。
Rust 和 Golang 重叠的领域主要在服务开发领域。
Golang 的优点是简单、上手快,语言已经给你安排好了并发模型,直接用即可。对于日程紧迫、有很多服务要写,且不在乎极致性能的开发团队,Golang 是不错的选择。
Golang 因为设计之初要考虑如何能适应新时代的并发需求,所以使用了运行时、使用调度器调度 Goroutine ,在Golang中内存是不需要开发者手动释放的,所以运行时中还有GC来帮助开发者管理内存。
另外, 为了语法简便,在语言诞生之初便不支持泛型,这也是目前 Golang 最被诟病的一点,因为一旦系统复杂到一定程度,你的每个类型都需要做一遍实现。
Golang 可能会在 2022 年的 1.18 版本添加对泛型的支持,但泛型对 Golang 来说是一把达摩克利斯之剑,它带来很多好处,但同时会大大破坏 Golang 的简洁和极速的编译体验,到时候可能会带给开发者这样一种困惑:既然 Golang 已经变得不简单,不那么容易上手,我为何不学 Rust 呢?
Rust 的很多设计思路和 Golang 相反。
Go 相对小巧,类型系统很简单;而 Rust 借鉴了Haskell,有完整的类型系统,支持泛型。为了性能的考虑,Rust 在处理泛型函数的时候会做 单态化( Monomorphization ),泛型函数里每个用到的类型会编译出一份代码,这也是为什么在编译的时候 Rust 编译速度如此缓慢。
Rust面向系统级的开发,Go 虽然想做新时代的C,但是它并不适合面向系统级开发,使用场景更多是应用程序、服务等的开发,因为它的庞大的运行时,决定了它不适合做直接和机器打交道的底层开发。
Rust的诞生目标就是取代C/C++,想要做出更好的系统层面的开发工具, 所以在语言设计之初就要求不能有运行时。所以你看到的类似Golang运行时的库比如Tokio,都是第三方库,不在语言核心中,这样可以把是否需要引入运行时的自由度给到开发者。
Rust 社区里有句话说得好:
Go for the code that has to ship tomorrow, Rust for the code that has to keep running for the next five years.
所以,我对 Rust 的前途持非常乐观的态度。它在系统开发层面可以取代一部分 C/C++ 的场景、在服务开发层面可以和 Java/Golang 竞争、在高性能前端应用通过编译成 WebAssembly,可以部分取代 JavaScript,同时,它又可以方便地通过 FFI 为各种流行的脚本语言提供安全的、高性能的底层库。
我觉得在整个编程语言的生态里,未来 Rust 会像水一样,无处不在且善利万物。
最后给你分享一下我在学习 Rust 的过程中觉得不错的一些资料,也顺带会说明怎么配合这门课程使用。
官方学习资料
Rust 社区里就有大量的学习资料供我们使用。
首先是官方的 Rust book,它涵盖了语言的方方面面,是入门 Rust 最权威的免费资料。不过这本书比较细碎,有些需要重点解释的内容又一笔带过,让人读完还是云里雾里的。
我记得当时学习 Deref trait 时,官方文档这段文字直接把我看懵了:
Rust does deref coercion when it finds types and trait implementations in three cases:
- From &T to &U when T: Deref<Target=U>
- From &mut T to &mut U when T: DerefMut<Target=U>
- From &mut T to &U when T: Deref<Target=U>
所以我觉得这本书适合学习语言的概貌,对于一时理解不了的内容,需要自己花时间另找资料,或者自己通过练习来掌握。在学习课程的过程中,如果你想巩固所学的内容,可以翻阅这本书。
另外一本官方的 Rust 死灵书(The Rustonomicon),讲述 Rust 的高级特性,主要是如何撰写和使用 unsafe Rust,内容不适合初学者。建议在学习完课程之后,或者起码学完进阶内容之后,再阅读这本书。
Rust 代码的文档系统 docs.rs 是所有编程语言中使用起来最舒服,也是体验最一致的。无论是标准库的文档,还是第三方库的文档,都是用相同的工具生成的,非常便于阅读,你自己撰写的 crate,发布后也会放在 docs.rs 里。在平时学习和撰写代码的时候,用好这些文档会对你的学习效率和开发效率大有裨益。
标准库的文档 建议你在学到某个数据类型或者概念时再去阅读,在每一讲中涉及的内容,我都会放上标准库的链接,你可以延伸阅读。
为了帮助 Rust 初学者进一步巩固 Rust 学习的效果,Rust 官方还出品了 rustlings,它涵盖了大量的小练习,可以用来夯实对知识和概念的理解。有兴趣、有余力的同学可以尝试一下。
其他学习资料
说完了官方的资料,我们看看其它关于 Rust 的内容包括书籍、博客、视频。
首先讲几本书。第一本是汉东的《 Rust 编程之道》,详尽深入,是不可多得的 Rust 中文书。汉东在极客时间有一门 Rust 视频课程,如果你感兴趣,也可以订阅。英文书有 Programming Rust,目前出了第二版,我读过第一版,写得不错,面面俱到,适合从头读到尾,也适合查漏补缺。
除了书籍相关的资料,我还订阅了一些不错的博客和公众号,也分享给你。博客我主要会看 This week in Rust,你可以订阅其邮件列表,每期扫一下感兴趣的主题再深度阅读。
公众号主要用于获取信息,可以了解社区的一些动态,有Rust 语言中文社区、Rust 碎碎念,这两个公众号有时会推 This week in Rust 里的内容,甚至会有翻译。
还有一个非常棒的内容来源是 Rust 语言开源杂志,每月一期,囊括了大量优秀的 Rust 文章。不过这个杂志的主要受众,我感觉还是对 Rust 有一定掌握的开发者,建议你在学完了进阶篇后再读里面的文章效果更好。
在 Rust 社区里,也有很多不错的视频资源。社区里不少人推荐 Beginner’s Series to: Rust,这是微软推出的一系列 Rust 培训,比较新。我简单看了一下还不错,讲得有些慢,可以 1.5 倍速播放节省时间。我自己主要订阅了 Jon Gjengset 的 YouTube 频道,他的视频面向中高级 Rust 用户,适合学习完本课程后再去观看。
国内视频的话,在 bilibili 上,也有大量的 Rust 培训资料,但需要自己先甄别。我做了几期“程序君的 Rust 培训”感兴趣也可以看看,可以作为课程的补充资料。
说这么多,希望你能够坚定对学习 Rust 的信心。相信我, 不管你未来是否使用 Rust,单单是学习 Rust 的过程,就能让你成为一个更好的程序员。
欢迎你在留言区分享你的想法,我们一起讨论。
参考资料
1.配合课程使用:官方的 Rust book、微软推出的一系列 Rust 培训 Beginner’s Series to: Rust、英文书 Programming Rust 查漏补缺
2.学完课程后进阶学习:官方的 Rust 死灵书(The Rustonomicon)、每月一期的 Rust 语言开源杂志、 Jon Gjengset 的 YouTube 频道、张汉东的《 Rust 编程之道》、我的B站上的“程序君的 Rust 培训”系列。
3.学有余力的练习:Rust 代码的文档系统 docs.rs 、小练习 rustlings
4.社区动态:博客 This week in Rust 、公众号 Rust 语言中文社区、 公众号 Rust 碎碎念
5.如果你对这个专栏怎么学还有疑惑,欢迎围观几个同学的学习方法和经历,在课程目录最后的“学习锦囊”系列,听听课代表们怎么说,相互借鉴,共同进步。直达链接也贴在这里: 学习锦囊(一)、 学习锦囊(二)、 学习锦囊(三)
初窥门径:从你的第一个Rust程序开始!
你好,我是陈天。储备好前置知识之后,今天我们就正式开始 Rust 语言本身的学习。
学语言最好的捷径就是把自己置身于语言的环境中,而且我们程序员讲究 “get hands dirty”,直接从代码开始学能带来最直观的体验。所以从这一讲开始,你就要在电脑上设置好 Rust 环境了。
今天会讲到很多 Rust 的基础知识,我都精心构造了代码案例来帮你理解, 非常推荐你自己一行行敲入这些代码,边写边思考为什么这么写,然后在运行时体会执行和输出的过程。如果遇到了问题,你也可以点击每个例子附带的代码链接,在 Rust playground 中运行。
Rust 安装起来非常方便,你可以用 rustup.rs 中给出的方法,根据你的操作系统进行安装。比如在 UNIX 系统下,可以直接运行:
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh
这会在你的系统上安装 Rust 工具链,之后,你就可以在本地用 cargo new 新建 Rust 项目、尝试 Rust 功能。动起手来,试试用Rust写你的第一个 hello world 程序 吧!
fn main() { println!("Hello world!"); }
你可以使用任何编辑器来撰写 Rust 代码,我个人偏爱 VS Code,因为它免费,功能强大且速度很快。在 VS Code 下我为 Rust 安装了一些插件,下面是我的安装顺序,你可以参考:
- rust-analyzer:它会实时编译和分析你的 Rust 代码,提示代码中的错误,并对类型进行标注。你也可以使用官方的 Rust 插件取代。
- rust syntax:为代码提供语法高亮。
- crates:帮助你分析当前项目的依赖是否是最新的版本。
- better toml:Rust 使用 toml 做项目的配置管理。better toml 可以帮你语法高亮,并展示 toml 文件中的错误。
- rust test lens:可以帮你快速运行某个 Rust 测试。
- Tabnine:基于 AI 的自动补全,可以帮助你更快地撰写代码。
第一个实用的 Rust 程序
现在你已经有工具和环境了,尽管我们目前一行 Rust 语法都还没有介绍,但这不妨碍我们写一个稍稍有用的 Rust 程序,跑一遍之后,你对 Rust 的基本功能、关键语法和生态系统就基本心中有数了,我们再来详细分析。
一定要动起手来,跟着课程节奏一行一行敲,如果碰到不太理解的知识点,不要担心,今天只需要你先把代码运行起来,我们后面会循序渐进学习到各个难点的。
另外, 我也建议你用自己常用的编程语言做同样的需求,和 Rust 对比一下,看简洁程度、代码可读性孰优孰劣。
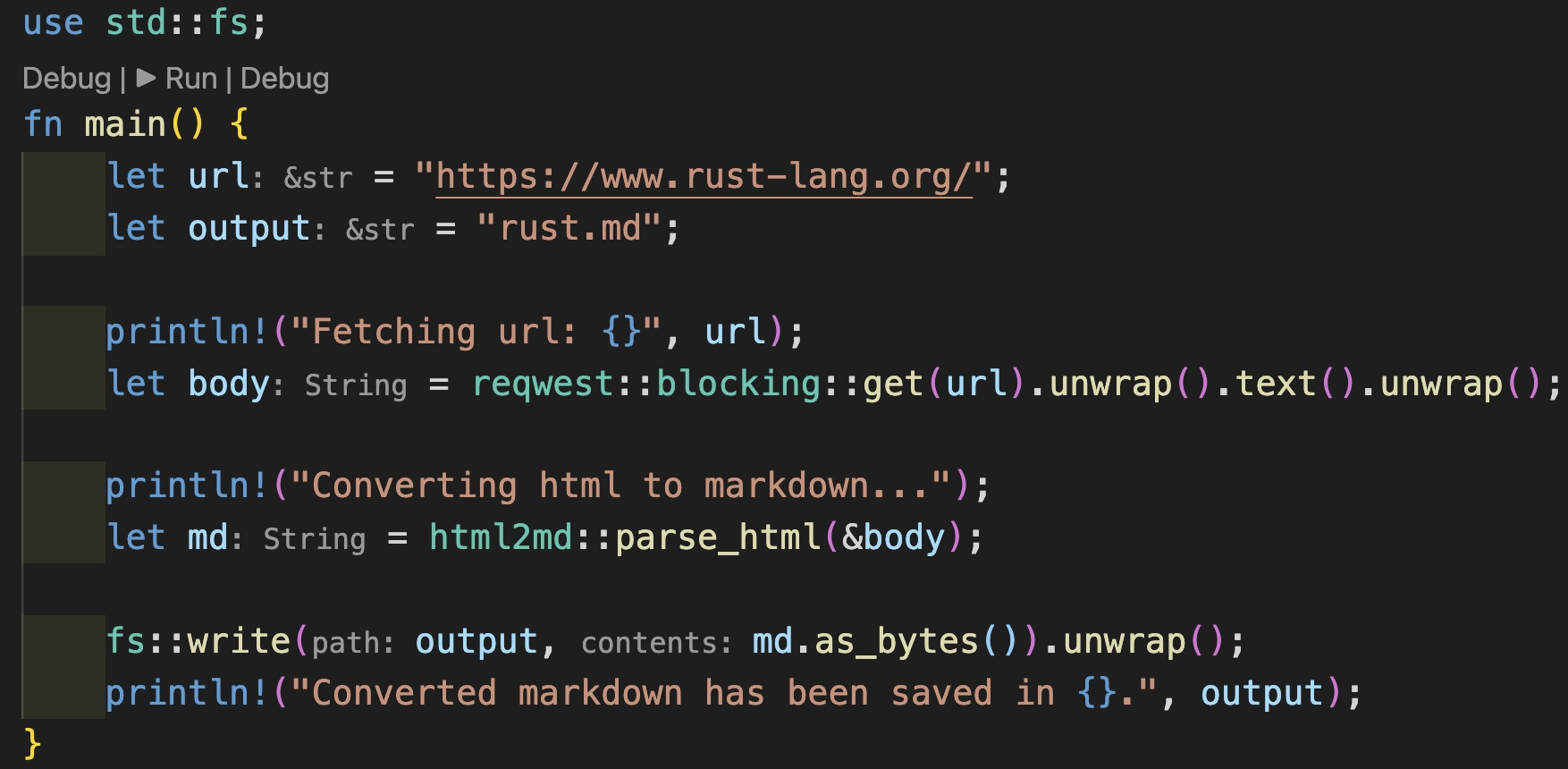
这个程序的需求很简单,通过 HTTP 请求 Rust 官网首页,然后把获得的 HTML 转换成 Markdown 保存起来。我相信用 JavaScript 或者 Python,只要选好相关的依赖,这也就是十多行代码的样子。我们看看用 Rust 怎么处理。
首先,我们用 cargo new scrape_url 生成一个新项目。默认情况下,这条命令会生成一个可执行项目 scrape_url,入口在 src/main.rs。我们在 Cargo.toml 文件里,加入如下的依赖:
#![allow(unused)] fn main() { [dependencies] reqwest = { version = "0.11", features = ["blocking"] } html2md = "0.2" }
Cargo.toml 是 Rust 项目的配置管理文件,它符合 toml 的语法。我们为这个项目添加了两个依赖:reqwest 和 html2md。 reqwest 是一个 HTTP 客户端,它的使用方式和 Python 下的 request 类似;html2md 顾名思义,把 HTML 文本转换成Markdown。
接下来,在 src/main.rs 里,我们为 main() 函数加入以下代码:
use std::fs; fn main() { let url = "https://www.rust-lang.org/"; let output = "rust.md"; println!("Fetching url: {}", url); let body = reqwest::blocking::get(url).unwrap().text().unwrap(); println!("Converting html to markdown..."); let md = html2md::parse_html(&body); fs::write(output, md.as_bytes()).unwrap(); println!("Converted markdown has been saved in {}.", output); }
保存后,在命令行下,进入这个项目的目录,运行 cargo run,在一段略微漫长的编译后,程序开始运行,在命令行下,你会看到如下的输出:
Fetching url: https://www.rust-lang.org/
Converting html to markdown...
Converted markdown has been saved in rust.md.
并且,在当前目录下,一个 rust.md 文件被创建出来了。打开一看,其内容就是 Rust 官网主页的内容。
Bingo!我们第一个 Rust 程序运行成功!
从这段并不长的代码中,我们可以感受到 Rust 的一些基本特点:
首先, Rust 使用名为 cargo 的工具来管理项目,它类似 Node.js 的 npm、Golang 的 go,用来做依赖管理以及开发过程中的任务管理,比如编译、运行、测试、代码格式化等等。
其次, Rust 的整体语法偏 C/C++ 风格。函数体用花括号 {} 包裹,表达式之间用分号 ; 分隔,访问结构体的成员函数或者变量使用点 . 运算符,而访问命名空间(namespace)或者对象的静态函数使用双冒号 :: 运算符。如果要简化对命名空间内部的函数或者数据类型的引用,可以使用 use 关键字,比如 use std::fs。此外,可执行体的入口函数是 main()。
另外,你也很容易看到, Rust 虽然是一门强类型语言,但编译器支持类型推导,这使得写代码时的直观感受和写脚本语言差不多。
很多不习惯类型推导的开发者,觉得这会降低代码的可读性,因为可能需要根据上下文才知道当前变量是什么类型。不过没关系,如果你在编辑器中使用了 rust-analyzer 插件,变量的类型会自动提示出来:
最后, Rust 支持宏编程,很多基础的功能比如 println!() 都被封装成一个宏,便于开发者写出简洁的代码。
这里例子没有展现出来,但 Rust 还具备的其它特点有:
- Rust 的变量默认是不可变的,如果要修改变量的值,需要显式地使用 mut 关键字。
- 除了 let / static / const / fn 等少数语句外,Rust 绝大多数代码都是表达式(expression)。所以 if / while / for / loop 都会返回一个值,函数最后一个表达式就是函数的返回值,这和函数式编程语言一致。
- Rust 支持面向接口编程和泛型编程。
- Rust 有非常丰富的数据类型和强大的标准库。
- Rust 有非常丰富的控制流程,包括模式匹配(pattern match)。
第一个实用的 Rust 程序就运行成功了,不知道你现在是不是有点迟疑,这些我现在都不太懂怎么办,是不是得先去把这些都掌握了才能继续学?不要迟疑,跟着继续学,后面都会讲到。
接下来,为了快速入门 Rust,我们一起梳理 Rust 开发的基本内容。
这部分涉及的知识在各个编程语言中都大同小异,略微枯燥,但是这一讲是我们后续学习的基础, 建议你每段示例代码都写一下,运行一下,并且和自己熟悉的语言对比来加深印象。

基本语法和基础数据类型
首先我们看在 Rust 下,我们如何定义变量、函数和数据结构。
变量和函数
前面说到,Rust 支持类型推导,在编译器能够推导类型的情况下,变量类型一般可以省略,但常量(const)和静态变量(static)必须声明类型。
定义变量的时候,根据需要,你可以添加 mut 关键字让变量具备可变性。 默认变量不可变 是一个很重要的特性,它符合最小权限原则(Principle of Least Privilege),有助于我们写出健壮且正确的代码。当你使用 mut 却没有修改变量,Rust 编译期会友好地报警,提示你移除不必要的 mut。
在Rust 下,函数是一等公民,可以作为参数或者返回值。我们来看一个函数作为参数的例子( 代码):
fn apply(value: i32, f: fn(i32) -> i32) -> i32 { f(value) } fn square(value: i32) -> i32 { value * value } fn cube(value: i32) -> i32 { value * value * value } fn main() { println!("apply square: {}", apply(2, square)); println!("apply cube: {}", apply(2, cube)); }
这里 fn(i32) -> i32 是 apply 函数第二个参数的类型,它表明接受一个函数作为参数,这个传入的函数必须是:参数只有一个,且类型为 i32,返回值类型也是 i32。
Rust 函数参数的类型和返回值的类型都必须显式定义,如果没有返回值可以省略,返回 unit。函数内部如果提前返回,需要用 return 关键字,否则最后一个表达式就是其返回值。如果最后一个表达式后添加了 ; 分号,隐含其返回值为 unit。你可以看这个例子( 代码):
fn pi() -> f64 { 3.1415926 } fn not_pi() { 3.1415926; } fn main() { let is_pi = pi(); let is_unit1 = not_pi(); let is_unit2 = { pi(); }; println!("is_pi: {:?}, is_unit1: {:?}, is_unit2: {:?}", is_pi, is_unit1, is_unit2); }
数据结构
了解了函数如何定义后,我们来看看 Rust 下如何定义数据结构。
数据结构是程序的核心组成部分,在对复杂的问题进行建模时,我们就要自定义数据结构。Rust 非常强大,可以用 struct 定义结构体,用 enum 定义标签联合体(tagged union),还可以像 Python 一样随手定义元组(tuple)类型。
比如我们可以这样定义一个聊天服务的数据结构( 代码):
#[derive(Debug)] enum Gender { Unspecified = 0, Female = 1, Male = 2, } #[derive(Debug, Copy, Clone)] struct UserId(u64); #[derive(Debug, Copy, Clone)] struct TopicId(u64); #[derive(Debug)] struct User { id: UserId, name: String, gender: Gender, } #[derive(Debug)] struct Topic { id: TopicId, name: String, owner: UserId, } // 定义聊天室中可能发生的事件 #[derive(Debug)] enum Event { Join((UserId, TopicId)), Leave((UserId, TopicId)), Message((UserId, TopicId, String)), } fn main() { let alice = User { id: UserId(1), name: "Alice".into(), gender: Gender::Female }; let bob = User { id: UserId(2), name: "Bob".into(), gender: Gender::Male }; let topic = Topic { id: TopicId(1), name: "rust".into(), owner: UserId(1) }; let event1 = Event::Join((alice.id, topic.id)); let event2 = Event::Join((bob.id, topic.id)); let event3 = Event::Message((alice.id, topic.id, "Hello world!".into())); println!("event1: {:?}, event2: {:?}, event3: {:?}", event1, event2, event3); }
简单解释一下:
- Gender:一个枚举类型,在 Rust 下,使用 enum 可以定义类似 C 的枚举类型
- UserId/TopicId :struct 的特殊形式,称为元组结构体。它的域都是匿名的,可以用索引访问,适用于简单的结构体。
- User/Topic:标准的结构体,可以把任何类型组合在结构体里使用。
- Event:标准的标签联合体,它定义了三种事件:Join、Leave、Message。每种事件都有自己的数据结构。
在定义数据结构的时候,我们一般会加入修饰,为数据结构引入一些额外的行为。在 Rust 里,数据的行为通过 trait 来定义,后续我们会详细介绍 trait,你现在可以暂时认为 trait 定义了数据结构可以实现的接口,类似 Java 中的 interface。
一般我们用 impl 关键字为数据结构实现 trait,但 Rust 贴心地提供了派生宏(derive macro),可以大大简化一些标准接口的定义,比如 #[derive(Debug)] 为数据结构实现了 Debug trait,提供了 debug 能力,这样可以通过 {:?},用 println! 打印出来。
在定义 UserId / TopicId 时我们还用到了 Copy / Clone 两个派生宏,Clone 让数据结构可以被复制,而 Copy 则让数据结构可以在参数传递的时候自动按字节拷贝。在下一讲所有权中,我会具体讲什么时候需要 Copy。
简单总结一下 Rust 定义变量、函数和数据结构:

控制流程
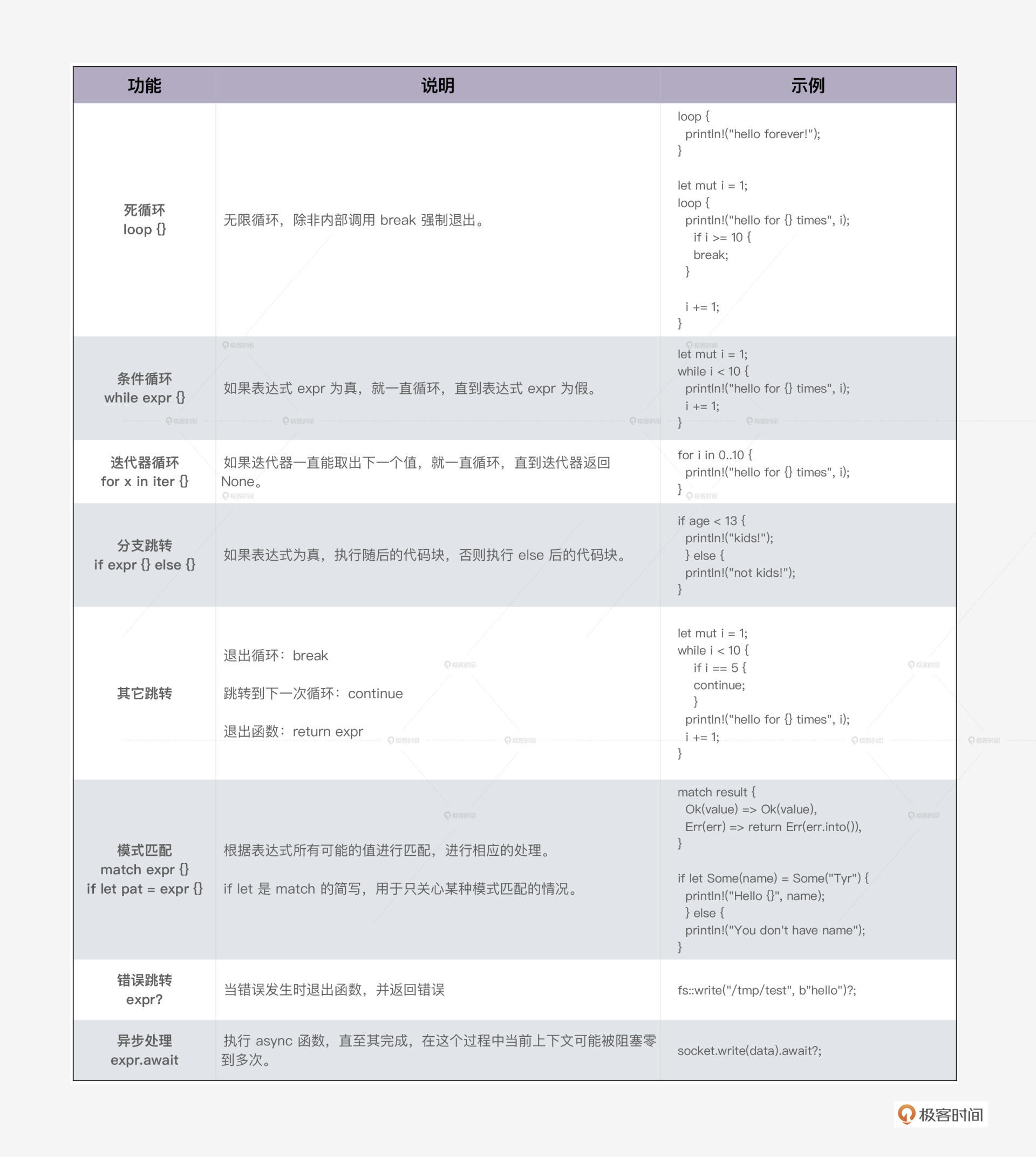
程序的基本控制流程分为以下几种,我们应该都很熟悉了,重点看如何在 Rust 中运行。
顺序执行 就是一行行代码往下执行。在执行的过程中,遇到函数,会发生函数调用 。函数调用 是代码在执行过程中,调用另一个函数,跳入其上下文执行,直到返回。
Rust 的 循环 和大部分语言都一致,支持死循环 loop、条件循环 while,以及对迭代器的循环 for。循环可以通过 break 提前终止,或者 continue 来跳到下一轮循环。
满足某个条件时会 跳转, Rust 支持分支跳转、模式匹配、错误跳转和异步跳转。
- 分支跳转就是我们熟悉的 if/else;
- Rust 的模式匹配可以通过匹配表达式或者值的某部分的内容,来进行分支跳转;
- 在错误跳转中,当调用的函数返回错误时,Rust 会提前终止当前函数的执行,向上一层返回错误。
- 在 Rust 的异步跳转中 ,当 async 函数执行 await 时,程序当前上下文可能被阻塞,执行流程会跳转到另一个异步任务执行,直至 await 不再阻塞。
我们通过斐波那契数列,使用 if 和 loop / while / for 这几种循环,来实现程序的基本控制流程( 代码):
fn fib_loop(n: u8) { let mut a = 1; let mut b = 1; let mut i = 2u8; loop { let c = a + b; a = b; b = c; i += 1; println!("next val is {}", b); if i >= n { break; } } } fn fib_while(n: u8) { let (mut a, mut b, mut i) = (1, 1, 2); while i < n { let c = a + b; a = b; b = c; i += 1; println!("next val is {}", b); } } fn fib_for(n: u8) { let (mut a, mut b) = (1, 1); for _i in 2..n { let c = a + b; a = b; b = c; println!("next val is {}", b); } } fn main() { let n = 10; fib_loop(n); fib_while(n); fib_for(n); }
这里需要指出的是,Rust 的 for 循环可以用于任何实现了 IntoIterator trait 的数据结构。
在执行过程中, IntoIterator 会生成一个迭代器,for 循环不断从迭代器中取值,直到迭代器返回 None 为止。因而,for 循环实际上只是一个语法糖,编译器会将其展开使用 loop 循环对迭代器进行循环访问,直至返回 None。
在 fib_for 函数中,我们还看到 2…n 这样的语法,想必 Python 开发者一眼就能明白这是 Range 操作,2…n 包含 2<= x < n 的所有值。和 Python 一样,在Rust中,你也可以省略 Range 的下标或者上标,比如:
#![allow(unused)] fn main() { let arr = [1, 2, 3]; assert_eq!(arr[..], [1, 2, 3]); assert_eq!(arr[0..=1], [1, 2]); }
和 Python 不同的是,Range 不支持负数,所以你不能使用 arr[1..-1] 这样的代码。这是因为,Range 的下标上标都是 usize 类型,不能为负数。
下表是 Rust 主要控制流程的一个总结:
模式匹配
Rust 的模式匹配吸取了函数式编程语言的优点,强大优雅且效率很高。它可以用于 struct / enum 中匹配部分或者全部内容,比如上文中我们设计的数据结构 Event,可以这样匹配( 代码):
#![allow(unused)] fn main() { fn process_event(event: &Event) { match event { Event::Join((uid, _tid)) => println!("user {:?} joined", uid), Event::Leave((uid, tid)) => println!("user {:?} left {:?}", uid, tid), Event::Message((_, _, msg)) => println!("broadcast: {}", msg), } } }
从代码中我们可以看到,可以直接对 enum 内层的数据进行匹配并赋值,这比很多只支持简单模式匹配的语言,例如 JavaScript 、Python ,可以省出好几行代码。
除了使用 match 关键字做模式匹配外,我们还可以用 if let / while let 做简单的匹配,如果上面的代码我们只关心 Event::Message,可以这么写( 代码):
#![allow(unused)] fn main() { fn process_message(event: &Event) { if let Event::Message((_, _, msg)) = event { println!("broadcast: {}", msg); } } }
Rust 的模式匹配是一个很重要的语言特性,被广泛应用在状态机处理、消息处理和错误处理中,如果你之前使用的语言是 C / Java / Python / JavaScript ,没有强大的模式匹配支持,要好好练习这一块。
错误处理
Rust 没有沿用 C++/Java 等诸多前辈使用的异常处理方式,而是借鉴 Haskell, 把错误封装在 Result<T, E> 类型中,同时提供了 ? 操作符来传播错误,方便开发。 Result<T, E> 类型是一个泛型数据结构,T 代表成功执行返回的结果类型,E 代表错误类型。
今天开始的 scrape_url 项目,其实里面很多调用已经使用了 Result<T, E> 类型,这里我再展示一下代码,不过我们使用了 unwrap() 方法,只关心成功返回的结果,如果出错,整个程序会终止。
use std::fs; fn main() { let url = "https://www.rust-lang.org/"; let output = "rust.md"; println!("Fetching url: {}", url); let body = reqwest::blocking::get(url).unwrap().text().unwrap(); println!("Converting html to markdown..."); let md = html2md::parse_html(&body); fs::write(output, md.as_bytes()).unwrap(); println!("Converted markdown has been saved in {}.", output); }
如果想让错误传播,可以把所有的 unwrap() 换成 ? 操作符,并让 main() 函数返回一个 Result<T, E>,如下所示:
use std::fs; // main 函数现在返回一个 Result fn main() -> Result<(), Box<dyn std::error::Error>> { let url = "https://www.rust-lang.org/"; let output = "rust.md"; println!("Fetching url: {}", url); let body = reqwest::blocking::get(url)?.text()?; println!("Converting html to markdown..."); let md = html2md::parse_html(&body); fs::write(output, md.as_bytes())?; println!("Converted markdown has been saved in {}.", output); Ok(()) }
关于错误处理我们先讲这么多,之后我们会单开一讲,对比其他语言,来详细学习 Rust 的错误处理。
Rust 项目的组织
当 Rust 代码规模越来越大时,我们就无法用单一文件承载代码了,需要多个文件甚至多个目录协同工作,这时我们 可以用 mod 来组织代码。
具体做法是:在项目的入口文件 lib.rs / main.rs 里,用 mod 来声明要加载的其它代码文件。如果模块内容比较多,可以放在一个目录下,在该目录下放一个 mod.rs 引入该模块的其它文件。这个文件,和 Python 的 __init__.py 有异曲同工之妙。这样处理之后,就可以用 mod + 目录名引入这个模块了,如下图所示:
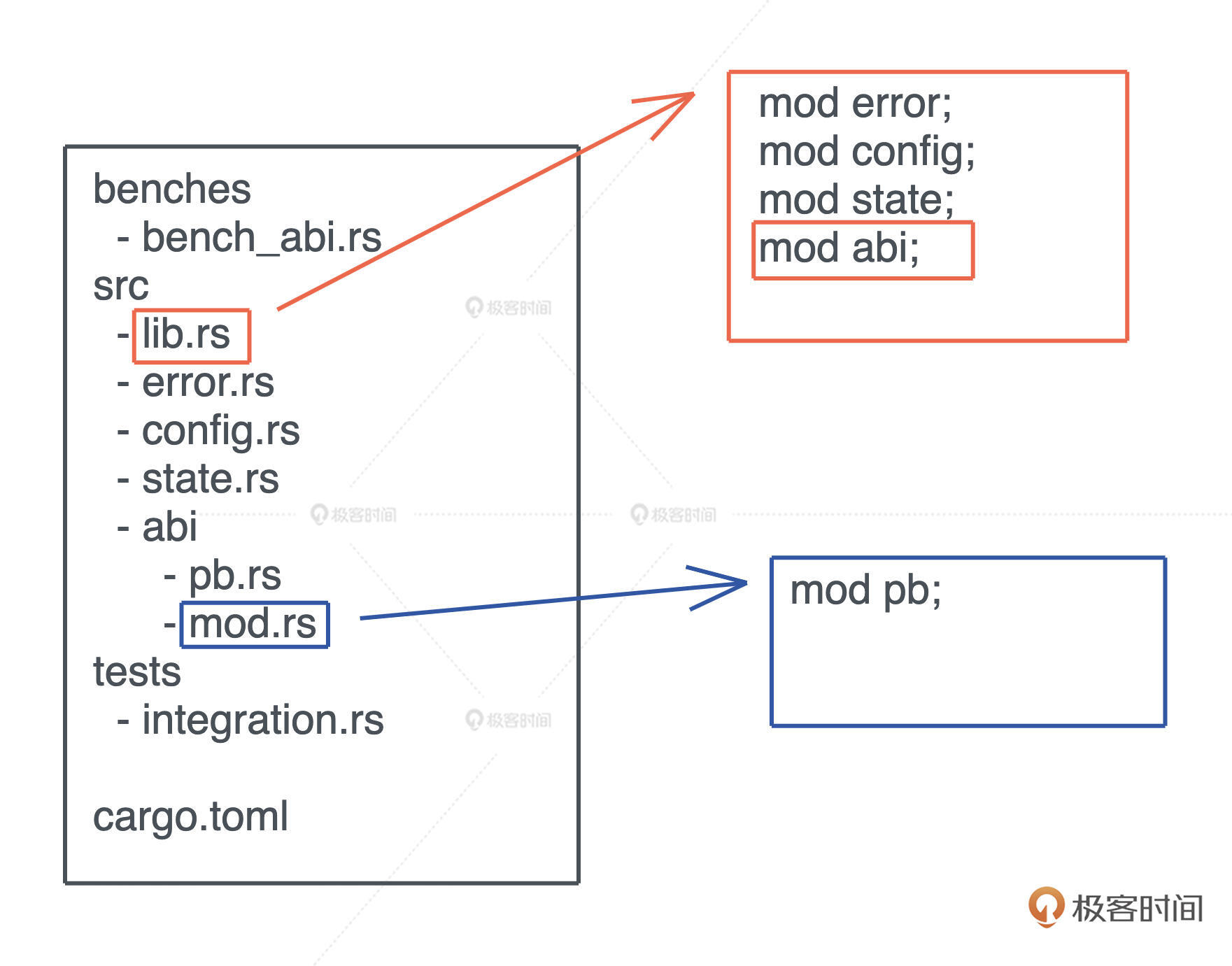
在 Rust 里, 一个项目也被称为一个 crate。crate 可以是可执行项目,也可以是一个库,我们可以用 cargo new <name> -- lib 来创建一个库。当 crate 里的代码改变时,这个 crate 需要被重新编译。
在一个 crate 下,除了项目的源代码,单元测试和集成测试的代码也会放在 crate 里。
Rust 的单元测试一般放在和被测代码相同的文件中,使用条件编译 #[cfg(test)] 来确保测试代码只在测试环境下编译。以下是一个 单元测试 的例子:
#![allow(unused)] fn main() { #[cfg(test)] mod tests { #[test] fn it_works() { assert_eq!(2 + 2, 4); } } }
集成测试一般放在 tests 目录下,和 src 平行。和单元测试不同,集成测试只能测试 crate 下的公开接口,编译时编译成单独的可执行文件。
在 crate 下,如果要运行测试用例,可以使用 cargo test。
当代码规模继续增长,把所有代码放在一个 crate 里就不是一个好主意了,因为任何代码的修改都会导致这个 crate 重新编译,这样效率不高。 我们可以使用 workspace。
一个 workspace 可以包含一到多个 crates,当代码发生改变时,只有涉及的 crates 才需要重新编译。当我们要构建一个 workspace 时,需要先在某个目录下生成一个如图所示的 Cargo.toml,包含 workspace 里所有的 crates,然后可以 cargo new 生成对应的 crates:
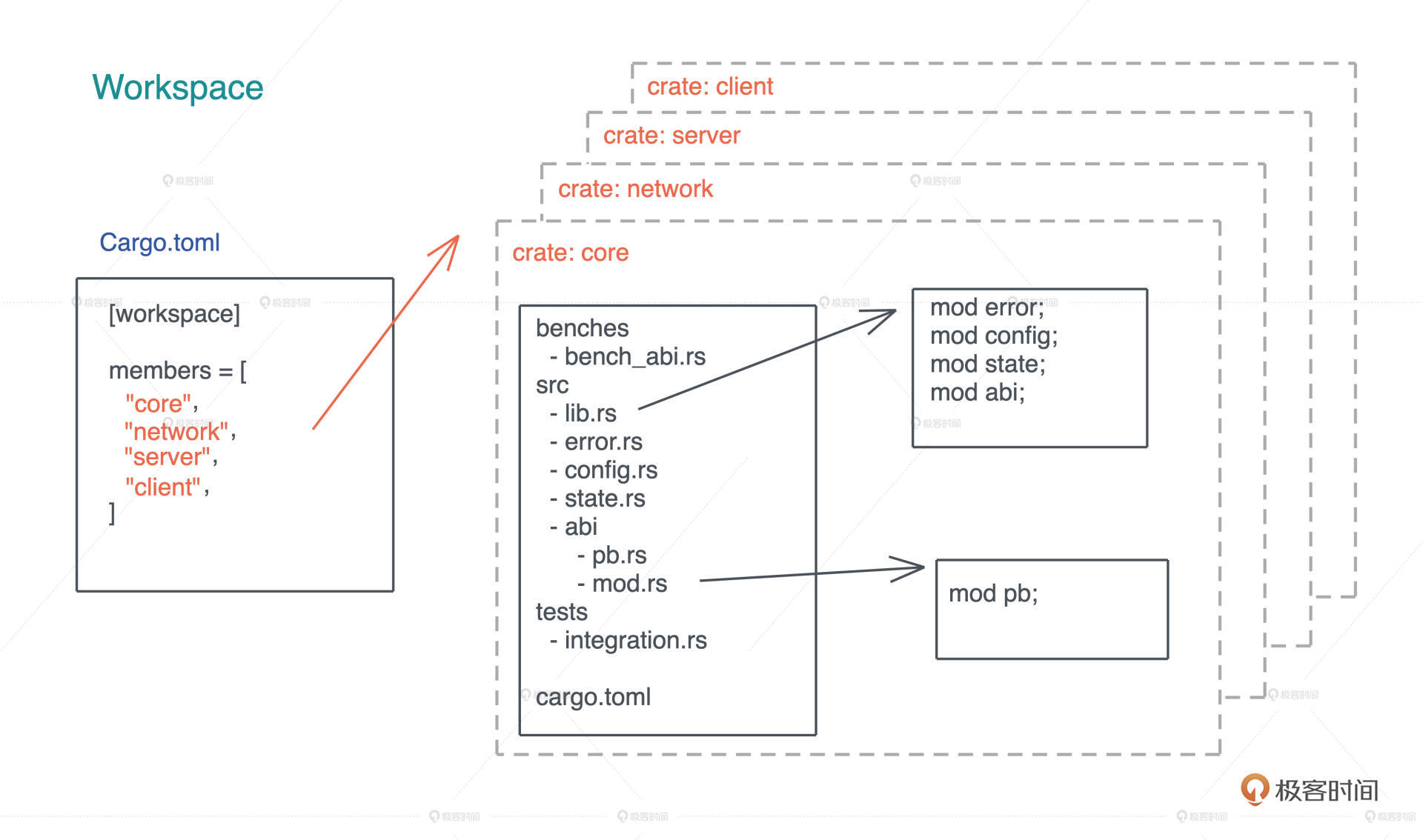
crate 和 workspace 还有一些更高级的用法,在后面遇到的时候会具体讲解。如果你有兴趣,也可以先阅读 Rust book 第 14 章 了解更多的知识。
小结
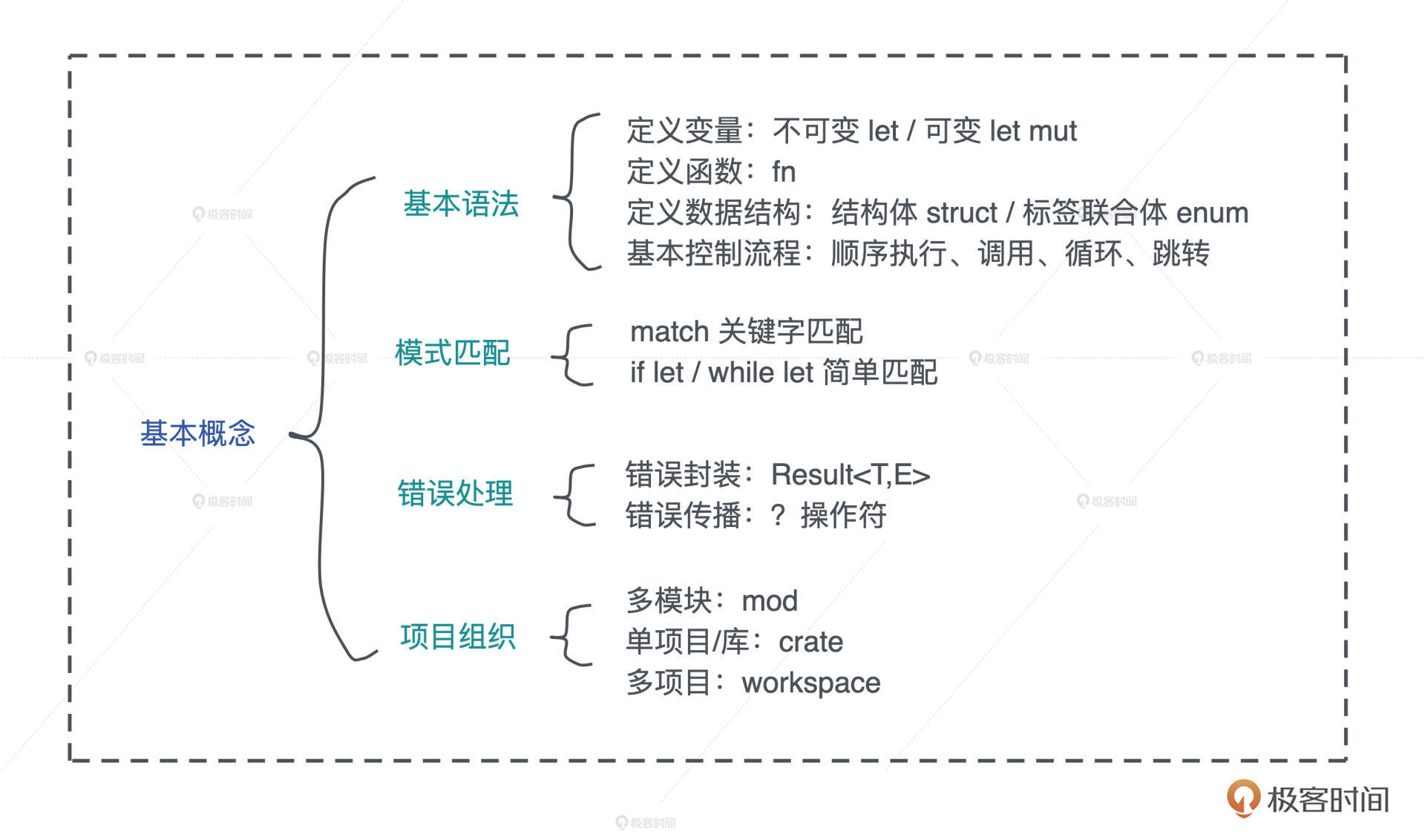
我们简单梳理了 Rust 的基本概念。通过 let/let mut 定义变量、用 fn 定义函数、用 struct / enum 定义复杂的数据结构,也学习了 Rust 的基本的控制流程,了解了模式匹配如何运作,知道如何处理错误。
最后考虑到代码规模问题,介绍了如何使用 mod、crate 和 workspace 来组织 Rust 代码。我总结到图中你可以看看。
今天是让你对 Rust 形成非常基本的认识,能够开始尝试写一些简单的 Rust 项目。
你也许会惊奇,用 Rust 写类似于 scrape_url 的功能,竟然和 Python 这样的脚本语言的体验几乎一致,太简单了!
下一讲我们会继续写一写代码,从实用的小工具的编写中真实感受 Rust 的魅力。
思考题
1.在上面的斐波那契数列的代码中,你也许注意到计算数列中下一个数的代码在三个函数中不断重复。这不符合 DRY(Don’t Repeat Yourself)原则。你可以写一个函数把它抽取出来么?
2.在 scrape_url 的例子里,我们在代码中写死了要获取的 URL 和要输出的文件名,这太不灵活了。你能改进这个代码,从命令行参数中获取用户提供的信息来绑定 URL 和文件名么?类似这样:
cargo run -- https://www.rust-lang.org rust.md
提示一下,打印一下 std::env::args() 看看会发生什么?
for arg in std::env::args() {
println!("{}", arg);
}
欢迎在留言区分享你的思考。恭喜你完成了 Rust 学习的第三次打卡,我们下一讲见!
参考资料
- TOML
- static 关键字
- lazy_static
- unit 类型
- How to write tests
- More about cargo and crates.io
- Rust 支持声明宏(declarative macro)和过程宏(procedure macro),其中过程宏又包含三种方式:函数宏(function macro),派生宏(derive macro)和属性宏(attribute macro)。println! 是函数宏,是因为 Rust 是强类型语言,函数的类型需要在编译期敲定,而 println! 接受任意个数的参数,所以只能用宏来表达。
get hands dirty:来写个实用的CLI小工具
你好,我是陈天。
在上一讲里,我们已经接触了 Rust 的基本语法。你是不是已经按捺不住自己的洪荒之力,想马上用 Rust 写点什么练练手,但是又发现自己好像有点“拔剑四顾心茫然”呢?
那这周我们就来玩个新花样, 做一周“learning by example”的挑战,来尝试用 Rust 写三个非常有实际价值的小应用,感受下 Rust 的魅力在哪里,解决真实问题的能力到底如何。
你是不是有点担心,我才刚学了最基本语法,还啥都不知道呢,这就能开始写小应用了?那我碰到不理解的知识怎么办?
不要担心,因为你肯定会碰到不太懂的语法,但是, 先不要强求自己理解,当成文言文抄写就可以了,哪怕这会不明白,只要你跟着课程节奏,通过撰写、编译和运行,你也能直观感受到 Rust 的魅力,就像小时候背唐诗一样。
好,我们开始今天的挑战。
HTTPie
为了覆盖绝大多数同学的需求,这次挑选的例子是工作中普遍会遇到的:写一个 CLI 工具,辅助我们处理各种任务。
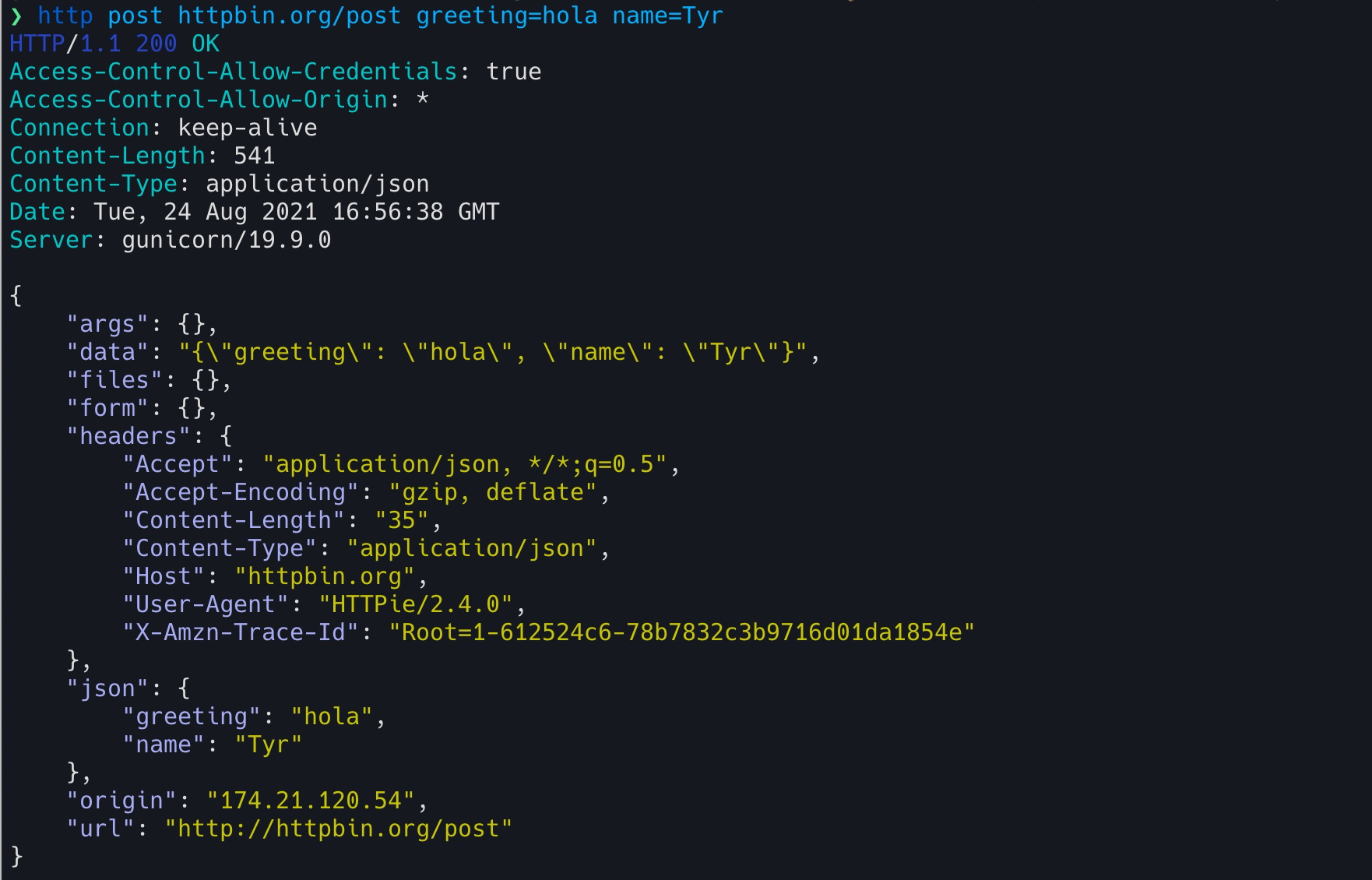
我们就以实现 HTTPie 为例,看看用 Rust 怎么做 CLI。HTTPie 是用 Python 开发的,一个类似 cURL 但对用户更加友善的命令行工具,它可以帮助我们更好地诊断 HTTP 服务。
下图是用 HTTPie 发送了一个 post 请求的界面,你可以看到,相比 cURL,它在可用性上做了很多工作,包括对不同信息的语法高亮显示:
你可以先想一想,如果用你最熟悉的语言实现 HTTPie ,要怎么设计、需要用到些什么库、大概用多少行代码?如果用 Rust 的话,又大概会要多少行代码?
带着你自己的这些想法,开始动手用 Rust 构建这个工具吧!我们的目标是, 用大约 200 行代码 实现这个需求。
功能分析
要做一个 HTTPie 这样的工具,我们先梳理一下要实现哪些主要功能:
- 首先是做命令行解析,处理子命令和各种参数,验证用户的输入,并且将这些输入转换成我们内部能理解的参数;
- 之后根据解析好的参数,发送一个 HTTP 请求,获得响应;
- 最后用对用户友好的方式输出响应。
这个流程你可以再看下图:
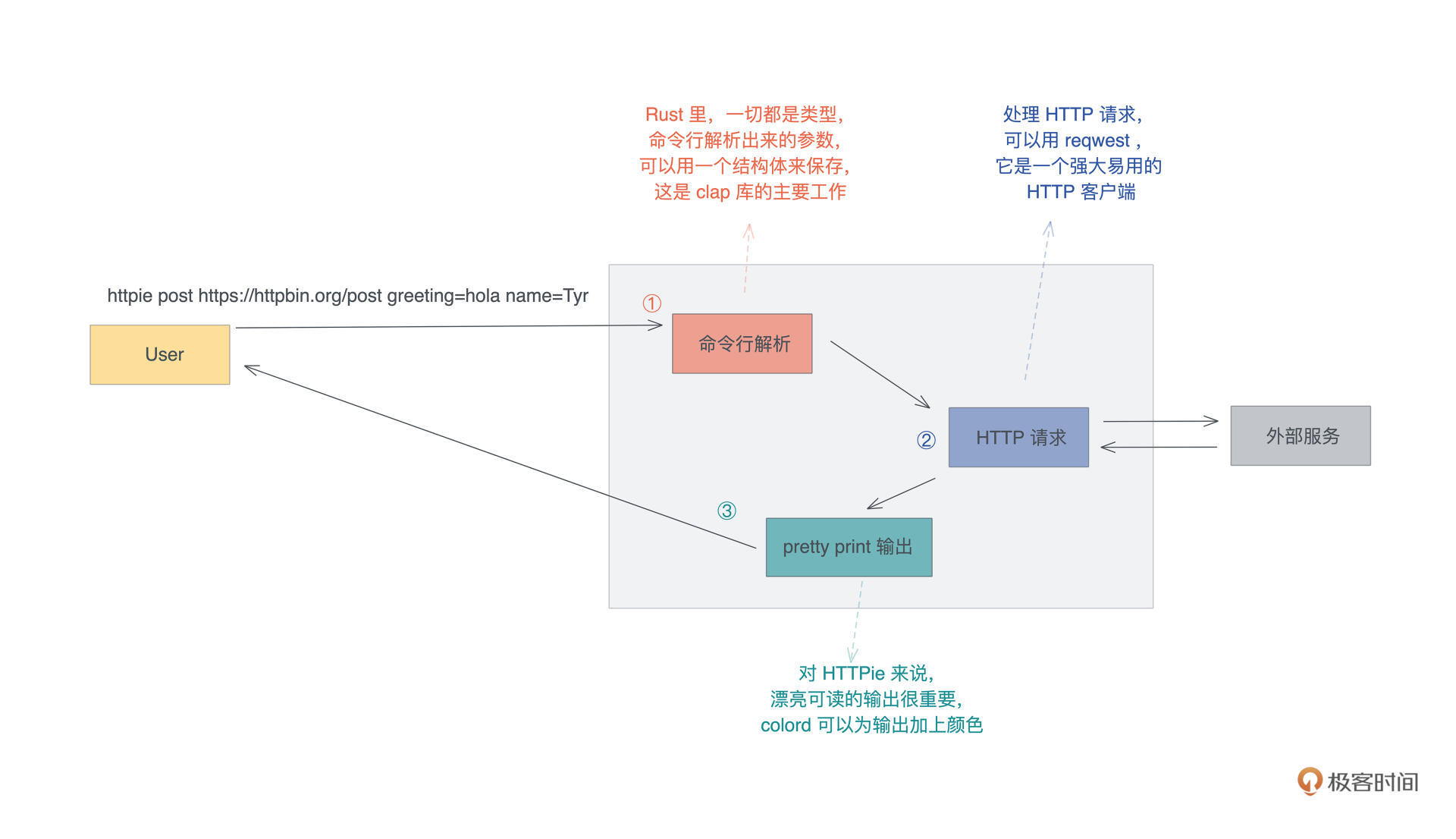
我们来看要实现这些功能对应需要用到的库:
- 对于命令行解析,Rust 有很多库可以满足这个需求,我们今天使用官方比较推荐的 clap。
- 对于 HTTP 客户端,在上一讲我们已经接触过 reqwest,我们就继续使用它,只不过我们这次尝个鲜,使用它的异步接口。
- 对于格式化输出,为了让输出像 Python 版本的 HTTPie 那样显得生动可读,我们可以引入一个命令终端多彩显示的库,这里我们选择比较简单的 colored。
- 除此之外,我们还需要一些额外的库:用 anyhow 做错误处理、用 jsonxf 格式化 JSON 响应、用 mime 处理 mime 类型,以及引入 tokio 做异步处理。
CLI 处理
好,有了基本的思路,我们来创建一个项目,名字就叫 httpie:
cargo new httpie
cd httpie
然后,用 VSCode 打开项目所在的目录,编辑 Cargo.toml 文件,添加所需要的依赖( 注意:以下代码用到了 beta 版本的 crate,可能未来会有破坏性更新,如果在本地无法编译,请参考 GitHub repo 中的代码):
#![allow(unused)] fn main() { [package] name = "httpie" version = "0.1.0" edition = "2018" [dependencies] anyhow = "1" # 错误处理 clap = "3.0.0-beta.4" # 命令行解析 colored = "2" # 命令终端多彩显示 jsonxf = "1.1" # JSON pretty print 格式化 mime = "0.3" # 处理 mime 类型 reqwest = { version = "0.11", features = ["json"] } # HTTP 客户端 tokio = { version = "1", features = ["full"] } # 异步处理库 }
我们先在 main.rs 添加处理 CLI 相关的代码:
use clap::{AppSettings, Clap}; // 定义 HTTPie 的 CLI 的主入口,它包含若干个子命令 // 下面 /// 的注释是文档,clap 会将其作为 CLI 的帮助 /// A naive httpie implementation with Rust, can you imagine how easy it is? #[derive(Clap, Debug)] #[clap(version = "1.0", author = "Tyr Chen <tyr@chen.com>")] #[clap(setting = AppSettings::ColoredHelp)] struct Opts { #[clap(subcommand)] subcmd: SubCommand, } // 子命令分别对应不同的 HTTP 方法,目前只支持 get / post #[derive(Clap, Debug)] enum SubCommand { Get(Get), Post(Post), // 我们暂且不支持其它 HTTP 方法 } // get 子命令 /// feed get with an url and we will retrieve the response for you #[derive(Clap, Debug)] struct Get { /// HTTP 请求的 URL url: String, } // post 子命令。需要输入一个 URL,和若干个可选的 key=value,用于提供 json body /// feed post with an url and optional key=value pairs. We will post the data /// as JSON, and retrieve the response for you #[derive(Clap, Debug)] struct Post { /// HTTP 请求的 URL url: String, /// HTTP 请求的 body body: Vec<String>, } fn main() { let opts: Opts = Opts::parse(); println!("{:?}", opts); }
代码中用到了 clap 提供的宏来让 CLI 的定义变得简单,这个宏能够生成一些额外的代码帮我们处理 CLI 的解析。通过 clap ,我们只需要 先用一个数据结构 T 描述 CLI 都会捕获什么数据,之后通过 T::parse() 就可以解析出各种命令行参数了。parse() 函数我们并没有定义,它是 #[derive(Clap)] 自动生成的。
目前我们定义了两个子命令,在 Rust 中子命令可以通过 enum 定义,每个子命令的参数又由它们各自的数据结构 Get 和 Post 来定义。
我们运行一下:
❯ cargo build --quiet && target/debug/httpie post httpbin.org/post a=1 b=2
Opts { subcmd: Post(Post { url: "httpbin.org/post", body: ["a=1", "b=2"] }) }
默认情况下,cargo build 编译出来的二进制,在项目根目录的 target/debug 下。可以看到,命令行解析成功,达到了我们想要的功能。
加入验证
然而,现在我们还没对用户输入做任何检验,如果有这样的输入,URL 就完全解析错误了:
❯ cargo build --quiet && target/debug/httpie post a=1 b=2
Opts { subcmd: Post(Post { url: "a=1", body: ["b=2"] }) }
所以,我们需要加入验证。输入有两项, 就要做两个验证,一是验证 URL,另一个是验证body。
首先来验证 URL 是合法的:
#![allow(unused)] fn main() { use anyhow::Result; use reqwest::Url; #[derive(Clap, Debug)] struct Get { /// HTTP 请求的 URL #[clap(parse(try_from_str = parse_url))] url: String, } fn parse_url(s: &str) -> Result<String> { // 这里我们仅仅检查一下 URL 是否合法 let _url: Url = s.parse()?; Ok(s.into()) } }
clap 允许你为每个解析出来的值添加自定义的解析函数,我们这里定义了个 parse_url 检查一下。
然后,我们要确保 body 里每一项都是 key=value 的格式。可以定义一个数据结构 KvPair 来存储这个信息,并且也自定义一个解析函数把解析的结果放入 KvPair:
#![allow(unused)] fn main() { use std::str::FromStr; use anyhow::{anyhow, Result}; #[derive(Clap, Debug)] struct Post { /// HTTP 请求的 URL #[clap(parse(try_from_str = parse_url))] url: String, /// HTTP 请求的 body #[clap(parse(try_from_str=parse_kv_pair))] body: Vec<KvPair>, } /// 命令行中的 key=value 可以通过 parse_kv_pair 解析成 KvPair 结构 #[derive(Debug)] struct KvPair { k: String, v: String, } /// 当我们实现 FromStr trait 后,可以用 str.parse() 方法将字符串解析成 KvPair impl FromStr for KvPair { type Err = anyhow::Error; fn from_str(s: &str) -> Result<Self, Self::Err> { // 使用 = 进行 split,这会得到一个迭代器 let mut split = s.split("="); let err = || anyhow!(format!("Failed to parse {}", s)); Ok(Self { // 从迭代器中取第一个结果作为 key,迭代器返回 Some(T)/None // 我们将其转换成 Ok(T)/Err(E),然后用 ? 处理错误 k: (split.next().ok_or_else(err)?).to_string(), // 从迭代器中取第二个结果作为 value v: (split.next().ok_or_else(err)?).to_string(), }) } } /// 因为我们为 KvPair 实现了 FromStr,这里可以直接 s.parse() 得到 KvPair fn parse_kv_pair(s: &str) -> Result<KvPair> { Ok(s.parse()?) } }
这里我们实现了一个 FromStr trait,可以把满足条件的字符串转换成 KvPair。FromStr 是 Rust 标准库定义的 trait,实现它之后,就可以调用字符串的 parse() 泛型函数,很方便地处理字符串到某个类型的转换了。
这样修改完成后,我们的 CLI 就比较健壮了,可以再测试一下:
#![allow(unused)] fn main() { ❯ cargo build --quiet ❯ target/debug/httpie post https://httpbin.org/post a=1 b error: Invalid value for '<BODY>...': Failed to parse b For more information try --help ❯ target/debug/httpie post abc a=1 error: Invalid value for '<URL>': relative URL without a base For more information try --help target/debug/httpie post https://httpbin.org/post a=1 b=2 Opts { subcmd: Post(Post { url: "https://httpbin.org/post", body: [KvPair { k: "a", v: "1" }, KvPair { k: "b", v: "2" }] }) } }
Cool,我们完成了基本的验证,不过很明显可以看到,我们并没有把各种验证代码一股脑塞在主流程中,而是 通过实现额外的验证函数和 trait 来完成的,这些新添加的代码,高度可复用且彼此独立,并不用修改主流程。
这非常符合软件开发的开闭原则( Open-Closed Principle):Rust 可以通过宏、trait、泛型函数、trait object 等工具,帮助我们更容易写出结构良好、容易维护的代码。
目前你也许还不太明白这些代码的细节,但是不要担心,继续写,今天先把代码跑起来就行了,不需要你搞懂每个知识点,之后我们都会慢慢讲到的。
HTTP 请求
好,接下来我们就继续进行 HTTPie 的核心功能:HTTP 的请求处理了。我们在 main() 函数里添加处理子命令的流程:
use reqwest::{header, Client, Response, Url}; #[tokio::main] async fn main() -> Result<()> { let opts: Opts = Opts::parse(); // 生成一个 HTTP 客户端 let client = Client::new(); let result = match opts.subcmd { SubCommand::Get(ref args) => get(client, args).await?, SubCommand::Post(ref args) => post(client, args).await?, }; Ok(result) }
注意看我们把 main 函数变成了 async fn,它代表异步函数。对于 async main,我们需要使用 #[tokio::main] 宏来自动添加处理异步的运行时。
然后在 main 函数内部,我们根据子命令的类型,我们分别调用 get 和 post 函数做具体处理,这两个函数实现如下:
#![allow(unused)] fn main() { use std::{collections::HashMap, str::FromStr}; async fn get(client: Client, args: &Get) -> Result<()> { let resp = client.get(&args.url).send().await?; println!("{:?}", resp.text().await?); Ok(()) } async fn post(client: Client, args: &Post) -> Result<()> { let mut body = HashMap::new(); for pair in args.body.iter() { body.insert(&pair.k, &pair.v); } let resp = client.post(&args.url).json(&body).send().await?; println!("{:?}", resp.text().await?); Ok(()) } }
其中,我们解析出来的 KvPair 列表,需要装入一个 HashMap,然后传给 HTTP client 的 JSON 方法。这样,我们的 HTTPie 的基本功能就完成了。
不过现在打印出来的数据对用户非常不友好,我们需要进一步用不同的颜色打印 HTTP header 和 HTTP body,就像 Python 版本的 HTTPie 那样,这部分代码比较简单,我们就不详细介绍了。
最后,来看完整的代码:
use anyhow::{anyhow, Result}; use clap::{AppSettings, Clap}; use colored::*; use mime::Mime; use reqwest::{header, Client, Response, Url}; use std::{collections::HashMap, str::FromStr}; // 以下部分用于处理 CLI // 定义 HTTPie 的 CLI 的主入口,它包含若干个子命令 // 下面 /// 的注释是文档,clap 会将其作为 CLI 的帮助 /// A naive httpie implementation with Rust, can you imagine how easy it is? #[derive(Clap, Debug)] #[clap(version = "1.0", author = "Tyr Chen <tyr@chen.com>")] #[clap(setting = AppSettings::ColoredHelp)] struct Opts { #[clap(subcommand)] subcmd: SubCommand, } // 子命令分别对应不同的 HTTP 方法,目前只支持 get / post #[derive(Clap, Debug)] enum SubCommand { Get(Get), Post(Post), // 我们暂且不支持其它 HTTP 方法 } // get 子命令 /// feed get with an url and we will retrieve the response for you #[derive(Clap, Debug)] struct Get { /// HTTP 请求的 URL #[clap(parse(try_from_str = parse_url))] url: String, } // post 子命令。需要输入一个 URL,和若干个可选的 key=value,用于提供 json body /// feed post with an url and optional key=value pairs. We will post the data /// as JSON, and retrieve the response for you #[derive(Clap, Debug)] struct Post { /// HTTP 请求的 URL #[clap(parse(try_from_str = parse_url))] url: String, /// HTTP 请求的 body #[clap(parse(try_from_str=parse_kv_pair))] body: Vec<KvPair>, } /// 命令行中的 key=value 可以通过 parse_kv_pair 解析成 KvPair 结构 #[derive(Debug, PartialEq)] struct KvPair { k: String, v: String, } /// 当我们实现 FromStr trait 后,可以用 str.parse() 方法将字符串解析成 KvPair impl FromStr for KvPair { type Err = anyhow::Error; fn from_str(s: &str) -> Result<Self, Self::Err> { // 使用 = 进行 split,这会得到一个迭代器 let mut split = s.split("="); let err = || anyhow!(format!("Failed to parse {}", s)); Ok(Self { // 从迭代器中取第一个结果作为 key,迭代器返回 Some(T)/None // 我们将其转换成 Ok(T)/Err(E),然后用 ? 处理错误 k: (split.next().ok_or_else(err)?).to_string(), // 从迭代器中取第二个结果作为 value v: (split.next().ok_or_else(err)?).to_string(), }) } } /// 因为我们为 KvPair 实现了 FromStr,这里可以直接 s.parse() 得到 KvPair fn parse_kv_pair(s: &str) -> Result<KvPair> { Ok(s.parse()?) } fn parse_url(s: &str) -> Result<String> { // 这里我们仅仅检查一下 URL 是否合法 let _url: Url = s.parse()?; Ok(s.into()) } /// 处理 get 子命令 async fn get(client: Client, args: &Get) -> Result<()> { let resp = client.get(&args.url).send().await?; Ok(print_resp(resp).await?) } /// 处理 post 子命令 async fn post(client: Client, args: &Post) -> Result<()> { let mut body = HashMap::new(); for pair in args.body.iter() { body.insert(&pair.k, &pair.v); } let resp = client.post(&args.url).json(&body).send().await?; Ok(print_resp(resp).await?) } // 打印服务器版本号 + 状态码 fn print_status(resp: &Response) { let status = format!("{:?} {}", resp.version(), resp.status()).blue(); println!("{}\n", status); } // 打印服务器返回的 HTTP header fn print_headers(resp: &Response) { for (name, value) in resp.headers() { println!("{}: {:?}", name.to_string().green(), value); } print!("\n"); } /// 打印服务器返回的 HTTP body fn print_body(m: Option<Mime>, body: &String) { match m { // 对于 "application/json" 我们 pretty print Some(v) if v == mime::APPLICATION_JSON => { println!("{}", jsonxf::pretty_print(body).unwrap().cyan()) } // 其它 mime type,我们就直接输出 _ => println!("{}", body), } } /// 打印整个响应 async fn print_resp(resp: Response) -> Result<()> { print_status(&resp); print_headers(&resp); let mime = get_content_type(&resp); let body = resp.text().await?; print_body(mime, &body); Ok(()) } /// 将服务器返回的 content-type 解析成 Mime 类型 fn get_content_type(resp: &Response) -> Option<Mime> { resp.headers() .get(header::CONTENT_TYPE) .map(|v| v.to_str().unwrap().parse().unwrap()) } /// 程序的入口函数,因为在 HTTP 请求时我们使用了异步处理,所以这里引入 tokio #[tokio::main] async fn main() -> Result<()> { let opts: Opts = Opts::parse(); let mut headers = header::HeaderMap::new(); // 为我们的 HTTP 客户端添加一些缺省的 HTTP 头 headers.insert("X-POWERED-BY", "Rust".parse()?); headers.insert(header::USER_AGENT, "Rust Httpie".parse()?); let client = reqwest::Client::builder() .default_headers(headers) .build()?; let result = match opts.subcmd { SubCommand::Get(ref args) => get(client, args).await?, SubCommand::Post(ref args) => post(client, args).await?, }; Ok(result) } // 仅在 cargo test 时才编译 #[cfg(test)] mod tests { use super::*; #[test] fn parse_url_works() { assert!(parse_url("abc").is_err()); assert!(parse_url("http://abc.xyz").is_ok()); assert!(parse_url("https://httpbin.org/post").is_ok()); } #[test] fn parse_kv_pair_works() { assert!(parse_kv_pair("a").is_err()); assert_eq!( parse_kv_pair("a=1").unwrap(), KvPair { k: "a".into(), v: "1".into() } ); assert_eq!( parse_kv_pair("b=").unwrap(), KvPair { k: "b".into(), v: "".into() } ); } }
在这个完整代码的最后,我还撰写了几个单元测试,你可以用 cargo test 运行。Rust 支持条件编译,这里 #[cfg(test)] 表明整个 mod tests 都只在 cargo test 时才编译。
使用 代码行数统计工具 tokei 可以看到,我们总共使用了 139 行代码,就实现了这个功能,其中还包含了约 30 行的单元测试代码:
❯ tokei src/main.rs
-------------------------------------------------------------------------------
Language Files Lines Code Comments Blanks
-------------------------------------------------------------------------------
Rust 1 200 139 33 28
-------------------------------------------------------------------------------
Total 1 200 139 33 28
-------------------------------------------------------------------------------
你可以使用 cargo build --release,编译出 release 版本,并将其拷贝到某个在 $PATH 下的目录,然后体验一下:
到这里一个带有完整帮助的 HTTPie 就可以投入使用了。
我们测试一下效果:
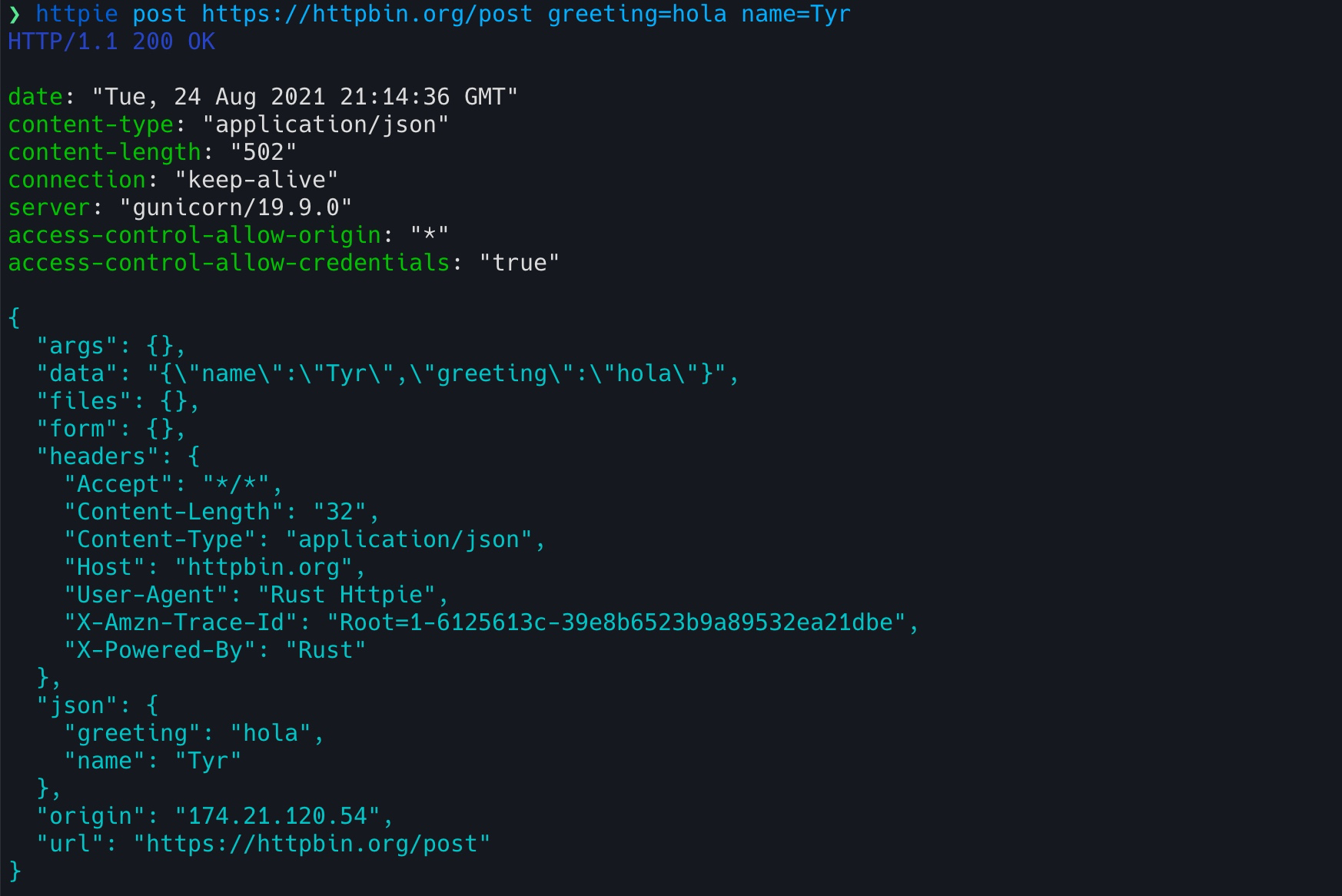
这和官方的 HTTPie 效果几乎一样。今天的源代码可以在 这里 找到.
哈,这个例子我们大获成功。我们只用了 100 行代码出头,就实现了 HTTPie 的核心功能,远低于预期的 200 行。不知道你能否从中隐约感受到 Rust 解决实际问题的能力,以今天实现的 HTTPie 为例,
- 要把 命令行解析成数据结构,我们只需要在数据结构上,添加一些简单的标注就能搞定。
- 数据的验证,又可以由单独的、和主流程没有任何耦合关系的函数完成。
- 作为 CLI 解析库,clap 的整体体验和 Python 的 click 非常类似,但比 Golang 的 cobra 要更简单。
这就是 Rust 语言的能力体现,明明是面向系统级开发,却能够做出类似 Python 的抽象和体验,所以一旦你适应了 Rust ,用起来就会感觉非常美妙。
小结
现在你应该有点明白,为什么我会在开篇词中会说,Rust 拥有强大的表现力。
或许你还是有点疑惑,这么学,我也太懵了,跟盲人摸象似的。其实初学者都会以为,必须要先搞明白所有的语法知识,才能动手写代码,不是的。
我们这周写三个实用例子的挑战,就是 为了让你,在懵懂地撰写代码的过程中,直观感受 Rust 处理问题、解决问题的方式,同时可以跟你熟悉的语言去类比,无论是 Golang / Java,还是 Python / JavaScript,如果我用自己熟悉的语言怎么解决、Rust 给了我什么样的支持、我感觉它还缺什么。
在这个过程中,你脑子里会产生各种深度的思考,这些思考又必然会引发越来越多的问号,这是好事,带着这些问号,在未来的课程中才能更有目的地学习,也一定会学得深刻而有效。
今天的小挑战并不太难,你可能还意犹未尽。别急,下一讲我们会再写个难度大一点的、工作中都会用到的 Web 服务,继续体验 Rust 的魅力。
思考题
我们只是实现了 HTTP header 和 body 的高亮区分,但是 HTTP body 还是有些不太美观,可以进一步做语法高亮,如果你完成了今天的代码,觉得自己学有余力可以再挑战一下,你不妨试一试用 syntect 继续完善我们的 HTTPie。syntect 是 Rust 的一个语法高亮库,非常强大。
欢迎在留言区分享你的思考。你的 Rust 学习第四次打卡成功,我们下一讲见!
特别说明
注意:本篇文章中依赖用到了 beta 版本的 crate,可能未来会有破坏性更新,如果在本地无法编译,请参考 GitHub repo 中的代码。后续文章中,如果出现类似问题,同样参考GitHub上的最新代码。学习愉快~
get hands dirty:做一个图片服务器有多难?
你好,我是陈天。
上一讲我们只用了百来行代码就写出了 HTTPie 这个小工具,你是不是有点意犹未尽,今天我们就来再写一个实用的小例子,看看Rust还能怎么玩。
再说明一下,代码看不太懂完全没有关系,先不要强求理解,跟着我的节奏一行行写就好, 先让自己的代码跑起来,感受 Rust 和自己常用语言的区别,看看代码风格是什么样的,就可以了。
今天的例子是我们在工作中都会遇到的需求:构建一个 Web Server,对外提供某种服务。类似上一讲的 HTTPie ,我们继续找一个已有的开源工具用 Rust 来重写,但是今天来挑战一个稍大一点的项目:构建一个类似 Thumbor 的图片服务器。
Thumbor
Thumbor 是 Python 下的一个非常著名的图片服务器,被广泛应用在各种需要动态调整图片尺寸的场合里。
它可以通过一个很简单的 HTTP 接口,实现图片的动态剪切和大小调整,另外还支持文件存储、替换处理引擎等其他辅助功能。我在之前的创业项目中还用过它,非常实用,性能也还不错。
我们看它的例子:
http://<thumbor-server>/300x200/smart/thumbor.readthedocs.io/en/latest/_images/logo-thumbor.png
在这个例子里,Thumbor 可以对这个图片最后的 URL 使用 smart crop 剪切,并调整大小为 300x200 的尺寸输出,用户访问这个 URL 会得到一个 300x200 大小的缩略图。
我们今天就来实现它最核心的功能,对图片进行动态转换。你可以想一想,如果用你最熟悉的语言,要实现这个服务,怎么设计,需要用到些什么库,大概用多少行代码?如果用 Rust 的话,又大概会多少行代码?
带着你自己的一些想法,开始用 Rust 构建这个工具吧!目标依旧是,用大约 200 行代码实现我们的需求。
设计分析
既然是图片转换,最基本的肯定是要支持各种各样的转换功能,比如调整大小、剪切、加水印,甚至包括图片的滤镜但是, 图片转换服务的难点其实在接口设计上,如何设计一套易用、简洁的接口,让图片服务器未来可以很轻松地扩展。
为什么这么说,你想如果有一天,产品经理来找你,突然想让原本只用来做缩略图的图片服务,支持老照片的滤镜效果,你准备怎么办?
Thumbor 给出的答案是,把要使用的处理方法的接口,按照一定的格式、一定的顺序放在 URL 路径中,不使用的图片处理方法就不放:
/hmac/trim/AxB:CxD/(adaptative-)(full-)fit-in/-Ex-F/HALIGN/VALIGN/smart/filters:FILTERNAME(ARGUMENT):FILTERNAME(ARGUMENT)/*IMAGE-URI*
但这样不容易扩展,解析起来不方便,也很难满足对图片做多个有序操作的要求,比如对某个图片我想先加滤镜再加水印,对另一个图片我想先加水印再加滤镜。
另外,如果未来要加更多的参数,一个不小心,还很可能和已有的参数冲突,或者造成 API 的破坏性更新(breaking change)。作为开发者,我们永远不要低估产品经理那颗什么奇葩想法都有的躁动的心。
所以,在构思这个项目的时候, 我们需要找一种更简洁且可扩展的方式,来描述对图片进行的一系列有序操作,比如说:先做 resize,之后对 resize 的结果添加一个水印,最后统一使用一个滤镜。
这样的有序操作,对应到代码中,可以用列表来表述,列表中每个操作可以是一个 enum,像这样:
#![allow(unused)] fn main() { // 解析出来的图片处理的参数 struct ImageSpec { specs: Vec<Spec> } // 每个参数的是我们支持的某种处理方式 enum Spec { Resize(Resize), Crop(Crop), ... } // 处理图片的 resize struct Resize { width: u32, height: u32 } }
现在需要的数据结构有了,刚才分析了 thumbor 使用的方式拓展性不好, 那我们如何设计一个任何客户端可以使用的、体现在 URL 上的接口,使其能够解析成我们设计的数据结构呢?
使用 querystring 么?虽然可行,但它在图片处理步骤比较复杂的时候,容易无序增长,比如我们要对某个图片做七八次转换,这个 querystring 就会非常长。
我这里的思路是使用 protobuf。protobuf 可以描述数据结构,几乎所有语言都有对 protobuf 的支持。当用 protobuf 生成一个 image spec 后,我们可以将其序列化成字节流。但字节流无法放在 URL 中,怎么办?我们可以用 base64 转码!
顺着这个思路,来试着写一下描述 image spec 的 protobuf 消息的定义:
message ImageSpec { repeated Spec specs = 1; }
message Spec {
oneof data {
Resize resize = 1;
Crop crop = 2;
...
}
}
...
这样我们就可以在 URL 中,嵌入通过 protobuf 生成的 base64 字符串,来提供可扩展的图片处理参数。处理过的 URL 长这个样子:
http://localhost:3000/image/CgoKCAjYBBCgBiADCgY6BAgUEBQKBDICCAM/<encoded origin url>
CgoKCAjYBBCgBiADCgY6BAgUEBQKBDICCAM 描述了我们上面说的图片的处理流程:先做 resize,之后对 resize 的结果添加一个水印,最后统一使用一个滤镜。它可以用下面的代码实现:
#![allow(unused)] fn main() { fn print_test_url(url: &str) { use std::borrow::Borrow; let spec1 = Spec::new_resize(600, 800, resize::SampleFilter::CatmullRom); let spec2 = Spec::new_watermark(20, 20); let spec3 = Spec::new_filter(filter::Filter::Marine); let image_spec = ImageSpec::new(vec![spec1, spec2, spec3]); let s: String = image_spec.borrow().into(); let test_image = percent_encode(url.as_bytes(), NON_ALPHANUMERIC).to_string(); println!("test url: http://localhost:3000/image/{}/{}", s, test_image); } }
使用 protobuf 的好处是,序列化后的结果比较小巧,而且任何支持 protobuf 的语言都可以生成或者解析这个接口。
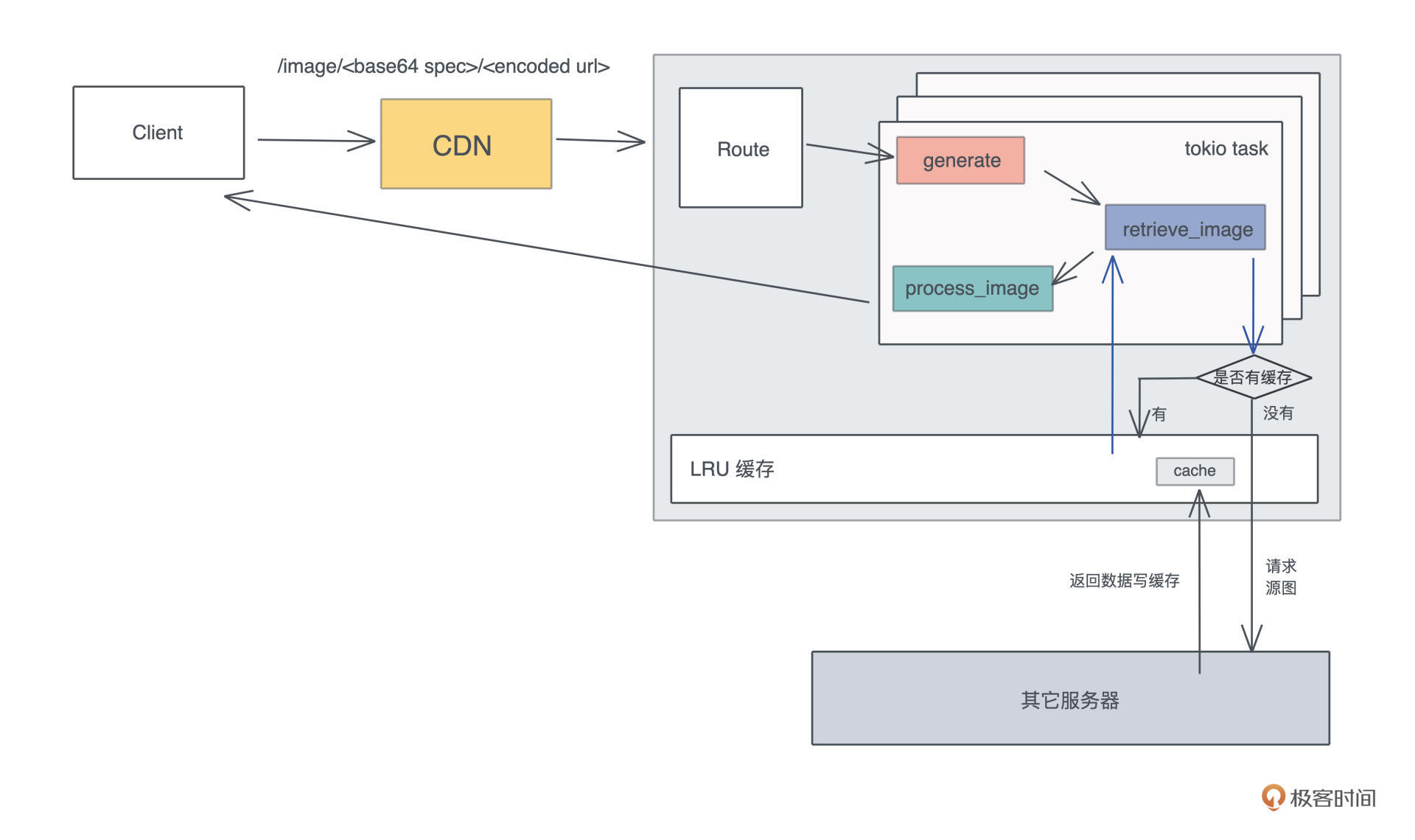
好,接口我们敲定好,接下来就是做一个 HTTP 服务器提供这个接口。在 HTTP 服务器对 /image 路由的处理流程里,我们需要从 URL 中获取原始的图片,然后按照 image spec 依次处理,最后把处理完的字节流返回给用户。
在这个流程中,显而易见能够想到的优化是, 为原始图片的获取过程,提供一个 LRU(Least Recently Used)缓存,因为访问外部网络是整个路径中最缓慢也最不可控的环节。
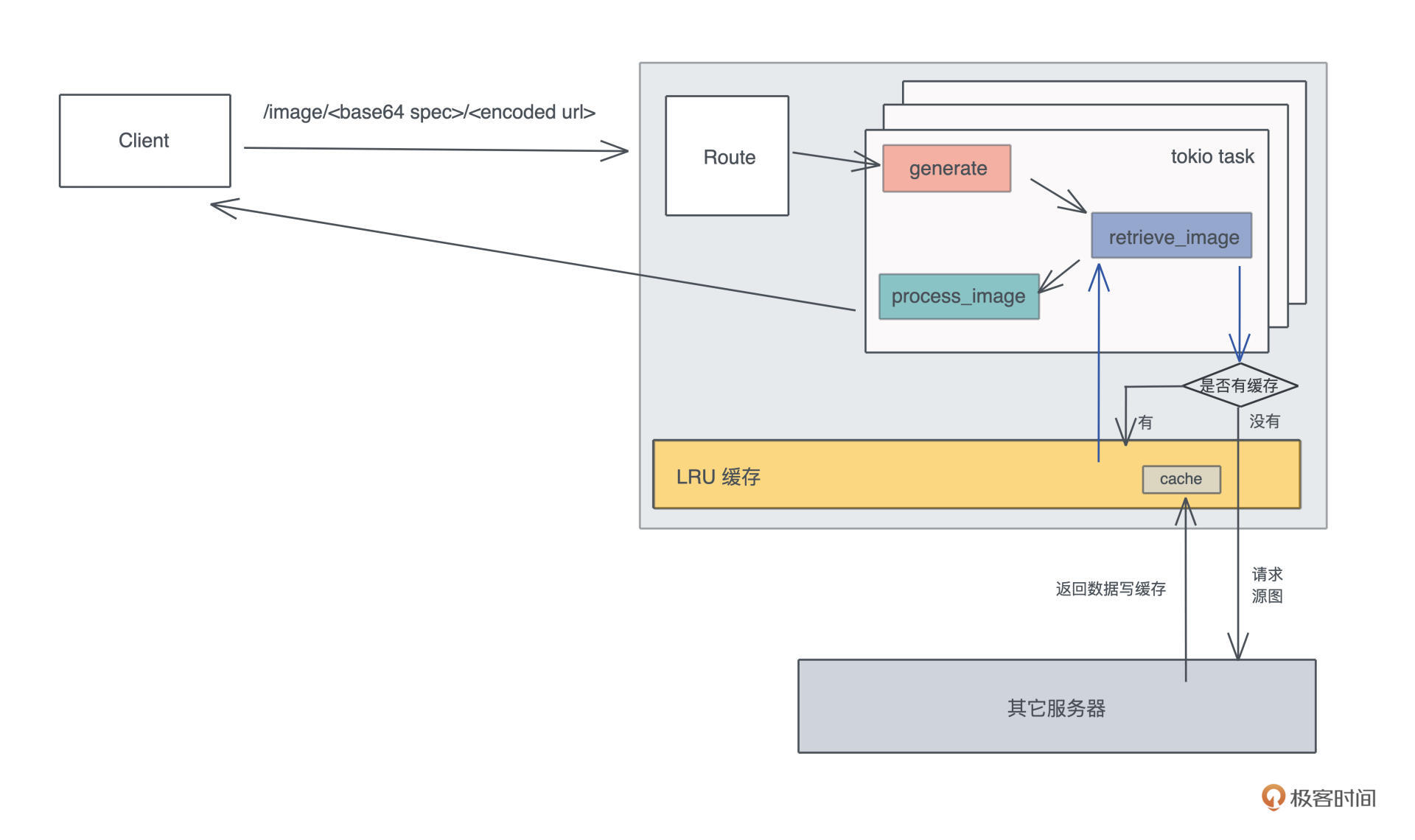
分析完后,是不是感觉 thumbor 也没有什么复杂的?不过你一定会有疑问:200 行代码真的可以完成这么多工作么?我们先写着,完成之后再来统计一下。
protobuf 的定义和编译
这个项目我们需要很多依赖,就不一一介绍了,未来在你的学习、工作中,大部分依赖你都会渐渐遇到和使用到。
我们照样先 “cargo new thumbor” 生成项目,然后在项目的 Cargo.toml 中添加这些依赖:
[dependencies]
axum = "0.2" # web 服务器
anyhow = "1" # 错误处理
base64 = "0.13" # base64 编码/解码
bytes = "1" # 处理字节流
image = "0.23" # 处理图片
lazy_static = "1" # 通过宏更方便地初始化静态变量
lru = "0.6" # LRU 缓存
percent-encoding = "2" # url 编码/解码
photon-rs = "0.3" # 图片效果
prost = "0.8" # protobuf 处理
reqwest = "0.11" # HTTP cliebnt
serde = { version = "1", features = ["derive"] } # 序列化/反序列化数据
tokio = { version = "1", features = ["full"] } # 异步处理
tower = { version = "0.4", features = ["util", "timeout", "load-shed", "limit"] } # 服务处理及中间件
tower-http = { version = "0.1", features = ["add-extension", "compression-full", "trace" ] } # http 中间件
tracing = "0.1" # 日志和追踪
tracing-subscriber = "0.2" # 日志和追踪
[build-dependencies]
prost-build = "0.8" # 编译 protobuf
在项目根目录下,生成一个 abi.proto 文件,写入我们支持的图片处理服务用到的数据结构:
syntax = "proto3";
package abi; // 这个名字会被用作编译结果,prost 会产生:abi.rs
// 一个 ImageSpec 是一个有序的数组,服务器按照 spec 的顺序处理
message ImageSpec { repeated Spec specs = 1; }
// 处理图片改变大小
message Resize {
uint32 width = 1;
uint32 height = 2;
enum ResizeType {
NORMAL = 0;
SEAM_CARVE = 1;
}
ResizeType rtype = 3;
enum SampleFilter {
UNDEFINED = 0;
NEAREST = 1;
TRIANGLE = 2;
CATMULL_ROM = 3;
GAUSSIAN = 4;
LANCZOS3 = 5;
}
SampleFilter filter = 4;
}
// 处理图片截取
message Crop {
uint32 x1 = 1;
uint32 y1 = 2;
uint32 x2 = 3;
uint32 y2 = 4;
}
// 处理水平翻转
message Fliph {}
// 处理垂直翻转
message Flipv {}
// 处理对比度
message Contrast { float contrast = 1; }
// 处理滤镜
message Filter {
enum Filter {
UNSPECIFIED = 0;
OCEANIC = 1;
ISLANDS = 2;
MARINE = 3;
// more: https://docs.rs/photon-rs/0.3.1/photon_rs/filters/fn.filter.html
}
Filter filter = 1;
}
// 处理水印
message Watermark {
uint32 x = 1;
uint32 y = 2;
}
// 一个 spec 可以包含上述的处理方式之一
message Spec {
oneof data {
Resize resize = 1;
Crop crop = 2;
Flipv flipv = 3;
Fliph fliph = 4;
Contrast contrast = 5;
Filter filter = 6;
Watermark watermark = 7;
}
}
这包含了我们支持的图片处理服务,以后可以轻松扩展它来支持更多的操作。
protobuf 是一个向下兼容的工具,所以在服务器不断支持更多功能时,还可以和旧版本的客户端兼容。在 Rust 下,我们可以用 prost 来使用和编译 protobuf。同样,在项目根目录下,创建一个 build.rs,写入以下代码:
fn main() { prost_build::Config::new() .out_dir("src/pb") .compile_protos(&["abi.proto"], &["."]) .unwrap(); }
build.rs 可以在编译 cargo 项目时,做额外的编译处理。这里我们使用 prost_build 把 abi.proto 编译到 src/pb 目录下。
这个目录现在还不存在,你需要 mkdir src/pb 创建它。运行 cargo build,你会发现在 src/pb 下,有一个 abi.rs 文件被生成出来,这个文件包含了从 protobuf 消息转换出来的 Rust 数据结构。我们先不用管 prost 额外添加的各种标记宏,就把它们当成普通的数据结构使用即可。
接下来,我们创建 src/pb/mod.rs,第三讲说过, 一个目录下的所有代码,可以通过 mod.rs 声明。在这个文件中,我们引入 abi.rs,并且撰写一些辅助函数。这些辅助函数主要是为了,让 ImageSpec 可以被方便地转换成字符串,或者从字符串中恢复。
另外,我们还写了一个测试确保功能的正确性,你可以 cargo test 测试一下。记得在 main.rs 里添加 mod pb; 引入这个模块。
#![allow(unused)] fn main() { use base64::{decode_config, encode_config, URL_SAFE_NO_PAD}; use photon_rs::transform ::SamplingFilter; use prost::Message; use std::convert::TryFrom; mod abi; // 声明 abi.rs pub use abi::*; impl ImageSpec { pub fn new(specs: Vec<Spec>) -> Self { Self { specs } } } // 让 ImageSpec 可以生成一个字符串 impl From<&ImageSpec> for String { fn from(image_spec: &ImageSpec) -> Self { let data = image_spec.encode_to_vec(); encode_config(data, URL_SAFE_NO_PAD) } } // 让 ImageSpec 可以通过一个字符串创建。比如 s.parse().unwrap() impl TryFrom<&str> for ImageSpec { type Error = anyhow::Error; fn try_from(value: &str) -> Result<Self, Self::Error> { let data = decode_config(value, URL_SAFE_NO_PAD)?; Ok(ImageSpec::decode(&data[..])?) } } // 辅助函数,photon_rs 相应的方法里需要字符串 impl filter::Filter { pub fn to_str(&self) -> Option<&'static str> { match self { filter::Filter::Unspecified => None, filter::Filter::Oceanic => Some("oceanic"), filter::Filter::Islands => Some("islands"), filter::Filter::Marine => Some("marine"), } } } // 在我们定义的 SampleFilter 和 photon_rs 的 SamplingFilter 间转换 impl From<resize::SampleFilter> for SamplingFilter { fn from(v: resize::SampleFilter) -> Self { match v { resize::SampleFilter::Undefined => SamplingFilter::Nearest, resize::SampleFilter::Nearest => SamplingFilter::Nearest, resize::SampleFilter::Triangle => SamplingFilter::Triangle, resize::SampleFilter::CatmullRom => SamplingFilter::CatmullRom, resize::SampleFilter::Gaussian => SamplingFilter::Gaussian, resize::SampleFilter::Lanczos3 => SamplingFilter::Lanczos3, } } } // 提供一些辅助函数,让创建一个 spec 的过程简单一些 impl Spec { pub fn new_resize_seam_carve(width: u32, height: u32) -> Self { Self { data: Some(spec::Data::Resize(Resize { width, height, rtype: resize::ResizeType::SeamCarve as i32, filter: resize::SampleFilter::Undefined as i32, })), } } pub fn new_resize(width: u32, height: u32, filter: resize::SampleFilter) -> Self { Self { data: Some(spec::Data::Resize(Resize { width, height, rtype: resize::ResizeType::Normal as i32, filter: filter as i32, })), } } pub fn new_filter(filter: filter::Filter) -> Self { Self { data: Some(spec::Data::Filter(Filter { filter: filter as i32, })), } } pub fn new_watermark(x: u32, y: u32) -> Self { Self { data: Some(spec::Data::Watermark(Watermark { x, y })), } } } #[cfg(test)] mod tests { use super::*; use std::borrow::Borrow; use std::convert::TryInto; #[test] fn encoded_spec_could_be_decoded() { let spec1 = Spec::new_resize(600, 600, resize::SampleFilter::CatmullRom); let spec2 = Spec::new_filter(filter::Filter::Marine); let image_spec = ImageSpec::new(vec![spec1, spec2]); let s: String = image_spec.borrow().into(); assert_eq!(image_spec, s.as_str().try_into().unwrap()); } } }
引入 HTTP 服务器
处理完和 protobuf 相关的内容,我们来处理 HTTP 服务的流程。Rust 社区有很多高性能的 Web 服务器,比如 actix-web 、 rocket 、 warp ,以及最近新出的 axum。我们就来用新鲜出炉的 axum 做这个服务器。
根据 axum 的文档,我们可以构建出下面的代码:
use axum::{extract::Path, handler::get, http::StatusCode, Router}; use percent_encoding::percent_decode_str; use serde::Deserialize; use std::convert::TryInto; // 引入 protobuf 生成的代码,我们暂且不用太关心他们 mod pb; use pb::*; // 参数使用 serde 做 Deserialize,axum 会自动识别并解析 #[derive(Deserialize)] struct Params { spec: String, url: String, } #[tokio::main] async fn main() { // 初始化 tracing tracing_subscriber::fmt::init(); // 构建路由 let app = Router::new() // `GET /image` 会执行 generate 函数,并把 spec 和 url 传递过去 .route("/image/:spec/:url", get(generate)); // 运行 web 服务器 let addr = "127.0.0.1:3000".parse().unwrap(); tracing::debug!("listening on {}", addr); axum::Server::bind(&addr) .serve(app.into_make_service()) .await .unwrap(); } // 目前我们就只把参数解析出来 async fn generate(Path(Params { spec, url }): Path<Params>) -> Result<String, StatusCode> { let url = percent_decode_str(&url).decode_utf8_lossy(); let spec: ImageSpec = spec .as_str() .try_into() .map_err(|_| StatusCode::BAD_REQUEST)?; Ok(format!("url: {}\n spec: {:#?}", url, spec)) }
把它们添加到 main.rs 后,使用 cargo run 运行服务器。然后我们就可以用上一讲做的 HTTPie 测试(eat your own dog food):
#![allow(unused)] fn main() { httpie get "http://localhost:3000/image/CgoKCAjYBBCgBiADCgY6BAgUEBQKBDICCAM/https%3A%2F%2Fimages%2Epexels%2Ecom%2Fphotos%2F2470905%2Fpexels%2Dphoto%2D2470905%2Ejpeg%3Fauto%3Dcompress%26cs%3Dtinysrgb%26dpr%3D2%26h%3D750%26w%3D1260" HTTP/1.1 200 OK content-type: "text/plain" content-length: "901" date: "Wed, 25 Aug 2021 18:03:50 GMT" url: https://images.pexels.com/photos/2470905/pexels-photo-2470905.jpeg?auto=compress&cs=tinysrgb&dpr=2&h=750&w=1260 spec: ImageSpec { specs: [ Spec { data: Some( Resize( Resize { width: 600, height: 800, rtype: Normal, filter: CatmullRom, }, ), ), }, Spec { data: Some( Watermark( Watermark { x: 20, y: 20, }, ), ), }, Spec { data: Some( Filter( Filter { filter: Marine, }, ), ), }, ], }
Wow,Web 服务器的接口部分我们已经能够正确处理了。
写到这里,如果出现的语法让你觉得迷茫,不要担心。因为我们还没有讲所有权、类型系统、泛型等内容,所以很多细节你会看不懂。今天这个例子,你只要跟我的思路走,了解整个处理流程就可以了。
获取源图并缓存
好,当接口已经可以工作之后,我们再来处理获取源图的逻辑。
根据之前的设计,需要 引入 LRU cache 来缓存源图。一般 Web 框架都会有中间件来处理全局的状态,axum 也不例外,可以使用 AddExtensionLayer 添加一个全局的状态,这个状态目前就是 LRU cache,在内存中缓存网络请求获得的源图。
我们把 main.rs 的代码,改成下面的代码:
use anyhow::Result; use axum::{ extract::{Extension, Path}, handler::get, http::{HeaderMap, HeaderValue, StatusCode}, AddExtensionLayer, Router, }; use bytes::Bytes; use lru::LruCache; use percent_encoding::{percent_decode_str, percent_encode, NON_ALPHANUMERIC}; use serde::Deserialize; use std::{ collections::hash_map::DefaultHasher, convert::TryInto, hash::{Hash, Hasher}, sync::Arc, }; use tokio::sync::Mutex; use tower::ServiceBuilder; use tracing::{info, instrument}; mod pb; use pb::*; #[derive(Deserialize)] struct Params { spec: String, url: String, } type Cache = Arc<Mutex<LruCache<u64, Bytes>>>; #[tokio::main] async fn main() { // 初始化 tracing tracing_subscriber::fmt::init(); let cache: Cache = Arc::new(Mutex::new(LruCache::new(1024))); // 构建路由 let app = Router::new() // `GET /` 会执行 .route("/image/:spec/:url", get(generate)) .layer( ServiceBuilder::new() .layer(AddExtensionLayer::new(cache)) .into_inner(), ); // 运行 web 服务器 let addr = "127.0.0.1:3000".parse().unwrap(); print_test_url("https://images.pexels.com/photos/1562477/pexels-photo-1562477.jpeg?auto=compress&cs=tinysrgb&dpr=3&h=750&w=1260"); info!("Listening on {}", addr); axum::Server::bind(&addr) .serve(app.into_make_service()) .await .unwrap(); } async fn generate( Path(Params { spec, url }): Path<Params>, Extension(cache): Extension<Cache>, ) -> Result<(HeaderMap, Vec<u8>), StatusCode> { let spec: ImageSpec = spec .as_str() .try_into() .map_err(|_| StatusCode::BAD_REQUEST)?; let url: &str = &percent_decode_str(&url).decode_utf8_lossy(); let data = retrieve_image(&url, cache) .await .map_err(|_| StatusCode::BAD_REQUEST)?; // TODO: 处理图片 let mut headers = HeaderMap::new(); headers.insert("content-type", HeaderValue::from_static("image/jpeg")); Ok((headers, data.to_vec())) } #[instrument(level = "info", skip(cache))] async fn retrieve_image(url: &str, cache: Cache) -> Result<Bytes> { let mut hasher = DefaultHasher::new(); url.hash(&mut hasher); let key = hasher.finish(); let g = &mut cache.lock().await; let data = match g.get(&key) { Some(v) => { info!("Match cache {}", key); v.to_owned() } None => { info!("Retrieve url"); let resp = reqwest::get(url).await?; let data = resp.bytes().await?; g.put(key, data.clone()); data } }; Ok(data) } // 调试辅助函数 fn print_test_url(url: &str) { use std::borrow::Borrow; let spec1 = Spec::new_resize(500, 800, resize::SampleFilter::CatmullRom); let spec2 = Spec::new_watermark(20, 20); let spec3 = Spec::new_filter(filter::Filter::Marine); let image_spec = ImageSpec::new(vec![spec1, spec2, spec3]); let s: String = image_spec.borrow().into(); let test_image = percent_encode(url.as_bytes(), NON_ALPHANUMERIC).to_string(); println!("test url: http://localhost:3000/image/{}/{}", s, test_image); }
这段代码看起来多,其实主要就是添加了 retrieve_image 这个函数。对于图片的网络请求,我们先把 URL 做个哈希,在 LRU 缓存中查找,找不到才用 reqwest 发送请求。
你可以 cargo run 运行一下现在的代码:
#![allow(unused)] fn main() { ❯ RUST_LOG=info cargo run --quiet test url: http://localhost:3000/image/CgoKCAj0AxCgBiADCgY6BAgUEBQKBDICCAM/https%3A%2F%2Fimages%2Epexels%2Ecom%2Fphotos%2F1562477%2Fpexels%2Dphoto%2D1562477%2Ejpeg%3Fauto%3Dcompress%26cs%3Dtinysrgb%26dpr%3D3%26h%3D750%26w%3D1260 Aug 26 16:43:45.747 INFO server2: Listening on 127.0.0.1:3000 }
为了测试方便,我放了个辅助函数可以生成一个测试 URL,在浏览器中打开后会得到一个和源图一模一样的图片。这就说明,网络处理的部分,我们就搞定了。
图片处理
接下来,我们就可以处理图片了。Rust 下有一个不错的、偏底层的 image 库,围绕它有很多上层的库,包括我们今天要使用 photon_rs。
我扫了一下它的源代码,感觉它不算一个特别优秀的库,内部有太多无谓的内存拷贝,所以性能还有不少提升空间。就算如此,从 photon_rs 自己的 benchmark 看,也比 PIL / ImageMagick 性能好太多,这也算是 Rust 性能强大的一个小小佐证吧。
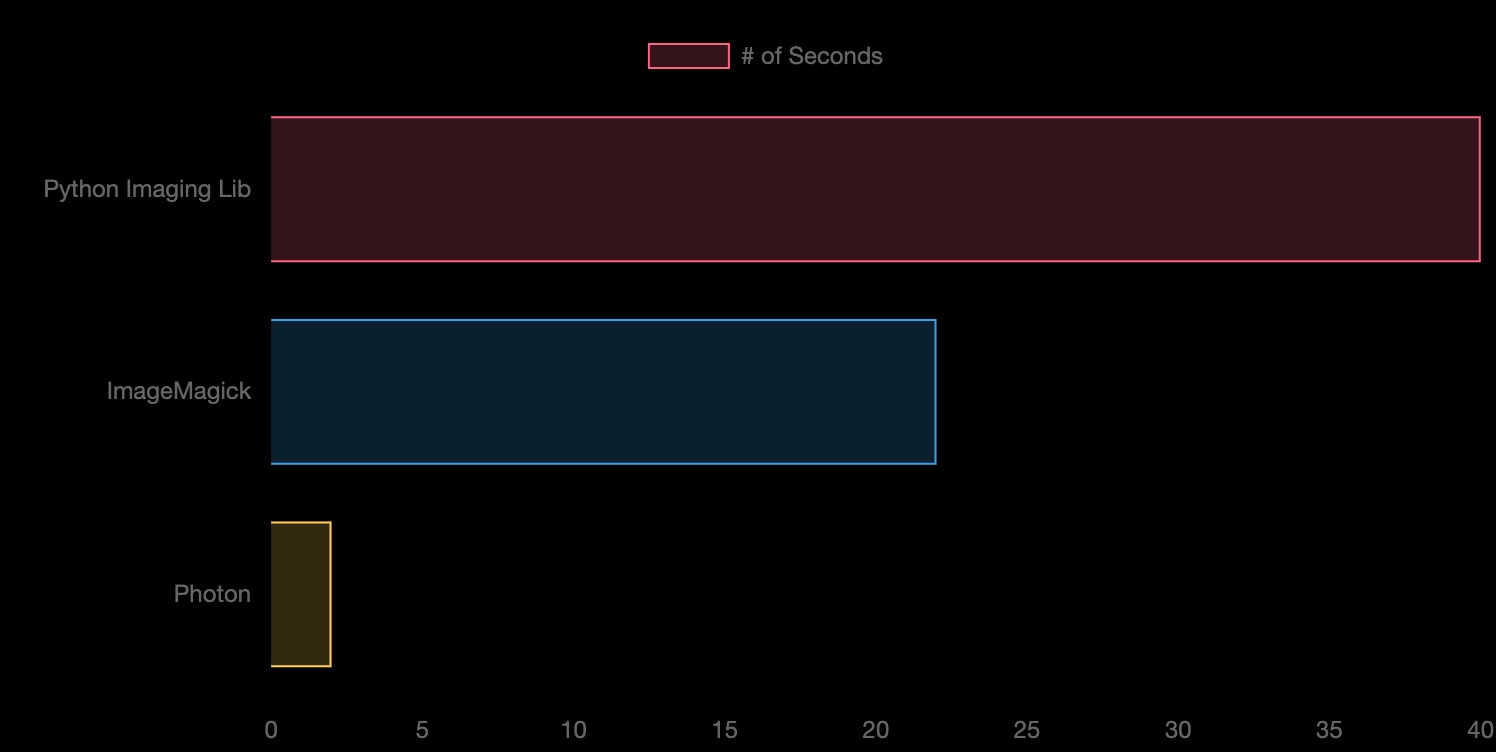
因为 photo_rs 使用简单,这里我们也不太关心更高的性能,就暂且用它。然而,作为一个有追求的开发者,我们知道,有朝一日可能要用不同的 image 引擎替换它,所以我们设计一个 Engine trait:
#![allow(unused)] fn main() { // Engine trait:未来可以添加更多的 engine,主流程只需要替换 engine pub trait Engine { // 对 engine 按照 specs 进行一系列有序的处理 fn apply(&mut self, specs: &[Spec]); // 从 engine 中生成目标图片,注意这里用的是 self,而非 self 的引用 fn generate(self, format: ImageOutputFormat) -> Vec<u8>; } }
它提供两个方法, apply 方法对 engine 按照 specs 进行一系列有序的处理,generate 方法从 engine 中生成目标图片。
那么 apply 方法怎么实现呢?我们可以再设计一个 trait,这样可以为每个 Spec 生成对应处理:
#![allow(unused)] fn main() { // SpecTransform:未来如果添加更多的 spec,只需要实现它即可 pub trait SpecTransform<T> { // 对图片使用 op 做 transform fn transform(&mut self, op: T); } }
好,有了这个思路,我们创建 src/engine 目录,并添加 src/engine/mod.rs,在这个文件里添加对 trait 的定义:
#![allow(unused)] fn main() { use crate::pb::Spec; use image::ImageOutputFormat; mod photon; pub use photon::Photon; // Engine trait:未来可以添加更多的 engine,主流程只需要替换 engine pub trait Engine { // 对 engine 按照 specs 进行一系列有序的处理 fn apply(&mut self, specs: &[Spec]); // 从 engine 中生成目标图片,注意这里用的是 self,而非 self 的引用 fn generate(self, format: ImageOutputFormat) -> Vec<u8>; } // SpecTransform:未来如果添加更多的 spec,只需要实现它即可 pub trait SpecTransform<T> { // 对图片使用 op 做 transform fn transform(&mut self, op: T); } }
接下来我们再生成一个文件 src/engine/photon.rs,对 photon 实现 Engine trait,这个文件主要是一些功能的实现细节,就不详述了,你可以看注释。
#![allow(unused)] fn main() { use super::{Engine, SpecTransform}; use crate::pb::*; use anyhow::Result; use bytes::Bytes; use image::{DynamicImage, ImageBuffer, ImageOutputFormat}; use lazy_static::lazy_static; use photon_rs::{ effects, filters, multiple, native::open_image_from_bytes, transform, PhotonImage, }; use std::convert::TryFrom; lazy_static! { // 预先把水印文件加载为静态变量 static ref WATERMARK: PhotonImage = { // 这里你需要把我 github 项目下的对应图片拷贝到你的根目录 // 在编译的时候 include_bytes! 宏会直接把文件读入编译后的二进制 let data = include_bytes!("../../rust-logo.png"); let watermark = open_image_from_bytes(data).unwrap(); transform::resize(&watermark, 64, 64, transform::SamplingFilter::Nearest) }; } // 我们目前支持 Photon engine pub struct Photon(PhotonImage); // 从 Bytes 转换成 Photon 结构 impl TryFrom<Bytes> for Photon { type Error = anyhow::Error; fn try_from(data: Bytes) -> Result<Self, Self::Error> { Ok(Self(open_image_from_bytes(&data)?)) } } impl Engine for Photon { fn apply(&mut self, specs: &[Spec]) { for spec in specs.iter() { match spec.data { Some(spec::Data::Crop(ref v)) => self.transform(v), Some(spec::Data::Contrast(ref v)) => self.transform(v), Some(spec::Data::Filter(ref v)) => self.transform(v), Some(spec::Data::Fliph(ref v)) => self.transform(v), Some(spec::Data::Flipv(ref v)) => self.transform(v), Some(spec::Data::Resize(ref v)) => self.transform(v), Some(spec::Data::Watermark(ref v)) => self.transform(v), // 对于目前不认识的 spec,不做任何处理 _ => {} } } } fn generate(self, format: ImageOutputFormat) -> Vec<u8> { image_to_buf(self.0, format) } } impl SpecTransform<&Crop> for Photon { fn transform(&mut self, op: &Crop) { let img = transform::crop(&mut self.0, op.x1, op.y1, op.x2, op.y2); self.0 = img; } } impl SpecTransform<&Contrast> for Photon { fn transform(&mut self, op: &Contrast) { effects::adjust_contrast(&mut self.0, op.contrast); } } impl SpecTransform<&Flipv> for Photon { fn transform(&mut self, _op: &Flipv) { transform::flipv(&mut self.0) } } impl SpecTransform<&Fliph> for Photon { fn transform(&mut self, _op: &Fliph) { transform::fliph(&mut self.0) } } impl SpecTransform<&Filter> for Photon { fn transform(&mut self, op: &Filter) { match filter::Filter::from_i32(op.filter) { Some(filter::Filter::Unspecified) => {} Some(f) => filters::filter(&mut self.0, f.to_str().unwrap()), _ => {} } } } impl SpecTransform<&Resize> for Photon { fn transform(&mut self, op: &Resize) { let img = match resize::ResizeType::from_i32(op.rtype).unwrap() { resize::ResizeType::Normal => transform::resize( &mut self.0, op.width, op.height, resize::SampleFilter::from_i32(op.filter).unwrap().into(), ), resize::ResizeType::SeamCarve => { transform::seam_carve(&mut self.0, op.width, op.height) } }; self.0 = img; } } impl SpecTransform<&Watermark> for Photon { fn transform(&mut self, op: &Watermark) { multiple::watermark(&mut self.0, &WATERMARK, op.x, op.y); } } // photon 库竟然没有提供在内存中对图片转换格式的方法,只好手工实现 fn image_to_buf(img: PhotonImage, format: ImageOutputFormat) -> Vec<u8> { let raw_pixels = img.get_raw_pixels(); let width = img.get_width(); let height = img.get_height(); let img_buffer = ImageBuffer::from_vec(width, height, raw_pixels).unwrap(); let dynimage = DynamicImage::ImageRgba8(img_buffer); let mut buffer = Vec::with_capacity(32768); dynimage.write_to(&mut buffer, format).unwrap(); buffer } }
好,图片处理引擎就搞定了。这里用了一个水印图片,你可以去 GitHub repo 下载,然后放在项目根目录下。我们同样把 engine 模块加入 main.rs,并引入 Photon:
#![allow(unused)] fn main() { mod engine; use engine::{Engine, Photon}; use image::ImageOutputFormat; }
还记得 src/main.rs 的代码中,我们留了一个 TODO 么?
// TODO: 处理图片
let mut headers = HeaderMap::new();
headers.insert("content-type", HeaderValue::from_static("image/jpeg"));
Ok((headers, data.to_vec()))
我们把这段替换掉,使用刚才写好的 Photon 引擎处理:
#![allow(unused)] fn main() { // 使用 image engine 处理 let mut engine: Photon = data .try_into() .map_err(|_| StatusCode::INTERNAL_SERVER_ERROR)?; engine.apply(&spec.specs); let image = engine.generate(ImageOutputFormat::Jpeg(85)); info!("Finished processing: image size {}", image.len()); let mut headers = HeaderMap::new(); headers.insert("content-type", HeaderValue::from_static("image/jpeg")); Ok((headers, image)) }
这样整个服务器的全部流程就完成了,完整的代码可以在 GitHub repo 访问。
我在网上随手找了一张图片来测试下效果。用 cargo build --release 编译 thumbor 项目,然后打开日志运行:
#![allow(unused)] fn main() { RUST_LOG=info target/release/thumbor }
打开测试链接,在浏览器中可以看到左下角的处理后图片。(原图片来自 pexels,发布者 Min An)

成功了!这就是我们的 Thumbor 服务根据用户的请求缩小到 500x800、加了水印和 Marine 滤镜后的效果。
从日志看,第一次请求时因为没有缓存,需要请求源图,所以总共花了 400ms;如果你再刷新一下,后续对同一图片的请求,会命中缓存,花了大概 200ms。
Aug 25 15:09:28.035 INFO thumbor: Listening on 127.0.0.1:3000
Aug 25 15:09:30.523 INFO retrieve_image{url="<https://images.pexels.com/photos/1562477/pexels-photo-1562477.jpeg?auto=compress&cs=tinysrgb&dpr=3&h=750&w=1260>"}: thumbor: Retrieve url
Aug 25 15:09:30.950 INFO thumbor: Finished processing: image size 52674
Aug 25 15:09:35.037 INFO retrieve_image{url="<https://images.pexels.com/photos/1562477/pexels-photo-1562477.jpeg?auto=compress&cs=tinysrgb&dpr=3&h=750&w=1260>"}: thumbor: Match cache 13782279907884137652
Aug 25 15:09:35.254 INFO thumbor: Finished processing: image size 52674
这个版本目前是一个没有详细优化过的版本,性能已经足够好。而且,像 Thumbor 这样的图片服务,前面还有 CDN(Content Distribution Network)扛压力,只有 CDN 需要回源时,才会访问到,所以也可以不用太优化。
最后来看看目标完成得如何。如果不算 protobuf 生成的代码,Thumbor 这个项目,到目前为止我们写了 324 行代码:
#![allow(unused)] fn main() { ❯ tokei src/main.rs src/engine/* src/pb/mod.rs ------------------------------------------------------------------------------- Language Files Lines Code Comments Blanks ------------------------------------------------------------------------------- Rust 4 394 324 22 48 ------------------------------------------------------------------------------- Total 4 394 324 22 48 ------------------------------------------------------------------------------- }
三百多行代码就把一个图片服务器的核心部分搞定了,不仅如此,还充分考虑到了架构的可扩展性,用 trait 实现了主要的图片处理流程,并且引入了缓存来避免不必要的网络请求。虽然比我们预期的 200 行代码多了 50% 的代码量,但我相信它进一步佐证了 Rust 强大的表达能力。
而且, 通过合理使用 protobuf 定义接口和使用 trait 做图片引擎,未来添加新的功能非常简单,可以像搭积木一样垒上去,不会影响已有的功能,完全符合开闭原则( Open-Closed Principle)。
作为一门系统级语言,Rust 使用独特的内存管理方案,零成本地帮我们管理内存;作为一门高级语言,Rust 提供了足够强大的类型系统和足够完善的标准库,帮我们很容易写出低耦合、高内聚的代码。
小结
今天讲的 Thumbor 要比上一讲的 HTTPie 难度高一个数量级(完整代码在 GitHub repo ),所以细节理解不了不打紧,但我相信你会进一步被 Rust 强大的表现力、抽象能力和解决实际问题的能力折服。
比如说,我们通过 Engine trait 分离了具体的图片处理引擎和主流程,让主流程变得干净清爽;同时在处理 protobuf 生成的数据结构时,大量使用了 From / TryFrom trait 做数据类型的转换,也是一种解耦(关注点分离)的思路。
听我讲得这么流畅,你是不是觉得我写的时候肯定不会犯错。其实并没有,我在用 axum 写源图获取的流程时,就因为使用 Mutex 的错误而被编译器毒打,花了些时间才解决。
但这种毒打是非常让人心悦诚服且快乐的,因为我知道, 这样的并发问题一旦泄露到生产环境,解决起来大概率会毫无头绪,只能一点点试错可能有问题的代码,那个时候代价就远非和编译器搏斗的这十来分钟可比了。
所以只要你入了门,写 Rust 代码的过程绝对是一种享受,绝大多数错误在编译时就被揪出来了,你的代码只要编译能通过,基本上不需要担心它运行时的正确性。
也正是因为这样,在前期学习 Rust 的时候编译很难通过,导致我们直观感觉它是一门难学的语言,但其实它又很容易上手。这听起来矛盾,但确实是我自己的感受:它之所以学起来有些费力,有点像讲拉丁语系的人学习中文一样, 要打破很多自己原有的认知,去拥抱新的思想和概念。但是只要多写多思考,时间长了,理解起来就是水到渠成的事。
思考题
之前提到通过合理使用 protobuf 定义接口和使用 trait 做图片引擎,未来添加新的功能非常简单。如果你学有余力,可以自己尝试一下。
我们看如何添加新功能:
- 首先添加新的 proto,定义新的 spec
- 然后为 spec 实现 SpecTransform trait 和一些辅助函数
- 最后在 Engine 中使用 spec
如果要换图片引擎呢?也很简单:
- 添加新的图片引擎,像 Photon 那样,实现 Engine trait 以及为每种 spec 实现 SpecTransform Trait。
- 在 main.rs 里使用新的引擎。
欢迎在留言区分享你的思考,如果你觉得有收获,也欢迎你分享给你身边的朋友,邀他一起挑战。你的 Rust 学习第五次打卡成功,我们下一讲见!
get hands dirty:SQL查询工具怎么一鱼多吃?
你好,我是陈天。
通过 HTTPie 和 Thumbor 的例子,相信你对 Rust 的能力和代码风格有了比较直观的了解。之前我们说过Rust的应用范围非常广,但是这两个例子体现得还不是太明显。
有同学想看看,在实际工作中有大量生命周期标注的代码的样子;有同学对 Rust 的宏好奇;有同学对 Rust 和其它语言的互操作感兴趣;还有同学想知道 Rust 做客户端的感觉。所以,我们今天就来 用一个很硬核的例子把这些内容都涵盖进来。
话不多说,我们直接开始。
SQL
我们工作的时候经常会跟各种数据源打交道,数据源包括数据库、Parquet、CSV、JSON 等,而打交道的过程无非是:数据的获取(fetch)、过滤(filter)、投影(projection)和排序(sort)。
做大数据的同学可以用类似 Spark SQL 的工具来完成各种异质数据的查询,但是我们平时用 SQL 并没有这么强大。因为虽然用 SQL 对数据库做查询,任何 DBMS 都支持,如果想用 SQL 查询 CSV 或者 JSON,就需要很多额外的处理。
所以如果能有一个简单的工具, 不需要引入 Spark,就能支持对任何数据源使用 SQL 查询,是不是很有意义?
比如,如果你的 shell 支持这样使用是不是爽爆了?
再比如,我们的客户端会从服务器 API 获取数据的子集,如果这个子集可以在前端通过 SQL 直接做一些额外查询,那将非常灵活,并且用户可以得到即时的响应。
软件领域有个著名的 格林斯潘第十定律:
任何 C 或 Fortran 程序复杂到一定程度之后,都会包含一个临时开发的、不合规范的、充满程序错误的、运行速度很慢的、只有一半功能的 Common Lisp 实现。
我们仿照它来一个程序君第四十二定律:
任何 API 接口复杂到一定程度后,都会包含一个临时开发的、不合规范的、充满程序错误的、运行速度很慢的、只有一半功能的 SQL 实现。
所以,我们今天就来设计一个可以对任何数据源使用 SQL 查询,并获得结果的库如何?当然,作为一个 MVP(Mimimu Viable Product),我们就暂且只支持对 CSV 的 SQL 查询。不单如此,我们还希望这个库可以给 Python3 和 Node.js 使用。
猜一猜这个库要花多少行代码?今天难度比较大,怎么着要 500 行吧?我们暂且以 500 行代码为基准来挑战。
设计分析
我们首先需要一个 SQL 解析器。在 Rust 下,写一个解析器并不困难,可以用 serde、用任何 parser combinator 或者 PEG parser 来实现,比如 nom 或者 pest。不过 SQL 解析,这种足够常见的需求,Rust 社区已经有方案,我们用 sqlparser-rs。
接下来就是如何把 CSV 或者其它数据源加载为 DataFrame。
做过数据处理或者使用过 pandas 的同学,应该对 DataFrame 并不陌生,它是一个矩阵数据结构,其中每一列可能包含不同的类型,可以在 DataFrame 上做过滤、投影和排序等操作。
在 Rust 下,我们可以用 polars ,来完成数据从 CSV 到 DataFrame 的加载和各种后续操作。
确定了这两个库之后,后续的工作就是:如何把 sqlparser 解析出来的抽象语法树 AST(Abstract Syntax Tree),映射到 polars 的 DataFrame 的操作上。
抽象语法树是用来描述复杂语法规则的工具,小到 SQL 或者某个 DSL,大到一门编程语言,其语言结构都可以通过 AST 来描述,如下图所示(来源: wikipedia):
如何在 SQL 语法和 DataFrame 的操作间进行映射呢?比如我们要从数据中选出三列显示,那这个 “select a, b, c” 就要能映射到 DataFrame 选取 a、b、c 三列输出。
polars 内部有自己的 AST 可以把各种操作聚合起来,最后一并执行。比如对于 “where a > 10 and b < 5”, Polars 的表达式是: col("a").gt(lit(10)).and(col("b").lt(lit(5)))。col 代表列,gt/lt 是大于/小于,lit 是字面量的意思。
有了这个认知,“对 CSV 等源进行 SQL 查询”核心要解决的问题变成了, 如何把一个 AST( SQL AST )转换成另一个 AST( DataFrame AST )。
等等,这不就是宏编程(对于 Rust 来说,是过程宏)做的事情么?因为进一步分析二者的数据结构,我们可以得到这样的对应关系:
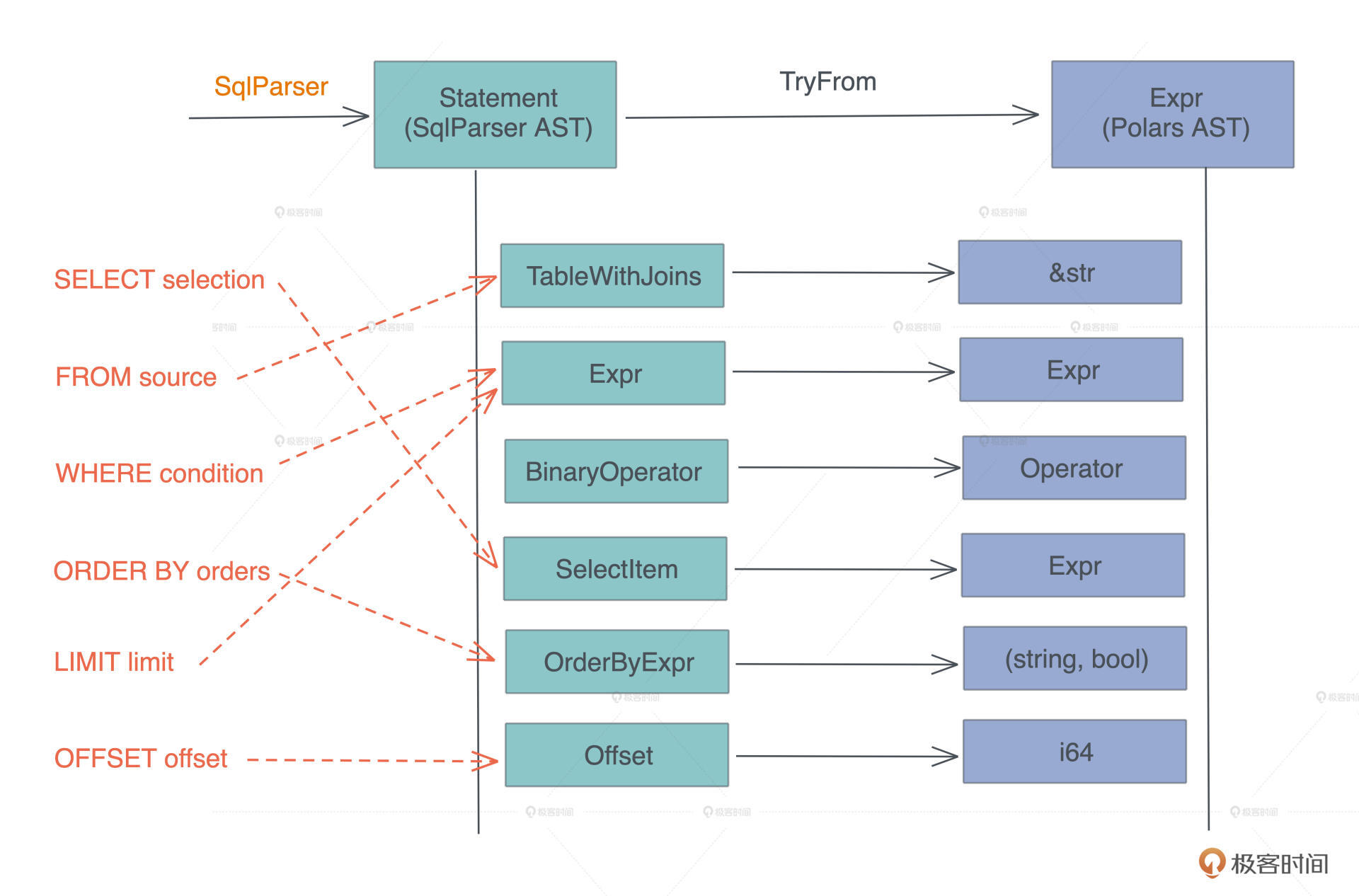
你看,我们要做的主要事情其实就是,在两个数据结构之间进行转换。所以,写完今天的代码,你肯定会对宏有足够的信心。
宏编程并没有什么大不了的,抛开 quote/unquote,它主要的工作就是把一棵语法树转换成另一颗语法树,而这个转换的过程深入下去,不过就是数据结构到数据结构的转换而已。所以一句话总结: 宏编程的主要流程就是实现若干 From 和 TryFrom,是不是很简单。
当然,这个转换的过程非常琐碎,如果语言本身没有很好的模式匹配能力,进行宏编程绝对是对自己非人道的折磨。
好在 Rust 有很棒的模式匹配支持,它虽然没有 Erlang/Elixir 的模式匹配那么强大,但足以秒杀绝大多数的编程语言。待会你在写的时候,能直观感受到。
创建一个 SQL 方言
好,分析完要做的事情,接下来就是按部就班写代码了。
我们用 cargo new queryer --lib 生成一个库。用 VSCode 打开生成的目录,创建和 src 平级的 examples,并在 Cargo.toml 中添加代码:
[[example]]
name = "dialect"
[dependencies]
anyhow = "1" # 错误处理,其实对于库我们应该用 thiserror,但这里简单起见就不节外生枝了
async-trait = "0.1" # 允许 trait 里有 async fn
sqlparser = "0.10" # SQL 解析器
polars = { version = "0.15", features = ["json", "lazy"] } # DataFrame 库
reqwest = { version = "0.11", default-features = false, features = ["rustls-tls"] } # 我们的老朋友 HTTP 客户端
tokio = { version = "1", features = ["fs"]} # 我们的老朋友异步库,我们这里需要异步文件处理
tracing = "0.1" # 日志处理
[dev-dependencies]
tracing-subscriber = "0.2" # 日志处理
tokio = { version = "1", features = ["full"]} # 在 example 下我们需要更多的 tokio feature
依赖搞定。因为对 sqlparser 的功能不太熟悉,这里写个 example 尝试一下,它会在 examples 目录下寻找 dialect.rs 文件。
所以,我们创建 examples/dialect.rs 文件,并写一些测试 sqlparser 的代码:
use sqlparser::{dialect::GenericDialect, parser::Parser}; fn main() { tracing_subscriber::fmt::init(); let sql = "SELECT a a1, b, 123, myfunc(b), * \ FROM data_source \ WHERE a > b AND b < 100 AND c BETWEEN 10 AND 20 \ ORDER BY a DESC, b \ LIMIT 50 OFFSET 10"; let ast = Parser::parse_sql(&GenericDialect::default(), sql); println!("{:#?}", ast); }
这段代码用一个 SQL 语句来测试 Parser::parse_sql 会输出什么样的结构。当你写库代码时,如果遇到不明白的第三方库,可以用撰写 example 这种方式先试一下。
我们运行 cargo run --example dialect 查看结果:
#![allow(unused)] fn main() { Ok([Query( Query { with: None, body: Select( Select { distinct: false, top: None, projection: [ ... ], from: [ TableWithJoins { ... } ], selection: Some(BinaryOp { ... }), ... } ), order_by: [ OrderByExpr { ... } ], limit: Some(Value( ... )), offset: Some(Offset { ... }) } ]) }
我把这个结构简化了一下,你在命令行里看到的,会远比这个复杂。
写到第9行这里,你有没有突发奇想, 如果 SQL 中的 FROM 子句后面可以接一个 URL 或者文件名该多好?这样,我们可以从这个 URL 或文件中读取数据。就像开头那个 “select * from ps” 的例子,把 ps 命令作为数据源,从它的输出中很方便地取数据。
但是普通的 SQL 语句是不支持这种写法的,不过 sqlparser 允许你创建自己的 SQL 方言,那我们就来尝试一下。
创建 src/dialect.rs 文件,添入下面的代码:
#![allow(unused)] fn main() { use sqlparser::dialect::Dialect; #[derive(Debug, Default)] pub struct TyrDialect; // 创建自己的 sql 方言。TyrDialect 支持 identifier 可以是简单的 url impl Dialect for TyrDialect { fn is_identifier_start(&self, ch: char) -> bool { ('a'..='z').contains(&ch) || ('A'..='Z').contains(&ch) || ch == '_' } // identifier 可以有 ':', '/', '?', '&', '=' fn is_identifier_part(&self, ch: char) -> bool { ('a'..='z').contains(&ch) || ('A'..='Z').contains(&ch) || ('0'..='9').contains(&ch) || [':', '/', '?', '&', '=', '-', '_', '.'].contains(&ch) } } /// 测试辅助函数 pub fn example_sql() -> String { let url = "https://raw.githubusercontent.com/owid/covid-19-data/master/public/data/latest/owid-covid-latest.csv"; let sql = format!( "SELECT location name, total_cases, new_cases, total_deaths, new_deaths \ FROM {} where new_deaths >= 500 ORDER BY new_cases DESC LIMIT 6 OFFSET 5", url ); sql } #[cfg(test)] mod tests { use super::*; use sqlparser::parser::Parser; #[test] fn it_works() { assert!(Parser::parse_sql(&TyrDialect::default(), &example_sql()).is_ok()); } } }
这个代码主要实现了 sqlparser 的 Dialect trait,可以重载 SQL 解析器判断标识符的方法。之后我们需要在 src/lib.rs 中添加
#![allow(unused)] fn main() { mod dialect; }
引入这个文件,最后也写了一个测试,你可以运行 cargo test 测试一下看看。
测试通过!现在我们可以正常解析出这样的 SQL 了:
SELECT * from https://abc.xyz/covid-cases.csv where new_deaths >= 500
Cool!你看,大约用了 10 行代码(第 7 行到第 19 行),通过添加可以让 URL 合法的字符,就实现了一个自己的支持 URL 的 SQL 方言解析。
为什么这么厉害?因为通过 trait,你可以很方便地做 控制反转(Inversion of Control),在 Rust 开发中,这是很常见的一件事情。
实现 AST 的转换
刚刚完成了SQL解析,接着就是用polars做AST转换了。
由于我们不太了解 polars 库,接下来还是先测试一下怎么用。创建 examples/covid.rs(记得在 Cargo.toml 中添加它哦),手工实现一个 DataFrame 的加载和查询:
use anyhow::Result; use polars::prelude::*; use std::io::Cursor; #[tokio::main] async fn main() -> Result<()> { tracing_subscriber::fmt::init(); let url = "https://raw.githubusercontent.com/owid/covid-19-data/master/public/data/latest/owid-covid-latest.csv"; let data = reqwest::get(url).await?.text().await?; // 使用 polars 直接请求 let df = CsvReader::new(Cursor::new(data)) .infer_schema(Some(16)) .finish()?; let filtered = df.filter(&df["new_deaths"].gt(500))?; println!( "{:?}", filtered.select(( "location", "total_cases", "new_cases", "total_deaths", "new_deaths" )) ); Ok(()) }
如果我们运行这个 example,可以得到一个打印得非常漂亮的表格,它从 GitHub 上的 owid-covid-latest.csv 文件中,读取并查询 new_deaths 大于 500 的国家和区域:
我们最终要实现的就是这个效果,通过解析一条做类似查询的 SQL,来进行相同的数据查询。怎么做呢?
今天一开始已经分析过了, 主要的工作就是把 sqlparser 解析出来的 AST 转换成 polars 定义的 AST。再回顾一下 SQL AST 的输出:
#![allow(unused)] fn main() { Ok([Query( Query { with: None, body: Select( Select { distinct: false, top: None, projection: [ ... ], from: [ TableWithJoins { ... } ], selection: Some(BinaryOp { ... }), ... } ), order_by: [ OrderByExpr { ... } ], limit: Some(Value( ... )), offset: Some(Offset { ... }) } ]) }
这里的 Query 是 Statement enum 其中一个结构。SQL 语句除了查询外,还有插入数据、删除数据、创建表等其他语句,我们今天不关心这些,只关心 Query。
所以,可以创建一个文件 src/convert.rs, 先定义一个数据结构 Sql 来描述两者的对应关系,然后再实现 Sql 的 TryFrom trait:
#![allow(unused)] fn main() { /// 解析出来的 SQL pub struct Sql<'a> { pub(crate) selection: Vec<Expr>, pub(crate) condition: Option<Expr>, pub(crate) source: &'a str, pub(crate) order_by: Vec<(String, bool)>, pub(crate) offset: Option<i64>, pub(crate) limit: Option<usize>, } impl<'a> TryFrom<&'a Statement> for Sql<'a> { type Error = anyhow::Error; fn try_from(sql: &'a Statement) -> Result<Self, Self::Error> { match sql { // 目前我们只关心 query (select ... from ... where ...) Statement::Query(q) => { ... } } } } }
框有了,继续写转换。我们看 Query 的结构:它有一个 body,是 Select 类型,其中包含 projection、from、select。在 Rust 里,我们可以用一个赋值语句,同时使用模式匹配加上数据的解构,将它们都取出来:
#![allow(unused)] fn main() { let Select { from: table_with_joins, selection: where_clause, projection, group_by: _, .. } = match &q.body { SetExpr::Select(statement) => statement.as_ref(), _ => return Err(anyhow!("We only support Select Query at the moment")), }; }
一句话,从匹配到取引用,再到将引用内部几个字段赋值给几个变量,都完成了,真是太舒服了!这样能够极大提高生产力的语言,你怎能不爱它?
我们再看一个处理 Offset 的例子,需要把 sqlparser 的 Offset 转换成 i64,同样,可以实现一个 TryFrom trait。这次是在 match 的一个分支上,做了数据结构的解构。
#![allow(unused)] fn main() { use sqlparser::ast::Offset as SqlOffset; // 因为 Rust trait 的孤儿规则,我们如果要想对已有的类型实现已有的 trait, // 需要简单包装一下 pub struct Offset<'a>(pub(crate) &'a SqlOffset); /// 把 SqlParser 的 offset expr 转换成 i64 impl<'a> From<Offset<'a>> for i64 { fn from(offset: Offset) -> Self { match offset.0 { SqlOffset { value: SqlExpr::Value(SqlValue::Number(v, _b)), .. } => v.parse().unwrap_or(0), _ => 0, } } } }
是的,数据的解构也可以在分支上进行,如果你还记得第三讲中谈到的 if let / while let,也是这个用法。这样对模式匹配的全方位支持,你用得越多,就会越感激 Rust 的作者,尤其在开发过程宏的时候。
从这段代码中还可以看到,定义的数据结构 Offset 使用了生命周期标注 <'a>,这是因为内部使用了 SqlOffset 的引用。有关生命周期的知识,我们很快就会讲到,这里你暂且不需要理解为什么要这么做。
整个 src/convert.rs 主要都是通过模式匹配,进行不同子类型之间的转换,代码比较无趣,而且和上面的代码类似,我就不贴了,你可以在这门课程的 GitHub repo 下的 06_queryer/queryer/src/convert.rs 中获取。
未来你在 Rust 下写过程宏(procedure macro),干的基本就是这个工作,只不过,最后你需要把转换后的 AST 使用 quote 输出成代码。在这个例子里,我们不需要这么做,polars 的 lazy 接口直接能处理 AST。
说句题外话,我之所以不厌其烦地讲述数据转换的这个过程,是因为它是我们编程活动中非常重要的部分。你想想,我们写代码,主要都在处理什么? 绝大多数处理逻辑都是把数据从一个接口转换成另一个接口。
以我们熟悉的用户注册流程为例:
- 用户的输入被前端校验后,转换成 CreateUser 对象,然后再转换成一个 HTTP POST 请求。
- 当这个请求到达服务器后,服务器将其读取,再转换成服务器的 CreateUser 对象,这个对象在校验和正规化(normalization)后被转成一个 ORM 对象(如果使用 ORM 的话),然后 ORM 对象再被转换成 SQL,发送给数据库服务器。
- 数据库服务器将 SQL 请求包装成一个 WAL(Write-Ahead Logging),这个 WAL 再被更新到数据库文件中。
整个数据转换过程如下图所示:
这样的处理流程,由于它和业务高度绑定,往往容易被写得很耦合,久而久之就变成了难以维护的意大利面条。 好的代码,应该是每个主流程都清晰简约,代码恰到好处地出现在那里,让人不需要注释也能明白作者在写什么。
这就意味着,我们要把那些并不重要的细节封装在单独的地方,封装的粒度以一次写完、基本不需要再变动为最佳,或者即使变动,它的影响也非常局部。
这样的代码,方便阅读、容易测试、维护简单,处理起来更是一种享受。Rust 标准库的 From / TryFrom trait ,就是出于这个目的设计的,非常值得我们好好使用。
从源中取数据
完成了 AST 的转换,接下来就是从源中获取数据。
我们通过对 Sql 结构的处理和填充,可以得到 SQL FROM 子句里的数据源,这个源,我们规定它必须是以 http(s):// 或者 file:// 开头的字符串。因为,以 http 开头我们可以通过 URL 获取内容,file 开头我们可以通过文件名,打开本地文件获取内容。
所以拿到了这个描述了数据源的字符串后,很容易能写出这样的代码:
#![allow(unused)] fn main() { /// 从文件源或者 http 源中获取数据 async fn retrieve_data(source: impl AsRef<str>) -> Result<String> { let name = source.as_ref(); match &name[..4] { // 包括 http / https "http" => Ok(reqwest::get(name).await?.text().await?), // 处理 file://<filename> "file" => Ok(fs::read_to_string(&name[7..]).await?), _ => Err(anyhow!("We only support http/https/file at the moment")), } } }
代码看起来很简单,但未来并不容易维护。因为一旦你的 HTTP 请求获得的结果需要做一些后续的处理,这个函数很快就会变得很复杂。那该怎么办呢?
如果你回顾前两讲我们写的代码,相信你心里马上有了答案: 可以用 trait 抽取 fetch 的逻辑,定义好接口,然后改变 retrieve_data 的实现。
所以下面是 src/fetcher.rs 的完整代码:
#![allow(unused)] fn main() { use anyhow::{anyhow, Result}; use async_trait::async_trait; use tokio::fs; // Rust 的 async trait 还没有稳定,可以用 async_trait 宏 #[async_trait] pub trait Fetch { type Error; async fn fetch(&self) -> Result<String, Self::Error>; } /// 从文件源或者 http 源中获取数据,组成 data frame pub async fn retrieve_data(source: impl AsRef<str>) -> Result<String> { let name = source.as_ref(); match &name[..4] { // 包括 http / https "http" => UrlFetcher(name).fetch().await, // 处理 file://<filename> "file" => FileFetcher(name).fetch().await, _ => return Err(anyhow!("We only support http/https/file at the moment")), } } struct UrlFetcher<'a>(pub(crate) &'a str); struct FileFetcher<'a>(pub(crate) &'a str); #[async_trait] impl<'a> Fetch for UrlFetcher<'a> { type Error = anyhow::Error; async fn fetch(&self) -> Result<String, Self::Error> { Ok(reqwest::get(self.0).await?.text().await?) } } #[async_trait] impl<'a> Fetch for FileFetcher<'a> { type Error = anyhow::Error; async fn fetch(&self) -> Result<String, Self::Error> { Ok(fs::read_to_string(&self.0[7..]).await?) } } }
这看上去似乎没有收益,还让代码变得更多。但它把 retrieve_data 和具体每一种类型的处理分离了,还是我们之前讲的思想,通过开闭原则,构建低耦合、高内聚的代码。这样未来我们修改 UrlFetcher 或者 FileFetcher,或者添加新的 Fetcher,对 retrieve_data 的变动都是最小的。
现在我们完成了SQL的解析、实现了从SQL到DataFrame的AST的转换,以及数据源的获取。挑战已经完成一大半了,就剩主流程逻辑了。
主流程
一般我们在做一个库的时候,不会把内部使用的数据结构暴露出去,而是会用自己的数据结构包裹它。
但这样代码有一个问题: 原有数据结构的方法,如果我们想暴露出去,每个接口都需要实现一遍,虽然里面的代码就是一句简单的 proxy,但还是很麻烦。这是我自己在使用很多语言的一个痛点。
正好在 queryer 库里也会有这个问题:SQL 查询后的结果,会放在一个 polars 的 DataFrame 中,但我们不想直接暴露这个 DataFrame 出去。因为一旦这么做,未来我们想加额外的 metadata,就无能为力了。
所以我定义了一个 DataSet,包裹住 DataFrame。可是,我还想暴露 DataSet 的接口,它有好多函数,总不能挨个 proxy 吧?
不用。Rust 提供了 Deref 和 DerefMut trait 做这个事情,它允许类型在解引用时,可以解引用到其它类型。我们后面在介绍 Rust 常用 trait 时,会详细介绍这两个 trait,现在先来看的 DataSet 怎么处理:
#![allow(unused)] fn main() { #[derive(Debug)] pub struct DataSet(DataFrame); /// 让 DataSet 用起来和 DataFrame 一致 impl Deref for DataSet { type Target = DataFrame; fn deref(&self) -> &Self::Target { &self.0 } } /// 让 DataSet 用起来和 DataFrame 一致 impl DerefMut for DataSet { fn deref_mut(&mut self) -> &mut Self::Target { &mut self.0 } } // DataSet 自己的方法 impl DataSet { /// 从 DataSet 转换成 csv pub fn to_csv(&self) -> Result<String> { ... } } }
可以看到,DataSet 在解引用时,它的 Target 是 DataFrame,这样 DataSet 在用户使用时,就和 DataFrame 一致了;我们还为 DataSet 实现了 to_csv 方法,可以把查询结果生成出 CSV。
好,定义好 DataSet,核心函数 query 实现起来其实很简单:先解析出我们要的 Sql 结构,然后从 source 中读入一个 DataSet,做 filter / order_by / offset / limit / select 等操作,最后返回 DataSet。
DataSet 的定义和 query 函数都在 src/lib.rs,它的完整代码如下:
#![allow(unused)] fn main() { use anyhow::{anyhow, Result}; use polars::prelude::*; use sqlparser::parser::Parser; use std::convert::TryInto; use std::ops::{Deref, DerefMut}; use tracing::info; mod convert; mod dialect; mod loader; mod fetcher; use convert::Sql; use loader::detect_content; use fetcher::retrieve_data; pub use dialect::example_sql; pub use dialect::TyrDialect; #[derive(Debug)] pub struct DataSet(DataFrame); /// 让 DataSet 用起来和 DataFrame 一致 impl Deref for DataSet { type Target = DataFrame; fn deref(&self) -> &Self::Target { &self.0 } } /// 让 DataSet 用起来和 DataFrame 一致 impl DerefMut for DataSet { fn deref_mut(&mut self) -> &mut Self::Target { &mut self.0 } } impl DataSet { /// 从 DataSet 转换成 csv pub fn to_csv(&self) -> Result<String> { let mut buf = Vec::new(); let writer = CsvWriter::new(&mut buf); writer.finish(self)?; Ok(String::from_utf8(buf)?) } } /// 从 from 中获取数据,从 where 中过滤,最后选取需要返回的列 pub async fn query<T: AsRef<str>>(sql: T) -> Result<DataSet> { let ast = Parser::parse_sql(&TyrDialect::default(), sql.as_ref())?; if ast.len() != 1 { return Err(anyhow!("Only support single sql at the moment")); } let sql = &ast[0]; // 整个 SQL AST 转换成我们定义的 Sql 结构的细节都埋藏在 try_into() 中 // 我们只需关注数据结构的使用,怎么转换可以之后需要的时候才关注,这是 // 关注点分离,是我们控制软件复杂度的法宝。 let Sql { source, condition, selection, offset, limit, order_by, } = sql.try_into()?; info!("retrieving data from source: {}", source); // 从 source 读入一个 DataSet // detect_content,怎么 detect 不重要,重要的是它能根据内容返回 DataSet let ds = detect_content(retrieve_data(source).await?).load()?; let mut filtered = match condition { Some(expr) => ds.0.lazy().filter(expr), None => ds.0.lazy(), }; filtered = order_by .into_iter() .fold(filtered, |acc, (col, desc)| acc.sort(&col, desc)); if offset.is_some() || limit.is_some() { filtered = filtered.slice(offset.unwrap_or(0), limit.unwrap_or(usize::MAX)); } Ok(DataSet(filtered.select(selection).collect()?)) } }
在 query 函数的主流程中,整个 SQL AST 转换成了我们定义的 Sql 结构,细节都埋藏在 try_into() 中,我们只需关注数据结构 Sql 的使用,怎么转换之后需要的时候再关注。
这就是 关注点分离(Separation of Concerns),是我们控制软件复杂度的法宝。Rust 标准库中那些经过千锤百炼的 trait,就是用来帮助我们写出更好的、复杂度更低的代码。
主流程里有个 detect_content 函数,它可以识别文本内容,选择相应的加载器把文本加载为 DataSet,因为目前只支持 CSV,但未来可以支持 JSON 等其他格式。这个函数定义在 src/loader.rs 里,我们创建这个文件,并添入下面的代码:
#![allow(unused)] fn main() { use crate::DataSet; use anyhow::Result; use polars::prelude::*; use std::io::Cursor; pub trait Load { type Error; fn load(self) -> Result<DataSet, Self::Error>; } #[derive(Debug)] #[non_exhaustive] pub enum Loader { Csv(CsvLoader), } #[derive(Default, Debug)] pub struct CsvLoader(pub(crate) String); impl Loader { pub fn load(self) -> Result<DataSet> { match self { Loader::Csv(csv) => csv.load(), } } } pub fn detect_content(data: String) -> Loader { // TODO: 内容检测 Loader::Csv(CsvLoader(data)) } impl Load for CsvLoader { type Error = anyhow::Error; fn load(self) -> Result<DataSet, Self::Error> { let df = CsvReader::new(Cursor::new(self.0)) .infer_schema(Some(16)) .finish()?; Ok(DataSet(df)) } } }
同样,通过 trait,我们虽然目前只支持 CsvLoader,但保留了为未来添加更多 Loader 的接口。
好,现在这个库就全部写完了,尝试编译一下。如果遇到了问题,不要着急,可以在这门课的 GitHub repo 里获取完整的代码,然后对应修改你本地的错误。
如果代码编译通过了,你可以修改之前的 examples/covid.rs,使用 SQL 来查询测试一下:
use anyhow::Result; use queryer::query; #[tokio::main] async fn main() -> Result<()> { tracing_subscriber::fmt::init(); let url = "https://raw.githubusercontent.com/owid/covid-19-data/master/public/data/latest/owid-covid-latest.csv"; // 使用 sql 从 URL 里获取数据 let sql = format!( "SELECT location name, total_cases, new_cases, total_deaths, new_deaths \ FROM {} where new_deaths >= 500 ORDER BY new_cases DESC", url ); let df1 = query(sql).await?; println!("{:?}", df1); Ok(()) }
Bingo!一切正常,我们完成了,用 SQL 语句请求网络上的某个 CSV ,并对 CSV 做查询和排序,返回结果的正确无误!
用 tokei 查看代码行数,可以看到,用了 375 行,远低于 500 行的目标!
❯ tokei src/
-------------------------------------------------------------------------------
Language Files Lines Code Comments Blanks
-------------------------------------------------------------------------------
Rust 5 466 375 22 69
-------------------------------------------------------------------------------
Total 5 466 375 22 69
-------------------------------------------------------------------------------
在这么小的代码量下,我们在架构上做了很多为解耦考虑的工作:整个架构被拆成了 Sql Parser、Fetcher、Loader 和 query 四个部分。
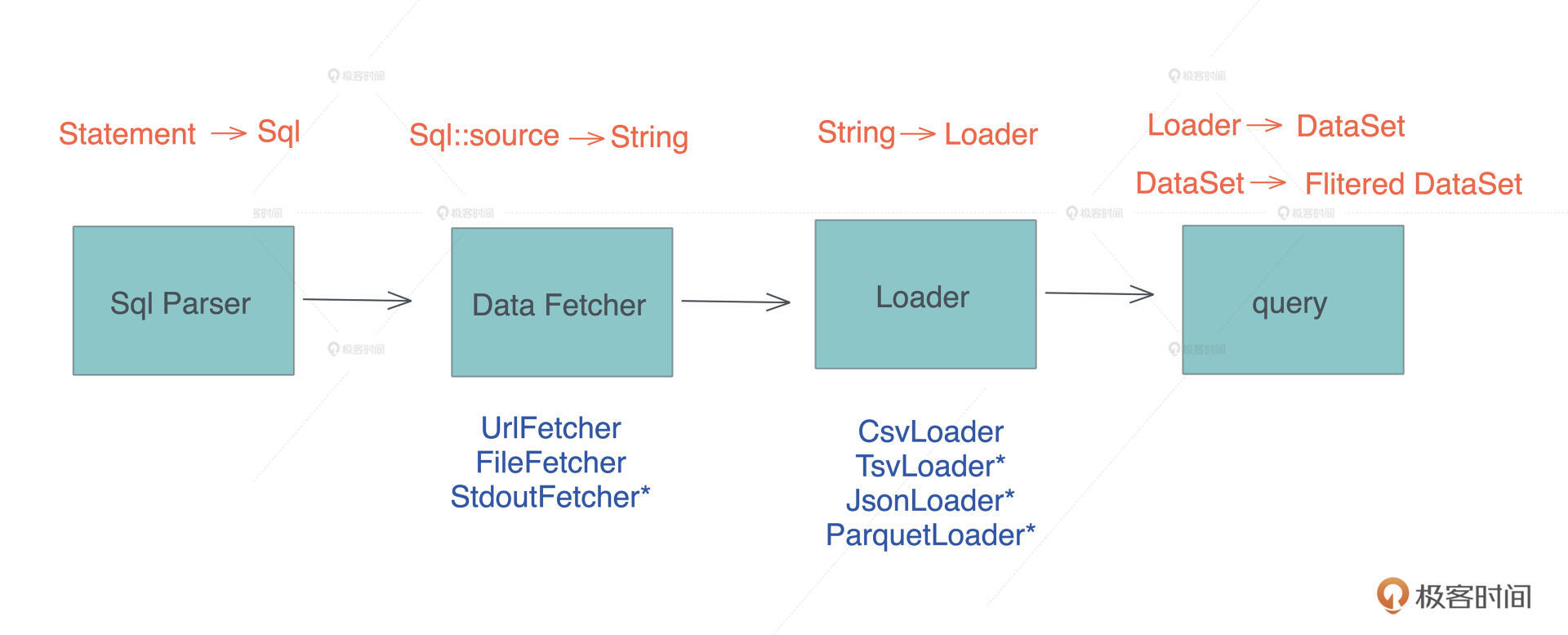
其中未来可能存在变化的 Fetcher 和 Loader 可以轻松扩展,比如我们一开始提到的那个 “select * from ps”,可以用一个 StdoutFetcher 和 TsvLoader 来处理。
支持其它语言
现在我们的核心代码写完了,有没有感觉自己成就感爆棚,实现的queryer工具可以在 Rust 下作为一个库,提供给其它 Rust 程序用,这很美妙。
但我们的故事还远不止如此。这么牛的功能,只能 Rust 程序员享用,太暴殄天物了。毕竟独乐乐不如众乐乐。所以,我们来试着 将它集成到其它语言,比如常用的 Node.js/Python。
Node.js/Python 中有很多高性能的代码,都是 C/C++ 写的,但跨语言调用往往涉及繁杂的接口转换代码,所以用 C/C++ ,写这些接口转换的时候非常痛苦。
我们看看如果用 Rust 的话,能否避免这些繁文缛节?毕竟,我们对使用 Rust ,为其它语言提供高性能代码,有很高的期望,如果这个过程也很复杂,那怎么用得起来?
对于 queryer 库,我们想暴露出来的主要接口是:query,用户传入一个 SQL 字符串和一个输出类型的字符串,返回一个按照 SQL 查询处理过的、符合输出类型的字符串。比如对 Python 来说,就是下面的接口:
def query(sql, output = 'csv')
好,我们来试试看。
先创建一个新的目录 queryer 作为 workspace,把现有的 queryer 移进去,成为它的子目录。然后,我们创建一个 Cargo.toml,包含以下代码:
[workspace]
members = [
"queryer",
"queryer-py"
]
Python
我们在 workspace 的根目录下, cargo new queryer-py --lib ,生成一个新的 crate。在 queryer-py 下,编辑 Cargo.toml:
[package]
name = "queryer_py" # Python 模块需要用下划线
version = "0.1.0"
edition = "2018"
[lib]
crate-type = ["cdylib"] # 使用 cdylib 类型
[dependencies]
queryer = { path = "../queryer" } # 引入 queryer
tokio = { version = "1", features = ["full"] }
[dependencies.pyo3] # 引入 pyo3
version = "0.14"
features = ["extension-module"]
[build-dependencies]
pyo3-build-config = "0.14"
Rust 和 Python 交互的库是 pyo3,感兴趣你可以课后看它的文档。在 src/lib.rs 下,添入如下代码:
#![allow(unused)] fn main() { use pyo3::{exceptions, prelude::*}; #[pyfunction] pub fn example_sql() -> PyResult<String> { Ok(queryer::example_sql()) } #[pyfunction] pub fn query(sql: &str, output: Option<&str>) -> PyResult<String> { let rt = tokio::runtime::Runtime::new().unwrap(); let data = rt.block_on(async { queryer::query(sql).await.unwrap() }); match output { Some("csv") | None => Ok(data.to_csv().unwrap()), Some(v) => Err(exceptions::PyTypeError::new_err(format!( "Output type {} not supported", v ))), } } #[pymodule] fn queryer_py(_py: Python, m: &PyModule) -> PyResult<()> { m.add_function(wrap_pyfunction!(query, m)?)?; m.add_function(wrap_pyfunction!(example_sql, m)?)?; Ok(()) } }
即使我不解释这些代码,你也基本能明白它在干嘛。我们为 Python 模块提供了两个接口 example_sql 和 query。
接下来在 queryer-py 目录下,创建 virtual env,然后用 maturin develop 构建 python 模块:
python3 -m venv .env
source .env/bin/activate
pip install maturin ipython
maturin develop
构建完成后,可以用 ipython 测试:
In [1]: import queryer_py
In [2]: sql = queryer_py.example_sql()
In [3]: print(queryer_py.query(sql, 'csv'))
name,total_cases,new_cases,total_deaths,new_deaths
India,32649947.0,46759.0,437370.0,509.0
Iran,4869414.0,36279.0,105287.0,571.0
Africa,7695475.0,33957.0,193394.0,764.0
South America,36768062.0,33853.0,1126593.0,1019.0
Brazil,20703906.0,27345.0,578326.0,761.0
Mexico,3311317.0,19556.0,257150.0,863.0
In [4]: print(queryer_py.query(sql, 'json'))
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-4-7082f1ffe46a> in <module>
----> 1 print(queryer_py.query(sql, 'json'))
TypeError: Output type json not supported
Cool!仅仅写了 20 行代码,就让我们的模块可以被 Python 调用,错误处理也很正常。你看,在用 Rust 库的基础上,我们稍微写一些辅助代码,就能够让它和不同的语言集成起来。我觉得这是 Rust 非常有潜力的使用方向。
毕竟,对很多公司来说,原有的代码库想要完整迁移到 Rust 成本很大,但是通过 Rust 和各个语言轻便地集成,可以把部分需要高性能的代码迁移到 Rust,尝到甜头,再一点点推广。这样,Rust 就能应用起来了。
小结
回顾这周的 Rust 代码之旅,我们先做了个 HTTPie,流程简单,青铜级难度,你学完所有权,理解了基本的 trait 后就能写。
之后的 Thumbor,引入了异步、泛型和更多的 trait,白银级难度,在你学完类型系统,对异步稍有了解后,应该可以搞定。
今天的 Queryer,使用了大量的 trait ,来让代码结构足够符合开闭原则和关注点分离,用了不少生命周期标注,来减少不必要的内存拷贝,还做了不少复杂的模式匹配来获取数据,是黄金级难度,在学完本课程的进阶篇后,你应该可以理解这些代码。
很多人觉得 Rust 代码很难写,尤其是泛型数据结构和生命周期搅在一起的时候。但在前两个例子里,生命周期的标注只出现过了一次。所以, 其实大部分时候,你的代码并不需要复杂的生命周期标注。
只要对所有权和生命周期的理解没有问题,如果你陷入了无休止的生命周期标注,和编译器痛苦地搏斗,那你也许要停下来先想一想:
编译器如此不喜欢我的写法,会不会我的设计本身就有问题呢?我是不是该使用更好的数据结构?我是不是该重新设计一下?我的代码是不是过度耦合了?
就像茴香豆的茴字有四种写法一样,同一个需求,用相同的语言,不同的人也会有不同的写法。但是, 优秀的设计一定是产生简单易读的代码,而不是相反。
好,这周的代码之旅就告一段落了,接下来我们就要展开一段壮丽的探险,你将会像比尔博·巴金斯那样,在通往孤山的冒险之旅中,一点点探索迷人的中土世界。等到我们学完了所有权、类型系统、trait、智能指针等内容之后,再来看这三个实例,相信你会有不一样的感悟。我也会在后续的课程中,根据已学内容,回顾今天写的代码,继续优化和完善它们。
思考题
Node.js 的处理和 Python 非常类似,但接口不太一样,就作为今天的思考题让你尝试一下。小提示:Rust 和 nodejs 间交互可以使用 neon。
欢迎在留言区分享你的思考。你的 Rust 学习第六次打卡成功,我们下一讲见!
参考资料
我们的 queryer 库目前使用到了操作系统的功能,比如文件系统,所以它无法被编译成 WebAssembly。未来如果能移除对操作系统的依赖,这个代码还能被编译成 WASM,供 Web 前端使用。
如果想在 iOS/Android 下使用这个库,可以用类似 Python/Node.js 的方法做接口封装,Mozilla 提供了一个 uniffi 的库,它自己的 Firefox 各个端也是这么处理的:
对于桌面开发,Rust 下有一个很有潜力的客户端开发工具 tauri,它很有机会取代很多使用 Electron 的场合。
我写了一个简单的 tuari App 叫 data-viewer,如果你感兴趣的话,可以在 github repo 下的 data-viewer 目录下看 tauri 使用 queryer 的代码,下面是运行后的效果。为了让代码最简单,前端没有用任何框架,如果你是一名前端开发者,可以用 Vue 或者 React 加上一个合适的 CSS 库让整个界面变得更加友好。
所有权:值的生杀大权到底在谁手上?
你好,我是陈天。
完成了上周的“get hands dirty”挑战,相信你对 Rust 的魅力已经有了感性的认知,是不是开始信心爆棚地尝试写小项目了。
但当你写的代码变多,编译器似乎开始和自己作对了,一些感觉没有问题的代码,编译器却总是莫名其妙报错。
那么从今天起我们重归理性,一起来研究 Rust 学习过程中最难啃的硬骨头:所有权和生命周期。为什么要从这个知识点开始呢?因为, 所有权和生命周期是 Rust 和其它编程语言的主要区别,也是 Rust 其它知识点的基础。
很多 Rust 初学者在这个地方没弄明白,一知半解地继续学习,结果越学越吃力,最后在实际上手写代码的时候就容易栽跟头,编译总是报错,丧失了对 Rust 的信心。
其实所有权和生命周期之所以这么难学明白,除了其与众不同的解决内存安全问题的角度外,另一个很大的原因是,目前的资料对初学者都不友好,上来就讲 Copy / Move 语义怎么用,而没有讲明白 为什么要这样用。
所以这一讲我们换个思路,从一个变量使用堆栈的行为开始,探究 Rust 设计所有权和生命周期的用意,帮你从根上解决这些编译问题。
变量在函数调用时发生了什么
首先,我们来看一看,在我们熟悉的大多数编程语言中,变量在函数调用时究竟会发生什么、存在什么问题。
看这段代码,main() 函数中定义了一个动态数组 data 和一个值 v,然后将其传递给函数 find_pos,在 data 中查找 v 是否存在,存在则返回 v 在 data 中的下标,不存在返回 None( 代码1):
fn main() { let data = vec![10, 42, 9, 8]; let v = 42; if let Some(pos) = find_pos(data, v) { println!("Found {} at {}", v, pos); } } fn find_pos(data: Vec<u32>, v: u32) -> Option<usize> { for (pos, item) in data.iter().enumerate() { if *item == v { return Some(pos); } } None }
这段代码不难理解,要再强调一下的是, 动态数组因为大小在编译期无法确定,所以放在堆上,并且在栈上有一个包含了长度和容量的胖指针指向堆上的内存。
在调用 find_pos() 时,main() 函数中的局部变量 data 和 v 作为参数传递给了 find_pos(),所以它们会被放在 find_pos() 的参数区。
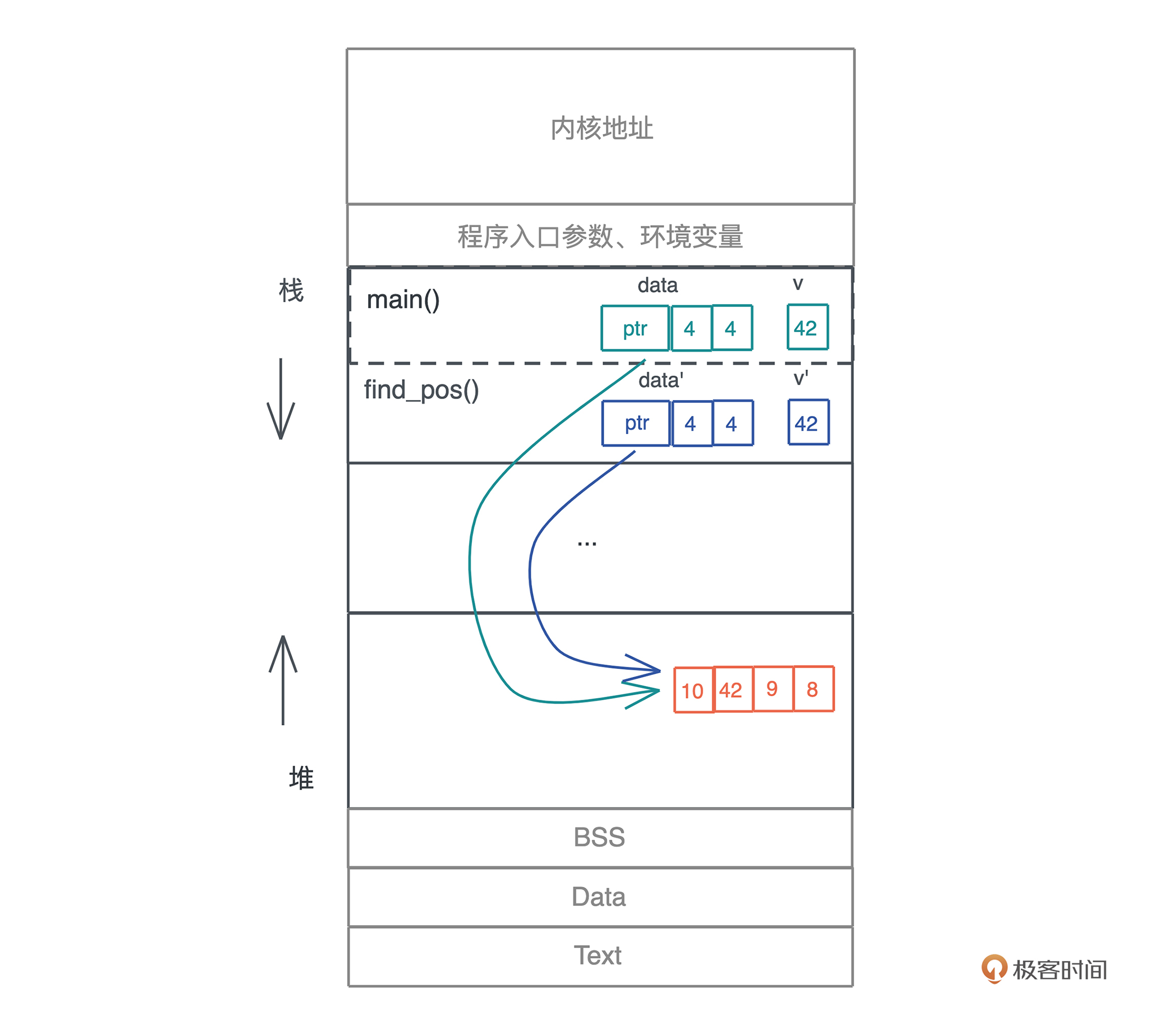
按照大多数编程语言的做法,现在堆上的内存就有了两个引用。不光如此,我们每把 data 作为参数传递一次,堆上的内存就会多一次引用。
但是,这些引用究竟会做什么操作,我们不得而知,也无从限制;而且堆上的内存究竟什么时候能释放,尤其在多个调用栈引用时,很难厘清,取决于最后一个引用什么时候结束。所以,这样一个看似简单的函数调用,给内存管理带来了极大麻烦。
对于堆内存多次引用的问题,我们先来看大多数语言的方案:
- C/C++ 要求开发者手工处理,非常不便。这需要我们在写代码时高度自律,按照前人总结的最佳实践来操作。但人必然会犯错,一个不慎就会导致内存安全问题,要么内存泄露,要么使用已释放内存,导致程序崩溃。
- Java 等语言使用追踪式 GC,通过定期扫描堆上数据还有没有人引用,来替开发者管理堆内存,不失为一种解决之道,但 GC 带来的 STW 问题让语言的使用场景受限,性能损耗也不小。
- ObjC/Swift 使用自动引用计数(ARC),在编译时自动添加维护引用计数的代码,减轻开发者维护堆内存的负担。但同样地,它也会有不小的运行时性能损耗。
现存方案都是从管理引用的角度思考的,有各自的弊端。我们回顾刚才梳理的函数调用过程,从源头上看,本质问题是堆上内存会被随意引用,那么换个角度,我们是不是可以限制引用行为本身呢?
Rust 的解决思路
这个想法打开了新的大门,Rust就是这样另辟蹊径的。
在 Rust 以前,引用是一种随意的、可以隐式产生的、对权限没有界定的行为,比如 C 里到处乱飞的指针、Java 中随处可见的按引用传参,它们可读可写,权限极大。而 Rust 决定限制开发者随意引用的行为。
其实作为开发者,我们在工作中常常能体会到: 恰到好处的限制,反而会释放无穷的创意和生产力。最典型的就是各种开发框架,比如 React、Ruby on Rails 等,他们限制了开发者使用语言的行为,却极大地提升了生产力。
好,思路我们已经有了,具体怎么实现来限制数据的引用行为呢?
要回答这个问题,我们需要先来回答:谁真正拥有数据或者说值的生杀大权,这种权利可以共享还是需要独占?
所有权和 Move 语义
照旧我们先尝试回答一下,对于值的生杀大权可以共享还是需要独占这一问题,我们大概都会觉得,一个值最好只有一个拥有者,因为所有权共享,势必会带来使用和释放上的不明确,走回 追踪式 GC 或者 ARC 的老路。
那么如何保证独占呢?具体实现其实是有些困难的,因为太多情况需要考虑。比如说一个变量被赋给另一个变量、作为参数传给另一个函数,或者作为返回值从函数返回,都可能造成这个变量的拥有者不唯一。怎么办?
对此,Rust 给出了如下规则:
- 一个值只能被一个变量所拥有,这个变量被称为所有者(Each value in Rust has a variable that’s called its owner)。
- 一个值同一时刻只能有一个所有者(There can only be one owner at a time),也就是说不能有两个变量拥有相同的值。所以对应刚才说的变量赋值、参数传递、函数返回等行为,旧的所有者会把值的所有权转移给新的所有者,以便保证单一所有者的约束。
- 当所有者离开作用域,其拥有的值被丢弃(When the owner goes out of scope, the value will be dropped),内存得到释放。
这三条规则很好理解,核心就是保证单一所有权。其中第二条规则讲的所有权转移是 Move 语义,Rust 从 C++ 那里学习和借鉴了这个概念。
第三条规则中的作用域(scope)是一个新概念,我简单说明一下,它指一个代码块(block),在 Rust 中,一对花括号括起来的代码区就是一个作用域。举个例子,如果一个变量被定义在 if {} 内,那么 if 语句结束,这个变量的作用域就结束了,其值会被丢弃;同样的,函数里定义的变量,在离开函数时会被丢弃。
在这三条所有权规则的约束下,我们看开头的引用问题是如何解决的:
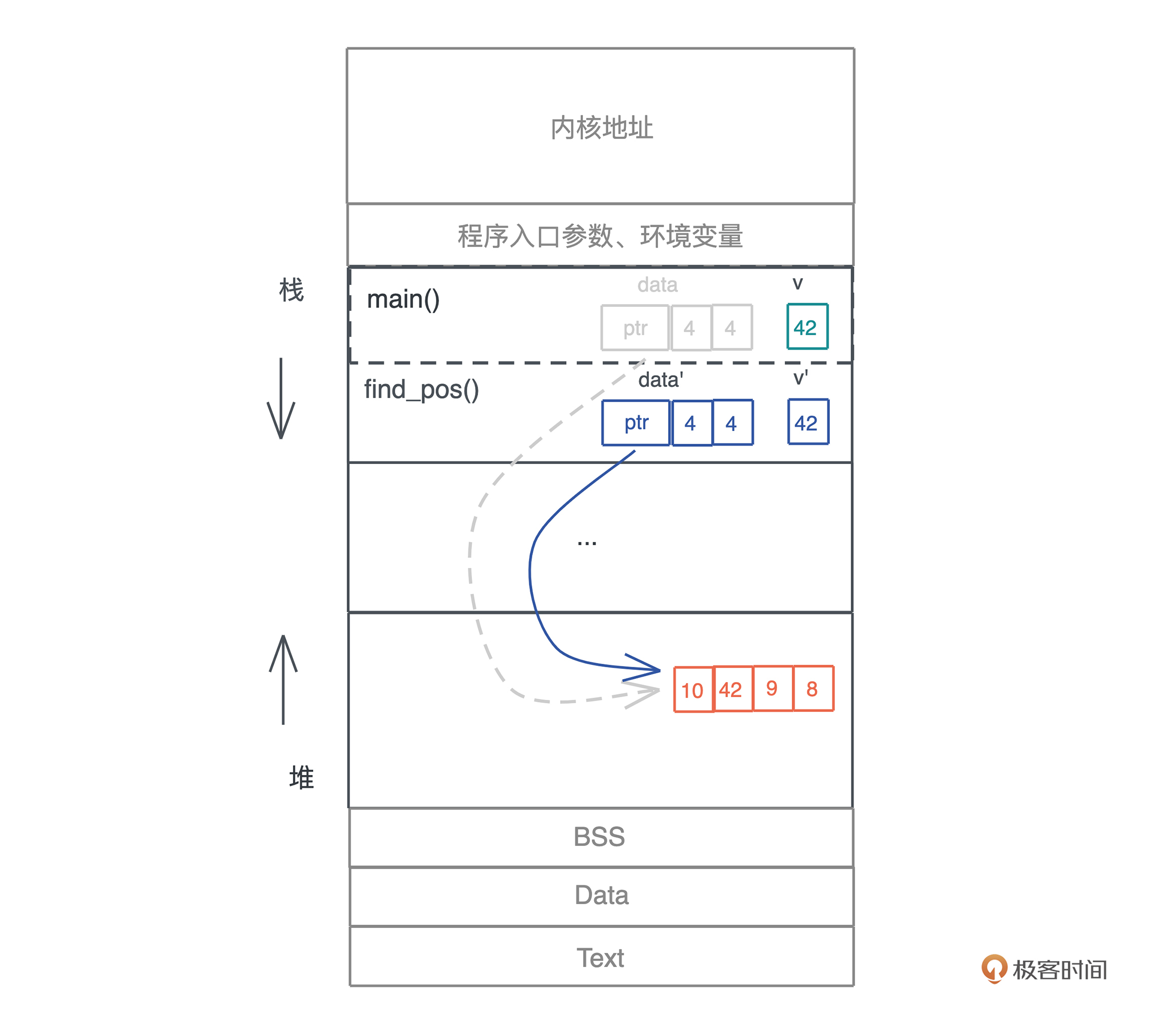
原先 main() 函数中的 data,被移动到 find_pos() 后,就失效了,编译器会保证 main() 函数随后的代码无法访问这个变量,这样,就确保了堆上的内存依旧只有唯一的引用。
看这个图,你可能会有一个小小的疑问:main() 函数传递给 find_pos() 函数的另一个参数 v,也会被移动吧?为什么图上并没有标灰?咱们暂且将这个疑问放到一边,等这一讲学完,相信你会有答案的。
现在,我们来写段代码加深一下对所有权的理解。
在这段代码里,先创建了一个不可变数据 data,然后将 data 赋值给 data1。按照所有权的规则,赋值之后,data 指向的值被移动给了 data1,它自己便不可访问了。而随后,data1 作为参数被传给函数 sum(),在 main() 函数下,data1 也不可访问了。
但是后续的代码依旧试图访问 data1 和 data,所以,这段代码应该会有两处错误( 代码2):
fn main() { let data = vec![1, 2, 3, 4]; let data1 = data; println!("sum of data1: {}", sum(data1)); println!("data1: {:?}", data1); // error1 println!("sum of data: {}", sum(data)); // error2 } fn sum(data: Vec<u32>) -> u32 { data.iter().fold(0, |acc, x| acc + x) }
运行时,编译器也确实捕获到了这两个错误,并清楚地告诉我们不能使用已经移动过的变量:
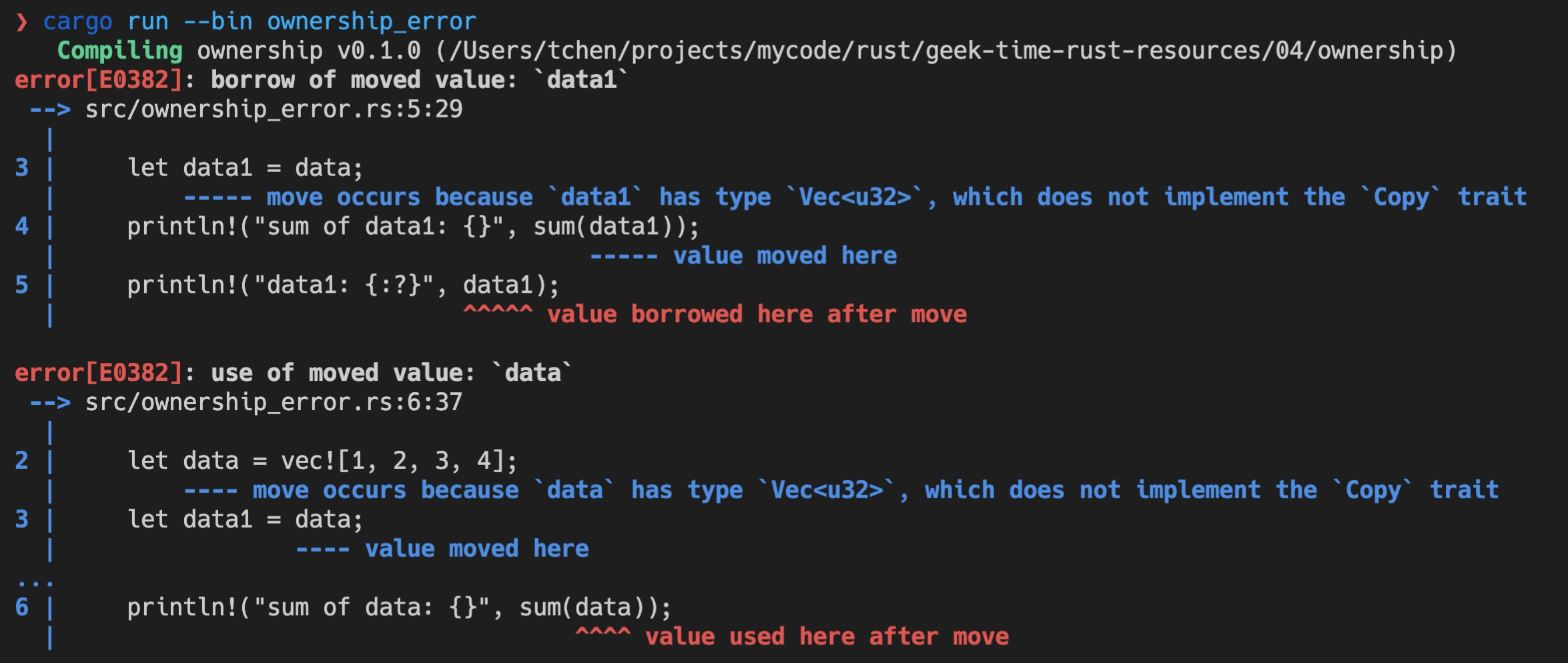
如果我们要在把 data1 传给 sum(),同时,还想让 main() 能够访问 data,该怎么办?
我们可以调用 data.clone() 把 data 复制一份出来给 data1,这样,在堆上就有 vec![1,2,3,4] 两个互不影响且可以独立释放的副本,如下图所示:
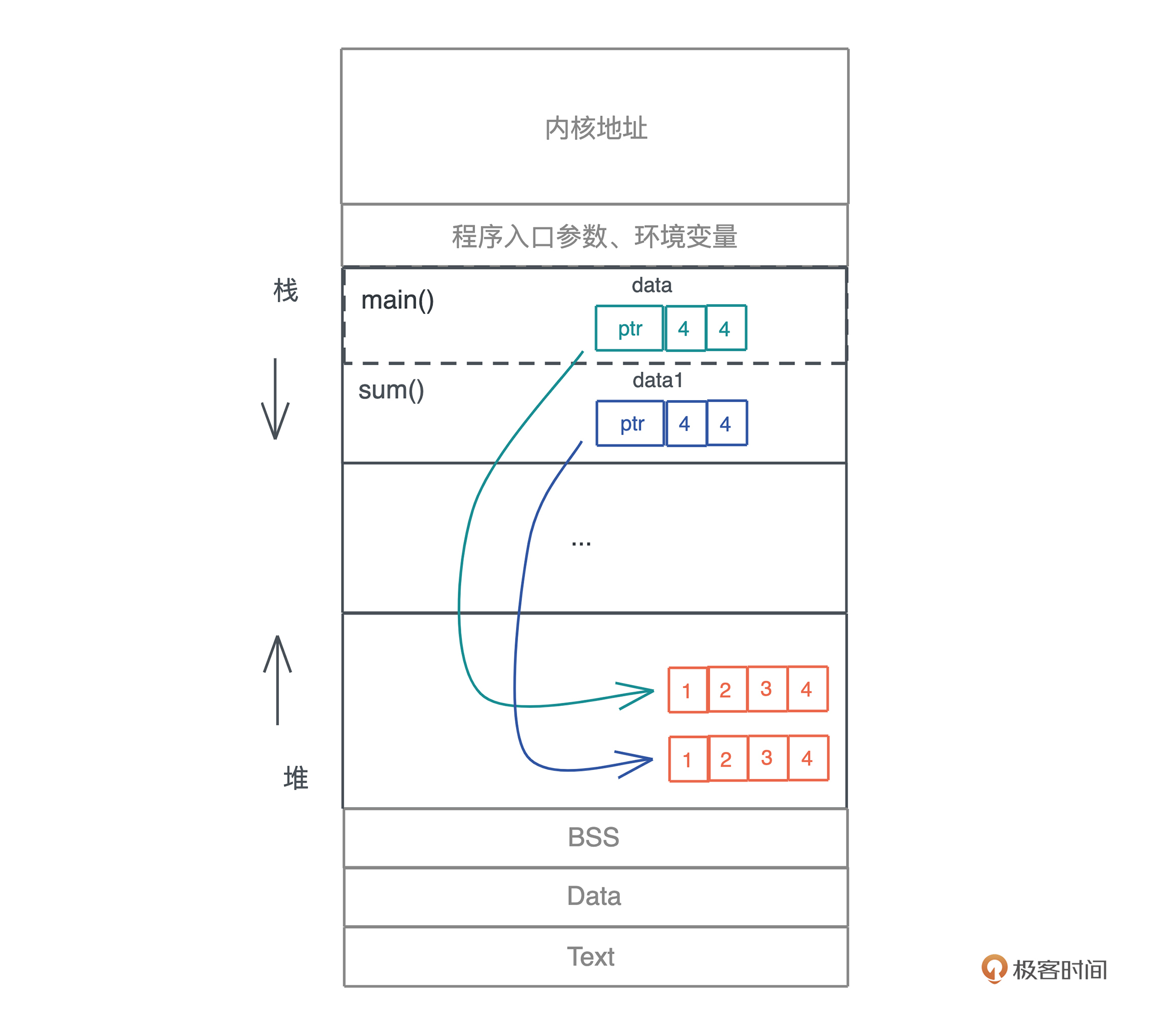
可以看到, 所有权规则,解决了谁真正拥有数据的生杀大权问题,让堆上数据的多重引用不复存在,这是它最大的优势。
但是,这也会让代码变复杂,尤其是一些只存储在栈上的简单数据,如果要避免所有权转移之后不能访问的情况,我们就需要手动复制,会非常麻烦,效率也不高。
Rust 考虑到了这一点,提供了两种方案:
- 如果你不希望值的所有权被转移,在 Move 语义外,Rust 提供了 Copy 语义。如果一个数据结构实现了 Copy trait,那么它就会使用 Copy 语义。这样,在你赋值或者传参时,值会自动按位拷贝(浅拷贝)。
- 如果你不希望值的所有权被转移,又无法使用 Copy 语义,那你可以 “借用”数据,我们下一讲会详细讨论“借用”。
我们先看今天要讲的第一种方案:Copy 语义。
Copy 语义和 Copy trait
符合 Copy 语义的类型, 在你赋值或者传参时,值会自动按位拷贝。这句话不难理解,那在Rust中是具体怎么实现的呢?
我们再仔细看看刚才代码编译器给出的错误,你会发现,它抱怨 data 的类型 Vec<u32> 没有实现 Copy trait,在赋值或者函数调用的时候无法 Copy,于是就按默认使用 Move 语义。而 Move 之后,原先的变量 data 无法访问,所以出错。
换句话说,当你要移动一个值,如果值的类型实现了 Copy trait,就会自动使用 Copy 语义进行拷贝,否则使用 Move 语义进行移动。
讲到这里,我插一句,在学习 Rust 的时候,你可以根据编译器详细的错误说明来尝试修改代码,使编译通过,在这个过程中,你可以用 Stack Overflow 搜索错误信息,进一步学习自己不了解的知识点。我也非常建议你根据上图中的错误代码 E0382 使用 rustc --explain E0382 探索更详细的信息。
好,回归正文,那在 Rust 中,什么数据结构实现了 Copy trait 呢? 你可以通过下面的代码快速验证一个数据结构是否实现了 Copy trait( 验证代码):
fn is_copy<T: Copy>() {} fn types_impl_copy_trait() { is_copy::<bool>(); is_copy::<char>(); // all iXX and uXX, usize/isize, fXX implement Copy trait is_copy::<i8>(); is_copy::<u64>(); is_copy::<i64>(); is_copy::<usize>(); // function (actually a pointer) is Copy is_copy::<fn()>(); // raw pointer is Copy is_copy::<*const String>(); is_copy::<*mut String>(); // immutable reference is Copy is_copy::<&[Vec<u8>]>(); is_copy::<&String>(); // array/tuple with values which is Copy is Copy is_copy::<[u8; 4]>(); is_copy::<(&str, &str)>(); } fn types_not_impl_copy_trait() { // unsized or dynamic sized type is not Copy is_copy::<str>(); is_copy::<[u8]>(); is_copy::<Vec<u8>>(); is_copy::<String>(); // mutable reference is not Copy is_copy::<&mut String>(); // array / tuple with values that not Copy is not Copy is_copy::<[Vec<u8>; 4]>(); is_copy::<(String, u32)>(); } fn main() { types_impl_copy_trait(); types_not_impl_copy_trait(); }
推荐你动手运行这段代码,并仔细阅读编译器错误,加深印象。我也总结一下:
- 原生类型,包括函数、不可变引用和裸指针实现了 Copy;
- 数组和元组,如果其内部的数据结构实现了 Copy,那么它们也实现了 Copy;
- 可变引用没有实现 Copy;
- 非固定大小的数据结构,没有实现 Copy。
另外, 官方文档介绍 Copy trait 的页面 包含了 Rust 标准库中实现 Copy trait 的所有数据结构。你也可以在访问某个数据结构的时候,查看其文档的 Trait implementation 部分,看看它是否实现了 Copy trait。
小结
今天我们学习了 Rust 的单一所有权模式、Move 语义、Copy 语义,我整理一下关键信息,方便你再回顾一遍。
- 所有权:一个值只能被一个变量所拥有,且同一时刻只能有一个所有者,当所有者离开作用域,其拥有的值被丢弃,内存得到释放。
- Move 语义:赋值或者传参会导致值 Move,所有权被转移,一旦所有权转移,之前的变量就不能访问。
- Copy 语义:如果值实现了 Copy trait,那么赋值或传参会使用 Copy 语义,相应的值会被按位拷贝(浅拷贝),产生新的值。
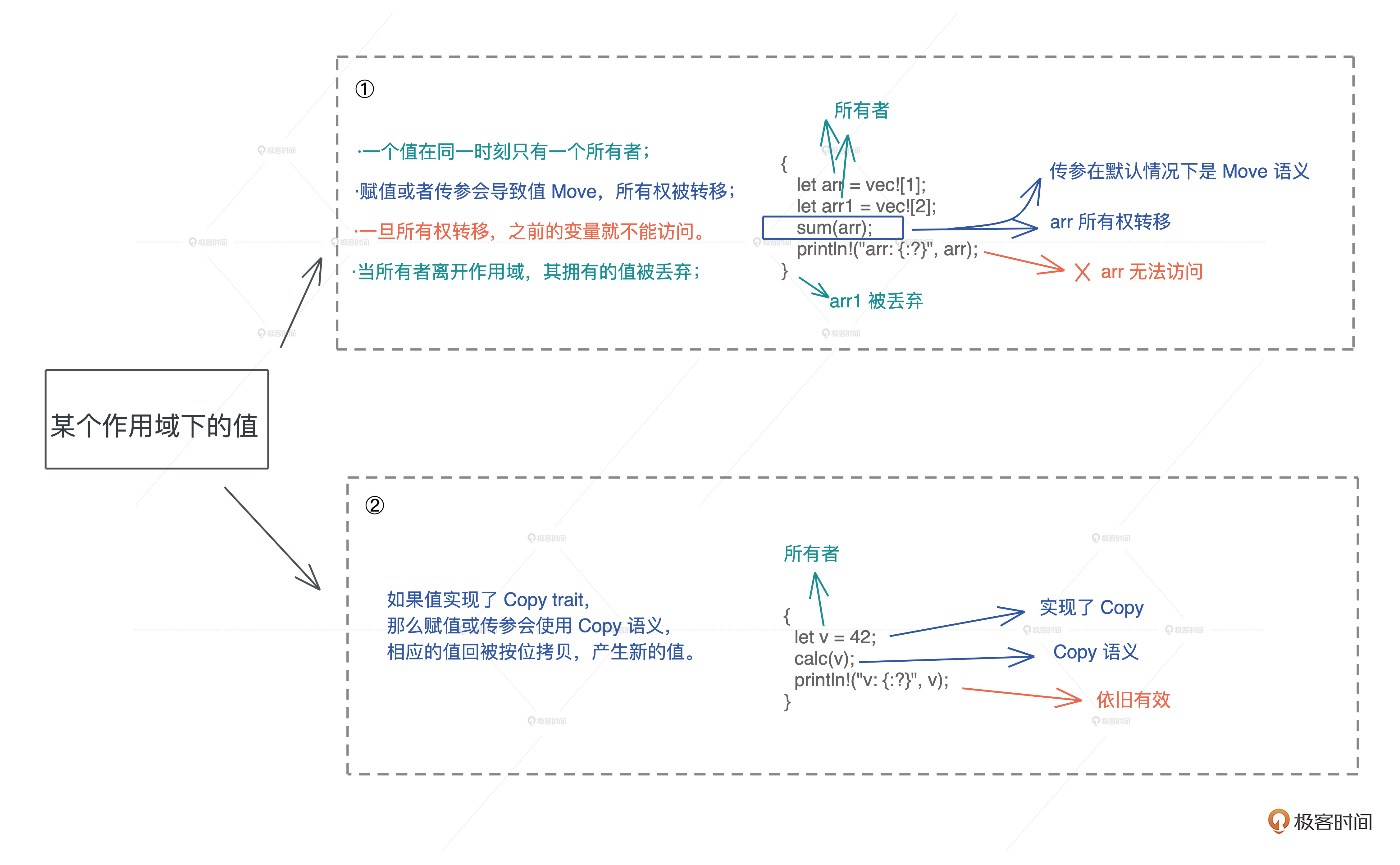
通过单一所有权模式,Rust 解决了堆内存过于灵活、不容易安全高效地释放的问题,不过所有权模型也引入了很多新的概念,比如今天讲的 Move / Copy 语义。
由于是全新的概念,我们学习起来有一定的难度,但是你只要抓住了核心点: Rust 通过单一所有权来限制任意引用的行为,就不难理解这些新概念背后的设计意义。
下一讲我们会继续学习Rust的所有权和生命周期,在不希望值的所有权被转移,又无法使用 Copy 语义的情况下,如何“借用”数据……
思考题
今天的思考题有两道,第一道题巩固学习收获。另外第二道题如果你还记得,在文中,我提出了一个小问题,让你暂时搁置,今天学完之后就有答案了,现在你有想法了吗?欢迎留言分享出来,我们一起讨论。
- 在 Rust 下,分配在堆上的数据结构可以引用栈上的数据么?为什么?
- main() 函数传递给 find_pos() 函数的另一个参数 v,也会被移动吧?为什么图上并没有将其标灰?
欢迎在留言区分享你的思考。今天是你 Rust 学习的第七次打卡,感谢你的收听,如果你觉得有收获,也欢迎你分享给身边的朋友,邀他一起讨论。
参考资料
trait 是 Rust 用于定义数据结构行为的接口。如果一个数据结构实现了 Copy trait,那么它在赋值、函数调用以及函数返回时会执行 Copy 语义,值会被按位拷贝一份(浅拷贝),而非移动。你可以看关于 Copy trait 的资料。
所有权:值的借用是如何工作的?
你好,我是陈天。
上一讲我们学习了 Rust 所有权的基本规则,在 Rust 下,值有单一的所有者。
当我们进行变量赋值、传参和函数返回时,如果涉及的数据结构没有实现 Copy trait,就会默认使用 Move 语义转移值的所有权,失去所有权的变量将无法继续访问原来的数据;如果数据结构实现了 Copy trait,就会使用 Copy 语义,自动把值复制一份,原有的变量还能继续访问。
虽然,单一所有权解决了其它语言中值被任意共享带来的问题,但也引发了一些不便。我们上一讲提到: 当你不希望值的所有权被转移,又因为没有实现 Copy trait 而无法使用 Copy 语义,怎么办?你可以“借用”数据,也就是这一讲我们要继续介绍的 Borrow 语义。
Borrow 语义
顾名思义,Borrow 语义允许一个值的所有权,在不发生转移的情况下,被其它上下文使用。就好像住酒店或者租房那样,旅客/租客只有房间的临时使用权,但没有它的所有权。另外,Borrow 语义通过引用语法(& 或者 &mut)来实现。
看到这里,你是不是有点迷惑了,怎么引入了一个“借用”的新概念,但是又写“引用”语法呢?
其实, 在 Rust 中,“借用”和“引用”是一个概念,只不过在其他语言中引用的意义和 Rust 不同,所以 Rust 提出了新概念“借用”,便于区分。
在其他语言中,引用是一种别名,你可以简单理解成鲁迅之于周树人,多个引用拥有对值的无差别的访问权限,本质上是共享了所有权;而在 Rust 下,所有的引用都只是借用了“临时使用权”,它并不破坏值的单一所有权约束。
因此 默认情况下,Rust 的借用都是只读的,就好像住酒店,退房时要完好无损。但有些情况下,我们也需要可变的借用,就像租房,可以对房屋进行必要的装饰,这一点待会详细讲。
所以,如果我们想避免 Copy 或者 Move,可以使用借用,或者说引用。
只读借用/引用
本质上,引用是一个受控的指针,指向某个特定的类型。在学习其他语言的时候,你会注意到函数传参有两种方式:传值(pass-by-value)和传引用(pass-by-reference)。
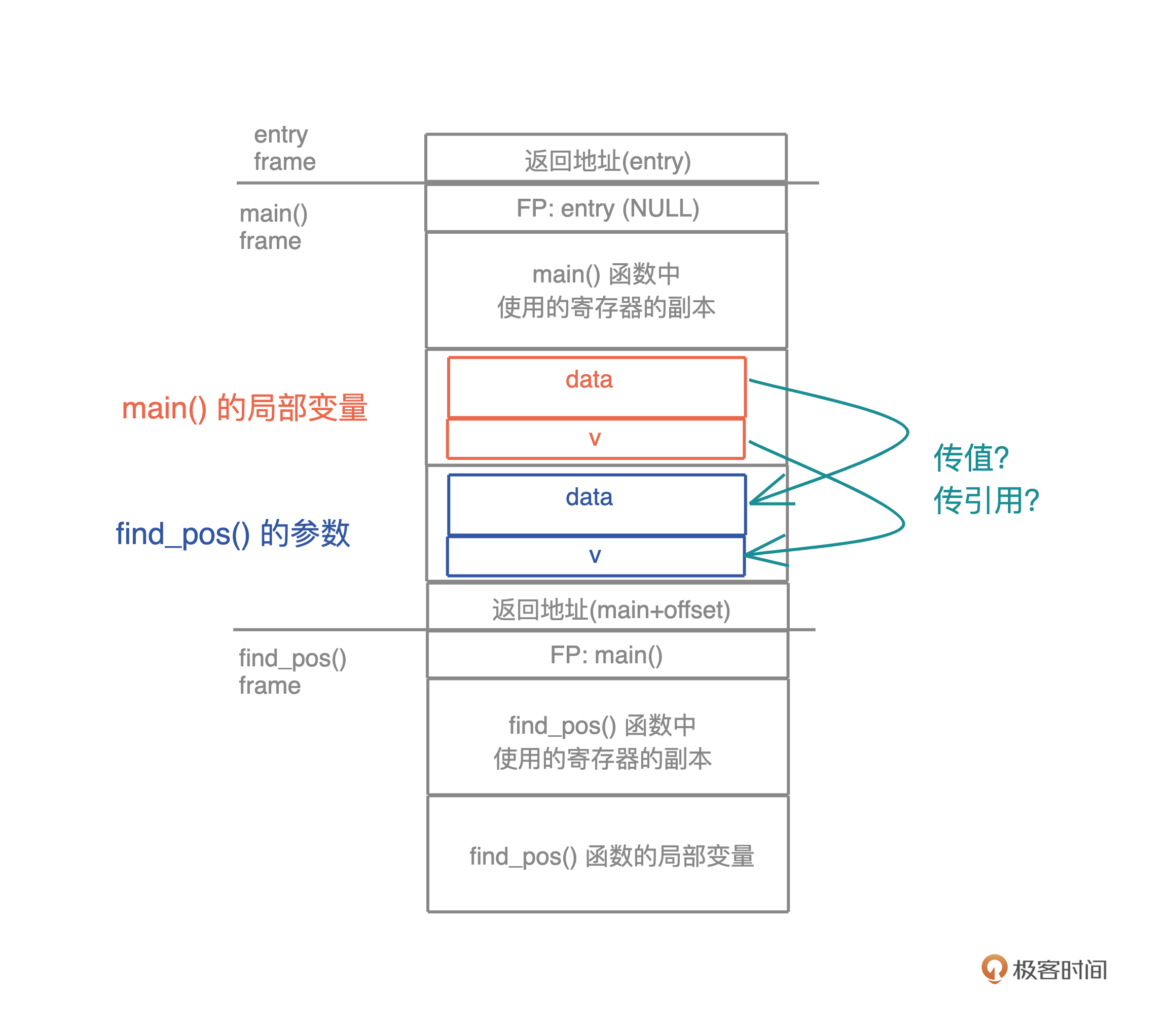
以 Java 为例,给函数传一个整数,这是传值,和 Rust 里的 Copy 语义一致;而给函数传一个对象,或者任何堆上的数据结构,Java 都会自动隐式地传引用。刚才说过,Java 的引用是对象的别名,这也导致随着程序的执行,同一块内存的引用到处都是,不得不依赖 GC 进行内存回收。
但 Rust 没有传引用的概念, Rust 所有的参数传递都是传值,不管是 Copy 还是 Move。所以在Rust中,你必须显式地把某个数据的引用,传给另一个函数。
Rust 的引用实现了 Copy trait,所以按照 Copy 语义,这个引用会被复制一份交给要调用的函数。对这个函数来说,它并不拥有数据本身,数据只是临时借给它使用,所有权还在原来的拥有者那里。
在 Rust里,引用是一等公民,和其他数据类型地位相等。
还是用上一讲有两处错误的 代码2 来演示。
fn main() { let data = vec![1, 2, 3, 4]; let data1 = data; println!("sum of data1: {}", sum(data1)); println!("data1: {:?}", data1); // error1 println!("sum of data: {}", sum(data)); // error2 } fn sum(data: Vec<u32>) -> u32 { data.iter().fold(0, |acc, x| acc + x) }
我们把 代码2 稍微改变一下,通过添加引用,让编译通过,并查看值和引用的地址( 代码3):
fn main() { let data = vec![1, 2, 3, 4]; let data1 = &data; // 值的地址是什么?引用的地址又是什么? println!( "addr of value: {:p}({:p}), addr of data {:p}, data1: {:p}", &data, data1, &&data, &data1 ); println!("sum of data1: {}", sum(data1)); // 堆上数据的地址是什么? println!( "addr of items: [{:p}, {:p}, {:p}, {:p}]", &data[0], &data[1], &data[2], &data[3] ); } fn sum(data: &Vec<u32>) -> u32 { // 值的地址会改变么?引用的地址会改变么? println!("addr of value: {:p}, addr of ref: {:p}", data, &data); data.iter().fold(0, |acc, x| acc + x) }
在运行这段代码之前,你可以先思考一下,data 对应值的地址是否保持不变,而 data1 引用的地址,在传给 sum() 函数后,是否还指向同一个地址。
好,如果你有想法了,可以再运行代码验证一下你是否正确,我们再看下图分析:
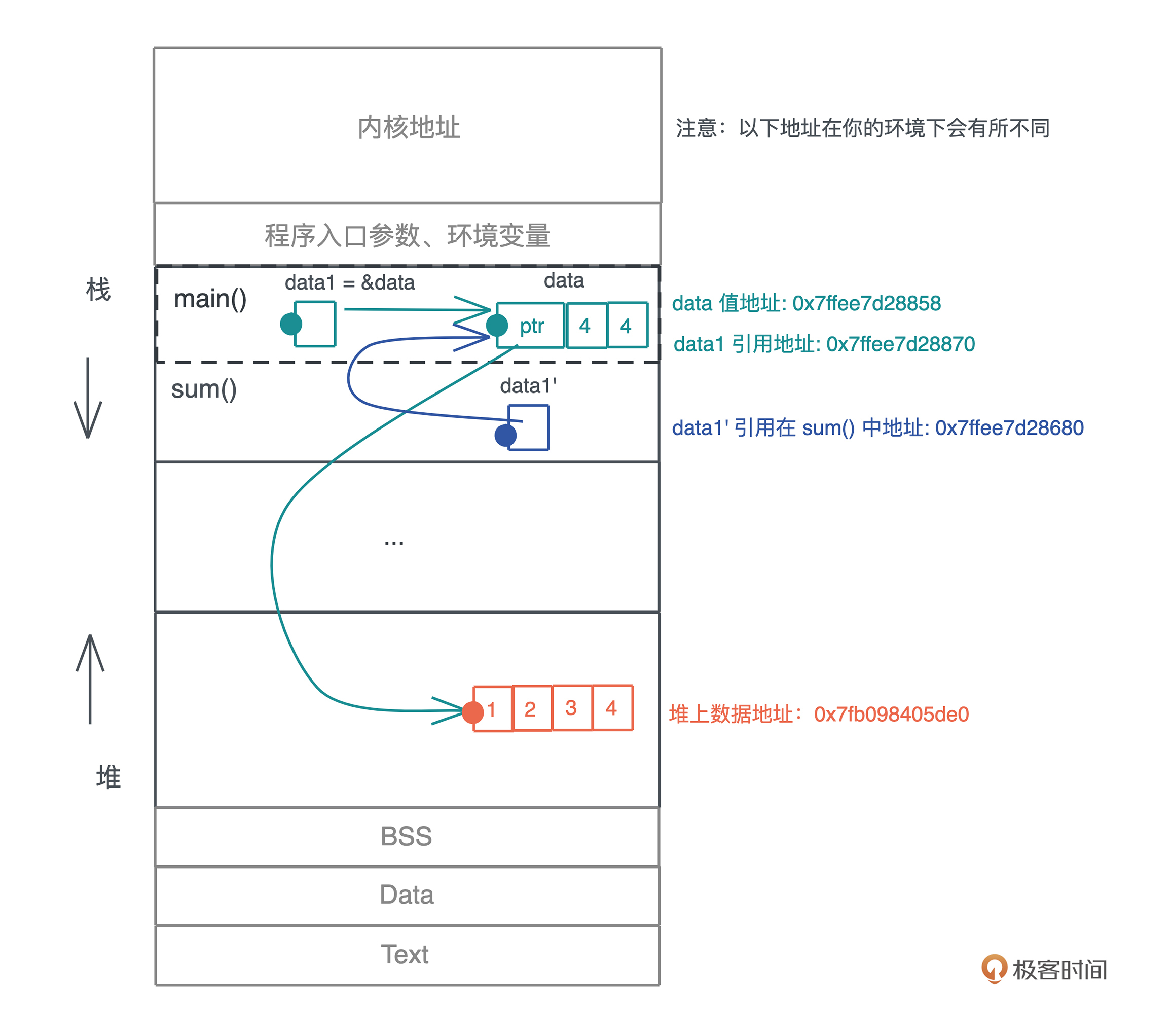
data1、&data 和传到 sum() 里的 data1’ 都指向 data 本身,这个值的地址是固定的。但是它们引用的地址都是不同的,这印证了我们讲 Copy trait 的时候,介绍过 只读引用实现了 Copy trait,也就意味着引用的赋值、传参都会产生新的浅拷贝。
虽然 data 有很多只读引用指向它,但堆上的数据依旧只有 data 一个所有者,所以值的任意多个引用并不会影响所有权的唯一性。
但我们马上就发现了新问题:一旦 data 离开了作用域被释放,如果还有引用指向 data,岂不是造成我们想极力避免的使用已释放内存(use after free)这样的内存安全问题?怎么办呢?
借用的生命周期及其约束
所以,我们对值的引用也要有约束,这个约束是:借用不能超过(outlive)值的生存期。
这个约束很直观,也很好理解。在上面的代码中,sum() 函数处在 main() 函数下一层调用栈中,它结束之后 main() 函数还会继续执行,所以在 main() 函数中定义的 data 生命周期要比 sum() 中对 data 的引用要长,这样不会有任何问题。
但如果是这样的代码呢( 情况1)?
fn main() { let r = local_ref(); println!("r: {:p}", r); } fn local_ref<'a>() -> &'a i32 { let a = 42; &a }
显然,生命周期更长的 main() 函数变量 r ,引用了生命周期更短的 local_ref() 函数里的局部变量,这违背了有关引用的约束,所以 Rust 不允许这样的代码编译通过。
那么,如果我们在堆内存中,使用栈内存的引用,可以么?
根据过去的开发经验,你也许会脱口而出:不行!因为堆内存的生命周期显然比栈内存要更长更灵活,这样做内存不安全。
我们写段代码试试看,把一个本地变量的引用存入一个可变数组中。从基础知识的学习中我们知道,可变数组存放在堆上,栈上只有一个胖指针指向它,所以这是一个典型的把栈上变量的引用存在堆上的例子( 情况2):
fn main() { let mut data: Vec<&u32> = Vec::new(); let v = 42; data.push(&v); println!("data: {:?}", data); }
竟然编译通过,怎么回事?我们变换一下,看看还能编译不( 情况3),又无法通过了!
fn main() { let mut data: Vec<&u32> = Vec::new(); push_local_ref(&mut data); println!("data: {:?}", data); } fn push_local_ref(data: &mut Vec<&u32>) { let v = 42; data.push(&v); }
到这里,你是不是有点迷糊了,这三种情况,为什么同样是对栈内存的引用,怎么编译结果都不一样?
这三段代码看似错综复杂,但如果抓住了一个核心要素“在一个作用域下,同一时刻,一个值只能有一个所有者”,你会发现,其实很简单。
堆变量的生命周期不具备任意长短的灵活性,因为堆上内存的生死存亡,跟栈上的所有者牢牢绑定。而栈上内存的生命周期,又跟栈的生命周期相关,所以我们 核心只需要关心调用栈的生命周期。
现在你是不是可以轻易判断出,为什么情况 1 和情况 3 的代码无法编译通过了,因为它们引用了生命周期更短的值,而情况2 的代码虽然在堆内存里引用栈内存,但生命周期是相同的,所以没有问题。
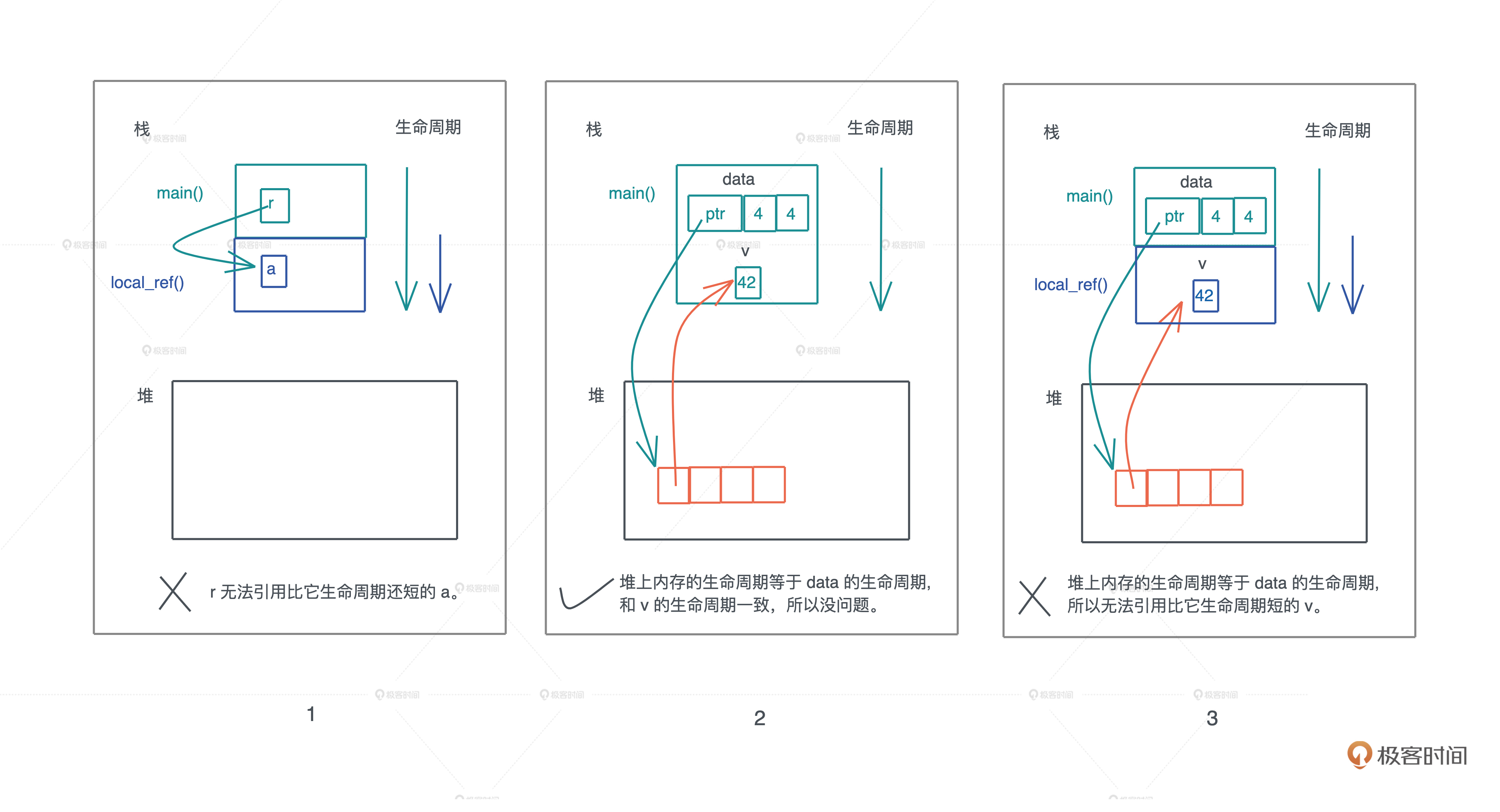
好,到这里,默认情况下,Rust 的只读借用就讲完了,借用者不能修改被借用的值,简单类比就像住酒店,只有使用权。
但之前也提到,有些情况下,我们也需要可变借用,想在借用的过程中修改值的内容,就像租房,需要对房屋进行必要的装饰。
可变借用/引用
在没有引入可变借用之前,因为一个值同一时刻只有一个所有者,所以如果要修改这个值,只能通过唯一的所有者进行。但是,如果允许借用改变值本身,会带来新的问题。
我们先看第一种情况, 多个可变引用共存:
fn main() { let mut data = vec![1, 2, 3]; for item in data.iter_mut() { data.push(*item + 1); } }
这段代码在遍历可变数组 data 的过程中,还往 data 里添加新的数据,这是很危险的动作,因为它破坏了循环的不变性(loop invariant),容易导致死循环甚至系统崩溃。所以,在同一个作用域下有多个可变引用,是不安全的。
由于 Rust 编译器阻止了这种情况,上述代码会编译出错。我们可以用 Python 来体验一下多个可变引用可能带来的死循环:
if __name__ == "__main__":
data = [1, 2]
for item in data:
data.append(item + 1)
print(item)
# unreachable code
print(data)
同一个上下文中多个可变引用是不安全的,那如果 同时有一个可变引用和若干个只读引用,会有问题吗?我们再看一段代码:
fn main() { let mut data = vec![1, 2, 3]; let data1 = vec![&data[0]]; println!("data[0]: {:p}", &data[0]); for i in 0..100 { data.push(i); } println!("data[0]: {:p}", &data[0]); println!("boxed: {:p}", &data1); }
在这段代码里,不可变数组 data1 引用了可变数组 data 中的一个元素,这是个只读引用。后续我们往 data 中添加了 100 个元素,在调用 data.push() 时,我们访问了 data 的可变引用。
这段代码中,data 的只读引用和可变引用共存,似乎没有什么影响,因为 data1 引用的元素并没有任何改动。
如果你仔细推敲,就会发现这里有内存不安全的潜在操作:如果继续添加元素,堆上的数据预留的空间不够了,就会重新分配一片足够大的内存,把之前的值拷过来,然后释放旧的内存。这样就会让 data1 中保存的 &data[0] 引用失效,导致内存安全问题。
Rust的限制
多个可变引用共存、可变引用和只读引用共存这两种问题,通过 GC 等自动内存管理方案可以避免第二种,但是第一个问题 GC 也无济于事。
所以为了保证内存安全,Rust 对可变引用的使用也做了严格的约束:
- 在一个作用域内,仅允许一个活跃的可变引用。所谓活跃,就是真正被使用来修改数据的可变引用,如果只是定义了,却没有使用或者当作只读引用使用,不算活跃。
- 在一个作用域内, 活跃的可变引用(写)和只读引用(读)是互斥的,不能同时存在。
这个约束你是不是觉得看上去似曾相识?对,它和数据在并发下的读写访问(比如 RwLock)规则非常类似,你可以类比学习。
从可变引用的约束我们也可以看到,Rust 不光解决了 GC 可以解决的内存安全问题,还解决了 GC 无法解决的问题。在编写代码的时候, Rust 编译器就像你的良师益友,不断敦促你采用最佳实践来撰写安全的代码。
学完今天的内容,我们再回看 开篇词 展示的第一性原理图,你的理解是不是更透彻了?
其实,我们拨开表层的众多所有权规则,一层层深究下去,触及最基础的概念,搞清楚堆或栈中值到底是如何存放的、在内存中值是如何访问的,然后从这些概念出发,或者扩展其外延,或者限制其使用,从根本上寻找解决之道,这才是我们处理复杂问题的最佳手段,也是Rust的设计思路。
小结
今天我们学习了 Borrow 语义,搞清楚了只读引用和可变引用的原理,结合上一讲学习的 Move / Copy 语义,Rust 编译器会通过检查,来确保代码没有违背这一系列的规则:
- 一个值在同一时刻只有一个所有者。当所有者离开作用域,其拥有的值会被丢弃。赋值或者传参会导致值 Move,所有权被转移,一旦所有权转移,之前的变量就不能访问。
- 如果值实现了 Copy trait,那么赋值或传参会使用 Copy 语义,相应的值会被按位拷贝,产生新的值。
- 一个值可以有多个只读引用。
- 一个值可以有唯一一个活跃的可变引用。可变引用(写)和只读引用(读)是互斥的关系,就像并发下数据的读写互斥那样。
- 引用的生命周期不能超出值的生命周期。
你也可以看这张图快速回顾:
但总有一些特殊情况,比如DAG,我们想绕过“一个值只有一个所有者”的限制,怎么办?下一讲我们继续学习……
思考题
- 上一讲我们在讲 Copy trait 时说到,可变引用没有实现 Copy trait。结合这一讲的内容,想想为什么?
- 下面这段代码,如何修改才能使其编译通过,避免同时有只读引用和可变引用?
fn main() { let mut arr = vec![1, 2, 3]; // cache the last item let last = arr.last(); arr.push(4); // consume previously stored last item println!("last: {:?}", last); }
欢迎在留言区分享你的思考。今天你完成了 Rust 学习的第八次打卡!如果你觉得有收获,也欢迎你分享给身边的朋友,邀TA一起讨论。
参考资料
有同学评论,好奇可变引用是如何导致堆内存重新分配的,我们看一个例子。我先分配一个 capacity 为 1 的 Vec,然后放入 32 个元素,此时它会重新分配,然后打印重新分配前后 &v[0] 的堆地址时,会看到发生了变化。
所以,如果我们有指向旧的 &v[0] 的地址,就会读到已释放内存,这就是我在文中说为什么在同一个作用域下,可变引用和只读引用不能共存( 代码)。
use std::mem;
fn main() {
// capacity 是 1, len 是 0
let mut v = vec![1];
// capacity 是 8, len 是 0
let v1: Vec<i32> = Vec::with_capacity(8);
print_vec("v1", v1);
// 我们先打印 heap 地址,然后看看添加内容是否会导致堆重分配
println!("heap start: {:p}", &v[0] as *const i32);
extend_vec(&mut v);
// heap 地址改变了!这就是为什么可变引用和不可变引用不能共存的原因
println!("new heap start: {:p}", &v[0] as *const i32);
print_vec("v", v);
}
fn extend_vec(v: &mut Vec<i32>) {
// Vec<T> 堆内存里 T 的个数是指数增长的,我们让它恰好 push 33 个元素
// capacity 会变成 64
(2..34).into_iter().for_each(|i| v.push(i));
}
fn print_vec<T>(name: &str, data: Vec<T>) {
let p: [usize; 3] = unsafe { mem::transmute(data) };
// 打印 Vec<T> 的堆地址,capacity,len
println!("{}: 0x{:x}, {}, {}", name, p[0], p[1], p[2]);
}
打印结果(地址在你机器上会不一样):
v1: 0x7f8a2f405e00, 8, 0
heap start: 0x7f8a2f405df0
new heap start: 0x7f8a2f405e20
v: 0x7f8a2f405e20, 64, 33
如果你运行了这段代码,你可能会注意到一个很有意思的细节:我在 playground 代码链接中给出的代码和文中的代码稍微有些不同。
在文中我的环境是 OS X,很少量的数据就会让堆内存重新分配,而 playground 是 Linux 环境,我一直试到 > 128KB 内存才让 Vec 的堆内存重分配。
所有权:一个值可以有多个所有者么?
你好,我是陈天。
之前介绍的单一所有权规则,能满足我们大部分场景中分配和使用内存的需求,而且在编译时,通过 Rust 借用检查器就能完成静态检查,不会影响运行时效率。
但是,规则总会有例外,在日常工作中有些特殊情况该怎么处理呢?
- 一个有向无环图(DAG)中,某个节点可能有两个以上的节点指向它,这个按照所有权模型怎么表述?
- 多个线程要访问同一块共享内存,怎么办?
我们知道,这些问题在程序运行过程中才会遇到,在编译期,所有权的静态检查无法处理它们,所以为了更好的灵活性,Rust 提供了 运行时的动态检查,来满足特殊场景下的需求。
这也是 Rust 处理很多问题的思路:编译时,处理大部分使用场景,保证安全性和效率;运行时,处理无法在编译时处理的场景,会牺牲一部分效率,提高灵活性。后续讲到静态分发和动态分发也会有体现,这个思路很值得我们借鉴。
那具体如何在运行时做动态检查呢?运行时的动态检查又如何与编译时的静态检查自洽呢?
Rust 的答案是使用引用计数的智能指针: Rc(Reference counter) 和 Arc(Atomic reference counter)。这里要特别说明一下,Arc 和 ObjC/Swift 里的 ARC(Automatic Reference Counting)不是一个意思,不过它们解决问题的手段类似,都是通过引用计数完成的。
Rc
我们先看 Rc。对某个数据结构 T,我们可以创建引用计数 Rc,使其有多个所有者。Rc 会把对应的数据结构创建在堆上,我们在第二讲谈到过,堆是唯一可以让动态创建的数据被到处使用的内存。
use std::rc::Rc; fn main() { let a = Rc::new(1); }
之后,如果想对数据创建更多的所有者,我们可以通过 clone() 来完成。
对一个 Rc 结构进行 clone(),不会将其内部的数据复制,只会增加引用计数。而当一个 Rc 结构离开作用域被 drop() 时,也只会减少其引用计数,直到引用计数为零,才会真正清除对应的内存。
use std::rc::Rc; fn main() { let a = Rc::new(1); let b = a.clone(); let c = a.clone(); }
上面的代码我们创建了三个 Rc,分别是 a、b 和 c。它们共同指向堆上相同的数据,也就是说,堆上的数据有了三个共享的所有者。在这段代码结束时,c 先 drop,引用计数变成 2,然后 b drop、a drop,引用计数归零,堆上内存被释放。
你也许会有疑问:为什么我们生成了对同一块内存的多个所有者,但是,编译器不抱怨所有权冲突呢?
仔细看这段代码:首先 a 是 Rc::new(1) 的所有者,这毋庸置疑;然后 b 和 c 都调用了 a.clone(),分别得到了一个新的 Rc,所以从编译器的角度,abc 都各自拥有一个 Rc。如果文字你觉得稍微有点绕,看看 Rc 的 clone() 函数的实现,就很清楚了( 源代码):
#![allow(unused)] fn main() { fn clone(&self) -> Rc<T> { // 增加引用计数 self.inner().inc_strong(); // 通过 self.ptr 生成一个新的 Rc 结构 Self::from_inner(self.ptr) } }
所以,Rc 的 clone() 正如我们刚才说的,不复制实际的数据,只是一个引用计数的增加。
你可能继续会疑惑:Rc 是怎么产生在堆上的?并且为什么这段堆内存不受栈内存生命周期的控制呢?
Box::leak()机制
上一讲我们讲到,在所有权模型下,堆内存的生命周期,和创建它的栈内存的生命周期保持一致。所以 Rc 的实现似乎与此格格不入。的确,如果完全按照上一讲的单一所有权模型,Rust 是无法处理 Rc 这样的引用计数的。
Rust必须提供一种机制,让代码可以像 C/C++ 那样, 创建不受栈内存控制的堆内存,从而绕过编译时的所有权规则。Rust 提供的方式是 Box::leak()。
Box 是 Rust 下的智能指针,它可以强制把任何数据结构创建在堆上,然后在栈上放一个指针指向这个数据结构,但此时堆内存的生命周期仍然是受控的,跟栈上的指针一致。我们后续讲到智能指针时会详细介绍 Box。
Box::leak(),顾名思义,它创建的对象,从堆内存上泄漏出去,不受栈内存控制,是一个自由的、生命周期可以大到和整个进程的生命周期一致的对象。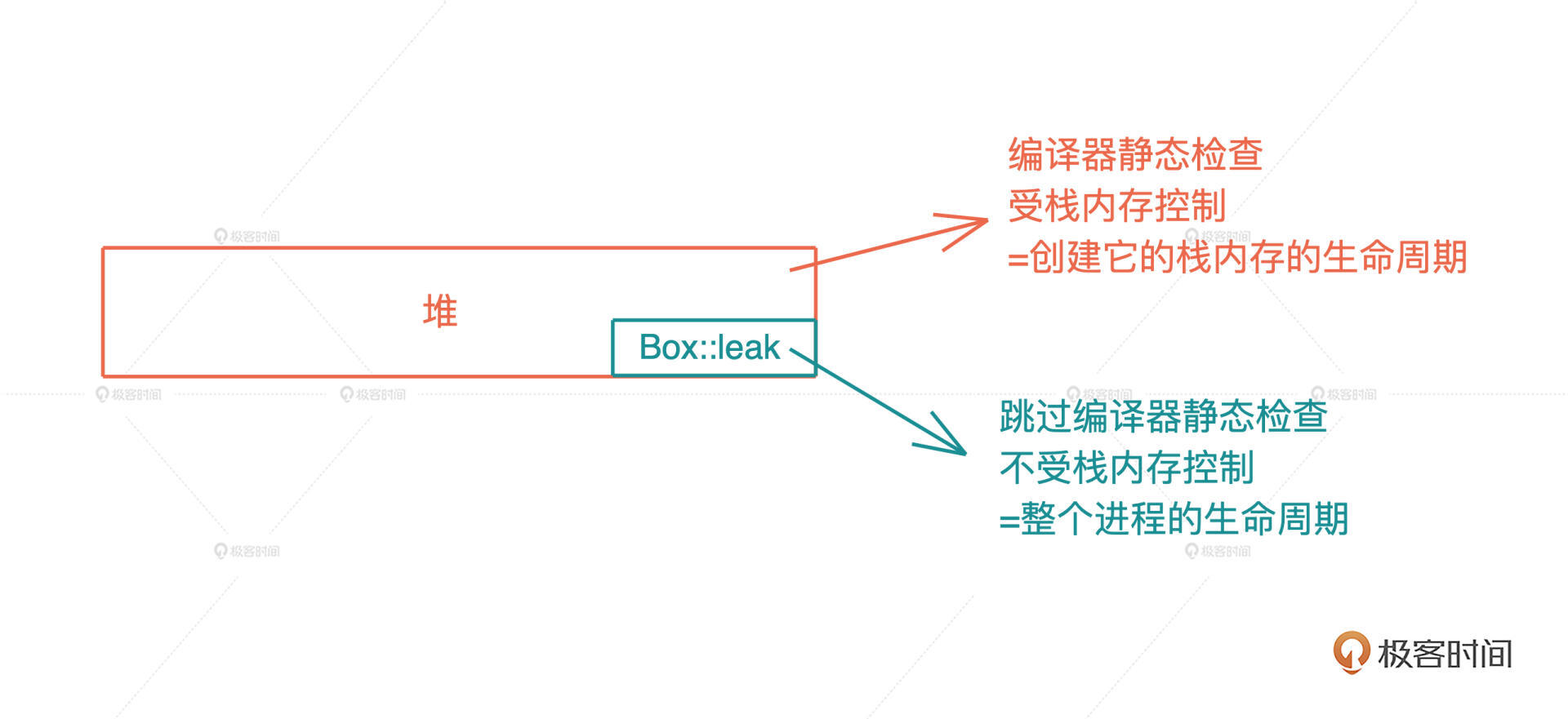
所以我们相当于主动撕开了一个口子,允许内存泄漏。注意,在 C/C++ 下,其实你通过 malloc 分配的每一片堆内存,都类似 Rust 下的 Box::leak()。我很喜欢 Rust 这样的设计,它符合最小权限原则( Principle of least privilege),最大程度帮助开发者撰写安全的代码。
有了 Box::leak(),我们就可以跳出 Rust 编译器的静态检查,保证 Rc 指向的堆内存,有最大的生命周期,然后我们再通过引用计数,在合适的时机,结束这段内存的生命周期。如果你对此感兴趣,可以看 Rc::new() 的源码。
插一句,在学习语言的过程中,不要因为觉得自己是个初学者,就不敢翻阅标准库的源码,相反,遇到不懂的地方,如果你去看对应的源码,得到的是第一手的知识,一旦搞明白,就会学得非常扎实,受益无穷。
搞明白了 Rc,我们就进一步理解 Rust 是如何进行所有权的静态检查和动态检查了:
- 静态检查,靠编译器保证代码符合所有权规则;
- 动态检查,通过 Box::leak 让堆内存拥有不受限的生命周期,然后在运行过程中,通过对引用计数的检查,保证这样的堆内存最终会得到释放。
实现 DAG
现在我们用 Rc 来实现之前无法实现的 DAG。
假设 Node 就只包含 id 和指向下游(downstream)的指针,因为 DAG 中的一个节点可能被多个其它节点指向,所以我们使用 Rc<Node> 来表述它;一个节点可能没有下游节点,所以我们用 Option<Rc<Node>> 来表述它。
要建立这样一个 DAG,我们需要为 Node 提供以下方法:
- new():建立一个新的 Node。
- update_downstream():设置 Node 的 downstream。
- get_downstream():clone 一份 Node 里的 downstream。
有了这些方法,我们就可以创建出拥有上图关系的 DAG 了( 代码1):
use std::rc::Rc; #[derive(Debug)] struct Node { id: usize, downstream: Option<Rc<Node>>, } impl Node { pub fn new(id: usize) -> Self { Self { id, downstream: None, } } pub fn update_downstream(&mut self, downstream: Rc<Node>) { self.downstream = Some(downstream); } pub fn get_downstream(&self) -> Option<Rc<Node>> { self.downstream.as_ref().map(|v| v.clone()) } } fn main() { let mut node1 = Node::new(1); let mut node2 = Node::new(2); let mut node3 = Node::new(3); let node4 = Node::new(4); node3.update_downstream(Rc::new(node4)); node1.update_downstream(Rc::new(node3)); node2.update_downstream(node1.get_downstream().unwrap()); println!("node1: {:?}, node2: {:?}", node1, node2); }
RefCell
在运行上述代码时,细心的你也许会疑惑:整个 DAG 在创建完成后还能修改么?
按最简单的写法,我们可以在上面的代码1的 main() 函数后,加入这段代码( 代码2),来修改 Node3 使其指向一个新的节点 Node5:
#![allow(unused)] fn main() { let node5 = Node::new(5); let node3 = node1.get_downstream().unwrap(); node3.update_downstream(Rc::new(node5)); println!("node1: {:?}, node2: {:?}", node1, node2); }
然而,它无法编译通过,编译器会告诉你“node3 cannot borrow as mutable”。
这是因为 Rc 是一个只读的引用计数器,你无法拿到 Rc 结构内部数据的可变引用,来修改这个数据。这可怎么办?
这里,我们需要使用 RefCell。
和 Rc 类似,RefCell 也绕过了 Rust 编译器的静态检查,允许我们在运行时,对某个只读数据进行可变借用。这就涉及 Rust 另一个比较独特且有点难懂的概念: 内部可变性(interior mutability)。
内部可变性
有内部可变性,自然能联想到外部可变性,所以我们先看这个更简单的定义,对比着学。
当我们用 let mut 显式地声明一个可变的值,或者,用 &mut 声明一个可变引用时,编译器可以在编译时进行严格地检查,保证只有可变的值或者可变的引用,才能修改值内部的数据,这被称作外部可变性(exterior mutability),外部可变性通过 mut 关键字声明。
然而,这样不够灵活,有时候我们希望能够绕开这个编译时的检查,对并未声明成 mut 的值或者引用,也想进行修改。也就是说, 在编译器的眼里,值是只读的,但是在运行时,这个值可以得到可变借用,从而修改内部的数据,这就是 RefCell 的用武之地。
我们看一个简单的例子( 代码2):
use std::cell::RefCell; fn main() { let data = RefCell::new(1); { // 获得 RefCell 内部数据的可变借用 let mut v = data.borrow_mut(); *v += 1; } println!("data: {:?}", data.borrow()); }
在这个例子里,data 是一个 RefCell,其初始值为 1。可以看到,我们并未将 data 声明为可变变量。之后我们可以通过使用 RefCell 的 borrow_mut() 方法,来获得一个可变的内部引用,然后对它做加 1 的操作。最后,我们可以通过 RefCell 的 borrow() 方法,获得一个不可变的内部引用,因为加了 1,此时它的值为 2。
你也许奇怪,这里为什么要把获取和操作可变借用的两句代码,用花括号分装到一个作用域下?
因为根据所有权规则,在同一个作用域下,我们 不能同时有活跃的可变借用和不可变借用。通过这对花括号,我们明确地缩小了可变借用的生命周期,不至于和后续的不可变借用冲突。
这里再想一步,如果没有这对花括号,这段代码是无法编译通过?还是运行时会出错( 代码3)?
use std::cell::RefCell; fn main() { let data = RefCell::new(1); let mut v = data.borrow_mut(); *v += 1; println!("data: {:?}", data.borrow()); }
如果你运行代码3,编译没有任何问题,但在运行到第 9 行时,会得到:“already mutably borrowed: BorrowError” 这样的错误。可以看到,所有权的借用规则在此依旧有效,只不过它在运行时检测。
这就是外部可变性和内部可变性的重要区别,我们用下表来总结一下:
实现可修改DAG
好,现在我们对 RefCell 有一个直观的印象,看看如何使用它和 Rc 来让之前的 DAG 变得可修改。
首先数据结构的 downstream 需要 Rc 内部嵌套一个 RefCell,这样,就可以利用 RefCell 的内部可变性,来获得数据的可变借用了,同时 Rc 还允许值有多个所有者。
完整的代码我放到这里了( 代码4):
use std::cell::RefCell; use std::rc::Rc; #[derive(Debug)] struct Node { id: usize, // 使用 Rc<RefCell<T>> 让节点可以被修改 downstream: Option<Rc<RefCell<Node>>>, } impl Node { pub fn new(id: usize) -> Self { Self { id, downstream: None, } } pub fn update_downstream(&mut self, downstream: Rc<RefCell<Node>>) { self.downstream = Some(downstream); } pub fn get_downstream(&self) -> Option<Rc<RefCell<Node>>> { self.downstream.as_ref().map(|v| v.clone()) } } fn main() { let mut node1 = Node::new(1); let mut node2 = Node::new(2); let mut node3 = Node::new(3); let node4 = Node::new(4); node3.update_downstream(Rc::new(RefCell::new(node4))); node1.update_downstream(Rc::new(RefCell::new(node3))); node2.update_downstream(node1.get_downstream().unwrap()); println!("node1: {:?}, node2: {:?}", node1, node2); let node5 = Node::new(5); let node3 = node1.get_downstream().unwrap(); // 获得可变引用,来修改 downstream node3.borrow_mut().downstream = Some(Rc::new(RefCell::new(node5))); println!("node1: {:?}, node2: {:?}", node1, node2); }
可以看到,通过使用 Rc<RefCell<T>> 这样的嵌套结构,我们的 DAG 也可以正常修改了。
Arc 和 Mutex/RwLock
我们用 Rc 和 RefCell 解决了 DAG 的问题,那么,开头提到的多个线程访问同一块内存的问题,是否也可以使用 Rc 来处理呢?
不行。因为 Rc 为了性能,使用的不是线程安全的引用计数器。因此,我们需要另一个引用计数的智能指针:Arc,它实现了线程安全的引用计数器。
Arc 内部的引用计数使用了 Atomic Usize ,而非普通的 usize。从名称上也可以感觉出来,Atomic Usize 是 usize 的原子类型,它使用了 CPU 的特殊指令,来保证多线程下的安全。如果你对原子类型感兴趣,可以看 std::sync::atomic 的文档。
Rust 实现两套不同的引用计数数据结构,完全是为了性能考虑,从这里我们也可以感受到 Rust 对性能的极致渴求。 如果不用跨线程访问,可以用效率非常高的 Rc;如果要跨线程访问,那么必须用 Arc。
同样的,RefCell 也不是线程安全的,如果我们要在多线程中,使用内部可变性,Rust 提供了 Mutex 和 RwLock。
这两个数据结构你应该都不陌生,Mutex是互斥量,获得互斥量的线程对数据独占访问,RwLock是读写锁,获得写锁的线程对数据独占访问,但当没有写锁的时候,允许有多个读锁。读写锁的规则和 Rust 的借用规则非常类似,我们可以类比着学。
Mutex 和 RwLock 都用在多线程环境下,对共享数据访问的保护上。刚才中我们构建的 DAG 如果要用在多线程环境下,需要把 Rc<RefCell<T>> 替换为 Arc<Mutex<T>> 或者 Arc<RwLock<T>>。更多有关 Arc/Mutex/RwLock 的知识,我们会在并发篇详细介绍。
小结
我们对所有权有了更深入的了解,掌握了 Rc / Arc、RefCell / Mutex / RwLock 这些数据结构的用法。
如果想绕过“一个值只有一个所有者”的限制,我们可以使用 Rc / Arc 这样带引用计数的智能指针。其中,Rc 效率很高,但只能使用在单线程环境下;Arc 使用了原子结构,效率略低,但可以安全使用在多线程环境下。
然而,Rc / Arc 是不可变的,如果想要修改内部的数据, 需要引入内部可变性,在单线程环境下,可以在 Rc 内部使用 RefCell;在多线程环境下,可以使用 Arc 嵌套 Mutex 或者 RwLock 的方法。
你可以看这张表快速回顾: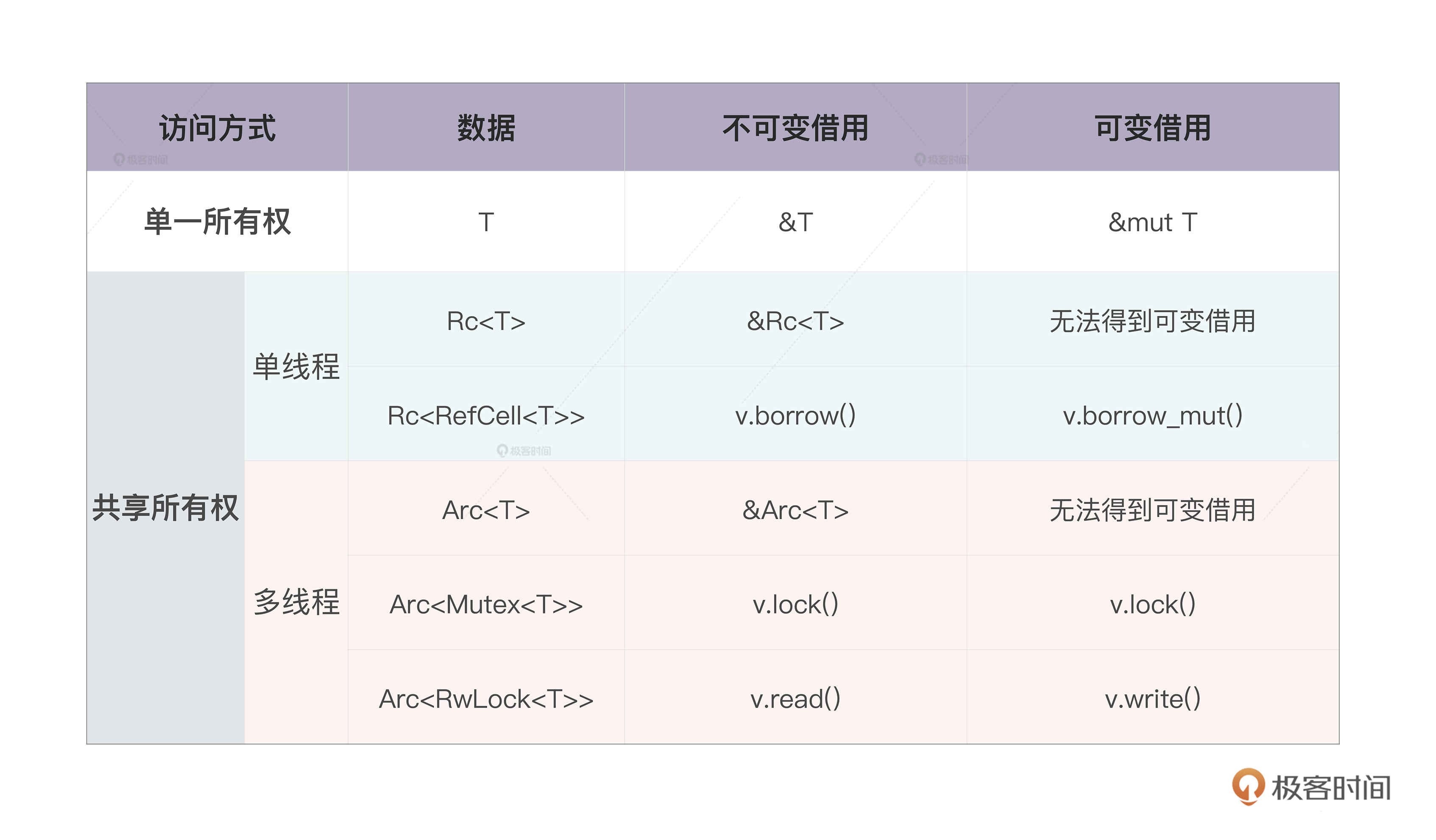
思考题
- 运行下面的代码,查看错误,并阅读 std::thread::spawn 的文档,找到问题的原因后,修改代码使其编译通过。
fn main() { let arr = vec![1]; std::thread::spawn(|| { println!("{:?}", arr); }); }
-
你可以写一段代码,在 main() 函数里生成一个字符串,然后通过
std::thread::spawn创建一个线程,让 main() 函数所在的主线程和新的线程共享这个字符串么?提示:使用 std::sync::Arc。 -
我们看到了 Rc 的 clone() 方法的实现:
#![allow(unused)] fn main() { fn clone(&self) -> Rc<T> { // 增加引用计数 self.inner().inc_strong(); // 通过 self.ptr 生成一个新的 Rc 结构 Self::from_inner(self.ptr) } }
你有没有注意到,这个方法传入的参数是 &self ,是个不可变引用,然而它调用了 self.inner().inc_strong() ,光看函数名字,它用来增加 self 的引用计数,可是,为什么这里对 self 的不可变引用可以改变 self 的内部数据呢?
欢迎在留言区分享你的思考。恭喜你完成了 Rust 学习的第九次打卡,如果你觉得有收获,也欢迎分享给你身边的朋友,邀TA一起讨论。
参考资料
- clone() 函数的 实现源码
- 最小权限原则
- Rc::new() 的 源码
- Arc 内部的引用计数使用了 Atomic Usize
- Atomic Usize 是 usize 的原子类型: std::sync::atomic 的文档
- 内部可变性:除了 RefCell 之外,Rust 还提供了 Cell。如果你想对 RefCell 和 Cell 进一步了解,可以看 Rust 标准库里 cell 的文档。
生命周期:你创建的值究竟能活多久?
你好,我是陈天。
之前提到过,在任何语言里,栈上的值都有自己的生命周期,它和帧的生命周期一致,而 Rust,进一步明确这个概念,并且为堆上的内存也引入了生命周期。
我们知道,在其它语言中,堆内存的生命周期是不确定的,或者是未定义的。因此,要么开发者手工维护,要么语言在运行时做额外的检查。而在 Rust 中,除非显式地做 Box::leak() / Box::into_raw() / ManualDrop 等动作, 一般来说,堆内存的生命周期,会默认和其栈内存的生命周期绑定在一起。
所以在这种默认情况下,在每个函数的作用域中,编译器就可以对比值和其引用的生命周期,来确保“引用的生命周期不超出值的生命周期”。
那你有没有想过,Rust 编译器是如何做到这一点的呢?
值的生命周期
在进一步讨论之前,我们先给值可能的生命周期下个定义。
如果一个值的生命周期 贯穿整个进程的生命周期,那么我们就称这种生命周期为 静态生命周期。
当值拥有静态生命周期,其引用也具有静态生命周期。我们在表述这种引用的时候,可以用 'static 来表示。比如: &'static str 代表这是一个具有静态生命周期的字符串引用。
一般来说,全局变量、静态变量、字符串字面量(string literal)等,都拥有静态生命周期。我们上文中提到的堆内存,如果使用了 Box::leak 后,也具有静态生命周期。
如果一个值是 在某个作用域中定义的,也就是说它被创建在栈上或者堆上,那么其 生命周期是动态的。
当这个值的作用域结束时,值的生命周期也随之结束。对于动态生命周期,我们约定用 'a 、 'b 或者 'hello 这样的小写字符或者字符串来表述。 ' 后面具体是什么名字不重要,它代表某一段动态的生命周期,其中, &'a str 和 &'b str 表示这两个字符串引用的生命周期可能不一致。
我们通过图总结一下:
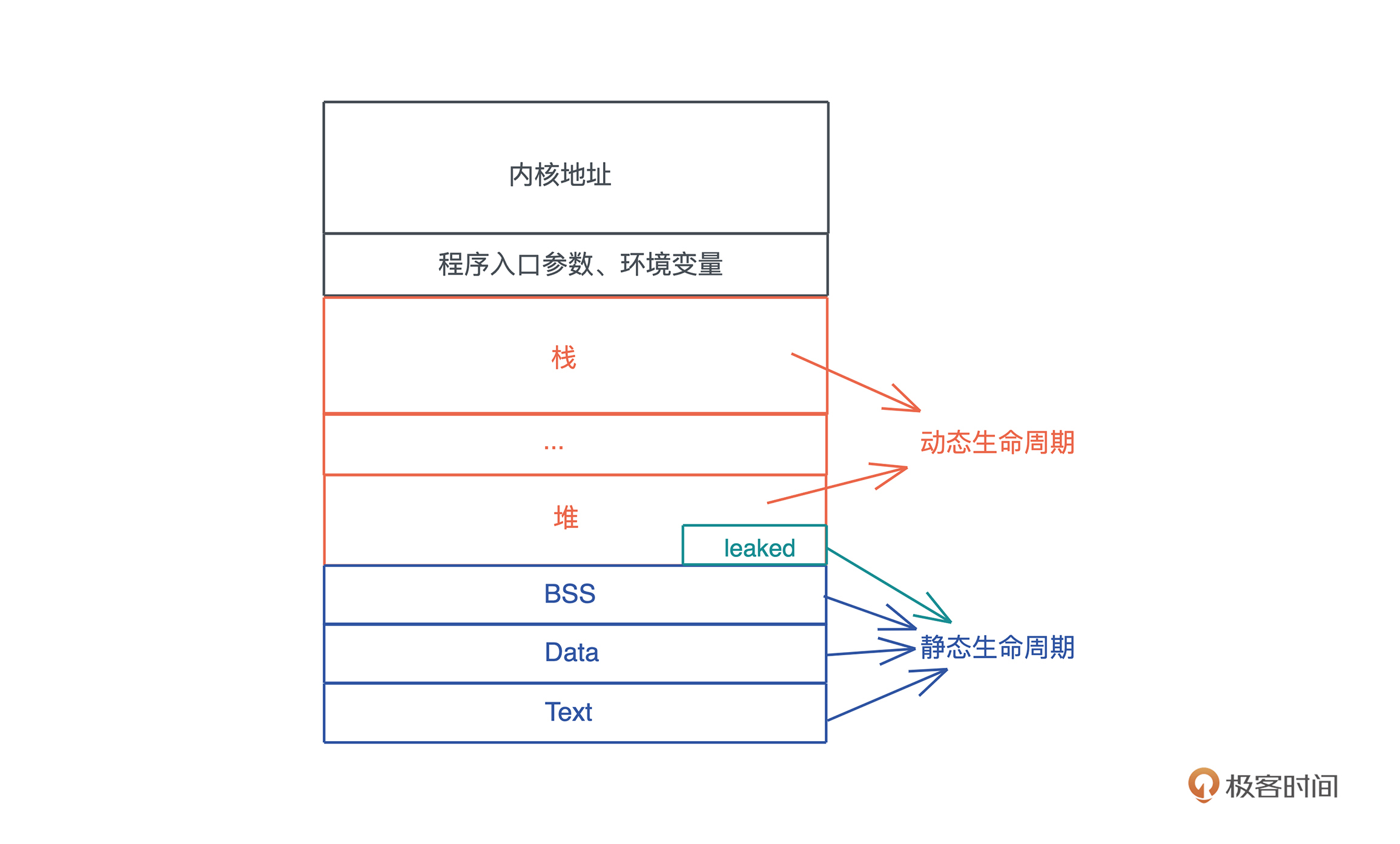
- 分配在堆和栈上的内存有其各自的作用域,它们的生命周期是动态的。
- 全局变量、静态变量、字符串字面量、代码等内容,在编译时,会被编译到可执行文件中的 BSS/Data/RoData/Text 段,然后在加载时,装入内存。因而,它们的生命周期和进程的生命周期一致,所以是静态的。
- 所以,函数指针的生命周期也是静态的,因为函数在 Text 段中,只要进程活着,其内存一直存在。
明白了这些基本概念后,我们来看对于值和引用,编译器是如何识别其生命周期的。
编译器如何识别生命周期
我们先从两个最基本最简单的例子开始。
左图的 例1,x 引用了在内层作用域中创建出来的变量 y。由于,变量从开始定义到其作用域结束的这段时间,是它的生命周期,所以 x 的生命周期 'a 大于 y 的生命周期 'b,当 x 引用 y 时,编译器报错。
右图 例 2 中,y 和 x 处在同一个作用域下, x 引用了 y,我们可以看到 x 的生命周期 'a 和 y 的生命周期 'b 几乎同时结束,或者说 'a 小于等于 'b,所以,x 引用 y 是可行的。
这两个小例子很好理解,我们再看个稍微复杂一些的。
示例代码在 main() 函数里创建了两个 String,然后将其传入 max() 函数比较大小。max() 函数接受两个字符串引用,返回其中较大的那个字符串的引用( 示例代码):
fn main() { let s1 = String::from("Lindsey"); let s2 = String::from("Rosie"); let result = max(&s1, &s2); println!("bigger one: {}", result); } fn max(s1: &str, s2: &str) -> &str { if s1 > s2 { s1 } else { s2 } }
这段代码是无法编译通过的,它会报错 “missing lifetime specifier” ,也就是说, 编译器在编译 max() 函数时,无法判断 s1、s2 和返回值的生命周期。
你是不是很疑惑,站在我们开发者的角度,这个代码理解起来非常直观,在 main() 函数里 s1 和 s2 两个值生命周期一致,它们的引用传给 max() 函数之后,无论谁的被返回,生命周期都不会超过 s1 或 s2。所以这应该是一段正确的代码啊?
为什么编译器报错了,不允许它编译通过呢?我们把这段代码稍微扩展一下,你就能明白编译器的困惑了。
在刚才的示例代码中,我们创建一个新的函数 get_max(),它接受一个字符串引用,然后和 “Cynthia” 这个字符串字面量比较大小。之前我们提到, 字符串字面量的生命周期是静态的,而 s1 是动态的,它们的生命周期显然不一致( 代码):
fn main() { let s1 = String::from("Lindsey"); let s2 = String::from("Rosie"); let result = max(&s1, &s2); println!("bigger one: {}", result); let result = get_max(&s1); println!("bigger one: {}", result); } fn get_max(s1: &str) -> &str { max(s1, "Cynthia") } fn max(s1: &str, s2: &str) -> &str { if s1 > s2 { s1 } else { s2 } }
当出现了多个参数,它们的生命周期可能不一致时,返回值的生命周期就不好确定了。编译器在编译某个函数时,并不知道这个函数将来有谁调用、怎么调用,所以, 函数本身携带的信息,就是编译器在编译时使用的全部信息。
根据这一点,我们再看示例代码,在编译 max() 函数时,参数 s1 和 s2 的生命周期是什么关系、返回值和参数的生命周期又有什么关系,编译器是无法确定的。
此时,就需要我们在函数签名中提供生命周期的信息,也就是生命周期标注(lifetime specifier)。在生命周期标注时,使用的参数叫生命周期参数(lifetime parameter)。通过生命周期标注,我们告诉编译器这些引用间生命周期的约束。
生命周期参数的描述方式和泛型参数一致,不过只使用小写字母。这里,两个入参 s1、 s2,以及返回值都用 'a 来约束。 生命周期参数,描述的是参数和参数之间、参数和返回值之间的关系,并不改变原有的生命周期。
在我们添加了生命周期参数后,s1 和 s2 的生命周期只要大于等于(outlive) 'a,就符合参数的约束,而返回值的生命周期同理,也需要大于等于 'a 。
在你运行上述示例代码的时候,编译器已经提示你,可以这么修改 max() 函数:
#![allow(unused)] fn main() { fn max<'a>(s1: &'a str, s2: &'a str) -> &'a str { if s1 > s2 { s1 } else { s2 } } }
当 main() 函数调用 max() 函数时,s1 和 s2 有相同的生命周期 'a ,所以它满足 (s1: &'a str, s2: &'a str) 的约束。当 get_max() 函数调用 max() 时,“Cynthia” 是静态生命周期,它大于 s1 的生命周期 'a ,所以它也可以满足 max() 的约束需求。
你的引用需要额外标注吗
学到这里,你可能会有困惑了:为什么我之前写的代码,很多函数的参数或者返回值都使用了引用,编译器却没有提示我要额外标注生命周期呢?
这是因为编译器希望尽可能减轻开发者的负担,其实所有使用了引用的函数,都需要生命周期的标注,只不过编译器会自动做这件事,省却了开发者的麻烦。
比如这个例子,first() 函数接受一个字符串引用,找到其中的第一个单词并返回( 代码):
fn main() { let s1 = "Hello world"; println!("first word of s1: {}", first(&s1)); } fn first(s: &str) -> &str { let trimmed = s.trim(); match trimmed.find(' ') { None => "", Some(pos) => &trimmed[..pos], } }
虽然我们没有做任何生命周期的标注,但编译器会通过一些简单的规则为函数自动添加标注:
- 所有引用类型的参数都有独立的生命周期
'a、'b等。 - 如果只有一个引用型输入,它的生命周期会赋给所有输出。
- 如果有多个引用类型的参数,其中一个是 self,那么它的生命周期会赋给所有输出。
规则 3 适用于 trait 或者自定义数据类型,我们先放在一边,以后遇到会再详细讲的。例子中的 first() 函数通过规则 1 和 2,可以得到一个带生命周期的版本( 代码):
#![allow(unused)] fn main() { fn first<'a>(s: &'a str) -> &'a str { let trimmed = s.trim(); match trimmed.find(' ') { None => "", Some(pos) => &trimmed[..pos], } } }
你可以看到,所有引用都能正常标注,没有冲突。那么对比之前返回较大字符串的示例代码( 示例代码), max() 函数为什么编译器无法处理呢?
按照规则 1, 我们可以对max() 函数的参数 s1 和 s2 分别标注 'a 和 'b ,但是 返回值如何标注?是 'a 还是 'b 呢?这里的冲突,编译器无能为力。
#![allow(unused)] fn main() { fn max<'a, 'b>(s1: &'a str, s2: &'b str) -> &'??? str }
所以,只有我们明白了代码逻辑,才能正确标注参数和返回值的约束关系,顺利编译通过。
引用标注小练习
好,Rust的生命周期这个知识点我们就讲完了,接下来我们来尝试写一个字符串分割函数strtok(),即时练习一下,如何加引用标注。
相信有过 C/C++ 经验的开发者都接触过这个strtok()函数,它会把字符串按照分隔符(delimiter)切出一个 token 并返回,然后将传入的字符串引用指向后续的 token。
用 Rust 实现并不困难,由于传入的 s 需要可变的引用,所以它是一个指向字符串引用的可变引用 &mut &str( 练习代码):
pub fn strtok(s: &mut &str, delimiter: char) -> &str { if let Some(i) = s.find(delimiter) { let prefix = &s[..i]; // 由于 delimiter 可以是 utf8,所以我们需要获得其 utf8 长度, // 直接使用 len 返回的是字节长度,会有问题 let suffix = &s[(i + delimiter.len_utf8())..]; *s = suffix; prefix } else { // 如果没找到,返回整个字符串,把原字符串指针 s 指向空串 let prefix = *s; *s = ""; prefix } } fn main() { let s = "hello world".to_owned(); let mut s1 = s.as_str(); let hello = strtok(&mut s1, ' '); println!("hello is: {}, s1: {}, s: {}", hello, s1, s); }
当我们尝试运行这段代码时,会遇到生命周期相关的编译错误。类似刚才讲的示例代码,是因为按照编译器的规则, &mut &str 添加生命周期后变成 &'b mut &'a str,这将导致返回的 '&str 无法选择一个合适的生命周期。
要解决这个问题,我们首先要思考一下:返回值和谁的生命周期有关?是指向字符串引用的可变引用 &mut ,还是字符串引用 &str 本身?
显然是后者。所以,我们可以为 strtok 添加生命周期标注:
#![allow(unused)] fn main() { pub fn strtok<'b, 'a>(s: &'b mut &'a str, delimiter: char) -> &'a str {...} }
因为返回值的生命周期跟字符串引用有关,我们只为这部分的约束添加标注就可以了,剩下的标注交给编译器自动添加,所以代码也可以简化成如下这样,让编译器将其扩展成上面的形式:
#![allow(unused)] fn main() { pub fn strtok<'a>(s: &mut &'a str, delimiter: char) -> &'a str {...} }
最终,正常工作的代码如下( 练习代码_改),可以通过编译:
pub fn strtok<'a>(s: &mut &'a str, delimiter: char) -> &'a str { if let Some(i) = s.find(delimiter) { let prefix = &s[..i]; let suffix = &s[(i + delimiter.len_utf8())..]; *s = suffix; prefix } else { let prefix = *s; *s = ""; prefix } } fn main() { let s = "hello world".to_owned(); let mut s1 = s.as_str(); let hello = strtok(&mut s1, ' '); println!("hello is: {}, s1: {}, s: {}", hello, s1, s); }
为了帮助你更好地理解这个函数的生命周期关系,我将每个堆上和栈上变量的关系画了个图供你参考。
这里跟你分享一个小技巧:如果你觉得某段代码理解或者分析起来很困难,也可以画类似的图,从最基础的数据在堆和栈上的关系开始想,就很容易厘清脉络。
在处理生命周期时,编译器会根据一定规则自动添加生命周期的标注。然而,当自动标注产生冲突时,需要我们手工标注。
生命周期标注的目的是,在参数和返回值之间建立联系或者约束。调用函数时,传入的参数的生命周期需要大于等于(outlive)标注的生命周期。
当每个函数都添加好生命周期标注后,编译器,就可以从函数调用的上下文中分析出,在传参时,引用的生命周期,是否和函数签名中要求的生命周期匹配。如果不匹配,就违背了“引用的生命周期不能超出值的生命周期”,编译器就会报错。
如果你搞懂了函数的生命周期标注,那么数据结构的生命周期标注也是类似。比如下面的例子,Employee 的 name 和 title 是两个字符串引用,Employee 的生命周期不能大于它们,否则会访问失效的内存,因而我们需要妥善标注:
#![allow(unused)] fn main() { struct Employee<'a, 'b> { name: &'a str, title: &'b str, age: u8, } }
使用数据结构时,数据结构自身的生命周期,需要小于等于其内部字段的所有引用的生命周期。
小结
今天我们介绍了静态生命周期和动态生命周期的概念,以及编译器如何识别值和引用的生命周期。
根据所有权规则,值的生命周期可以确认,它可以一直存活到所有者离开作用域;而引用的生命周期不能超过值的生命周期。在同一个作用域下,这是显而易见的。然而, 当发生函数调用时,编译器需要通过函数的签名来确定,参数和返回值之间生命周期的约束。
大多数情况下,编译器可以通过上下文中的规则,自动添加生命周期的约束。如果无法自动添加,则需要开发者手工来添加约束。一般,我们只需要确定好返回值和哪个参数的生命周期相关就可以了。而对于数据结构,当内部有引用时,我们需要为引用标注生命周期。
思考题
- 如果我们把 strtok() 函数的签名写成这样,会发生什么问题?为什么它会发生这个问题?你可以试着编译一下看看。
#![allow(unused)] fn main() { pub fn strtok<'a>(s: &'a mut &str, delimiter: char) -> &'a str {...} }
- 回顾 第 6 讲SQL查询工具 的代码,现在,看看你是不是对代码中的生命周期标注有了更深理解?
感谢你的收听,你已经打卡 Rust 学习10次啦!
如果你觉得有收获,也欢迎你分享给你身边的朋友,邀他一起讨论。坚持学习,我们下节课见。
参考资料
- 栈上的内存不必特意释放,顶多是编译时编译器不再允许该变量被访问。因为栈上的内存会随着栈帧的结束而结束。如果你有点模糊,可以再看看 前置知识,温习一下栈和堆。
- Rust 的 I/O 安全性目前是 “almost safety”,为什么不是完全安全,感兴趣的同学可以看这个 RFC。
- 更多 关于 Box::leak 的信息。
- ArcInner 的结构。
- Rust 的生命周期管理一直在进化,进化方向是在常见的场景下,尽量避免因为生命周期的处理,代码不得不换成不那么容易阅读的写作方式。比如下面的代码:
use std::collections::HashMap; fn main() { let mut map = HashMap::new(); map.insert("hello", "world"); let key = "hello1"; // 按照之前的说法,这段代码无法编译通过,因为同一个 scope 下不能有两个可变引用 // 但因为 RFC2094 non-lexical lifetimes,Rust 编译器可以处理这个场景, // 因为当 None 时,map.get_mut() 的引用实际已经结束 match map.get_mut(key) /* <----- 可变引用的生命周期一直持续到 match 结果 */ { Some(v) => do_something(v), None => { map.insert(key, "tyr"); // <--- 这里又获得了一个可变引用 } } } fn do_something(_v: &mut &str) { todo!() }
如果你对此感兴趣,想了解更多,可以参看: RFC2094 - Non-lexical lifetimes。我们在平时写代码时,可以就像这段代码这样先按照正常的方式去写,如果编译器抱怨,再分析引用的生命周期,换个写法。此外,随时保持你的 Rust 版本是最新的,也有助于让你的代码总是可以使用最简单的方式撰写。
内存管理:从创建到消亡,值都经历了什么?
你好,我是陈天。
初探 Rust 以来,我们一直在学习有关所有权和生命周期的内容,想必现在,你对 Rust 内存管理的核心思想已经有足够理解了。
通过单一所有权模式,Rust 解决了堆内存过于灵活、不容易安全高效地释放的问题,既避免了手工释放内存带来的巨大心智负担和潜在的错误;又避免了全局引入追踪式 GC 或者 ARC 这样的额外机制带来的效率问题。
不过所有权模型也引入了很多新概念,从 Move / Copy / Borrow 语义到生命周期管理,所以学起来有些难度。
但是,你发现了吗,其实大部分新引入的概念,包括 Copy 语义和值的生命周期,在其它语言中都是隐式存在的,只不过 Rust 把它们定义得更清晰,更明确地界定了使用的范围而已。
今天我们沿着之前的思路,先梳理和总结 Rust 内存管理的基本内容,然后从一个值的奇幻之旅讲起,看看在内存中,一个值,从创建到消亡都经历了什么,把之前讲的融会贯通。
到这里你可能有点不耐烦了吧,怎么今天又要讲内存的知识。其实是因为, 内存管理是任何编程语言的核心,重要性就像武学中的内功。只有当我们把数据在内存中如何创建、如何存放、如何销毁弄明白,之后阅读代码、分析问题才会有一种游刃有余的感觉。
内存管理
我们在 第一讲 说过堆和栈,它们是代码中使用内存的主要场合。
栈内存“分配”和“释放”都很高效,在编译期就确定好了,因而它无法安全承载动态大小或者生命周期超出帧存活范围外的值。所以,我们需要运行时可以自由操控的内存,也就是堆内存,来弥补栈的缺点。
堆内存足够灵活,然而堆上数据的生命周期该如何管理,成为了各门语言的心头大患。
C 采用了未定义的方式,由开发者手工控制;C++ 在 C 的基础上改进,引入智能指针,半手工半自动。Java 和 DotNet 使用 GC 对堆内存全面接管,堆内存进入了受控(managed)时代。所谓受控代码(managed code),就是代码在一个“运行时”下工作,由运行时来保证堆内存的安全访问。
整个堆内存生命周期管理的发展史如下图所示:
而Rust 的创造者们,重新审视了堆内存的生命周期,发现 大部分堆内存的需求在于动态大小,小部分需求是更长的生命周期。所以它默认将堆内存的生命周期和使用它的栈内存的生命周期绑在一起,并留了个小口子 leaked机制,让堆内存在需要的时候,可以有超出帧存活期的生命周期。
我们看下图的对比总结:
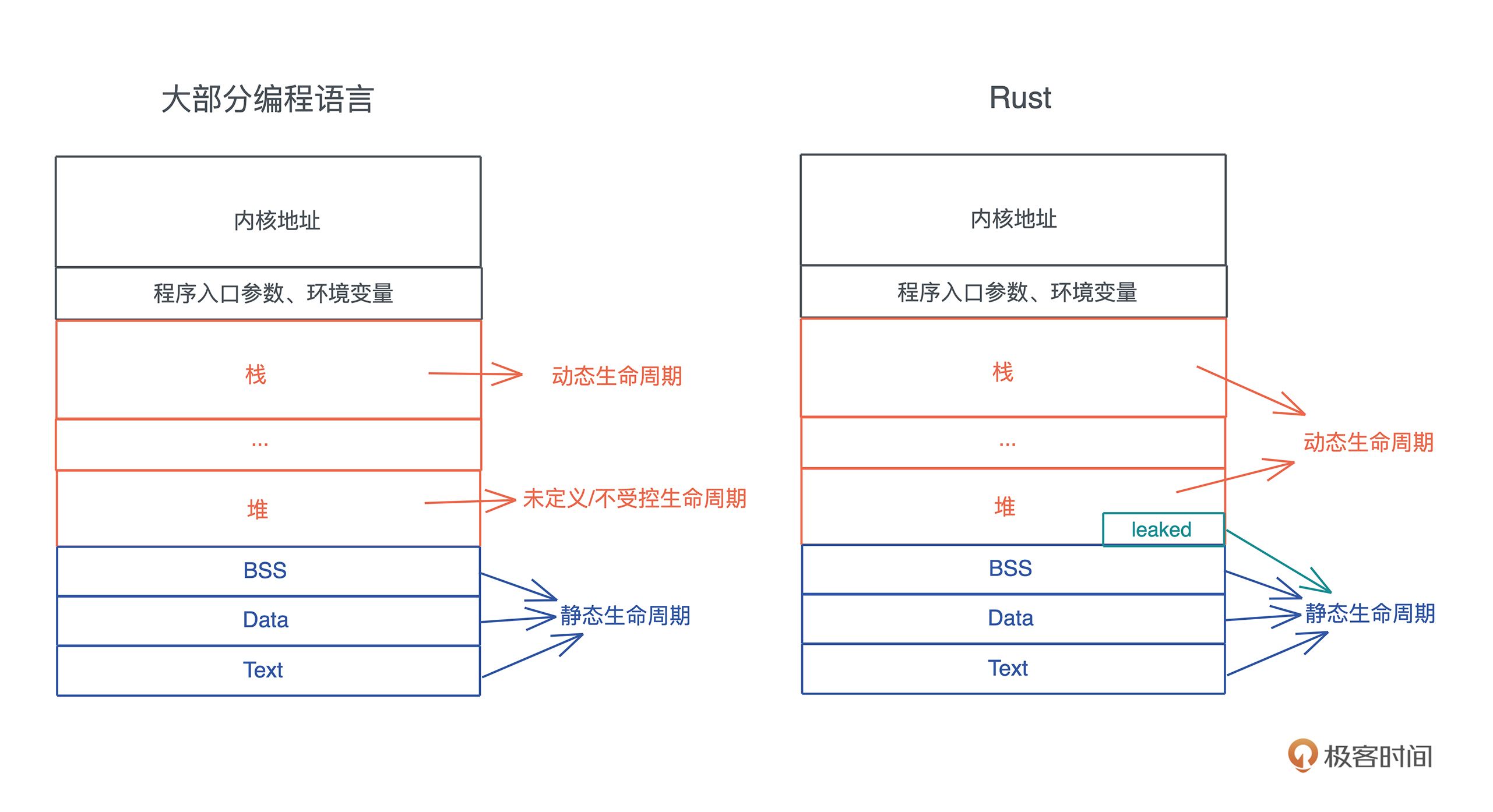
有了这些基本的认知,我们再看看在值的创建、使用和销毁的过程中, Rust 是如何管理内存的。
希望学完今天的内容之后,看到一个 Rust 的数据结构,你就可以在脑海中大致浮现出,这个数据结构在内存中的布局:哪些字段在栈上、哪些在堆上,以及它大致的大小。
值的创建
当我们为数据结构创建一个值,并将其赋给一个变量时,根据值的性质,它有可能被创建在栈上,也有可能被创建在堆上。
简单回顾一下,我们在 第一、 第二讲 说过,理论上,编译时可以确定大小的值都会放在栈上,包括 Rust 提供的原生类型比如字符、数组、元组(tuple)等,以及开发者自定义的固定大小的结构体(struct)、枚举(enum) 等。
如果数据结构的大小无法确定,或者它的大小确定但是在使用时需要更长的生命周期,就最好放在堆上。
接下来我们来看 struct / enum / vec
struct
Rust 在内存中排布数据时, 会根据每个域的对齐(aligment)对数据进行重排,使其内存大小和访问效率最好。比如,一个包含 A、B、C 三个域的 struct,它在内存中的布局可能是 A、C、B: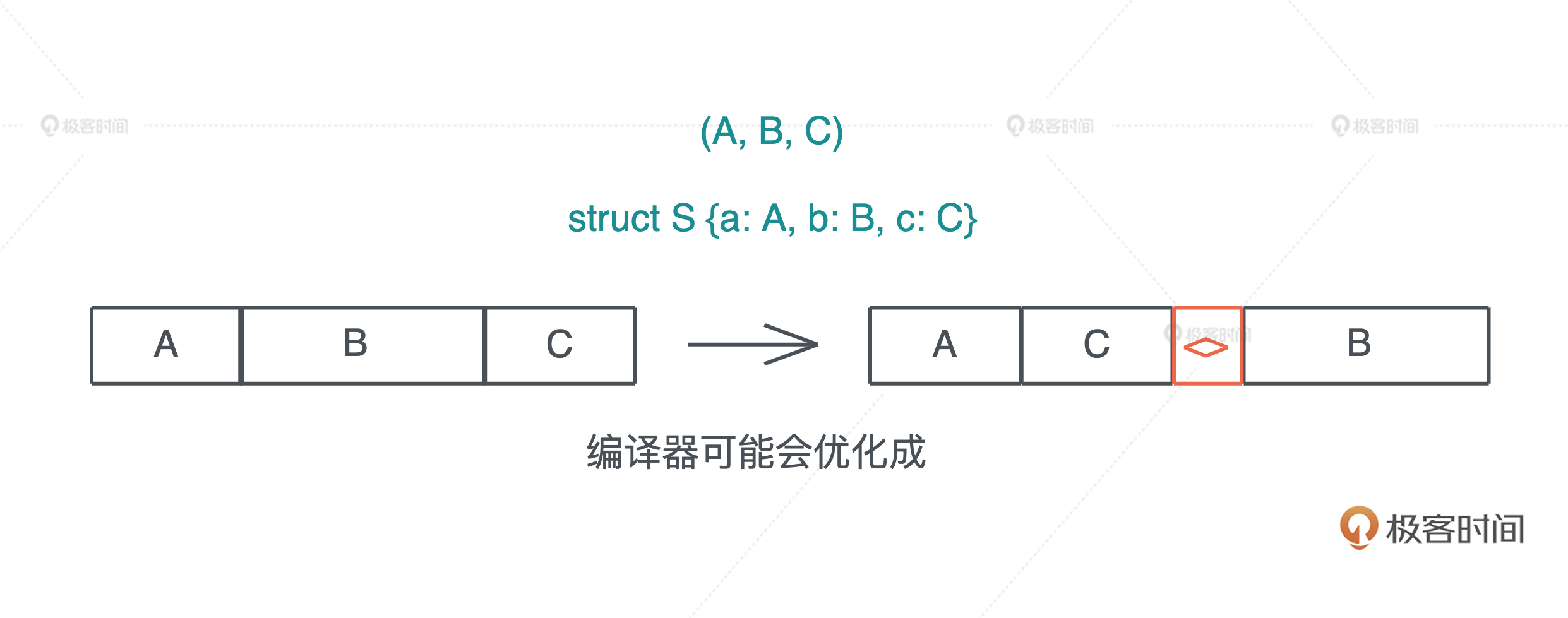
为什么 Rust 编译器会这么做呢?
我们先看看 C 语言在内存中表述一个结构体时遇到的问题。来写一段代码,其中两个数据结构 S1 和 S2 都有三个域 a、b、c,其中 a 和 c 是 u8,占用一个字节,b 是 u16,占用两个字节。S1 在定义时顺序是 a、b、c,而 S2 在定义时顺序是 a、c、b:
猜猜看 S1 和 S2 的大小是多少?
#include <stdio.h>
struct S1 {
u_int8_t a;
u_int16_t b;
u_int8_t c;
};
struct S2 {
u_int8_t a;
u_int8_t c;
u_int16_t b;
};
void main() {
printf("size of S1: %d, S2: %d", sizeof(struct S1), sizeof(struct S2));
}
正确答案是:6 和 4。
为什么明明只用了 4 个字节,S1 的大小却是 6 呢?这是因为 CPU 在加载不对齐的内存时,性能会急剧下降,所以 要避免用户定义不对齐的数据结构时,造成的性能影响。
对于这个问题,C 语言会对结构体会做这样的处理:
- 首先确定每个域的长度和对齐长度,原始类型的对齐长度和类型的长度一致。
- 每个域的起始位置要和其对齐长度对齐,如果无法对齐,则添加 padding 直至对齐。
- 结构体的对齐大小和其最大域的对齐大小相同,而结构体的长度则四舍五入到其对齐的倍数。
字面上看这三条规则,你是不是觉得像绕口令,别担心,我们结合刚才的代码再来看,其实很容易理解。
对于 S1,字段 a 是 u8 类型,所以其长度和对齐都是 1,b 是 u16,其长度和对齐是 2。然而因为 a 只占了一个字节,b 的偏移是 1,根据第二条规则,起始位置和 b 的长度无法对齐,所以编译器会添加一个字节的 padding,让 b 的偏移为 2,这样 b 就对齐了。
随后 c 长度和对齐都是 1,不需要 padding。这样算下来,S1 的大小是 5,但根据上面的第三条规则,S1 的对齐是 2,和 5 最接近的“2 的倍数”是 6,所以 S1 最终的长度是 6。其实,这最后一条规则是为了让 S1 放在数组中,可以有效对齐。
所以, 如果结构体的定义考虑地不够周全,会为了对齐浪费很多空间。我们看到,保存同样的数据,S1 和 S2 的大小相差了 50%。
使用 C 语言时,定义结构体的最佳实践是,充分考虑每一个域的对齐,合理地排列它们,使其内存使用最高效。这个工作由开发者做会很费劲,尤其是嵌套的结构体,需要仔细地计算才能得到最优解。
而 Rust 编译器替我们自动完成了这个优化,这就是为什么 Rust 会自动重排你定义的结构体,来达到最高效率。我们看同样的代码,在 Rust 下,S1 和 S2 大小都是 4( 代码):
use std::mem::{align_of, size_of}; struct S1 { a: u8, b: u16, c: u8, } struct S2 { a: u8, c: u8, b: u16, } fn main() { println!("sizeof S1: {}, S2: {}", size_of::<S1>(), size_of::<S2>()); println!("alignof S1: {}, S2: {}", align_of::<S1>(), align_of::<S2>()); }
你也可以看这张图来直观对比, C 和 Rust 的行为:
虽然,Rust 编译器默认为开发者优化结构体的排列,但你也可以使用 #[repr] 宏,强制让 Rust 编译器不做优化,和 C 的行为一致,这样,Rust 代码可以方便地和 C 代码无缝交互。
在明白了 Rust 下 struct 的布局后( tuple 类似),我们看看 enum 。
enum
enum 我们之前讲过,在 Rust 下它是一个标签联合体(tagged union),它的大小是标签的大小,加上最大类型的长度。
第三讲 基础语法中,我们定义 enum 数据结构时,简单提到有 Option
根据刚才说的三条对齐规则,tag 后的内存,会根据其对齐大小进行对齐,所以对于 Option
下图展示了 enum、Option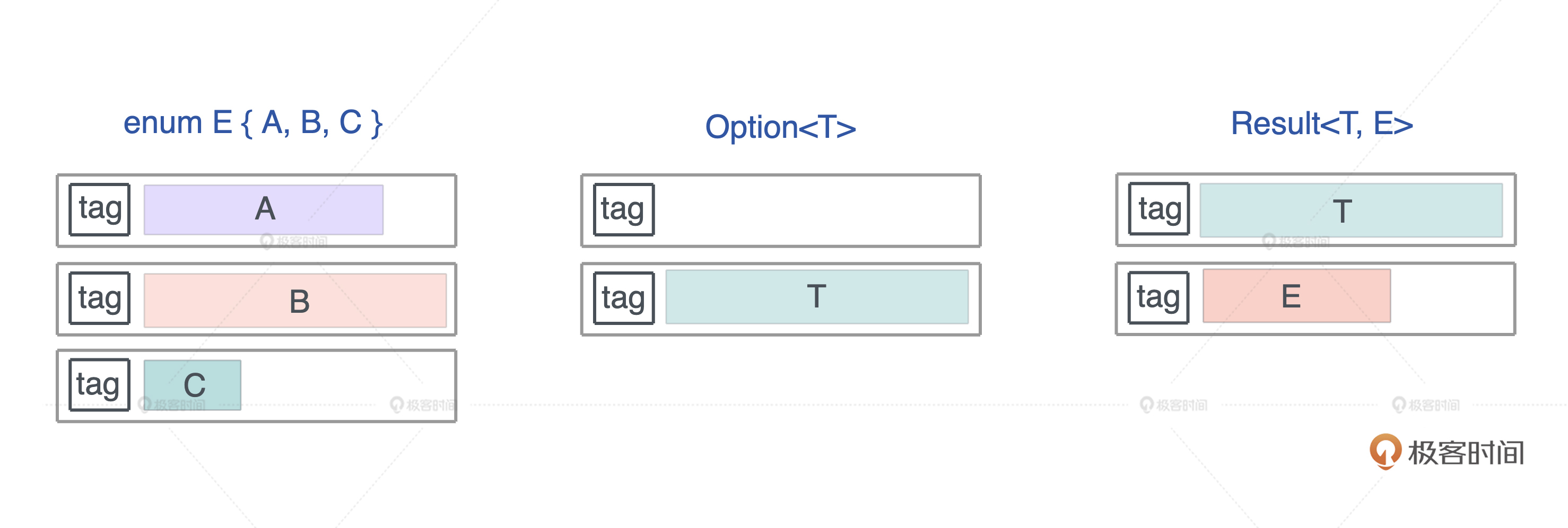
值得注意的是,Rust 编译器会对 enum 做一些额外的优化,让某些常用结构的内存布局更紧凑。我们先来写一段代码,帮你更好地了解不同数据结构占用的大小( 代码):
use std::collections::HashMap; use std::mem::size_of; enum E { A(f64), B(HashMap<String, String>), C(Result<Vec<u8>, String>), } // 这是一个声明宏,它会打印各种数据结构本身的大小,在 Option 中的大小,以及在 Result 中的大小 macro_rules! show_size { (header) => { println!( "{:<24} {:>4} {} {}", "Type", "T", "Option<T>", "Result<T, io::Error>" ); println!("{}", "-".repeat(64)); }; ($t:ty) => { println!( "{:<24} {:4} {:8} {:12}", stringify!($t), size_of::<$t>(), size_of::<Option<$t>>(), size_of::<Result<$t, std::io::Error>>(), ) }; } fn main() { show_size!(header); show_size!(u8); show_size!(f64); show_size!(&u8); show_size!(Box<u8>); show_size!(&[u8]); show_size!(String); show_size!(Vec<u8>); show_size!(HashMap<String, String>); show_size!(E); }
这段代码包含了一个声明宏(declarative macro)show_size,我们先不必管它。运行这段代码时,你会发现,Option 配合带有引用类型的数据结构,比如 &u8、Box、Vec、HashMap , 没有额外占用空间,这就很有意思了。
Type T Option<T> Result<T, io::Error>
----------------------------------------------------------------
u8 1 2 24
f64 8 16 24
&u8 8 8 24
Box<u8> 8 8 24
&[u8] 16 16 24
String 24 24 32
Vec<u8> 24 24 32
HashMap<String, String> 48 48 56
E 56 56 64
对于 Option 结构而言,它的 tag 只有两种情况:0 或 1, tag 为 0 时,表示 None,tag 为 1 时,表示 Some。
正常来说,当我们把它和一个引用放在一起时,虽然 tag 只占 1 个 bit,但 64 位 CPU 下,引用结构的对齐是 8,所以它自己加上额外的 padding,会占据 8 个字节,一共16字节,这非常浪费内存。怎么办呢?
Rust 是这么处理的,我们知道,引用类型的第一个域是个指针,而指针是不可能等于 0 的,但是我们 可以复用这个指针:当其为 0 时,表示 None,否则是 Some,减少了内存占用,这是个非常巧妙的优化,我们可以学习。
vec 和 String
从刚才代码的结果中,我们也看到 String 和 Vec
而 Vec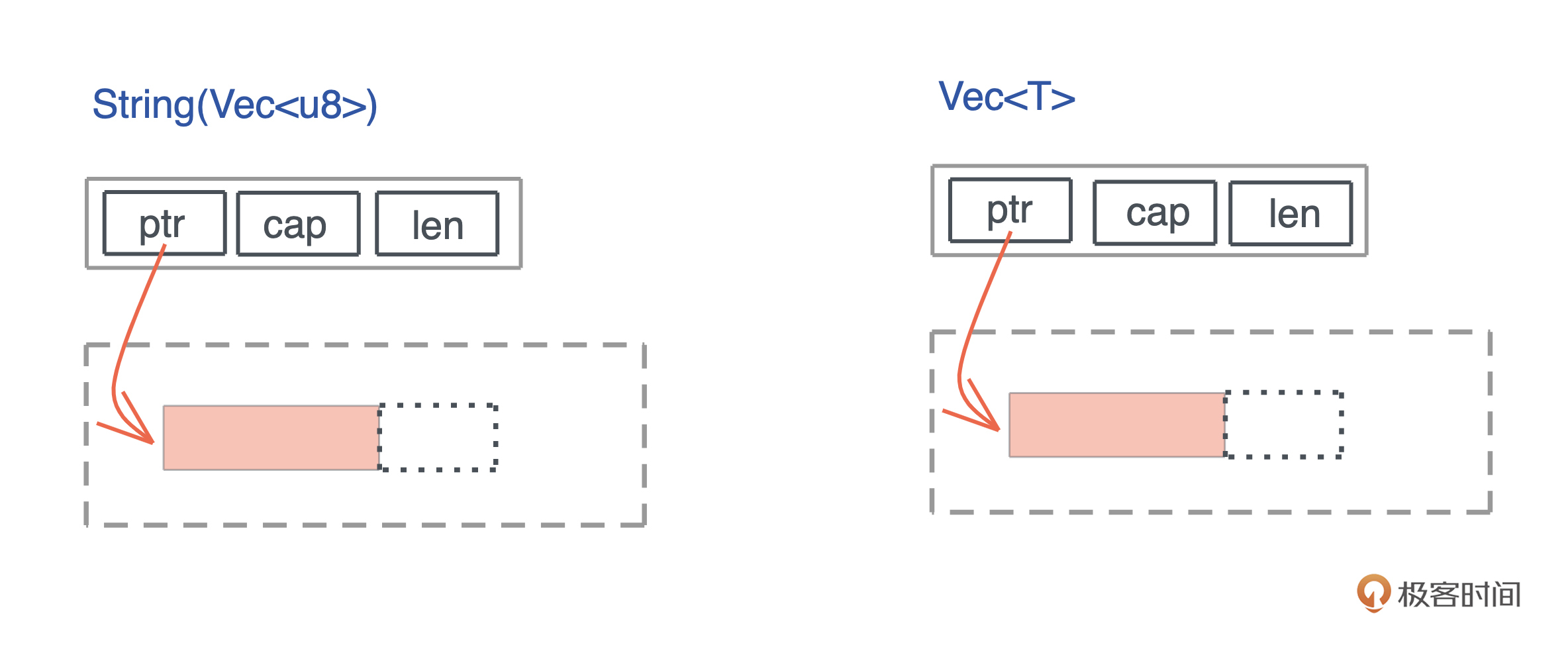
很多动态大小的数据结构,在创建时都有类似的内存布局: 栈内存放的胖指针,指向堆内存分配出来的数据,我们之前介绍的 Rc 也是如此。
关于值在创建时的内存布局,今天就先讲这么多。如果你对其它数据结构的内存布局感兴趣,可以访问 cheats.rs,它是 Rust 语言的备忘清单,非常适合随时翻阅。比如,引用类型的内存布局:
现在,值已经创建成功了,我们对它的内存布局有了足够的认识。那在使用期间,它的内存会发生什么样的变化呢,我们接着看。
值的使用
在讲所有权的时候,我们知道了,对 Rust 而言,一个值如果没有实现 Copy,在赋值、传参以及函数返回时会被 Move。
其实 Copy 和 Move 在内部实现上,都是浅层的按位做内存复制,只不过 Copy 允许你访问之前的变量,而 Move 不允许。我们看图: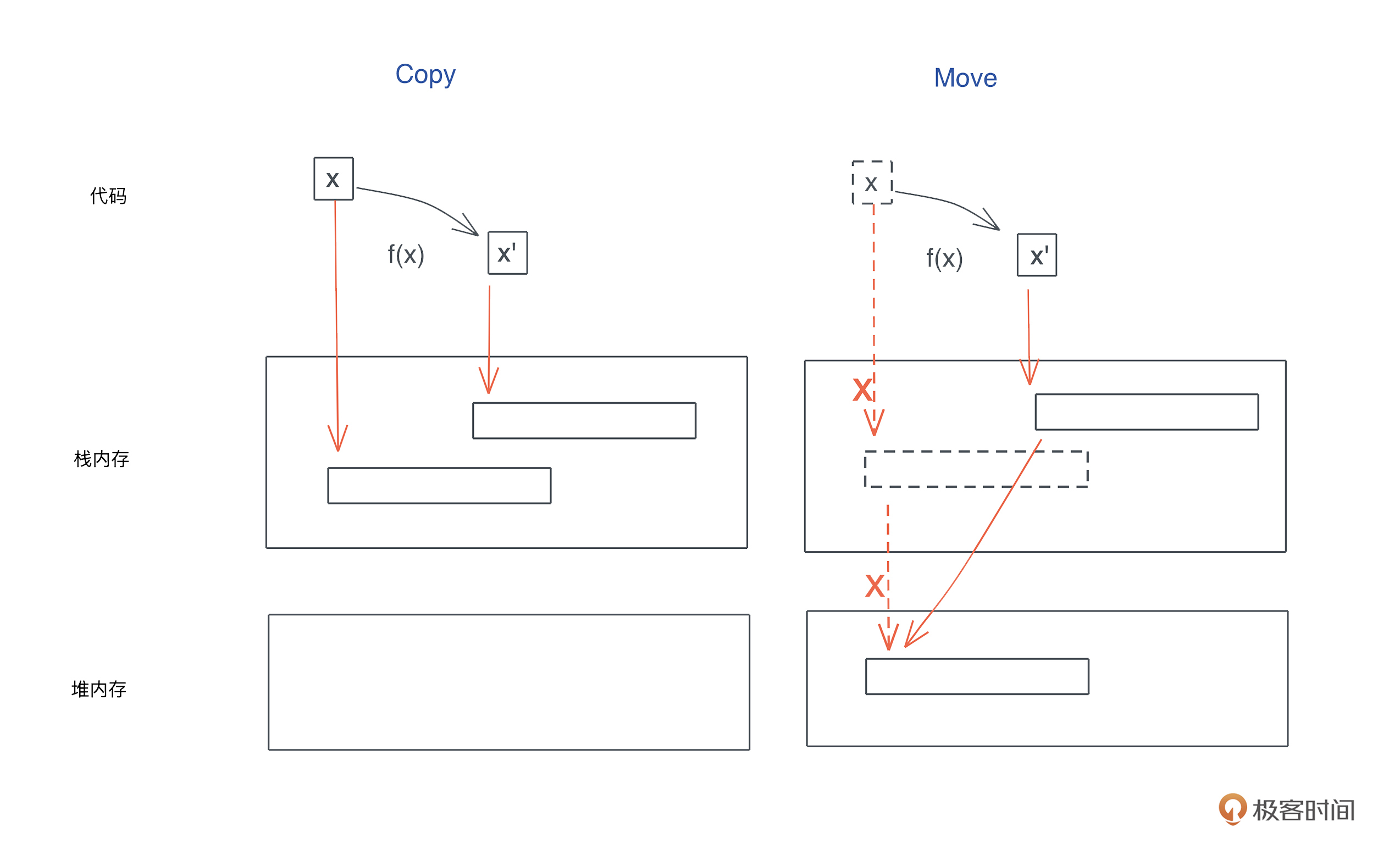
在我们的认知中,内存复制是个很重的操作,效率很低。确实是这样,如果你的关键路径中的每次调用,都要复制几百 k 的数据,比如一个大数组,是很低效的。
但是,如果你要复制的只是原生类型(Copy)或者栈上的胖指针(Move),不涉及堆内存的复制也就是深拷贝(deep copy),那这个效率是非常高的,我们不必担心每次赋值或者每次传参带来的性能损失。
所以,无论是 Copy 还是 Move,它的效率都是非常高的。
不过也有一个例外,要说明:对栈上的大数组传参,由于需要复制整个数组,会影响效率。所以,一般我们 建议在栈上不要放大数组,如果实在需要,那么传递这个数组时,最好用传引用而不是传值。
在使用值的过程中,除了 Move,你还需要注意值的动态增长。因为Rust 下,集合类型的数据结构,都会在使用过程中自动扩展。
以一个 Vecshrink_to_fit 方法,来节约对内存的使用。
值的销毁
好,这个值的旅程已经过半,创建和使用都已经讲完了,最后我们谈谈值的销毁。
之前笼统地谈到,当所有者离开作用域,它拥有的值会被丢弃。那从代码层面讲,Rust 到底是如何丢弃的呢?
这里用到了 Drop trait。Drop trait 类似面向对象编程中的析构函数, 当一个值要被释放,它的 Drop trait 会被调用。比如下面的代码,变量 greeting 是一个字符串,在退出作用域时,其 drop() 函数被自动调用,释放堆上包含 “hello world” 的内存,然后再释放栈上的内存: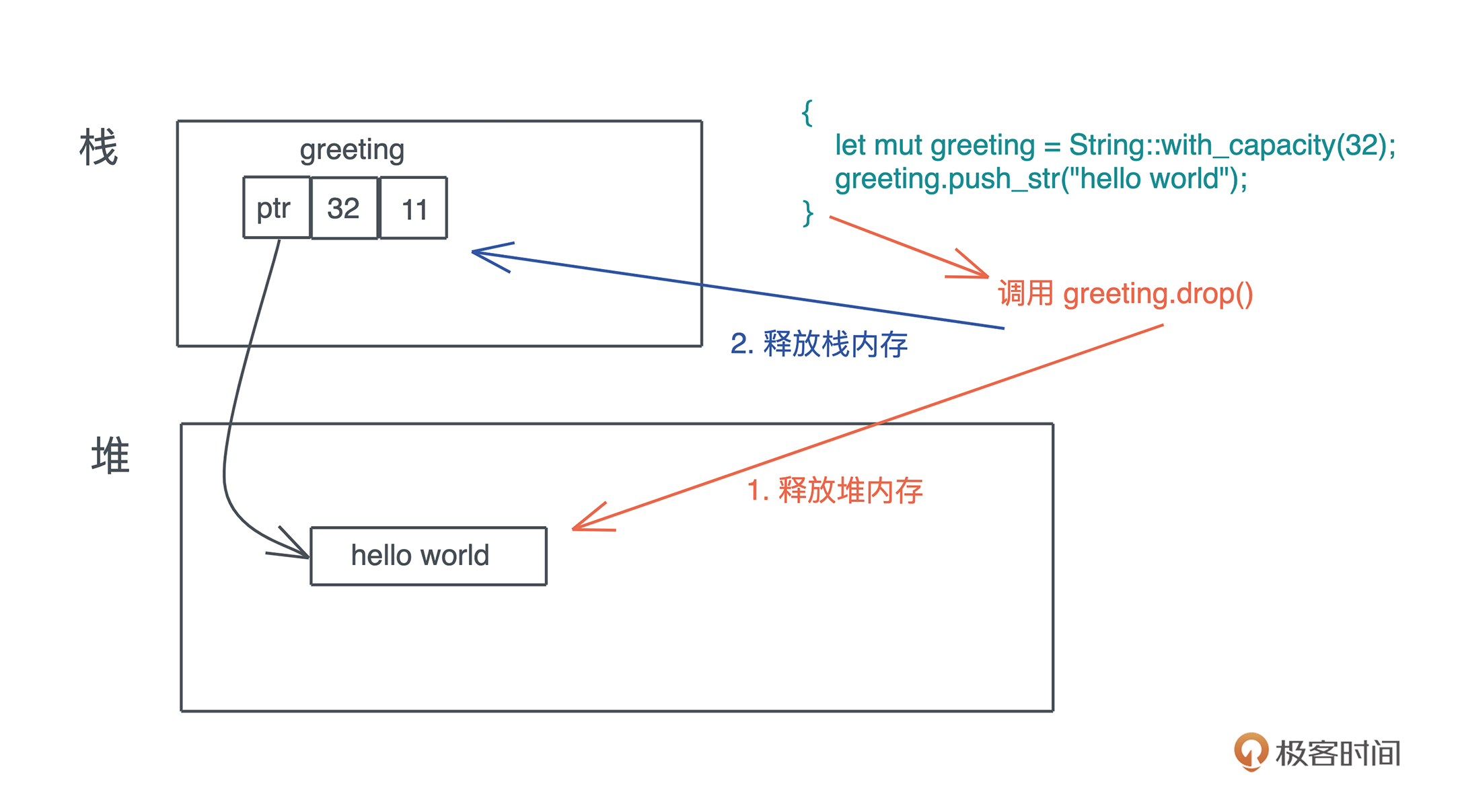
如果要释放的值是一个复杂的数据结构,比如一个结构体,那么这个结构体在调用 drop() 时,会依次调用每一个域的 drop() 函数,如果域又是一个复杂的结构或者集合类型,就会递归下去,直到每一个域都释放干净。
我们可以看这个例子: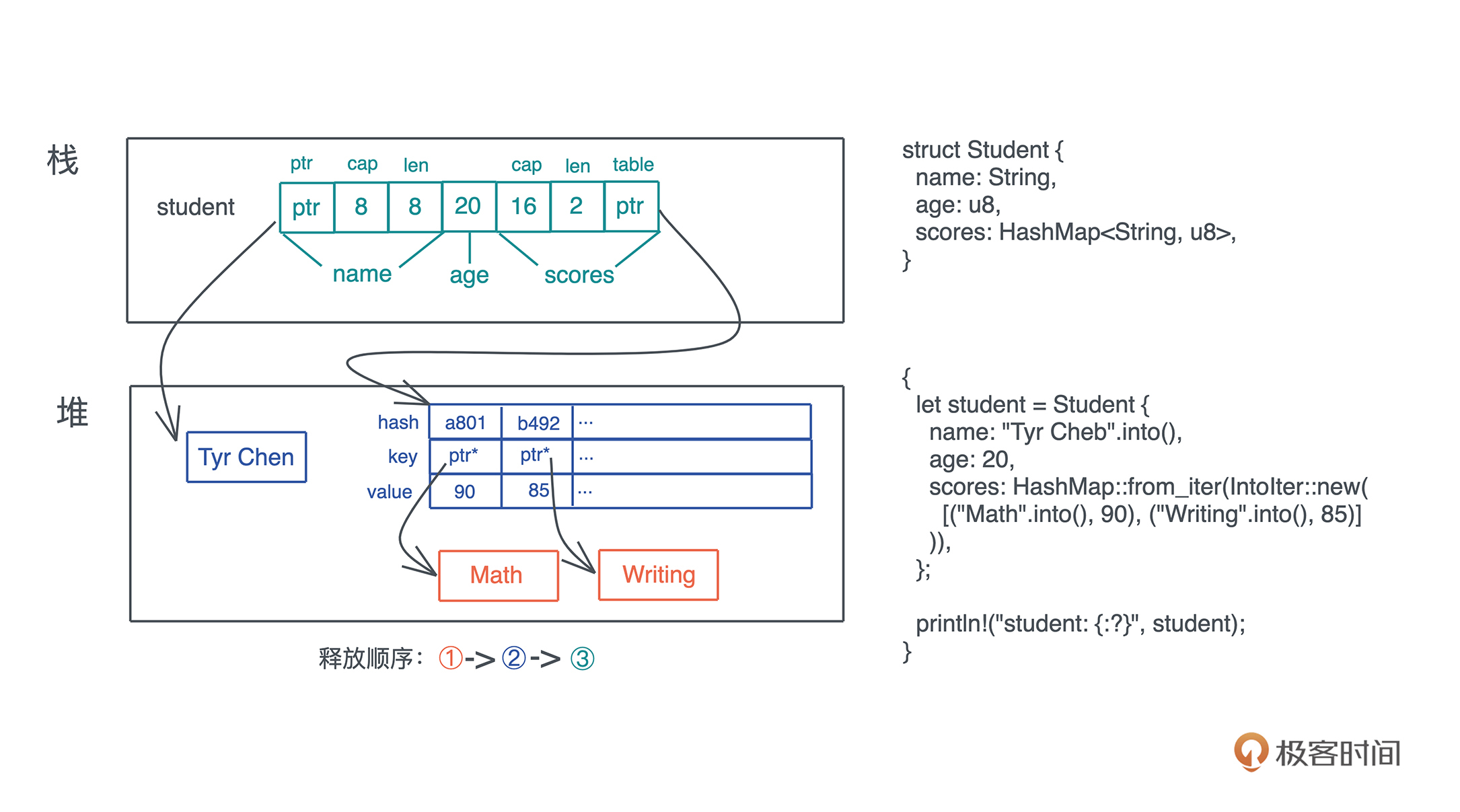
代码中的 student 变量是一个结构体,有 name、age、scores。其中 name 是 String,scores 是 HashMap,它们本身需要额外 drop()。又因为 HashMap 的 key 是 String,所以还需要进一步调用这些 key 的 drop()。整个释放顺序从内到外是:先释放 HashMap 下的 key,然后释放 HashMap 堆上的表结构,最后释放栈上的内存。
堆内存释放
所有权机制规定了,一个值只能有一个所有者,所以在释放堆内存的时候,整个过程简单清晰,就是单纯调用 Drop trait,不需要有其他顾虑。这种对值安全,也没有额外负担的释放能力,是 Rust 独有的。
我觉得 Rust 在内存管理方面的设计特别像蚁群。在蚁群中,每个个体的行为都遵循着非常简单死板的规范,最终, 大量简单的个体能构造出一个高效且不出错的系统。
反观其它语言,每个个体或者说值,都非常灵活,引用传来传去,最终却构造出来一个很难分析的复杂系统。单靠编译器无法决定,每个值在各个作用域中究竟能不能安全地释放,导致系统,要么像 C/C++ 一样将这个重担部分或者全部地交给开发者,要么像 Java 那样构建另一个系统来专门应对内存安全释放的问题。
在Rust里,你自定义的数据结构,绝大多数情况下,不需要实现自己的 Drop trait,编译器缺省的行为就足够了。但是,如果你想自己控制 drop 行为,你也可以为这些数据结构实现它。
如果你定义的 drop() 函数和系统自定义的 drop() 函数都 drop() 某个域,Rust 编译器会确保,这个域只会被 drop 一次。至于 Drop trait 怎么实现、有什么注意事项、什么场合下需要自定义,我们在后续的课程中会再详细展开。
释放其他资源
我们刚才讲 Rust 的 Drop trait 主要是为了应对堆内存释放的问题,其实,它还可以释放任何资源,比如 socket、文件、锁等等。Rust 对所有的资源都有很好的 RAII 支持。
比如我们创建一个文件 file,往里面写入 “hello world”,当 file 离开作用域时,不但它的内存会被释放,它占用的资源、操作系统打开的文件描述符,也会被释放,也就是文件会自动被关闭。( 代码)
use std::fs::File; use std::io::prelude::*; fn main() -> std::io::Result<()> { let mut file = File::create("foo.txt")?; file.write_all(b"hello world")?; Ok(()) }
在其他语言中,无论 Java、Python 还是 Golang,你都需要显式地关闭文件,避免资源的泄露。这是因为,即便 GC 能够帮助开发者最终释放不再引用的内存,它并不能释放除内存外的其它资源。
而 Rust,再一次地,因为其清晰的所有权界定,使编译器清楚地知道:当一个值离开作用域的时候,这个值不会有任何人引用,它占用的任何资源,包括内存资源,都可以立即释放,而不会导致问题(也有例外,感兴趣可以看这个 RFC)。
说到这,你也许觉得不用显式地关闭文件、关闭 socket、释放锁,不过是省了一句 “close()” 而已,有什么大不了的?
然而,不要忘了,在庞大的业务代码中,还有很大一部分要用来处理错误。当错误处理搅和进来,我们面对的代码,逻辑更复杂,需要添加 close() 调用的上下文更多。虽然Python 的 with、Golang 的 defer,可以一定程度上解决资源释放的问题,但还不够完美。
一旦,多个变量和多种异常或者错误叠加,我们忘记释放资源的风险敞口会成倍增加,很多死锁或者资源泄露就是这么产生的。
从 Drop trait 中我们再一次看到,从事物的本原出发解决问题,会极其优雅地解决掉很多其他关联问题。好比,所有权,几个简单规则,就让我们顺带处理掉了资源释放的大难题。
小结
我们进一步探讨了 Rust 的内存管理,在所有权和生命周期管理的基础上,介绍了一个值在内存中创建、使用和销毁的过程,学习了数据结构在创建时,是如何在内存中布局的,大小和对齐之间的关系;数据在使用过程中,是如何 Move 和自动增长的;以及数据是如何销毁的。
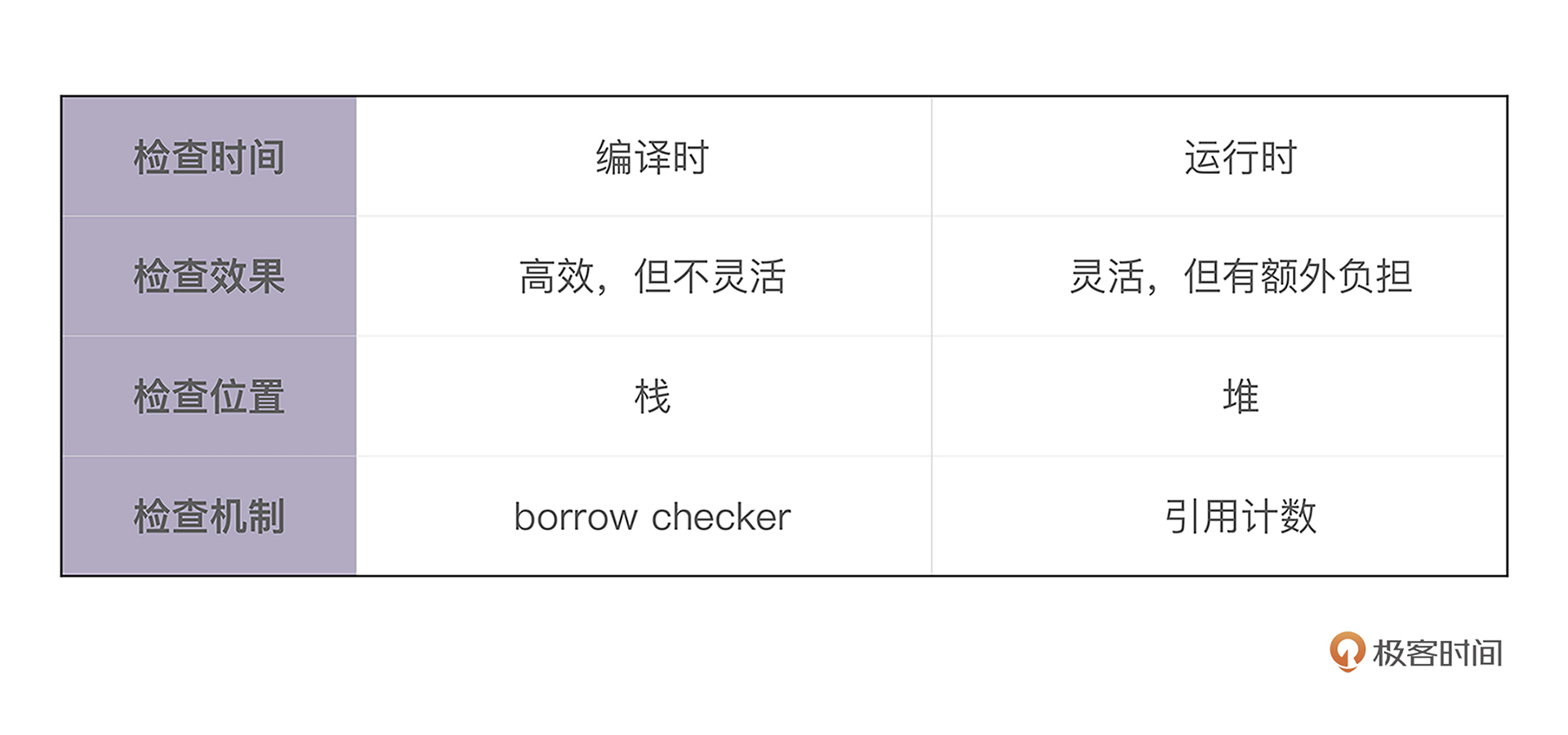
数据结构在内存中的布局,尤其是哪些部分放在栈上,哪些部分放在堆上,非常有助于我们理解代码的结构和效率。
你不必强行记忆这些内容,只要有个思路,在需要的时候,翻阅本文或者 cheats.rs 即可。当我们掌握了数据结构如何创建、在使用过程中如何 Move 或者 Copy、最后如何销毁,我们在阅读别人的代码或者自己撰写代码时就会更加游刃有余。
思考题
Result<String, ()> 占用多少内存?为什么?
感谢你的收听,如果你觉得有收获,也欢迎你分享给你身边的朋友,邀他一起讨论。你的Rust学习第11次打卡完成,我们下节课见。
参考资料
- Rust 语言的备忘清单 cheats.rs
- 代码受这个 Stack Overflow 帖子 启发,有删改
- String 结构的 源码
- Vec
结构 源码 - RAII 是一个拗口的名词,中文意思是“资源获取即初始化”。
加餐|愚昧之巅:你的Rust学习常见问题汇总
你好,我是陈天。
到目前为止,我们已经学了很多 Rust 的知识,比如基本语法、内存管理、所有权、生命周期等,也展示了三个非常有代表性的示例项目,让你了解接近真实应用环境的 Rust 代码是什么样的。
虽然学了这么多东西,你是不是还是有种“一学就会,一写就废”的感觉?别着急,饭要一口一口吃,任何新知识的学习都不是一蹴而就的,我们让子弹先飞一会。你也可以鼓励一下自己,已经完成了这么多次打卡,继续坚持。
在今天这个加餐里我们就休个小假,调整一下学习节奏,来聊一聊 Rust 开发中的常见问题,希望可以解决你的一些困惑。
所有权问题
Q: 如果我想创建双向链表,该怎么处理?
Rust 标准库有 LinkedList,它是一个双向链表的实现。但是当你需要使用链表的时候,可以先考虑一下, 同样的需求是否可以用列表 Vec
如果你只是好奇如何实现双向链表,那么可以用之前讲的 Rc / RefCell ( 第9讲)来实现。对于链表的 next 指针,你可以用 Rc;对于 prev 指针,可以用 Weak。
Weak 相当于一个弱化版本的 Rc,不参与到引用计数的计算中,而Weak 可以 upgrade 到 Rc 来使用。如果你用过其它语言的引用计数数据结构,你应该对 Weak 不陌生,它可以帮我们打破循环引用。感兴趣的同学可以自己试着实现一下,然后对照这个 参考实现。
你也许好奇为什么 Rust 标准库的 LinkedList 不用 Rc/Weak,那是因为标准库直接用 NonNull 指针和 unsafe。
Q: 编译器总告诉我:“use of moved value” 错误,该怎么破?
这是我们初学 Rust 时经常会遇到的错误,这个错误是说 你在试图访问一个所有权已经移走的变量。
对于这样的错误,首先你要判断,这个变量真的需要被移动到另一个作用域下么?如果不需要,可不可以使用借用?( 第8讲)如果的确需要移动给另一个作用域的话:
- 如果需要多个所有者共享同一份数据,可以使用 Rc / Arc,辅以 Cell / RefCell / Mutex / RwLock。( 第9讲)
- 如果不需要多个所有者共享,那可以考虑实现 Clone 甚至 Copy。( 第7讲)
生命周期问题
Q: 为什么我的函数返回一个引用的时候,编译器总是跟我过不去?
函数返回引用时,除非是静态引用,那么这个引用一定和带有引用的某个输入参数有关。输入参数可能是 &self、&mut self 或者 &T / &mut T。 我们要建立正确的输入和返回值之间的关系,这个关系和函数内部的实现无关,只和函数的签名有关。
比如 HashMap 的 get() 方法:
#![allow(unused)] fn main() { pub fn get<Q: ?Sized>(&self, k: &Q) -> Option<&V> where K: Borrow<Q>, Q: Hash + Eq }
我们并不用实现它或者知道它如何实现,就可以确定返回值 Option<&V> 到底跟谁有关系。因为这里只有两个选择:&self 或者 k: &Q。显然是 &self,因为 HashMap 持有数据,而 k 只是用来在 HashMap 里查询的 key。
这里为什么不需要使用生命周期参数呢?因为我们之前讲的规则: 当 &self / &mut self 出现时,返回值的生命周期和它关联。( 第10讲)这是一个很棒的规则,因为大部分方法,如果返回引用,它基本上是引用 &self 里的某个数据。
如果你能搞明白这一层关系,那么就比较容易处理,函数返回引用时出现的生命周期错误。
当你要返回在函数执行过程中,创建的或者得到的数据,和参数无关,那么 无论它是一个有所有权的数据,还是一个引用,你只能返回带所有权的数据。对于引用,这就意味着调用 clone() 或者 to_owned() 来,从引用中得到所有权。
数据结构问题
Q: 为什么 Rust 字符串这么混乱,有 String、&String、&str 这么多不同的表述?
我不得不说,这是一个很有误导性的问题,因为这个问题有点胡乱总结的倾向,很容易把人带到沟里。
首先,任何数据结构 T,都可以有指向它的引用 &T, 所以 String 跟 &String的区别,以及 String 跟 &str的区别,压根是两个问题。
更好的问题是:为什么有了 String,还要有 &str?或者,更通用的问题:为什么 String、Vec
一旦问到点子上,答案不言自喻,因为切片是一个非常通用的数据结构。
用过 Python 的人都知道:
s = "hello world"
let slice1 = s[:5] # 可以对字符串切片
let slice2 = slice1[1:3] # 可以对切片再切片
print(slice1, slice2) # 打印 hello, el
这和 Rust 的 String 切片何其相似:
#![allow(unused)] fn main() { let s = "hello world".to_string(); let slice1 = &s[..5]; // 可以对字符串切片 let slice2 = &slice1[1..3]; // 可以对切片再切片 println!("{} {}", slice1, slice2); // 打印 hello el }
所以 &str 是 String 的切片,也可以是 &str 的切片。它和 &[T] 一样,没有什么特别的,就是一个带着长度的胖指针,指向了一片连续的内存区域。
你可以这么理解: 切片之于 Vec
Q: 在课程的示例代码中,用了很多 unwrap(),这样可以么?
当我们需要从 Option 或者 Result<T, E> 中获得数据时,可以使用 unwrap(),这是示例代码出现 unwrap() 的原因。
如果我们只是写一些学习性质的代码,那么 unwrap() 是可以接受的,但在生产环境中,除非你可以确保 unwrap() 不会引发 panic!(),否则应该使用模式匹配来处理数据,或者使用错误处理的 ? 操作符。我们后续会有专门一讲聊 Rust 的错误处理。
那什么情况下我们可以确定 unwrap() 不会 panic 呢?如果在做 unwrap() 之前, Option
#![allow(unused)] fn main() { // 假设 v 是一个 Vec<T> if v.is_empty() { return None; } // 我们现在确定至少有一个数据,所以 unwrap 是安全的 let first = v.pop().unwrap(); }
Q: 为什么标准库的数据结构比如 Rc / Vec 用那么多 unsafe,但别人总是告诉我,unsafe 不好?
好问题。C 语言的开发者也认为 asm 不好,但 C 的很多库里也大量使用 asm。
标准库的责任是,在保证安全的情况下,即使牺牲一定的可读性,也要用最高效的手段来实现要实现的功能;同时,为标准库的用户提供一个优雅、高级的抽象,让他们可以在绝大多数场合下写出漂亮的代码,无需和丑陋打交道。
Rust中,unsafe 代码把程序的正确性和安全性交给了开发者来保证,而标准库的开发者花了大量的精力和测试来保证这种正确性和安全性。而我们自己撰写 unsafe 代码时,除非有经验丰富的开发者 review 代码,否则,有可能疏于对并发情况的考虑,写出了有问题的代码。
所以只要不是必须,建议不要写 unsafe 代码。 毕竟大部分我们要处理的问题,都可以通过良好的设计、合适的数据结构和算法来实现。
Q: 在 Rust 里,我如何声明全局变量呢?
在 第3讲 里,我们讲过 const 和 static,它们都可以用于声明全局变量。但注意,除非使用 unsafe,static 无法作为 mut 使用,因为这意味着它可能在多个线程下被修改,所以不安全:
static mut COUNTER: u64 = 0; fn main() { COUNTER += 1; // 编译不过,编译器告诉你需要使用 unsafe }
如果你的确想用可写的全局变量,可以用 Mutex
use lazy_static::lazy_static; use std::collections::HashMap; use std::sync::{Arc, Mutex}; lazy_static! { static ref HASHMAP: Arc<Mutex<HashMap<u32, &'static str>>> = { let mut m = HashMap::new(); m.insert(0, "foo"); m.insert(1, "bar"); m.insert(2, "baz"); Arc::new(Mutex::new(m)) }; } fn main() { let mut map = HASHMAP.lock().unwrap(); map.insert(3, "waz"); println!("map: {:?}", map); }
调试工具
Q: Rust 下,一般如何调试应用程序?
我自己一般会用 tracing 来打日志,一些简单的示例代码会使用 println! / dbg! ,来查看数据结构在某个时刻的状态。而在平时的开发中,我几乎不会用调试器设置断点单步跟踪。
因为与其浪费时间在调试上,不如多花时间做设计。 在实现的时候,添加足够清晰的日志,以及撰写合适的单元测试,来确保代码逻辑上的正确性。如果你发现自己总需要使用调试工具单步跟踪才能搞清楚程序的状态,说明代码没有设计好,过于复杂。
当我学习 Rust 时,会常用调试工具来查看内存信息,后续的课程中我们会看到,在分析有些数据结构时使用了这些工具。
Rust 下,我们可以用 rust-gdb 或 rust-lldb,它们提供了一些对 Rust 更友好的 pretty-print 功能,在安装 Rust 时,它们也会被安装。我个人习惯使用 gdb,但 rust-gdb 适合在 linux 下,在 OS X 下有些问题,所以我一般会切到 Ubuntu 虚拟机中使用 rust-gdb。
其它问题
Q: 为什么 Rust 编译出来的二进制那么大?为什么 Rust 代码运行起来那么慢?
如果你是用 cargo build 编译出来的,那很正常,因为这是个 debug build,里面有大量的调试信息。你可以用 cargo build --release 来编译出优化过的版本,它会小很多。另外,还可以通过很多方法进一步优化二进制的大小,如果你对此感兴趣,可以参考这个 文档。
Rust的很多库如果你不用 --release 来编译,它不会做任何优化,有时候甚至感觉比你的 Node.js 代码还慢。所以当你要把代码应用在生产环境,一定要使用 release build。
Q: 这门课使用什么样的 Rust 版本?会随着 2021 edition 更新么?
会的。Rust 是一门不断在发展的语言,每六周就会有一个新的版本诞生,伴随着很多新的功能。比如 const generics( 代码):
#[derive(Debug)] struct Packet<const N: usize> { data: [u8; N], } fn main() { let ip = Packet { data: [0u8; 20] }; let udp = Packet { data: [0u8; 8] }; println!("ip: {:?}, udp: {:?}", ip, udp); }
再比如最近刚发的 1.55 支持了 open range pattern( 代码):
fn main() { println!("{}", match_range(10001)); } fn match_range(v: usize) -> &'static str { match v { 0..=99 => "good", 100..=9999 => "unbelievable", 10000.. => "beyond expectation", _ => unreachable!(), } }
再过一个多月,Rust 就要发布 2021 edition 了。由于 Rust 良好的向后兼容能力,我建议保持使用最新的 Rust 版本。等 2021 edition 发布后,我会更新代码库到 2021 edition,文稿中的相应代码也会随之更新。
思考题
来一道简单的思考题,我们把之前学的内容融会贯通一下,代码展示了有问题的生命周期,你能找到原因么?( 代码)
#![allow(unused)] fn main() { use std::str::Chars; // 错误,为什么? fn lifetime1() -> &str { let name = "Tyr".to_string(); &name[1..] } // 错误,为什么? fn lifetime2(name: String) -> &str { &name[1..] } // 正确,为什么? fn lifetime3(name: &str) -> Chars { name.chars() } }
欢迎在留言区抢答,也非常欢迎你分享这段时间的学习感受,一起交流进步。我们下节课回归正文讲Rust的类型系统,下节课见!
类型系统:Rust的类型系统有什么特点?
你好,我是陈天。今天我们就开始类型系统的学习。
如果你用 C/Golang 这样不支持泛型的静态语言,或者用 Python/Ruby/JavaScript 这样的动态语言,这个部分可能是个难点,希望你做好要转换思维的准备;如果你用 C++/Java/Swift 等支持泛型的静态语言,可以比较一下 Rust 和它们的异同。
其实在之前的课程中,我们已经写了不少 Rust 代码,使用了各种各样的数据结构,相信你对 Rust 的类型系统已经有了一个非常粗浅的印象。那类型系统到底是什么?能用来干什么?什么时候用呢?今天就来一探究竟。
作为一门语言的核心要素,类型系统很大程度上塑造了语言的用户体验以及程序的安全性。为什么这么说?因为,在机器码的世界中,没有类型而言,指令仅仅和立即数或者内存打交道,内存中存放的数据都是字节流。
所以,可以说 类型系统完全是一种工具,编译器在编译时对数据做静态检查,或者语言在运行时对数据做动态检查的时候,来保证某个操作处理的数据是开发者期望的数据类型。
现在你是不是能理解,为什么Rust类型系统对类型问题的检查格外严格(总是报错)。
类型系统基本概念与分类
在具体讲 Rust 的类型系统之前,我们先来澄清一些类型系统的概念,在基本理解上达成一致。
在 第二讲 提到过,类型,是对值的区分,它包含了值在内存中的长度、对齐以及值可以进行的操作等信息。
比如 u32 类型,它是一个无符号 32 位整数,长度是 4 个字节,对齐也是 4 个字节,取值范围在 0~4G 之间;u32 类型实现了加减乘除、大小比较等接口,所以可以做类似 1 + 2、i <= 3 这样的操作。
类型系统其实就是,对类型进行定义、检查和处理的系统。所以,按对类型的操作阶段不同,就有了不同的划分标准,也对应有不同分类,我们一个一个看。
按定义后类型是否可以隐式转换,可以分为强类型和弱类型。Rust 不同类型间不能自动转换,所以是强类型语言,而 C / C++ / JavaScript 会自动转换,是弱类型语言。
按类型检查的时机,在编译时检查还是运行时检查,可以分为静态类型系统和动态类型系统。对于静态类型系统,还可以进一步分为显式静态和隐式静态,Rust / Java / Swift 等语言都是显式静态语言,而 Haskell 是隐式静态语言。
在类型系统中,多态是一个非常重要的思想,它是指 在使用相同的接口时,不同类型的对象,会采用不同的实现。
对于动态类型系统,多态通过 鸭子类型(duck typing) 实现;而对于静态类型系统,多态可以通过 参数多态(parametric polymorphism)、 特设多态(adhoc polymorphism) 和 子类型多态(subtype polymorphism) 实现。
- 参数多态是指,代码操作的类型是一个满足某些约束的参数,而非具体的类型。
- 特设多态是指同一种行为有多个不同实现的多态。比如加法,可以 1+1,也可以是 “abc” + “cde”、matrix1 + matrix2、甚至 matrix1 + vector1。在面向对象编程语言中,特设多态一般指函数的重载。
- 子类型多态是指,在运行时,子类型可以被当成父类型使用。
在 Rust 中,参数多态通过泛型来支持、特设多态通过 trait 来支持、子类型多态可以用 trait object 来支持,我们待会讲参数多态,下节课再详细讲另外两个。
你可以看下图来更好地厘清这些概念之间的关系:
Rust 类型系统
好,掌握了类型系统的基本概念和分类,再看 Rust 的类型系统。
按刚才不同阶段的分类,在定义时, Rust 不允许类型的隐式转换,也就是说,Rust 是强类型语言;同时在检查时,Rust 使用了静态类型系统,在编译期保证类型的正确。强类型加静态类型,使得 Rust 是一门类型安全的语言。
其实说到“类型安全”,我们经常听到这个术语,但是你真的清楚它是什么涵义吗?
从内存的角度看, 类型安全是指代码,只能按照被允许的方法,访问它被授权访问的内存。
以一个长度为 4,存放 u64 数据的数组为例,访问这个数组的代码,只能在这个数组的起始地址到数组的结束地址之间这片 32 个字节的内存中访问,而且访问是按照 8 字节来对齐的,另外,数组中的每个元素,只能做 u64 类型允许的操作。对此,编译器会对代码进行严格检查来保证这个行为。我们看下图: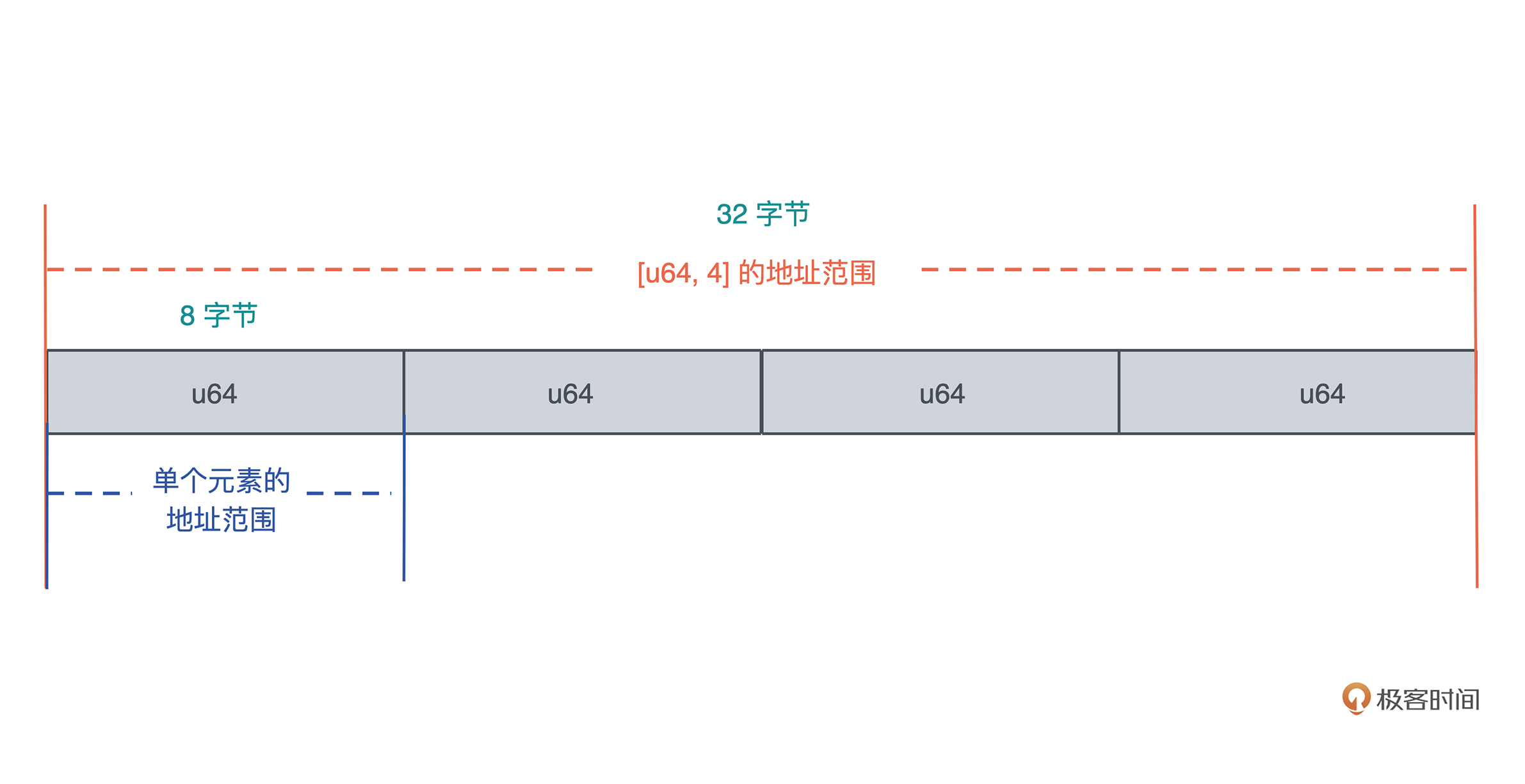
所以 C/C++ 这样,定义后数据可以隐式转换类型的弱类型语言,不是内存安全的,而 Rust 这样的强类型语言,是类型安全的,不会出现开发者不小心引入了一个隐式转换,导致读取不正确的数据,甚至内存访问越界的问题。
在此基础上,Rust 还进一步对内存的访问进行了读/写分开的授权。所以, Rust 下的内存安全更严格:代码只能按照被允许的方法和被允许的权限,访问它被授权访问的内存。
为了做到这么严格的类型安全,Rust 中除了 let / fn / static / const 这些定义性语句外,都是表达式,而一切表达式都有类型,所以可以说在 Rust 中,类型无处不在。
你也许会有疑问,那类似这样的代码,它的类型是什么?
if has_work {
do_something();
}
在Rust中,对于一个作用域,无论是 if / else / for 循环,还是函数,最后一个表达式的返回值就是作用域的返回值,如果表达式或者函数不返回任何值,那么它返回一个 unit () 。unit 是只有一个值的类型,它的值和类型都是 () 。
像上面这个 if 块,它的类型和返回值是 () ,所以当它被放在一个没有返回值的函数中,如下所示:
fn work(has_work: bool) {
if has_work {
do_something();
}
}
Rust 类型无处不在这个逻辑还是自洽的。
unit 的应用非常广泛,除了作为返回值,它还被大量使用在数据结构中,比如 Result<(), Error> 表示返回的错误类型中,我们只关心错误,不关心成功的值,再比如 HashSet 实际上是 HashMap<K, ()> 的一个类型别名。
到这里简单总结一下,我们了解到 Rust 是强类型/静态类型语言,并且在代码中,类型无处不在。
作为静态类型语言,Rust 提供了大量的数据类型,但是在使用的过程中,进行类型标注是很费劲的,所以Rust 类型系统贴心地提供了 类型推导。
而对比动态类型系统,静态类型系统还比较麻烦的是,同一个算法,对应输入的数据结构不同,需要有不同的实现,哪怕这些实现没有什么逻辑上的差异。对此,Rust 给出的答案是 泛型(参数多态)。
所以接下来,我们先看 Rust 有哪些基本的数据类型,然后了解一下类型推导是如何完成的,最后看 Rust 是如何支持泛型的。
数据类型
在第二讲中介绍了原生类型和组合类型的定义,今天就详细介绍一下这两种类型在 Rust 中的设计。
Rust 的原生类型包括字符、整数、浮点数、布尔值、数组(array)、元组(tuple)、切片(slice)、指针、引用、函数等,见下表( 参考链接):
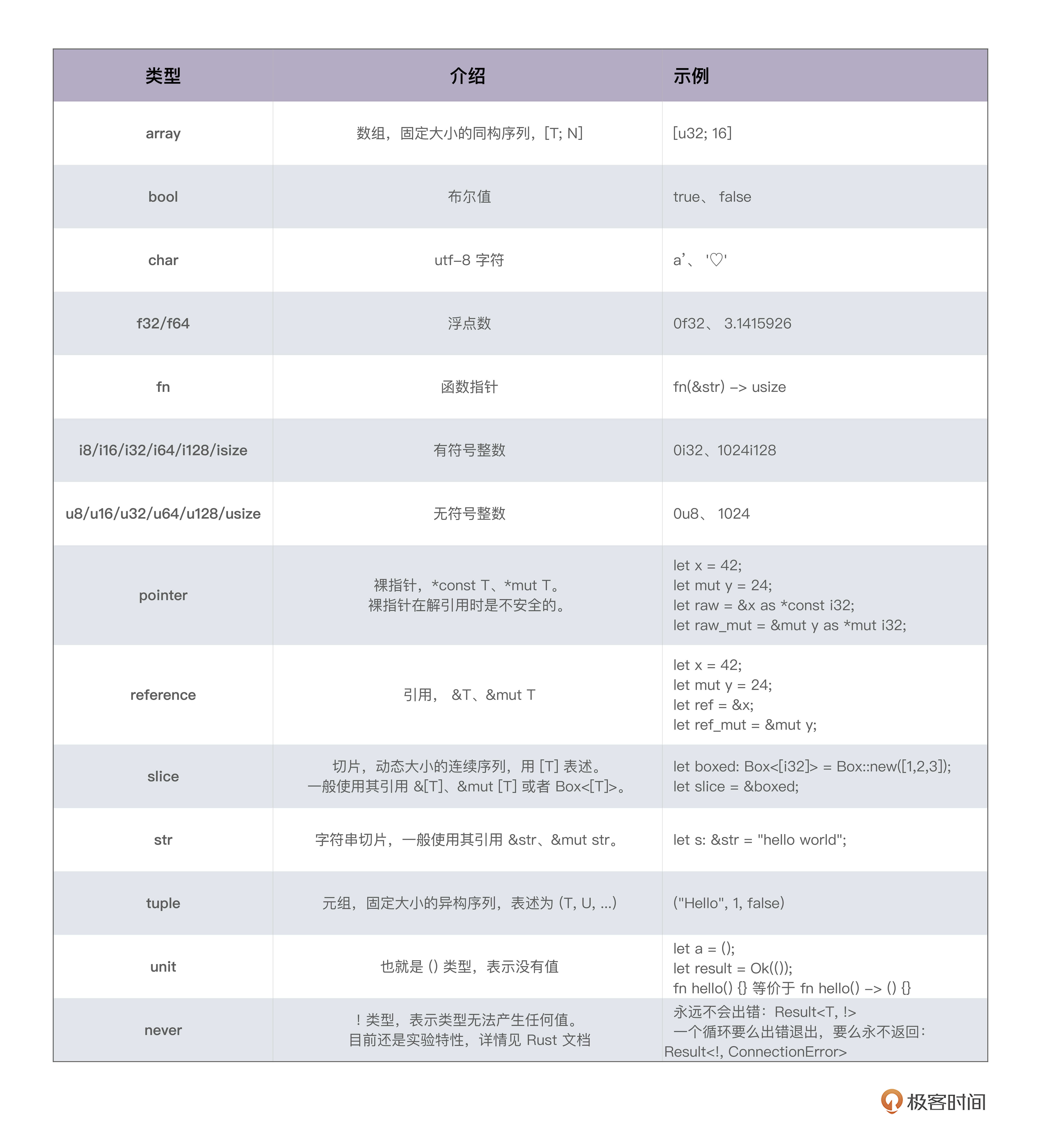
在原生类型的基础上,Rust 标准库还支持非常丰富的组合类型,看看已经遇到的:
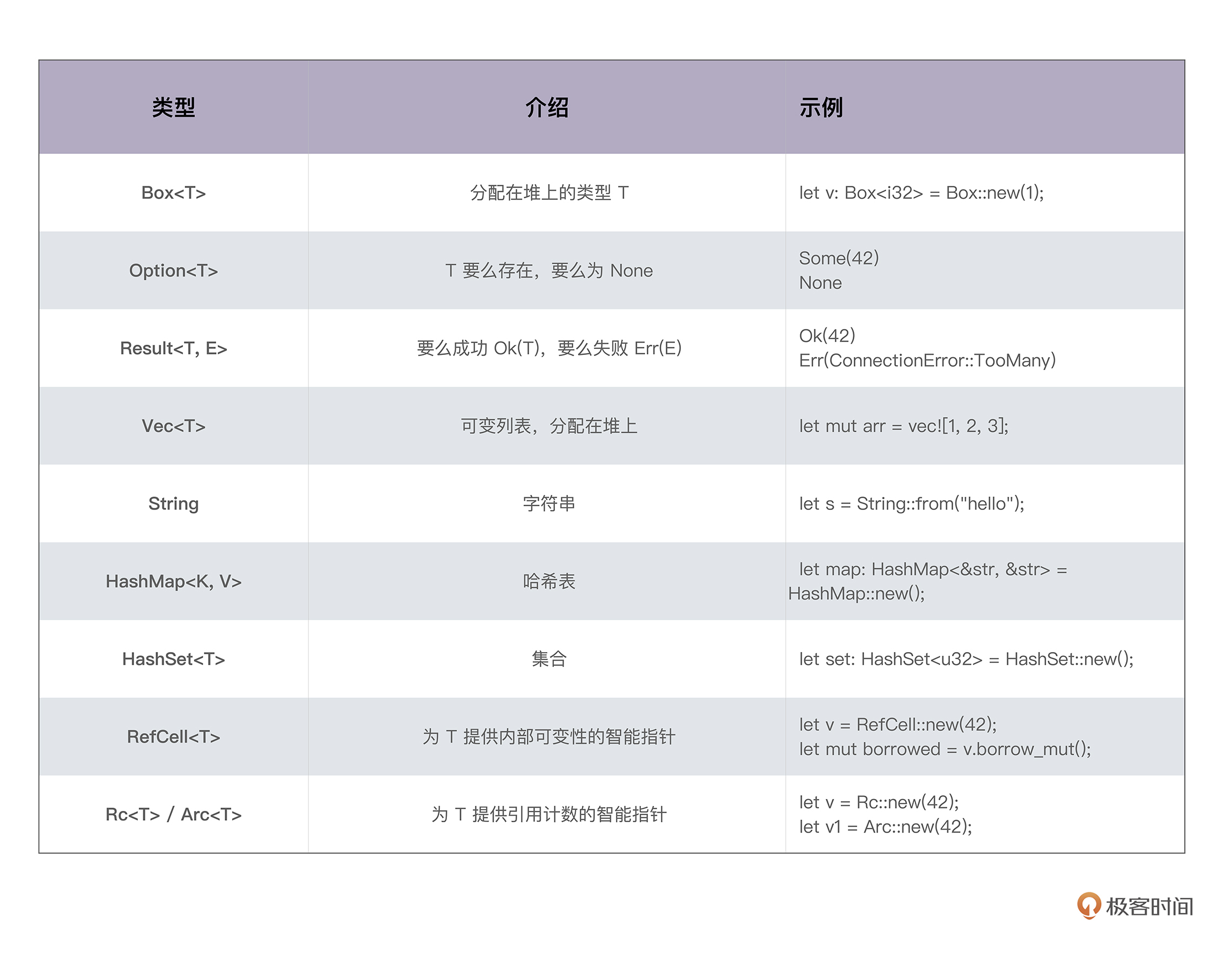
之后我们不断会遇到新的数据类型,推荐你有意识地记录一下,相信到最后,你的这个列表会积累得很长很长。
另外在 Rust 已有数据类型的基础上,你也可以使用结构体(struct)和标签联合(enum)定义自己的组合类型,之前已经有过详细的介绍,这里就不再赘述,你可以看下图回顾: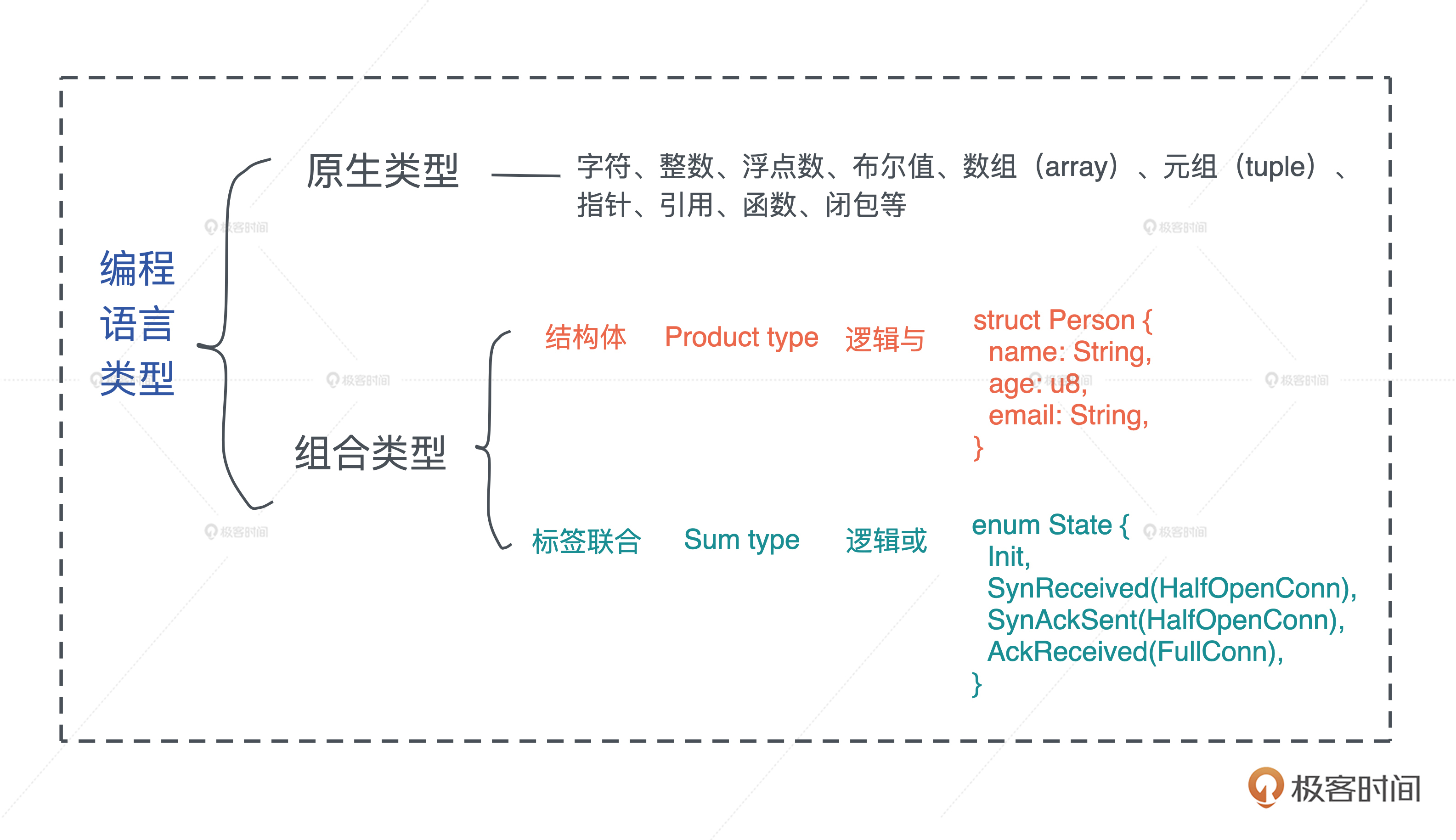
类型推导
作为静态类型系统的语言,虽然能够在编译期保证类型的安全,但一个很大的不便是,代码撰写起来很繁杂,到处都要进行类型的声明。尤其刚刚讲了 Rust 的数据类型相当多,所以,为了减轻开发者的负担,Rust 支持局部的类型推导。
在一个作用域之内,Rust 可以根据变量使用的上下文,推导出变量的类型,这样我们就不需要显式地进行类型标注了。比如这段 代码,创建一个 BTreeMap 后,往这个 map 里添加了 key 为 “hello”、value 为 “world” 的值:
use std::collections::BTreeMap; fn main() { let mut map = BTreeMap::new(); map.insert("hello", "world"); println!("map: {:?}", map); }
此时, Rust 编译器可以从上下文中推导出, BTreeMap<K, V> 的类型 K 和 V 都是字符串引用 &str,所以这段代码可以编译通过,然而,如果你把第 5 行这个作用域内的 insert 语句注释去掉,Rust 编译器就会报错:“cannot infer type for type parameter K”。
很明显, Rust 编译器需要足够的上下文来进行类型推导,所以有些情况下,编译器无法推导出合适的类型,比如下面的代码尝试把一个列表中的偶数过滤出来,生成一个新的列表( 代码):
fn main() { let numbers = vec![1, 2, 3, 4, 5, 6, 7, 8, 9, 10]; let even_numbers = numbers .into_iter() .filter(|n| n % 2 == 0) .collect(); println!("{:?}", even_numbers); }
collect 是 Iterator trait 的方法,它把一个 iterator 转换成一个集合。因为很多集合类型,如 Veccollect 究竟要返回什么类型,编译器是无法从上下文中推断的。
所以这段代码无法编译,它会给出如下错误:“consider giving even_numbers a type”。
这种情况,就无法依赖类型推导来简化代码了,必须让 even_numbers 有一个明确的类型。所以,我们可以使用类型声明( 代码):
fn main() { let numbers = vec![1, 2, 3, 4, 5, 6, 7, 8, 9, 10]; let even_numbers: Vec<_> = numbers .into_iter() .filter(|n| n % 2 == 0) .collect(); println!("{:?}", even_numbers); }
注意这里编译器只是无法推断出集合类型,但集合类型内部元素的类型,还是可以根据上下文得出,所以我们可以简写成 Vec<_> 。
除了给变量一个显式的类型外,我们也可以让 collect 返回一个明确的类型( 代码):
fn main() { let numbers = vec![1, 2, 3, 4, 5, 6, 7, 8, 9, 10]; let even_numbers = numbers .into_iter() .filter(|n| n % 2 == 0) .collect::<Vec<_>>(); println!("{:?}", even_numbers); }
你可以看到,在泛型函数后使用 ::<T> 来强制使用类型 T,这种写法被称为 turbofish。我们再看一个对 IP 地址和端口转换的例子( 代码):
use std::net::SocketAddr; fn main() { let addr = "127.0.0.1:8080".parse::<SocketAddr>().unwrap(); println!("addr: {:?}, port: {:?}", addr.ip(), addr.port()); }
turbofish 的写法在很多场景都有优势,因为在某些上下文中,你想直接把一个表达式传递给一个函数或者当成一个作用域的返回值,比如:
match data {
Some(s) => v.parse::<User>()?,
_ => return Err(...),
}
如果 User 类型在上下文无法被推导出来,又没有 turbofish 的写法,我们就不得不先给一个局部变量赋值时声明类型,然后再返回,这样代码就变得冗余了。
有些情况下, 即使上下文中含有类型的信息,也需要开发者为变量提供类型,比如常量和静态变量的定义。看一个例子( 代码):
const PI: f64 = 3.1415926; static E: f32 = 2.71828; fn main() { const V: u32 = 10; static V1: &str = "hello"; println!("PI: {}, E: {}, V {}, V1: {}", PI, E, V, V1); }
这可能是因为 const / static 主要用于定义全局变量,它们可以在不同的上下文中使用,所以为了代码的可读性,需要明确的类型声明。
用泛型实现参数多态
类型的定义和使用就讲到这里,刚才说过 Rust 通过泛型,来避免开发者为不同的类型提供不同的算法。一门静态类型语言不支持泛型,用起来是很痛苦的,比如我们熟悉的 Vec
所以我们现在来看看 Rust 对泛型的支持如何。今天先讲参数多态,它包括泛型数据结构和泛型函数,下一讲介绍特设多态和子类型多态。
泛型数据结构
Rust 对数据结构的泛型,或者说参数化类型,有着完整的支持。
在过去的学习中,其实你已经接触到了很多带有参数的数据类型,这些参数化类型可以极大地增强代码的复用性,减少代码的冗余。几乎所有支持静态类型系统的现代编程语言,都支持参数化类型,不过 Golang 目前是个例外。
我们从一个最简单的泛型例子 Option
#![allow(unused)] fn main() { enum Option<T> { Some(T), None, } }
这个数据结构你应该很熟悉了,T 代表任意类型,当 Option 有值时是 Some(T),否则是 None。
在定义刚才这个泛型数据结构的时候,你有没有这样的感觉,有点像在定义函数:
- 函数, 是把重复代码中的参数抽取出来,使其更加通用,调用函数的时候,根据参数的不同,我们得到不同的结果;
- 而泛型, 是把重复数据结构中的参数抽取出来,在使用泛型类型时,根据不同的参数,我们会得到不同的具体类型。
再来看一个复杂一点的泛型结构 Vec
#![allow(unused)] fn main() { pub struct Vec<T, A: Allocator = Global> { buf: RawVec<T, A>, len: usize, } pub struct RawVec<T, A: Allocator = Global> { ptr: Unique<T>, cap: usize, alloc: A, } }
Vec 有两个参数,一个是 T,是列表里的每个数据的类型,另一个是 A,它有进一步的限制 A: Allocator ,也就是说 A 需要满足 Allocator trait。
A 这个参数有默认值 Global,它是 Rust 默认的全局分配器,这也是为什么 Vec
在讲生命周期标注的时候,我们讲过,数据类型内部如果有借用的数据,需要显式地标注生命周期。其实在 Rust 里, 生命周期标注也是泛型的一部分,一个生命周期 'a 代表任意的生命周期,和 T 代表任意类型是一样的。
来看一个枚举类型 Cow
#![allow(unused)] fn main() { pub enum Cow<'a, B: ?Sized + 'a> where B: ToOwned, { // 借用的数据 Borrowed(&'a B), // 拥有的数据 Owned(<B as ToOwned>::Owned), } }
Cow(Clone-on-Write)是Rust中一个很有意思且很重要的数据结构。它就像 Option 一样,在返回数据的时候,提供了一种可能:要么返回一个借用的数据(只读),要么返回一个拥有所有权的数据(可写)。
这里你搞清楚泛型参数的约束就可以了,未来还会遇到 Cow,届时再详细讲它的用法。
对于拥有所有权的数据 B ,第一个是生命周期约束。这里 B 的生命周期是 'a,所以 B 需要满足 'a,这里和泛型约束一样,也是用 B: 'a 来表示。当 Cow 内部的类型 B 生命周期为 'a 时,Cow 自己的生命周期也是 'a。
B 还有两个约束:?Sized 和 “where B: ToOwned”。
在表述泛型参数的约束时,Rust 允许两种方式,一种类似函数参数的类型声明,用 “:” 来表明约束,多个约束之间用 + 来表示;另一种是使用 where 子句,在定义的结尾来表明参数的约束。两种方法都可以,且可以共存。
?Sized 是一种特殊的约束写法,? 代表可以放松问号之后的约束。由于 Rust 默认的泛型参数都需要是 Sized,也就是固定大小的类型,所以这里 ?Sized 代表用可变大小的类型。
ToOwned 是一个 trait,它可以把借用的数据克隆出一个拥有所有权的数据。
所以这里对 B 的三个约束分别是:
- 生命周期 'a
- 长度可变 ?Sized
- 符合 ToOwned trait
最后我解释一下 Cow 这个 enum 里 <B as ToOwned>::Owned 的含义:它对 B 做了一个强制类型转换,转成 ToOwned trait,然后访问 ToOwned trait 内部的 Owned 类型。
因为在 Rust 里,子类型可以强制转换成父类型,B 可以用 ToOwned 约束,所以它是 ToOwned trait 的子类型,因而 B 可以安全地强制转换成 ToOwned。这里 B as ToOwned 是成立的。
上面 Vec 和 Cow 的例子中,泛型参数的约束都发生在开头 struct 或者 enum 的定义中,其实,很多时候,我们也可以 在不同的实现下逐步添加约束,比如下面这个例子( 代码):
use std::fs::File; use std::io::{BufReader, Read, Result}; // 定义一个带有泛型参数 R 的 reader,此处我们不限制 R struct MyReader<R> { reader: R, buf: String, } // 实现 new 函数时,我们不需要限制 R impl<R> MyReader<R> { pub fn new(reader: R) -> Self { Self { reader, buf: String::with_capacity(1024), } } } // 定义 process 时,我们需要用到 R 的方法,此时我们限制 R 必须实现 Read trait impl<R> MyReader<R> where R: Read, { pub fn process(&mut self) -> Result<usize> { self.reader.read_to_string(&mut self.buf) } } fn main() { // 在 windows 下,你需要换个文件读取,否则会出错 let f = File::open("/etc/hosts").unwrap(); let mut reader = MyReader::new(BufReader::new(f)); let size = reader.process().unwrap(); println!("total size read: {}", size); }
逐步添加约束,可以让约束只出现在它不得不出现的地方,这样代码的灵活性最大。
泛型函数
了解了泛型数据结构是如何定义和使用的,再来看泛型函数,它们的思想类似。 在声明一个函数的时候,我们还可以不指定具体的参数或返回值的类型,而是由泛型参数来代替。对函数而言,这是更高阶的抽象。
一个简单的例子( 代码):
fn id<T>(x: T) -> T { return x; } fn main() { let int = id(10); let string = id("Tyr"); println!("{}, {}", int, string); }
这里,id() 是一个泛型函数,它接受一个带有泛型类型的参数,返回一个泛型类型。
对于泛型函数,Rust 会进行 单态化(Monomorphization) 处理,也就是在编译时,把所有用到的泛型函数的泛型参数展开,生成若干个函数。所以,刚才的 id() 编译后会得到一个处理后的多个版本( 代码):
fn id_i32(x: i32) -> i32 { return x; } fn id_str(x: &str) -> &str { return x; } fn main() { let int = id_i32(42); let string = id_str("Tyr"); println!("{}, {}", int, string); }
单态化的好处是,泛型函数的调用是静态分派(static dispatch),在编译时就一一对应,既保有多态的灵活性,又没有任何效率的损失,和普通函数调用一样高效。
但是对比刚才编译会展开的代码也能很清楚看出来,单态化有很明显的坏处,就是编译速度很慢, 一个泛型函数,编译器需要找到所有用到的不同类型,一个个编译,所以 Rust 编译代码的速度总被人吐槽,这和单态化脱不开干系(另一个重要因素是宏)。
同时,这样编出来的二进制会比较大,因为泛型函数的二进制代码实际存在 N 份。
还有一个可能你不怎么注意的问题: 因为单态化,代码以二进制分发会损失泛型的信息。如果我写了一个库,提供了如上的 id() 函数,使用这个库的开发者如果拿到的是二进制,那么这个二进制中必须带有原始的泛型函数,才能正确调用。但单态化之后,原本的泛型信息就被丢弃了。
小结
今天我们介绍了类型系统的一些基本概念以及 Rust 的类型系统。
用一张图描述了 Rust 类型系统的主要特征,包括其属性、数据结构、类型推导和泛型编程:
按类型定义、检查以及检查时能否被推导出来,Rust 是 强类型+静态类型+显式类型。
因为是静态类型,那么在写代码时常用的类型你需要牢牢掌握。为了避免静态类型要到处做类型标注的繁琐,Rust提供了类型推导。
在少数情况下,Rust 无法通过上下文进行类型推导,我们需要为变量显式地标注类型,或者通过 turbofish 语法,为泛型函数提供一个确定的类型。有个例外是在 Rust 代码中定义常量或者静态变量时,即使上下文中类型信息非常明确,也需要显式地进行类型标注。
在参数多态上,Rust 提供有完善支持的泛型。你可以使用和定义 泛型数据结构,在声明一个函数的时候,也可以不指定具体的参数或返回值的类型,而是由泛型参数来代替,也就是 泛型函数。它们的思想其实差不多,因为当数据结构可以泛型时,函数自然也就需要支持泛型。
另外,生命周期标注其实也是泛型的一部分,而对于泛型函数,在编译时会被单态化,导致编译速度慢。
下一讲我们接着介绍特设多态和子类型多态……
思考题
下面这段 代码 为什么不能编译通过?你可以修改它使其正常工作么?
use std::io::{BufWriter, Write}; use std::net::TcpStream; #[derive(Debug)] struct MyWriter<W> { writer: W, } impl<W: Write> MyWriter<W> { pub fn new(addr: &str) -> Self { let stream = TcpStream::connect("127.0.0.1:8080").unwrap(); Self { writer: BufWriter::new(stream), } } pub fn write(&mut self, buf: &str) -> std::io::Result<()> { self.writer.write_all(buf.as_bytes()) } } fn main() { let writer = MyWriter::new("127.0.0.1:8080"); writer.write("hello world!"); }
欢迎在留言区答题交流,你已经完成Rust学习的第12次打卡,我们下节课见!
参考资料
1.绝大多数支持静态类型系统的语言同时也会支持动态类型系统,因为单纯靠静态类型无法支持运行时的类型转换,比如 里氏替换原则。
里氏替换原则简单说就是子类型对象可以在程序中代替父类型对象。它是运行时多态的基础。所以如果要支持运行时多态,以及动态分派、后期绑定、反射等功能,编程语言需要支持动态类型系统。
2.动态类型系统的缺点是没有编译期的类型检查,程序不够安全,只能通过大量的单元测试来保证代码的健壮性。但使用动态类型系统的程序容易撰写,不用花费大量的时间来抠数据结构或者函数的类型。
所以一般用在脚本语言中,如 JavaScript / Python / Elixir。不过因为这些脚本语言越来越被用在大型项目中,所以它们也都有各自的类型标注的方法,来提供编译时的额外检查。
3.为了语言的简单易懂,编译高效,Golang 在设计之初没有支持泛型,但未来在 Golang 2 中也许会添加泛型。
4.当我们在堆上分配内存的时候,我们通过分配器来进行内存的分配,以及管理已分配的内存,包括增大(grow)、缩小(shrink)等。在处理某些情况下,默认的分配器也许不够高效,我们 可以使用 jemalloc 来分配内存。
5.如果你对各个语言是如何实现和处理泛型比较感兴趣的话,可以参考下图( 来源):
类型系统:如何使用trait来定义接口?
你好,我是陈天。
通过上一讲的学习,我们对 Rust 类型系统的本质有了认识。作为对类型进行定义、检查和处理的工具,类型系统保证了某个操作处理的数据类型是我们所希望的。
在Rust强大的泛型支持下,我们可以很方便地定义、使用泛型数据结构和泛型函数,并使用它们来处理参数多态,让输入输出参数的类型更灵活,增强代码的复用性。
今天我们继续讲多态中另外两种方式:特设多态和子类型多态,看看它们能用来解决什么问题、如何实现、如何使用。
如果你不太记得这两种多态的定义,我们简单回顾一下:特设多态包括运算符重载,是指同一种行为有很多不同的实现;而把子类型当成父类型使用,比如 Cat 当成 Animal 使用,属于子类型多态。
这两种多态的实现在Rust中都和 trait 有关,所以我们得先来了解一下 trait 是什么,再看怎么用 trait 来处理这两种多态。
什么是 trait?
trait 是 Rust 中的接口,它 定义了类型使用这个接口的行为。你可以类比到自己熟悉的语言中理解,trait 对于 Rust 而言,相当于 interface 之于 Java、protocol 之于 Swift、type class 之于 Haskell。
在开发复杂系统的时候,我们常常会强调接口和实现要分离。因为这是一种良好的设计习惯,它把调用者和实现者隔离开,双方只要按照接口开发,彼此就可以不受对方内部改动的影响。
trait 就是这样。它可以把数据结构中的行为单独抽取出来,使其可以在多个类型之间共享;也可以作为约束,在泛型编程中,限制参数化类型必须符合它规定的行为。
基本 trait
我们来看看基本 trait 如何定义。这里,以标准库中 std::io::Write 为例,可以看到这个 trait 中定义了一系列方法的接口:
#![allow(unused)] fn main() { pub trait Write { fn write(&mut self, buf: &[u8]) -> Result<usize>; fn flush(&mut self) -> Result<()>; fn write_vectored(&mut self, bufs: &[IoSlice<'_>]) -> Result<usize> { ... } fn is_write_vectored(&self) -> bool { ... } fn write_all(&mut self, buf: &[u8]) -> Result<()> { ... } fn write_all_vectored(&mut self, bufs: &mut [IoSlice<'_>]) -> Result<()> { ... } fn write_fmt(&mut self, fmt: Arguments<'_>) -> Result<()> { ... } fn by_ref(&mut self) -> &mut Self where Self: Sized { ... } } }
这些方法也被称作关联函数(associate function)。 在 trait 中,方法可以有缺省的实现,对于这个 Write trait,你只需要实现 write 和 flush 两个方法,其他都有 缺省实现。
如果你把 trait 类比为父类,实现 trait 的类型类比为子类,那么缺省实现的方法就相当于子类中可以重载但不是必须重载的方法。
在刚才定义方法的时候,我们频繁看到两个特殊的关键字:Self 和 self。
- Self 代表当前的类型,比如 File 类型实现了 Write,那么实现过程中使用到的 Self 就指代 File。
- self 在用作方法的第一个参数时,实际上是 self: Self 的简写,所以 &self 是 self: &Self, 而 &mut self 是 self: &mut Self。
光讲定义,理解不太深刻,我们构建一个 BufBuilder 结构实现 Write trait,结合代码来说明。( Write trait 代码):
use std::fmt; use std::io::Write; struct BufBuilder { buf: Vec<u8>, } impl BufBuilder { pub fn new() -> Self { Self { buf: Vec::with_capacity(1024), } } } // 实现 Debug trait,打印字符串 impl fmt::Debug for BufBuilder { fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result { write!(f, "{}", String::from_utf8_lossy(&self.buf)) } } impl Write for BufBuilder { fn write(&mut self, buf: &[u8]) -> std::io::Result<usize> { // 把 buf 添加到 BufBuilder 的尾部 self.buf.extend_from_slice(buf); Ok(buf.len()) } fn flush(&mut self) -> std::io::Result<()> { // 由于是在内存中操作,所以不需要 flush Ok(()) } } fn main() { let mut buf = BufBuilder::new(); buf.write_all(b"Hello world!").unwrap(); println!("{:?}", buf); }
从代码中可以看到,我们实现了 write 和 flush 方法,其它的方法都用缺省实现,这样 BufBuilder 对 Write trait 的实现是完整的。如果没有实现 write 或者 flush,Rust 编译器会报错,你可以自己尝试一下。
数据结构一旦实现了某个 trait,那么这个 trait 内部的方法都可以被使用,比如这里我们调用了 buf.write_all() 。
那么 write_all() 是如何被调用的呢?我们回去看 write_all 的签名:
#![allow(unused)] fn main() { fn write_all(&mut self, buf: &[u8]) -> Result<()> }
它接受两个参数:&mut self 和 &[u8],第一个参数传递的是 buf 这个变量的可变引用,第二个参数传递的是 b"Hello world!"。
基本 trait 练习
好,搞明白 trait 基本的定义和使用后,我们来尝试定义一个 trait 巩固下。
假设我们要做一个字符串解析器,可以把字符串的某部分解析成某个类型,那么可以这么定义这个 trait:它有一个方法是 parse,这个方法接受一个字符串引用,返回 Self。
#![allow(unused)] fn main() { pub trait Parse { fn parse(s: &str) -> Self; } }
这个 parse 方法是 trait 的静态方法,因为它的第一个参数和 self 无关,所以在调用时需要使用 T::parse(str) 。
我们来尝试为 u8 这个数据结构来实现 parse,比如说:“123abc” 会被解析出整数 123,而 “abcd” 会被解析出 0。
要达到这样的目的,需要引入一个新的库 Regex 使用正则表达式提取需要的内容,除此之外,还需要使用 str::parse 函数 把一个包含数字的字符串转换成数字。
整个代码如下( Parse trait 练习代码):
use regex::Regex; pub trait Parse { fn parse(s: &str) -> Self; } impl Parse for u8 { fn parse(s: &str) -> Self { let re: Regex = Regex::new(r"^[0-9]+").unwrap(); if let Some(captures) = re.captures(s) { // 取第一个 match,将其捕获的 digits 换成 u8 captures .get(0) .map_or(0, |s| s.as_str().parse().unwrap_or(0)) } else { 0 } } } #[test] fn parse_should_work() { assert_eq!(u8::parse("123abcd"), 123); assert_eq!(u8::parse("1234abcd"), 0); assert_eq!(u8::parse("abcd"), 0); } fn main() { println!("result: {}", u8::parse("255 hello world")); }
这个实现并不难,如果你感兴趣的话,可以再尝试为 f64 实现这个 Parse trait,比如 “123.45abcd” 需要被解析成 123.45。
在实现 f64 的过程中,你是不是感觉除了类型和用于捕获的 regex 略有变化外,整个代码基本和上面的代码是重复的?作为开发者,我们希望 Don’t Repeat Yourself(DRY),所以这样的代码写起来很别扭,让人不舒服。有没有更好的方法?
有!上一讲介绍了泛型编程,所以 在实现 trait 的时候,也可以用泛型参数来实现 trait,需要注意的是,要对泛型参数做一定的限制。
- 第一,不是任何类型都可以通过字符串解析出来,在例子中,我们只能处理数字类型,并且这个类型还要能够被 str::parse 处理。
具体看文档,str::parse 是一个泛型函数,它返回任何实现了 FromStr trait 的类型,所以这里 对泛型参数的第一个限制是,它必须实现了 FromStr trait。
- 第二,上面代码当无法正确解析字符串的时候,会直接返回 0,表示无法处理,但我们使用泛型参数后,无法返回 0,因为 0 不一定是某个符合泛型参数的类型中的一个值。怎么办?
其实返回 0 的目的是为处理不了的情况,返回一个缺省值,在 Rust 标准库中有 Default trait,绝大多数类型都实现了这个 trait,来为数据结构提供缺省值,所以 泛型参数的另一个限制是 Default。
好,基本的思路有了,来看看代码吧( Parse trait DRY代码):
use std::str::FromStr; use regex::Regex; pub trait Parse { fn parse(s: &str) -> Self; } // 我们约束 T 必须同时实现了 FromStr 和 Default // 这样在使用的时候我们就可以用这两个 trait 的方法了 impl<T> Parse for T where T: FromStr + Default, { fn parse(s: &str) -> Self { let re: Regex = Regex::new(r"^[0-9]+(\.[0-9]+)?").unwrap(); // 生成一个创建缺省值的闭包,这里主要是为了简化后续代码 // Default::default() 返回的类型根据上下文能推导出来,是 Self // 而我们约定了 Self,也就是 T 需要实现 Default trait let d = || Default::default(); if let Some(captures) = re.captures(s) { captures .get(0) .map_or(d(), |s| s.as_str().parse().unwrap_or(d())) } else { d() } } } #[test] fn parse_should_work() { assert_eq!(u32::parse("123abcd"), 123); assert_eq!(u32::parse("123.45abcd"), 0); assert_eq!(f64::parse("123.45abcd"), 123.45); assert_eq!(f64::parse("abcd"), 0f64); } fn main() { println!("result: {}", u8::parse("255 hello world")); }
通过对带有约束的泛型参数实现 trait,一份代码就实现了 u32 / f64 等类型的 Parse trait,非常精简。不过,看这段代码你有没有感觉还是有些问题?当无法正确解析字符串时,我们返回了缺省值,难道不是应该返回一个错误么?
是的。 这里返回缺省值的话,会跟解析 “0abcd” 这样的情况混淆,不知道解析出的 0,究竟是出错了,还是本该解析出 0。
所以更好的方式是 parse 函数返回一个 Result<T, E>:
#![allow(unused)] fn main() { pub trait Parse { fn parse(s: &str) -> Result<Self, E>; } }
但这里 Result 的 E 让人犯难了:要返回的错误信息,在 trait 定义时并不确定,不同的实现者可以使用不同的错误类型,这里 trait 的定义者最好能够把这种灵活性留给 trait 的实现者。怎么办?
想想既然 trait 允许内部包含方法,也就是关联函数,可不可以进一步包含关联类型呢?答案是肯定的。
带关联类型的 trait
Rust 允许 trait 内部包含关联类型,实现时跟关联函数一样,它也需要实现关联类型。我们看怎么为 Parse trait 添加关联类型:
#![allow(unused)] fn main() { pub trait Parse { type Error; fn parse(s: &str) -> Result<Self, Self::Error>; } }
有了关联类型 Error,Parse trait 就可以在出错时返回合理的错误了,看修改后的代码( Parse trait DRY.2代码):
use std::str::FromStr; use regex::Regex; pub trait Parse { type Error; fn parse(s: &str) -> Result<Self, Self::Error> where Self: Sized; } impl<T> Parse for T where T: FromStr + Default, { // 定义关联类型 Error 为 String type Error = String; fn parse(s: &str) -> Result<Self, Self::Error> { let re: Regex = Regex::new(r"^[0-9]+(\.[0-9]+)?").unwrap(); if let Some(captures) = re.captures(s) { // 当出错时我们返回 Err(String) captures .get(0) .map_or(Err("failed to capture".to_string()), |s| { s.as_str() .parse() .map_err(|_err| "failed to parse captured string".to_string()) }) } else { Err("failed to parse string".to_string()) } } } #[test] fn parse_should_work() { assert_eq!(u32::parse("123abcd"), Ok(123)); assert_eq!( u32::parse("123.45abcd"), Err("failed to parse captured string".into()) ); assert_eq!(f64::parse("123.45abcd"), Ok(123.45)); assert!(f64::parse("abcd").is_err()); } fn main() { println!("result: {:?}", u8::parse("255 hello world")); }
上面的代码中,我们允许用户把错误类型延迟到 trait 实现时才决定,这种带有关联类型的 trait 比普通 trait,更加灵活,抽象度更高。
trait 方法里的参数或者返回值,都可以用关联类型来表述,而在实现有关联类型的 trait 时,只需要额外提供关联类型的具体类型即可。
支持泛型的 trait
到目前为止,我们一步步了解了基础 trait 的定义、使用,以及更为复杂灵活的带关联类型的 trait。所以结合上一讲介绍的泛型,你有没有想到这个问题:trait 的定义是不是也可以支持泛型呢?
比如要定义一个 Concat trait 允许数据结构拼接起来,那么自然而然地,我们希望 String 可以和 String 拼接、和 &str 拼接,甚至和任何能转换成 String 的数据结构拼接。这个时候,就需要 Trait 也支持泛型了。
来看看标准库里的操作符是如何重载的,以 std::ops::Add 这个用于提供加法运算的 trait 为例:
#![allow(unused)] fn main() { pub trait Add<Rhs = Self> { type Output; #[must_use] fn add(self, rhs: Rhs) -> Self::Output; } }
这个 trait 有一个泛型参数 Rhs,代表加号右边的值,它被用在 add 方法的第二个参数位。这里 Rhs 默认是 Self,也就是说你用 Add trait ,如果不提供泛型参数,那么加号右值和左值都要是相同的类型。
我们来定义一个复数类型,尝试使用下这个 trait( Add trait 练习代码1):
use std::ops::Add; #[derive(Debug)] struct Complex { real: f64, imagine: f64, } impl Complex { pub fn new(real: f64, imagine: f64) -> Self { Self { real, imagine } } } // 对 Complex 类型的实现 impl Add for Complex { type Output = Self; // 注意 add 第一个参数是 self,会移动所有权 fn add(self, rhs: Self) -> Self::Output { let real = self.real + rhs.real; let imagine = self.imagine + rhs.imagine; Self::new(real, imagine) } } fn main() { let c1 = Complex::new(1.0, 1f64); let c2 = Complex::new(2 as f64, 3.0); println!("{:?}", c1 + c2); // c1、c2 已经被移动,所以下面这句无法编译 // println!("{:?}", c1 + c2); }
复数类型有实部和虚部,两个复数的实部相加,虚部相加,得到一个新的复数。注意 add 的第一个参数是 self,它会移动所有权,所以调用完两个复数 c1 + c2 后,根据所有权规则,它们就无法使用了。
所以,Add trait 对于实现了 Copy trait 的类型如 u32、f64 等结构来说,用起来很方便,但对于我们定义的 Complex 类型,执行一次加法,原有的值就无法使用,很不方便,怎么办?能不能对 Complex 的引用实现 Add trait 呢?
可以的。我们为 &Complex 也实现 Add( Add trait 练习代码2):
// ... // 如果不想移动所有权,可以为 &Complex 实现 add,这样可以做 &c1 + &c2 impl Add for &Complex { // 注意返回值不应该是 Self 了,因为此时 Self 是 &Complex type Output = Complex; fn add(self, rhs: Self) -> Self::Output { let real = self.real + rhs.real; let imagine = self.imagine + rhs.imagine; Complex::new(real, imagine) } } fn main() { let c1 = Complex::new(1.0, 1f64); let c2 = Complex::new(2 as f64, 3.0); println!("{:?}", &c1 + &c2); println!("{:?}", c1 + c2); }
可以做 &c1 + &c2,这样所有权就不会移动了。
讲了这么多,你可能有疑问了,这里都只使用了缺省的泛型参数,那定义泛型有什么用?
我们用加法的实际例子,来回答这个问题。之前都是两个复数的相加,现在设计一个复数和一个实数直接相加,相加的结果是实部和实数相加,虚部不变。好,来看看这个需求怎么实现( Add trait 练习代码3):
// ... // 因为 Add<Rhs = Self> 是个泛型 trait,我们可以为 Complex 实现 Add<f64> impl Add<f64> for &Complex { type Output = Complex; // rhs 现在是 f64 了 fn add(self, rhs: f64) -> Self::Output { let real = self.real + rhs; Complex::new(real, self.imagine) } } fn main() { let c1 = Complex::new(1.0, 1f64); let c2 = Complex::new(2 as f64, 3.0); println!("{:?}", &c1 + &c2); println!("{:?}", &c1 + 5.0); println!("{:?}", c1 + c2); }
通过使用 Add ,为 Complex 实现了和 f64 相加的方法。 所以泛型 trait 可以让我们在需要的时候,对同一种类型的同一个 trait,有多个实现。
这个小例子实用性不太够,再来看一个实际工作中可能会使用到的泛型 trait,你就知道这个支持有多强大了。
tower::Service 是一个第三方库,它定义了一个精巧的用于处理请求,返回响应的经典 trait,在不少著名的第三方网络库中都有使用,比如处理 gRPC 的 tonic。
看 Service 的定义:
#![allow(unused)] fn main() { // Service trait 允许某个 service 的实现能处理多个不同的 Request pub trait Service<Request> { type Response; type Error; // Future 类型受 Future trait 约束 type Future: Future; fn poll_ready( &mut self, cx: &mut Context<'_> ) -> Poll<Result<(), Self::Error>>; fn call(&mut self, req: Request) -> Self::Future; } }
这个 trait 允许某个 Service 能处理多个不同的 Request。我们在 Web 开发中使用该 trait 的话,每个 Method+URL 可以定义为一个 Service,其 Request 是输入类型。
注意对于某个确定的 Request 类型,只会返回一种 Response,所以这里 Response 使用关联类型,而非泛型。如果有可能返回多个 Response,那么应该使用泛型 Service<Request, Response>。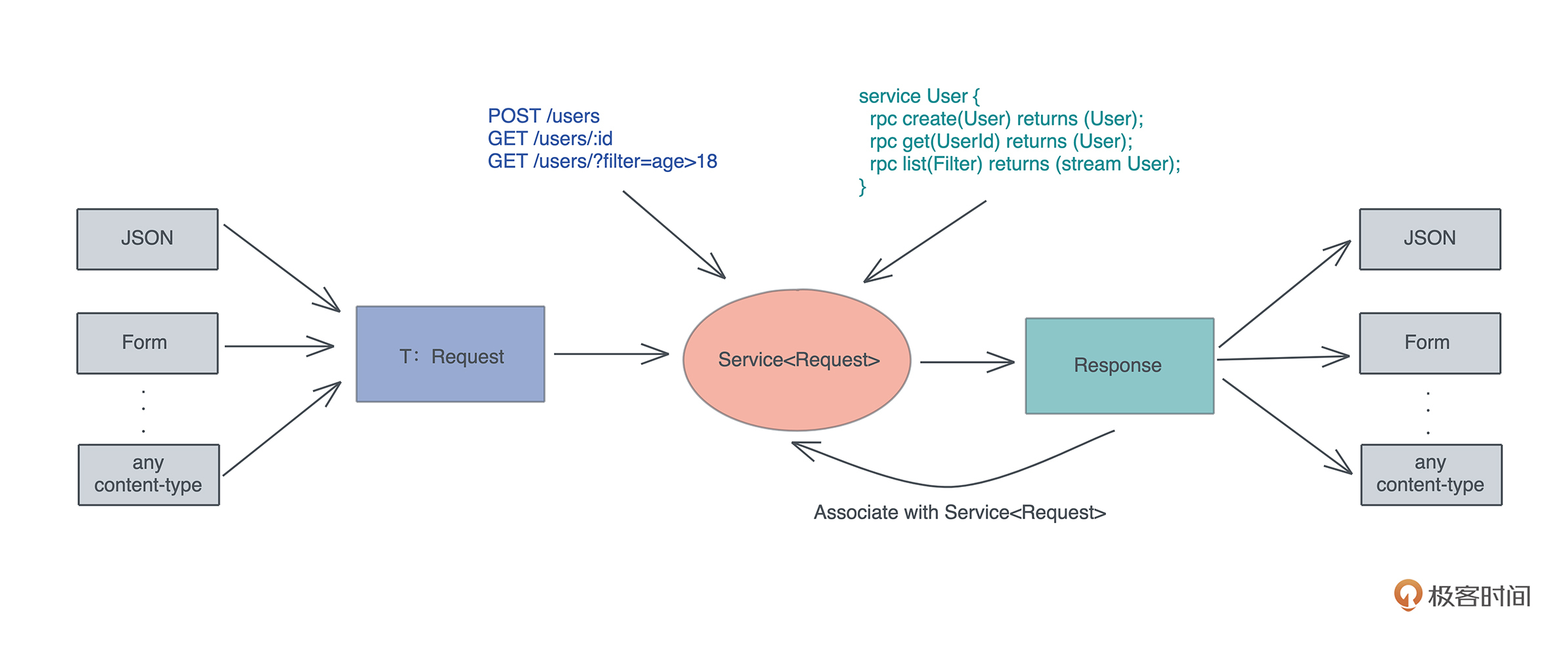
未来讲网络开发的时候再详细讲这个 trait,现在你只要能理解泛型 trait 的广泛应用场景就可以了。
trait 的“继承”
在 Rust 中,一个 trait 可以“继承”另一个 trait 的关联类型和关联函数。比如 trait B: A ,是说任何类型 T,如果实现了 trait B,它也必须实现 trait A,换句话说, trait B 在定义时可以使用 trait A 中的关联类型和方法。
可“继承”对扩展 trait 的能力很有帮助,很多常见的 trait 都会使用 trait 继承来提供更多的能力,比如 tokio 库中的 AsyncWriteExt、futures 库中的 StreamExt。
以 StreamExt 为例,由于 StreamExt 中的方法都有缺省的实现,且所有实现了 Stream trait 的类型都实现了 StreamExt:
#![allow(unused)] fn main() { impl<T: ?Sized> StreamExt for T where T: Stream {} }
所以如果你实现了 Stream trait,就可以直接使用 StreamExt 里的方法了,非常方便。
好,到这里trait就基本讲完了,简单总结一下,trait 作为对不同数据结构中相同行为的一种抽象。除了基本 trait 之外,
- 当行为和具体的数据关联时,比如字符串解析时定义的 Parse trait,我们引入了带有关联类型的 trait,把和行为有关的数据类型的定义,进一步延迟到 trait 实现的时候。
- 对于同一个类型的同一个 trait 行为,可以有不同的实现,比如我们之前大量使用的 From,此时可以用泛型 trait。
可以说 Rust 的 trait 就像一把瑞士军刀,把需要定义接口的各种场景都考虑进去了。
而特设多态是同一种行为的不同实现。所以其实, 通过定义 trait 以及为不同的类型实现这个 trait,我们就已经实现了特设多态。
刚刚讲过的 Add trait 就是一个典型的特设多态,同样是加法操作,根据操作数据的不同进行不同的处理。Service trait 是一个不那么明显的特设多态,同样是 Web 请求,对于不同的 URL,我们使用不同的代码去处理。
如何做子类型多态?
从严格意义上说,子类型多态是面向对象语言的专利。 如果一个对象 A 是对象 B 的子类,那么 A 的实例可以出现在任何期望 B 的实例的上下文中,比如猫和狗都是动物,如果一个函数的接口要求传入一个动物,那么传入猫和狗都是允许的。
Rust 虽然没有父类和子类,但 trait 和实现 trait 的类型之间也是类似的关系,所以,Rust 也可以做子类型多态。看一个例子( 代码):
struct Cat; struct Dog; trait Animal { fn name(&self) -> &'static str; } impl Animal for Cat { fn name(&self) -> &'static str { "Cat" } } impl Animal for Dog { fn name(&self) -> &'static str { "Dog" } } fn name(animal: impl Animal) -> &'static str { animal.name() } fn main() { let cat = Cat; println!("cat: {}", name(cat)); }
这里 impl Animal 是 T: Animal 的简写,所以 name 函数的定义和以下定义等价:
#![allow(unused)] fn main() { fn name<T: Animal>(animal: T) -> &'static str; }
上一讲提到过,这种泛型函数会根据具体使用的类型被单态化,编译成多个实例,是静态分派。
静态分派固然很好,效率很高, 但很多时候,类型可能很难在编译时决定。比如要撰写一个格式化工具,这个在 IDE 里很常见,我们可以定义一个 Formatter 接口,然后创建一系列实现:
#![allow(unused)] fn main() { pub trait Formatter { fn format(&self, input: &mut String) -> bool; } struct MarkdownFormatter; impl Formatter for MarkdownFormatter { fn format(&self, input: &mut String) -> bool { input.push_str("\nformatted with Markdown formatter"); true } } struct RustFormatter; impl Formatter for RustFormatter { fn format(&self, input: &mut String) -> bool { input.push_str("\nformatted with Rust formatter"); true } } struct HtmlFormatter; impl Formatter for HtmlFormatter { fn format(&self, input: &mut String) -> bool { input.push_str("\nformatted with HTML formatter"); true } } }
首先,使用什么格式化方法,只有当打开文件,分析出文件内容之后才能确定,我们无法在编译期给定一个具体类型。其次,一个文件可能有一到多个格式化工具,比如一个 Markdown 文件里有 Rust 代码,同时需要 MarkdownFormatter 和 RustFormatter 来格式化。
这里如果使用一个 Vec
#![allow(unused)] fn main() { pub fn format(input: &mut String, formatters: Vec<???>) { for formatter in formatters { formatter.format(input); } } }
正常情况下, Vec<> 容器里的类型需要是一致的,但此处无法给定一个一致的类型。
所以我们要有一种手段,告诉编译器,此处需要并且仅需要任何实现了 Formatter 接口的数据类型。 在 Rust 里,这种类型叫Trait Object,表现为 &dyn Trait 或者 Box<dyn Trait>。
这里, dyn 关键字只是用来帮助我们更好地区分普通类型和 Trait 类型,阅读代码时,看到 dyn 就知道后面跟的是一个 trait 了。
于是,上述代码可以写成:
#![allow(unused)] fn main() { pub fn format(input: &mut String, formatters: Vec<&dyn Formatter>) { for formatter in formatters { formatter.format(input); } } }
这样可以在运行时,构造一个 Formatter 的列表,传递给 format 函数进行文件的格式化,这就是 动态分派(dynamic dispatching)。
看最终调用的 格式化工具代码:
pub trait Formatter { fn format(&self, input: &mut String) -> bool; } struct MarkdownFormatter; impl Formatter for MarkdownFormatter { fn format(&self, input: &mut String) -> bool { input.push_str("\nformatted with Markdown formatter"); true } } struct RustFormatter; impl Formatter for RustFormatter { fn format(&self, input: &mut String) -> bool { input.push_str("\nformatted with Rust formatter"); true } } struct HtmlFormatter; impl Formatter for HtmlFormatter { fn format(&self, input: &mut String) -> bool { input.push_str("\nformatted with HTML formatter"); true } } pub fn format(input: &mut String, formatters: Vec<&dyn Formatter>) { for formatter in formatters { formatter.format(input); } } fn main() { let mut text = "Hello world!".to_string(); let html: &dyn Formatter = &HtmlFormatter; let rust: &dyn Formatter = &RustFormatter; let formatters = vec![html, rust]; format(&mut text, formatters); println!("text: {}", text); }
这个实现是不是很简单?学到这里你在兴奋之余,不知道会不会感觉有点负担,又一个Rust新名词出现了。别担心,虽然 Trait Object 是 Rust 独有的概念,但是这个概念并不新鲜。为什么这么说呢,来看它的实现机理。
Trait Object 的实现机理
当需要使用 Formatter trait 做动态分派时,可以像如下例子一样,将一个具体类型的引用,赋给 &Formatter : 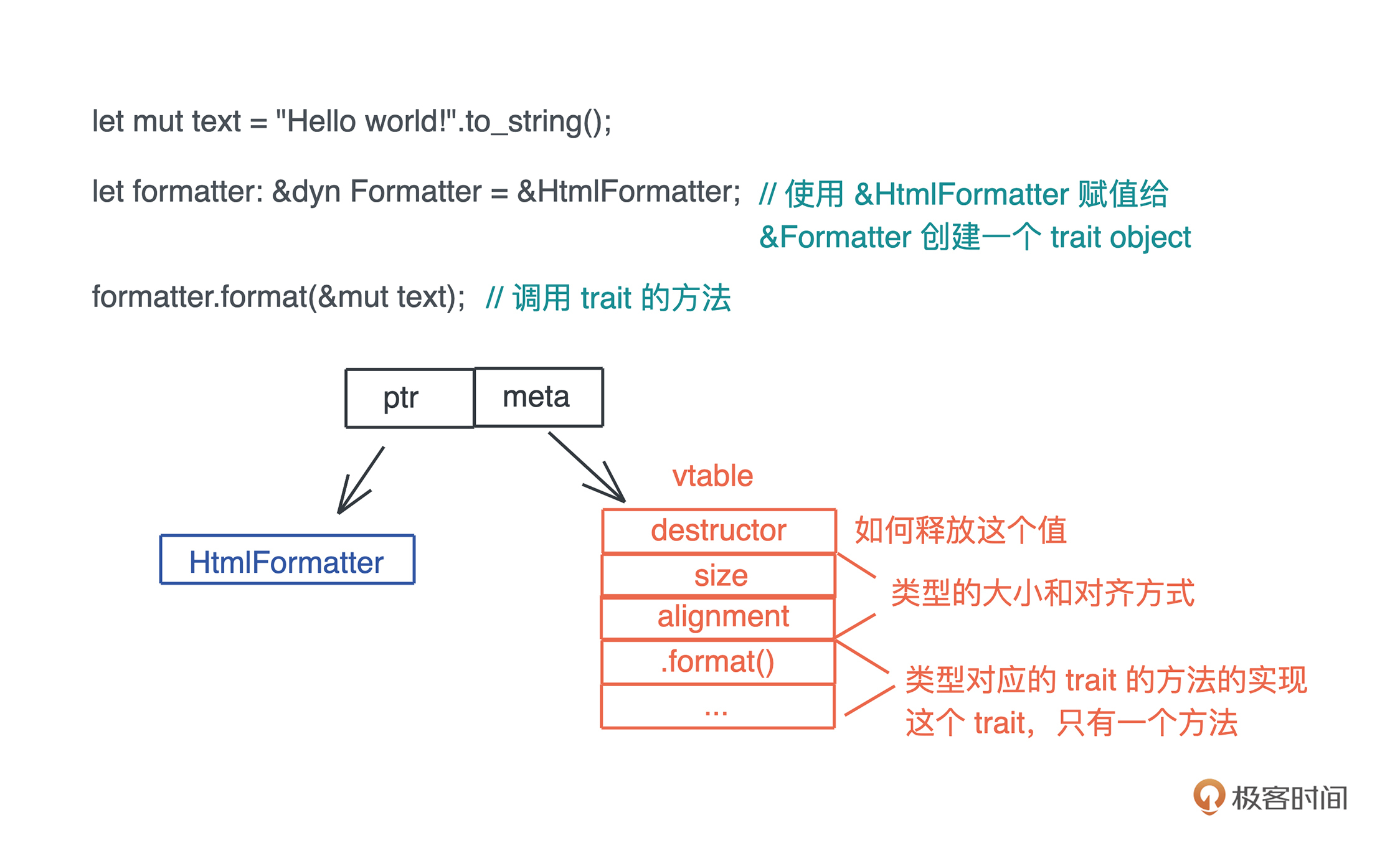
HtmlFormatter 的引用赋值给 Formatter 后,会生成一个 Trait Object,在上图中可以看到, Trait Object 的底层逻辑就是胖指针。其中,一个指针指向数据本身,另一个则指向虚函数表(vtable)。
vtable 是一张静态的表,Rust 在编译时会为使用了 trait object 的类型的 trait 实现生成一张表,放在可执行文件中(一般在 TEXT 或 RODATA 段)。看下图,可以帮助你理解:
在这张表里,包含具体类型的一些信息,如 size、aligment 以及一系列函数指针:
- 这个接口支持的所有的方法,比如
format(); - 具体类型的 drop trait,当 Trait object 被释放,它用来释放其使用的所有资源。
这样,当在运行时执行 formatter.format() 时,formatter 就可以从 vtable 里找到对应的函数指针,执行具体的操作。
所以, Rust 里的 Trait Object 没什么神秘的,它不过是我们熟知的 C++ / Java 中 vtable 的一个变体而已。
这里说句题外话,C++ / Java 指向 vtable 的指针,在编译时放在类结构里,而 Rust 放在 Trait object 中。这也是为什么 Rust 很容易对原生类型做动态分派,而 C++/Java 不行。
事实上,Rust 也并不区分原生类型和组合类型,对 Rust 来说,所有类型的地位都是一致的。
不过,你使用 trait object 的时候,要注意对象安全(object safety)。只有满足对象安全的 trait 才能使用 trait object,在 官方文档 中有详细讨论。
那什么样的 trait 不是对象安全的呢?
如果 trait 所有的方法,返回值是 Self 或者携带泛型参数,那么这个 trait 就不能产生 trait object。
不允许返回 Self,是因为 trait object 在产生时,原来的类型会被抹去,所以 Self 究竟是谁不知道。比如 Clone trait 只有一个方法 clone(),返回 Self,所以它就不能产生 trait object。
不允许携带泛型参数,是因为 Rust 里带泛型的类型在编译时会做单态化,而 trait object 是运行时的产物,两者不能兼容。
比如 From trait,因为整个 trait 带了泛型,每个方法也自然包含泛型,就不能产生 trait object。如果一个 trait 只有部分方法返回 Self 或者使用了泛型参数,那么这部分方法在 trait object 中不能调用。
小结
今天完整地介绍了 trait 是如何定义和使用的,包括最基本的 trait、带关联类型的 trait,以及泛型 trait。我们还回顾了通过 trait 做静态分发以及使用 trait object 做动态分发。
今天的内容比较多,不太明白的地方建议你多看几遍,你也可以通过下图来回顾这一讲的主要内容:
trait 作为对不同数据结构中相同行为的一种抽象,它可以让我们 在开发时,通过用户需求,先敲定系统的行为,把这些行为抽象成 trait,之后再慢慢确定要使用的数据结构,以及如何为数据结构实现这些 trait。
所以,trait 是你做 Rust 开发的核心元素。什么时候使用什么 trait,需要根据需求来确定。
但是需求往往不是那么明确的,尤其是因为我们要把用户需求翻译成系统设计上的需求。这种翻译能力,得靠足够多源码的阅读和思考,以及足够丰富的历练,一点点累积成的。 因为 Rust 的 trait 再强大,也只是一把瑞士军刀,能让它充分发挥作用的是持有它的那个人。
以在 get hands dirty 系列中写的代码为例,我们使用了 trait 对系统进行解耦,并增强其扩展性,你可以简单回顾一下。比如第 5 讲的 Engine trait 和 SpecTransform trait,使用了普通 trait:
#![allow(unused)] fn main() { // Engine trait:未来可以添加更多的 engine,主流程只需要替换 engine pub trait Engine { // 对 engine 按照 specs 进行一系列有序的处理 fn apply(&mut self, specs: &[Spec]); // 从 engine 中生成目标图片,注意这里用的是 self,而非 self 的引用 fn generate(self, format: ImageOutputFormat) -> Vec<u8>; } // SpecTransform:未来如果添加更多的 spec,只需要实现它即可 pub trait SpecTransform<T> { // 对图片使用 op 做 transform fn transform(&mut self, op: T); } }
第 6 讲的 Fetch/Load trait,使用了带关联类型的 trait:
#![allow(unused)] fn main() { // Rust 的 async trait 还没有稳定,可以用 async_trait 宏 #[async_trait] pub trait Fetch { type Error; async fn fetch(&self) -> Result<String, Self::Error>; } pub trait Load { type Error; fn load(self) -> Result<DataSet, Self::Error>; } }
思考题
1.对于 Add
2.如下代码能编译通过么,为什么?
use std::{fs::File, io::Write}; fn main() { let mut f = File::create("/tmp/test_write_trait").unwrap(); let w: &mut dyn Write = &mut f; w.write_all(b"hello ").unwrap(); let w1 = w.by_ref(); w1.write_all(b"world").unwrap(); }
3.在 Complex 的例子中,c1 + c2 会导致所有权移动,所以我们使用了 &c1 + &c2 来避免这种行为。除此之外,你还有什么方法能够让 c1 + c2 执行完之后还能继续使用么?如何修改 Complex 的代码来实现这个功能呢?
#![allow(unused)] fn main() { // c1、c2 已经被移动,所以下面这句无法编译 // println!("{:?}", c1 + c2); }
4.学有余力的同学可以挑战一下, Iterator 是 Rust 下的迭代器的 trait,你可以阅读 Iterator 的文档获得更多的信息。它有一个关联类型 Item 和一个方法 next() 需要实现,每次调用 next,如果迭代器中还能得到一个值,则返回 Some(Item),否则返回 None。请阅读 如下代码,想想看如何实现 SentenceIter 这个结构的迭代器?
struct SentenceIter<'a> { s: &'a mut &'a str, delimiter: char, } impl<'a> SentenceIter<'a> { pub fn new(s: &'a mut &'a str, delimiter: char) -> Self { Self { s, delimiter } } } impl<'a> Iterator for SentenceIter<'a> { type Item; // 想想 Item 应该是什么类型? fn next(&mut self) -> Option<Self::Item> { // 如何实现 next 方法让下面的测试通过? todo!() } } #[test] fn it_works() { let mut s = "This is the 1st sentence. This is the 2nd sentence."; let mut iter = SentenceIter::new(&mut s, '.'); assert_eq!(iter.next(), Some("This is the 1st sentence.")); assert_eq!(iter.next(), Some("This is the 2nd sentence.")); assert_eq!(iter.next(), None); } fn main() { let mut s = "a。 b。 c"; let sentences: Vec<_> = SentenceIter::new(&mut s, '。').collect(); println!("sentences: {:?}", sentences); }
今天你已经完成了Rust学习的第13次打卡。我们下节课见~
延伸阅读
使用 trait 有两个注意事项:
- 第一,在定义和使用 trait 时,我们需要遵循孤儿规则(Orphan Rule)。
trait 和实现 trait 的数据类型,至少有一个是在当前 crate 中定义的,也就是说,你不能为第三方的类型实现第三方的 trait,当你尝试这么做时,Rust 编译器会报错。我们在第6讲的 SQL查询工具query中,定义了很多简单的直接包裹已有数据结构的类型,就是为了应对孤儿规则。
- 第二,Rust 对含有 async fn 的 trait ,还没有一个很好的被标准库接受的实现,如果你感兴趣可以看 这篇文章 了解它背后的原因。
在第5讲Thumbor图片服务器我们使用了 async_trait 这个库,为 trait 的实现添加了一个标记宏 #[async_trait]。这是目前最推荐的无缝使用 async trait 的方法。未来 async trait 如果有了标准实现,我们不需要对现有代码做任何改动。
使用 async_trait 的代价是每次调用会发生额外的堆内存分配,但绝大多数应用场景下,这并不会有性能上的问题。
还记得当时写get hands dirty系列时,说我们在后面讲到具体知识点会再回顾么。你可以再回去看看(第5讲)在Thumbor图片服务器中定义的 Engine / SpecTransform,以及(第6讲)在SQL查询工具query中定义的 Fetch / Load,想想它们的作用以及给架构带来的好处。
另外,有同学可能好奇为什么我说“ vtable 会为每个类型的每个 trait 实现生成一张表”。这个并没有在任何公开的文档中提及,不过既然它是一个数据结构,我们就可以通过打印它的地址来追踪它的行为。我写了一段代码,你可以自行运行来进一步加深对 vtable 的理解( 代码):
use std::fmt::{Debug, Display}; use std::mem::transmute; fn main() { let s1 = String::from("hello world!"); let s2 = String::from("goodbye world!"); // Display / Debug trait object for s let w1: &dyn Display = &s1; let w2: &dyn Debug = &s1; // Display / Debug trait object for s1 let w3: &dyn Display = &s2; let w4: &dyn Debug = &s2; // 强行把 triat object 转换成两个地址 (usize, usize) // 这是不安全的,所以是 unsafe let (addr1, vtable1): (usize, usize) = unsafe { transmute(w1) }; let (addr2, vtable2): (usize, usize) = unsafe { transmute(w2) }; let (addr3, vtable3): (usize, usize) = unsafe { transmute(w3) }; let (addr4, vtable4): (usize, usize) = unsafe { transmute(w4) }; // s 和 s1 在栈上的地址,以及 main 在 TEXT 段的地址 println!( "s1: {:p}, s2: {:p}, main(): {:p}", &s1, &s2, main as *const () ); // trait object(s / Display) 的 ptr 地址和 vtable 地址 println!("addr1: 0x{:x}, vtable1: 0x{:x}", addr1, vtable1); // trait object(s / Debug) 的 ptr 地址和 vtable 地址 println!("addr2: 0x{:x}, vtable2: 0x{:x}", addr2, vtable2); // trait object(s1 / Display) 的 ptr 地址和 vtable 地址 println!("addr3: 0x{:x}, vtable3: 0x{:x}", addr3, vtable3); // trait object(s1 / Display) 的 ptr 地址和 vtable 地址 println!("addr4: 0x{:x}, vtable4: 0x{:x}", addr4, vtable4); // 指向同一个数据的 trait object 其 ptr 地址相同 assert_eq!(addr1, addr2); assert_eq!(addr3, addr4); // 指向同一种类型的同一个 trait 的 vtable 地址相同 // 这里都是 String + Display assert_eq!(vtable1, vtable3); // 这里都是 String + Debug assert_eq!(vtable2, vtable4); }
(如果你觉得有收获,也欢迎你分享给身边的朋友,邀他一起讨论~)
类型系统:有哪些必须掌握的trait?
你好,我是陈天。
开发软件系统时,我们弄清楚需求,要对需求进行架构上的分析和设计。在这个过程中,合理地定义和使用 trait,会让代码结构具有很好的扩展性,让系统变得非常灵活。
之前在 get hands dirty 系列中就粗略见识到了 trait 的巨大威力,使用了 From
经过上两讲的学习,相信你现在对trait 的理解就深入了。在实际解决问题的过程中, 用好这些 trait,会让你的代码结构更加清晰,阅读和使用都更加符合 Rust 生态的习惯。比如数据结构实现了 Debug trait,那么当你想打印数据结构时,就可以用 {:?} 来打印;如果你的数据结构实现了 From
trait
Rust 语言的标准库定义了大量的标准 trait,来先来数已经学过的,看看攒了哪些:
- Clone / Copy trait,约定了数据被深拷贝和浅拷贝的行为;
- Read / Write trait,约定了对 I/O 读写的行为;
- Iterator,约定了迭代器的行为;
- Debug,约定了数据如何被以 debug 的方式显示出来的行为;
- Default,约定数据类型的缺省值如何产生的行为;
- From
/ TryFrom ,约定了数据间如何转换的行为。
我们会再学习几类重要的 trait,包括和内存分配释放相关的 trait、用于区别不同类型协助编译器做类型安全检查的标记 trait、进行类型转换的 trait、操作符相关的 trait,以及 Debug/Display/Default。
在学习这些 trait的过程中,你也可以结合之前讲的内容,有意识地思考一下Rust为什么这么设计,在增进对语言理解的同时,也能写出更加优雅的 Rust 代码。
内存相关:Clone / Copy / Drop
首先来看内存相关的 Clone/Copy/Drop。这三个 trait 在介绍所有权的时候已经学习过,这里我们再深入研究一下它们的定义和使用场景。
Clone trait
首先看 Clone:
#![allow(unused)] fn main() { pub trait Clone { fn clone(&self) -> Self; fn clone_from(&mut self, source: &Self) { *self = source.clone() } } }
Clone trait 有两个方法, clone() 和 clone_from() ,后者有缺省实现,所以平时我们只需要实现 clone() 方法即可。你也许会疑惑,这个 clone_from() 有什么作用呢?因为看起来 a.clone_from(&b) ,和 a = b.clone() 是等价的。
其实不是,如果 a 已经存在,在 clone 过程中会分配内存,那么 用 a.clone_from(&b) 可以避免内存分配,提高效率。
Clone trait 可以通过派生宏直接实现,这样能简化不少代码。如果在你的数据结构里,每一个字段都已经实现了Clone trait,你可以用 #[derive(Clone)] ,看下面的 代码,定义了 Developer 结构和 Language 枚举:
#[derive(Clone, Debug)] struct Developer { name: String, age: u8, lang: Language } #[allow(dead_code)] #[derive(Clone, Debug)] enum Language { Rust, TypeScript, Elixir, Haskell } fn main() { let dev = Developer { name: "Tyr".to_string(), age: 18, lang: Language::Rust }; let dev1 = dev.clone(); println!("dev: {:?}, addr of dev name: {:p}", dev, dev.name.as_str()); println!("dev1: {:?}, addr of dev1 name: {:p}", dev1, dev1.name.as_str()) }
如果没有为 Language 实现 Clone 的话,Developer 的派生宏 Clone 将会编译出错。运行这段代码可以看到,对于 name,也就是 String 类型的 Clone,其堆上的内存也被 Clone 了一份,所以 Clone 是深度拷贝,栈内存和堆内存一起拷贝。
值得注意的是,clone 方法的接口是 &self,这在绝大多数场合下都是适用的,我们在 clone 一个数据时只需要有已有数据的只读引用。但对 Rc
Copy trait
和 Clone trait 不同的是,Copy trait 没有任何额外的方法,它只是一个标记 trait(marker trait)。它的 trait 定义:
#![allow(unused)] fn main() { pub trait Copy: Clone {} }
所以看这个定义,如果要实现 Copy trait 的话,必须实现 Clone trait,然后实现一个空的 Copy trait。你是不是有点疑惑:这样不包含任何行为的 trait 有什么用呢?
这样的 trait 虽然没有任何行为,但它可以用作 trait bound 来进行类型安全检查,所以我们管它叫 标记 trait。
和 Clone 一样,如果数据结构的所有字段都实现了 Copy,也可以用 #[derive(Copy)] 宏来为数据结构实现 Copy。试着为 Developer 和 Language 加上 Copy:
#![allow(unused)] fn main() { #[derive(Clone, Copy, Debug)] struct Developer { name: String, age: u8, lang: Language } #[derive(Clone, Copy, Debug)] enum Language { Rust, TypeScript, Elixir, Haskell } }
这个代码会出错。因为 String 类型没有实现 Copy。 因此,Developer 数据结构只能 clone,无法 copy。我们知道,如果类型实现了 Copy,那么在赋值、函数调用的时候,值会被拷贝,否则所有权会被移动。
所以上面的代码 Developer 类型在做参数传递时,会执行 Move 语义,而 Language 会执行 Copy 语义。
在讲所有权可变/不可变引用的时候提到,不可变引用实现了 Copy,而可变引用 &mut T 没有实现 Copy。为什么是这样?
因为如果可变引用实现了 Copy trait,那么生成一个可变引用然后把它赋值给另一个变量时,就会违背所有权规则:同一个作用域下只能有一个可变引用。可见,Rust 标准库在哪些结构可以 Copy、哪些不可以 Copy 上,有着仔细的考量。
Drop trait
在内存管理中已经详细探讨过 Drop trait。这里我们再看一下它的定义:
#![allow(unused)] fn main() { pub trait Drop { fn drop(&mut self); } }
大部分场景无需为数据结构提供 Drop trait,系统默认会依次对数据结构的每个域做 drop。但有两种情况你可能需要手工实现 Drop。
第一种是希望在数据结束生命周期的时候做一些事情,比如记日志。
第二种是需要对资源回收的场景。编译器并不知道你额外使用了哪些资源,也就无法帮助你 drop 它们。比如说锁资源的释放,在 MutexGuard
#![allow(unused)] fn main() { impl<T: ?Sized> Drop for MutexGuard<'_, T> { #[inline] fn drop(&mut self) { unsafe { self.lock.poison.done(&self.poison); self.lock.inner.raw_unlock(); } } } }
需要注意的是,Copy trait 和 Drop trait 是互斥的,两者不能共存,当你尝试为同一种数据类型实现 Copy 时,也实现 Drop,编译器就会报错。这其实很好理解: Copy是按位做浅拷贝,那么它会默认拷贝的数据没有需要释放的资源;而Drop恰恰是为了释放额外的资源而生的。
我们还是写一段代码来辅助理解,在代码中,强行用 Box::into_raw 获得堆内存的指针,放入 RawBuffer 结构中,这样就接管了这块堆内存的释放。
虽然 RawBuffer 可以实现 Copy trait,但这样一来就无法实现 Drop trait。如果程序非要这么写,会导致内存泄漏,因为该释放的堆内存没有释放。
但是这个操作不会破坏 Rust 的正确性保证:即便你 Copy 了 N 份 RawBuffer,由于无法实现 Drop trait,RawBuffer 指向的那同一块堆内存不会释放,所以不会出现 use after free 的内存安全问题。( 代码)
use std::{fmt, slice}; // 注意这里,我们实现了 Copy,这是因为 *mut u8/usize 都支持 Copy #[derive(Clone, Copy)] struct RawBuffer { // 裸指针用 *const / *mut 来表述,这和引用的 & 不同 ptr: *mut u8, len: usize, } impl From<Vec<u8>> for RawBuffer { fn from(vec: Vec<u8>) -> Self { let slice = vec.into_boxed_slice(); Self { len: slice.len(), // into_raw 之后,Box 就不管这块内存的释放了,RawBuffer 需要处理释放 ptr: Box::into_raw(slice) as *mut u8, } } } // 如果 RawBuffer 实现了 Drop trait,就可以在所有者退出时释放堆内存 // 然后,Drop trait 会跟 Copy trait 冲突,要么不实现 Copy,要么不实现 Drop // 如果不实现 Drop,那么就会导致内存泄漏,但它不会对正确性有任何破坏 // 比如不会出现 use after free 这样的问题。 // 你可以试着把下面注释去掉,看看会出什么问题 // impl Drop for RawBuffer { // #[inline] // fn drop(&mut self) { // let data = unsafe { Box::from_raw(slice::from_raw_parts_mut(self.ptr, self.len)) }; // drop(data) // } // } impl fmt::Debug for RawBuffer { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { let data = self.as_ref(); write!(f, "{:p}: {:?}", self.ptr, data) } } impl AsRef<[u8]> for RawBuffer { fn as_ref(&self) -> &[u8] { unsafe { slice::from_raw_parts(self.ptr, self.len) } } } fn main() { let data = vec![1, 2, 3, 4]; let buf: RawBuffer = data.into(); // 因为 buf 允许 Copy,所以这里 Copy 了一份 use_buffer(buf); // buf 还能用 println!("buf: {:?}", buf); } fn use_buffer(buf: RawBuffer) { println!("buf to die: {:?}", buf); // 这里不用特意 drop,写出来只是为了说明 Copy 出来的 buf 被 Drop 了 drop(buf) }
对于代码安全来说,内存泄漏危害大?还是 use after free 危害大呢?肯定是后者。Rust 的底线是内存安全,所以两害相权取其轻。
实际上,任何编程语言都无法保证不发生人为的内存泄漏,比如程序在运行时,开发者疏忽了,对哈希表只添加不删除,就会造成内存泄漏。但 Rust 会保证即使开发者疏忽了,也不会出现内存安全问题。
建议你仔细阅读这段代码中的注释,试着把注释掉的 Drop trait 恢复,然后再把代码改得可以编译通过,认真思考一下 Rust 这样做的良苦用心。
标记 trait:Sized / Send / Sync / Unpin
好,讲完内存相关的主要 trait,来看标记 trait。
刚才我们已经看到了一个标记 trait:Copy。Rust 还支持其它几种标记 trait: Sized / Send / Sync / Unpin。
Sized trait 用于标记有具体大小的类型。在使用泛型参数时,Rust 编译器会自动为泛型参数加上 Sized 约束,比如下面的 Data
#![allow(unused)] fn main() { struct Data<T> { inner: T, } fn process_data<T>(data: Data<T>) { todo!(); } }
它等价于:
#![allow(unused)] fn main() { struct Data<T: Sized> { inner: T, } fn process_data<T: Sized>(data: Data<T>) { todo!(); } }
大部分时候,我们都希望能自动添加这样的约束,因为这样定义出的泛型结构,在编译期,大小是固定的,可以作为参数传递给函数。如果没有这个约束,T 是大小不固定的类型, process_data 函数会无法编译。
但是这个自动添加的约束有时候不太适用, 在少数情况下,需要 T 是可变类型的,怎么办?Rust 提供了 ?Sized 来摆脱这个约束。
如果开发者显式定义了 T: ?Sized,那么 T 就可以是任意大小。如果你对( 第12讲)之前说的 Cow 还有印象,可能会记得 Cow 中泛型参数 B 的约束是 ?Sized:
#![allow(unused)] fn main() { pub enum Cow<'a, B: ?Sized + 'a> where B: ToOwned, { // 借用的数据 Borrowed(&'a B), // 拥有的数据 Owned(<B as ToOwned>::Owned), } }
这样 B 就可以是 [T] 或者 str 类型,大小都是不固定的。要注意 Borrowed(&'a B) 大小是固定的,因为它内部是对 B 的一个引用,而引用的大小是固定的。
Send / Sync
说完了 Sized,我们再来看 Send / Sync,定义是:
#![allow(unused)] fn main() { pub unsafe auto trait Send {} pub unsafe auto trait Sync {} }
这两个 trait 都是 unsafe auto trait,auto 意味着编译器会在合适的场合,自动为数据结构添加它们的实现,而 unsafe 代表实现的这个 trait 可能会违背 Rust 的内存安全准则,如果开发者手工实现这两个 trait ,要自己为它们的安全性负责。
Send/Sync 是 Rust 并发安全的基础:
- 如果一个类型 T 实现了 Send trait,意味着 T 可以安全地从一个线程移动到另一个线程,也就是说所有权可以在线程间移动。
- 如果一个类型 T 实现了 Sync trait,则意味着 &T 可以安全地在多个线程中共享。一个类型 T 满足 Sync trait,当且仅当 &T 满足 Send trait。
对于 Send/Sync 在线程安全中的作用,可以这么看, 如果一个类型T: Send,那么 T 在某个线程中的独占访问是线程安全的;如果一个类型 T: Sync,那么 T 在线程间的只读共享是安全的。
对于我们自己定义的数据结构,如果其内部的所有域都实现了 Send / Sync,那么这个数据结构会被自动添加 Send / Sync 。基本上原生数据结构都支持 Send / Sync,也就是说,绝大多数自定义的数据结构都是满足 Send / Sync 的。标准库中,不支持 Send / Sync 的数据结构主要有:
- 裸指针 *const T / *mut T。它们是不安全的,所以既不是 Send 也不是 Sync。
- UnsafeCell
不支持 Sync。也就是说,任何使用了 Cell 或者 RefCell 的数据结构不支持 Sync。 - 引用计数 Rc 不支持 Send 也不支持 Sync。所以 Rc 无法跨线程。
之前介绍过 Rc / RefCell( 第9讲),我们来看看,如果尝试跨线程使用 Rc / RefCell,会发生什么。在 Rust 下,如果想创建一个新的线程,需要使用 std::thread::spawn:
#![allow(unused)] fn main() { pub fn spawn<F, T>(f: F) -> JoinHandle<T> where F: FnOnce() -> T, F: Send + 'static, T: Send + 'static, }
它的参数是一个闭包(后面会讲),这个闭包需要 Send + 'static:
- 'static 意思是闭包捕获的自由变量必须是一个拥有所有权的类型,或者是一个拥有静态生命周期的引用;
- Send 意思是,这些被捕获自由变量的所有权可以从一个线程移动到另一个线程。
从这个接口上,可以得出结论:如果在线程间传递 Rc,是无法编译通过的,因为 Rc 的实现不支持 Send 和 Sync。写段代码验证一下( 代码):
#![allow(unused)] fn main() { // Rc 既不是 Send,也不是 Sync fn rc_is_not_send_and_sync() { let a = Rc::new(1); let b = a.clone(); let c = a.clone(); thread::spawn(move || { println!("c= {:?}", c); }); } }
果然,这段代码不通过。
那么,RefCell
#![allow(unused)] fn main() { fn refcell_is_send() { let a = RefCell::new(1); thread::spawn(move || { println!("a= {:?}", a); }); } }
验证一下发现,这是 OK 的。
既然 Rc 不能 Send,我们无法跨线程使用 Rc<RefCell
#![allow(unused)] fn main() { // RefCell 现在有多个 Arc 持有它,虽然 Arc 是 Send/Sync,但 RefCell 不是 Sync fn refcell_is_not_sync() { let a = Arc::new(RefCell::new(1)); let b = a.clone(); let c = a.clone(); thread::spawn(move || { println!("c= {:?}", c); }); } }
不可以。
因为 Arc 内部的数据是共享的,需要支持 Sync 的数据结构,但是RefCell 不是 Sync,编译失败。所以在多线程情况下,我们只能使用支持 Send/Sync 的 Arc ,和 Mutex 一起,构造一个可以在多线程间共享且可以修改的类型( 代码):
use std::{ sync::{Arc, Mutex}, thread, }; // Arc<Mutex<T>> 可以多线程共享且修改数据 fn arc_mutext_is_send_sync() { let a = Arc::new(Mutex::new(1)); let b = a.clone(); let c = a.clone(); let handle = thread::spawn(move || { let mut g = c.lock().unwrap(); *g += 1; }); { let mut g = b.lock().unwrap(); *g += 1; } handle.join().unwrap(); println!("a= {:?}", a); } fn main() { arc_mutext_is_send_sync(); }
这几段代码建议你都好好阅读和运行一下,对于编译出错的情况,仔细看看编译器给出的错误,会帮助你理解好 Send/Sync trait 以及它们如何保证并发安全。
最后一个标记 trait Unpin,是用于自引用类型的,在后面讲到 Future trait 时,再详细讲这个 trait。
类型转换相关:From / Into/AsRef / AsMut
好,学完了标记 trait,来看看和类型转换相关的 trait。在软件开发的过程中,我们经常需要在某个上下文中,把一种数据结构转换成另一种数据结构。
不过转换有很多方式,看下面的代码,你觉得哪种方式更好呢?
#![allow(unused)] fn main() { // 第一种方法,为每一种转换提供一个方法 // 把字符串 s 转换成 Path let v = s.to_path(); // 把字符串 s 转换成 u64 let v = s.to_u64(); // 第二种方法,为 s 和要转换的类型之间实现一个 Into<T> trait // v 的类型根据上下文得出 let v = s.into(); // 或者也可以显式地标注 v 的类型 let v: u64 = s.into(); }
第一种方式,在类型 T 的实现里,要为每一种可能的转换提供一个方法;第二种,我们为类型 T 和类型 U 之间的转换实现一个数据转换 trait,这样可以用同一个方法来实现不同的转换。
显然,第二种方法要更好,因为它符合软件开发的开闭原则(Open-Close Principle),“ 软件中的对象(类、模块、函数等等)对扩展是开放的,但是对修改是封闭的”。
在第一种方式下,未来每次要添加对新类型的转换,都要重新修改类型 T 的实现,而第二种方式,我们只需要添加一个对于数据转换 trait 的新实现即可。
基于这个思路,对值类型的转换和对引用类型的转换,Rust 提供了两套不同的 trait:
- 值类型到值类型的转换:From
/ Into / TryFrom / TryInto - 引用类型到引用类型的转换:AsRef
/ AsMut
From / Into
先看 From
#![allow(unused)] fn main() { pub trait From<T> { fn from(T) -> Self; } pub trait Into<T> { fn into(self) -> T; } }
在实现 From
#![allow(unused)] fn main() { // 实现 From 会自动实现 Into impl<T, U> Into<U> for T where U: From<T> { fn into(self) -> U { U::from(self) } } }
所以大部分情况下,只用实现 From
#![allow(unused)] fn main() { let s = String::from("Hello world!"); let s: String = "Hello world!".into(); }
这两种方式是等价的,怎么选呢?From
此外,From
#![allow(unused)] fn main() { // From(以及 Into)是自反的 impl<T> From<T> for T { fn from(t: T) -> T { t } } }
有了 From
use std::net::{IpAddr, Ipv4Addr, Ipv6Addr}; fn print(v: impl Into<IpAddr>) { println!("{:?}", v.into()); } fn main() { let v4: Ipv4Addr = "2.2.2.2".parse().unwrap(); let v6: Ipv6Addr = "::1".parse().unwrap(); // IPAddr 实现了 From<[u8; 4],转换 IPv4 地址 print([1, 1, 1, 1]); // IPAddr 实现了 From<[u16; 8],转换 IPv6 地址 print([0xfe80, 0, 0, 0, 0xaede, 0x48ff, 0xfe00, 0x1122]); // IPAddr 实现了 From<Ipv4Addr> print(v4); // IPAddr 实现了 From<Ipv6Addr> print(v6); }
所以,合理地使用 From
注意,如果你的数据类型在转换过程中有可能出现错误,可以使用 TryFrom
AsRef / AsMut
搞明白了 From
#![allow(unused)] fn main() { pub trait AsRef<T> where T: ?Sized { fn as_ref(&self) -> &T; } pub trait AsMut<T> where T: ?Sized { fn as_mut(&mut self) -> &mut T; } }
在 trait 的定义上,都允许 T 使用大小可变的类型,如 str、[u8] 等。AsMut
看标准库中打开文件的接口 std::fs::File::open:
#![allow(unused)] fn main() { pub fn open<P: AsRef<Path>>(path: P) -> Result<File> }
它的参数 path 是符合 AsRef
来写一段代码体验一下 AsRef
#[allow(dead_code)] enum Language { Rust, TypeScript, Elixir, Haskell, } impl AsRef<str> for Language { fn as_ref(&self) -> &str { match self { Language::Rust => "Rust", Language::TypeScript => "TypeScript", Language::Elixir => "Elixir", Language::Haskell => "Haskell", } } } fn print_ref(v: impl AsRef<str>) { println!("{}", v.as_ref()); } fn main() { let lang = Language::Rust; // &str 实现了 AsRef<str> print_ref("Hello world!"); // String 实现了 AsRef<str> print_ref("Hello world!".to_string()); // 我们自己定义的 enum 也实现了 AsRef<str> print_ref(lang); }
现在对在 Rust 下,如何使用 From / Into / AsRef / AsMut 进行类型间转换,有了深入了解,未来我们还会在实战中使用到这些 trait。
刚才的小例子中要额外说明一下的是,如果你的代码出现 v.as_ref().clone() 这样的语句,也就是说你要对 v 进行引用转换,然后又得到了拥有所有权的值,那么你应该实现 From
操作符相关:Deref / DerefMut
操作符相关的 trait ,上一讲我们已经看到了 Add
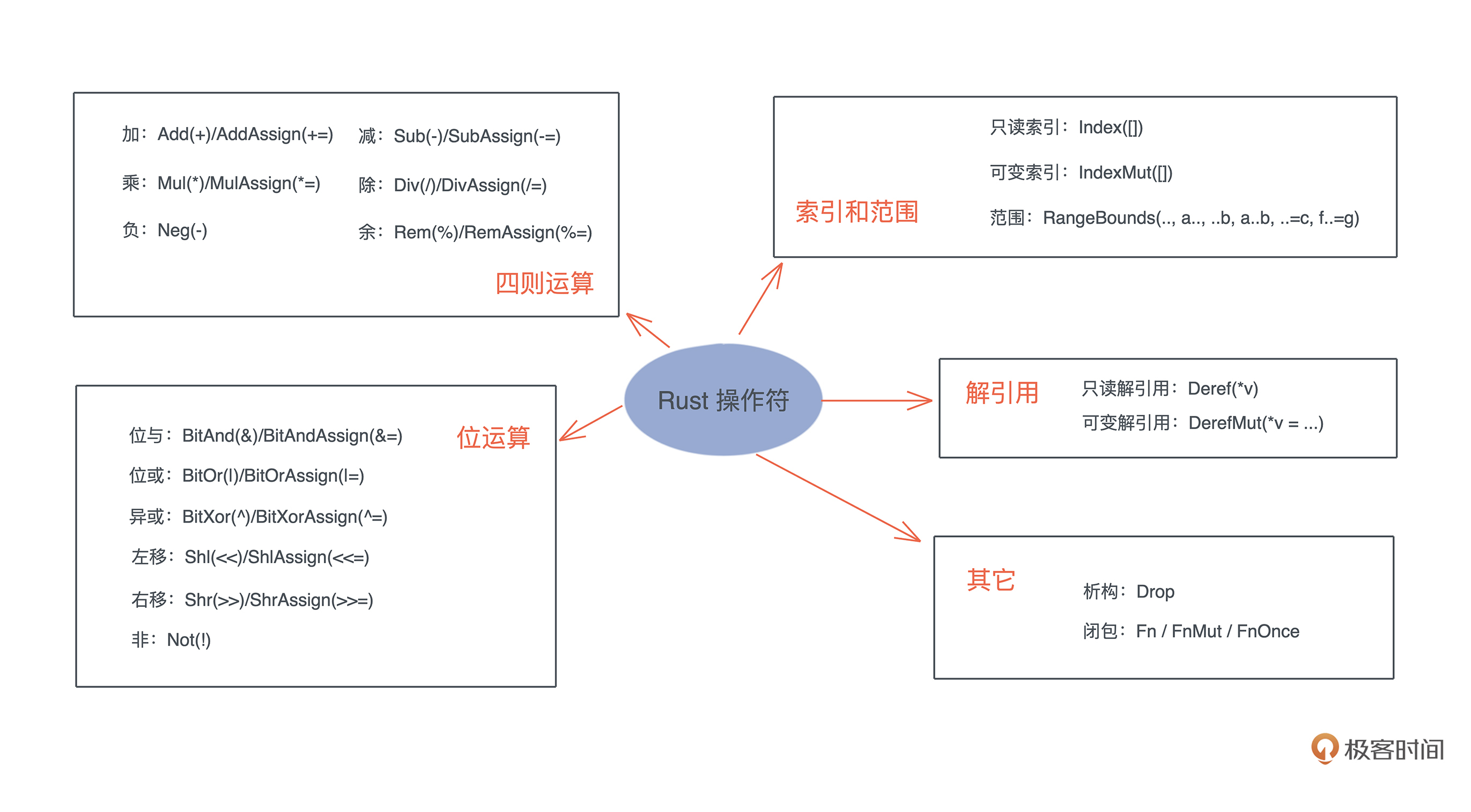
今天重点要介绍的操作符是 Deref 和 DerefMut。来看它们的定义:
#![allow(unused)] fn main() { pub trait Deref { // 解引用出来的结果类型 type Target: ?Sized; fn deref(&self) -> &Self::Target; } pub trait DerefMut: Deref { fn deref_mut(&mut self) -> &mut Self::Target; } }
可以看到,DerefMut “继承”了 Deref,只是它额外提供了一个 deref_mut 方法,用来获取可变的解引用。所以这里重点学习 Deref。
对于普通的引用,解引用很直观,因为它只有一个指向值的地址,从这个地址可以获取到所需要的值,比如下面的例子:
#![allow(unused)] fn main() { let mut x = 42; let y = &mut x; // 解引用,内部调用 DerefMut(其实现就是 *self) *y += 1; }
但对智能指针来说,拿什么域来解引用就不那么直观了,我们来看之前学过的 Rc 是怎么实现 Deref 的:
#![allow(unused)] fn main() { impl<T: ?Sized> Deref for Rc<T> { type Target = T; fn deref(&self) -> &T { &self.inner().value } } }
可以看到,它最终指向了堆上的 RcBox 内部的 value 的地址,然后如果对其解引用的话,得到了 value 对应的值。以下图为例,最终打印出 v = 1。
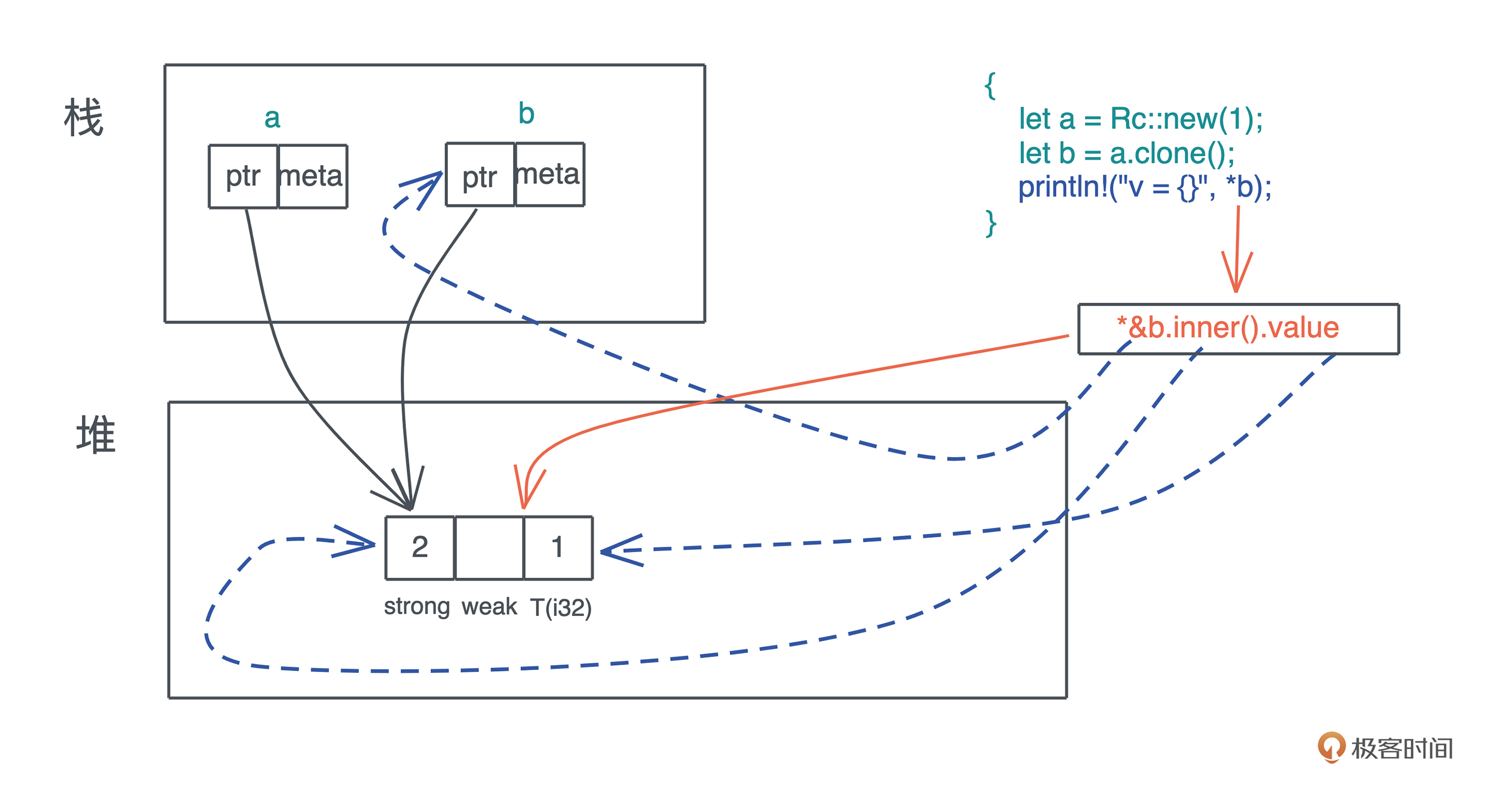
从图中还可以看到,Deref 和 DerefMut 是自动调用的,*b 会被展开为 *(b.deref())。
在 Rust 里,绝大多数智能指针都实现了 Deref,我们也可以为自己的数据结构实现 Deref。看一个例子( 代码):
use std::ops::{Deref, DerefMut}; #[derive(Debug)] struct Buffer<T>(Vec<T>); impl<T> Buffer<T> { pub fn new(v: impl Into<Vec<T>>) -> Self { Self(v.into()) } } impl<T> Deref for Buffer<T> { type Target = [T]; fn deref(&self) -> &Self::Target { &self.0 } } impl<T> DerefMut for Buffer<T> { fn deref_mut(&mut self) -> &mut Self::Target { &mut self.0 } } fn main() { let mut buf = Buffer::new([1, 3, 2, 4]); // 因为实现了 Deref 和 DerefMut,这里 buf 可以直接访问 Vec<T> 的方法 // 下面这句相当于:(&mut buf).deref_mut().sort(),也就是 (&mut buf.0).sort() buf.sort(); println!("buf: {:?}", buf); }
但是在这个例子里,数据结构 Buffer
可以实现 Deref 和 DerefMut,这样在解引用的时候,直接访问到 buf.0,省去了代码的啰嗦和数据结构内部字段的隐藏。
在这段代码里,还有一个值得注意的地方:写 buf.sort() 的时候,并没有做解引用的操作,为什么会相当于访问了 buf.0.sort() 呢?这是因为 sort() 方法第一个参数是 &mut self,此时 Rust 编译器会强制做 Deref/DerefMut 的解引用,所以这相当于 (*(&mut buf)).sort()。
其它:Debug / Display / Default
现在我们对运算符相关的 trait 有了足够的了解,最后来看看其它一些常用的 trait: Debug / Display / Default。
先看 Debug / Display,它们的定义如下:
#![allow(unused)] fn main() { pub trait Debug { fn fmt(&self, f: &mut Formatter<'_>) -> Result<(), Error>; } pub trait Display { fn fmt(&self, f: &mut Formatter<'_>) -> Result<(), Error>; } }
可以看到,Debug 和 Display 两个 trait 的签名一样,都接受一个 &self 和一个 &mut Formatter。那为什么要有两个一样的 trait 呢?
这是因为 Debug 是为开发者调试打印数据结构所设计的,而 Display 是给用户显示数据结构所设计的。这也是为什么 Debug trait 的实现可以通过派生宏直接生成,而 Display 必须手工实现。在使用的时候,Debug 用 {:?} 来打印,Display 用 {} 打印。
最后看 Default trait。它的定义如下:
#![allow(unused)] fn main() { pub trait Default { fn default() -> Self; } }
Default trait 用于为类型提供缺省值。它也可以通过 derive 宏 #[derive(Default)] 来生成实现,前提是类型中的每个字段都实现了 Default trait。在初始化一个数据结构时,我们可以部分初始化,然后剩余的部分使用 Default::default()。
Debug/Display/Default 如何使用,统一看个例子( 代码):
use std::fmt; // struct 可以 derive Default,但我们需要所有字段都实现了 Default #[derive(Clone, Debug, Default)] struct Developer { name: String, age: u8, lang: Language, } // enum 不能 derive Default #[allow(dead_code)] #[derive(Clone, Debug)] enum Language { Rust, TypeScript, Elixir, Haskell, } // 手工实现 Default impl Default for Language { fn default() -> Self { Language::Rust } } impl Developer { pub fn new(name: &str) -> Self { // 用 ..Default::default() 为剩余字段使用缺省值 Self { name: name.to_owned(), ..Default::default() } } } impl fmt::Display for Developer { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!( f, "{}({} years old): {:?} developer", self.name, self.age, self.lang ) } } fn main() { // 使用 T::default() let dev1 = Developer::default(); // 使用 Default::default(),但此时类型无法通过上下文推断,需要提供类型 let dev2: Developer = Default::default(); // 使用 T::new let dev3 = Developer::new("Tyr"); println!("dev1: {}\\ndev2: {}\\ndev3: {:?}", dev1, dev2, dev3); }
它们实现起来非常简单,你可以看文中的代码。
小结
今天介绍了内存管理、类型转换、操作符、数据显示等相关的基本 trait,还介绍了标记 trait,它是一种特殊的 trait,主要是用于协助编译器检查类型安全。

在我们使用 Rust 开发时,trait 占据了非常核心的地位。 一个设计良好的 trait 可以大大提升整个系统的可用性和扩展性。
很多优秀的第三方库,都围绕着 trait 展开它们的能力,比如上一讲提到的 tower-service 中的 Service trait,再比如你日后可能会经常使用到的 parser combinator 库 nom 的 Parser trait。
因为 trait 实现了延迟绑定。不知道你是否还记得,之前串讲编程基础概念的时候,就谈到了延迟绑定。在软件开发中,延迟绑定会带来极大的灵活性。
从数据的角度看,数据结构是具体数据的延迟绑定,泛型结构是具体数据结构的延迟绑定;从代码的角度看,函数是一组实现某个功能的表达式的延迟绑定,泛型函数是函数的延迟绑定。那么 trait 是什么的延迟绑定呢?
trait 是行为的延迟绑定。我们可以在不知道具体要处理什么数据结构的前提下,先通过 trait 把系统的很多行为约定好。这也是为什么开头解释标准trait时,频繁用到了“约定……行为”。
相信通过今天的学习,你能对 trait 有更深刻的认识,在撰写自己的数据类型时,就能根据需要实现这些 trait。
思考题
1.Vec
2.在使用 Arc<Mutex
#![allow(unused)] fn main() { use std::sync::{Arc, Mutex}; let shared = Arc::new(Mutex::new(1)); let mut g = shared.lock().unwrap(); *g += 1; }
3.有余力的同学可以尝试一下,为下面的 List
#![allow(unused)] fn main() { use std::{ collections::LinkedList, ops::{Deref, DerefMut, Index}, }; struct List<T>(LinkedList<T>); impl<T> Deref for List<T> { type Target = LinkedList<T>; fn deref(&self) -> &Self::Target { &self.0 } } impl<T> DerefMut for List<T> { fn deref_mut(&mut self) -> &mut Self::Target { &mut self.0 } } impl<T> Default for List<T> { fn default() -> Self { Self(Default::default()) } } impl<T> Index<isize> for List<T> { type Output = T; fn index(&self, index: isize) -> &Self::Output { todo!(); } } #[test] fn it_works() { let mut list: List<u32> = List::default(); for i in 0..16 { list.push_back(i); } assert_eq!(list[0], 0); assert_eq!(list[5], 5); assert_eq!(list[15], 15); assert_eq!(list[16], 0); assert_eq!(list[-1], 15); assert_eq!(list[128], 0); assert_eq!(list[-128], 0); } }
今天你已经完成了Rust学习的第14次打卡,坚持学习,如果你觉得有收获,也欢迎分享给身边的朋友,邀TA一起讨论。我们下节课见~
数据结构:这些浓眉大眼的结构竟然都是智能指针?
你好,我是陈天。
到现在为止我们学了Rust的所有权与生命周期、内存管理以及类型系统,基础知识里还剩一块版图没有涉及:数据结构,数据结构里最容易让人困惑的就是智能指针,所以今天我们就来解决这个难点。
我们之前简单介绍过指针,这里还是先回顾一下:指针是一个持有内存地址的值,可以通过解引用来访问它指向的内存地址,理论上可以解引用到任意数据类型;引用是一个特殊的指针,它的解引用访问是受限的,只能解引用到它引用数据的类型,不能用作它用。
那什么是智能指针呢?
智能指针
在指针和引用的基础上,Rust 偷师 C++,提供了智能指针。智能指针是一个表现行为很像指针的数据结构,但除了指向数据的指针外,它还有元数据以提供额外的处理能力。
这个定义有点模糊,我们对比其他的数据结构来明确一下。
你有没有觉得很像之前讲的胖指针。智能指针一定是一个胖指针,但胖指针不一定是一个智能指针。比如 &str 就只是一个胖指针,它有指向堆内存字符串的指针,同时还有关于字符串长度的元数据。
我们看智能指针 String 和 &str 的区别:
从图上可以看到,String 除了多一个 capacity 字段,似乎也没有什么特殊。 但 String 对堆上的值有所有权,而 &str 是没有所有权的,这是 Rust 中智能指针和普通胖指针的区别。
那么又有一个问题了,智能指针和结构体有什么区别呢?因为我们知道,String 是用结构体定义的:
#![allow(unused)] fn main() { pub struct String { vec: Vec<u8>, } }
和普通的结构体不同的是,String 实现了 Deref 和 DerefMut,这使得它在解引用的时候,会得到 &str,看下面的 标准库的实现:
#![allow(unused)] fn main() { impl ops::Deref for String { type Target = str; fn deref(&self) -> &str { unsafe { str::from_utf8_unchecked(&self.vec) } } } impl ops::DerefMut for String { fn deref_mut(&mut self) -> &mut str { unsafe { str::from_utf8_unchecked_mut(&mut *self.vec) } } } }
另外,由于在堆上分配了数据,String 还需要为其分配的资源做相应的回收。而 String 内部使用了 Vec
#![allow(unused)] fn main() { unsafe impl<#[may_dangle] T, A: Allocator> Drop for Vec<T, A> { fn drop(&mut self) { unsafe { // use drop for [T] // use a raw slice to refer to the elements of the vector as weakest necessary type; // could avoid questions of validity in certain cases ptr::drop_in_place(ptr::slice_from_raw_parts_mut(self.as_mut_ptr(), self.len)) } // RawVec handles deallocation } } }
所以再清晰一下定义, 在 Rust 中,凡是需要做资源回收的数据结构,且实现了 Deref/DerefMut/Drop,都是智能指针。
按照这个定义,除了 String,在之前的课程中我们遇到了很多智能指针,比如用于在堆上分配内存的 Box
今天我们就深入分析三个使用智能指针的数据结构:在堆上创建内存的 Box
而且最后我们会尝试实现自己的智能指针。希望学完后你不但能更好地理解智能指针,还能在需要的时候,构建自己的智能指针来解决问题。
Box
我们先看 Box
为什么有Box
C 需要使用 malloc/calloc/realloc/free 来处理内存的分配,很多时候,被分配出来的内存在函数调用中来来回回使用,导致谁应该负责释放这件事情很难确定,给开发者造成了极大的心智负担。
C++ 在此基础上改进了一下,提供了一个智能指针 unique_ptr,可以在指针退出作用域的时候释放堆内存,这样保证了堆内存的单一所有权。这个 unique_ptr 就是 Rust 的 Box
你看 Box
#![allow(unused)] fn main() { pub struct Unique<T: ?Sized> { pointer: *const T, // NOTE: this marker has no consequences for variance, but is necessary // for dropck to understand that we logically own a `T`. // // For details, see: // https://github.com/rust-lang/rfcs/blob/master/text/0769-sound-generic-drop.md#phantom-data _marker: PhantomData<T>, } }
我们知道,在堆上分配内存,需要使用内存分配器(Allocator)。如果你上过操作系统课程,应该还记得一个简单的 buddy system 是如何分配和管理堆内存的。
设计内存分配器的目的除了保证正确性之外,就是为了有效地利用剩余内存,并控制内存在分配和释放过程中产生的碎片的数量。在多核环境下,它还要能够高效地处理并发请求。(如果你对通用内存分配器感兴趣,可以看参考资料)
堆上分配内存的 Box
#![allow(unused)] fn main() { pub struct Box<T: ?Sized,A: Allocator = Global>(Unique<T>, A) }
Allocator trait 提供很多方法:
- allocate是主要方法,用于分配内存,对应 C 的 malloc/calloc;
- deallocate,用于释放内存,对应 C 的 free;
- 还有 grow / shrink,用来扩大或缩小堆上已分配的内存,对应 C 的 realloc。
这里对 Allocator trait 我们就不详细介绍了,如果你想替换默认的内存分配器,可以使用 #[global_allocator] 标记宏,定义你自己的全局分配器。下面的代码展示了如何在 Rust 下使用 jemalloc:
use jemallocator::Jemalloc; #[global_allocator] static GLOBAL: Jemalloc = Jemalloc; fn main() {}
这样设置之后,你使用 Box::new() 分配的内存就是 jemalloc 分配出来的了。另外,如果你想撰写自己的全局分配器,可以实现 GlobalAlloc trait,它和 Allocator trait 的区别,主要在于是否允许分配长度为零的内存。
使用场景
下面我们来实现一个自己的内存分配器。别担心,这里就是想 debug 一下,看看内存如何分配和释放,并不会实际实现某个分配算法。
首先看内存的分配。这里 MyAllocator 就用 System allocator,然后加 eprintln!(),和我们常用的 println!() 不同的是,eprintln!() 将数据打印到 stderr( 代码):
use std::alloc::{GlobalAlloc, Layout, System}; struct MyAllocator; unsafe impl GlobalAlloc for MyAllocator { unsafe fn alloc(&self, layout: Layout) -> *mut u8 { let data = System.alloc(layout); eprintln!("ALLOC: {:p}, size {}", data, layout.size()); data } unsafe fn dealloc(&self, ptr: *mut u8, layout: Layout) { System.dealloc(ptr, layout); eprintln!("FREE: {:p}, size {}", ptr, layout.size()); } } #[global_allocator] static GLOBAL: MyAllocator = MyAllocator; #[allow(dead_code)] struct Matrix { // 使用不规则的数字如 505 可以让 dbg! 的打印很容易分辨出来 data: [u8; 505], } impl Default for Matrix { fn default() -> Self { Self { data: [0; 505] } } } fn main() { // 在这句执行之前已经有好多内存分配 let data = Box::new(Matrix::default()); // 输出中有一个 1024 大小的内存分配,是 println! 导致的 println!( "!!! allocated memory: {:p}, len: {}", &*data, std::mem::size_of::<Matrix>() ); // data 在这里 drop,可以在打印中看到 FREE // 之后还有很多其它内存被释放 }
注意这里不能使用 println!() 。因为 stdout 会打印到一个由 Mutex 互斥锁保护的共享全局 buffer 中,这个过程中会涉及内存的分配,分配的内存又会触发 println!(),最终造成程序崩溃。而 eprintln! 直接打印到 stderr,不会 buffer。
运行这段代码,你可以看到类似如下输出,其中 505 大小的内存是我们 Box::new() 出来的:
❯ cargo run --bin allocator --quiet
ALLOC: 0x7fbe0dc05c20, size 4
ALLOC: 0x7fbe0dc05c30, size 5
FREE: 0x7fbe0dc05c20, size 4
ALLOC: 0x7fbe0dc05c40, size 64
ALLOC: 0x7fbe0dc05c80, size 48
ALLOC: 0x7fbe0dc05cb0, size 80
ALLOC: 0x7fbe0dc05da0, size 24
ALLOC: 0x7fbe0dc05dc0, size 64
ALLOC: 0x7fbe0dc05e00, size 505
ALLOC: 0x7fbe0e008800, size 1024
!!! allocated memory: 0x7fbe0dc05e00, len: 505
FREE: 0x7fbe0dc05e00, size 505
FREE: 0x7fbe0e008800, size 1024
FREE: 0x7fbe0dc05c30, size 5
FREE: 0x7fbe0dc05c40, size 64
FREE: 0x7fbe0dc05c80, size 48
FREE: 0x7fbe0dc05cb0, size 80
FREE: 0x7fbe0dc05dc0, size 64
FREE: 0x7fbe0dc05da0, size 24
在使用 Box 分配堆内存的时候要注意,Box::new() 是一个函数,所以传入它的数据会出现在栈上,再移动到堆上。所以,如果我们的 Matrix 结构不是 505 个字节,是一个非常大的结构,就有可能出问题。
比如下面的代码想在堆上分配 16M 内存,如果你在 playground 里运行,直接栈溢出 stack overflow( 代码):
fn main() { // 在堆上分配 16M 内存,但它会现在栈上出现,再移动到堆上 let boxed = Box::new([0u8; 1 << 24]); println!("len: {}", boxed.len()); }
但如果你在本地使用 “cargo run —release” 编译成 release 代码运行,会正常执行!
这是因为 “cargo run” 或者在 playground 下运行,默认是 debug build,它不会做任何 inline 的优化,而 Box::new() 的实现就一行代码,并注明了要 inline,在 release 模式下,这个函数调用会被优化掉:
#![allow(unused)] fn main() { #[cfg(not(no_global_oom_handling))] #[inline(always)] #[doc(alias = "alloc")] #[doc(alias = "malloc")] #[stable(feature = "rust1", since = "1.0.0")] pub fn new(x: T) -> Self { box x } }
如果不 inline,整个 16M 的大数组会通过栈内存传递给 Box::new,导致栈溢出。这里我们惊喜地发现了一个新的关键字 box。然而 box 是 Rust 内部的关键字,用户代码无法调用,它只出现在 Rust 代码中,用于分配堆内存,box 关键字在编译时,会使用内存分配器分配内存。
搞明白 Box
#![allow(unused)] fn main() { #[stable(feature = "rust1", since = "1.0.0")] unsafe impl<#[may_dangle] T: ?Sized, A: Allocator> Drop for Box<T, A> { fn drop(&mut self) { // FIXME: Do nothing, drop is currently performed by compiler. } } }
哈,目前 drop trait 什么都没有做,编译器会自动插入 deallocate 的代码。这是 Rust 语言的一种策略: 在具体实现还没有稳定下来之前,我先把接口稳定,实现随着之后的迭代慢慢稳定。
这样可以极大地避免语言在发展的过程中,引入对开发者而言的破坏性更新(breaking change)。破坏性更新会使得开发者在升级语言的版本时,不得不大幅更改原有代码。
Python 是个前车之鉴,由于引入了大量的破坏性更新,Python 2 到 3 的升级花了十多年才慢慢完成。所以 Rust 在设计接口时非常谨慎,很多重要的接口都先以库的形式存在了很久,最终才成为标准库的一部分,比如 Future trait。一旦接口稳定后,内部的实现可以慢慢稳定。
Cow<'a, B>
了解了 Box 的工作原理后,再来看 Cow<'a, B>的原理和使用场景,( 第12讲)讲泛型数据结构的时候,我们简单讲过参数B的三个约束。
Cow 是 Rust 下用于提供写时克隆(Clone-on-Write)的一个智能指针,它跟虚拟内存管理的写时复制(Copy-on-write)有异曲同工之妙: 包裹一个只读借用,但如果调用者需要所有权或者需要修改内容,那么它会 clone 借用的数据。
我们看Cow的定义:
#![allow(unused)] fn main() { pub enum Cow<'a, B> where B: 'a + ToOwned + ?Sized { Borrowed(&'a B), Owned(<B as ToOwned>::Owned), } }
它是一个 enum,可以包含一个对类型 B 的只读引用,或者包含对类型 B 的拥有所有权的数据。
这里又引入了两个 trait,首先是 ToOwned,在 ToOwned trait 定义的时候,又引入了 Borrow trait,它们都是 std::borrow 下的 trait:
#![allow(unused)] fn main() { pub trait ToOwned { type Owned: Borrow<Self>; #[must_use = "cloning is often expensive and is not expected to have side effects"] fn to_owned(&self) -> Self::Owned; fn clone_into(&self, target: &mut Self::Owned) { ... } } pub trait Borrow<Borrowed> where Borrowed: ?Sized { fn borrow(&self) -> &Borrowed; } }
如果你看不懂这段代码,不要着急,想要理解 Cow trait,ToOwned trait 是一道坎,因为 type Owned: Borrow
首先,type Owned: Borrow
#![allow(unused)] fn main() { impl ToOwned for str { type Owned = String; #[inline] fn to_owned(&self) -> String { unsafe { String::from_utf8_unchecked(self.as_bytes().to_owned()) } } fn clone_into(&self, target: &mut String) { let mut b = mem::take(target).into_bytes(); self.as_bytes().clone_into(&mut b); *target = unsafe { String::from_utf8_unchecked(b) } } } }
可以看到关联类型 Owned 被定义为 String,而根据要求,String 必须定义 Borrow
ToOwned 要求是 Borrow
#![allow(unused)] fn main() { impl Borrow<str> for String { #[inline] fn borrow(&self) -> &str { &self[..] } } }
你是不是有点晕了,我用一张图梳理了这几个 trait 之间的关系:
通过这张图,我们可以更好地搞清楚 Cow 和 ToOwned / Borrow
这里,你可能会疑惑,为何 Borrow 要定义成一个泛型 trait 呢?搞这么复杂,难道一个类型还可以被借用成不同的引用么?
是的。我们看一个例子( 代码):
use std::borrow::Borrow; fn main() { let s = "hello world!".to_owned(); // 这里必须声明类型,因为 String 有多个 Borrow<T> 实现 // 借用为 &String let r1: &String = s.borrow(); // 借用为 &str let r2: &str = s.borrow(); println!("r1: {:p}, r2: {:p}", r1, r2); }
在这里例子里,String 可以被借用为 &String,也可以被借用为 &str。
好,再来继续看 Cow。我们说它是智能指针,那它自然需要 实现 Deref trait:
#![allow(unused)] fn main() { impl<B: ?Sized + ToOwned> Deref for Cow<'_, B> { type Target = B; fn deref(&self) -> &B { match *self { Borrowed(borrowed) => borrowed, Owned(ref owned) => owned.borrow(), } } } }
实现的原理很简单,根据 self 是 Borrowed 还是 Owned,我们分别取其内容,生成引用:
- 对于 Borrowed,直接就是引用;
- 对于 Owned,调用其 borrow() 方法,获得引用。
这就很厉害了。虽然 Cow 是一个 enum,但是通过 Deref 的实现,我们可以获得统一的体验,比如 Cow
使用场景
那么 Cow 有什么用呢?显然,它可以在需要的时候才进行内存的分配和拷贝,在很多应用场合,它可以大大提升系统的效率。如果 Cow<'a, B> 中的 Owned 数据类型是一个需要在堆上分配内存的类型,如 String、Vec
我们说过,相对于栈内存的分配释放来说,堆内存的分配和释放效率要低很多,其内部还涉及系统调用和锁, 减少不必要的堆内存分配是提升系统效率的关键手段。而 Rust 的 Cow<'a, B>,在帮助你达成这个效果的同时,使用体验还非常简单舒服。
光这么说没有代码佐证,我们看一个使用 Cow 的实际例子。
在解析 URL 的时候,我们经常需要将 querystring 中的参数,提取成 KV pair 来进一步使用。绝大多数语言中,提取出来的 KV 都是新的字符串,在每秒钟处理几十 k 甚至上百 k 请求的系统中,你可以想象这会带来多少次堆内存的分配。
但在 Rust 中,我们可以用 Cow 类型轻松高效处理它,在读取 URL 的过程中:
- 每解析出一个 key 或者 value,我们可以用一个 &str 指向 URL 中相应的位置,然后用 Cow 封装它;
- 而当解析出来的内容不能直接使用,需要 decode 时,比如 “hello%20world”,我们可以生成一个解析后的 String,同样用 Cow 封装它。
看下面的例子( 代码):
use std::borrow::Cow; use url::Url; fn main() { let url = Url::parse("https://tyr.com/rust?page=1024&sort=desc&extra=hello%20world").unwrap(); let mut pairs = url.query_pairs(); assert_eq!(pairs.count(), 3); let (mut k, v) = pairs.next().unwrap(); // 因为 k, v 都是 Cow<str> 他们用起来感觉和 &str 或者 String 一样 // 此刻,他们都是 Borrowed println!("key: {}, v: {}", k, v); // 当修改发生时,k 变成 Owned k.to_mut().push_str("_lala"); print_pairs((k, v)); print_pairs(pairs.next().unwrap()); // 在处理 extra=hello%20world 时,value 被处理成 "hello world" // 所以这里 value 是 Owned print_pairs(pairs.next().unwrap()); } fn print_pairs(pair: (Cow<str>, Cow<str>)) { println!("key: {}, value: {}", show_cow(pair.0), show_cow(pair.1)); } fn show_cow(cow: Cow<str>) -> String { match cow { Cow::Borrowed(v) => format!("Borrowed {}", v), Cow::Owned(v) => format!("Owned {}", v), } }
是不是很简洁。
类似 URL parse 这样的处理方式,在 Rust 标准库和第三方库中非常常见。比如 Rust 下著名的 serde 库,可以非常高效地对 Rust 数据结构,进行序列化/反序列化操作,它对 Cow 就有很好的支持。
我们可以通过如下代码将一个 JSON 数据反序列化成 User 类型,同时让 User 中的 name 使用 Cow 来引用 JSON 文本中的内容( 代码):
use serde::Deserialize; use std::borrow::Cow; #[derive(Debug, Deserialize)] struct User<'input> { #[serde(borrow)] name: Cow<'input, str>, age: u8, } fn main() { let input = r#"{ "name": "Tyr", "age": 18 }"#; let user: User = serde_json::from_str(input).unwrap(); match user.name { Cow::Borrowed(x) => println!("borrowed {}", x), Cow::Owned(x) => println!("owned {}", x), } }
未来在你用 Rust 构造系统时,也可以充分考虑在数据类型中使用 Cow。
MutexGuard
如果说,上面介绍的 String、Box
MutexGuard 这个结构是在调用 Mutex::lock 时生成的:
#![allow(unused)] fn main() { pub fn lock(&self) -> LockResult<MutexGuard<'_, T>> { unsafe { self.inner.raw_lock(); MutexGuard::new(self) } } }
首先,它会取得锁资源,如果拿不到,会在这里等待;如果拿到了,会把 Mutex 结构的引用传递给 MutexGuard。
我们看 MutexGuard 的 定义 以及它的 Deref 和 Drop 的 实现,很简单:
#![allow(unused)] fn main() { // 这里用 must_use,当你得到了却不使用 MutexGuard 时会报警 #[must_use = "if unused the Mutex will immediately unlock"] pub struct MutexGuard<'a, T: ?Sized + 'a> { lock: &'a Mutex<T>, poison: poison::Guard, } impl<T: ?Sized> Deref for MutexGuard<'_, T> { type Target = T; fn deref(&self) -> &T { unsafe { &*self.lock.data.get() } } } impl<T: ?Sized> DerefMut for MutexGuard<'_, T> { fn deref_mut(&mut self) -> &mut T { unsafe { &mut *self.lock.data.get() } } } impl<T: ?Sized> Drop for MutexGuard<'_, T> { #[inline] fn drop(&mut self) { unsafe { self.lock.poison.done(&self.poison); self.lock.inner.raw_unlock(); } } } }
从代码中可以看到,当 MutexGuard 结束时,Mutex 会做 unlock,这样用户在使用 Mutex 时,可以不必关心何时释放这个互斥锁。因为无论你在调用栈上怎样传递 MutexGuard ,哪怕在错误处理流程上提前退出,Rust 有所有权机制,可以确保只要 MutexGuard 离开作用域,锁就会被释放。
使用场景
我们来看一个使用 Mutex 和 MutexGuard 的例子( 代码),代码很简单,我写了详尽的注释帮助你理解。
use lazy_static::lazy_static; use std::borrow::Cow; use std::collections::HashMap; use std::sync::{Arc, Mutex}; use std::thread; use std::time::Duration; // lazy_static 宏可以生成复杂的 static 对象 lazy_static! { // 一般情况下 Mutex 和 Arc 一起在多线程环境下提供对共享内存的使用 // 如果你把 Mutex 声明成 static,其生命周期是静态的,不需要 Arc static ref METRICS: Mutex<HashMap<Cow<'static, str>, usize>> = Mutex::new(HashMap::new()); } fn main() { // 用 Arc 来提供并发环境下的共享所有权(使用引用计数) let metrics: Arc<Mutex<HashMap<Cow<'static, str>, usize>>> = Arc::new(Mutex::new(HashMap::new())); for _ in 0..32 { let m = metrics.clone(); thread::spawn(move || { let mut g = m.lock().unwrap(); // 此时只有拿到 MutexGuard 的线程可以访问 HashMap let data = &mut *g; // Cow 实现了很多数据结构的 From trait, // 所以我们可以用 "hello".into() 生成 Cow let entry = data.entry("hello".into()).or_insert(0); *entry += 1; // MutexGuard 被 Drop,锁被释放 }); } thread::sleep(Duration::from_millis(100)); println!("metrics: {:?}", metrics.lock().unwrap()); }
如果你有疑问,这样如何保证锁的线程安全呢?如果我在线程 1 拿到了锁,然后把 MutexGuard 移动给线程 2 使用,加锁和解锁在完全不同的线程下,会有很大的死锁风险。怎么办?
不要担心,MutexGuard 不允许 Send,只允许 Sync,也就是说,你可以把 MutexGuard 的引用传给另一个线程使用,但你无法把 MutexGuard 整个移动到另一个线程:
#![allow(unused)] fn main() { impl<T: ?Sized> !Send for MutexGuard<'_, T> {} unsafe impl<T: ?Sized + Sync> Sync for MutexGuard<'_, T> {} }
类似 MutexGuard 的智能指针有很多用途。比如要创建一个连接池,你可以在 Drop trait 中,回收 checkout 出来的连接,将其再放回连接池。如果你对此感兴趣,可以看看 r2d2 的实现,它是 Rust 下一个数据库连接池的实现。
实现自己的智能指针
到目前为止,三个经典的智能指针,在堆上创建内存的 Box
那么,如果我们想实现自己的智能指针,该怎么做?或者咱们换个问题:有什么数据结构适合实现成为智能指针?
因为很多时候, 我们需要实现一些自动优化的数据结构,在某些情况下是一种优化的数据结构和相应的算法,在其他情况下使用通用的结构和通用的算法。
比如当一个 HashSet 的内容比较少的时候,可以用数组实现,但内容逐渐增多,再转换成用哈希表实现。如果我们想让使用者不用关心这些实现的细节,使用同样的接口就能享受到更好的性能,那么,就可以考虑用智能指针来统一它的行为。
使用小练习
我们来看一个实际的例子。之前讲过,Rust 下 String 在栈上占了 24 个字节,然后在堆上存放字符串实际的内容,对于一些比较短的字符串,这很浪费内存。有没有办法在字符串长到一定程度后,才使用标准的字符串呢?
参考 Cow,我们可以用一个 enum 来处理:当字符串小于 N 字节时,我们直接用栈上的数组,否则,使用 String。但是这个 N 不宜太大,否则当使用 String 时,会比目前的版本浪费内存。
怎么设计呢?之前在内存管理的部分讲过,当使用 enum 时,额外的 tag + 为了对齐而使用的 padding 会占用一些内存。因为 String 结构是 8 字节对齐的,我们的 enum 最小 8 + 24 = 32 个字节。
所以,可以设计一个数据结构, 内部用一个字节表示字符串的长度,用 30 个字节表示字符串内容,再加上 1 个字节的 tag,正好也是 32 字节,可以和 String 放在一个 enum 里使用。我们暂且称这个 enum 叫 MyString,它的结构如下图所示:
为了让 MyString 表现行为和 &str 一致,我们可以通过实现 Deref trait 让 MyString 可以被解引用成 &str。除此之外,还可以实现 Debug/Display 和 From
整个实现的代码如下( 代码),代码本身不难理解,你可以试着自己实现一下,或者一行行抄下来运行,感受一下。
use std::{fmt, ops::Deref, str}; const MINI_STRING_MAX_LEN: usize = 30; // MyString 里,String 有 3 个 word,供 24 字节,所以它以 8 字节对齐 // 所以 enum 的 tag + padding 最少 8 字节,整个结构占 32 字节。 // MiniString 可以最多有 30 字节(再加上 1 字节长度和 1字节 tag),就是 32 字节. struct MiniString { len: u8, data: [u8; MINI_STRING_MAX_LEN], } impl MiniString { // 这里 new 接口不暴露出去,保证传入的 v 的字节长度小于等于 30 fn new(v: impl AsRef<str>) -> Self { let bytes = v.as_ref().as_bytes(); // 我们在拷贝内容时一定要使用字符串的字节长度 let len = bytes.len(); let mut data = [0u8; MINI_STRING_MAX_LEN]; data[..len].copy_from_slice(bytes); Self { len: len as u8, data, } } } impl Deref for MiniString { type Target = str; fn deref(&self) -> &Self::Target { // 由于生成 MiniString 的接口是隐藏的,它只能来自字符串,所以下面这行是安全的 str::from_utf8(&self.data[..self.len as usize]).unwrap() // 也可以直接用 unsafe 版本 // unsafe { str::from_utf8_unchecked(&self.data[..self.len as usize]) } } } impl fmt::Debug for MiniString { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { // 这里由于实现了 Deref trait,可以直接得到一个 &str 输出 write!(f, "{}", self.deref()) } } #[derive(Debug)] enum MyString { Inline(MiniString), Standard(String), } // 实现 Deref 接口对两种不同的场景统一得到 &str impl Deref for MyString { type Target = str; fn deref(&self) -> &Self::Target { match *self { MyString::Inline(ref v) => v.deref(), MyString::Standard(ref v) => v.deref(), } } } impl From<&str> for MyString { fn from(s: &str) -> Self { match s.len() > MINI_STRING_MAX_LEN { true => Self::Standard(s.to_owned()), _ => Self::Inline(MiniString::new(s)), } } } impl fmt::Display for MyString { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "{}", self.deref()) } } fn main() { let len1 = std::mem::size_of::<MyString>(); let len2 = std::mem::size_of::<MiniString>(); println!("Len: MyString {}, MiniString {}", len1, len2); let s1: MyString = "hello world".into(); let s2: MyString = "这是一个超过了三十个字节的很长很长的字符串".into(); // debug 输出 println!("s1: {:?}, s2: {:?}", s1, s2); // display 输出 println!( "s1: {}({} bytes, {} chars), s2: {}({} bytes, {} chars)", s1, s1.len(), s1.chars().count(), s2, s2.len(), s2.chars().count() ); // MyString 可以使用一切 &str 接口,感谢 Rust 的自动 Deref assert!(s1.ends_with("world")); assert!(s2.starts_with("这")); }
这个简单实现的 MyString,不管它内部的数据是纯栈上的 MiniString 版本,还是包含堆上内存的 String 版本,使用的体验和 &str 都一致,仅仅牺牲了一点点效率和内存,就可以让小容量的字符串,可以高效地存储在栈上并且自如地使用。
事实上,Rust 有个叫 smartstring 的第三方库就实现了这个功能。我们的版本在内存上不算经济,对于 String 来说,额外多用了 8 个字节,smartstring 通过优化,只用了和 String 结构一样大小的 24 个字节,就达到了我们想要的结果。你如果感兴趣的话,欢迎去看看它的 源代码。
小结
今天我们介绍了三个重要的智能指针,它们有各自独特的实现方式和使用场景。
Box
Cow 实现了 Clone-on-write 的数据结构,让你可以在需要的时候再获得数据的所有权。Cow 结构是一种使用 enum 根据当前的状态进行分发的经典方案。甚至,你可以用类似的方案取代 trait object 做动态分发, 其效率是动态分发的数十倍。
如果你想合理地处理资源相关的管理,MutexGuard 是一个很好的参考,它把从 Mutex 中获得的锁包装起来,实现只要 MutexGuard 退出作用域,锁就一定会释放。如果你要做资源池,可以使用类似 MutexGuard 的方式。
思考题
- 目前 MyString 只能从 &str 生成。如果要支持从 String 中生成一个 MyString,该怎么做?
- 目前 MyString 只能读取,不能修改,能不能给它加上类似 String 的 push_str 接口?
- 你知道 Cow<[u8]> 和 Cow
的大小么?试着打印一下看看。想想,为什么它的大小是这样呢?
欢迎在留言区分享你的思考。今天你已经完成Rust学习第15次打卡了,继续加油,我们下节课见~
参考资料
常见的通用内存分配器有 glibc 的 pthread malloc、Google 开发的 tcmalloc、FreeBSD 上默认使用的 jemalloc 等。除了通用内存分配器,对于特定类型内存的分配,我们还可以用 slab,slab 相当于一个预分配好的对象池,可以扩展和收缩。
数据结构:Vec、&[T]、Box<[T]> ,你真的了解集合容器么?
你好,我是陈天。今天来学集合容器。
现在我们接触到了越来越多的数据结构,我把 Rust 中主要的数据结构从原生类型、容器类型和系统相关类型几个维度整理一下,你可以数数自己掌握了哪些。
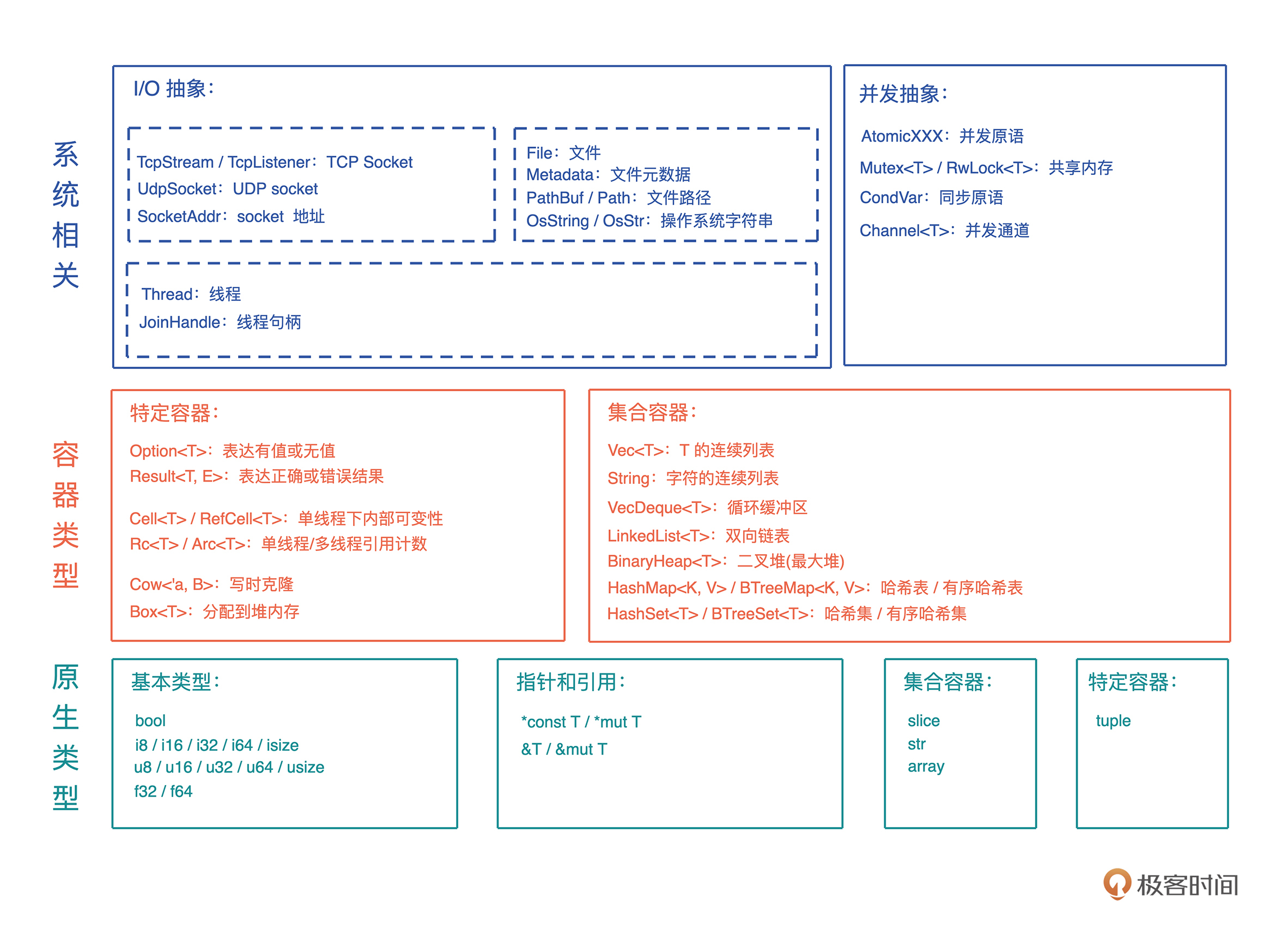
可以看到,容器占据了数据结构的半壁江山。
提到容器,很可能你首先会想到的就是数组、列表这些可以遍历的容器,但其实 只要把某种特定的数据封装在某个数据结构中,这个数据结构就是一个容器。比如 Option
对于容器的两小类,到目前为止,像 Cow 这样,为特定目的而产生的容器我们已经介绍了不少,包括 Box、Rc、Arc、RefCell、还没讲到的 Option 和 Result 等。
今天我们来详细讲讲另一类,集合容器。
集合容器
集合容器,顾名思义,就是把一系列拥有相同类型的数据放在一起,统一处理,比如:
- 我们熟悉的字符串 String、数组 [T; n]、列表 Vec
和哈希表 HashMap<K, V>等; - 虽然到处在使用,但还并不熟悉的切片 slice;
- 在其他语言中使用过,但在 Rust 中还没有用过的循环缓冲区 VecDeque
、双向列表 LinkedList 等。
这些集合容器有很多共性,比如可以被遍历、可以进行 map-reduce 操作、可以从一种类型转换成另一种类型等等。
我们会选取两类典型的集合容器:切片和哈希表,深入解读,理解了这两类容器,其它的集合容器设计思路都差不多,并不难学习。今天先介绍切片以及和切片相关的容器,下一讲我们学习哈希表。
切片究竟是什么?
在 Rust 里,切片是描述一组属于同一类型、长度不确定的、在内存中连续存放的数据结构,用 [T] 来表述。因为长度不确定,所以切片是个 DST(Dynamically Sized Type)。
切片一般只出现在数据结构的定义中,不能直接访问,在使用中主要用以下形式:
- &[T]:表示一个只读的切片引用。
- &mut [T]:表示一个可写的切片引用。
- Box<[T]>:一个在堆上分配的切片。
怎么理解切片呢?我打个比方, 切片之于具体的数据结构,就像数据库中的视图之于表。你可以把它看成一种工具,让我们可以统一访问行为相同、结构类似但有些许差异的类型。
来看下面的 代码,辅助理解:
fn main() { let arr = [1, 2, 3, 4, 5]; let vec = vec![1, 2, 3, 4, 5]; let s1 = &arr[..2]; let s2 = &vec[..2]; println!("s1: {:?}, s2: {:?}", s1, s2); // &[T] 和 &[T] 是否相等取决于长度和内容是否相等 assert_eq!(s1, s2); // &[T] 可以和 Vec<T>/[T;n] 比较,也会看长度和内容 assert_eq!(&arr[..], vec); assert_eq!(&vec[..], arr); }
对于 array 和 vector,虽然是不同的数据结构,一个放在栈上,一个放在堆上,但它们的切片是类似的;而且对于相同内容数据的相同切片,比如 &arr[1…3] 和 &vec[1…3],这两者是等价的。除此之外,切片和对应的数据结构也可以直接比较,这是因为它们之间实现了 PartialEq trait( 源码参考资料)。
下图比较清晰地呈现了切片和数据之间的关系: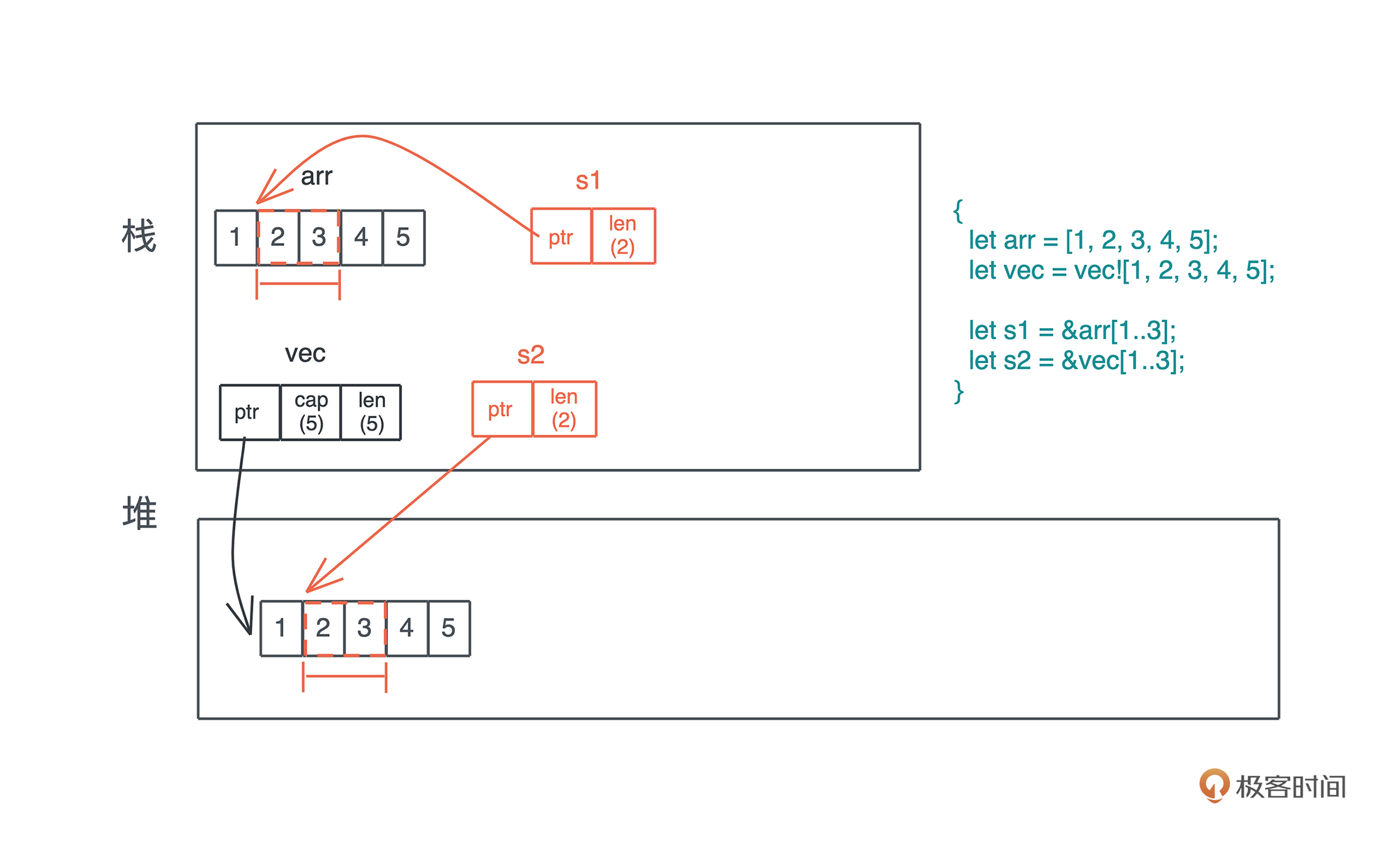
另外在 Rust 下,切片日常中都是使用引用 &[T],所以很多同学容易搞不清楚 &[T] 和 &Vec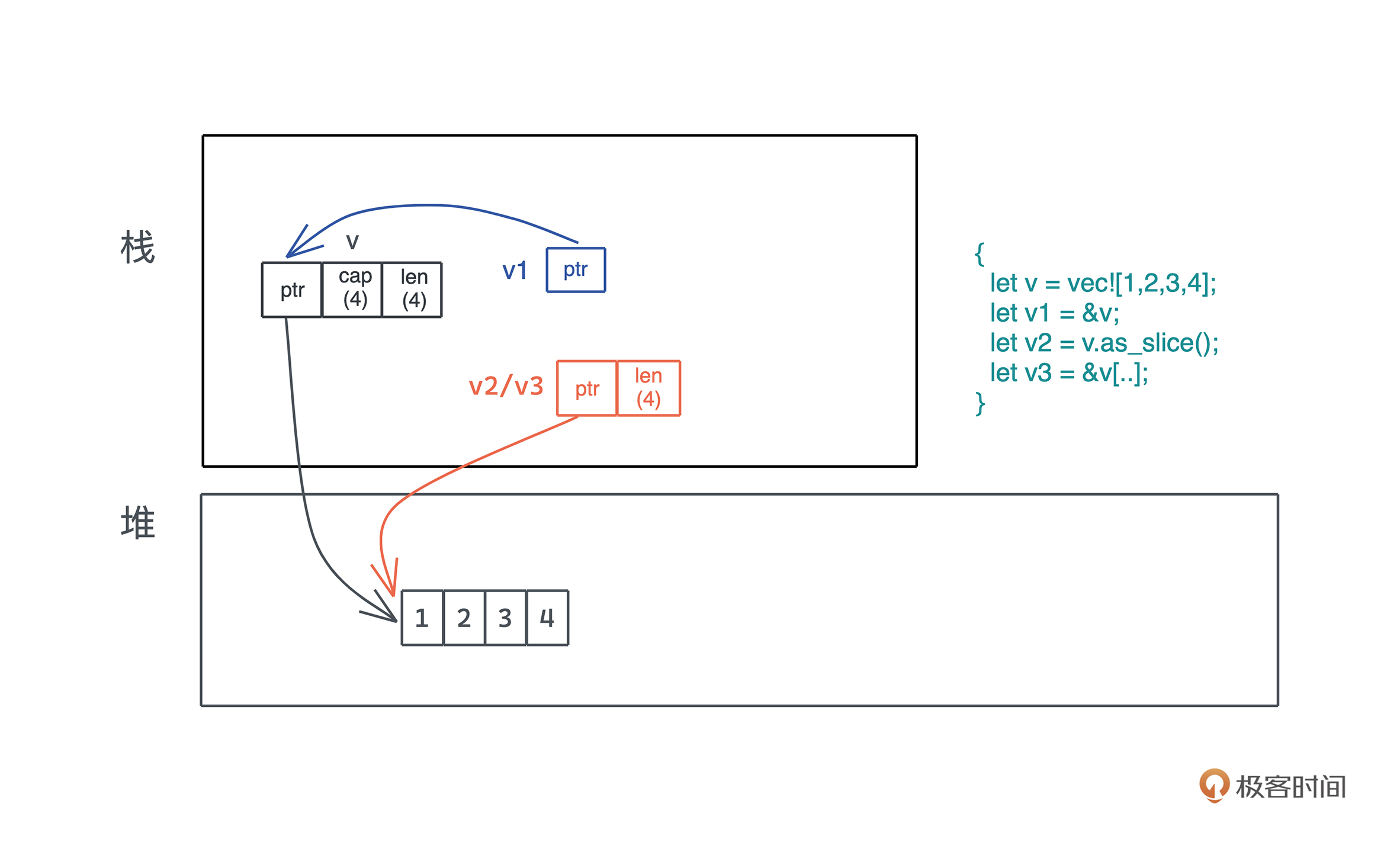
在使用的时候,支持切片的具体数据类型,你可以根据需要,解引用转换成切片类型。比如 Vec
use std::fmt; fn main() { let v = vec![1, 2, 3, 4]; // Vec 实现了 Deref,&Vec<T> 会被自动解引用为 &[T],符合接口定义 print_slice(&v); // 直接是 &[T],符合接口定义 print_slice(&v[..]); // &Vec<T> 支持 AsRef<[T]> print_slice1(&v); // &[T] 支持 AsRef<[T]> print_slice1(&v[..]); // Vec<T> 也支持 AsRef<[T]> print_slice1(v); let arr = [1, 2, 3, 4]; // 数组虽没有实现 Deref,但它的解引用就是 &[T] print_slice(&arr); print_slice(&arr[..]); print_slice1(&arr); print_slice1(&arr[..]); print_slice1(arr); } // 注意下面的泛型函数的使用 fn print_slice<T: fmt::Debug>(s: &[T]) { println!("{:?}", s); } fn print_slice1<T, U>(s: T) where T: AsRef<[U]>, U: fmt::Debug, { println!("{:?}", s.as_ref()); }
这也就意味着,通过解引用,这几个和切片有关的数据结构都会获得切片的所有能力,包括:binary_search、chunks、concat、contains、start_with、end_with、group_by、iter、join、sort、split、swap 等一系列丰富的功能,感兴趣的同学可以看 切片的文档。
切片和迭代器 Iterator
迭代器可以说是切片的孪生兄弟。 切片是集合数据的视图,而迭代器定义了对集合数据的各种各样的访问操作。
通过切片的 iter() 方法,我们可以生成一个迭代器,对切片进行迭代。
在 第12讲 Rust类型推导已经见过了 iterator trait(用 collect 方法把过滤出来的数据形成新列表)。iterator trait 有大量的方法,但绝大多数情况下,我们只需要定义它的关联类型 Item 和 next() 方法。
- Item 定义了每次我们从迭代器中取出的数据类型;
- next() 是从迭代器里取下一个值的方法。当一个迭代器的 next() 方法返回 None 时,表明迭代器中没有数据了。
#![allow(unused)] fn main() { #[must_use = "iterators are lazy and do nothing unless consumed"] pub trait Iterator { type Item; fn next(&mut self) -> Option<Self::Item>; // 大量缺省的方法,包括 size_hint, count, chain, zip, map, // filter, for_each, skip, take_while, flat_map, flatten // collect, partition 等 ... } }
看一个例子,对 Vec
fn main() { // 这里 Vec<T> 在调用 iter() 时被解引用成 &[T],所以可以访问 iter() let result = vec![1, 2, 3, 4] .iter() .map(|v| v * v) .filter(|v| *v < 16) .take(1) .collect::<Vec<_>>(); println!("{:?}", result); }
需要注意的是 Rust 下的迭代器是个懒接口(lazy interface),也就是说 这段代码直到运行到 collect 时才真正开始执行,之前的部分不过是在不断地生成新的结构,来累积处理逻辑而已。你可能好奇,这是怎么做到的呢?
在 VS Code 里,如果你使用了 rust-analyzer 插件,就可以发现这一奥秘:
原来,Iterator 大部分方法都返回一个实现了 Iterator 的数据结构,所以可以这样一路链式下去,在 Rust 标准库中,这些数据结构被称为 Iterator Adapter。比如上面的 map 方法,它返回 Map 结构,而 Map 结构实现了 Iterator( 源码)。
整个过程是这样的(链接均为源码资料):
- 在 collect() 执行的时候,它实际 试图使用 FromIterator 从迭代器中构建一个集合类型,这会不断调用 next() 获取下一个数据;
- 此时的 Iterator 是 Take,Take 调自己的 next(),也就是它会 调用 Filter 的 next();
- Filter 的 next() 实际上 调用自己内部的 iter 的 find(),此时内部的 iter 是 Map,find() 会 使用 try_fold(),它会 继续调用 next(),也就是 Map 的 next();
- Map 的 next() 会 调用其内部的 iter 取 next() 然后执行 map 函数。而此时内部的 iter 来自 Vec
。
所以,只有在 collect() 时,才触发代码一层层调用下去,并且调用会根据需要随时结束。这段代码中我们使用了 take(1),整个调用链循环一次,就能满足 take(1) 以及所有中间过程的要求,所以它只会循环一次。
你可能会有疑惑:这种函数式编程的写法,代码是漂亮了,然而这么多无谓的函数调用,性能肯定很差吧?毕竟,函数式编程语言的一大恶名就是性能差。
这个你完全不用担心, Rust 大量使用了 inline 等优化技巧,这样非常清晰友好的表达方式,性能和 C 语言的 for 循环差别不大。如果你对性能对比感兴趣,可以去最后的参考资料区看看。
介绍完是什么,按惯例我们就要上代码实际使用一下了。不过迭代器是非常重要的一个功能,基本上每种语言都有对迭代器的完整支持,所以只要你之前用过,对此应该并不陌生,大部分的方法,你一看就能明白是在做什么。所以这里就不再额外展示,等你遇到具体需求时,可以翻 Iterator 的文档 查阅。
如果标准库中的功能还不能满足你的需求,你可以看看 itertools,它是和 Python 下 itertools 同名且功能类似的工具,提供了大量额外的 adapter。可以看一个简单的例子( 代码):
use itertools::Itertools; fn main() { let err_str = "bad happened"; let input = vec![Ok(21), Err(err_str), Ok(7)]; let it = input .into_iter() .filter_map_ok(|i| if i > 10 { Some(i * 2) } else { None }); // 结果应该是:vec![Ok(42), Err(err_str)] println!("{:?}", it.collect::<Vec<_>>()); }
在实际开发中,我们可能从一组 Future 中汇聚出一组结果,里面有成功执行的结果,也有失败的错误信息。如果想对成功的结果进一步做 filter/map,那么标准库就无法帮忙了,就需要用 itertools 里的 filter_map_ok()。
特殊的切片:&str
好,学完了普通的切片 &[T],我们来看一种特殊的切片:&str。之前讲过,String 是一个特殊的 Vec
对于 String、&String、&str,很多人也经常分不清它们的区别,我们在之前的一篇加餐中简单聊了这个问题,在上一讲智能指针中,也对比过String和&str。对于&String 和 &str,如果你理解了上文中 &Vec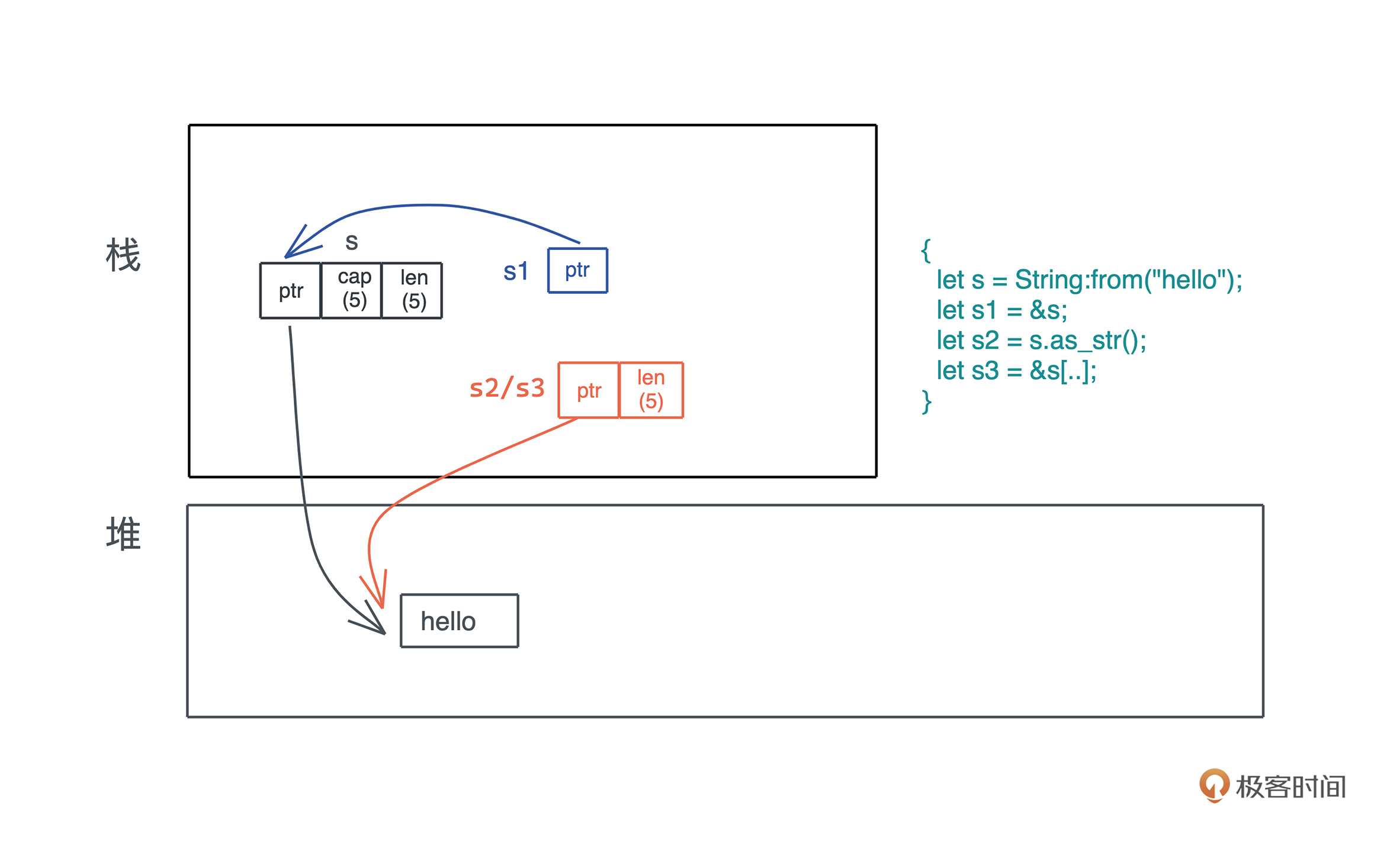
String 在解引用时,会转换成 &str。可以用下面的代码验证( 代码):
use std::fmt; fn main() { let s = String::from("hello"); // &String 会被解引用成 &str print_slice(&s); // &s[..] 和 s.as_str() 一样,都会得到 &str print_slice(&s[..]); // String 支持 AsRef<str> print_slice1(&s); print_slice1(&s[..]); print_slice1(s.clone()); // String 也实现了 AsRef<[u8]>,所以下面的代码成立 // 打印出来是 [104, 101, 108, 108, 111] print_slice2(&s); print_slice2(&s[..]); print_slice2(s); } fn print_slice(s: &str) { println!("{:?}", s); } fn print_slice1<T: AsRef<str>>(s: T) { println!("{:?}", s.as_ref()); } fn print_slice2<T, U>(s: T) where T: AsRef<[U]>, U: fmt::Debug, { println!("{:?}", s.as_ref()); }
有同学会有疑问:那么字符的列表和字符串有什么关系和区别?我们直接写一段代码来看看:
use std::iter::FromIterator; fn main() { let arr = ['h', 'e', 'l', 'l', 'o']; let vec = vec!['h', 'e', 'l', 'l', 'o']; let s = String::from("hello"); let s1 = &arr[1..3]; let s2 = &vec[1..3]; // &str 本身就是一个特殊的 slice let s3 = &s[1..3]; println!("s1: {:?}, s2: {:?}, s3: {:?}", s1, s2, s3); // &[char] 和 &[char] 是否相等取决于长度和内容是否相等 assert_eq!(s1, s2); // &[char] 和 &str 不能直接对比,我们把 s3 变成 Vec<char> assert_eq!(s2, s3.chars().collect::<Vec<_>>()); // &[char] 可以通过迭代器转换成 String,String 和 &str 可以直接对比 assert_eq!(String::from_iter(s2), s3); }
可以看到,字符列表可以通过迭代器转换成 String,String 也可以通过 chars() 函数转换成字符列表,如果不转换,二者不能比较。
下图我把数组、列表、字符串以及它们的切片放在一起比较,可以帮你更好地理解它们的区别: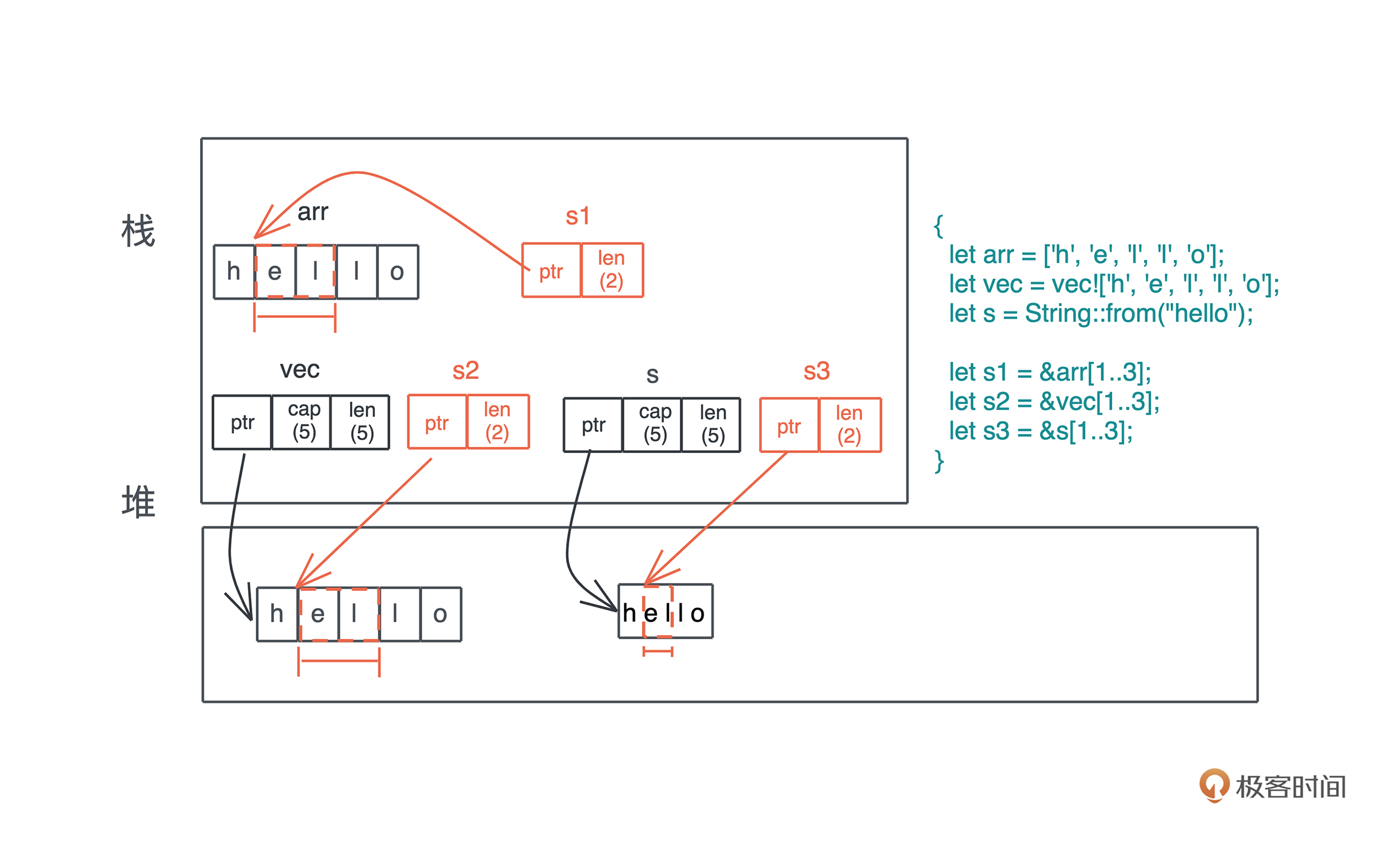
切片的引用和堆上的切片,它们是一回事么?
开头我们讲过,切片主要有三种使用方式:切片的只读引用 &[T]、切片的可变引用 &mut [T] 以及 Box<[T]>。刚才已经详细学习了只读切片 &[T],也和其他各种数据结构进行了对比帮助理解,可变切片 &mut [T] 和它类似,不必介绍。
现在我们来看看 Box<[T]>。
Box<[T]> 是一个比较有意思的存在,它和 Vec
Box<[T]>和切片的引用&[T] 也很类似:它们都是在栈上有一个包含长度的胖指针,指向存储数据的内存位置。区别是:Box<[T]> 只会指向堆,&[T] 指向的位置可以是栈也可以是堆;此外,Box<[T]> 对数据具有所有权,而 &[T] 只是一个借用。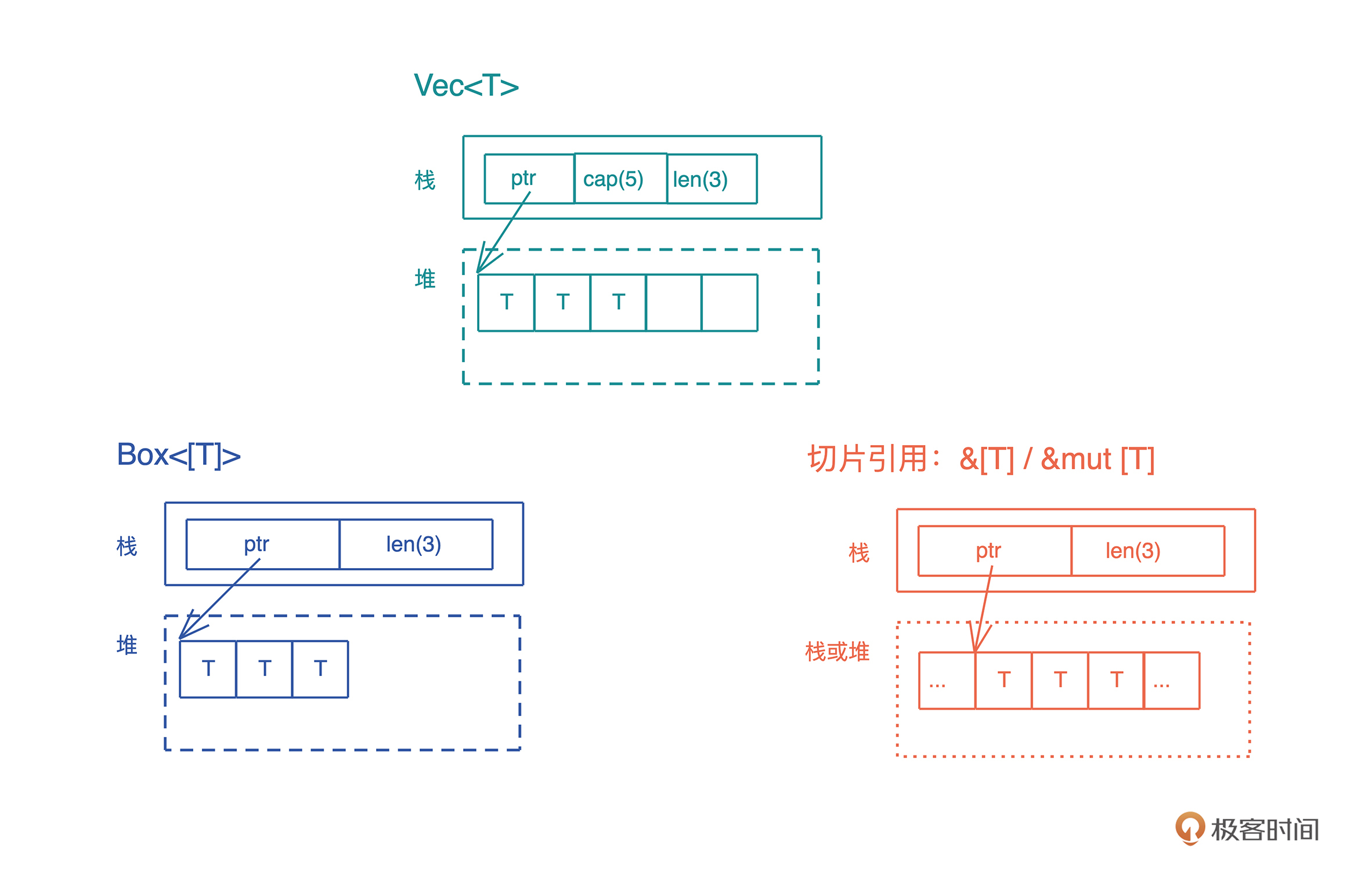
那么如何产生 Box<[T]> 呢?目前可用的接口就只有一个:从已有的 Vec
use std::ops::Deref; fn main() { let mut v1 = vec![1, 2, 3, 4]; v1.push(5); println!("cap should be 8: {}", v1.capacity()); // 从 Vec<T> 转换成 Box<[T]>,此时会丢弃多余的 capacity let b1 = v1.into_boxed_slice(); let mut b2 = b1.clone(); let v2 = b1.into_vec(); println!("cap should be exactly 5: {}", v2.capacity()); assert!(b2.deref() == v2); // Box<[T]> 可以更改其内部数据,但无法 push b2[0] = 2; // b2.push(6); println!("b2: {:?}", b2); // 注意 Box<[T]> 和 Box<[T; n]> 并不相同 let b3 = Box::new([2, 2, 3, 4, 5]); println!("b3: {:?}", b3); // b2 和 b3 相等,但 b3.deref() 和 v2 无法比较 assert!(b2 == b3); // assert!(b3.deref() == v2); }
运行代码可以看到,Vec
这两个转换都是很轻量的转换,只是变换一下结构,不涉及数据的拷贝。区别是,当 Vec
所以, 当我们需要在堆上创建固定大小的集合数据,且不希望自动增长,那么,可以先创建 Vec
小结
我们讨论了切片以及和切片相关的主要数据类型。切片是一个很重要的数据类型,你可以着重理解它存在的意义,以及使用方式。
今天学完相信你也看到了,围绕着切片有很多数据结构,而 切片将它们抽象成相同的访问方式,实现了在不同数据结构之上的同一抽象,这种方法很值得我们学习。此外,当我们构建自己的数据结构时,如果它内部也有连续排列的等长的数据结构,可以考虑 AsRef 或者 Deref 到切片。
下图描述了切片和数组 [T;n]、列表 Vec
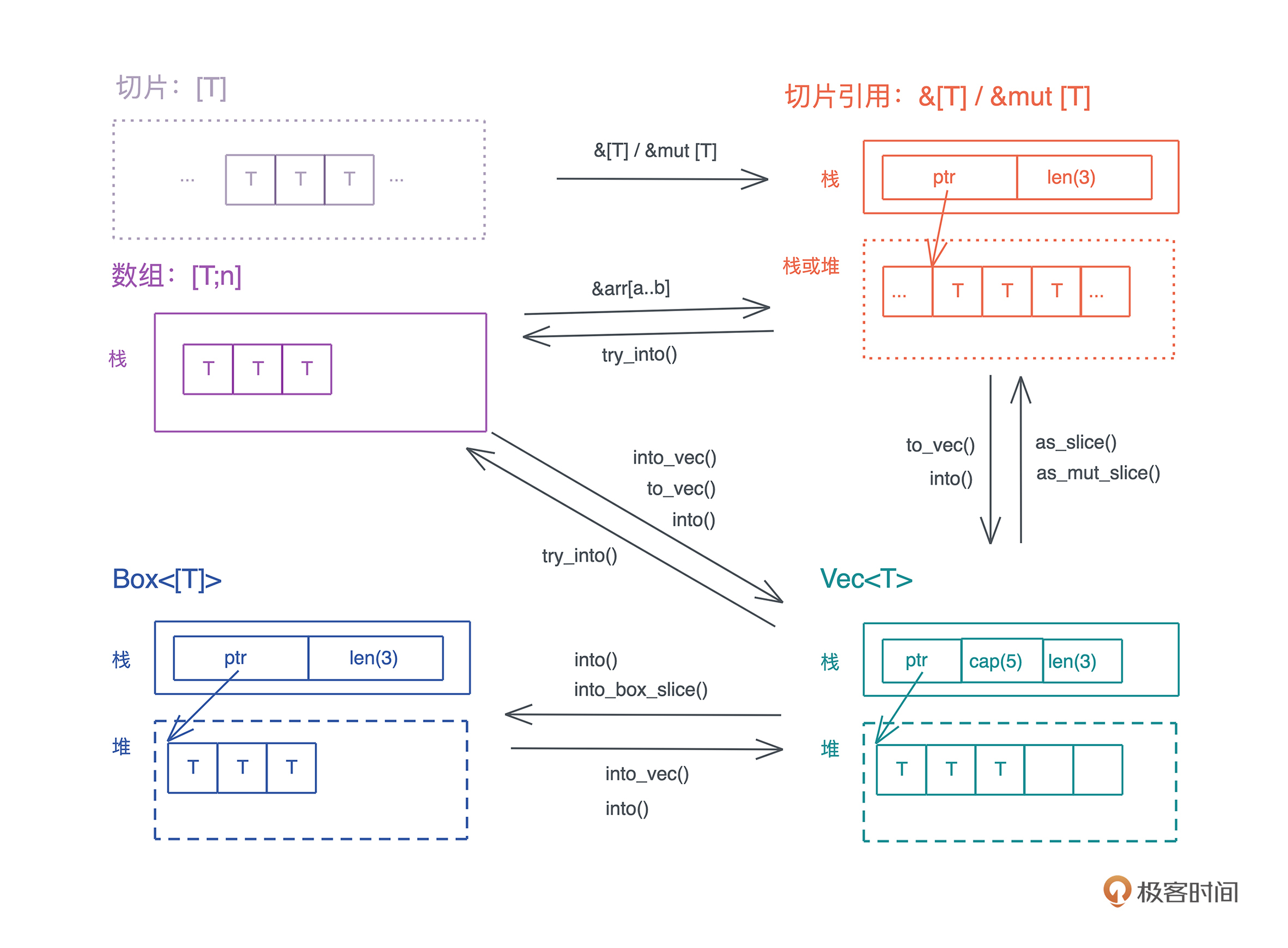
下一讲我们继续学习哈希表……
思考题
1.在讲 &str 时,里面的 print_slice1 函数,如果写成这样可不可以?你可以尝试一下,然后说明理由。
#![allow(unused)] fn main() { // fn print_slice1<T: AsRef<str>>(s: T) { // println!("{:?}", s.as_ref()); // } fn print_slice1<T, U>(s: T) where T: AsRef<U>, U: fmt::Debug, { println!("{:?}", s.as_ref()); } }
2.类似 itertools,你可以试着开发一个新的 Iterator trait IteratorExt,为其提供 window_count 函数,使其可以做下图中的动作( 来源):
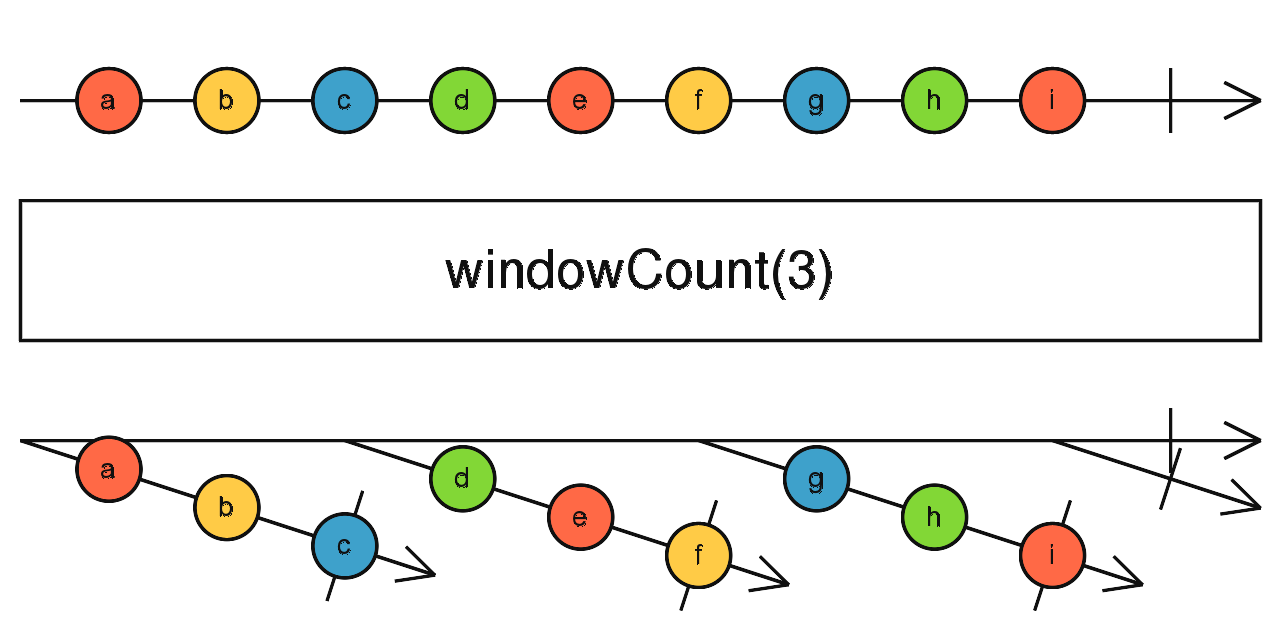
感谢你的阅读,如果你觉得有收获,也欢迎你分享给你身边的朋友,邀他一起讨论。你已经完成了Rust学习的第16次打卡啦,我们下节课见。
参考资料:Rust 的 Iterator 究竟有多快?
当使用 Iterator 提供的这种函数式编程风格的时候,我们往往会担心性能。虽然我告诉你 Rust 大量使用 inline 来优化,但你可能还心存疑惑。
下面的代码和截图来自一个 Youtube 视频: Sharing code between iOS & Android with Rust,演讲者通过在使用 Iterator 处理一个很大的图片,比较 Rust / Swift / Kotlin native / C 这几种语言的性能。你也可以看到在处理迭代器时, Rust 代码和 Kotlin 或者 Swift 代码非常类似。
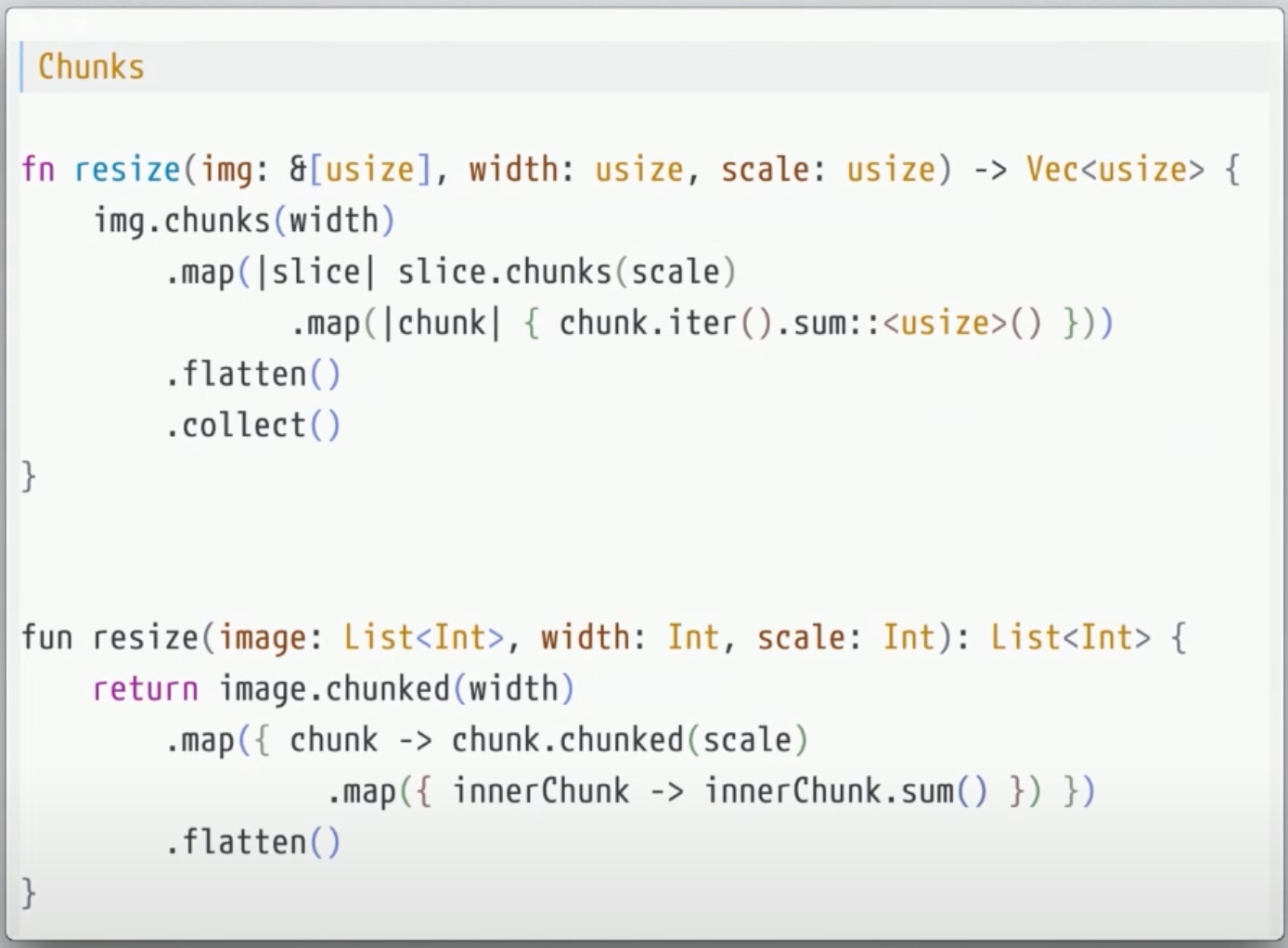
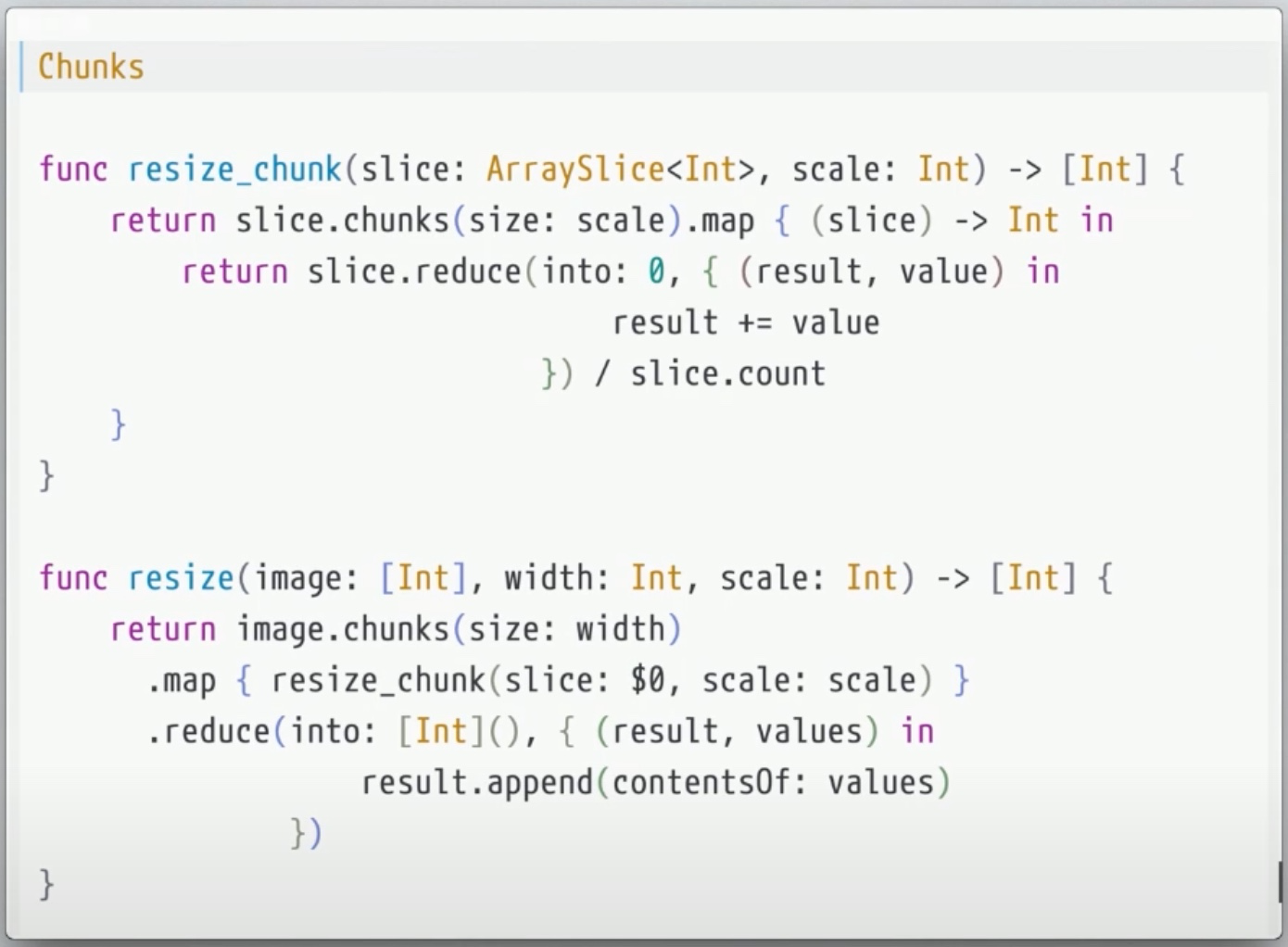
运行结果,在函数式编程方式下(C 没有函数式编程支持,所以直接使用了 for 循环),Rust 和 C 几乎相当在1s 左右,C 比 Rust 快 20%,Swift 花了 11.8s,而 Kotlin native 直接超时:
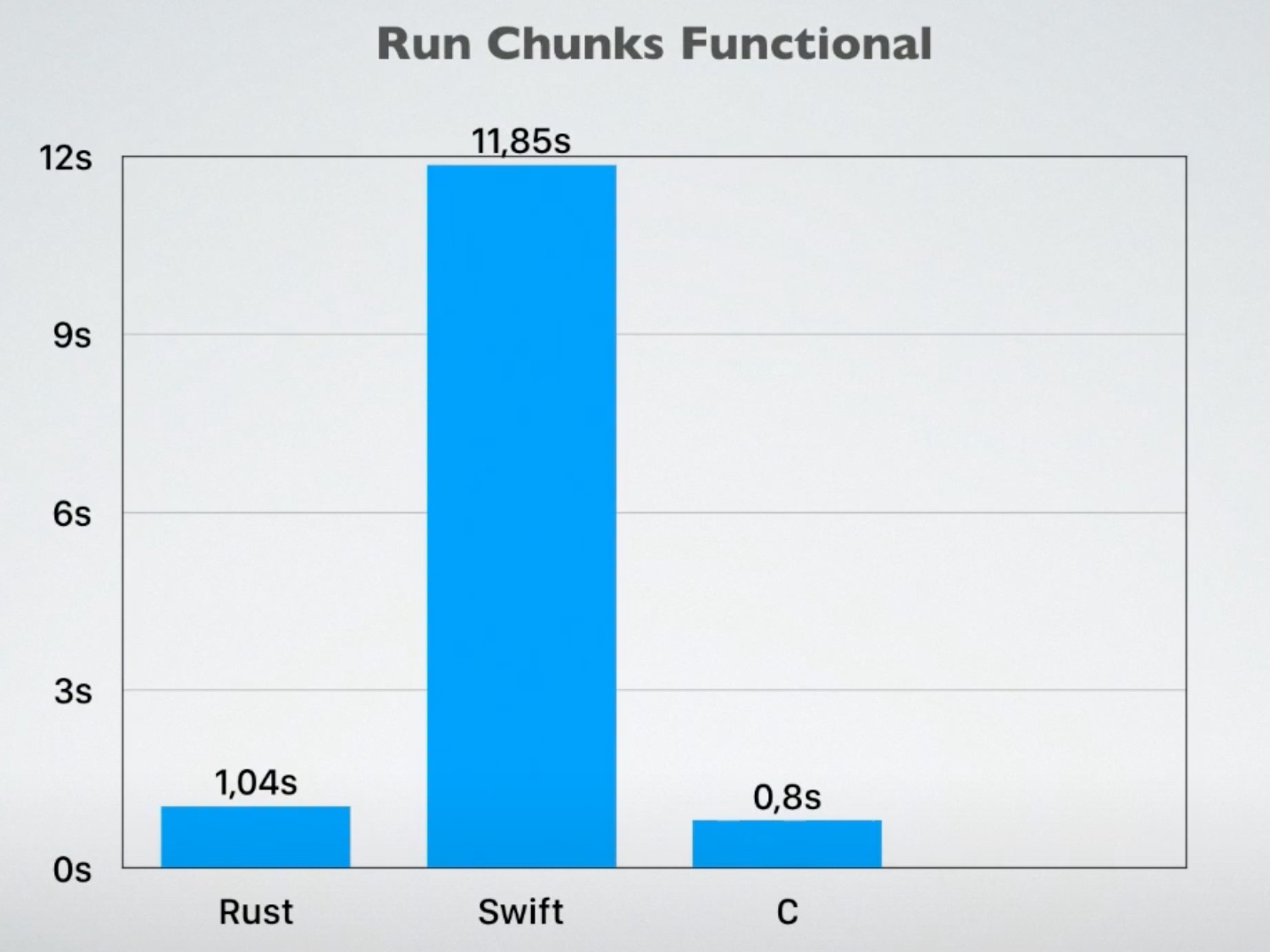
所以 Rust 在对函数式编程,尤其是 Iterator 上的优化,还是非常不错的。这里面除了 inline 外,Rust 闭包的优异性能也提供了很多支持(未来我们会讲为什么)。在使用时,你完全不用担心性能。
数据结构:软件系统核心部件哈希表,内存如何布局?
你好,我是陈天。
上一讲我们深入学习了切片,对比了数组、列表、字符串和它们的切片以及切片引用的关系。今天就继续讲 Rust 里另一个非常重要的集合容器:HashMap,也就是哈希表。
如果谈论软件开发中最重要、出镜率最高的数据结构,那哈希表一定位列其中。很多编程语言甚至将哈希表作为一种内置的数据结构,做进了语言的核心。比如 PHP 的关联数组(associate array)、Python 的字典(dict)、JavaScript 的对象(object)和 Map。
Google 的工程师Matt Kulukundis 在 cppCon 2017 做的一个演讲,说:全世界 Google 的服务器上 1% 的 CPU 时间用来做哈希表的计算,超过 4% 的内存用来存储哈希表。足以证明哈希表的重要性。
我们知道,哈希表和列表类似,都用于处理需要随机访问的数据结构。如果数据结构的输入和输出能一一对应,那么可以使用列表,如果无法一一对应,那么就需要使用哈希表。
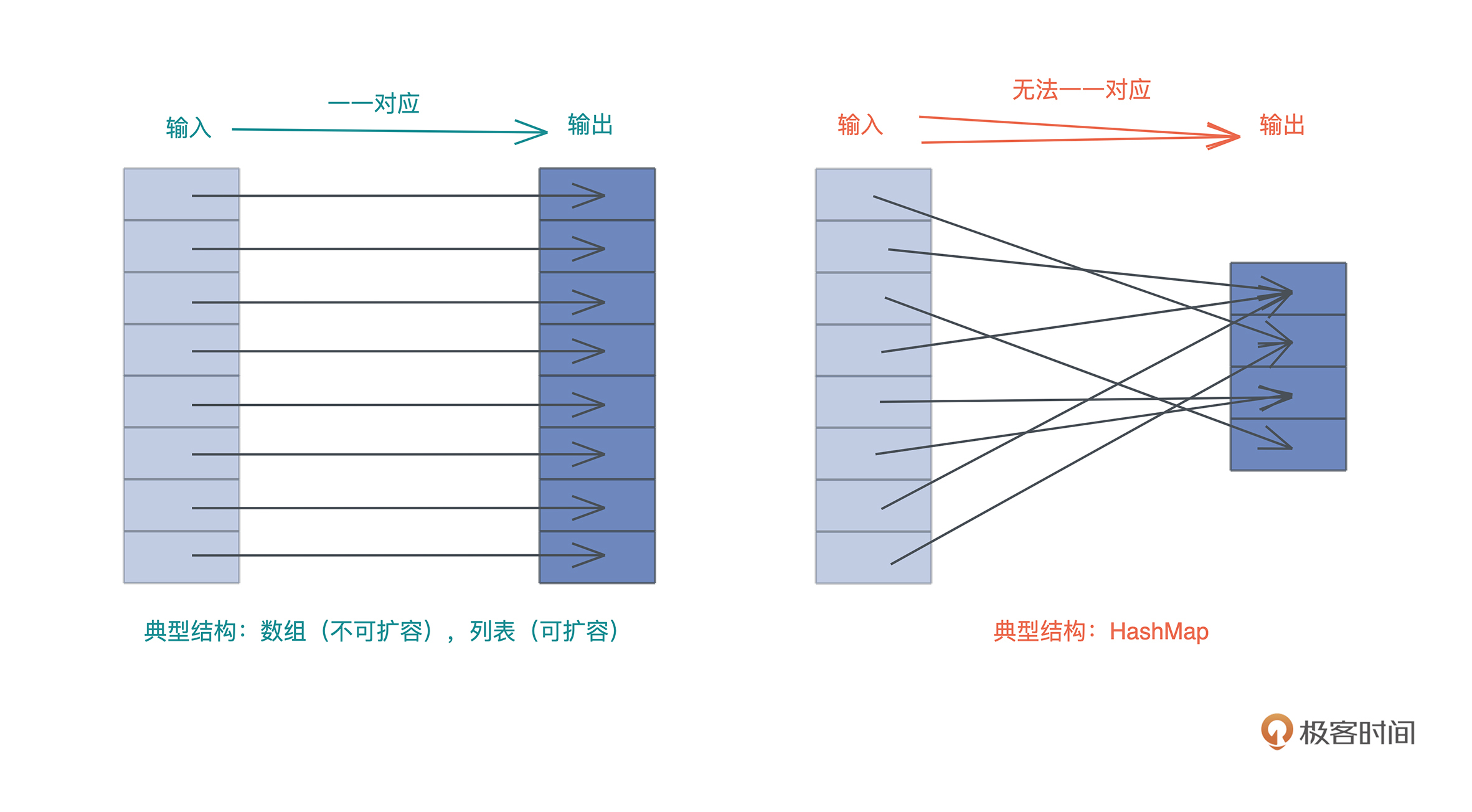
Rust 的哈希表
那 Rust 为我们提供了什么样的哈希表呢?它长什么样?性能如何?我们从官方文档学起。
如果你打开 HashMap 的文档,会看到这样一句话:
A hash map implemented with quadratic probing and SIMD lookup.
这一看就有点肾上腺素上升了,出现了两个高端词汇:二次探查(quadratic probing)和 SIMD 查表(SIMD lookup),都是什么意思?它们是Rust哈希表算法的设计核心,我们今天的学习也会围绕着这两个词展开,所以别着急,等学完相信你会理解这句话的。
先把基础理论扫一遍。哈希表最核心的特点就是: 巨量的可能输入和有限的哈希表容量。 这就会引发哈希冲突,也就是两个或者多个输入的哈希被映射到了同一个位置,所以我们要能够处理哈希冲突。
要解决冲突,首先可以通过更好的、分布更均匀的哈希函数,以及使用更大的哈希表来缓解冲突,但无法完全解决,所以我们还需要使用冲突解决机制。
如何解决冲突?
理论上,主要的冲突解决机制有链地址法(chaining)和开放寻址法(open addressing)。
链地址法,我们比较熟悉,就是把落在同一个哈希上的数据用单链表或者双链表连接起来。这样在查找的时候,先找到对应的哈希桶(hash bucket),然后再在冲突链上挨个比较,直到找到匹配的项:
冲突链处理哈希冲突非常直观,很容易理解和撰写代码,但缺点是哈希表和冲突链使用了不同的内存,对缓存不友好。
开放寻址法把整个哈希表看做一个大数组,不引入额外的内存,当冲突产生时,按照一定的规则把数据插入到其它空闲的位置。比如线性探寻(linear probing)在出现哈希冲突时,不断往后探寻,直到找到空闲的位置插入。
而 二次探查,理论上是在冲突发生时,不断探寻哈希位置加减 n 的二次方,找到空闲的位置插入,我们看图,更容易理解:
 (图中示意是理论上的处理方法,实际为了性能会有很多不同的处理。)
(图中示意是理论上的处理方法,实际为了性能会有很多不同的处理。)
开放寻址还有其它方案,比如二次哈希什么的,今天就不详细介绍了。
好,搞明白哈希表的二次探查的理论知识,我们可以推测,Rust 哈希表不是用冲突链来解决哈希冲突,而是用开放寻址法的二次探查来解决的。当然,后面会讲到 Rust 的二次探查和理论的处理方式有些差别。
而另一个关键词,使用 SIMD 做单指令多数据的查表,也和一会要讲到 Rust 哈希表巧妙的内存布局息息相关。
HashMap 的数据结构
进入正题,我们来看看 Rust 哈希表的数据结构是什么样子的,打开标准库的 源代码:
#![allow(unused)] fn main() { use hashbrown::hash_map as base; #[derive(Clone)] pub struct RandomState { k0: u64, k1: u64, } pub struct HashMap<K, V, S = RandomState> { base: base::HashMap<K, V, S>, } }
可以看到,HashMap 有三个泛型参数,K 和 V 代表 key / value 的类型,S 是哈希算法的状态,它默认是 RandomState,占两个 u64。RandomState 使用 SipHash 作为缺省的哈希算法,它是一个加密安全的哈希函数(cryptographically secure hashing)。
从定义中还能看到,Rust 的 HashMap 复用了 hashbrown 的 HashMap。hashbrown 是 Rust 下对 Google Swiss Table 的一个改进版实现,我们打开 hashbrown 的代码,看它的 结构:
#![allow(unused)] fn main() { pub struct HashMap<K, V, S = DefaultHashBuilder, A: Allocator + Clone = Global> { pub(crate) hash_builder: S, pub(crate) table: RawTable<(K, V), A>, } }
可以看到,HashMap 里有两个域,一个是 hash_builder,类型是刚才我们提到的标准库使用的 RandomState,还有一个是具体的 RawTable:
#![allow(unused)] fn main() { pub struct RawTable<T, A: Allocator + Clone = Global> { table: RawTableInner<A>, // Tell dropck that we own instances of T. marker: PhantomData<T>, } struct RawTableInner<A> { // Mask to get an index from a hash value. The value is one less than the // number of buckets in the table. bucket_mask: usize, // [Padding], T1, T2, ..., Tlast, C1, C2, ... // ^ points here ctrl: NonNull<u8>, // Number of elements that can be inserted before we need to grow the table growth_left: usize, // Number of elements in the table, only really used by len() items: usize, alloc: A, } }
RawTable 中,实际上有意义的数据结构是 RawTableInner,前四个字段很重要,我们一会讲HashMap的内存布局会再提到:
- usize 的 bucket_mask,是哈希表中哈希桶的数量减一;
- 名字叫 ctrl 的指针,它指向哈希表堆内存末端的 ctrl 区;
- usize 的字段 growth_left,指哈希表在下次自动增长前还能存储多少数据;
- usize 的 items,表明哈希表现在有多少数据。
这里最后的 alloc 字段,和 RawTable 的 marker 一样,只是一个用来占位的类型,我们现在只需知道,它用来分配在堆上的内存。
HashMap 的基本使用方法
数据结构搞清楚,我们再看具体使用方法。Rust 哈希表的使用很简单,它提供了一系列很方便的方法,使用起来和其它语言非常类似,你只要看看 文档,就很容易理解。我们来写段代码,尝试一下( 代码):
use std::collections::HashMap; fn main() { let mut map = HashMap::new(); explain("empty", &map); map.insert('a', 1); explain("added 1", &map); map.insert('b', 2); map.insert('c', 3); explain("added 3", &map); map.insert('d', 4); explain("added 4", &map); // get 时需要使用引用,并且也返回引用 assert_eq!(map.get(&'a'), Some(&1)); assert_eq!(map.get_key_value(&'b'), Some((&'b', &2))); map.remove(&'a'); // 删除后就找不到了 assert_eq!(map.contains_key(&'a'), false); assert_eq!(map.get(&'a'), None); explain("removed", &map); // shrink 后哈希表变小 map.shrink_to_fit(); explain("shrinked", &map); } fn explain<K, V>(name: &str, map: &HashMap<K, V>) { println!("{}: len: {}, cap: {}", name, map.len(), map.capacity()); }
运行这段代码,我们可以看到这样的输出:
#![allow(unused)] fn main() { empty: len: 0, cap: 0 added 1: len: 1, cap: 3 added 3: len: 3, cap: 3 added 4: len: 4, cap: 7 removed: len: 3, cap: 7 shrinked: len: 3, cap: 3 }
可以看到,当 HashMap::new() 时,它并没有分配空间,容量为零, 随着哈希表不断插入数据,它会以 2的幂减一的方式增长,最小是 3。当删除表中的数据时,原有的表大小不变,只有显式地调用 shrink_to_fit,才会让哈希表变小。
HashMap 的内存布局
但是通过 HashMap 的公开接口,我们无法看到 HashMap 在内存中是如何布局的,还是需要借助之前使用过的 std::mem::transmute 方法,来把数据结构打出来。我们把刚才的代码改一改( 代码):
use std::collections::HashMap; fn main() { let map = HashMap::new(); let mut map = explain("empty", map); map.insert('a', 1); let mut map = explain("added 1", map); map.insert('b', 2); map.insert('c', 3); let mut map = explain("added 3", map); map.insert('d', 4); let mut map = explain("added 4", map); map.remove(&'a'); explain("final", map); } // HashMap 结构有两个 u64 的 RandomState,然后是四个 usize, // 分别是 bucket_mask, ctrl, growth_left 和 items // 我们 transmute 打印之后,再 transmute 回去 fn explain<K, V>(name: &str, map: HashMap<K, V>) -> HashMap<K, V> { let arr: [usize; 6] = unsafe { std::mem::transmute(map) }; println!( "{}: bucket_mask 0x{:x}, ctrl 0x{:x}, growth_left: {}, items: {}", name, arr[2], arr[3], arr[4], arr[5] ); unsafe { std::mem::transmute(arr) } }
运行之后,可以看到:
#![allow(unused)] fn main() { empty: bucket_mask 0x0, ctrl 0x1056df820, growth_left: 0, items: 0 added 1: bucket_mask 0x3, ctrl 0x7fa0d1405e30, growth_left: 2, items: 1 added 3: bucket_mask 0x3, ctrl 0x7fa0d1405e30, growth_left: 0, items: 3 added 4: bucket_mask 0x7, ctrl 0x7fa0d1405e90, growth_left: 3, items: 4 final: bucket_mask 0x7, ctrl 0x7fa0d1405e90, growth_left: 4, items: 3 }
有意思,我们发现在运行的过程中,ctrl 对应的堆地址发生了改变。
在我的 OS X 下,一开始哈希表为空,ctrl 地址看上去是一个 TEXT/RODATA 段的地址,应该是指向了一个默认的空表地址;插入第一个数据后,哈希表分配了 4 个 bucket,ctrl 地址发生改变;在插入三个数据后,growth_left 为零,再插入时,哈希表重新分配,ctrl 地址继续改变。
刚才在探索 HashMap 数据结构时,说过 ctrl 是一个指向哈希表堆地址末端 ctrl 区的地址,所以我们可以通过这个地址,计算出哈希表堆地址的起始地址。
因为哈希表有 8 个 bucket(0x7 + 1),每个 bucket 大小是 key(char) + value(i32) 的大小,也就是 8 个字节,所以一共是 64 个字节。对于这个例子, 通过 ctrl 地址减去 64,就可以得到哈希表的堆内存起始地址。然后,我们可以用 rust-gdb / rust-lldb 来打印这个内存(如果你对 rust-gdb / rust-lldb 感兴趣,可以看文末的参考阅读)。
这里我用 Linux 下的 rust-gdb 设置断点,依次查看哈希表有一个、三个、四个值,以及删除一个值的状态:
#![allow(unused)] fn main() { ❯ rust-gdb ~/.target/debug/hashmap2 GNU gdb (Ubuntu 9.2-0ubuntu2) 9.2 ... (gdb) b hashmap2.rs:32 Breakpoint 1 at 0xa43e: file src/hashmap2.rs, line 32. (gdb) r Starting program: /home/tchen/.target/debug/hashmap2 ... 最初的状态,哈希表为空 empty: bucket_mask 0x0, ctrl 0x555555597be0, growth_left: 0, items: 0 Breakpoint 1, hashmap2::explain (name=..., map=...) at src/hashmap2.rs:32 32 unsafe { std::mem::transmute(arr) } (gdb) c Continuing. 插入了一个元素后,bucket 有 4 个(0x3+1),堆地址起始位置 0x5555555a7af0 - 4*8(0x20) added 1: bucket_mask 0x3, ctrl 0x5555555a7af0, growth_left: 2, items: 1 Breakpoint 1, hashmap2::explain (name=..., map=...) at src/hashmap2.rs:32 32 unsafe { std::mem::transmute(arr) } (gdb) x /12x 0x5555555a7ad0 0x5555555a7ad0: 0x00000061 0x00000001 0x00000000 0x00000000 0x5555555a7ae0: 0x00000000 0x00000000 0x00000000 0x00000000 0x5555555a7af0: 0x0affffff 0xffffffff 0xffffffff 0xffffffff (gdb) c Continuing. 插入了三个元素后,哈希表没有剩余空间,堆地址起始位置不变 0x5555555a7af0 - 4*8(0x20) added 3: bucket_mask 0x3, ctrl 0x5555555a7af0, growth_left: 0, items: 3 Breakpoint 1, hashmap2::explain (name=..., map=...) at src/hashmap2.rs:32 32 unsafe { std::mem::transmute(arr) } (gdb) x /12x 0x5555555a7ad0 0x5555555a7ad0: 0x00000061 0x00000001 0x00000062 0x00000002 0x5555555a7ae0: 0x00000000 0x00000000 0x00000063 0x00000003 0x5555555a7af0: 0x0a72ff02 0xffffffff 0xffffffff 0xffffffff (gdb) c Continuing. 插入第四个元素后,哈希表扩容,堆地址起始位置变为 0x5555555a7b50 - 8*8(0x40) added 4: bucket_mask 0x7, ctrl 0x5555555a7b50, growth_left: 3, items: 4 Breakpoint 1, hashmap2::explain (name=..., map=...) at src/hashmap2.rs:32 32 unsafe { std::mem::transmute(arr) } (gdb) x /20x 0x5555555a7b10 0x5555555a7b10: 0x00000061 0x00000001 0x00000000 0x00000000 0x5555555a7b20: 0x00000064 0x00000004 0x00000063 0x00000003 0x5555555a7b30: 0x00000000 0x00000000 0x00000062 0x00000002 0x5555555a7b40: 0x00000000 0x00000000 0x00000000 0x00000000 0x5555555a7b50: 0xff72ffff 0x0aff6502 0xffffffff 0xffffffff (gdb) c Continuing. 删除 a 后,剩余 4 个位置。注意 ctrl bit 的变化,以及 0x61 0x1 并没有被清除 final: bucket_mask 0x7, ctrl 0x5555555a7b50, growth_left: 4, items: 3 Breakpoint 1, hashmap2::explain (name=..., map=...) at src/hashmap2.rs:32 32 unsafe { std::mem::transmute(arr) } (gdb) x /20x 0x5555555a7b10 0x5555555a7b10: 0x00000061 0x00000001 0x00000000 0x00000000 0x5555555a7b20: 0x00000064 0x00000004 0x00000063 0x00000003 0x5555555a7b30: 0x00000000 0x00000000 0x00000062 0x00000002 0x5555555a7b40: 0x00000000 0x00000000 0x00000000 0x00000000 0x5555555a7b50: 0xff72ffff 0xffff6502 0xffffffff 0xffffffff }
这段输出蕴藏了很多信息,我们结合示意图来仔细梳理。
首先,插入第一个元素 ‘a’: 1 后,哈希表的内存布局如下:
key ‘a’ 的 hash 和 bucket_mask 0x3 运算后得到第 0 个位置插入。同时,这个 hash 的头 7 位取出来,在 ctrl 表中对应的位置,也就是第 0 个字节,把这个值写入。
要理解这个步骤,关键就是要搞清楚这个 ctrl 表是什么。
ctrl 表
ctrl 表的主要目的是快速查找。它的设计非常优雅,值得我们学习。
一张 ctrl 表里,有若干个 128bit 或者说 16 个字节的分组(group),group 里的每个字节叫 ctrl byte,对应一个 bucket,那么一个 group 对应 16 个 bucket。如果一个 bucket 对应的 ctrl byte 首位不为 1,就表示这个 ctrl byte 被使用;如果所有位都是 1,或者说这个字节是 0xff,那么它是空闲的。
一组 control byte 的整个 128 bit 的数据,可以通过一条指令被加载进来,然后和某个值进行 mask,找到它所在的位置。这就是一开始提到的 SIMD 查表。
我们知道,现代 CPU 都支持单指令多数据集的操作,而Rust 充分利用了 CPU 这种能力,一条指令可以让多个相关的数据载入到缓存中处理,大大加快查表的速度。所以,Rust 的哈希表查询的效率非常高。
具体怎么操作,我们来看 HashMap 是如何通过 ctrl 表来进行数据查询的。假设这张表里已经添加了一些数据,我们现在要查找 key 为 ‘c’ 的数据:
- 首先对 ‘c’ 做哈希,得到一个哈希值 h;
- 把 h 跟 bucket_mask 做与,得到一个值,图中是 139;
- 拿着这个 139,找到对应的 ctrl group 的起始位置,因为 ctrl group 以 16 为一组,所以这里找到 128;
- 用 SIMD 指令加载从 128 对应地址开始的 16 个字节;
- 对 hash 取头 7 个 bit,然后和刚刚取出的 16 个字节一起做与,找到对应的匹配,如果找到了,它(们)很大概率是要找的值;
- 如果不是,那么以二次探查(以 16 的倍数不断累积)的方式往后查找,直到找到为止。
你可以结合下图理解这个算法: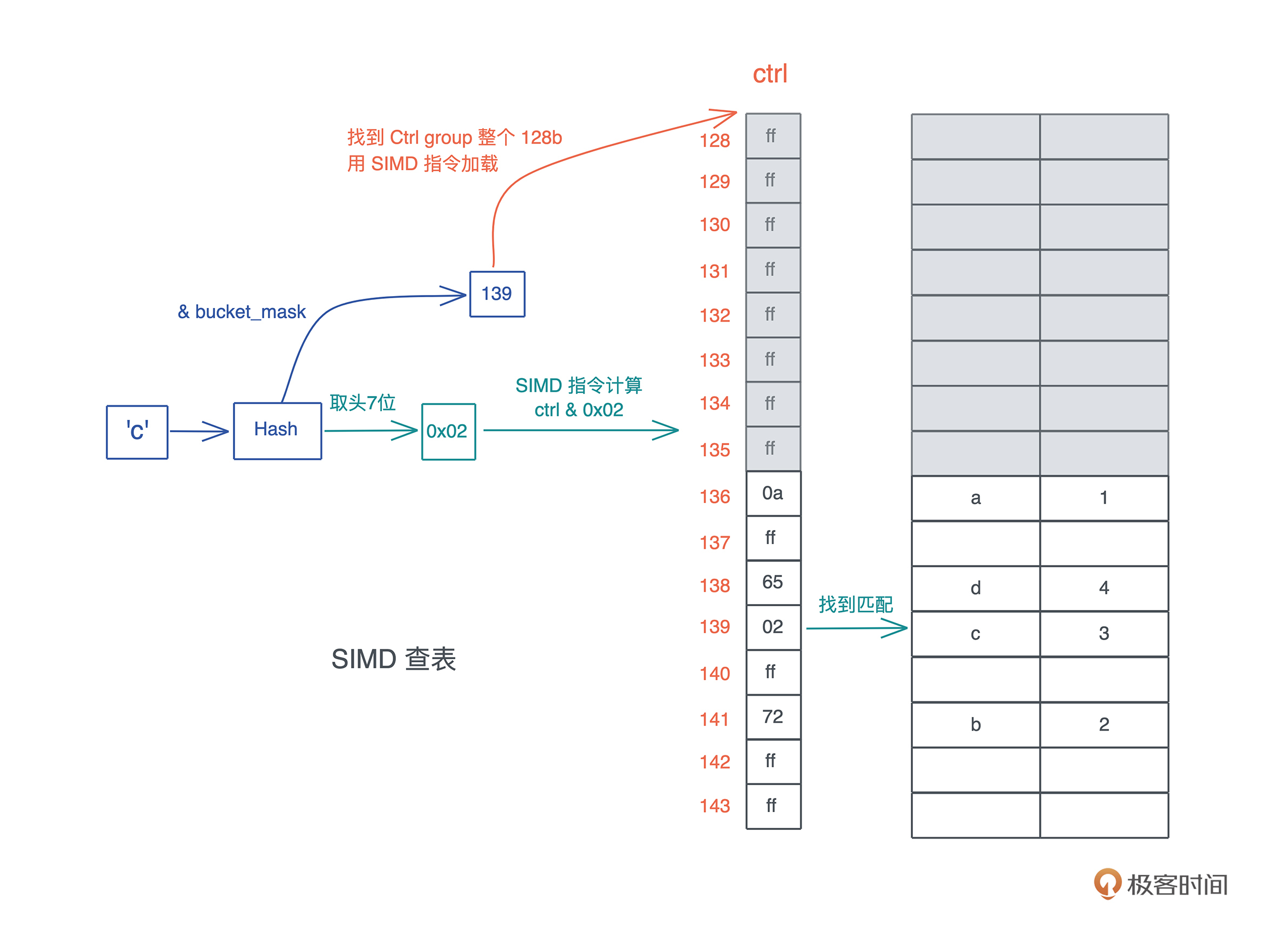
所以,当 HashMap 插入和删除数据,以及因此导致重新分配的时候,主要工作就是在维护这张 ctrl 表和数据的对应。
因为 ctrl 表是所有操作最先触及的内存,所以,在 HashMap 的结构中, 堆内存的指针直接指向 ctrl 表,而不是指向堆内存的起始位置,这样可以减少一次内存的访问。
哈希表重新分配与增长
好,回到刚才讲的内存布局继续说。在插入第一条数据后,我们的哈希表只有 4 个 bucket,所以只有头 4 个字节的 ctrl 表有用。随着哈希表的增长,bucket 不够,就会导致重新分配。由于 bucket_mask 永远比 bucket 数量少 1,所以插入三个元素后就会重新分配。
根据 rust-gdb 中得到的信息,我们看插入三个元素后没有剩余空间的哈希表,在加入 ‘d’: 4 时,是如何增长的。
首先, 哈希表会按幂扩容,从 4 个 bucket 扩展到 8 个 bucket。
这会导致分配新的堆内存,然后原来的 ctrl table 和对应的kv数据会被移动到新的内存中。这个例子里因为 char 和 i32 实现了 Copy trait,所以是拷贝;如果 key 的类型是 String,那么只有 String 的 24 个字节 (ptr|cap|len) 的结构被移动,String 的实际内存不需要变动。
在移动的过程中,会涉及 哈希的重分配。从下图可以看到,‘a’ / ‘c’ 的相对位置和它们的 ctrl byte 没有变化,但重新做 hash 后,‘b’ 的 ctrl byte 和位置都发生了变化:
删除一个值
明白了哈希表是如何增长的,我们再来看删除的时候会发生什么。
当要在哈希表中删除一个值时,整个过程和查找类似,先要找到要被删除的 key 所在的位置。在找到具体位置后, 并不需要实际清除内存,只需要将它的 ctrl byte 设回 0xff(或者标记成删除状态)。这样,这个 bucket 就可以被再次使用了:
这里有一个问题,当 key/value 有额外的内存时,比如 String,它的内存不会立即回收,只有在下一次对应的 bucket 被使用时,让 HashMap 不再拥有这个 String 的所有权之后,这个 String 的内存才被回收。我们看下面的示意图:
一般来说,这并不会带来什么问题,顶多是内存占用率稍高一些。但某些极端情况下,比如在哈希表中添加大量内容,又删除大量内容后运行,这时你可以通过 shrink_to_fit / shrink_to 释放掉不需要的内存。
让自定义的数据结构做 Hash key
有时候,我们需要让自定义的数据结构成为 HashMap 的 key。此时,要使用到三个 trait: Hash、 PartialEq、 Eq,不过这三个 trait 都可以通过派生宏自动生成。其中:
- 实现了 Hash ,可以让数据结构计算哈希;
- 实现了 PartialEq/Eq,可以让数据结构进行相等和不相等的比较。Eq 实现了比较的自反性(a == a)、对称性(a == b 则 b == a)以及传递性(a == b,b == c,则 a == c),PartialEq 没有实现自反性。
我们可以写个例子,看看自定义数据结构如何支持 HashMap:
use std::{ collections::{hash_map::DefaultHasher, HashMap}, hash::{Hash, Hasher}, }; // 如果要支持 Hash,可以用 #[derive(Hash)],前提是每个字段都实现了 Hash // 如果要能作为 HashMap 的 key,还需要 PartialEq 和 Eq #[derive(Debug, Hash, PartialEq, Eq)] struct Student<'a> { name: &'a str, age: u8, } impl<'a> Student<'a> { pub fn new(name: &'a str, age: u8) -> Self { Self { name, age } } } fn main() { let mut hasher = DefaultHasher::new(); let student = Student::new("Tyr", 18); // 实现了 Hash 的数据结构可以直接调用 hash 方法 student.hash(&mut hasher); let mut map = HashMap::new(); // 实现了 Hash / PartialEq / Eq 的数据结构可以作为 HashMap 的 key map.insert(student, vec!["Math", "Writing"]); println!("hash: 0x{:x}, map: {:?}", hasher.finish(), map); }
HashSet / BTreeMap / BTreeSet
最后我们简单讲讲和 HashMap 相关的其它几个数据结构。
有时我们只需要简单确认元素是否在集合中,如果用 HashMap 就有些浪费空间了。这时可以用HashSet,它就是简化的 HashMap,可以用来存放无序的集合,定义直接是 HashMap<K, ()>:
#![allow(unused)] fn main() { use hashbrown::hash_set as base; pub struct HashSet<T, S = RandomState> { base: base::HashSet<T, S>, } pub struct HashSet<T, S = DefaultHashBuilder, A: Allocator + Clone = Global> { pub(crate) map: HashMap<T, (), S, A>, } }
使用 HashSet 查看一个元素是否属于集合的效率非常高。
另一个和 HashMap 一样常用的数据结构就是BTreeMap了。BTreeMap 是内部使用 B-tree 来组织哈希表的数据结构。另外 BTreeSet 和 HashSet 类似,是 BTreeMap 的简化版,可以用来存放有序集合。
我们这里重点看下BTreeMap,它的数据结构如下:
#![allow(unused)] fn main() { pub struct BTreeMap<K, V> { root: Option<Root<K, V>>, length: usize, } pub type Root<K, V> = NodeRef<marker::Owned, K, V, marker::LeafOrInternal>; pub struct NodeRef<BorrowType, K, V, Type> { height: usize, node: NonNull<LeafNode<K, V>>, _marker: PhantomData<(BorrowType, Type)>, } struct LeafNode<K, V> { parent: Option<NonNull<InternalNode<K, V>>>, parent_idx: MaybeUninit<u16>, len: u16, keys: [MaybeUninit<K>; CAPACITY], vals: [MaybeUninit<V>; CAPACITY], } struct InternalNode<K, V> { data: LeafNode<K, V>, edges: [MaybeUninit<BoxedNode<K, V>>; 2 * B], } }
和 HashMap 不同的是,BTreeMap 是有序的。我们看个例子( 代码):
use std::collections::BTreeMap; fn main() { let map = BTreeMap::new(); let mut map = explain("empty", map); for i in 0..16usize { map.insert(format!("Tyr {}", i), i); } let mut map = explain("added", map); map.remove("Tyr 1"); let map = explain("remove 1", map); for item in map.iter() { println!("{:?}", item); } } // BTreeMap 结构有 height,node 和 length // 我们 transmute 打印之后,再 transmute 回去 fn explain<K, V>(name: &str, map: BTreeMap<K, V>) -> BTreeMap<K, V> { let arr: [usize; 3] = unsafe { std::mem::transmute(map) }; println!( "{}: height: {}, root node: 0x{:x}, len: 0x{:x}", name, arr[0], arr[1], arr[2] ); unsafe { std::mem::transmute(arr) } }
它的输出如下:
#![allow(unused)] fn main() { empty: height: 0, root node: 0x0, len: 0x0 added: height: 1, root node: 0x7f8286406190, len: 0x10 remove 1: height: 1, root node: 0x7f8286406190, len: 0xf ("Tyr 0", 0) ("Tyr 10", 10) ("Tyr 11", 11) ("Tyr 12", 12) ("Tyr 13", 13) ("Tyr 14", 14) ("Tyr 15", 15) ("Tyr 2", 2) ("Tyr 3", 3) ("Tyr 4", 4) ("Tyr 5", 5) ("Tyr 6", 6) ("Tyr 7", 7) ("Tyr 8", 8) ("Tyr 9", 9) }
可以看到,在遍历时,BTreeMap 会按照 key 的顺序把值打印出来。如果你想让自定义的数据结构可以作为 BTreeMap 的 key,那么需要实现 PartialOrd 和 Ord,这两者的关系和 PartialEq / Eq 类似,PartialOrd 也没有实现自反性。同样的,PartialOrd 和 Ord 也可以通过派生宏来实现。
小结
在学习数据结构的时候,常用数据结构的内存布局和基本算法你一定要理解清楚,对它在不同情况下如何增长,也要尽量做到心里有数。
这一讲我们花大精力详细学习了 HashMap 的数据结构以及算法的基本思路,算是抛砖引玉。这门课无论多深入讲解,也只能触及 Rust 整个生态圈的九牛一毛,不可能面面俱到。
我的原则是“授人以鱼不如授人以渔”,在你掌握这样的分析方法后,以后遇到标准库或者第三方库的其它的数据结构,也可以用类似的方法深入探索学习。
此外,我们程序员学东西, 会用是第一层,知道它是如何设计的是第二层,能够自己写出来才是第三层。Rust借鉴的 Google Swiss table 算法简单精巧,虽然 hashbrown 在实现时,为了最大化性能和利用 SSE 指令集,使用了很多 unsafe 代码,但我们撰写一个性能不那么好的 safe 版本,并不是复杂的事情,非常推荐你实现一下。
集合类型我们就暂时讲解到这里,未来实战要使用到某些数据结构时,比如 VecDeque,我们再深入探索。其他的集合类型,你也可以在要用的时候自行阅读 文档。
如果你想了解这两讲中集合类型的时间复杂度,可以看下表( 来源):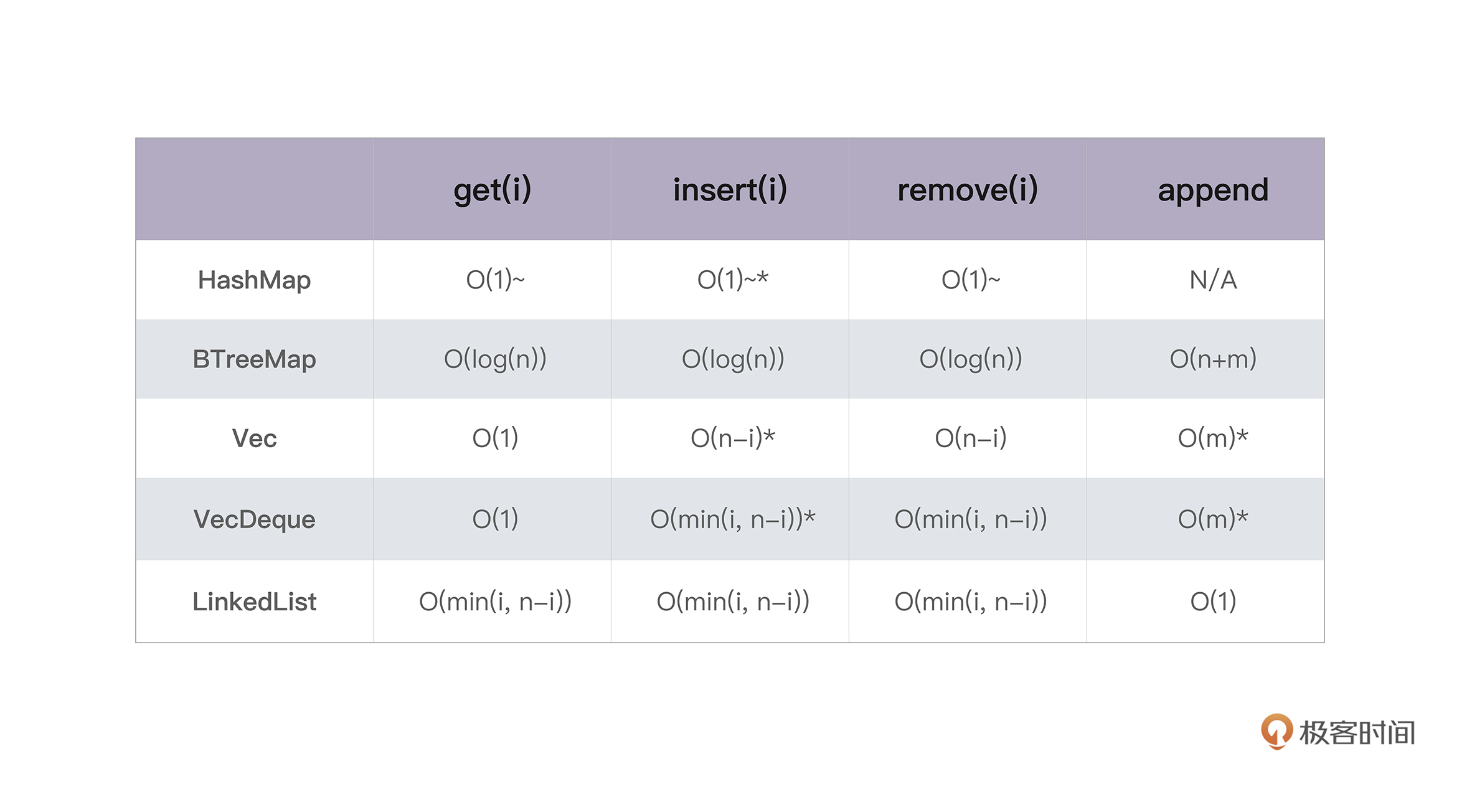
思考题
1.修改下面代码的错误,使其编译通过( 代码)。
use std::collections::BTreeMap; #[derive(Debug)] struct Name { pub name: String, pub flags: u32, } impl Name { pub fn new(name: impl AsRef<str>, flags: u32) -> Self { Self { name: name.as_ref().to_string(), flags, } } } fn main() { let mut map = BTreeMap::new(); map.insert(Name::new("/etc/password", 0x1), 12); map.insert(Name::new("/etc/hosts", 0x1), 4); map.insert(Name::new("/home/tchen", 0x0), 28); for item in map.iter() { println!("{:?}", item); } }
2.思考一下,如果一个 session 表的 key 是 (Source IP、Source Port、Dst IP、Dst Port、Proto) 这样的长度 15 个字节的五元组,value 是 200 字节的 Session 结构,要容纳 1200000 个 Session,整个哈希表要占多大的堆内存?内存的利用率如何?
3.使用文中同样的方式,结合 rust-gdb / rust-lldb 探索 BTreeMap。你能画出来在插入以 26 个字母为 key,1~26 为 value 后的 BTreeMap 的内存布局么?
今天你完成了Rust学习的第17次打卡,我们下节课见。
参考资料
1.为什么 Rust 的 HashMap 要缺省采用加密安全的哈希算法?
我们知道哈希表在软件系统中的重要地位,但哈希表在最坏情况下,如果绝大多数 key 的 hash 都碰撞在一起,性能会到 O(n),这会极大拖累系统的效率。
比如 1M 大小的 session 表,正常情况下查表速度是 O(1),但极端情况下,需要比较 1M 个数据后才能找到,这样的系统就容易被 DoS 攻击。所以如果不是加密安全的哈希函数,只要黑客知道哈希算法,就可以构造出大量的 key 产生足够多的哈希碰撞,造成目标系统 DoS。
SipHash 就是为了回应 DoS 攻击而创建的哈希算法,虽然和 sha2 这样的加密哈希不同(不要将 SipHash 用于加密!),但它可以提供类似等级的安全性。把 SipHash 作为 HashMap 的缺省的哈希算法,Rust 可以避免开发者在不知情的情况下被 DoS,就像曾经在 Web 世界 发生的那样。
当然,这一切的代价是性能损耗,虽然 SipHash 非常快,但它比 hashbrown 缺省使用的 Ahash 慢了不少。如果你确定使用的 HashMap 不需要 DoS 防护(比如一个完全内部使用的 HashMap),那么可以用 Ahash 来替换。你只需要使用 Ahash 提供的 RandomState 即可:
#![allow(unused)] fn main() { use ahash::{AHasher, RandomState}; use std::collections::HashMap; let mut map: HashMap<char, i32, RandomState> = HashMap::default(); map.insert('a', 1); }
2.如何使用 rust-gdb / rust-lldb?
之前的愚昧之巅 加餐 提过 gdb / lldb ,今天就是使用示例。没有使用过的朋友,可以看看它们的文档了解一下。
gdb 适合在 Linux 下,lldb 可以在 OS X 下调试 Rust 程序。 rust-gdb / rust-lldb 提供了一些对 Rust 更友好的 pretty-print 功能,在安装 Rust 时,它们也会被安装。使用过 gdb 的同学,可以看 gdb 速查手册,也可以看看 gdb/lldb 命令对应手册。
我一般不用它们调试程序。 不管任何语言,如果开发时,你发现自己总在设置断点调试程序,说明你撰写代码的方式有问题。要么,没有把接口和算法设计清楚,想到哪写到哪;要么,是你的函数写得过于复杂,太多状态纠缠,没有遵循 SRP(Single Responsibility Principle)。
好的代码是写出来的,不是调出来的。与其把时间花在调试上,不如把时间花在设计、日志,以及单元测试上。所以,gdb/lldb 对我来说,是一个理解数据结构在内存中布局以及探索算法如何运行的工具。你可以仔细阅读文中展示的 gdb session 和与之相关的代码,看看如何构造代码来结合 gdb 探索 HashMap 在不同状态下的行为。
如果你觉得有收获,也欢迎分享给你身边的朋友,邀TA一起讨论~
错误处理:为什么Rust的错误处理与众不同?
你好,我是陈天。
作为被线上业务毒打过的开发者,我们都对墨菲定律刻骨铭心。任何一个系统,只要运行的时间足够久,或者用户的规模足够大,极小概率的错误就一定会发生。比如,主机的磁盘可能被写满、数据库系统可能会脑裂、上游的服务比如 CDN 可能会宕机,甚至承载服务的硬件本身可能损坏等等。
因为我们平时写练习代码,一般只会关注正常路径,可以对小概率发生的错误路径置之不理; 但在实际生产环境中,任何错误只要没有得到妥善处理,就会给系统埋下隐患,轻则影响开发者用户体验,重则会给系统带来安全上的问题,马虎不得。
在一门编程语言中,控制流程是语言的核心流程,而错误处理又是控制流程的重要组成部分。
语言优秀的错误处理能力,会大大减少错误处理对整体流程的破坏,让我们写代码更行云流水,读起来心智负担也更小。
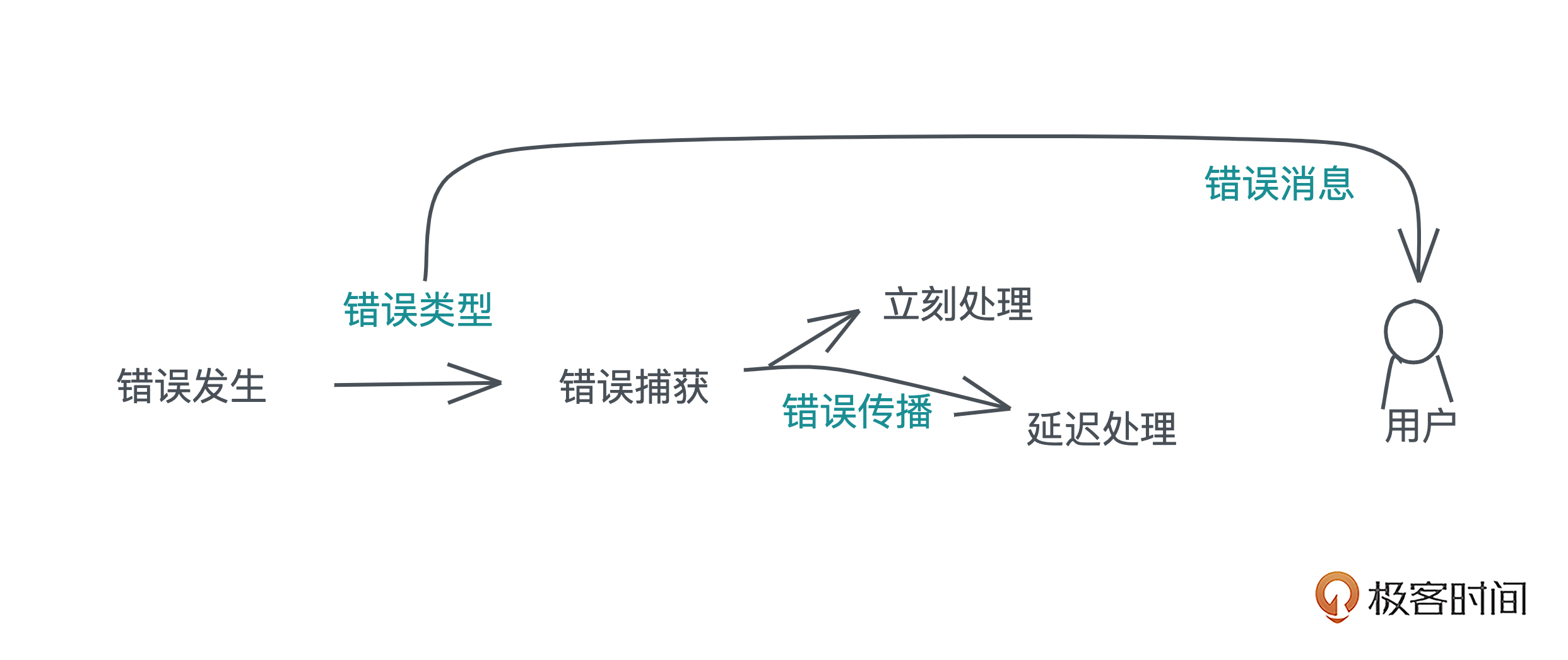
对我们开发者来说,错误处理包含这么几部分:
- 当错误发生时,用合适的错误类型捕获这个错误。
- 错误捕获后,可以立刻处理,也可以延迟到不得不处理的地方再处理,这就涉及到错误的传播(propagate)。
- 最后,根据不同的错误类型,给用户返回合适的、帮助他们理解问题所在的错误消息。
作为一门极其注重用户体验的编程语言,Rust 从其它优秀的语言中,尤其是 Haskell ,吸收了错误处理的精髓,并以自己独到的方式展现出来。
错误处理的主流方法
在详细介绍 Rust 的错误处理方式之前,让我们稍稍放慢脚步,看看错误处理的三种主流方法以及其他语言是如何应用这些方法的。
使用返回值(错误码)
使用返回值来表征错误,是最古老也是最实用的一种方式,它的使用范围很广,从函数返回值,到操作系统的系统调用的错误码 errno、进程退出的错误码retval,甚至 HTTP API 的状态码,都能看到这种方法的身影。
举个例子,在 C 语言中,如果 fopen(filename) 无法打开文件,会返回 NULL,调用者通过判断返回值是否为 NULL,来进行相应的错误处理。
我们再看个例子:
size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream)
单看这个接口,我们很难直观了解,当读文件出错时,错误是如何返回的。从文档中,我们得知,如果返回的 size_t 和传入的 size_t 不一致,那么要么发生了错误,要么是读到文件尾(EOF),调用者要进一步通过 ferror 才能得到更详细的错误。
像 C 这样,通过返回值携带错误信息,有很多局限。返回值有它原本的语义,强行把错误类型嵌入到返回值原本的语义中,需要全面且实时更新的文档,来确保开发者能正确区别对待,正常返回和错误返回。
所以 Golang 对其做了扩展,在函数返回的时候,可以专门携带一个错误对象。比如上文的 fread,在 Golang 下可以这么定义:
func Fread(file *File, b []byte) (n int, err error)
Golang这样,区分开错误返回和正常返回,相对 C 来说进了一大步。
但是使用返回值的方式,始终有个致命的问题: 在调用者调用时,错误就必须得到处理或者显式的传播。
如果函数 A 调用了函数 B,在 A 返回错误的时候,就要把 B 的错误转换成 A 的错误,显示出来。如下图所示:
这样写出来的代码会非常冗长,对我们开发者的用户体验不太好。如果不处理,又会丢掉这个错误信息,造成隐患。
另外, 大部分生产环境下的错误是嵌套的。一个 SQL 执行过程中抛出的错误,可能是服务器出错,而更深层次的错误可能是,连接数据库服务器的 TLS session 状态异常。
其实知道服务器出错之外,我们更需要清楚服务器出错的内在原因。因为服务器出错这个表层错误会提供给最终用户,而出错的深层原因要提供给我们自己,服务的维护者。但是这样的嵌套错误在 C / Golang 都是很难完美表述的。
使用异常
因为返回值不利于错误的传播,有诸多限制,Java 等很多语言使用异常来处理错误。
你可以把异常看成一种 关注点分离(Separation of Concerns): 错误的产生和错误的处理完全被分隔开,调用者不必关心错误,而被调者也不强求调用者关心错误。
程序中任何可能出错的地方,都可以抛出异常;而异常可以通过栈回溯(stack unwind)被一层层自动传递,直到遇到捕获异常的地方,如果回溯到 main 函数还无人捕获,程序就会崩溃。如下图所示:
使用异常来返回错误可以极大地简化错误处理的流程,它解决了返回值的传播问题。
然而,上图中异常返回的过程看上去很直观,就像数据库中的事务(transaction)在出错时会被整体撤销(rollback)一样。但实际上,这个过程远比你想象的复杂,而且需要额外操心 异常安全(exception safety)。
我们看下面用来切换背景图片的(伪)代码:
void transition(...) {
lock(&mutex);
delete background;
++changed;
background = new Background(...);
unlock(&mutex);
}
试想,如果在创建新的背景时失败,抛出异常,会跳过后续的处理流程,一路栈回溯到 try catch 的代码,那么,这里锁住的 mutex 无法得到释放,而已有的背景被清空,新的背景没有创建,程序进入到一个奇怪的状态。
确实在大多数情况下,用异常更容易写代码,但 当异常安全无法保证时,程序的正确性会受到很大的挑战。因此,你在使用异常处理时,需要特别注意异常安全,尤其是在并发环境下。
而比较讽刺的是,保证异常安全的第一个原则就是: 避免抛出异常。这也是 Golang 在语言设计时避开了常规的异常, 走回返回值的老路 的原因。
异常处理另外一个比较严重的问题是:开发者会滥用异常。只要有错误,不论是否严重、是否可恢复,都一股脑抛个异常。到了需要的地方,捕获一下了之。殊不知,异常处理的开销要比处理返回值大得多,滥用会有很多额外的开销。
使用类型系统
第三种错误处理的方法就是使用类型系统。其实,在使用返回值处理错误的时候,我们已经看到了类型系统的雏形。
错误信息既然可以通过已有的类型携带,或者通过多返回值的方式提供,那么 通过类型来表征错误,使用一个内部包含正常返回类型和错误返回类型的复合类型,通过类型系统来强制错误的处理和传递,是不是可以达到更好的效果呢?
的确如此。这种方式被大量使用在有强大类型系统支持的函数式编程语言中,如 Haskell/Scala/Swift。其中最典型的包含了错误类型的复合类型是 Haskell 的 Maybe 和 Either 类型。
Maybe 类型允许数据包含一个值(Just)或者没有值(Nothing),这对简单的不需要类型的错误很有用。还是以打开文件为例,如果我们只关心成功打开文件的句柄,那么 Maybe 就足够了。
当我们需要更为复杂的错误处理时,我们可以使用 Either 类型。它允许数据是 Left a 或者 Right b 。其中,a 是运行出错的数据类型,b 可以是成功的数据类型。
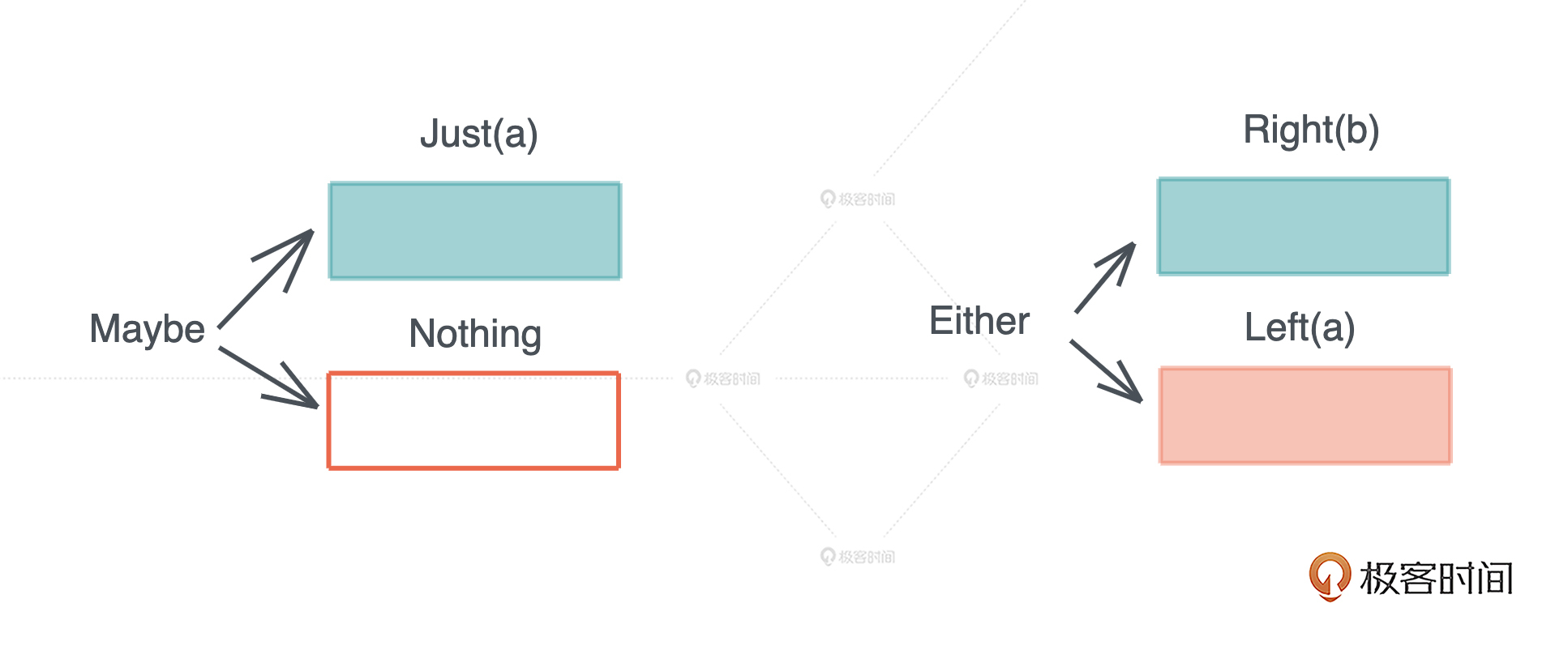
我们可以看到,这种方法依旧是通过返回值返回错误,但是错误被包裹在一个完整的、必须处理的类型中,比 Golang 的方法更安全。
我们前面提到,使用返回值返回错误的一大缺点是,错误需要被调用者立即处理或者显式传递。但是使用 Maybe / Either 这样的类型来处理错误的好处是, 我们可以用函数式编程的方法简化错误的处理,比如map、fold 等函数,让代码相对不那么冗余。
需要注意的是,很多不可恢复的错误,如“磁盘写满,无法写入”的错误,使用异常处理可以避免一层层传递错误,让代码简洁高效,所以大多数使用类型系统来处理错误的语言,会同时使用异常处理作为补充。
Rust 的错误处理
由于诞生的年代比较晚,Rust 有机会从已有的语言中学习到各种错误处理的优劣。对于 Rust 来说,目前的几种方式相比而言,最佳的方法是,使用类型系统来构建主要的错误处理流程。
Rust 偷师 Haskell,构建了对标 Maybe 的 Option 类型和 对标 Either 的 Result 类型。
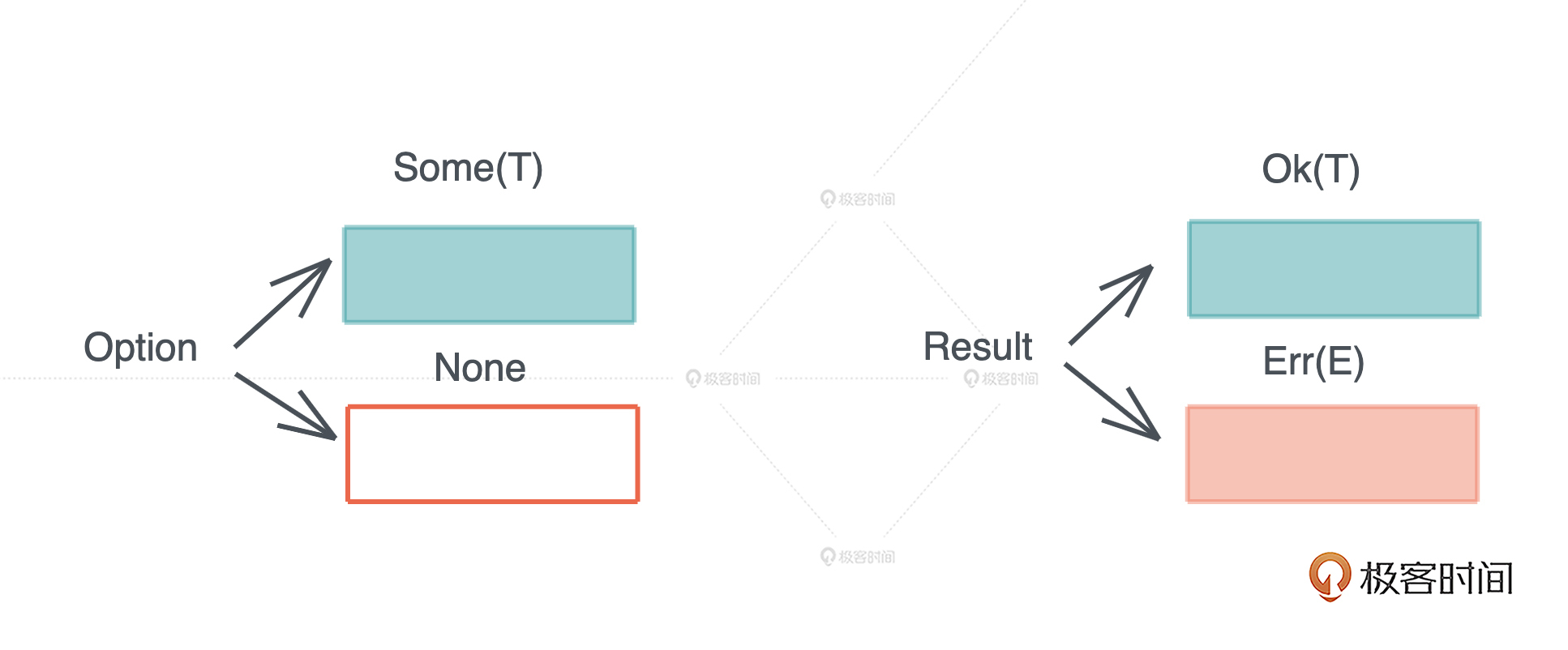
Option 和 Result
Option 是一个 enum,其定义如下:
#![allow(unused)] fn main() { pub enum Option<T> { None, Some(T), } }
它可以承载有值/无值这种最简单的错误类型。
Result 是一个更加复杂的 enum,其定义如下:
#![allow(unused)] fn main() { #[must_use = "this `Result` may be an `Err` variant, which should be handled"] pub enum Result<T, E> { Ok(T), Err(E), } }
当函数出错时,可以返回 Err(E),否则 Ok(T)。
我们看到,Result 类型声明时还有个 must_use 的标注,编译器会对有 must_use 标注的所有类型做特殊处理:如果该类型对应的值没有被显式使用,则会告警。这样,保证错误被妥善处理。如下图所示:

这里,如果我们调用 read_file 函数时,直接丢弃返回值,由于 #[must_use] 的标注,Rust 编译器报警,要求我们使用其返回值。
这虽然可以极大避免遗忘错误的显示处理,但如果我们并不关心错误,只需要传递错误,还是会写出像 C 或者 Golang 一样比较冗余的代码。怎么办?
? 操作符
好在 Rust 除了有强大的类型系统外,还具备元编程的能力。早期 Rust 提供了 try! 宏来简化错误的显式处理,后来为了进一步提升用户体验,try! 被进化成 ? 操作符。
所以在 Rust 代码中,如果你只想传播错误,不想就地处理,可以用 ? 操作符,比如( 代码):
#![allow(unused)] fn main() { use std::fs::File; use std::io::Read; fn read_file(name: &str) -> Result<String, std::io::Error> { let mut f = File::open(name)?; let mut contents = String::new(); f.read_to_string(&mut contents)?; Ok(contents) } }
通过 ? 操作符,Rust 让错误传播的代价和异常处理不相上下,同时又避免了异常处理的诸多问题。
? 操作符内部被展开成类似这样的代码:
#![allow(unused)] fn main() { match result { Ok(v) => v, Err(e) => return Err(e.into()) } }
所以,我们可以方便地写出类似这样的代码,简洁易懂,可读性很强:
#![allow(unused)] fn main() { fut .await? .process()? .next() .await?; }
整个代码的执行流程如下:
虽然 ? 操作符使用起来非常方便,但你要注意在不同的错误类型之间是无法直接使用的,需要实现 From trait 在二者之间建立起转换的桥梁,这会带来额外的麻烦。我们暂且把这个问题放下,稍后我们会谈到解决方案。
函数式错误处理
Rust 还为 Option 和 Result 提供了大量的辅助函数,如 map / map_err / and_then,你可以很方便地处理数据结构中部分情况。如下图所示:
通过这些函数,你可以很方便地对错误处理引入 Railroad oriented programming 范式。比如用户注册的流程,你需要校验用户输入,对数据进行处理,转换,然后存入数据库中。你可以这么撰写这个流程:
#![allow(unused)] fn main() { Ok(data) .and_then(validate) .and_then(process) .map(transform) .and_then(store) .map_error(...) }
执行流程如下图所示:
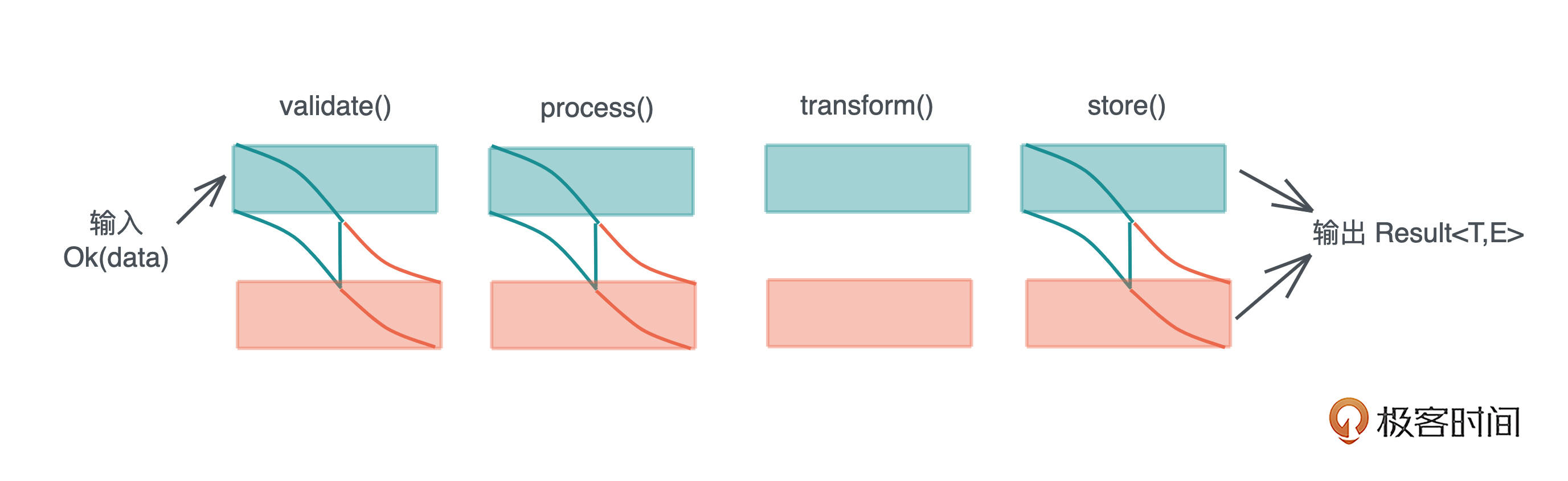
此外,Option 和 Result的互相转换也很方便,这也得益于 Rust 构建的强大的函数式编程的能力。
我们可以看到,无论是通过 ? 操作符,还是函数式编程进行错误处理,Rust 都力求让错误处理灵活高效,让开发者使用起来简单直观。
panic! 和 catch_unwind
使用 Option 和 Result 是 Rust 中处理错误的首选,绝大多数时候我们也应该使用,但 Rust 也提供了特殊的异常处理能力。
在 Rust 看来,一旦你需要抛出异常,那抛出的一定是严重的错误。所以,Rust 跟 Golang 一样,使用了诸如 panic! 这样的字眼警示开发者:想清楚了再使用我。在使用 Option 和 Result 类型时,开发者也可以对其 unwarp() 或者 expect(),强制把 Option
一般而言,panic! 是不可恢复或者不想恢复的错误,我们希望在此刻,程序终止运行并得到崩溃信息。比如下面的代码,它解析 noise protoco 的协议变量:
#![allow(unused)] fn main() { let params: NoiseParams = "Noise_XX_25519_AESGCM_SHA256".parse().unwrap(); }
如果开发者不小心把协议变量写错了,最佳的方式是立刻 panic! 出来,让错误立刻暴露,以便解决这个问题。
有些场景下,我们也希望能够像异常处理那样能够栈回溯,把环境恢复到捕获异常的上下文。Rust 标准库下提供了 catch_unwind() ,把调用栈回溯到 catch_unwind 这一刻,作用和其它语言的 try {…} catch {…} 一样。见如下 代码:
use std::panic; fn main() { let result = panic::catch_unwind(|| { println!("hello!"); }); assert!(result.is_ok()); let result = panic::catch_unwind(|| { panic!("oh no!"); }); assert!(result.is_err()); println!("panic captured: {:#?}", result); }
当然,和异常处理一样,并不意味着你可以滥用这一特性,我想,这也是 Rust 把抛出异常称作 panic! ,而捕获异常称作 catch_unwind的原因,让初学者望而生畏,不敢轻易使用。这也是一个不错的用户体验。
catch_unwind 在某些场景下非常有用,比如你在使用 Rust 为 erlang VM 撰写 NIF,你不希望 Rust 代码中的任何 panic! 导致 erlang VM 崩溃。因为崩溃是一个非常不好的体验,它违背了 erlang 的设计原则:process 可以 let it crash,但错误代码不该导致 VM 崩溃。
此刻,你就可以把 Rust 代码整个封装在 catch_unwind() 函数所需要传入的闭包中。这样,一旦任何代码中,包括第三方 crates 的代码,含有能够导致 panic! 的代码,都会被捕获,并被转换为一个 Result。
Error trait 和错误类型的转换
上文中,我们讲到 Result<T, E> 里 E 是一个代表错误的数据类型。为了规范这个代表错误的数据类型的行为,Rust 定义了 Error trait:
#![allow(unused)] fn main() { pub trait Error: Debug + Display { fn source(&self) -> Option<&(dyn Error + 'static)> { ... } fn backtrace(&self) -> Option<&Backtrace> { ... } fn description(&self) -> &str { ... } fn cause(&self) -> Option<&dyn Error> { ... } } }
我们可以定义我们自己的数据类型,然后为其实现 Error trait。
不过,这样的工作已经有人替我们简化了:我们可以使用 thiserror 和 anyhow 来简化这个步骤。thiserror 提供了一个派生宏(derive macro)来简化错误类型的定义,比如:
#![allow(unused)] fn main() { use thiserror::Error; #[derive(Error, Debug)] #[non_exhaustive] pub enum DataStoreError { #[error("data store disconnected")] Disconnect(#[from] io::Error), #[error("the data for key `{0}` is not available")] Redaction(String), #[error("invalid header (expected {expected:?}, found {found:?})")] InvalidHeader { expected: String, found: String, }, #[error("unknown data store error")] Unknown, } }
如果你在撰写一个 Rust 库,那么 thiserror 可以很好地协助你对这个库里所有可能发生的错误进行建模。
而 anyhow 实现了 anyhow::Error 和任意符合 Error trait 的错误类型之间的转换,让你可以使用 ? 操作符,不必再手工转换错误类型。anyhow 还可以让你很容易地抛出一些临时的错误,而不必费力定义错误类型,当然,我们不提倡滥用这个能力。
作为一名严肃的开发者,我非常建议你在开发前,先用类似 thiserror 的库定义好你项目中主要的错误类型,并随着项目的深入,不断增加新的错误类型,让系统中所有的潜在错误都无所遁形。
小结
这一讲我们讨论了错误处理的三种方式:使用返回值、异常处理和类型系统。而Rust 站在巨人的肩膀上,采各家之长,形成了我们目前看到的方案: 主要用类型系统来处理错误,辅以异常来应对不可恢复的错误。
- 相比 C/Golang 直接用返回值的错误处理方式,Rust 在类型上更完备,构建了逻辑更为严谨的 Option 类型和 Result 类型,既避免了错误被不慎忽略,也避免了用啰嗦的表达方式传递错误;
- 相对于 C++ / Java 使用异常的方式,Rust 区分了可恢复错误和不可恢复错误,分别使用 Option / Result,以及 panic! / catch_unwind 来应对,更安全高效,避免了异常安全带来的诸多问题;
- 而对比它的老师 Haskell,Rust 的错误处理更加实用简洁,这得益于它强大的元编程功能,使用 ?操作符来简化错误的传递。
总结一下:Rust 的错误处理很实用、足够强大、处理起来又不会过于冗长,充分使用 Rust 语言本身的能力,大大简化了错误传递的代码,简洁明了,几乎接近于异常处理的方式。
当然,Rust 错误处理还有很多提升空间,尤其标准库没有给出足够的工具,导致社区里有大量的互不兼容的辅助库。不过这些都瑕不掩瑜,对 Rust 语言来说,错误处理还处于一个不断进化的阶段,相信未来标准库会给出更好更方便的答案。
思考题
如果你要开发一个类似Redis 的缓存服务器,你都会定义哪些错误?为什么?
欢迎在留言区分享你的思考。你已经打卡Rust学习第18次啦,如果你觉得有收获,也欢迎你分享给身边的朋友,邀他一起讨论。
拓展阅读
4.对 Railroad oriented programming 范式感兴趣的同学可以看看这个 slides
闭包:FnOnce、FnMut和Fn,为什么有这么多类型?
你好,我是陈天。
在现代编程语言中,闭包是一个很重要的工具,可以让我们很方便地以函数式编程的方式来撰写代码。因为闭包可以作为参数传递给函数,可以作为返回值被函数返回,也可以为它实现某个 trait,使其能表现出其他行为,而不仅仅是作为函数被调用。
这些都是怎么做到的?这就和 Rust 里闭包的本质有关了,我们今天就来学习基础篇的最后一个知识点:闭包。
闭包的定义
之前介绍了闭包的基本概念和一个非常简单的例子:
闭包是将函数,或者说代码和其环境一起存储的一种数据结构。闭包引用的上下文中的自由变量,会被捕获到闭包的结构中,成为闭包类型的一部分( 第二讲)。
闭包会根据内部的使用情况,捕获环境中的自由变量。在 Rust 里,闭包可以用 |args| {code} 来表述,图中闭包 c 捕获了上下文中的 a 和 b,并通过引用来使用这两个自由变量:
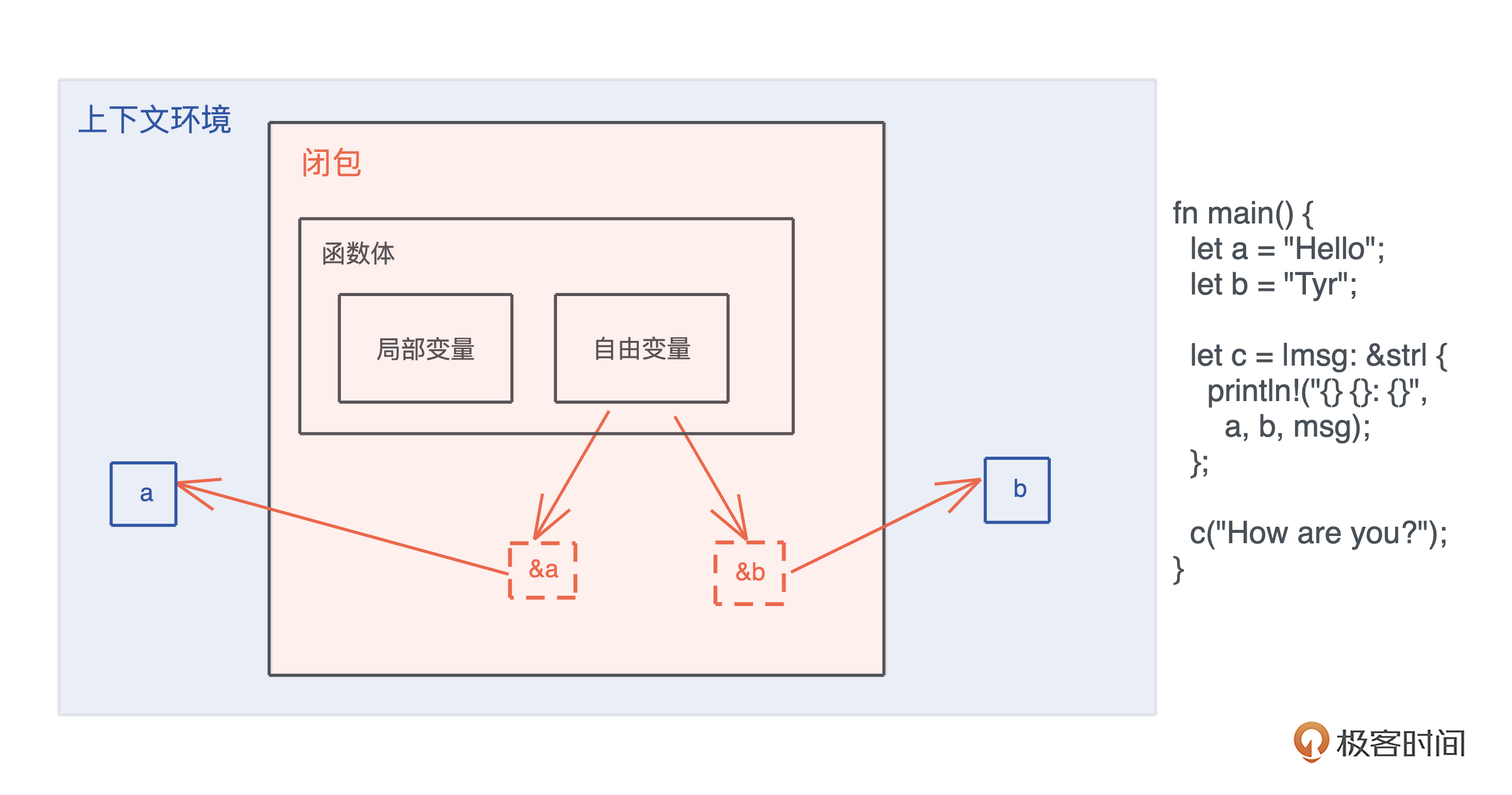
除了用引用来捕获自由变量之外,还有另外一个方法使用 move 关键字 move |args| {code} 。
之前的课程中,多次见到了创建新线程的 thread::spawn,它的参数就是一个闭包:
#![allow(unused)] fn main() { pub fn spawn<F, T>(f: F) -> JoinHandle<T> where F: FnOnce() -> T, F: Send + 'static, T: Send + 'static, }
仔细看这个接口:
- F: FnOnce() → T,表明 F 是一个接受 0 个参数、返回 T 的闭包。FnOnce 我们稍后再说。
- F: Send + 'static,说明闭包 F 这个数据结构,需要静态生命周期或者拥有所有权,并且它还能被发送给另一个线程。
- T: Send + 'static,说明闭包 F 返回的数据结构 T,需要静态生命周期或者拥有所有权,并且它还能被发送给另一个线程。
1 和 3 都很好理解,2 就有些费解了。一个闭包,它不就是一段代码 + 被捕获的变量么?需要静态生命周期或者拥有所有权是什么意思?
拆开看。代码自然是静态生命周期了,那么是不是意味着被捕获的变量,需要静态生命周期或者拥有所有权?
的确如此。在使用 thread::spawn 时,我们需要使用 move 关键字,把变量的所有权从当前作用域移动到闭包的作用域,让 thread::spawn 可以正常编译通过:
use std::thread; fn main() { let s = String::from("hello world"); let handle = thread::spawn(move || { println!("moved: {:?}", s); }); handle.join().unwrap(); }
但你有没有好奇过,加 move 和不加 move,这两种闭包有什么本质上的不同?闭包究竟是一种什么样的数据类型,让编译器可以判断它是否满足 Send + 'static 呢?我们从闭包的本质下手来尝试回答这两个问题。
闭包本质上是什么?
在官方的 Rust reference 中,有这样的 定义:
A closure expression produces a closure value with a unique, anonymous type that cannot be written out. A closure type is approximately equivalent to a struct which contains the captured variables.
闭包是一种匿名类型, 一旦声明,就会产生一个新的类型,但这个类型无法被其它地方使用。 这个类型就像一个结构体,会包含所有捕获的变量。
所以闭包类似一个特殊的结构体?
为了搞明白这一点,我们得写段代码探索一下,建议你跟着敲一遍认真思考( 代码):
use std::{collections::HashMap, mem::size_of_val}; fn main() { // 长度为 0 let c1 = || println!("hello world!"); // 和参数无关,长度也为 0 let c2 = |i: i32| println!("hello: {}", i); let name = String::from("tyr"); let name1 = name.clone(); let mut table = HashMap::new(); table.insert("hello", "world"); // 如果捕获一个引用,长度为 8 let c3 = || println!("hello: {}", name); // 捕获移动的数据 name1(长度 24) + table(长度 48),closure 长度 72 let c4 = move || println!("hello: {}, {:?}", name1, table); let name2 = name.clone(); // 和局部变量无关,捕获了一个 String name2,closure 长度 24 let c5 = move || { let x = 1; let name3 = String::from("lindsey"); println!("hello: {}, {:?}, {:?}", x, name2, name3); }; println!( "c1: {}, c2: {}, c3: {}, c4: {}, c5: {}, main: {}", size_of_val(&c1), size_of_val(&c2), size_of_val(&c3), size_of_val(&c4), size_of_val(&c5), size_of_val(&main), ) }
分别生成了 5 个闭包:
- c1 没有参数,也没捕获任何变量,从代码输出可以看到,c1 长度为 0;
- c2 有一个 i32 作为参数,没有捕获任何变量,长度也为 0,可以看出参数跟闭包的大小无关;
- c3 捕获了一个对变量 name 的引用,这个引用是 &String,长度为 8。而 c3 的长度也是 8;
- c4 捕获了变量 name1 和 table,由于用了 move,它们的所有权移动到了 c4 中。c4 长度是 72,恰好等于 String 的 24 字节,加上 HashMap 的 48 字节。
- c5 捕获了 name2,name2 的所有权移动到了 c5,虽然 c5 有局部变量,但它的大小和局部变量也无关,c5 的大小等于 String 的 24 字节。
学到这里,前面的第一个问题就解决了,可以看到,不带 move 时,闭包捕获的是对应自由变量的引用;带 move 时,对应自由变量的所有权会被移动到闭包结构中。
继续分析这段代码的运行结果。
还知道了, 闭包的大小跟参数、局部变量都无关,只跟捕获的变量有关。如果你回顾 第一讲 函数调用,参数和局部变量在栈中如何存放的图,就很清楚了:因为它们是在调用的时刻才在栈上产生的内存分配,说到底和闭包类型本身是无关的,所以闭包的大小跟它们自然无关。
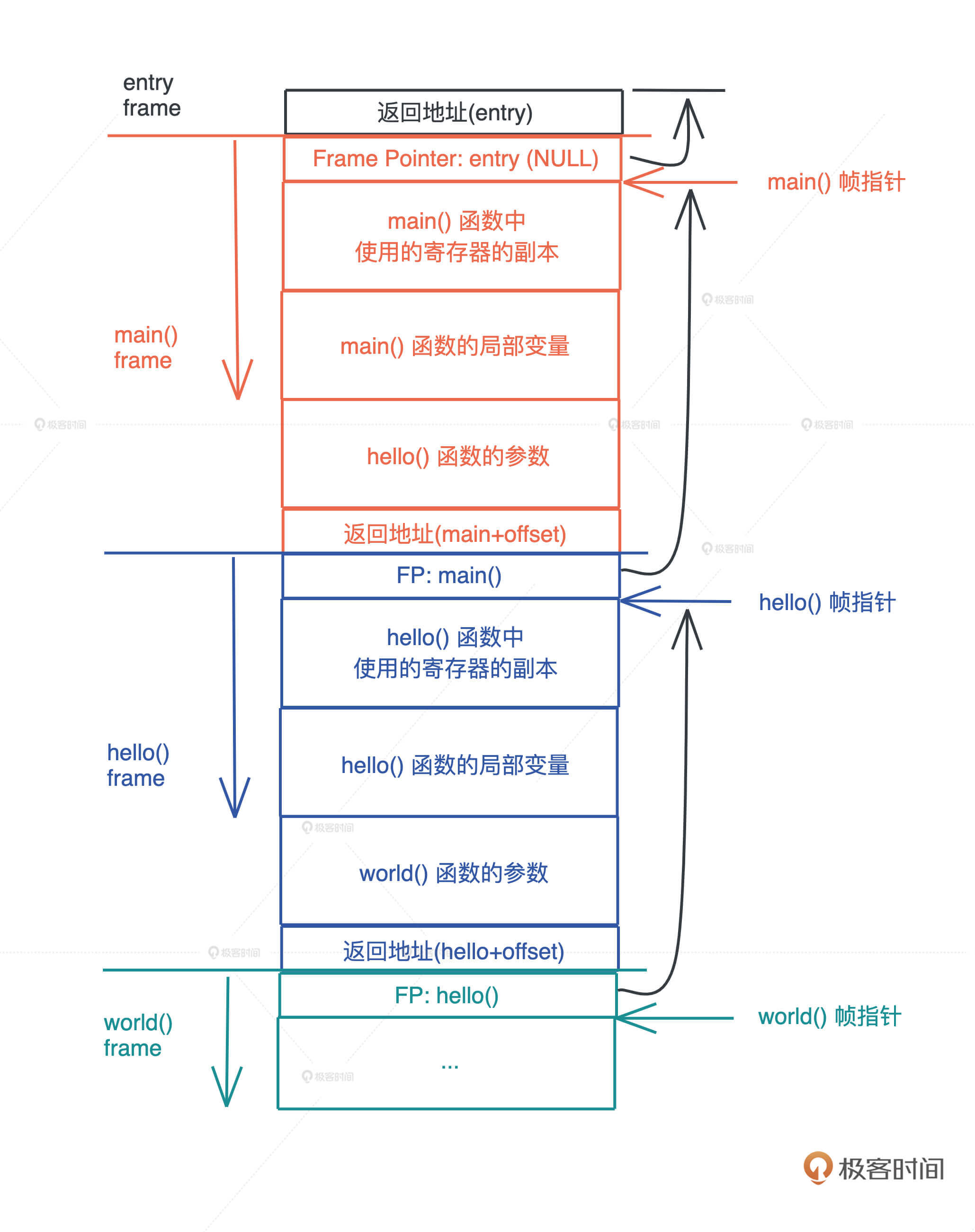
那一个闭包类型在内存中究竟是如何排布的,和结构体有什么区别?我们要再次结合 rust-gdb 探索,看看上面的代码在运行结束前,几个长度不为 0 闭包内存里都放了什么:

可以看到,c3 的确是一个引用,把它指向的内存地址的 24 个字节打出来,是 (ptr | cap | len) 的标准结构。如果打印 ptr 对应的堆内存的 3 个字节,是 ‘t’ ‘y’ ‘r’。
而 c4 捕获的 name 和 table,内存结构和下面的结构体一模一样:
#![allow(unused)] fn main() { struct Closure4 { name: String, // (ptr|cap|len)=24字节 table: HashMap<&str, &str> // (RandomState(16)|mask|ctrl|left|len)=48字节 } }
不过,对于 closure 类型来说,编译器知道像函数一样调用闭包 c4() 是合法的,并且知道执行 c4() 时,代码应该跳转到什么地址来执行。在执行过程中,如果遇到 name、table,可以从自己的数据结构中获取。
那么多想一步,闭包捕获变量的顺序,和其内存结构的顺序是一致的么?的确如此,如果我们调整闭包里使用 name1 和 table 的顺序:
#![allow(unused)] fn main() { let c4 = move || println!("hello: {:?}, {}", table, name1); }
其数据的位置是相反的,类似于:
#![allow(unused)] fn main() { struct Closure4 { table: HashMap<&str, &str> // (RandomState(16)|mask|ctrl|left|len)=48字节 name: String, // (ptr|cap|len)=24字节 } }
从 gdb 中也可以看到同样的结果:

不过这只是逻辑上的位置,如果你还记得 第 11 讲 struct 在内存的排布,Rust 编译器会重排内存,让数据能够以最小的代价对齐,所以有些情况下,内存中数据的顺序可能和 struct 定义不一致。
所以回到刚才闭包和结构体的比较。在 Rust 里,闭包产生的匿名数据类型,格式和 struct 是一样的。看图中 gdb 的输出, 闭包是存储在栈上,并且除了捕获的数据外,闭包本身不包含任何额外函数指针指向闭包的代码。如果你理解了 c3 / c4 这两个闭包,c5 是如何构造的就很好理解了。
现在,你是不是可以回答为什么 thread::spawn 对传入的闭包约束是 Send + 'static 了?究竟什么样的闭包满足它呢?很明显,使用了 move 且 move 到闭包内的数据结构满足 Send,因为此时,闭包的数据结构拥有所有数据的所有权,它的生命周期是 'static。
看完Rust闭包的内存结构,你是不是想说“就这”,没啥独特之处吧?但是对比其他语言,结合接下来我的解释,你再仔细想想就会有一种“这怎么可能”的惊讶。
不同语言的闭包设计
闭包最大的问题是变量的多重引用导致生命周期不明确,所以你先想,其它支持闭包的语言(lambda 也是闭包),它们的闭包会放在哪里?
栈上么?是,又好像不是。
因为闭包这玩意,从当前上下文中捕获了些变量,变得有点不伦不类,不像函数那样清楚,尤其是这些被捕获的变量,它们的归属和生命周期处理起来很麻烦。所以,大部分编程语言的闭包很多时候无法放在栈上,需要额外的堆分配。你可以看这个 Golang 的例子。
不光 Golang,Java / Swift / Python / JavaScript 等语言都是如此,这也是为什么大多数编程语言闭包的性能要远低于函数调用。因为使用闭包就意味着:额外的堆内存分配、潜在的动态分派(很多语言会把闭包处理成函数指针)、额外的内存回收。
在性能上,唯有 C++ 的 lambda 和 Rust 闭包类似,不过 C++ 的闭包还有 一些场景 会触发堆内存分配。如果你还记得 16 讲的 Rust / Swift / Kotlin iterator 函数式编程的性能测试:
Kotlin 运行超时,Swift 很慢,Rust 的性能却和使用命令式编程的 C 几乎一样,除了编译器优化的效果,也因为 Rust 闭包的性能和函数差不多。
为什么 Rust 可以做到这样呢?这又跟 Rust 从根本上使用所有权和借用,解决了内存归属问题有关。
在其他语言中,闭包变量因为多重引用导致生命周期不明确,但 Rust 从一开始就消灭了这个问题:
- 如果不使用 move 转移所有权,闭包会引用上下文中的变量, 这个引用受借用规则的约束,所以只要编译通过,那么闭包对变量的引用就不会超过变量的生命周期,没有内存安全问题。
- 如果使用 move 转移所有权,上下文中的变量在转移后就无法访问, 闭包完全接管这些变量,它们的生命周期和闭包一致,所以也不会有内存安全问题。
而 Rust 为每个闭包生成一个新的类型,又使得 调用闭包时可以直接和代码对应,省去了使用函数指针再转一道手的额外消耗。
所以还是那句话,当回归到最初的本原,你解决的不是单个问题,而是由此引发的所有问题。我们不必为堆内存管理设计 GC、不必为其它资源的回收提供 defer 关键字、不必为并发安全进行诸多限制、也不必为闭包挖空心思搞优化。
Rust的闭包类型
现在我们搞明白了闭包究竟是个什么东西,在内存中怎么表示,接下来我们看看 FnOnce / FnMut / Fn 这三种闭包类型有什么区别。
在声明闭包的时候,我们并不需要指定闭包要满足的约束,但是当闭包作为函数的参数或者数据结构的一个域时,我们需要告诉调用者,对闭包的约束。还以 thread::spawn 为例,它要求传入的闭包满足 FnOnce trait。
FnOnce
先来看 FnOnce。它的 定义 如下:
#![allow(unused)] fn main() { pub trait FnOnce<Args> { type Output; extern "rust-call" fn call_once(self, args: Args) -> Self::Output; } }
FnOnce 有一个关联类型 Output,显然,它是闭包返回值的类型;还有一个方法 call_once,要注意的是 call_once 第一个参数是 self,它会转移 self 的所有权到 call_once 函数中。
这也是为什么 FnOnce 被称作 Once : 它只能被调用一次。再次调用,编译器就会报变量已经被 move 这样的常见所有权错误了。
至于 FnOnce 的参数,是一个叫 Args 的泛型参数,它并没有任何约束。如果你对这个感兴趣可以看文末的参考资料。
看一个隐式的 FnOnce 的例子:
fn main() { let name = String::from("Tyr"); // 这个闭包啥也不干,只是把捕获的参数返回去 let c = move |greeting: String| (greeting, name); let result = c("hello".to_string()); println!("result: {:?}", result); // 无法再次调用 let result = c("hi".to_string()); }
这个闭包 c,啥也没做,只是把捕获的参数返回。就像一个结构体里,某个字段被转移走之后,就不能再访问一样,闭包内部的数据一旦被转移,这个闭包就不完整了,也就无法再次使用,所以它是一个 FnOnce 的闭包。
如果一个闭包并不转移自己的内部数据,那么它就不是 FnOnce,然而,一旦它被当做 FnOnce 调用,自己会被转移到 call_once 函数的作用域中,之后就无法再次调用了,我们看个例子( 代码):
fn main() { let name = String::from("Tyr"); // 这个闭包会 clone 内部的数据返回,所以它不是 FnOnce let c = move |greeting: String| (greeting, name.clone()); // 所以 c1 可以被调用多次 println!("c1 call once: {:?}", c("qiao".into())); println!("c1 call twice: {:?}", c("bonjour".into())); // 然而一旦它被当成 FnOnce 被调用,就无法被再次调用 println!("result: {:?}", call_once("hi".into(), c)); // 无法再次调用 // let result = c("hi".to_string()); // Fn 也可以被当成 FnOnce 调用,只要接口一致就可以 println!("result: {:?}", call_once("hola".into(), not_closure)); } fn call_once(arg: String, c: impl FnOnce(String) -> (String, String)) -> (String, String) { c(arg) } fn not_closure(arg: String) -> (String, String) { (arg, "Rosie".into()) }
FnMut
理解了 FnOnce,我们再来看 FnMut,它的 定义 如下:
#![allow(unused)] fn main() { pub trait FnMut<Args>: FnOnce<Args> { extern "rust-call" fn call_mut( &mut self, args: Args ) -> Self::Output; } }
首先,FnMut “继承”了 FnOnce,或者说 FnOnce 是 FnMut 的 super trait。所以FnMut也拥有 Output 这个关联类型和 call_once 这个方法。此外,它还有一个 call_mut() 方法。 注意 call_mut() 传入 &mut self,它不移动 self,所以 FnMut 可以被多次调用。
因为 FnOnce 是 FnMut 的 super trait,所以,一个 FnMut 闭包,可以被传给一个需要 FnOnce 的上下文,此时调用闭包相当于调用了 call_once()。
如果你理解了前面讲的闭包的内存组织结构,那么 FnMut 就不难理解,就像结构体如果想改变数据需要用 let mut 声明一样,如果你想改变闭包捕获的数据结构,那么就需要 FnMut。我们看个例子( 代码):
fn main() { let mut name = String::from("hello"); let mut name1 = String::from("hola"); // 捕获 &mut name let mut c = || { name.push_str(" Tyr"); println!("c: {}", name); }; // 捕获 mut name1,注意 name1 需要声明成 mut let mut c1 = move || { name1.push_str("!"); println!("c1: {}", name1); }; c(); c1(); call_mut(&mut c); call_mut(&mut c1); call_once(c); call_once(c1); } // 在作为参数时,FnMut 也要显式地使用 mut,或者 &mut fn call_mut(c: &mut impl FnMut()) { c(); } // 想想看,为啥 call_once 不需要 mut? fn call_once(c: impl FnOnce()) { c(); }
在声明的闭包 c 和 c1 里,我们修改了捕获的 name 和 name1。不同的是 name 使用了引用,而 name1 移动了所有权,这两种情况和其它代码一样,也需要遵循所有权和借用有关的规则。所以,如果在闭包 c 里借用了 name,你就不能把 name 移动给另一个闭包 c1。
这里也展示了,c 和 c1 这两个符合 FnMut 的闭包,能作为 FnOnce 来调用。我们在代码中也确认了,FnMut 可以被多次调用,这是因为 call_mut() 使用的是 &mut self,不移动所有权。
Fn
最后我们来看看 Fn trait。它的 定义 如下:
#![allow(unused)] fn main() { pub trait Fn<Args>: FnMut<Args> { extern "rust-call" fn call(&self, args: Args) -> Self::Output; } }
可以看到,它“继承”了 FnMut,或者说 FnMut 是 Fn 的 super trait。这也就意味着 任何需要 FnOnce 或者 FnMut 的场合,都可以传入满足 Fn 的闭包。我们继续看例子( 代码):
fn main() { let v = vec![0u8; 1024]; let v1 = vec![0u8; 1023]; // Fn,不移动所有权 let mut c = |x: u64| v.len() as u64 * x; // Fn,移动所有权 let mut c1 = move |x: u64| v1.len() as u64 * x; println!("direct call: {}", c(2)); println!("direct call: {}", c1(2)); println!("call: {}", call(3, &c)); println!("call: {}", call(3, &c1)); println!("call_mut: {}", call_mut(4, &mut c)); println!("call_mut: {}", call_mut(4, &mut c1)); println!("call_once: {}", call_once(5, c)); println!("call_once: {}", call_once(5, c1)); } fn call(arg: u64, c: &impl Fn(u64) -> u64) -> u64 { c(arg) } fn call_mut(arg: u64, c: &mut impl FnMut(u64) -> u64) -> u64 { c(arg) } fn call_once(arg: u64, c: impl FnOnce(u64) -> u64) -> u64 { c(arg) }
闭包的使用场景
在讲完Rust的三个闭包类型之后,最后来看看闭包的使用场景。虽然今天才开始讲闭包,但其实之前隐晦地使用了很多闭包。
thread::spawn 自不必说,我们熟悉的 Iterator trait 里面大部分函数都接受一个闭包,比如 map:
#![allow(unused)] fn main() { fn map<B, F>(self, f: F) -> Map<Self, F> where Self: Sized, F: FnMut(Self::Item) -> B, { Map::new(self, f) } }
可以看到,Iterator 的 map() 方法接受一个 FnMut,它的参数是 Self::Item,返回值是没有约束的泛型参数 B。Self::Item 是 Iterator::next() 方法吐出来的数据,被 map 之后,可以得到另一个结果。
所以在函数的参数中使用闭包,是闭包一种非常典型的用法。另外闭包也可以作为函数的返回值,举个简单的例子( 代码):
use std::ops::Mul; fn main() { let c1 = curry(5); println!("5 multiply 2 is: {}", c1(2)); let adder2 = curry(3.14); println!("pi multiply 4^2 is: {}", adder2(4. * 4.)); } fn curry<T>(x: T) -> impl Fn(T) -> T where T: Mul<Output = T> + Copy, { move |y| x * y }
最后,闭包还有一种并不少见,但可能不太容易理解的用法: 为它实现某个 trait,使其也能表现出其他行为,而不仅仅是作为函数被调用。比如说有些接口既可以传入一个结构体,又可以传入一个函数或者闭包。
我们看一个 tonic(Rust 下的 gRPC 库)的 例子:
#![allow(unused)] fn main() { pub trait Interceptor { /// Intercept a request before it is sent, optionally cancelling it. fn call(&mut self, request: crate::Request<()>) -> Result<crate::Request<()>, Status>; } impl<F> Interceptor for F where F: FnMut(crate::Request<()>) -> Result<crate::Request<()>, Status>, { fn call(&mut self, request: crate::Request<()>) -> Result<crate::Request<()>, Status> { self(request) } } }
在这个例子里,Interceptor 有一个 call 方法,它可以让 gRPC Request 被发送出去之前被修改,一般是添加各种头,比如 Authorization 头。
我们可以创建一个结构体,为它实现 Interceptor,不过大部分时候 Interceptor 可以直接通过一个闭包函数完成。为了让传入的闭包也能通过 Interceptor::call() 来统一调用,可以为符合某个接口的闭包实现 Interceptor trait。掌握了这种用法,我们就可以通过某些 trait 把特定的结构体和闭包统一起来调用,是不是很神奇。
小结
Rust 闭包的效率非常高。首先闭包捕获的变量,都储存在栈上,没有堆内存分配。其次因为闭包在创建时会隐式地创建自己的类型,每个闭包都是一个新的类型。通过闭包自己唯一的类型,Rust 不需要额外的函数指针来运行闭包,所以 闭包的调用效率和函数调用几乎一致。
Rust 支持三种不同的闭包 trait:FnOnce、FnMut 和 Fn。FnOnce 是 FnMut 的 super trait,而 FnMut 又是 Fn 的 super trait。从这些 trait 的接口可以看出,
- FnOnce 只能调用一次;
- FnMut 允许在执行时修改闭包的内部数据,可以执行多次;
- Fn 不允许修改闭包的内部数据,也可以执行多次。
总结一下三种闭包使用的情况以及它们之间的关系: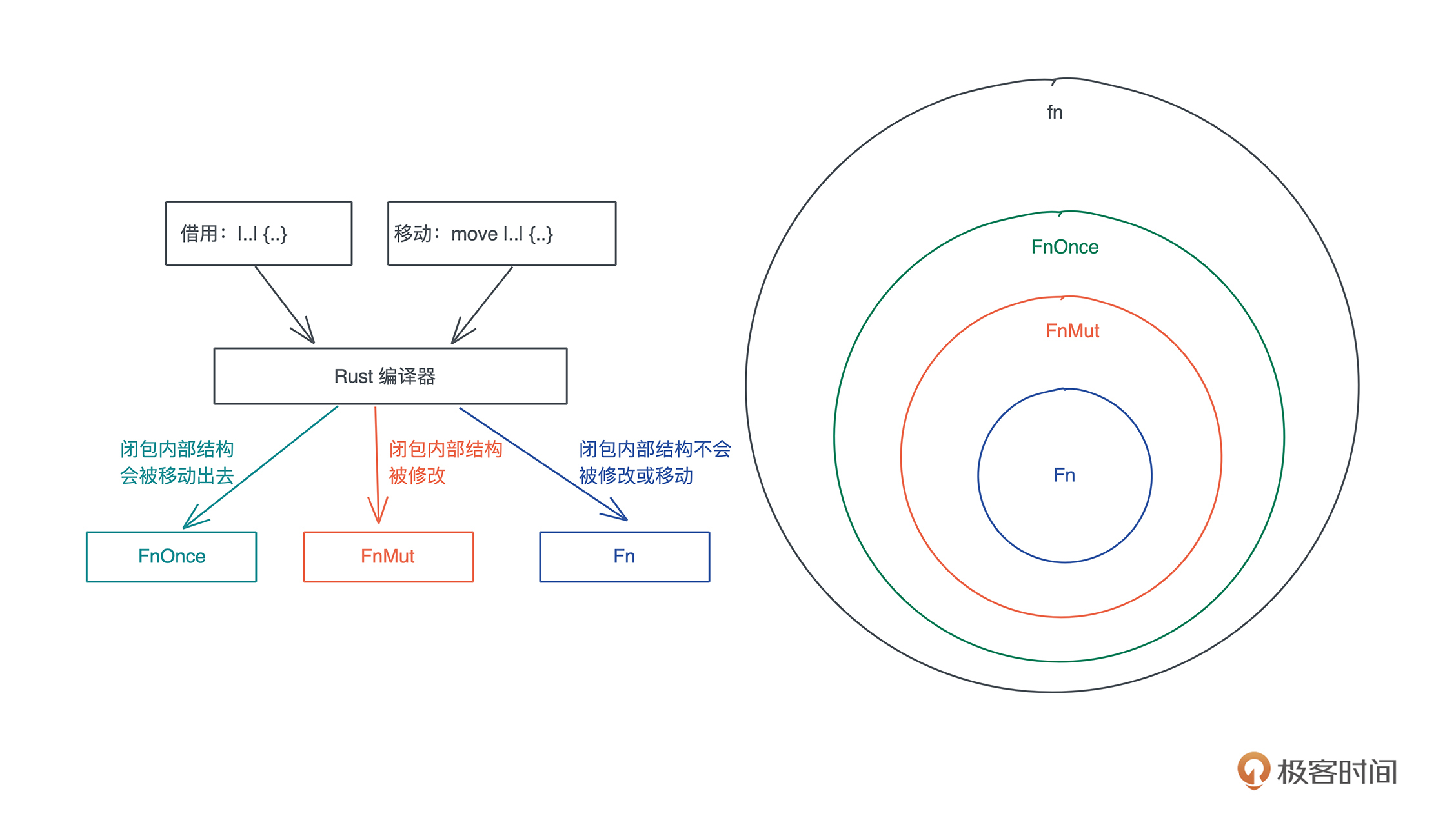
思考题
- 下面的代码,闭包 c 相当于一个什么样的结构体?它的长度多大?代码的最后,main() 函数还能访问变量 name 么?为什么?
fn main() { let name = String::from("Tyr"); let vec = vec!["Rust", "Elixir", "Javascript"]; let v = &vec[..]; let data = (1, 2, 3, 4); let c = move || { println!("data: {:?}", data); println!("v: {:?}, name: {:?}", v, name.clone()); }; c(); // 请问在这里,还能访问 name 么?为什么? }
- 在讲到 FnMut 时,我们放了一段代码,在那段代码里,我问了一个问题:为啥 call_once 不需要 c 是 mut 呢?就像下面这样:
#![allow(unused)] fn main() { // 想想看,为啥 call_once 不需要 mut? fn call_once(mut c: impl FnOnce()) { c(); } }
- 为下面的代码添加实现,使其能够正常工作( 代码):
pub trait Executor { fn execute(&self, cmd: &str) -> Result<String, &'static str>; } struct BashExecutor { env: String, } impl Executor for BashExecutor { fn execute(&self, cmd: &str) -> Result<String, &'static str> { Ok(format!( "fake bash execute: env: {}, cmd: {}", self.env, cmd )) } } // 看看我给的 tonic 的例子,想想怎么实现让 27 行可以正常执行 fn main() { let env = "PATH=/usr/bin".to_string(); let cmd = "cat /etc/passwd"; let r1 = execute(cmd, BashExecutor { env: env.clone() }); println!("{:?}", r1); let r2 = execute(cmd, |cmd: &str| { Ok(format!("fake fish execute: env: {}, cmd: {}", env, cmd)) }); println!("{:?}", r2); } fn execute(cmd: &str, exec: impl Executor) -> Result<String, &'static str> { exec.execute(cmd) }
你已经完成Rust学习的第19次打卡。如果你觉得有收获,也欢迎你分享给身边的朋友,邀TA一起讨论。我们下节课见~
参考资料
怎么理解 FnOnce 的 Args 泛型参数呢?Args 又是怎么和 FnOnce 的约束,比如 FnOnce(String) 这样的参数匹配呢?感兴趣的同学可以看下面的例子,它(不完全)模拟了 FnOnce 中闭包的使用( 代码):
struct ClosureOnce<Captured, Args, Output> { // 捕获的数据 captured: Captured, // closure 的执行代码 func: fn(Args, Captured) -> Output, } impl<Captured, Args, Output> ClosureOnce<Captured, Args, Output> { // 模拟 FnOnce 的 call_once,直接消耗 self fn call_once(self, greeting: Args) -> Output { (self.func)(greeting, self.captured) } } // 类似 greeting 闭包的函数体 fn greeting_code1(args: (String,), captured: (String,)) -> (String, String) { (args.0, captured.0) } fn greeting_code2(args: (String, String), captured: (String, u8)) -> (String, String, String, u8) { (args.0, args.1, captured.0, captured.1) } fn main() { let name = "Tyr".into(); // 模拟变量捕捉 let c = ClosureOnce { captured: (name,), func: greeting_code1, }; // 模拟闭包调用,这里和 FnOnce 不完全一样,传入的是一个 tuple 来匹配 Args 参数 println!("{:?}", c.call_once(("hola".into(),))); // 调用一次后无法继续调用 // println!("{:?}", clo.call_once("hola".into())); // 更复杂一些的复杂的闭包 let c1 = ClosureOnce { captured: ("Tyr".into(), 18), func: greeting_code2, }; println!("{:?}", c1.call_once(("hola".into(), "hallo".into()))); }
4 Steps :如何更好地阅读Rust源码?
你好,我是陈天。
到目前为止,Rust 的基础知识我们就学得差不多了。这倒不是说已经像用筛子一样,把基础知识仔细筛了一遍,毕竟我只能给你提供学习Rust的思路,扫清入门障碍。老话说得好,师傅领进门修行靠个人,在 Rust 世界里打怪升级,还要靠你自己去探索、去努力。
虽然不能帮你打怪,但是打怪的基本技巧可以聊一聊。所以在开始阶段实操引入大量新第三方库之前,我们非常有必要先聊一下这个很重要的技巧: 如何更好地阅读源码。
其实会读源码是个终生受益的开发技能,却往往被忽略。在我读过的绝大多数的编程书籍里,很少有讲如何阅读代码的,就像世间的书籍千千万万,“如何阅读一本书”这样的题材却凤毛麟角。
当然,在解决“如何”之前,我们要先搞明白“为什么”。
为什么要阅读源码?
如果课程的每一讲你都认真看过,会发现时刻都在引用标准库的源码,让我们在阅读的时候,不光学基础知识,还能围绕它的第一手资料也就是源代码展开讨论。
如果说他人总结的知识是果实,那源代码就是结出这果实的种子。只摘果子吃,就是等他人赏饭,非常被动,也不容易分清果子的好坏;如果靠朴素的源码种子结出了自己的果实,确实前期要耐得住寂寞施肥浇水,但收割的时刻,一切尽在自己的掌控之中。
作为开发者,我们每天都和代码打交道。经过数年的基础教育和职业培训,我们都会“写”代码,或者至少会抄代码和改代码。但是,会读代码的其实并不多,会读代码又真正能读懂一些大项目源码的,少之又少。
这种怪状,真要追究起来,就是因为 前期我们所有的教育和培训都在强调怎么写代码,并没有教怎么读代码,而走入工作后,大多数场景也都是一个萝卜一个坑, 我们只需要了解系统的一个局部就能开展工作,读和工作内容不相干的代码,似乎没什么用。
那没有读过大量代码究竟有什么问题,毕竟工作好像还是能正常开展?就拿跟写代码有很多相通之处的写作来对比。
小时候我们都经历过读课文、背课文、写作文的过程。除了学习语法和文法知识外,从小学开始,经年累月,阅读各种名家作品,经过各种写作训练,才累积出自己的写作能力。所以可以说,写作建立在大量阅读基础上。
而我们写代码的过程就很不同了,在学会基础的语法和试验了若干 example 后,跳过了大量阅读名家作品的阶段,直接坐火箭般蹿到自己开始写业务代码。
这样跳过了大量的代码阅读有三个问题:
首先没有足够积累,我们很容易 养成 StackOverflow driven 的写代码习惯。
遇到不知如何写的代码,从网上找现成的答案,找个高票的复制粘贴,改一改凑活着用,先完成功能再说。写代码的过程中遇到问题,就开启调试模式,要么设置无数断点一步步跟踪,要么到处打印信息试图为满是窟窿的代码打上补丁,导致写代码的整个过程就是一部调代码的血泪史。
其次, 因为平时基础不牢靠,我们靠边写边学的进步是最慢的。道理很简单,前辈们踩过坑总结的经验教训,都不得不亲自用最慢的法子一点点试着踩一遍。
最后还有一个非常容易被忽略的天花板问题, 周围能触达的那个最强工程师开发水平的上限,就是我们的上限。
但是如果重视读源码平时积累,并且具备一定阅读技巧,这三个问题就能迎刃而解。就像写作文形容美女时,你立即能想到“肌肤胜雪、明眸善睐、齿如含贝、气若幽兰……”,而不是憋了半天就三字“哇美女”。为了让我们在写代码的时候,摆脱只会“哇美女”这样的初级阶段,多读源码非常关键。
三大功用
读源码的第一个好处是, 知识的源头在你这里,你可以根据事实来分辨是非,而不是迷信权威。比如说之前讲 Rc 时( 第9讲),我们通过源码引出 Box::leak ,回答了为啥 Rc 可以突破 Rust 单一所有权的桎梏;谈到 FnOnce 时( 第19讲),通过源码一眼看透为啥 FnOnce 只能调用一次。
未来你在跟别人分享的时候,可以很自信地回答这些问题,而不必说因为《陈天的 Rust 第一课》里是这么说的,这也解决了刚才的第一个问题。
通过源码我们还学到了很多技巧。比如 Rc::clone() 如何使用内部可变性来保持 Clone trait 的不可变约束( 第9讲);Iterator 里的方法如何通过不断构造新的 Iterator 数据结构,来支持 lazy evaluation ( 第16讲)。
未来你在写代码时,这些技巧都可以使用,从“哇美女”的初级水平到可以试着使用“一笑倾城,再笑倾国”的地步。这是读源码的第二个好处, 看别人的代码,积累了素材,开拓了思路,自己写代码时可以“文思如泉涌,下笔如有神”。
最后一个能解决的问题就是打破天花板了。累积素材是基础,被启发出来的思路将这些素材串成线,才形成了自己的知识。
优秀的代码读得越多,越能引发思考,从而引发更多的阅读,形成一个飞轮效应,让自己的知识变得越来越丰富。而知识的融会贯通,最终形成读代码的第三大功用: 通过了解、吸收别人的思想,去芜存菁,最终形成自己的思想或者说智慧。
当然从素材、到知识、再到智慧,要长期积累,并非一朝一夕之功。搞明白“为什么”给到我们的三个学习方向,所以现在来进一步解决“如何”,分享一下我的方法论,为你的积累助助力。
如何阅读源码呢?
我们以第三方库 Bytes 为例,来看看如何阅读源码。希望你跟着今天的节奏走,不管是否关心 bytes 的实现,都先以它为蓝本,把基本方法熟悉一遍,再扩展到更多代码的阅读,比如 hyper、 nom、 tokio、 tonic 等。
Bytes 是 tokio 下一个高效处理网络数据的库,代码本身 3.5k LoC(不包括 2.1k LoC 注释),加上测试 5.3k。代码结构非常简单:
❯ tree src
src
├── buf
│ ├── buf_impl.rs
│ ├── buf_mut.rs
│ ├── chain.rs
│ ├── iter.rs
│ ├── limit.rs
│ ├── mod.rs
│ ├── reader.rs
│ ├── take.rs
│ ├── uninit_slice.rs
│ ├── vec_deque.rs
│ └── writer.rs
├── bytes.rs
├── bytes_mut.rs
├── fmt
│ ├── debug.rs
│ ├── hex.rs
│ └── mod.rs
├── lib.rs
├── loom.rs
└── serde.rs
能看到,脉络很清晰,是很容易阅读的代码。
先简单讲一下读 Rust 代码的顺序:从 crate 的大纲开始,先了解目标代码能干什么、怎么用;然后学习核心 trait,看看它支持哪些功能;之后再掌握主要的数据结构,开始写一些示例代码;最后围绕自己感兴趣的情景深入阅读。
至于为什么这么读,我们边读边具体说明。
step1:从大纲开始
我们先从文档的大纲入手。Rust 的文档系统是所有编程语言中处在第一梯队的,即便不是最好的,也是最好之一。它的文档和代码结合地很紧密,可以来回跳转。
Rust 几乎所有库的文档都在 docs.rs 下,比如 Bytes 的文档可以通过 docs.rs/bytes 访问:
首先阅读 crate 的文档,这样可以快速了解这个 crate 是做什么的,就像阅读一本书的时候,可以从书的序和前言入手了解梗概。除此之外,我们还可以看一下源码根目录下的 README.md,作为补充资料。
有了大致了解后,你就可以深入了解自己感兴趣的内容。我们就按照初学的顺序来看。
对于 Bytes,我们看到它有两个 trait Buf / BufMut 以及两个数据结构 Bytes/BytesMut,没有 crate 级别的函数。接下来就是深入阅读代码了。
我看的顺序一般是:trait → struct → 函数/方法。因为这和我们写代码的思考方式非常类似:
- 先从需求的流程中敲定系统的行为,需要定义什么接口 trait;
- 再考虑系统有什么状态,定义了哪些数据结构struct;
- 最后到实现细节,包括如何为数据结构实现 trait、数据结构自身有什么算法、如何把整个流程串起来等等。
step2:熟悉核心 trait 的行为
所以先看trait,我们以 Buf trait 为例。点进去看文档,主页面给了这个 trait 的定义和一个使用示例。
注意左侧导航栏的 “required Methods” 和 “Provided Methods”,前者是实现这个 trait 需要实现的方法,后者是缺省方法。也就是说数据结构只要实现了这个 trait 的三个方法:advance()、chunk() 和 remaining(),就可以自动实现所有的缺省方法。当然,你也可以重载某个缺省方法。
导航栏继续往下拉,可以看到 bytes 为哪些 “foreign types” 实现了 Buf trait,以及当前模块有哪些 implementors。这些信息很重要,说明了这个 trait 的生态:
对于其它数据类型(foreign type):
- 切片 &[u8]、VecDeque
都实现了 Buf trait; - 如果 T 满足 Buf trait,那么 &mut T、Box
也实现了 Buf trait; - 如果 T 实现了 AsRef<[u8]>,那 Cursor
也实现了 Buf trait。
所以回过头来,上一幅图文档给到的示例,一个 &[u8] 可以使用 Buf trait 里的方法就顺理成章了:
#![allow(unused)] fn main() { use bytes::Buf; let mut buf = &b"hello world"[..]; assert_eq!(b'h', buf.get_u8()); assert_eq!(b'e', buf.get_u8()); assert_eq!(b'l', buf.get_u8()); let mut rest = [0; 8]; buf.copy_to_slice(&mut rest); assert_eq!(&rest[..], &b"lo world"[..]); }
而且也知道了,如果未来为自己的数据结构 T 实现 Buf trait,那么我们无需为 Box
看到这里,我们目前还没有深入源码,但已经可以学习到高手定义 trait 的一些思路:
- 定义好 trait 后, 可以考虑一下标准库的数据结构,哪些可以实现这个 trait。
- 如果未来别人的某个类型 T ,实现了你的 trait, 那他的 &T、&mut T、Box
等衍生类型,是否能够自动实现这个 trait 。
好,接着看左侧导航栏中的 “implementors”,Bytes、BytesMut、Chain、Take 都实现了 Buf trait,这样我们知道了在这个 crate 里,哪些数据结构实现了这个 trait,之后遇到它们就知道都能用来做什么了。
现在,对 Buf trait 以及围绕着它的生态,我们已经有了一个基本的认识,后面你可以从几个方向深入学习:
你甚至不用 clone bytes 的源码,在 docs.rs 里就可以直接完成这些代码的阅读,非常方便。
step3:掌握主要的struct
扫完 trait 的基本功能后,我们再来看数据结构。以 Bytes 这个结构为例:
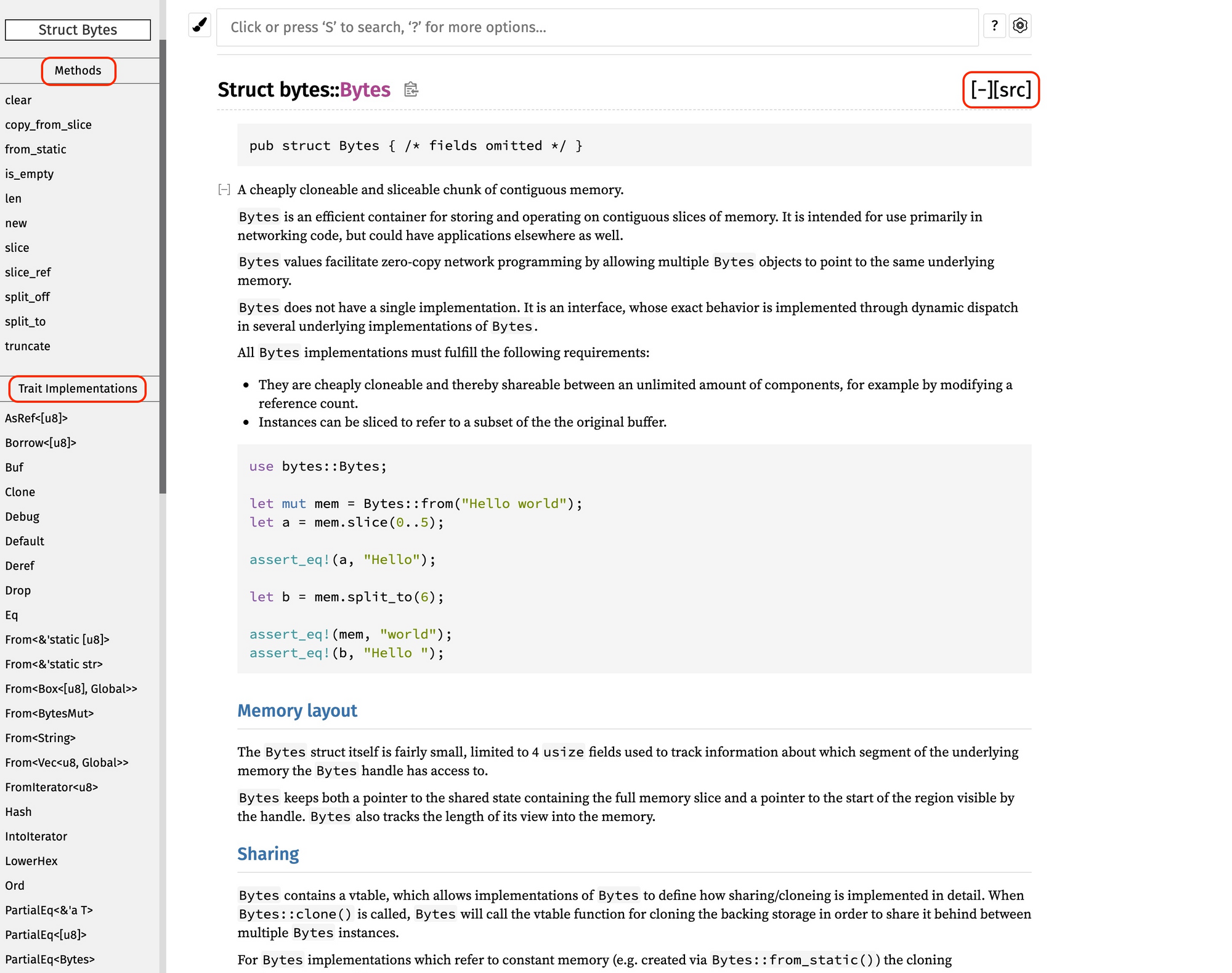
一般来说,好的文档会给出数据结构的介绍、用法、使用时的注意事项,以及一些代码示例。了解了数据结构的基本介绍后,继续看看它的内部结构:
#![allow(unused)] fn main() { /// ```text /// /// Arc ptrs +---------+ /// ________________________ / | Bytes 2 | /// / +---------+ /// / +-----------+ | | /// |_________/ | Bytes 1 | | | /// | +-----------+ | | /// | | | ___/ data | tail /// | data | tail |/ | /// v v v v /// +-----+---------------------------------+-----+ /// | Arc | | | | | /// +-----+---------------------------------+-----+ /// ``` pub struct Bytes { ptr: *const u8, len: usize, // inlined "trait object" data: AtomicPtr<()>, vtable: &'static Vtable, } pub(crate) struct Vtable { /// fn(data, ptr, len) pub clone: unsafe fn(&AtomicPtr<()>, *const u8, usize) -> Bytes, /// fn(data, ptr, len) pub drop: unsafe fn(&mut AtomicPtr<()>, *const u8, usize), } }
数据结构的代码往往会有一些注释,帮助你理解它的设计。对于 Bytes 来说,顺着代码往下看:
- 它内部使用了裸指针和长度,模拟一个切片,指向内存中的一片连续地址;
- 同时,还使用了 AtomicPtr 和手工打造的 Vtable 来模拟了 trait object 的行为。
- 看 Vtable 的样子,大概可以推断出 Bytes 的 clone() 和 drop() 的行为是动态的,这是个很有意思的发现。
不过先不忙继续探索它如何实现这个行为的,继续看文档。
和 trait 类似的,在左侧的导航栏,有一些值得关注的信息(上图+下图):这个数据结构有哪些方法(Methods)、实现了哪些 trait(Trait implementations),以及 Auto trait / Blanket trait 的实现。
可以看到,Bytes 除了实现了刚才讲过的 Buf trait 外,还实现了很多标准 trait。
这也带给我们新的启发: 我们自己的数据结构,也应该尽可能实现需要的标准 trait,包括但不限于:AsRef、Borrow、Clone、Debug、Default、Deref、Drop、PartialEq/Eq、From
注意,除了这些 trait 外,Bytes 还实现了 Send / Sync。如果看很多我们接触过的数据结构,比如 Vec
#![allow(unused)] fn main() { unsafe impl Send for Bytes {} unsafe impl Sync for Bytes {} }
这是因为之前讲过,如果你的数据结构里使用了不支持 Send / Sync 的类型,编译器默认这个数据结构不能跨线程安全使用,不会自动添加 Send / Sync trait 的实现。但如果你能确保跨线程的安全性,可以手工通过 unsafe impl 实现它们。
了解一个数据结构实现了哪些 trait,非常有助于理解它如何使用。所以, 标准库里的主要 trait 我们一定要好好学习,多多使用,最好能形成肌肉记忆。这样,学习别人的代码时,效率会很高。比如我看 Bytes 这个数据结构,扫一下它实现了哪些 trait,就基本能知道:
- 什么数据结构可以转化成 Bytes,也就是如何生成 Bytes 结构;
- Bytes 可以跟谁比较;
- Bytes 是否可以跨线程使用;
- 在使用中,Bytes 的行为和谁比较像(看 Deref trait)。
这就是肌肉记忆的好处。你可以去 crates.io 的 Data structures 类别下多翻翻不同的库,比如 IndexMap,看看它实现了哪些标准 trait,不了解的就看看那些 trait 的文档,也可以回顾 第 14 讲(有哪些必须掌握的 trait)。
当你了解了数据结构的基本文档,知道它实现了哪些方法和哪些 trait 后,基本上,这个数据结构的使用就不在话下了。你也可以看源代码里的 examples 目录或者 tests 目录,看看数据结构对外是如何使用的,作为参考。
对于 bytes 库,它没有额外的 examples 目录,所以我们可以看 tests/test_bytes.rs 来理解 Bytes 类型可以如何使用。现在,你应该能比较从容地使用这个Bytes 库了,不妨尝试写一些自己的示例代码,感受它的能力。
step4:深入研究实现逻辑
当 trait 和数据结构都掌握好,我们已经可以从它的接口上学到很多开发上的思想和技巧,一些关键接口,也了解了足够多的实现细节。获得的知识对使用这个库来做一些事情已经绰绰有余。
大部分对源代码的学习,可以就此止步。因为对我们来说,没有太富余的时间把每个遇到的库都从头到尾研究一番,只要搞明白如何使用好 Rust 生态中可用的库来构建想构建的系统,就足够了。
但有些时候,我们希望能够更深入一步。
比如说想更好地使用这个库,希望进一步了解 Bytes 是如何做到在多线程中可以共享数据的,它跟 Arc<Vec> 有什么区别, Arc<Vec> 是不是可以完成 Bytes 的工作?又或者说,在实现某个系统时,我们也想像 Bytes 这样,实现数据结构自己的 vtable,让数据结构更灵活。
这时就要去深入按主题阅读代码了。这里我推荐 “主题阅读”或者说“情境阅读”,就是围绕着一个特定的使用场景,以这个场景的主流程为脉络,搞明白实现原理。
这时,光靠 docs.rs 上的代码已经满足不了我们的需求,我们要把代码 clone 下来,用 VS Code 打开仔细研究。下图展示了本地 ~/projects/opensource/rust 目录下的代码,它们都是我在不同时期,为了不同的目的,在某些场景下阅读过的源代码:

我们就继续以 Bytes 如何实现自己的 vtable 为例,深入看 Bytes 是如何 clone 的?看 clone 的实现:
#![allow(unused)] fn main() { impl Clone for Bytes { #[inline] fn clone(&self) -> Bytes { unsafe { (self.vtable.clone)(&self.data, self.ptr, self.len) } } } }
它用了 vtable 的 clone 方法,传入了 data ,指向数据的指针以及长度。根据这个信息,我们如果能找到 Bytes 定义的所有 vtable,以及每个 vtable 的 clone() 做了什么事,就足以了解 Bytes 是如何实现 vtable 的了。
因为这一讲并非讲解 Bytes 是如何实现的,就不详细一步步带读代码了。相信你很快从代码中能够找到 STATIC_VTABLE、PROMOTABLE_EVEN_VTABLE、PROMOTABLE_ODD_VTABLE 和 SHARED_VTABLE 这四张表。
后三张表是处理动态数据的,在使用时如果 Bytes 的来源是 Vec
由于 Bytes 的 ptr 指向这个 Bytes 的起始地址,而 data 指向引用计数的地址,所以,你可以在这段内存上,生成任意多的、大小不同、起始位置不一样的 Bytes 结构,它们都
用同一个引用计数。这要比 Arc<Vec> 要灵活得多。具体流程,你可以看下图:
在围绕着情景读代码时, 建议你使用绘图工具,边读边记录(我用的excalidraw),非常有助于你理解代码脉络,不至于在无穷无尽的跳转中迷失了方向。
同时,善用 gdb 等工具来辅助阅读,就像第 17 讲我们剖析 HashMap 结构那样。一个场景理解完毕,这张脉络图也出来了,你可以对它稍作整理,使其成为自己知识库的一部分。
你也可以在团队内部的分享会上,对着图来分享代码,帮助团队更好地理解某些复杂的逻辑。所谓 learning by teaching,在分享的过程中,相当于又学了一遍,也许之前迷茫的地方会茅塞顿开,也许别人一个不经意的问题会让你思考之前没有想到的点。
小结
阅读别人的代码,尤其是优秀的代码,能帮助你快速地成长。
Rust 为了让代码和文档可读性更强,在工具链上做了巨大的努力,让我们在读源码或者别人代码的时候,很容易厘清代码的主要流程和使用方式。今天讲的阅读代码尤其是阅读 Rust 代码的很多技巧,少有人分享但又很重要,掌握好它,你就掌握了通向大牛之路的钥匙。
注意阅读的顺序:从大纲开始,先了解目标代码能干什么,怎么用;然后学习它的主要 trait;之后是数据结构,搞明白后再看看示例代码(examples)或者集成测试(tests),自己写一些示例代码;最后,围绕着自己感兴趣的情景深入阅读。并不是所有的代码都需要走到最后一步,你要根据自己的需要和精力量力而行。
思考题
1.我们一起大致分析了 Bytes 的 clone() 的使用的场景,你能用类似的方式研究一下 drop() 是怎么工作的么?
2.仔细看 Buf trait 里的方法,想想为什么它为 &mut T 实现了 Buf trait,但没有为 &T 实现 Buf trait 呢?如果你认为你找到了答案,再想想为什么它可以为 &[u8] 实现 Buf trait 呢?
3.花点时间看看 BufMut trait 的文档。Vec 可以使用 BufMut 么?如果可以,试着写写代码在 Vec 上调用 BufMut 的各种接口,感受一下。
4.如果有余力,可以研究一下 BytesMut。重点看一下 split_off() 方法是如何实现的。
欢迎你在留言区分享自己读源码的一些故事,欢迎抢答思考题。感谢你的一路坚持,今天你完成了Rust学习的第20次打卡,我们下节课开始第一个阶段的实操,下节课见~
参考资料
如果在阅读 Bytes 的 clone() 场景时,对于 PROMOTABLE_EVEN_VTABLE、PROMOTABLE_ODD_VTABLE 这两张表比较迷惑,且不明白为什么会根据 ptr & 0x1 是否等于 0 来提供不同的 vtable:
#![allow(unused)] fn main() { impl From<Box<[u8]>> for Bytes { fn from(slice: Box<[u8]>) -> Bytes { // Box<[u8]> doesn't contain a heap allocation for empty slices, // so the pointer isn't aligned enough for the KIND_VEC stashing to // work. if slice.is_empty() { return Bytes::new(); } let len = slice.len(); let ptr = Box::into_raw(slice) as *mut u8; if ptr as usize & 0x1 == 0 { let data = ptr as usize | KIND_VEC; Bytes { ptr, len, data: AtomicPtr::new(data as *mut _), vtable: &PROMOTABLE_EVEN_VTABLE, } } else { Bytes { ptr, len, data: AtomicPtr::new(ptr as *mut _), vtable: &PROMOTABLE_ODD_VTABLE, } } } } }
这是因为,Box<[u8]> 是 1 字节对齐,所以 Box<[u8]> 指向的堆地址可能末尾是 0 或者 1。而 data 这个 AtomicPtr 指针,在指向 Shared 结构时,这个结构的对齐是 2/4/8 字节(16/32/64 位 CPU 下),末尾一定为 0:
#![allow(unused)] fn main() { struct Shared { // holds vec for drop, but otherwise doesnt access it _vec: Vec<u8>, ref_cnt: AtomicUsize, } }
所以这里用了一个小技巧,以 data 指针末尾是否为 0x1 来区别,当前的 Bytes 是升级成共享,类似于 Arc 的结构(KIND_ARC),还是依旧停留在非共享的,类似 Vec 的结构(KIND_VEC)。
这个复用指针最后几个 bit 记录一些 flag 的小技巧,在很多系统中都会使用。比如 Erlang VM,在存储 list 时,因为地址的对齐,最后两个 bit 不会被用到,所以当最后一个 bit 是 1 时,代表这是个指向 list 元素的地址。这种技巧,如果你不知道的话,看代码会很懵,一旦了解就没那么神秘了。
如果你觉得有收获,欢迎分享~
阶段实操(1):构建一个简单的KV server-基本流程
你好,我是陈天。
从第七讲开始,我们一路过关斩将,和所有权、生命周期死磕,跟类型系统和 trait 反复拉锯,为的是啥?就是为了能够读懂别人写的代码,进而让自己也能写出越来越复杂且优雅的代码。
今天就到检验自身实力的时候了,毕竟talk is cheap,知识点掌握得再多,自己写不出来也白搭,所以我们把之前学的知识都运用起来,一起写个简单的 KV server。
不过这次和 get hands dirty 重感性体验的代码不同,我会带你一步步真实打磨,讲得比较细致,所以内容也会比较多,我分成了上下两篇文章,希望你能耐心看完,认真感受 Rust best practice 在架构设计以及代码实现思路上的体现。
为什么选 KV server 来实操呢?因为它是一个 足够简单又足够复杂 的服务。参考工作中用到的 Redis / Memcached 等服务,来梳理它的需求。
- 最核心的功能是根据不同的命令进行诸如数据存贮、读取、监听等操作;
- 而客户端要能通过网络访问 KV server,发送包含命令的请求,得到结果;
- 数据要能根据需要,存储在内存中或者持久化到磁盘上。
先来一个短平糙的实现
如果是为了完成任务构建 KV server,其实最初的版本两三百行代码就可以搞定,但是这样的代码以后维护起来就是灾难。
我们看一个省却了不少细节的意大利面条式的版本,你可以随着我的注释重点看流程:
use anyhow::Result; use async_prost::AsyncProstStream; use dashmap::DashMap; use futures::prelude::*; use kv::{ command_request::RequestData, CommandRequest, CommandResponse, Hset, KvError, Kvpair, Value, }; use std::sync::Arc; use tokio::net::TcpListener; use tracing::info; #[tokio::main] async fn main() -> Result<()> { // 初始化日志 tracing_subscriber::fmt::init(); let addr = "127.0.0.1:9527"; let listener = TcpListener::bind(addr).await?; info!("Start listening on {}", addr); // 使用 DashMap 创建放在内存中的 kv store let table: Arc<DashMap<String, Value>> = Arc::new(DashMap::new()); loop { // 得到一个客户端请求 let (stream, addr) = listener.accept().await?; info!("Client {:?} connected", addr); // 复制 db,让它在 tokio 任务中可以使用 let db = table.clone(); // 创建一个 tokio 任务处理这个客户端 tokio::spawn(async move { // 使用 AsyncProstStream 来处理 TCP Frame // Frame: 两字节 frame 长度,后面是 protobuf 二进制 let mut stream = AsyncProstStream::<_, CommandRequest, CommandResponse, _>::from(stream).for_async(); // 从 stream 里取下一个消息(拿出来后已经自动 decode 了) while let Some(Ok(msg)) = stream.next().await { info!("Got a new command: {:?}", msg); let resp: CommandResponse = match msg.request_data { // 为演示我们就处理 HSET Some(RequestData::Hset(cmd)) => hset(cmd, &db), // 其它暂不处理 _ => unimplemented!(), }; info!("Got response: {:?}", resp); // 把 CommandResponse 发送给客户端 stream.send(resp).await.unwrap(); } }); } } // 处理 hset 命令 fn hset(cmd: Hset, db: &DashMap<String, Value>) -> CommandResponse { match cmd.pair { Some(Kvpair { key, value: Some(v), }) => { // 往 db 里写入 let old = db.insert(key, v).unwrap_or_default(); // 把 value 转换成 CommandResponse old.into() } v => KvError::InvalidCommand(format!("hset: {:?}", v)).into(), } }
这段代码非常地平铺直叙,从输入到输出,一蹴而就,如果这样写,任务确实能很快完成,但是它有种“完成之后,哪管洪水滔天”的感觉。
你复制代码后,打开两个窗口,分别运行 “cargo run --example naive_server” 和 “cargo run --example client”,就可以看到运行 server 的窗口有如下打印:
Sep 19 22:25:34.016 INFO naive_server: Start listening on 127.0.0.1:9527
Sep 19 22:25:38.401 INFO naive_server: Client 127.0.0.1:51650 connected
Sep 19 22:25:38.401 INFO naive_server: Got a new command: CommandRequest { request_data: Some(Hset(Hset { table: "table1", pair: Some(Kvpair { key: "hello", value: Some(Value { value: Some(String("world")) }) }) })) }
Sep 19 22:25:38.401 INFO naive_server: Got response: CommandResponse { status: 200, message: "", values: [Value { value: None }], pairs: [] }
虽然整体功能算是搞定了,不过以后想继续为这个 KV server 增加新的功能,就需要来来回回改这段代码。
此外,也不好做单元测试,因为所有的逻辑都被压缩在一起了,没有“单元”可言。虽然未来可以逐步把不同的逻辑分离到不同的函数,使主流程尽可能简单一些。但是,它们依旧是耦合在一起的,如果不做大的重构,还是解决不了实质的问题。
所以不管用什么语言开发,这样的代码都是我们要极力避免的,不光自己不要这么写,code review 遇到别人这么写也要严格地揪出来。
架构和设计
那么,怎样才算是好的实现呢?
好的实现应该是在分析完需求后,首先从系统的主流程开始,搞清楚从客户端的请求到最终客户端收到响应,都会经过哪些主要的步骤;然后根据这些步骤,思考哪些东西需要延迟绑定,构建主要的接口和 trait;等这些东西深思熟虑之后,最后再考虑实现。也就是所谓的“谋定而后动”。
开头已经分析 KV server 这个需求,现在我们来梳理主流程。你可以先自己想想,再参考示意图看看有没有缺漏:
这个流程中有一些关键问题需要进一步探索:
- 客户端和服务器用什么协议通信?TCP?gRPC?HTTP?支持一种还是多种?
- 客户端和服务器之间交互的应用层协议如何定义?怎么做序列化/反序列化?是用 Protobuf、JSON 还是 Redis RESP?或者也可以支持多种?
- 服务器都支持哪些命令?第一版优先支持哪些?
- 具体的处理逻辑中,需不需要加 hook,在处理过程中发布一些事件,让其他流程可以得到通知,进行额外的处理?这些 hook 可不可以提前终止整个流程的处理?
- 对于存储,要支持不同的存储引擎么?比如 MemDB(内存)、RocksDB(磁盘)、SledDB(磁盘)等。对于 MemDB,我们考虑支持 WAL(Write-Ahead Log) 和 snapshot 么?
- 整个系统可以配置么?比如服务使用哪个端口、哪个存储引擎?
- …
如果你想做好架构,那么,问出这些问题,并且找到这些问题的答案就很重要。值得注意的是,这里面很多问题产品经理并不能帮你回答,或者TA的回答会将你带入歧路。作为一个架构师,我们需要对系统未来如何应对变化负责。
下面是我的思考,你可以参考:
1.像 KV server 这样需要高性能的场景,通信应该优先考虑 TCP 协议。所以我们暂时只支持 TCP,未来可以根据需要支持更多的协议,如 HTTP2/gRPC。还有,未来可能对安全性有额外的要求,所以我们要保证 TLS 这样的安全协议可以即插即用。总之, 网络层需要灵活。
2.应用层协议我们可以用 protobuf 定义。protobuf 直接解决了协议的定义以及如何序列化和反序列化。Redis 的 RESP 固然不错,但它的短板也显而易见,命令需要额外的解析,而且大量的 \r\n 来分隔命令或者数据,也有些浪费带宽。使用 JSON 的话更加浪费带宽,且 JSON 的解析效率不高,尤其是数据量很大的时候。
protobuf 就很适合 KV server 这样的场景,灵活、可向后兼容式升级、解析效率很高、生成的二进制非常省带宽,唯一的缺点是需要额外的工具 protoc 来编译成不同的语言。虽然 protobuf 是首选,但也许未来为了和 Redis 客户端互通,还是要支持 RESP。
3.服务器支持的命令我们可以参考 Redis 的命令集。第一版先来支持 HXXX 命令,比如 HSET、HMSET、HGET、HMGET 等。从命令到命令的响应,可以做个 trait 来抽象。
4.处理流程中计划加这些 hook:收到客户端的命令后 OnRequestReceived、处理完客户端的命令后 OnRequestExecuted、发送响应之前 BeforeResponseSend、发送响应之后 AfterResponseSend。这样, 处理过程中的主要步骤都有事件暴露出去,让我们的 KV server 可以非常灵活,方便调用者在初始化服务的时候注入额外的处理逻辑。
5.存储必然需要足够灵活。可以对存储做个 trait 来抽象其基本的行为,一开始可以就只做 MemDB,未来肯定需要有支持持久化的存储。
6.需要支持配置,但优先级不高。等基本流程搞定,使用过程中发现足够的痛点,就可以考虑配置文件如何处理了。
当这些问题都敲定下来,系统的基本思路就有了。我们可以先把几个重要的接口定义出来,然后仔细审视这些接口。
最重要的几个接口就是 三个主体交互的接口:客户端和服务器的接口或者说协议、服务器和命令处理流程的接口、服务器和存储的接口。
客户端和服务器间的协议
首先是客户端和服务器之间的协议。来试着用 protobuf 定义一下我们第一版支持的客户端命令:
syntax = "proto3";
package abi;
// 来自客户端的命令请求
message CommandRequest {
oneof request_data {
Hget hget = 1;
Hgetall hgetall = 2;
Hmget hmget = 3;
Hset hset = 4;
Hmset hmset = 5;
Hdel hdel = 6;
Hmdel hmdel = 7;
Hexist hexist = 8;
Hmexist hmexist = 9;
}
}
// 服务器的响应
message CommandResponse {
// 状态码;复用 HTTP 2xx/4xx/5xx 状态码
uint32 status = 1;
// 如果不是 2xx,message 里包含详细的信息
string message = 2;
// 成功返回的 values
repeated Value values = 3;
// 成功返回的 kv pairs
repeated Kvpair pairs = 4;
}
// 从 table 中获取一个 key,返回 value
message Hget {
string table = 1;
string key = 2;
}
// 从 table 中获取所有的 Kvpair
message Hgetall { string table = 1; }
// 从 table 中获取一组 key,返回它们的 value
message Hmget {
string table = 1;
repeated string keys = 2;
}
// 返回的值
message Value {
oneof value {
string string = 1;
bytes binary = 2;
int64 integer = 3;
double float = 4;
bool bool = 5;
}
}
// 返回的 kvpair
message Kvpair {
string key = 1;
Value value = 2;
}
// 往 table 里存一个 kvpair,
// 如果 table 不存在就创建这个 table
message Hset {
string table = 1;
Kvpair pair = 2;
}
// 往 table 中存一组 kvpair,
// 如果 table 不存在就创建这个 table
message Hmset {
string table = 1;
repeated Kvpair pairs = 2;
}
// 从 table 中删除一个 key,返回它之前的值
message Hdel {
string table = 1;
string key = 2;
}
// 从 table 中删除一组 key,返回它们之前的值
message Hmdel {
string table = 1;
repeated string keys = 2;
}
// 查看 key 是否存在
message Hexist {
string table = 1;
string key = 2;
}
// 查看一组 key 是否存在
message Hmexist {
string table = 1;
repeated string keys = 2;
}
通过 prost,这个 protobuf 文件可以被编译成 Rust 代码(主要是 struct 和 enum),供我们使用。你应该还记得,之前在 第 5 讲 谈到 thumbor 的开发时,已经见识到了 prost 处理 protobuf 的方式了。
CommandService trait
客户端和服务器间的协议敲定之后,就要思考如何处理请求的命令,返回响应。
我们目前打算支持 9 种命令,未来可能支持更多命令。所以最好 定义一个 trait 来统一处理所有的命令,返回处理结果。在处理命令的时候,需要和存储发生关系,这样才能根据请求中携带的参数读取数据,或者把请求中的数据存入存储系统中。所以,这个 trait 可以这么定义:
#![allow(unused)] fn main() { /// 对 Command 的处理的抽象 pub trait CommandService { /// 处理 Command,返回 Response fn execute(self, store: &impl Storage) -> CommandResponse; } }
有了这个 trait,并且每一个命令都实现了这个 trait 后,dispatch 方法就可以是类似这样的代码:
#![allow(unused)] fn main() { // 从 Request 中得到 Response,目前处理 HGET/HGETALL/HSET pub fn dispatch(cmd: CommandRequest, store: &impl Storage) -> CommandResponse { match cmd.request_data { Some(RequestData::Hget(param)) => param.execute(store), Some(RequestData::Hgetall(param)) => param.execute(store), Some(RequestData::Hset(param)) => param.execute(store), None => KvError::InvalidCommand("Request has no data".into()).into(), _ => KvError::Internal("Not implemented".into()).into(), } } }
这样,未来我们支持新命令时,只需要做两件事:为命令实现 CommandService、在 dispatch 方法中添加新命令的支持。
Storage trait
再来看为不同的存储而设计的 Storage trait,它提供 KV store 的主要接口:
#![allow(unused)] fn main() { /// 对存储的抽象,我们不关心数据存在哪儿,但需要定义外界如何和存储打交道 pub trait Storage { /// 从一个 HashTable 里获取一个 key 的 value fn get(&self, table: &str, key: &str) -> Result<Option<Value>, KvError>; /// 从一个 HashTable 里设置一个 key 的 value,返回旧的 value fn set(&self, table: &str, key: String, value: Value) -> Result<Option<Value>, KvError>; /// 查看 HashTable 中是否有 key fn contains(&self, table: &str, key: &str) -> Result<bool, KvError>; /// 从 HashTable 中删除一个 key fn del(&self, table: &str, key: &str) -> Result<Option<Value>, KvError>; /// 遍历 HashTable,返回所有 kv pair(这个接口不好) fn get_all(&self, table: &str) -> Result<Vec<Kvpair>, KvError>; /// 遍历 HashTable,返回 kv pair 的 Iterator fn get_iter(&self, table: &str) -> Result<Box<dyn Iterator<Item = Kvpair>>, KvError>; } }
在 CommandService trait 中已经看到,在处理客户端请求的时候,与之打交道的是 Storage trait,而非具体的某个 store。这样做的好处是, 未来根据业务的需要,在不同的场景下添加不同的 store,只需要为其实现 Storage trait 即可,不必修改 CommandService 有关的代码。
比如在 HGET 命令的实现时,我们使用 Storage::get 方法,从 table 中获取数据,它跟某个具体的存储方案无关:
#![allow(unused)] fn main() { impl CommandService for Hget { fn execute(self, store: &impl Storage) -> CommandResponse { match store.get(&self.table, &self.key) { Ok(Some(v)) => v.into(), Ok(None) => KvError::NotFound(self.table, self.key).into(), Err(e) => e.into(), } } } }
Storage trait 里面的绝大多数方法相信你可以定义出来,但 get_iter() 这个接口可能你会比较困惑,因为它返回了一个 Box
之前( 第 13 讲)讲过这是 trait object。
这里我们想返回一个 iterator,调用者不关心它具体是什么类型,只要可以不停地调用 next() 方法取到下一个值就可以了。不同的实现,可能返回不同的 iterator,如果要用同一个接口承载,我们需要使用 trait object。在使用 trait object 时,因为 Iterator 是个带有关联类型的 trait,所以这里需要指明关联类型 Item 是什么类型,这样调用者才好拿到这个类型进行处理。
你也许会有疑问,set / del 明显是个会导致 self 修改的方法,为什么它的接口依旧使用的是 &self 呢?
我们思考一下它的用法。对于 Storage trait,最简单的实现是 in-memory 的 HashMap。由于我们支持的是 HSET / HGET 这样的命令, 它们可以从不同的表中读取数据,所以需要嵌套的 HashMap,类似 HashMap<String, HashMap<String, Value>>。
另外,由于 要在多线程/异步环境下读取和更新内存中的 HashMap,所以我们需要类似 Arc<RwLock<HashMap<String, Arc<RwLock<HashMap<String, Value>>>>>> 的结构。这个结构是一个多线程环境下具有内部可变性的数据结构,所以 get / set 的接口是 &self 就足够了。
小结
到现在,我们梳理了 KV server 的主要需求和主流程,思考了流程中可能出现的问题,也敲定了三个重要的接口:客户端和服务器的协议、CommandService trait、Storage trait。下一讲继续实现 KV server,在看讲解之前,你可以先想一想自己平时是怎么开发的。
思考题
想一想,对于 Storage trait,为什么返回值都用了 Result<T, E>?在实现 MemTable 的时候,似乎所有返回都是 Ok(T) 啊?
欢迎在留言区分享你的思考。我们下篇见~
阶段实操(2):构建一个简单的KV server-基本流程
你好,我是陈天。
上篇我们的KV store刚开了个头,写好了基本的接口。你是不是摩拳擦掌准备开始写具体实现的代码了?别着急,当定义好接口后,先不忙实现,在撰写更多代码前,我们可以从一个使用者的角度来体验接口如何使用、是否好用,反观设计有哪些地方有待完善。
还是按照上一讲定义接口的顺序来一个一个测试:首先我们来构建协议层。
实现并验证协议层
先创建一个项目: cargo new kv --lib。进入到项目目录,在 Cargo.toml 中添加依赖:
#![allow(unused)] fn main() { [package] name = "kv" version = "0.1.0" edition = "2018" [dependencies] bytes = "1" # 高效处理网络 buffer 的库 prost = "0.8" # 处理 protobuf 的代码 tracing = "0.1" # 日志处理 [dev-dependencies] anyhow = "1" # 错误处理 async-prost = "0.2.1" # 支持把 protobuf 封装成 TCP frame futures = "0.3" # 提供 Stream trait tokio = { version = "1", features = ["rt", "rt-multi-thread", "io-util", "macros", "net" ] } # 异步网络库 tracing-subscriber = "0.2" # 日志处理 [build-dependencies] prost-build = "0.8" # 编译 protobuf }
然后在项目根目录下创建 abi.proto,把上文中 protobuf 的代码放进去。在根目录下,再创建 build.rs:
fn main() { let mut config = prost_build::Config::new(); config.bytes(&["."]); config.type_attribute(".", "#[derive(PartialOrd)]"); config .out_dir("src/pb") .compile_protos(&["abi.proto"], &["."]) .unwrap(); }
这个代码在 第 5 讲 已经见过了, build.rs 在编译期运行来进行额外的处理。
这里我们为编译出来的代码额外添加了一些属性。比如为 protobuf 的 bytes 类型生成 Bytes 而非缺省的 Vec
记得创建 src/pb 目录,否则编不过。现在,在项目根目录下做 cargo build 会生成 src/pb/abi.rs 文件,里面包含所有 protobuf 定义的消息的 Rust 数据结构。我们创建 src/pb/mod.rs,引入 abi.rs,并做一些基本的类型转换:
#![allow(unused)] fn main() { pub mod abi; use abi::{command_request::RequestData, *}; impl CommandRequest { /// 创建 HSET 命令 pub fn new_hset(table: impl Into<String>, key: impl Into<String>, value: Value) -> Self { Self { request_data: Some(RequestData::Hset(Hset { table: table.into(), pair: Some(Kvpair::new(key, value)), })), } } } impl Kvpair { /// 创建一个新的 kv pair pub fn new(key: impl Into<String>, value: Value) -> Self { Self { key: key.into(), value: Some(value), } } } /// 从 String 转换成 Value impl From<String> for Value { fn from(s: String) -> Self { Self { value: Some(value::Value::String(s)), } } } /// 从 &str 转换成 Value impl From<&str> for Value { fn from(s: &str) -> Self { Self { value: Some(value::Value::String(s.into())), } } } }
最后,在 src/lib.rs 中,引入 pb 模块:
#![allow(unused)] fn main() { mod pb; pub use pb::abi::*; }
这样,我们就有了能把 KV server 最基本的 protobuf 接口运转起来的代码。
在根目录下创建 examples,这样可以写一些代码测试客户端和服务器之间的协议。我们可以先创建一个 examples/client.rs 文件,写入如下代码:
use anyhow::Result; use async_prost::AsyncProstStream; use futures::prelude::*; use kv::{CommandRequest, CommandResponse}; use tokio::net::TcpStream; use tracing::info; #[tokio::main] async fn main() -> Result<()> { tracing_subscriber::fmt::init(); let addr = "127.0.0.1:9527"; // 连接服务器 let stream = TcpStream::connect(addr).await?; // 使用 AsyncProstStream 来处理 TCP Frame let mut client = AsyncProstStream::<_, CommandResponse, CommandRequest, _>::from(stream).for_async(); // 生成一个 HSET 命令 let cmd = CommandRequest::new_hset("table1", "hello", "world".into()); // 发送 HSET 命令 client.send(cmd).await?; if let Some(Ok(data)) = client.next().await { info!("Got response {:?}", data); } Ok(()) }
这段代码连接服务器的 9527 端口,发送一个 HSET 命令出去,然后等待服务器的响应。
同样的,我们创建一个 examples/dummy_server.rs 文件,写入代码:
use anyhow::Result; use async_prost::AsyncProstStream; use futures::prelude::*; use kv::{CommandRequest, CommandResponse}; use tokio::net::TcpListener; use tracing::info; #[tokio::main] async fn main() -> Result<()> { tracing_subscriber::fmt::init(); let addr = "127.0.0.1:9527"; let listener = TcpListener::bind(addr).await?; info!("Start listening on {}", addr); loop { let (stream, addr) = listener.accept().await?; info!("Client {:?} connected", addr); tokio::spawn(async move { let mut stream = AsyncProstStream::<_, CommandRequest, CommandResponse, _>::from(stream).for_async(); while let Some(Ok(msg)) = stream.next().await { info!("Got a new command: {:?}", msg); // 创建一个 404 response 返回给客户端 let mut resp = CommandResponse::default(); resp.status = 404; resp.message = "Not found".to_string(); stream.send(resp).await.unwrap(); } info!("Client {:?} disconnected", addr); }); } }
在这段代码里,服务器监听 9527 端口,对任何客户端的请求,一律返回 status = 404,message 是 “Not found” 的响应。
如果你对这两段代码中的异步和网络处理半懂不懂,没关系,你先把代码抄下来运行。今天的内容跟网络无关,你重点看处理流程就行。未来会讲到网络和异步处理的。
我们可以打开一个命令行窗口,运行: RUST_LOG=info cargo run --example dummy_server --quiet。然后在另一个命令行窗口,运行: RUST_LOG=info cargo run --example client --quiet。
此时,服务器和客户端都收到了彼此的请求和响应,协议层看上去运作良好。一旦验证通过,就你可以进入下一步,因为协议层的其它代码都只是工作量而已,在之后需要的时候可以慢慢实现。
实现并验证 Storage trait
接下来构建 Storage trait。
我们上一讲谈到了如何使用嵌套的支持并发的 im-memory HashMap 来实现 storage trait。由于 Arc<RwLock<HashMap<K, V>>> 这样的支持并发的 HashMap 是一个刚需,Rust 生态有很多相关的 crate 支持,这里我们可以使用 dashmap 创建一个 MemTable 结构,来实现 Storage trait。
先创建 src/storage 目录,然后创建 src/storage/mod.rs,把刚才讨论的 trait 代码放进去后,在 src/lib.rs 中引入 “mod storage”。此时会发现一个错误:并未定义 KvError。
所以来定义 KvError。 第 18 讲 讨论错误处理时简单演示了,如何使用 thiserror 的派生宏来定义错误类型,今天就用它来定义 KvError。创建 src/error.rs,然后填入:
#![allow(unused)] fn main() { use crate::Value; use thiserror::Error; #[derive(Error, Debug, PartialEq)] pub enum KvError { #[error("Not found for table: {0}, key: {1}")] NotFound(String, String), #[error("Cannot parse command: `{0}`")] InvalidCommand(String), #[error("Cannot convert value {:0} to {1}")] ConvertError(Value, &'static str), #[error("Cannot process command {0} with table: {1}, key: {2}. Error: {}")] StorageError(&'static str, String, String, String), #[error("Failed to encode protobuf message")] EncodeError(#[from] prost::EncodeError), #[error("Failed to decode protobuf message")] DecodeError(#[from] prost::DecodeError), #[error("Internal error: {0}")] Internal(String), } }
这些 error 的定义其实是在实现过程中逐步添加的,但为了讲解方便,先一次性添加。对于 Storage 的实现,我们只关心 StorageError,其它的 error 定义未来会用到。
同样,在 src/lib.rs 下引入 mod error,现在 src/lib.rs 是这个样子的:
#![allow(unused)] fn main() { mod error; mod pb; mod storage; pub use error::KvError; pub use pb::abi::*; pub use storage::*; }
src/storage/mod.rs 是这个样子的:
#![allow(unused)] fn main() { use crate::{KvError, Kvpair, Value}; /// 对存储的抽象,我们不关心数据存在哪儿,但需要定义外界如何和存储打交道 pub trait Storage { /// 从一个 HashTable 里获取一个 key 的 value fn get(&self, table: &str, key: &str) -> Result<Option<Value>, KvError>; /// 从一个 HashTable 里设置一个 key 的 value,返回旧的 value fn set(&self, table: &str, key: String, value: Value) -> Result<Option<Value>, KvError>; /// 查看 HashTable 中是否有 key fn contains(&self, table: &str, key: &str) -> Result<bool, KvError>; /// 从 HashTable 中删除一个 key fn del(&self, table: &str, key: &str) -> Result<Option<Value>, KvError>; /// 遍历 HashTable,返回所有 kv pair(这个接口不好) fn get_all(&self, table: &str) -> Result<Vec<Kvpair>, KvError>; /// 遍历 HashTable,返回 kv pair 的 Iterator fn get_iter(&self, table: &str) -> Result<Box<dyn Iterator<Item = Kvpair>>, KvError>; } }
代码目前没有编译错误,可以在这个文件末尾添加测试代码,尝试使用这些接口了,当然,我们还没有构建 MemTable,但通过 Storage trait 已经大概知道 MemTable 怎么用,所以可以先写段测试体验一下:
#![allow(unused)] fn main() { #[cfg(test)] mod tests { use super::*; #[test] fn memtable_basic_interface_should_work() { let store = MemTable::new(); test_basi_interface(store); } #[test] fn memtable_get_all_should_work() { let store = MemTable::new(); test_get_all(store); } fn test_basi_interface(store: impl Storage) { // 第一次 set 会创建 table,插入 key 并返回 None(之前没值) let v = store.set("t1", "hello".into(), "world".into()); assert!(v.unwrap().is_none()); // 再次 set 同样的 key 会更新,并返回之前的值 let v1 = store.set("t1", "hello".into(), "world1".into()); assert_eq!(v1, Ok(Some("world".into()))); // get 存在的 key 会得到最新的值 let v = store.get("t1", "hello"); assert_eq!(v, Ok(Some("world1".into()))); // get 不存在的 key 或者 table 会得到 None assert_eq!(Ok(None), store.get("t1", "hello1")); assert!(store.get("t2", "hello1").unwrap().is_none()); // contains 纯在的 key 返回 true,否则 false assert_eq!(store.contains("t1", "hello"), Ok(true)); assert_eq!(store.contains("t1", "hello1"), Ok(false)); assert_eq!(store.contains("t2", "hello"), Ok(false)); // del 存在的 key 返回之前的值 let v = store.del("t1", "hello"); assert_eq!(v, Ok(Some("world1".into()))); // del 不存在的 key 或 table 返回 None assert_eq!(Ok(None), store.del("t1", "hello1")); assert_eq!(Ok(None), store.del("t2", "hello")); } fn test_get_all(store: impl Storage) { store.set("t2", "k1".into(), "v1".into()).unwrap(); store.set("t2", "k2".into(), "v2".into()).unwrap(); let mut data = store.get_all("t2").unwrap(); data.sort_by(|a, b| a.partial_cmp(b).unwrap()); assert_eq!( data, vec![ Kvpair::new("k1", "v1".into()), Kvpair::new("k2", "v2".into()) ] ) } fn test_get_iter(store: impl Storage) { store.set("t2", "k1".into(), "v1".into()).unwrap(); store.set("t2", "k2".into(), "v2".into()).unwrap(); let mut data: Vec<_> = store.get_iter("t2").unwrap().collect(); data.sort_by(|a, b| a.partial_cmp(b).unwrap()); assert_eq!( data, vec![ Kvpair::new("k1", "v1".into()), Kvpair::new("k2", "v2".into()) ] ) } } }
这种在写实现之前写单元测试,是标准的 TDD(Test-Driven Development)方式。
我个人不是 TDD 的狂热粉丝, 但会在构建完 trait 后,为这个 trait 撰写测试代码,因为写测试代码是个很好的验证接口是否好用的时机。毕竟我们不希望实现 trait 之后,才发现 trait 的定义有瑕疵,需要修改,这个时候改动的代价就比较大了。
所以,当 trait 推敲完毕,就可以开始写使用 trait 的测试代码了。在使用过程中仔细感受,如果写测试用例时用得不舒服,或者为了使用它需要做很多繁琐的操作,那么可以重新审视 trait 的设计。
你如果仔细看单元测试的代码,就会发现我始终秉持 测试 trait 接口的思想。尽管在测试中需要一个实际的数据结构进行 trait 方法的测试,但核心的测试代码都用的泛型函数,让这些代码只跟 trait 相关。
这样,一来可以避免某个具体 trait 实现的干扰,二来在之后想加入更多 trait 实现时,可以共享测试代码。比如未来想支持 DiskTable,那么只消加几个测试例,调用已有的泛型函数即可。
好,搞定测试,确认trait设计没有什么问题之后,我们来写具体实现。可以创建 src/storage/memory.rs 来构建 MemTable:
#![allow(unused)] fn main() { use crate::{KvError, Kvpair, Storage, Value}; use dashmap::{mapref::one::Ref, DashMap}; /// 使用 DashMap 构建的 MemTable,实现了 Storage trait #[derive(Clone, Debug, Default)] pub struct MemTable { tables: DashMap<String, DashMap<String, Value>>, } impl MemTable { /// 创建一个缺省的 MemTable pub fn new() -> Self { Self::default() } /// 如果名为 name 的 hash table 不存在,则创建,否则返回 fn get_or_create_table(&self, name: &str) -> Ref<String, DashMap<String, Value>> { match self.tables.get(name) { Some(table) => table, None => { let entry = self.tables.entry(name.into()).or_default(); entry.downgrade() } } } } impl Storage for MemTable { fn get(&self, table: &str, key: &str) -> Result<Option<Value>, KvError> { let table = self.get_or_create_table(table); Ok(table.get(key).map(|v| v.value().clone())) } fn set(&self, table: &str, key: String, value: Value) -> Result<Option<Value>, KvError> { let table = self.get_or_create_table(table); Ok(table.insert(key, value)) } fn contains(&self, table: &str, key: &str) -> Result<bool, KvError> { let table = self.get_or_create_table(table); Ok(table.contains_key(key)) } fn del(&self, table: &str, key: &str) -> Result<Option<Value>, KvError> { let table = self.get_or_create_table(table); Ok(table.remove(key).map(|(_k, v)| v)) } fn get_all(&self, table: &str) -> Result<Vec<Kvpair>, KvError> { let table = self.get_or_create_table(table); Ok(table .iter() .map(|v| Kvpair::new(v.key(), v.value().clone())) .collect()) } fn get_iter(&self, _table: &str) -> Result<Box<dyn Iterator<Item = Kvpair>>, KvError> { todo!() } } }
除了 get_iter() 外,这个实现代码非常简单,相信你看一下 dashmap 的文档,也能很快写出来。get_iter() 写起来稍微有些难度,我们先放下不表,会在下一篇 KV server 讲。如果你对此感兴趣,想挑战一下,欢迎尝试。
实现完成之后,我们可以测试它是否符合预期。注意现在 src/storage/memory.rs 还没有被添加,所以 cargo 并不会编译它。要在 src/storage/mod.rs 开头添加代码:
#![allow(unused)] fn main() { mod memory; pub use memory::MemTable; }
这样代码就可以编译通过了。因为还没有实现 get_iter 方法,所以这个测试需要被注释掉:
#![allow(unused)] fn main() { // #[test] // fn memtable_iter_should_work() { // let store = MemTable::new(); // test_get_iter(store); // } }
如果你运行 cargo test ,可以看到测试都通过了:
> cargo test
Compiling kv v0.1.0 (/Users/tchen/projects/mycode/rust/geek-time-rust-resources/21/kv)
Finished test [unoptimized + debuginfo] target(s) in 1.95s
Running unittests (/Users/tchen/.target/debug/deps/kv-8d746b0f387a5271)
running 2 tests
test storage::tests::memtable_basic_interface_should_work ... ok
test storage::tests::memtable_get_all_should_work ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests kv
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
实现并验证 CommandService trait
Storage trait 我们就算基本验证通过了,现在再来验证 CommandService。
我们创建 src/service 目录,以及 src/service/mod.rs 和 src/service/command_service.rs 文件,并在 src/service/mod.rs 写入:
#![allow(unused)] fn main() { use crate::*; mod command_service; /// 对 Command 的处理的抽象 pub trait CommandService { /// 处理 Command,返回 Response fn execute(self, store: &impl Storage) -> CommandResponse; } }
不要忘记在 src/lib.rs 中加入 service:
#![allow(unused)] fn main() { mod error; mod pb; mod service; mod storage; pub use error::KvError; pub use pb::abi::*; pub use service::*; pub use storage::*; }
然后,在 src/service/command_service.rs 中,我们可以先写一些测试。为了简单起见,就列 HSET、HGET、HGETALL 三个命令:
#![allow(unused)] fn main() { use crate::*; #[cfg(test)] mod tests { use super::*; use crate::command_request::RequestData; #[test] fn hset_should_work() { let store = MemTable::new(); let cmd = CommandRequest::new_hset("t1", "hello", "world".into()); let res = dispatch(cmd.clone(), &store); assert_res_ok(res, &[Value::default()], &[]); let res = dispatch(cmd, &store); assert_res_ok(res, &["world".into()], &[]); } #[test] fn hget_should_work() { let store = MemTable::new(); let cmd = CommandRequest::new_hset("score", "u1", 10.into()); dispatch(cmd, &store); let cmd = CommandRequest::new_hget("score", "u1"); let res = dispatch(cmd, &store); assert_res_ok(res, &[10.into()], &[]); } #[test] fn hget_with_non_exist_key_should_return_404() { let store = MemTable::new(); let cmd = CommandRequest::new_hget("score", "u1"); let res = dispatch(cmd, &store); assert_res_error(res, 404, "Not found"); } #[test] fn hgetall_should_work() { let store = MemTable::new(); let cmds = vec![ CommandRequest::new_hset("score", "u1", 10.into()), CommandRequest::new_hset("score", "u2", 8.into()), CommandRequest::new_hset("score", "u3", 11.into()), CommandRequest::new_hset("score", "u1", 6.into()), ]; for cmd in cmds { dispatch(cmd, &store); } let cmd = CommandRequest::new_hgetall("score"); let res = dispatch(cmd, &store); let pairs = &[ Kvpair::new("u1", 6.into()), Kvpair::new("u2", 8.into()), Kvpair::new("u3", 11.into()), ]; assert_res_ok(res, &[], pairs); } // 从 Request 中得到 Response,目前处理 HGET/HGETALL/HSET fn dispatch(cmd: CommandRequest, store: &impl Storage) -> CommandResponse { match cmd.request_data.unwrap() { RequestData::Hget(v) => v.execute(store), RequestData::Hgetall(v) => v.execute(store), RequestData::Hset(v) => v.execute(store), _ => todo!(), } } // 测试成功返回的结果 fn assert_res_ok(mut res: CommandResponse, values: &[Value], pairs: &[Kvpair]) { res.pairs.sort_by(|a, b| a.partial_cmp(b).unwrap()); assert_eq!(res.status, 200); assert_eq!(res.message, ""); assert_eq!(res.values, values); assert_eq!(res.pairs, pairs); } // 测试失败返回的结果 fn assert_res_error(res: CommandResponse, code: u32, msg: &str) { assert_eq!(res.status, code); assert!(res.message.contains(msg)); assert_eq!(res.values, &[]); assert_eq!(res.pairs, &[]); } } }
这些测试的作用就是验证产品需求,比如:
- HSET 成功返回上一次的值(这和 Redis 略有不同,Redis 返回表示多少 key 受影响的一个整数)
- HGET 返回 Value
- HGETALL 返回一组无序的 Kvpair
目前这些测试是无法编译通过的,因为里面使用了一些未定义的方法,比如 10.into():想把整数 10 转换成一个 Value、CommandRequest::new_hgetall(“score”):想生成一个 HGETALL 命令。
为什么要这么写?因为如果是 CommandService 接口的使用者,自然希望使用这个接口的时候,调用的整体感觉非常简单明了。
如果接口期待一个 Value,但在上下文中拿到的是 10、“hello” 这样的值,那我们作为设计者就要考虑为 Value 实现 From
到现在为止我们写了两轮测试了,相信你对测试代码的作用有大概理解。我们来总结一下:
- 验证并帮助接口迭代
- 验证产品需求
- 通过使用核心逻辑,帮助我们更好地思考外围逻辑并反推其实现
前两点是最基本的,也是很多人对TDD的理解,其实还有更重要的也就是第三点。除了前面的辅助函数外,我们在测试代码中还看到了 dispatch 函数,它目前用来辅助测试。 但紧接着你会发现,这样的辅助函数,可以合并到核心代码中。这才是“测试驱动开发”的实质。
好,根据测试,我们需要在 src/pb/mod.rs 中添加相关的外围逻辑,首先是 CommandRequest 的一些方法,之前写了 new_hset,现在再加入 new_hget 和 new_hgetall:
#![allow(unused)] fn main() { impl CommandRequest { /// 创建 HGET 命令 pub fn new_hget(table: impl Into<String>, key: impl Into<String>) -> Self { Self { request_data: Some(RequestData::Hget(Hget { table: table.into(), key: key.into(), })), } } /// 创建 HGETALL 命令 pub fn new_hgetall(table: impl Into<String>) -> Self { Self { request_data: Some(RequestData::Hgetall(Hgetall { table: table.into(), })), } } /// 创建 HSET 命令 pub fn new_hset(table: impl Into<String>, key: impl Into<String>, value: Value) -> Self { Self { request_data: Some(RequestData::Hset(Hset { table: table.into(), pair: Some(Kvpair::new(key, value)), })), } } } }
然后写对 Value 的 From
#![allow(unused)] fn main() { /// 从 i64转换成 Value impl From<i64> for Value { fn from(i: i64) -> Self { Self { value: Some(value::Value::Integer(i)), } } } }
测试代码目前就可以编译通过了,然而测试显然会失败,因为还没有做具体的实现。我们在 src/service/command_service.rs 下添加 trait 的实现代码:
#![allow(unused)] fn main() { impl CommandService for Hget { fn execute(self, store: &impl Storage) -> CommandResponse { match store.get(&self.table, &self.key) { Ok(Some(v)) => v.into(), Ok(None) => KvError::NotFound(self.table, self.key).into(), Err(e) => e.into(), } } } impl CommandService for Hgetall { fn execute(self, store: &impl Storage) -> CommandResponse { match store.get_all(&self.table) { Ok(v) => v.into(), Err(e) => e.into(), } } } impl CommandService for Hset { fn execute(self, store: &impl Storage) -> CommandResponse { match self.pair { Some(v) => match store.set(&self.table, v.key, v.value.unwrap_or_default()) { Ok(Some(v)) => v.into(), Ok(None) => Value::default().into(), Err(e) => e.into(), }, None => Value::default().into(), } } } }
这自然会引发更多的编译错误,因为我们很多地方都是用了 into() 方法,却没有实现相应的转换,比如,Value 到 CommandResponse 的转换、KvError 到 CommandResponse 的转换、Vec
所以在 src/pb/mod.rs 里继续补上相应的外围逻辑:
#![allow(unused)] fn main() { /// 从 Value 转换成 CommandResponse impl From<Value> for CommandResponse { fn from(v: Value) -> Self { Self { status: StatusCode::OK.as_u16() as _, values: vec![v], ..Default::default() } } } /// 从 Vec<Kvpair> 转换成 CommandResponse impl From<Vec<Kvpair>> for CommandResponse { fn from(v: Vec<Kvpair>) -> Self { Self { status: StatusCode::OK.as_u16() as _, pairs: v, ..Default::default() } } } /// 从 KvError 转换成 CommandResponse impl From<KvError> for CommandResponse { fn from(e: KvError) -> Self { let mut result = Self { status: StatusCode::INTERNAL_SERVER_ERROR.as_u16() as _, message: e.to_string(), values: vec![], pairs: vec![], }; match e { KvError::NotFound(_, _) => result.status = StatusCode::NOT_FOUND.as_u16() as _, KvError::InvalidCommand(_) => result.status = StatusCode::BAD_REQUEST.as_u16() as _, _ => {} } result } } }
从前面写接口到这里具体实现,不知道你是否感受到了这样一种模式:在 Rust 下, 但凡出现两个数据结构 v1 到 v2 的转换,你都可以先以 v1.into() 来表示这个逻辑,继续往下写代码,之后再去补 From
你学完这节课可以再去回顾一下 第 6 讲,仔细思考一下当时说的“绝大多数处理逻辑都是把数据从一个接口转换成另一个接口”。
现在代码应该可以编译通过并测试通过了,你可以 cargo test 测试一下。
最后的拼图:Service 结构的实现
好,所有的接口,包括客户端/服务器的协议接口、Storage trait 和 CommandService trait 都验证好了,接下来就是考虑如何用一个数据结构把所有这些东西串联起来。
依旧从使用者的角度来看如何调用它。为此,我们在 src/service/mod.rs 里添加如下的测试代码:
#![allow(unused)] fn main() { #[cfg(test)] mod tests { use super::*; use crate::{MemTable, Value}; #[test] fn service_should_works() { // 我们需要一个 service 结构至少包含 Storage let service = Service::new(MemTable::default()); // service 可以运行在多线程环境下,它的 clone 应该是轻量级的 let cloned = service.clone(); // 创建一个线程,在 table t1 中写入 k1, v1 let handle = thread::spawn(move || { let res = cloned.execute(CommandRequest::new_hset("t1", "k1", "v1".into())); assert_res_ok(res, &[Value::default()], &[]); }); handle.join().unwrap(); // 在当前线程下读取 table t1 的 k1,应该返回 v1 let res = service.execute(CommandRequest::new_hget("t1", "k1")); assert_res_ok(res, &["v1".into()], &[]); } } #[cfg(test)] use crate::{Kvpair, Value}; // 测试成功返回的结果 #[cfg(test)] pub fn assert_res_ok(mut res: CommandResponse, values: &[Value], pairs: &[Kvpair]) { res.pairs.sort_by(|a, b| a.partial_cmp(b).unwrap()); assert_eq!(res.status, 200); assert_eq!(res.message, ""); assert_eq!(res.values, values); assert_eq!(res.pairs, pairs); } // 测试失败返回的结果 #[cfg(test)] pub fn assert_res_error(res: CommandResponse, code: u32, msg: &str) { assert_eq!(res.status, code); assert!(res.message.contains(msg)); assert_eq!(res.values, &[]); assert_eq!(res.pairs, &[]); } }
注意,这里的 assert_res_ok() 和 assert_res_error() 是从 src/service/command_service.rs 中挪过来的。 在开发的过程中,不光产品代码需要不断重构,测试代码也需要重构来贯彻 DRY 思想。
我见过很多生产环境的代码,产品功能部分还说得过去,但测试代码像是个粪坑,经年累月地 copy/paste 使其臭气熏天,每个开发者在添加新功能的时候,都掩着鼻子往里扔一坨走人,使得维护难度越来越高,每次需求变动,都涉及一大坨测试代码的变动,这样非常不好。
测试代码的质量也要和产品代码的质量同等要求。好的开发者写的测试代码的可读性也是非常强的。你可以对比上面写的三段测试代码多多感受。
在撰写测试的时候,我们要特别注意: 测试代码要围绕着系统稳定的部分,也就是接口,来测试,而尽可能少地测试实现。这是我对这么多年工作中血淋淋的教训的深刻总结。
因为产品代码和测试代码,两者总需要一个是相对稳定的,既然产品代码会不断地根据需求变动,测试代码就必然需要稳定一些。
那什么样的测试代码是稳定的?测试接口的代码是稳定的。只要接口不变,无论具体实现如何变化,哪怕今天引入一个新的算法,明天重写实现,测试代码依旧能够凛然不动,做好产品质量的看门狗。
好,我们回来写代码。在这段测试中,已经敲定了 Service 这个数据结构的使用蓝图,它可以跨线程,可以调用 execute 来执行某个 CommandRequest 命令,返回 CommandResponse。
根据这些想法,在 src/service/mod.rs 里添加 Service 的声明和实现:
#![allow(unused)] fn main() { /// Service 数据结构 pub struct Service<Store = MemTable> { inner: Arc<ServiceInner<Store>>, } impl<Store> Clone for Service<Store> { fn clone(&self) -> Self { Self { inner: Arc::clone(&self.inner), } } } /// Service 内部数据结构 pub struct ServiceInner<Store> { store: Store, } impl<Store: Storage> Service<Store> { pub fn new(store: Store) -> Self { Self { inner: Arc::new(ServiceInner { store }), } } pub fn execute(&self, cmd: CommandRequest) -> CommandResponse { debug!("Got request: {:?}", cmd); // TODO: 发送 on_received 事件 let res = dispatch(cmd, &self.inner.store); debug!("Executed response: {:?}", res); // TODO: 发送 on_executed 事件 res } } // 从 Request 中得到 Response,目前处理 HGET/HGETALL/HSET pub fn dispatch(cmd: CommandRequest, store: &impl Storage) -> CommandResponse { match cmd.request_data { Some(RequestData::Hget(param)) => param.execute(store), Some(RequestData::Hgetall(param)) => param.execute(store), Some(RequestData::Hset(param)) => param.execute(store), None => KvError::InvalidCommand("Request has no data".into()).into(), _ => KvError::Internal("Not implemented".into()).into(), } } }
这段代码有几个地方值得注意:
- 首先 Service 结构内部有一个 ServiceInner 存放实际的数据结构,Service 只是用 Arc 包裹了 ServiceInner。这也是 Rust 的一个惯例,把需要在多线程下 clone 的主体和其内部结构分开,这样代码逻辑更加清晰。
- execute() 方法目前就是调用了 dispatch,但它未来潜在可以做一些事件分发。这样处理体现了 SRP(Single Responsibility Principle)原则。
- dispatch 其实就是把测试代码的 dispatch 逻辑移动过来改动了一下。
再一次,我们重构了测试代码,把它的辅助函数变成了产品代码的一部分。现在,你可以运行 cargo test 测试一下,如果代码无法编译,可能是缺一些 use 代码,比如:
#![allow(unused)] fn main() { use crate::{ command_request::RequestData, CommandRequest, CommandResponse, KvError, MemTable, Storage, }; use std::sync::Arc; use tracing::debug; }
新的 server
现在处理逻辑已经都完成了,可以写个新的 example 测试服务器代码。
把之前的 examples/dummy_server.rs 复制一份,成为 examples/server.rs,然后引入 Service,主要的改动就三句:
#![allow(unused)] fn main() { // main 函数开头,初始化 service let service: Service = Service::new(MemTable::new()); // tokio::spawn 之前,复制一份 service let svc = service.clone(); // while loop 中,使用 svc 来执行 cmd let res = svc.execute(cmd); }
你可以试着自己修改。完整的代码如下:
use anyhow::Result; use async_prost::AsyncProstStream; use futures::prelude::*; use kv::{CommandRequest, CommandResponse, MemTable, Service}; use tokio::net::TcpListener; use tracing::info; #[tokio::main] async fn main() -> Result<()> { tracing_subscriber::fmt::init(); let service: Service = Service::new(MemTable::new()); let addr = "127.0.0.1:9527"; let listener = TcpListener::bind(addr).await?; info!("Start listening on {}", addr); loop { let (stream, addr) = listener.accept().await?; info!("Client {:?} connected", addr); let svc = service.clone(); tokio::spawn(async move { let mut stream = AsyncProstStream::<_, CommandRequest, CommandResponse, _>::from(stream).for_async(); while let Some(Ok(cmd)) = stream.next().await { let res = svc.execute(cmd); stream.send(res).await.unwrap(); } info!("Client {:?} disconnected", addr); }); } }
完成之后,打开一个命令行窗口,运行: RUST_LOG=info cargo run --example server --quiet,然后在另一个命令行窗口,运行: RUST_LOG=info cargo run --example client --quiet。此时,服务器和客户端都收到了彼此的请求和响应,并且处理正常。
我们的 KV server 第一版的基本功能就完工了!当然,目前还只处理了 3 个命令,剩下 6 个需要你自己完成。
小结
KV server 并不是一个很难的项目,但想要把它写好,并不简单。如果你跟着讲解一步步走下来,可以感受到一个有潜在生产环境质量的 Rust 项目应该如何开发。在这上下两讲内容中,有两点我们一定要认真领会。
第一点,你要对需求有一个清晰的把握,找出其中不稳定的部分(variant)和比较稳定的部分(invariant)。在 KV server 中,不稳定的部分是,对各种新的命令的支持,以及对不同的 storage 的支持。 所以需要构建接口来消弭不稳定的因素,让不稳定的部分可以用一种稳定的方式来管理。
第二点,代码和测试可以围绕着接口螺旋前进,使用 TDD 可以帮助我们进行这种螺旋式的迭代。 在一个设计良好的系统中:接口是稳定的,测试接口的代码是稳定的,实现可以是不稳定的。在迭代开发的过程中,我们要不断地重构,让测试代码和产品代码都往最优的方向发展。
纵观我们写的 KV server,包括测试在内,你很难发现有函数或者方法超过 50 行,代码可读性非常强,几乎不需要注释,就可以理解。另外因为都是用接口做的交互,未来维护和添加新的功能,也基本上满足 OCP 原则,除了 dispatch 函数需要很小的修改外,其它新的代码都是在实现一些接口而已。
相信你能初步感受到在 Rust 下撰写代码的最佳实践。如果你之前用其他语言,已经采用了类似的最佳实践,那么可以感受一下同样的实践在 Rust 下使用的那种优雅;如果你之前由于种种原因,写的是类似之前意大利面条似的代码,那在开发 Rust 程序时,你可以试着接纳这种更优雅的开发方式。
毕竟,现在我们手中有了更先进的武器,就可以用更先进的打法。
思考题
- 为剩下 6 个命令 HMGET、HMSET、HDEL、HMDEL、HEXIST、HMEXIST 构建测试,并实现它们。在测试和实现过程中,你也许需要添加更多的 From
的实现。 - 如果有余力,可以试着实现 MemTable 的 get_iter() 方法(后续的 KV Store 实现会讲)。
延伸思考
虽然我们的 KV server 使用了 concurrent hashmap 来处理并发,但这并不一定是最好的选择。
我们也可以创建一个线程池,每个线程有自己的 HashMap。当 HGET/HSET 等命令来临时,可以对 key 做个哈希,然后分派到 “拥有” 那个 key 的线程,这样,可以避免在处理的时候加锁,提高系统的吞吐。你可以想想如果用这种方式处理,该怎么做。
恭喜你完成了学习的第22次打卡。如果你觉得有收获,也欢迎你分享给身边的朋友,邀他一起讨论。我们下一讲期中测试见~
加餐|期中测试:来写一个简单的grep命令行
你好,我是陈天。
现在 Rust 基础篇已经学完了,相信你已经有足够的信心去应对一些简单的开发任务。今天我们就来个期中测试,实际考察一下你对 Rust 语言的理解以及对所学知识的应用情况。
我们要做的小工具是 rgrep,它是一个类似 grep 的工具。如果你是一个 *nix 用户,那大概率使用过 grep 或者 ag 这样的文本查找工具。
grep 命令用于查找文件里符合条件的字符串。如果发现某个文件的内容符合所指定的字符串,grep 命令会把含有字符串的那一行显示出;若不指定任何文件名称,或是所给予的文件名为 -,grep 命令会从标准输入设备读取数据。
我们的 rgrep 要稍微简单一些,它可以支持以下三种使用场景:
首先是最简单的,给定一个字符串以及一个文件,打印出文件中所有包含该字符串的行:
$ rgrep Hello a.txt
55: Hello world. This is an exmaple text
然后放宽限制,允许用户提供一个正则表达式,来查找文件中所有包含该字符串的行:
$ rgrep Hel[^\\s]+ a.txt
55: Hello world. This is an exmaple text
89: Help me! I need assistant!
如果这个也可以实现,那进一步放宽限制,允许用户提供一个正则表达式,来查找满足文件通配符的所有文件(你可以使用 globset 或者 glob 来处理通配符),比如:
$ rgrep Hel[^\\s]+ a*.txt
a.txt
55:1 Hello world. This is an exmaple text
89:1 Help me! I need assistant!
5:6 Use `Help` to get help.
abc.txt:
100:1 Hello Tyr!
其中,冒号前面的数字是行号,后面的数字是字符在这一行的位置。
给你一点小提示。
- 对于命令行的部分,你可以使用 clap3 或者 structopt,也可以就用 env.args()。
- 对于正则表达式的支持,可以使用 regex。
- 至于文件的读取,可以使用 std::fs 或者 tokio::fs。你可以顺序对所有满足通配符的文件进行处理,也可以用 rayon 或者 tokio 来并行处理。
- 对于输出的结果,最好能把匹配的文字用不同颜色展示。

如果你有余力,可以看看 grep 的文档,尝试实现更多的功能。
祝你好运!
加油,我们下节课作业讲解见。
加餐|期中测试:参考实现讲解
你好,我是陈天。
上一讲给你布置了一份简单的期中考试习题,不知道你完成的怎么样。今天我们来简单讲一讲实现,供你参考。
支持 grep 并不是一件复杂的事情,相信你在使用了 clap、glob、rayon 和 regex 后,都能写出类似的代码(伪代码):
#![allow(unused)] fn main() { /// Yet another simplified grep built with Rust. #[derive(Clap, Debug)] #[clap(version = "1.0", author = "Tyr Chen <tyr@chen.com>")] #[clap(setting = AppSettings::ColoredHelp)] pub struct GrepConfig { /// regex pattern to match against file contents pattern: String, /// Glob of file pattern glob: String, } impl GrepConfig { pub fn matches(&self) -> Result<()> { let regex = Regex::new(&self.pattern)?; let files: Vec<_> = glob::glob(&self.glob)?.collect(); files.into_par_iter().for_each(|v| { if let Ok(filename) = v { if let Ok(file) = File::open(&filename) { let reader = BufReader::new(file); |- for (lineno, line) in reader.lines().enumerate() { | if let Ok(line) = line { | if let Some(_) = pattern.find(&line) { | println!("{}: {}", lineno + 1, &line); | } | } |- } } } }); Ok(()) } } }
这个代码撰写的感觉和 Python 差不多,除了阅读几个依赖花些时间外,几乎没有难度。
不过,这个代码不具备可测试性,会给以后的维护和扩展带来麻烦。我们来看看如何优化,使这段代码更加容易测试。
如何写出好实现
首先,我们要剥离主要逻辑。
主要逻辑是什么?自然是对于单个文件的 grep,也就是代码中标记的部分。我们可以将它抽离成一个函数:
#![allow(unused)] fn main() { fn process(reader: BufReader<File>) }
当然,从接口的角度来说,这个 process 函数定义得太死,如果不是从 File 中取数据,改天需求变了,也需要支持从 stdio 中取数据呢?就需要改动这个接口了。
所以可以 使用泛型:
#![allow(unused)] fn main() { fn process<R: Read>(reader: BufReader<R>) }
泛型参数 R 只需要满足 std::io::Read trait 就可以。
这个接口虽然抽取出来了,但它依旧不可测,因为它内部直接 println!,把找到的数据直接打印出来了。我们当然可以把要打印的行放入一个 Vec
不过,这是为了测试而测试, 更好的方式是把输出的对象从 Stdout 抽象成 Write。现在 process 的接口变为:
#![allow(unused)] fn main() { fn process<R: Read, W: Write>(reader: BufReader<R>, writer: &mut Writer) }
这样,我们就可以使用实现了 Read trait 的 &[u8] 作为输入,以及使用实现了 Write trait 的 Vec
好,有了这个思路,来看看我是怎么写这个 rgrep 的,供你参考。
首先 cargo new rgrep 创建一个新的项目。在 Cargo.toml 中,添加如下依赖:
#![allow(unused)] fn main() { [dependencies] anyhow = "1" clap = "3.0.0-beta.4" # 我们需要使用最新的 3.0.0-beta.4 或者更高版本 colored = "2" glob = "0.3" itertools = "0.10" rayon = "1" regex = "1" thiserror = "1" }
对于处理命令行的 clap,我们需要 3.0 的版本。不要在意 VS Code 插件提示你最新版本是 2.33,那是因为 beta 不算正式版本。
然后创建 src/lib.rs 和 src/error.rs,在 error.rs 中添加一些错误定义:
#![allow(unused)] fn main() { use thiserror::Error; #[derive(Error, Debug)] pub enum GrepError { #[error("Glob pattern error")] GlobPatternError(#[from] glob::PatternError), #[error("Regex pattern error")] RegexPatternError(#[from] regex::Error), #[error("I/O error")] IoError(#[from] std::io::Error), } }
它们都是需要进行转换的错误。thiserror 能够通过宏帮我们完成错误类型的转换。
在 src/lib.rs 中,添入如下代码:
#![allow(unused)] fn main() { use clap::{AppSettings, Clap}; use colored::*; use itertools::Itertools; use rayon::iter::{IntoParallelIterator, ParallelIterator}; use regex::Regex; use std::{ fs::File, io::{self, BufRead, BufReader, Read, Stdout, Write}, ops::Range, path::Path, }; mod error; pub use error::GrepError; /// 定义类型,这样,在使用时可以简化复杂类型的书写 pub type StrategyFn<W, R> = fn(&Path, BufReader<R>, &Regex, &mut W) -> Result<(), GrepError>; /// 简化版本的 grep,支持正则表达式和文件通配符 #[derive(Clap, Debug)] #[clap(version = "1.0", author = "Tyr Chen <tyr@chen.com>")] #[clap(setting = AppSettings::ColoredHelp)] pub struct GrepConfig { /// 用于查找的正则表达式 pattern: String, /// 文件通配符 glob: String, } impl GrepConfig { /// 使用缺省策略来查找匹配 pub fn match_with_default_strategy(&self) -> Result<(), GrepError> { self.match_with(default_strategy) } /// 使用某个策略函数来查找匹配 pub fn match_with(&self, strategy: StrategyFn<Stdout, File>) -> Result<(), GrepError> { let regex = Regex::new(&self.pattern)?; // 生成所有符合通配符的文件列表 let files: Vec<_> = glob::glob(&self.glob)?.collect(); // 并行处理所有文件 files.into_par_iter().for_each(|v| { if let Ok(filename) = v { if let Ok(file) = File::open(&filename) { let reader = BufReader::new(file); let mut stdout = io::stdout(); if let Err(e) = strategy(filename.as_path(), reader, ®ex, &mut stdout) { println!("Internal error: {:?}", e); } } } }); Ok(()) } } /// 缺省策略,从头到尾串行查找,最后输出到 writer pub fn default_strategy<W: Write, R: Read>( path: &Path, reader: BufReader<R>, pattern: &Regex, writer: &mut W, ) -> Result<(), GrepError> { let matches: String = reader .lines() .enumerate() .map(|(lineno, line)| { line.ok() .map(|line| { pattern .find(&line) .map(|m| format_line(&line, lineno + 1, m.range())) }) .flatten() }) .filter_map(|v| v.ok_or(()).ok()) .join("\n"); if !matches.is_empty() { writer.write(path.display().to_string().green().as_bytes())?; writer.write(b"\n")?; writer.write(matches.as_bytes())?; writer.write(b"\n")?; } Ok(()) } /// 格式化输出匹配的行,包含行号、列号和带有高亮的第一个匹配项 pub fn format_line(line: &str, lineno: usize, range: Range<usize>) -> String { let Range { start, end } = range; let prefix = &line[..start]; format!( "{0: >6}:{1: <3} {2}{3}{4}", lineno.to_string().blue(), // 找到匹配项的起始位置,注意对汉字等非 ascii 字符,我们不能使用 prefix.len() // 这是一个 O(n) 的操作,会拖累效率,这里只是为了演示的效果 (prefix.chars().count() + 1).to_string().cyan(), prefix, &line[start..end].red(), &line[end..] ) } }
和刚才的思路稍有不同的是,process 函数叫 default_strategy()。另外我们 为 GrepConfig 提供了两个方法,一个是 match_with_default_strategy(),另一个是 match_with(),调用者可以自己传入一个函数或者闭包,对给定的 BufReader 进行处理。这是一种常用的解耦的处理方法。
在 src/lib.rs 里,继续撰写单元测试:
#![allow(unused)] fn main() { #[cfg(test)] mod tests { use super::*; #[test] fn format_line_should_work() { let result = format_line("Hello, Tyr~", 1000, 7..10); let expected = format!( "{0: >6}:{1: <3} Hello, {2}~", "1000".blue(), "7".cyan(), "Tyr".red() ); assert_eq!(result, expected); } #[test] fn default_strategy_should_work() { let path = Path::new("src/main.rs"); let input = b"hello world!\nhey Tyr!"; let reader = BufReader::new(&input[..]); let pattern = Regex::new(r"he\\w+").unwrap(); let mut writer = Vec::new(); default_strategy(path, reader, &pattern, &mut writer).unwrap(); let result = String::from_utf8(writer).unwrap(); let expected = [ String::from("src/main.rs"), format_line("hello world!", 1, 0..5), format_line("hey Tyr!\n", 2, 0..3), ]; assert_eq!(result, expected.join("\n")); } } }
你可以重点关注测试是如何使用 default_strategy() 函数,而 match_with() 方法又是如何使用它的。运行 cargo test,两个测试都能通过。
最后,在 src/main.rs 中添加命令行处理逻辑:
use anyhow::Result; use clap::Clap; use rgrep::*; fn main() -> Result<()> { let config: GrepConfig = GrepConfig::parse(); config.match_with_default_strategy()?; Ok(()) }
在命令行下运行: cargo run --quiet -- "Re[^\\s]+" "src/*.rs" ,会得到类似如下输出。注意,文件输出的顺序可能不完全一样,因为 rayon 是多个线程并行执行的。
小结
rgrep 是一个简单的命令行工具,仅仅写了上百行代码,就完成了一个性能相当不错的简化版 grep。在不做复杂的接口设计时,我们可以不用生命周期,不用泛型,甚至不用太关心所有权,就可以写出非常类似脚本语言的代码。
从这个意义上讲, Rust 用来做一次性的、即用即抛型的代码,或者说,写个快速原型,也有用武之地;当我们需要更好的代码质量、更高的抽象度、更灵活的设计时,Rust 提供了足够多的工具,让我们将原型进化成更成熟的代码。
相信在做 rgrep 的过程中,你能感受到用 Rust 开发软件的愉悦。
今天我们就不布置思考题了,你可以多多体会KV server和rgrep工具的实现。恭喜你完成了Rust基础篇的学习,进度条过半,我们下节课进阶篇见。
欢迎你分享给身边的朋友,邀他一起讨论。
延伸阅读
在 YouTube 上,有一个新鲜出炉的视频: Visualizing memory layout of Rust’s data types,用 40 分钟的时间,总结了我们前面基础篇二十讲里提到的主要数据结构的内存布局。我个人非常喜欢这个视频,因为它和我一直倡导的“厘清数据是如何在堆和栈上存储”的思路不谋而合,在这里也推荐给你。如果你想快速复习一下,查漏补缺,那么非常建议你花上一个小时时间仔细看一下这个视频。
类型系统:如何在实战中使用泛型编程?
你好,我是陈天。
从这一讲开始,我们就到进阶篇了。在进阶篇中,我们会先进一步夯实对类型系统的理解,然后再展开网络处理、Unsafe Rust、FFI 等主题。
为什么要把类型系统作为进阶篇的基石?之前讲解 rgrep 的代码时你可以看到,当要构建可读性更强、更加灵活、更加可测试的系统时,我们都要或多或少使用 trait 和泛型编程。
所以可以说在 Rust 开发中,泛型编程是我们必须掌握的一项技能。在你构建每一个数据结构或者函数时,最好都问问自己:我是否有必要在此刻就把类型定死?是不是可以把这个决策延迟到尽可能靠后的时刻,这样可以为未来留有余地?
在《架构整洁之道》里 Uncle Bob 说: 架构师的工作不是作出决策,而是尽可能久地推迟决策,在现在不作出重大决策的情况下构建程序,以便以后有足够信息时再作出决策。所以,如果我们能通过泛型来推迟决策,系统的架构就可以足够灵活,可以更好地面对未来的变更。
今天,我们就来讲讲如何在实战中使用泛型编程,来延迟决策。如果你对 Rust 的泛型编程掌握地还不够牢靠,建议再温习一下第 12 和 13 讲,也可以阅读 The Rust Programming Language 第 10 章 作为辅助。
泛型数据结构的逐步约束
在进入正题之前,我们以标准库的 BufReader 结构为例,先简单回顾一下,在定义数据结构和实现数据结构时,如果使用了泛型参数,到底有什么样的好处。
看这个定义的小例子:
#![allow(unused)] fn main() { pub struct BufReader<R> { inner: R, buf: Box<[u8]>, pos: usize, cap: usize, } }
BufReader 对要读取的 R 做了一个泛型的抽象。也就是说,R 此刻是个 File,还是一个 Cursor,或者直接是 Vec
到了实现阶段,根据不同的需求,我们可以为 R 做不同的限制。这个限制需要细致到什么程度呢?只需要添加刚好满足实现需要的限制即可。
比如在提供 capacity()、buffer() 这些不需要使用 R 的任何特殊能力的时候,可以 不做任何限制:
#![allow(unused)] fn main() { impl<R> BufReader<R> { pub fn capacity(&self) -> usize { ... } pub fn buffer(&self) -> &[u8] { ... } } }
但在实现 new() 的时候,因为使用了 Read trait 里的方法,所以这时需要明确传进来的 R 满足 Read 约束:
#![allow(unused)] fn main() { impl<R: Read> BufReader<R> { pub fn new(inner: R) -> BufReader<R> { ... } pub fn with_capacity(capacity: usize, inner: R) -> BufReader<R> { ... } } }
同样,在实现 Debug 时,也可以要求 R 满足 Debug trait 的约束:
#![allow(unused)] fn main() { impl<R> fmt::Debug for BufReader<R> where R: fmt::Debug { fn fmt(&self, fmt: &mut fmt::Formatter<'_>) -> fmt::Result { ... } } }
如果你多花一些时间,把 bufreader.rs 对接口的所有实现都过一遍,还会发现 BufReader 在实现过程中使用了 Seek trait。
整体而言,impl BufReader 的代码根据不同的约束,分成了不同的代码块。这是一种非常典型的实现泛型代码的方式,我们可以学习起来,在自己的代码中也应用这种方法。
通过使用泛型参数,BufReader 把决策交给使用者。我们在上一讲期中考试的 rgrep 实现中也看到了,在测试和 rgrep 的实现代码中,是如何为 BufReader 提供不同的类型来满足不同的使用场景的。
泛型参数的三种使用场景
泛型参数的使用和逐步约束就简单复习到这里,相信你已经掌握得比较好了,我们开始今天的重头戏,来学习实战中如何使用泛型编程。
先看泛型参数,它有三种常见的使用场景:
- 使用泛型参数延迟数据结构的绑定;
- 使用泛型参数和 PhantomData,声明数据结构中不直接使用,但在实现过程中需要用到的类型;
- 使用泛型参数让同一个数据结构对同一个 trait 可以拥有不同的实现。
用泛型参数做延迟绑定
先来看我们已经比较熟悉的,用泛型参数做延迟绑定。在 KV server 的 上篇 中,我构建了一个 Service 数据结构:
#![allow(unused)] fn main() { /// Service 数据结构 pub struct Service<Store = MemTable> { inner: Arc<ServiceInner<Store>>, } }
它使用了一个泛型参数 Store,并且这个泛型参数有一个缺省值 MemTable。指定了泛型参数缺省值的好处是,在使用时,可以不必提供泛型参数,直接使用缺省值。这个泛型参数在随后的实现中可以被逐渐约束:
#![allow(unused)] fn main() { impl<Store> Service<Store> { pub fn new(store: Store) -> Self { ... } } impl<Store: Storage> Service<Store> { pub fn execute(&self, cmd: CommandRequest) -> CommandResponse { ... } } }
同样的,在泛型函数中,可以使用 impl Storage 或者 <Store: Storage> 的方式去约束:
#![allow(unused)] fn main() { pub fn dispatch(cmd: CommandRequest, store: &impl Storage) -> CommandResponse { ... } // 等价于 pub fn dispatch<Store: Storage>(cmd: CommandRequest, store: &Store) -> CommandResponse { ... } }
这种用法,想必你现在已经非常熟悉了,可以在开发中使用泛型参数来对类型进行延迟绑定。
使用泛型参数和幽灵数据(PhantomData)提供额外类型
在熟悉了泛型参数的基本用法后,我来考考你:现在要设计一个 User 和 Product 数据结构,它们都有一个 u64 类型的 id。然而我希望每个数据结构的 id 只能和同种类型的 id 比较,也就是说如果 user.id 和 product.id 比较,编译器就能直接报错,拒绝这种行为。该怎么做呢?
你可以停下来先想一想。
很可能会立刻想到这个办法。先用一个自定义的数据结构 Identifier
#![allow(unused)] fn main() { pub struct Identifier<T> { inner: u64, } }
然后,在 User 和 Product 中,各自用 Identifier
#![allow(unused)] fn main() { #[derive(Debug, Default, PartialEq, Eq)] pub struct Identifier<T> { inner: u64, } #[derive(Debug, Default, PartialEq, Eq)] pub struct User { id: Identifier<Self>, } #[derive(Debug, Default, PartialEq, Eq)] pub struct Product { id: Identifier<Self>, } #[cfg(test)] mod tests { use super::*; #[test] fn id_should_not_be_the_same() { let user = User::default(); let product = Product::default(); // 两个 id 不能比较,因为他们属于不同的类型 // assert_ne!(user.id, product.id); assert_eq!(user.id.inner, product.id.inner); } } }
然而它无法编译通过。为什么呢?
因为 Identifier
别急。如果你使用过任何其他支持泛型的语言,无论是 Java、Swift 还是 TypeScript,可能都接触过 Phantom Type(幽灵类型) 的概念。像刚才的写法,Swift / TypeScript 会让其通过,因为它们的编译器会自动把多余的泛型参数当成 Phantom type 来用,比如下面 TypeScript 的例子,可以编译:
// NotUsed is allowed
class MyNumber<T, NotUsed> {
inner: T;
add: (x: T, y: T) => T;
}
但 Rust 对此有洁癖。Rust 并不希望在定义类型时,出现目前还没使用,但未来会被使用的泛型参数,所以 Rust 编译器对此无情拒绝,把门关得严严实实。
不过,别担心,作为过来人,Rust 知道 Phantom Type 的必要性,所以开了一扇叫 PhantomData 的窗户:让我们可以用 PhantomData 来持有 Phantom Type。PhantomData 中文一般翻译成幽灵数据,这名字透着一股让人不敢亲近的邪魅,但它 被广泛用在处理,数据结构定义过程中不需要,但是在实现过程中需要的泛型参数。
我们来试一下:
#![allow(unused)] fn main() { use std::marker::PhantomData; #[derive(Debug, Default, PartialEq, Eq)] pub struct Identifier<T> { inner: u64, _tag: PhantomData<T>, } #[derive(Debug, Default, PartialEq, Eq)] pub struct User { id: Identifier<Self>, } #[derive(Debug, Default, PartialEq, Eq)] pub struct Product { id: Identifier<Self>, } #[cfg(test)] mod tests { use super::*; #[test] fn id_should_not_be_the_same() { let user = User::default(); let product = Product::default(); // 两个 id 不能比较,因为他们属于不同的类型 // assert_ne!(user.id, product.id); assert_eq!(user.id.inner, product.id.inner); } } }
Bingo!编译通过!在使用了 PhantomData 后,编译器允许泛型参数 T 的存在。
现在我们确认了: 在定义数据结构时,对于额外的、暂时不需要的泛型参数,用 PhantomData 来“拥有”它们,这样可以规避编译器的报错。PhantomData 正如其名,它实际上长度为零,是个 ZST(Zero-Sized Type),就像不存在一样,唯一作用就是类型的标记。
再来写一个例子,加深对 PhantomData 的理解( 代码):
#![allow(unused)] fn main() { use std::{ marker::PhantomData, sync::atomic::{AtomicU64, Ordering}, }; static NEXT_ID: AtomicU64 = AtomicU64::new(1); pub struct Customer<T> { id: u64, name: String, _type: PhantomData<T>, } pub trait Free { fn feature1(&self); fn feature2(&self); } pub trait Personal: Free { fn advance_feature(&self); } impl<T> Free for Customer<T> { fn feature1(&self) { println!("feature 1 for {}", self.name); } fn feature2(&self) { println!("feature 2 for {}", self.name); } } impl Personal for Customer<PersonalPlan> { fn advance_feature(&self) { println!( "Dear {}(as our valuable customer {}), enjoy this advanced feature!", self.name, self.id ); } } pub struct FreePlan; pub struct PersonalPlan(f32); impl<T> Customer<T> { pub fn new(name: String) -> Self { Self { id: NEXT_ID.fetch_add(1, Ordering::Relaxed), name, _type: PhantomData::default(), } } } impl From<Customer<FreePlan>> for Customer<PersonalPlan> { fn from(c: Customer<FreePlan>) -> Self { Self::new(c.name) } } /// 订阅成为付费用户 pub fn subscribe(customer: Customer<FreePlan>, payment: f32) -> Customer<PersonalPlan> { let _plan = PersonalPlan(payment); // 存储 plan 到 DB // ... customer.into() } #[cfg(test)] mod tests { use super::*; #[test] fn test_customer() { // 一开始是个免费用户 let customer = Customer::<FreePlan>::new("Tyr".into()); // 使用免费 feature customer.feature1(); customer.feature2(); // 用着用着觉得产品不错愿意付费 let customer = subscribe(customer, 6.99); customer.feature1(); customer.feature1(); // 付费用户解锁了新技能 customer.advance_feature(); } } }
在这个例子里,Customer 有个额外的类型 T。
通过类型 T,我们可以将用户分成不同的等级,比如免费用户是 Customer
使用泛型参数来提供多个实现
用泛型参数做延迟绑定、结合PhantomData来提供额外类型,是我们经常能看到的泛型参数的用法。
有时候,对于同一个 trait,我们想要有不同的实现,该怎么办?比如一个方程,它可以是线性方程,也可以是二次方程,我们希望为不同的类型实现不同 Iterator。可以这样做( 代码):
#![allow(unused)] fn main() { use std::marker::PhantomData; #[derive(Debug, Default)] pub struct Equation<IterMethod> { current: u32, _method: PhantomData<IterMethod>, } // 线性增长 #[derive(Debug, Default)] pub struct Linear; // 二次增长 #[derive(Debug, Default)] pub struct Quadratic; impl Iterator for Equation<Linear> { type Item = u32; fn next(&mut self) -> Option<Self::Item> { self.current += 1; if self.current >= u32::MAX { return None; } Some(self.current) } } impl Iterator for Equation<Quadratic> { type Item = u32; fn next(&mut self) -> Option<Self::Item> { self.current += 1; if self.current >= u16::MAX as u32 { return None; } Some(self.current * self.current) } } #[cfg(test)] mod tests { use super::*; #[test] fn test_linear() { let mut equation = Equation::<Linear>::default(); assert_eq!(Some(1), equation.next()); assert_eq!(Some(2), equation.next()); assert_eq!(Some(3), equation.next()); } #[test] fn test_quadratic() { let mut equation = Equation::<Quadratic>::default(); assert_eq!(Some(1), equation.next()); assert_eq!(Some(4), equation.next()); assert_eq!(Some(9), equation.next()); } } }
这个代码很好理解,但你可能会有疑问:这样做有什么好处么?为什么不构建两个数据结构 LinearEquation 和 QuadraticEquation,分别实现 Iterator 呢?
的确,对于这个例子,使用泛型的意义并不大,因为 Equation 自身没有很多共享的代码。但如果 Equation,只除了实现 Iterator 的逻辑不一样,其它大量的代码都是相同的,并且未来除了一次方程和二次方程,还会支持三次、四次……,那么, 用泛型数据结构来统一相同的逻辑,用泛型参数的具体类型来处理变化的逻辑,就非常有必要了。
来看一个真实存在的例子 AsyncProstReader,它来自之前我们在 KV server 里用过的 async-prost 库。async-prost 库,可以把 TCP 或者其他协议中的 stream 里传输的数据,分成一个个 frame 处理。其中的 AsyncProstReader 为 AsyncDestination 和 AsyncFrameDestination 提供了不同的实现,你可以不用关心它具体做了些什么,只要学习它的接口的设计:
#![allow(unused)] fn main() { /// A marker that indicates that the wrapping type is compatible with `AsyncProstReader` with Prost support. #[derive(Debug)] pub struct AsyncDestination; /// a marker that indicates that the wrapper type is compatible with `AsyncProstReader` with Framed support. #[derive(Debug)] pub struct AsyncFrameDestination; /// A wrapper around an async reader that produces an asynchronous stream of prost-decoded values #[derive(Debug)] pub struct AsyncProstReader<R, T, D> { reader: R, pub(crate) buffer: BytesMut, into: PhantomData<T>, dest: PhantomData<D>, } }
这个数据结构虽然使用了三个泛型参数,其实数据结构中真正用到的只有一个 R,它可以是一个实现了 AsyncRead 的数据结构(稍后会看到)。 另外两个泛型参数 T 和 D,在数据结构定义的时候其实并不需要,只是在数据结构的实现过程中,才需要用到它们的约束。其中,
- T 是从 R 中读取出的数据反序列化出来的类型,在实现时用 prost::Message 约束。
- D 是一个类型占位符,它会根据需要被具体化为 AsyncDestination 或者 AsyncFrameDestination。
类型参数 D 如何使用,我们可以先想像一下。实现 AsyncProstReader 的时候,我们希望在使用 AsyncDestination 时,提供一种实现,而在使用 AsyncFrameDestination 时,提供另一种实现。也就是说,这里的类型参数 D,在 impl 的时候,会被具体化成某个类型。
拿着这个想法,来看 AsyncProstReader 在实现 Stream 时,D 是如何具体化的。这里你不用关心 Stream 具体是什么以及如何实现。实现的代码不重要,重要的是接口( 代码):
#![allow(unused)] fn main() { impl<R, T> Stream for AsyncProstReader<R, T, AsyncDestination> where T: Message + Default, R: AsyncRead + Unpin, { type Item = Result<T, io::Error>; fn poll_next(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Option<Self::Item>> { ... } } }
再看对另外一个对 D 的具体实现:
#![allow(unused)] fn main() { impl<R, T> Stream for AsyncProstReader<R, T, AsyncFrameDestination> where R: AsyncRead + Unpin, T: Framed + Default, { type Item = Result<T, io::Error>; fn poll_next(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Option<Self::Item>> { ... } } }
在这个例子里,除了 Stream 的实现不同外,AsyncProstReader 的其它实现都是共享的。所以我们有必要为其增加一个泛型参数 D,使其可以根据不同的 D 的类型,来提供不同的 Stream 实现。
AsyncProstReader 综合使用了泛型的三种用法,感兴趣的话你可以看源代码。如果你无法一下子领悟它的代码,也不必担心。很多时候,这样的高级技巧在阅读代码时用途会更大一些,起码你能搞明白别人的代码为什么这么写。至于自己写的时候是否要这么用,你可以根据自己掌握的程度来决定。
毕竟, 我们写代码的首要目标是正确地实现所需要的功能,在正确性的前提下,优雅简洁的表达才有意义。
泛型函数的高级技巧
如果你掌握了泛型数据结构的基本使用方法,那么泛型函数并不复杂,因为在使用泛型参数和对泛型参数进行约束方面是一致的。
之前的课程中,我们已经在函数参数中多次使用泛型参数了,想必你已经有足够的掌握。关于泛型函数,我们讲两点,一是返回值如果想返回泛型参数,该怎么处理?二是对于复杂的泛型参数,该如何声明?
返回值携带泛型参数怎么办?
在 KV server 中,构建 Storage trait 的 get_iter 接口时,我们已经见到了这样的用法:
#![allow(unused)] fn main() { pub trait Storage { ... /// 遍历 HashTable,返回 kv pair 的 Iterator fn get_iter(&self, table: &str) -> Result<Box<dyn Iterator<Item = Kvpair>>, KvError>; } }
对于 get_iter() 方法,并不关心返回值是一个什么样的 Iterator,只要它能够允许我们不断调用 next() 方法,获得一个 Kvpair 的结构,就可以了。在实现里,使用了 trait object。
你也许会有疑惑,为什么不能直接使用 impl Iterator 呢?
// 目前 trait 还不支持
fn get_iter(&self, table: &str) -> Result<impl Iterator<Item = Kvpair>, KvError>;
原因是 Rust 目前还不支持在 trait 里使用 impl trait 做返回值:
#![allow(unused)] fn main() { pub trait ImplTrait { // 允许 fn impl_in_args(s: impl Into<String>) -> String { s.into() } // 不允许 fn impl_as_return(s: String) -> impl Into<String> { s } } }
那么使用泛型参数做返回值呢?可以,但是在实现的时候会很麻烦,你很难在函数中正确构造一个返回泛型参数的语句:
#![allow(unused)] fn main() { // 可以正确编译 pub fn generics_as_return_working(i: u32) -> impl Iterator<Item = u32> { std::iter::once(i) } // 期待泛型类型,却返回一个具体类型 pub fn generics_as_return_not_working<T: Iterator<Item = u32>>(i: u32) -> T { std::iter::once(i) } }
那怎么办?很简单,我们可以返回 trait object,它消除了类型的差异,把所有不同的实现 Iterator 的类型都统一到一个相同的 trait object 下:
#![allow(unused)] fn main() { // 返回 trait object pub fn trait_object_as_return_working(i: u32) -> Box<dyn Iterator<Item = u32>> { Box::new(std::iter::once(i)) } }
明白了这一点,回到刚才 KV server的 Storage trait:
#![allow(unused)] fn main() { pub trait Storage { ... /// 遍历 HashTable,返回 kv pair 的 Iterator fn get_iter(&self, table: &str) -> Result<Box<dyn Iterator<Item = Kvpair>>, KvError>; } }
现在你是不是更好地理解了,在这个 trait 里,为何我们需要使用 Box<dyn Iterator<Item = Kvpair>> ?
不过使用 trait object 是有额外的代价的,首先这里有一次额外的堆分配,其次动态分派会带来一定的性能损失。
复杂的泛型参数该如何处理?
在泛型函数中,有时候泛型参数可以非常复杂。比如泛型参数是一个闭包,闭包返回一个 Iterator,Iterator 中的 Item 又有某个约束。看下面的示例代码:
#![allow(unused)] fn main() { pub fn comsume_iterator<F, Iter, T>(mut f: F) where F: FnMut(i32) -> Iter, // F 是一个闭包,接受 i32,返回 Iter 类型 Iter: Iterator<Item = T>, // Iter 是一个 Iterator,Item 是 T 类型 T: std::fmt::Debug, // T 实现了 Debug trait { // 根据 F 的类型,f(10) 返回 iterator,所以可以用 for 循环 for item in f(10) { println!("{:?}", item); // item 实现了 Debug trait,所以可以用 {:?} 打印 } } }
这个代码的泛型参数虽然非常复杂,不过一步步分解,其实并不难理解其实质:
- 参数 F 是一个闭包,接受 i32,返回 Iter 类型;
- 参数 Iter 是一个 Iterator,Item 是 T 类型;
- 参数 T 是一个实现了 Debug trait 的类型。
这么分解下来,我们就可以看到,为何这段代码能够编译通过,同时也可以写出合适的测试示例,来测试它:
#![allow(unused)] fn main() { #[cfg(test)] mod tests { use super::*; #[test] fn test_consume_iterator() { // 不会 panic 或者出错 comsume_iterator(|i| (0..i).into_iter()) } } }
小结
泛型编程在 Rust 开发中占据着举足轻重的地位,几乎你写的每一段代码都或多或少会使用到泛型有关的结构,比如标准库的 Vec
当然,泛型编程也是一把双刃剑。任何时候,当我们引入抽象,即便能做到零成本抽象,要记得抽象本身也是一种成本。
当我们把代码抽象成函数、把数据结构抽象成泛型结构,即便运行时几乎并无添加额外成本,它还是会带来设计时的成本,如果抽象得不好,还会带来更大的维护上的成本。 做系统设计,我们考虑 ROI(Return On Investment)时,要把 TCO(Total Cost of Ownership)也考虑进去。这也是为什么过度设计的系统和不做设计的系统,它们长期的 TCO 都非常糟糕。
建议你在自己的代码中使用复杂的泛型结构前,最好先做一些准备。
首先,自然是了解使用泛型的场景,以及主要的模式,就像本文介绍的那样;之后,可以多读别人的代码,多看优秀的系统,都是如何使用泛型来解决实际问题的。同时,不要着急把复杂的泛型引入到你自己的系统中,可以先多写一些小的、测试性质的代码,就像文中的那些示例代码一样,从小处着手,去更深入地理解泛型;
有了这些准备打底,最后在你的大型项目中,需要的时候引入自己的泛型数据结构或者函数,去解决实际问题。
思考题
如果你理解了今天讲的泛型的用法,那么阅读 futures 库时,遇到类似的复杂泛型声明,比如说 StreamExt trait 的 for_each_concurrent,你能搞明白它的参数 f 代表什么吗?你该怎么使用这个方法呢?
#![allow(unused)] fn main() { fn for_each_concurrent<Fut, F>( self, limit: impl Into<Option<usize>>, f: F, ) -> ForEachConcurrent<Self, Fut, F> where F: FnMut(Self::Item) -> Fut, Fut: Future<Output = ()>, Self: Sized, { { ... } }
今天你已经完成了Rust学习的第23次打卡。如果你觉得有收获,也欢迎你分享给身边的朋友,邀他一起讨论。我们下节课见。
类型系统:如何在实战中使用trait object?
你好,我是陈天。
今天我们来看看 trait object 是如何在实战中使用的。
照例先来回顾一下 trait object。当我们在运行时想让某个具体类型,只表现出某个 trait 的行为,可以通过将其赋值给一个 dyn T,无论是 &dyn T,还是 Box
你可以再阅读一下 第 13 讲 的这个图,来回顾 trait object 是怎么回事:
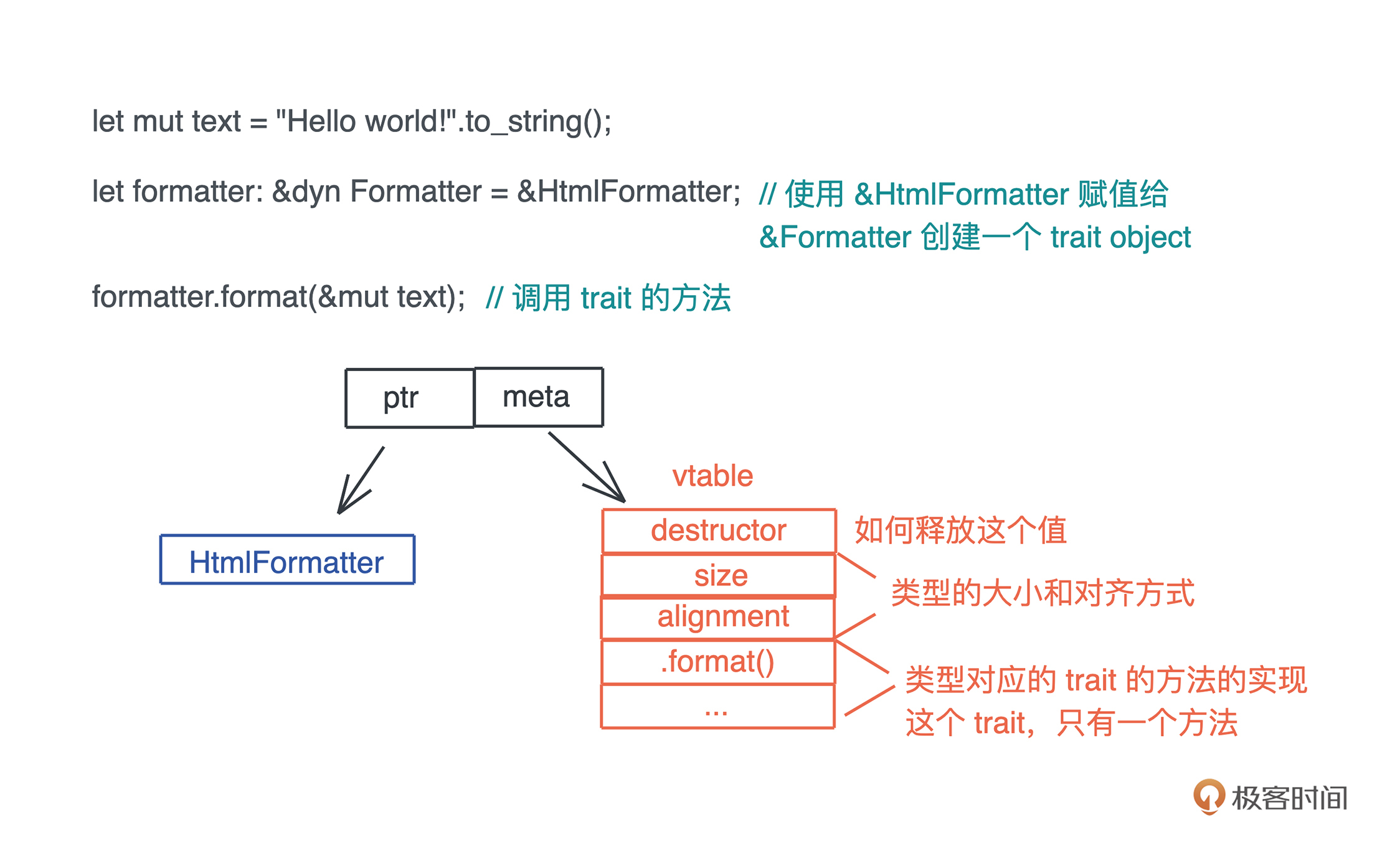
在编译 dyn T 时,Rust 会为使用了 trait object 类型的 trait 实现,生成相应的 vtable,放在可执行文件中(一般在 TEXT 或 RODATA 段):
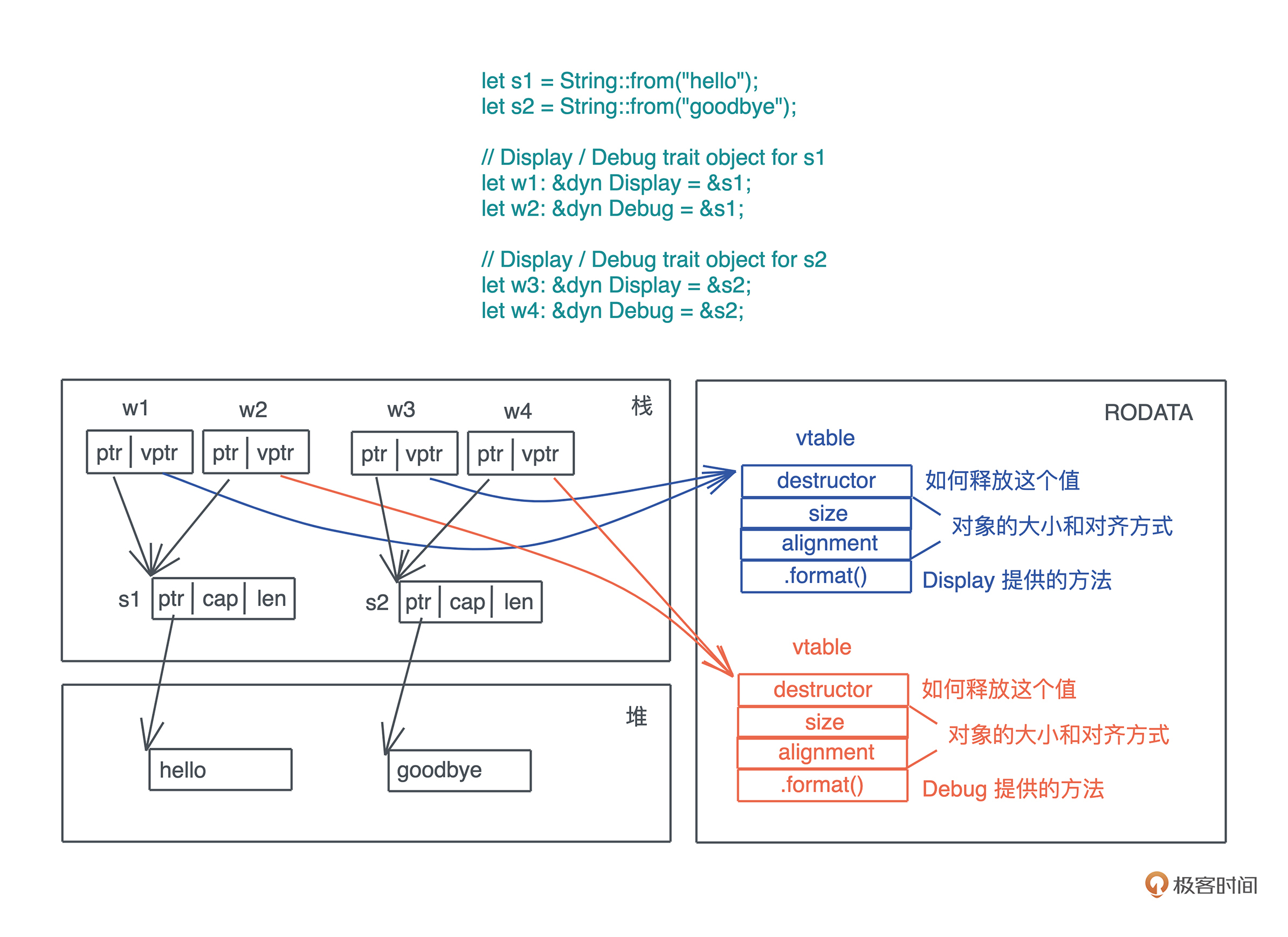
这样,当 trait object 调用 trait 的方法时,它会先从 vptr 中找到对应的 vtable,进而找到对应的方法来执行。
使用 trait object 的好处是, 当在某个上下文中需要满足某个 trait 的类型,且这样的类型可能有很多,当前上下文无法确定会得到哪一个类型时,我们可以用 trait object 来统一处理行为。和泛型参数一样,trait object 也是一种延迟绑定,它让决策可以延迟到运行时,从而得到最大的灵活性。
当然,有得必有失。trait object 把决策延迟到运行时,带来的后果是执行效率的打折。在 Rust 里,函数或者方法的执行就是一次跳转指令,而 trait object 方法的执行还多一步,它涉及额外的内存访问,才能得到要跳转的位置再进行跳转,执行的效率要低一些。
此外,如果要把 trait object 作为返回值返回,或者要在线程间传递 trait object,都免不了使用 Box
好,对 trait object 的回顾就到这里,如果你对它还一知半解,请复习 13 讲,并且阅读 Rust book 里的: Using Trait Objects that allow for values of different types。接下来我们讲讲实战中 trait object 的主要使用场景。
在函数中使用 trait object
我们可以在函数的参数或者返回值中使用 trait object。
先来看在参数中使用 trait object。下面的代码构建了一个 Executor trait,并对比做静态分发的 impl Executor、做动态分发的 &dyn Executor 和 Box
#![allow(unused)] fn main() { use std::{error::Error, process::Command}; pub type BoxedError = Box<dyn Error + Send + Sync>; pub trait Executor { fn run(&self) -> Result<Option<i32>, BoxedError>; } pub struct Shell<'a, 'b> { cmd: &'a str, args: &'b [&'a str], } impl<'a, 'b> Shell<'a, 'b> { pub fn new(cmd: &'a str, args: &'b [&'a str]) -> Self { Self { cmd, args } } } impl<'a, 'b> Executor for Shell<'a, 'b> { fn run(&self) -> Result<Option<i32>, BoxedError> { let output = Command::new(self.cmd).args(self.args).output()?; Ok(output.status.code()) } } /// 使用泛型参数 pub fn execute_generics(cmd: &impl Executor) -> Result<Option<i32>, BoxedError> { cmd.run() } /// 使用 trait object: &dyn T pub fn execute_trait_object(cmd: &dyn Executor) -> Result<Option<i32>, BoxedError> { cmd.run() } /// 使用 trait object: Box<dyn T> pub fn execute_boxed_trait_object(cmd: Box<dyn Executor>) -> Result<Option<i32>, BoxedError> { cmd.run() } #[cfg(test)] mod tests { use super::*; #[test] fn shell_shall_work() { let cmd = Shell::new("ls", &[]); let result = cmd.run().unwrap(); assert_eq!(result, Some(0)); } #[test] fn execute_shall_work() { let cmd = Shell::new("ls", &[]); let result = execute_generics(&cmd).unwrap(); assert_eq!(result, Some(0)); let result = execute_trait_object(&cmd).unwrap(); assert_eq!(result, Some(0)); let boxed = Box::new(cmd); let result = execute_boxed_trait_object(boxed).unwrap(); assert_eq!(result, Some(0)); } } }
其中,impl Executor 使用的是泛型参数的简化版本,而 &dyn Executor 和 Box
这里为了简化代码,我使用了 type 关键字创建了一个 BoxedError 类型,是 Box<dyn Error + Send + Sync + 'static> 的别名,它是 Error trait 的 trait object,除了要求类型实现了 Error trait 外,它还有额外的约束:类型必须满足 Send / Sync 这两个 trait。
在参数中使用 trait object 比较简单,再来看一个实战中的 例子 巩固一下:
#![allow(unused)] fn main() { pub trait CookieStore: Send + Sync { fn set_cookies( &self, cookie_headers: &mut dyn Iterator<Item = &HeaderValue>, url: &Url ); fn cookies(&self, url: &Url) -> Option<HeaderValue>; } }
这是我们之前使用过的 reqwest 库中的一个处理 CookieStore 的 trait。在 set_cookies 方法中使用了 &mut dyn Iterator 这样一个 trait object。
在函数返回值中使用
好,相信你对在参数中如何使用 trait object 已经没有什么问题了,我们再看返回值中使用 trait object,这是 trait object 使用频率比较高的场景。
之前已经出现过很多次了。比如上一讲已经详细介绍的,为何 KV server 里的 Storage trait 不能使用泛型参数来处理返回的 iterator,只能用 Box
#![allow(unused)] fn main() { pub trait Storage: Send + Sync + 'static { ... /// 遍历 HashTable,返回 kv pair 的 Iterator fn get_iter(&self, table: &str) -> Result<Box<dyn Iterator<Item = Kvpair>>, KvError>; } }
再来看一些实战中会遇到的例子。
首先是 async_trait。它是一种特殊的 trait,方法中包含 async fn。目前 Rust 并不支持 trait 中使用 async fn,一个变通的方法是使用 async_trait 宏。
在 get hands dirty 系列中,我们就使用过 async trait。下面是 第 6 讲 SQL查询工具数据源的获取中定义的 Fetch trait:
#![allow(unused)] fn main() { // Rust 的 async trait 还没有稳定,可以用 async_trait 宏 #[async_trait] pub trait Fetch { type Error; async fn fetch(&self) -> Result<String, Self::Error>; } }
这里宏展开后,类似于:
#![allow(unused)] fn main() { pub trait Fetch { type Error; fn fetch<'a>(&'a self) -> Result<Pin<Box<dyn Future<Output = String> + Send + 'a>>, Self::Error>; } }
它使用了 trait object 作为返回值。这样,不管 fetch() 的实现,返回什么样的 Future 类型,都可以被 trait object 统一起来,调用者只需要按照正常 Future 的接口使用即可。
我们再看一个 snow 下的 CryptoResolver 的例子:
#![allow(unused)] fn main() { /// An object that resolves the providers of Noise crypto choices pub trait CryptoResolver { /// Provide an implementation of the Random trait or None if none available. fn resolve_rng(&self) -> Option<Box<dyn Random>>; /// Provide an implementation of the Dh trait for the given DHChoice or None if unavailable. fn resolve_dh(&self, choice: &DHChoice) -> Option<Box<dyn Dh>>; /// Provide an implementation of the Hash trait for the given HashChoice or None if unavailable. fn resolve_hash(&self, choice: &HashChoice) -> Option<Box<dyn Hash>>; /// Provide an implementation of the Cipher trait for the given CipherChoice or None if unavailable. fn resolve_cipher(&self, choice: &CipherChoice) -> Option<Box<dyn Cipher>>; /// Provide an implementation of the Kem trait for the given KemChoice or None if unavailable #[cfg(feature = "hfs")] fn resolve_kem(&self, _choice: &KemChoice) -> Option<Box<dyn Kem>> { None } } }
这是一个处理 Noise Protocol 使用何种加密算法的一个 trait。这个 trait 的每个方法,都返回一个 trait object,每个 trait object 都提供加密算法中所需要的不同的能力,比如随机数生成算法(Random)、DH 算法(Dh)、哈希算法(Hash)、对称加密算法(Cipher)和密钥封装算法(Kem)。
所有这些,都有一系列的具体的算法实现,通过 CryptoResolver trait,可以得到当前使用的某个具体算法的 trait object, 这样,在处理业务逻辑时,我们不用关心当前究竟使用了什么算法,就能根据这些 trait object 构筑相应的实现,比如下面的 generate_keypair:
#![allow(unused)] fn main() { pub fn generate_keypair(&self) -> Result<Keypair, Error> { // 拿到当前的随机数生成算法 let mut rng = self.resolver.resolve_rng().ok_or(InitStage::GetRngImpl)?; // 拿到当前的 DH 算法 let mut dh = self.resolver.resolve_dh(&self.params.dh).ok_or(InitStage::GetDhImpl)?; let mut private = vec![0u8; dh.priv_len()]; let mut public = vec![0u8; dh.pub_len()]; // 使用随机数生成器 和 DH 生成密钥对 dh.generate(&mut *rng); private.copy_from_slice(dh.privkey()); public.copy_from_slice(dh.pubkey()); Ok(Keypair { private, public }) } }
说句题外话,如果你想更好地学习 trait 和 trait object 的使用,snow 是一个很好的学习资料。你可以顺着 CryptoResolver 梳理它用到的这几个主要的加密算法相关的 trait,看看别人是怎么定义 trait、如何把各个 trait 关联起来,以及最终如何把 trait 和核心数据结构联系起来的(小提示: Builder 以及 HandshakeState)。
在数据结构中使用 trait object
了解了在函数中是如何使用 trait object 的,接下来我们再看看在数据结构中,如何使用 trait object。
继续以 snow 的代码为例,看 HandshakeState这个用于处理 Noise Protocol 握手协议的数据结构,用到了哪些 trait object( 代码):
#![allow(unused)] fn main() { pub struct HandshakeState { pub(crate) rng: Box<dyn Random>, pub(crate) symmetricstate: SymmetricState, pub(crate) cipherstates: CipherStates, pub(crate) s: Toggle<Box<dyn Dh>>, pub(crate) e: Toggle<Box<dyn Dh>>, pub(crate) fixed_ephemeral: bool, pub(crate) rs: Toggle<[u8; MAXDHLEN]>, pub(crate) re: Toggle<[u8; MAXDHLEN]>, pub(crate) initiator: bool, pub(crate) params: NoiseParams, pub(crate) psks: [Option<[u8; PSKLEN]>; 10], #[cfg(feature = "hfs")] pub(crate) kem: Option<Box<dyn Kem>>, #[cfg(feature = "hfs")] pub(crate) kem_re: Option<[u8; MAXKEMPUBLEN]>, pub(crate) my_turn: bool, pub(crate) message_patterns: MessagePatterns, pub(crate) pattern_position: usize, } }
你不需要了解 Noise protocol,也能够大概可以明白这里 Random、Dh 以及 Kem 三个 trait object 的作用:它们为握手期间使用的加密协议提供最大的灵活性。
想想看,如果这里不用 trait object,这个数据结构该怎么处理?
可以用泛型参数,也就是说:
#![allow(unused)] fn main() { pub struct HandshakeState<R, D, K> where R: Random, D: Dh, K: Kem { ... } }
这是我们大部分时候处理这样的数据结构的选择。但是,过多的泛型参数会带来两个问题:首先,代码实现过程中,所有涉及的接口都变得非常臃肿,你在使用 HandshakeState<R, D, K> 的任何地方,都必须带着这几个泛型参数以及它们的约束。其次,这些参数所有被使用到的情况,组合起来,会生成大量的代码。
而使用 trait object,我们在牺牲一点性能的前提下,消除了这些泛型参数,实现的代码更干净清爽,且代码只会有一份实现。
在数据结构中使用 trait object 还有一种很典型的场景是, 闭包。
因为在 Rust 中,闭包都是以匿名类型的方式出现,我们无法直接在数据结构中使用其类型,只能用泛型参数。而对闭包使用泛型参数后,如果捕获的数据太大,可能造成数据结构本身太大;但有时,我们并不在意一点点性能损失,更愿意让代码处理起来更方便。
比如用于做 RBAC 的库 oso 里的 AttributeGetter,它包含了一个 Fn:
#![allow(unused)] fn main() { #[derive(Clone)] pub struct AttributeGetter( Arc<dyn Fn(&Instance, &mut Host) -> crate::Result<PolarValue> + Send + Sync>, ); }
如果你对在 Rust 中如何实现 Python 的 getattr 感兴趣,可以看看 oso 的代码。
再比如做交互式 CLI 的 dialoguer 的 Input,它的 validator 就是一个 FnMut:
#![allow(unused)] fn main() { pub struct Input<'a, T> { prompt: String, default: Option<T>, show_default: bool, initial_text: Option<String>, theme: &'a dyn Theme, permit_empty: bool, validator: Option<Box<dyn FnMut(&T) -> Option<String> + 'a>>, #[cfg(feature = "history")] history: Option<&'a mut dyn History<T>>, } }
用 trait object 处理 KV server 的 Service 结构
好,到这里用 trait object 做动态分发的几个场景我们就介绍完啦,来写段代码练习一下。
就用之前写的 KV server 的 Service 结构来趁热打铁,我们尝试对它做个处理,使其内部使用 trait object。
其实对于 KV server 而言,使用泛型是更好的选择,因为此处泛型并不会造成太多的复杂性,我们也不希望丢掉哪怕一点点性能。然而,出于学习的目的,我们可以看看如果 store 使用 trait object,代码会变成什么样子。你自己可以先尝试一下,再来看下面的示例( 代码):
#![allow(unused)] fn main() { use std::{error::Error, sync::Arc}; // 定义类型,让 KV server 里的 trait 可以被编译通过 pub type KvError = Box<dyn Error + Send + Sync>; pub struct Value(i32); pub struct Kvpair(i32, i32); /// 对存储的抽象,我们不关心数据存在哪儿,但需要定义外界如何和存储打交道 pub trait Storage: Send + Sync + 'static { fn get(&self, table: &str, key: &str) -> Result<Option<Value>, KvError>; fn set(&self, table: &str, key: String, value: Value) -> Result<Option<Value>, KvError>; fn contains(&self, table: &str, key: &str) -> Result<bool, KvError>; fn del(&self, table: &str, key: &str) -> Result<Option<Value>, KvError>; fn get_all(&self, table: &str) -> Result<Vec<Kvpair>, KvError>; fn get_iter(&self, table: &str) -> Result<Box<dyn Iterator<Item = Kvpair>>, KvError>; } // 使用 trait object,不需要泛型参数,也不需要 ServiceInner 了 pub struct Service { pub store: Arc<dyn Storage>, } // impl 的代码略微简单一些 impl Service { pub fn new<S: Storage>(store: S) -> Self { Self { store: Arc::new(store), } } } // 实现 trait 时也不需要带着泛型参数 impl Clone for Service { fn clone(&self) -> Self { Self { store: Arc::clone(&self.store), } } } }
从这段代码中可以看到,通过牺牲一点性能,我们让代码整体撰写和使用起来方便了不少。
小结
无论是上一讲的泛型参数,还是今天的 trait object,都是 Rust 处理多态的手段。当系统需要使用多态来解决复杂多变的需求,让同一个接口可以展现不同的行为时,我们要决定究竟是编译时的静态分发更好,还是运行时的动态分发更好。
一般情况下,作为 Rust 开发者,我们不介意泛型参数带来的稍微复杂的代码结构,愿意用开发时的额外付出,换取运行时的高效;但 有时候,当泛型参数过多,导致代码出现了可读性问题,或者运行效率并不是主要矛盾的时候,我们可以通过使用 trait object 做动态分发,来降低代码的复杂度。
具体看,在有些情况,我们不太容易使用泛型参数,比如希望函数返回某个 trait 的实现,或者数据结构中某些参数在运行时的组合过于复杂,比如上文提到的 HandshakeState,此时,使用 trait object 是更好的选择。
思考题
期中测试中我给出的 rgrep 的代码,如果把 StrategyFn 的接口改成使用 trait object:
#![allow(unused)] fn main() { /// 定义类型,这样,在使用时可以简化复杂类型的书写 pub type StrategyFn = fn(&Path, &mut dyn BufRead, &Regex, &mut dyn Write) -> Result<(), GrepError>; }
你能把实现部分修改,使测试通过么?对比修改前后的代码,你觉得对 rgrep,哪种实现更好?为什么?
今天你完成了Rust学习的第24次打卡。如果你觉得有收获,也欢迎分享给你身边的朋友,邀他一起讨论。我们下节课见。
延伸阅读
我们总说 trait object 性能会差一些,因为需要从 vtable 中额外加载对应的方法的地址,才能跳转执行。那么这个性能差异究竟有多大呢?网上有人说调用 trait object 的方法,性能会比直接调用类型的方法差一个数量级,真的么?
我用 criterion 做了一个简单的测试,测试的 trait 使用的就是我们这一讲使用的 Executor trait。测试代码如下(你可以访问 GitHub repo 中这一讲的代码):
#![allow(unused)] fn main() { use advanced_trait_objects::{ execute_boxed_trait_object, execute_generics, execute_trait_object, Shell, }; use criterion::{black_box, criterion_group, criterion_main, Criterion}; pub fn generics_benchmark(c: &mut Criterion) { c.bench_function("generics", |b| { b.iter(|| { let cmd = Shell::new("ls", &[]); execute_generics(black_box(&cmd)).unwrap(); }) }); } pub fn trait_object_benchmark(c: &mut Criterion) { c.bench_function("trait object", |b| { b.iter(|| { let cmd = Shell::new("ls", &[]); execute_trait_object(black_box(&cmd)).unwrap(); }) }); } pub fn boxed_object_benchmark(c: &mut Criterion) { c.bench_function("boxed object", |b| { b.iter(|| { let cmd = Box::new(Shell::new("ls", &[])); execute_boxed_trait_object(black_box(cmd)).unwrap(); }) }); } criterion_group!( benches, generics_benchmark, trait_object_benchmark, boxed_object_benchmark ); criterion_main!(benches); }
为了不让实现本身干扰接口调用的速度,我们在 trait 的方法中什么也不做,直接返回:
#![allow(unused)] fn main() { impl<'a, 'b> Executor for Shell<'a, 'b> { fn run(&self) -> Result<Option<i32>, BoxedError> { // let output = Command::new(self.cmd).args(self.args).output()?; // Ok(output.status.code()) Ok(Some(0)) } } }
测试结果如下:
generics time: [3.0995 ns 3.1549 ns 3.2172 ns]
change: [-96.890% -96.810% -96.732%] (p = 0.00 < 0.05)
Performance has improved.
Found 5 outliers among 100 measurements (5.00%)
4 (4.00%) high mild
1 (1.00%) high severe
trait object time: [4.0348 ns 4.0934 ns 4.1552 ns]
change: [-96.024% -95.893% -95.753%] (p = 0.00 < 0.05)
Performance has improved.
Found 8 outliers among 100 measurements (8.00%)
3 (3.00%) high mild
5 (5.00%) high severe
boxed object time: [65.240 ns 66.473 ns 67.777 ns]
change: [-67.403% -66.462% -65.530%] (p = 0.00 < 0.05)
Performance has improved.
Found 2 outliers among 100 measurements (2.00%)
可以看到,使用泛型做静态分发最快,平均 3.15ns;使用 &dyn Executor 平均速度 4.09ns,要慢 30%;而使用 Box
那么,这个性能差异重要么?
在回答这个问题之前,我们把 run() 方法改回来:
#![allow(unused)] fn main() { impl<'a, 'b> Executor for Shell<'a, 'b> { fn run(&self) -> Result<Option<i32>, BoxedError> { let output = Command::new(self.cmd).args(self.args).output()?; Ok(output.status.code()) } } }
我们知道 Command 的执行速度比较慢,但是想再看看,对于执行效率低的方法,这个性能差异是否重要。
新的测试结果不出所料:
generics time: [4.6901 ms 4.7267 ms 4.7678 ms]
change: [+145694872% +148496855% +151187366%] (p = 0.00 < 0.05)
Performance has regressed.
Found 7 outliers among 100 measurements (7.00%)
3 (3.00%) high mild
4 (4.00%) high severe
trait object time: [4.7452 ms 4.7912 ms 4.8438 ms]
change: [+109643581% +113478268% +116908330%] (p = 0.00 < 0.05)
Performance has regressed.
Found 7 outliers among 100 measurements (7.00%)
4 (4.00%) high mild
3 (3.00%) high severe
boxed object time: [4.7867 ms 4.8336 ms 4.8874 ms]
change: [+6935303% +7085465% +7238819%] (p = 0.00 < 0.05)
Performance has regressed.
Found 8 outliers among 100 measurements (8.00%)
4 (4.00%) high mild
4 (4.00%) high severe
因为执行一个 Shell 命令的效率实在太低,到毫秒的量级,虽然 generics 依然最快,但使用 &dyn Executor 和 Box
所以,如果是那种执行效率在数百纳秒以内的函数,是否使用 trait object,尤其是 boxed trait object,性能差别会比较明显;但当函数本身的执行需要数微秒到数百微秒时,性能差别就很小了;到了毫秒的量级,性能的差别几乎无关紧要。
总的来说,大部分情况,我们在撰写代码的时候,不必太在意 trait object 的性能问题。如果你实在在意关键路径上 trait object 的性能,那么先尝试看能不能不要做额外的堆内存分配。
类型系统:如何围绕trait来设计和架构系统?
你好,我是陈天。
Trait,trait,trait,怎么又是 trait?how old are you?
希望你还没有厌倦我们没完没了地聊关于 trait 的话题。因为 trait 在 Rust 开发中的地位,怎么吹都不为过。
其实不光是 Rust 中的 trait,任何一门语言,和接口处理相关的概念,都是那门语言在使用过程中最重要的概念。 软件开发的整个行为,基本上可以说是不断创建和迭代接口,然后在这些接口上进行实现的过程。
在这个过程中,有些接口是标准化的,雷打不动,就像钢筋、砖瓦、螺丝、钉子、插座等这些材料一样,无论要构筑的房子是什么样子的,这些标准组件的接口在确定下来后,都不会改变,它们就像 Rust 语言标准库中的标准 trait 一样。
而有些接口是跟构造的房子息息相关的,比如门窗、电器、家具等,它们就像你要设计的系统中的 trait 一样,可以把系统的各个部分联结起来,最终呈现给用户一个完整的使用体验。
之前讲了trait 的基础知识,也介绍了如何在实战中使用 trait 和 trait object。今天,我们再花一讲的时间,来看看如何围绕着 trait 来设计和架构系统。
由于在讲架构和设计时,不免要引入需求,然后我需要解释这需求的来龙去脉,再提供设计思路,再介绍 trait 在其中的作用,但这样下来,一堂课的内容能讲好一个系统设计就不错了。所以我们换个方式,把之前设计过的系统捋一下,重温它们的 trait 设计,看看其中的思路以及取舍。
用 trait 让代码自然舒服好用
在 第 5 讲,thumbor 的项目里,我设计了一个 SpecTransform trait,通过它可以统一处理任意类型的、描述我们希望如何处理图片的 spec:
// 一个 spec 可以包含上述的处理方式之一(这是 protobuf 定义)
message Spec {
oneof data {
Resize resize = 1;
Crop crop = 2;
Flipv flipv = 3;
Fliph fliph = 4;
Contrast contrast = 5;
Filter filter = 6;
Watermark watermark = 7;
}
}
SpecTransform trait 的定义如下( 代码):
#![allow(unused)] fn main() { // SpecTransform:未来如果添加更多的 spec,只需要实现它即可 pub trait SpecTransform<T> { // 对图片使用 op 做 transform fn transform(&mut self, op: T); } }
它可以用来对图片使用某个 spec 进行处理。
但如果你阅读 GitHub 上的源码,你可能会发现一个没用到的文件 imageproc.rs 中类似的 trait( 代码):
#![allow(unused)] fn main() { pub trait ImageTransform { fn transform(&self, image: &mut PhotonImage); } }
这个 trait 是第一版的 trait。我依旧保留着它,就是想在此展示一下 trait 设计上的取舍。
当你审视这段代码的时候会不会觉得,这个 trait 的设计有些草率?因为如果传入的 image 来自不同的图片处理引擎,而某个图片引擎提供的 image 类型不是 PhotonImage,那这个接口不就无法使用了么?
hmm,这是个设计上的大问题啊。想想看,以目前所学的知识,怎么解决这个问题呢?什么可以帮助我们延迟 image 是否必须是 PhotonImage 的决策呢?
对,泛型。我们可以使用泛型 trait 修改一下刚才那段代码:
#![allow(unused)] fn main() { // 使用 trait 可以统一处理的接口,以后无论增加多少功能,只需要加新的 Spec,然后实现 ImageTransform 接口 pub trait ImageTransform<Image> { fn transform(&self, image: &mut Image); } }
把传入的 image 类型抽象成泛型类型之后,延迟了图片类型判断和支持的决策,可用性更高。
但如果你继续对比现在的 ImageTransform和之前写的 SpecTransform,会发现,它们实现 trait 的数据结构和用在 trait 上的泛型参数,正好掉了个个。
你看,PhotonImage 下对于 Contrast 的 ImageTransform 的实现:
#![allow(unused)] fn main() { impl ImageTransform<PhotonImage> for Contrast { fn transform(&self, image: &mut Image) { effects::adjust_contrast(image, self.contrast); } } }
而同样的,PhotonImage 下对 Contract 的 SpecTransform 的实现:
#![allow(unused)] fn main() { impl SpecTransform<&Contrast> for Photon { fn transform(&mut self, op: &Contrast) { effects::adjust_contrast(&mut self.0, op.contrast); } } }
这两种方式基本上等价,但一个围绕着 Spec 展开,一个围绕着 Image 展开:
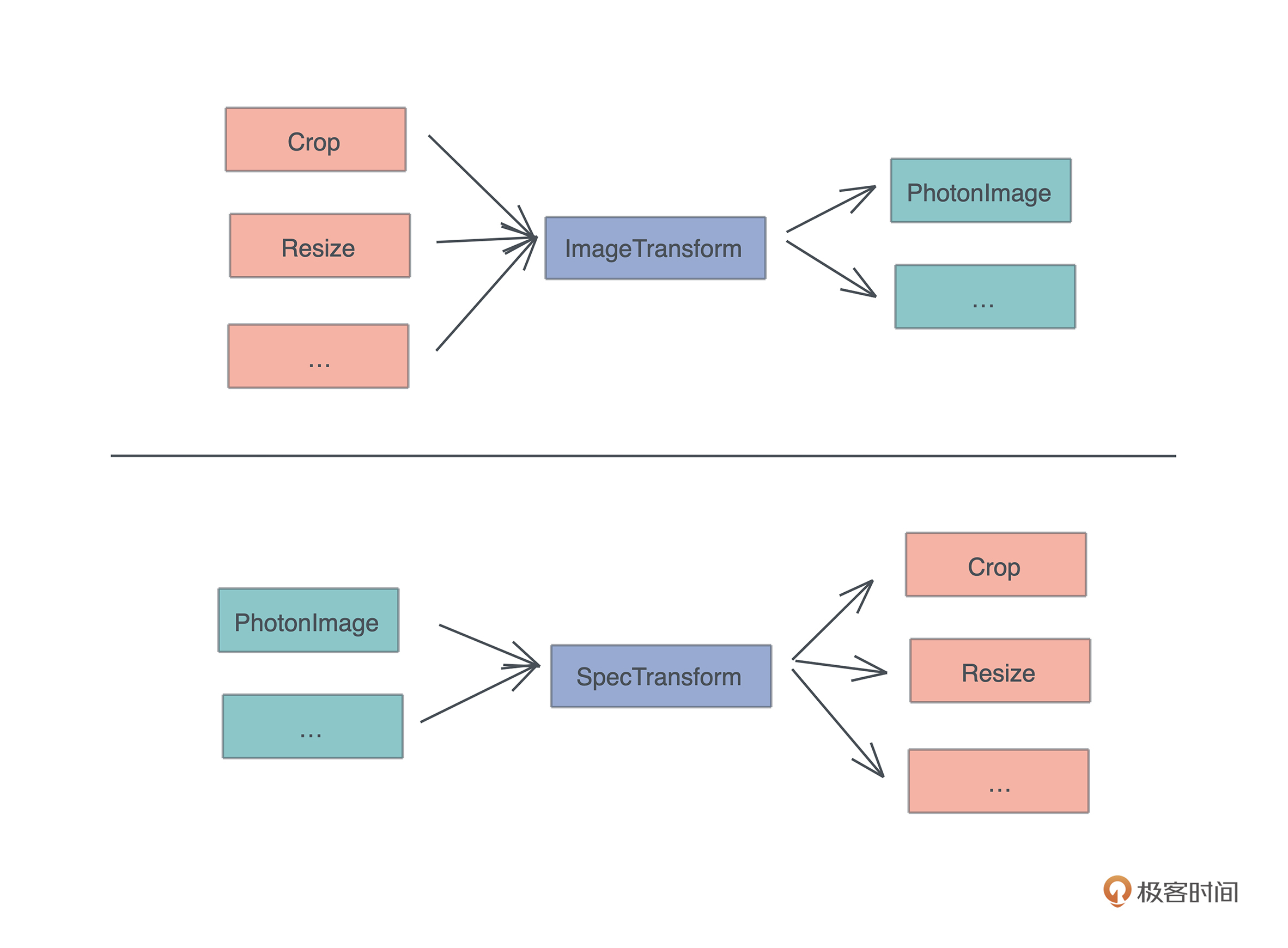
那么,哪种设计更好呢?
其实二者并没有功能上或者性能上的优劣。
那为什么我选择了 SpecTransform 的设计呢?在第一版的设计我还没有考虑 Engine的时候,是以 Spec 为中心的;但在把 Engine 考虑进去后,我以 Engine 为中心重新做了设计,这样做的好处是,开发新的 Engine 的时候,SpecTransform trait 用起来更顺手,更自然一些。
嗯,顺手,自然。接口的设计一定要关注使用者的体验,一个使用起来感觉自然顺手舒服的接口,就是更好的接口。 因为这意味着使用的时候,代码可以自然而然写出来,而无需看文档。
比如同样是 Python 代码:
df[df["age"] > 10]
就要比:
df.filter(df.col("age").gt(10))
要更加自然舒服。前面的代码,你看一眼别人怎么用,自己就很快能写出来,而后者,你需要先搞清楚 filter 函数是怎么回事,以及col()、gt() 这两个方法如何使用。
我们再来看来两段 Rust 代码。这行使用了 From/Into trait 的代码:
#![allow(unused)] fn main() { let url = generate_url_with_spec(image_spec.into()); }
就要比:
#![allow(unused)] fn main() { let data = image_spec.encode_to_vec(); let s = encode_config(data, URL_SAFE_NO_PAD); let url = generate_url_with_spec(s); }
要简洁、自然得多。它把实现细节都屏蔽了起来,只让用户关心他们需要关心的逻辑。
所以,我们在设计 trait 的时候,除了关注功能,还要注意是否好用、易用。这也是为什么我们在介绍 KV server 的时候,不断强调,trait 在设计结束之后,不要先着急撰写实现 trait 的代码,而是最好先写一些对于 trait 使用的测试代码。
你在写这些测试代码的使用体验,就是别人在使用你的 trait 构建系统时的真实体验,如果它用起来别扭、啰嗦,不看文档就不容易用对,那这个 trait 本身还有待进一步迭代。
用 trait 做桥接
在软件开发的绝大多数时候,我们都不会从零到一完完全全设计和构建系统的所有部分。就像盖房子,不可能从一抔土、一块瓦片开始打造。我们需要依赖生态系统中已有的组件。
作为架构师,你的职责是在生态系统中找到合适的组件,连同你自己打造的部分,一起粘合起来,形成一个产品。所以,你会遇到那些接口与你预期不符的组件,可是自己又无法改变那些组件来让接口满足你的预期,怎么办?
此刻,我们需要桥接。
就像要用的电器是二相插口,而附近墙上的插座只有三相插口,我们总不能修改电器或者墙上的插座,使其满足对方吧?正确的做法是购置一个多项插座来桥接二者。
在 Rust 里,桥接的工作可以通过函数来完成,但最好通过 trait 来桥接。继续看 第 5 讲 thumbor 里的另一个 trait Engine( 代码):
#![allow(unused)] fn main() { // Engine trait:未来可以添加更多的 engine,主流程只需要替换 engine pub trait Engine { // 对 engine 按照 specs 进行一系列有序的处理 fn apply(&mut self, specs: &[Spec]); // 从 engine 中生成目标图片,注意这里用的是 self,而非 self 的引用 fn generate(self, format: ImageOutputFormat) -> Vec<u8>; } }
通过 Engine 这个 trait,我们把第三方的库 photon和自己设计的 Image Spec 连接起来,使得我们不用关心 Engine 背后究竟是什么,只需要调用 apply 和 generate 方法即可:
#![allow(unused)] fn main() { // 使用 image engine 处理 let mut engine: Photon = data .try_into() .map_err(|_| StatusCode::INTERNAL_SERVER_ERROR)?; engine.apply(&spec.specs); let image = engine.generate(ImageOutputFormat::Jpeg(85)); }
这段代码中,由于之前为 Photon 实现了 TryFrom
#![allow(unused)] fn main() { // 从 Bytes 转换成 Photon 结构 impl TryFrom<Bytes> for Photon { type Error = anyhow::Error; fn try_from(data: Bytes) -> Result<Self, Self::Error> { Ok(Self(open_image_from_bytes(&data)?)) } } }
就桥接 thumbor 代码和 photon crate 而言,Engine 表现良好,它让我们不但很容易使用 photon crate,还可以很方便在未来需要的时候替换掉 photon crate。
不过,Engine 在构造时,所做的桥接还是不够直观和自然,如果不仔细看代码或者文档,使用者可能并不清楚,第3行代码,如何通过 TryFrom/TryInto 得到一个实现了 Engine 的结构。从这个使用体验来看,我们会希望通过使用 Engine trait,任何一个图片引擎都可以统一地创建 Engine结构。怎么办?
可以为这个 trait 添加一个缺省的 create 方法:
#![allow(unused)] fn main() { // Engine trait:未来可以添加更多的 engine,主流程只需要替换 engine pub trait Engine { // 生成一个新的 engine fn create<T>(data: T) -> Result<Self> where Self: Sized, T: TryInto<Self>, { data.try_into() .map_err(|_| anyhow!("failed to create engine")) } // 对 engine 按照 specs 进行一系列有序的处理 fn apply(&mut self, specs: &[Spec]); // 从 engine 中生成目标图片,注意这里用的是 self,而非 self 的引用 fn generate(self, format: ImageOutputFormat) -> Vec<u8>; } }
注意看新 create 方法的约束:任何 T,只要实现了相应的 TryFrom/TryInto,就可以用这个缺省的 create() 方法来构造 Engine。
有了这个接口后,上面使用 engine 的代码可以更加直观,省掉了第3行的try_into()处理:
#![allow(unused)] fn main() { // 使用 image engine 处理 let mut engine = Photon::create(data) .map_err(|_| StatusCode::INTERNAL_SERVER_ERROR)?; engine.apply(&spec.specs); let image = engine.generate(ImageOutputFormat::Jpeg(85)); }
桥接是架构中一个非常重要的思想,我们一定要掌握这个思想的精髓。
再举个例子。比如现在想要系统可以通过访问某个 REST API,得到用户自己发布的、按时间顺序倒排的朋友圈。怎么写这段代码呢?最简单粗暴的方式是:
#![allow(unused)] fn main() { let secret_api = api_with_user_token(&user, params); let data: Vec<Status> = reqwest::get(secret_api)?.json()?; }
更好的方式是使用 trait 桥接来屏蔽实现细节:
#![allow(unused)] fn main() { pub trait FriendCircle { fn get_published(&self, user: &User) -> Result<Vec<Status>, FriendCircleError>; ... } }
这样,我们的业务逻辑代码可以围绕着这个接口展开,而无需关心它具体的实现是来自 REST API,还是其它什么地方;也不用关心实现做没做 cache、有没有重传机制、具体都会返回什么样的错误(FriendCircleError 就已经提供了所有的出错可能)等等。
使用 trait 提供控制反转
继续看刚才的Engine 代码,在 Engine 和 T 之间通过 TryInto trait 进行了解耦,使得调用者可以灵活处理他们的 T:
#![allow(unused)] fn main() { pub trait Engine { // 生成一个新的 engine fn create<T>(data: T) -> Result<Self> where Self: Sized, T: TryInto<Self>, { data.try_into() .map_err(|_| anyhow!("failed to create engine")) } ... } }
这里还体现了trait 在设计中,另一个很重要的作用,控制反转。
通过使用 trait,我们可以在设计底层库的时候告诉上层: 我需要某个满足 trait X 的数据,因为我依赖这个数据实现的 trait X 方法来完成某些功能,但这个数据具体怎么实现,我不知道,也不关心。
刚才为 Engine 新构建的 create 方法。T 是实现 Engine 所需要的依赖,我们不知道属于类型 T 的 data 是如何在上下文中产生的,也不关心 T 具体是什么,只要 T 实现了 TryInto
使用 trait 做控制反转另一个例子是 第 6 讲 中的 Dialect trait( 代码):
#![allow(unused)] fn main() { pub trait Dialect: Debug + Any { /// Determine if a character starts a quoted identifier. The default /// implementation, accepting "double quoted" ids is both ANSI-compliant /// and appropriate for most dialects (with the notable exception of /// MySQL, MS SQL, and sqlite). You can accept one of characters listed /// in `Word::matching_end_quote` here fn is_delimited_identifier_start(&self, ch: char) -> bool { ch == '"' } /// Determine if a character is a valid start character for an unquoted identifier fn is_identifier_start(&self, ch: char) -> bool; /// Determine if a character is a valid unquoted identifier character fn is_identifier_part(&self, ch: char) -> bool; } }
我们只需要为自己的 SQL 方言实现 Dialect trait:
#![allow(unused)] fn main() { // 创建自己的 sql 方言。TyrDialect 支持 identifier 可以是简单的 url impl Dialect for TyrDialect { fn is_identifier_start(&self, ch: char) -> bool { ('a'..='z').contains(&ch) || ('A'..='Z').contains(&ch) || ch == '_' } // identifier 可以有 ':', '/', '?', '&', '=' fn is_identifier_part(&self, ch: char) -> bool { ('a'..='z').contains(&ch) || ('A'..='Z').contains(&ch) || ('0'..='9').contains(&ch) || [':', '/', '?', '&', '=', '-', '_', '.'].contains(&ch) } } }
就可以让 sql parser 解析我们的 SQL 方言:
#![allow(unused)] fn main() { let ast = Parser::parse_sql(&TyrDialect::default(), sql.as_ref())?; }
这就是 Dialect 这个看似简单的 trait 的强大用途。
对于我们这些使用者来说,通过Dialect trait,可以很方便地注入自己的解析函数,来提供我们的 SQL 方言的额外信息;对于 sqlparser 这个库的作者来说,通过 Dialect trait,他不必关心未来会有多少方言、每个方言长什么样子,只需要方言的作者告诉他如何 tokenize 一个标识符即可。
控制反转是架构中经常使用到的功能,它能够 让调用者和被调用者之间的关系在某个时刻调转过来,被调用者反过来调用调用者提供的能力,二者协同完成一些事情。
比如 MapReduce 的架构:用于 map 的方法和用于 reduce 的方法是啥,MapReduce 的架构设计者并不清楚,但调用者可以把这些方法提供给 MapReduce 架构,由 MapReduce 架构在合适的时候进行调用。
当然,控制反转并非只能由 trait 来完成,但使用 trait 做控制反转会非常灵活,调用者和被调用者只需要关心它们之间的接口,而非具体的数据结构。
用 trait 实现 SOLID 原则
其实刚才介绍的用 trait 做控制反转,核心体现的就是面向对象设计时SOLID原则中的,依赖反转原则DIP,这是一个很重要的构建灵活系统的思想。
在做面向对象设计时,我们经常会探讨 SOLID 原则:
- SRP:单一职责原则,是指每个模块应该只负责单一的功能,不应该让多个功能耦合在一起,而是应该将其组合在一起。
- OCP:开闭原则,是指软件系统应该对修改关闭,而对扩展开放。
- LSP:里氏替换原则,是指如果组件可替换,那么这些可替换的组件应该遵守相同的约束,或者说接口。
- ISP:接口隔离原则,是指使用者只需要知道他们感兴趣的方法,而不该被迫了解和使用对他们来说无用的方法或者功能。
- DIP:依赖反转原则,是指某些场合下底层代码应该依赖高层代码,而非高层代码去依赖底层代码。
虽然 Rust 不是一门面向对象语言,但这些思想都是通用的。
在过去的课程中,我一直强调 SRP 和 OCP。你看 第 6 讲 的 Fetch / Load trait,它们都只负责一个很简单的动作:
#![allow(unused)] fn main() { #[async_trait] pub trait Fetch { type Error; async fn fetch(&self) -> Result<String, Self::Error>; } pub trait Load { type Error; fn load(self) -> Result<DataSet, Self::Error>; } }
以 Fetch 为例,我们先实现了 UrlFetcher,后来又根据需要,实现了 FileFetcher。
FileFetcher 的实现并不会对 UrlFetcher 的实现代码有任何影响,也就是说,在实现 FileFetcher 的时候,已有的所有实现了 Fetch 接口的代码都是稳定的,它们对修改是关闭的;同时,在实现 FileFetcher 的时候,我们扩展了系统的能力,使系统可以根据不同的前缀( from file:// 或者 from <http:// >)进行不同的处理,这是对扩展开放。
前面提到的 SpecTransform / Engine trait,包括 21 讲 中 KV server 里涉及的 CommandService trait:
#![allow(unused)] fn main() { /// 对 Command 的处理的抽象 pub trait CommandService { /// 处理 Command,返回 Response fn execute(self, store: &impl Storage) -> CommandResponse; } }
也是 SRP 和 OCP 原则的践行者。
LSP 里氏替换原则自不必说,我们本文中所有的内容都在践行通过使用接口,来使组件可替换。比如上文提到的 Engine trait,在 KV server 中我们使用的 Storage trait,都允许我们在不改变代码核心逻辑的前提下,替换其中的主要组件。
至于 ISP 接口隔离原则,我们目前撰写的 trait 都很简单,天然满足接口隔离原则。其实,大部分时候,当你的 trait 满足 SRP 单一职责原则时,它也满足接口隔离原则。
但在 Rust 中,有些 trait 的接口可能会比较庞杂, 此时,如果我们想减轻调用者的负担,让它们能够在需要的时候才引入某些接口,可以使用 trait 的继承。比如 AsyncRead / AsyncWrite / Stream 和它们对应的 AsyncReadExt / AsyncWriteExt / StreamExt 等。这样,复杂的接口被不同的 trait 分担了并隔离开。
小结
接口设计是架构设计中最核心的环节。 好的接口容易使用,很难误用,会让使用接口的人产生共鸣。当我们说一段代码读起来/写起来感觉很舒服,或者很不舒服、很冗长、很难看,这种感觉往往就来自于接口给人的感觉,我们可以妥善使用 trait 来降低甚至消除这种不舒服的感觉。
当我们的代码和其他人的代码共存时,接口在不同的组件之间就起到了桥接的作用。通过桥接,甚至可以把原本设计不好的代码,先用接口封装成我们希望的样子,然后实现这个简单的包装,之后再慢慢改动原先不好的设计。
这样,由于系统的其它部分使用新的接口处理,未来改动的影响被控制在很小的范围。在第 5 讲设计 thumbor 的时候我也提到,photon 库并不是一个设计良好的库,然而,通过 Engine trait 的桥接,未来即使我们 fork 一下 photon 库,对其大改,并不会影响 thumbor 的代码。
最后,在软件设计时,我们还要注意 SOLID 原则。基本上, 好的 trait,设计一定是符合 SOLID 原则的,从 Rust 标准库的设计,以及之前讲到的 trait,结合今天的解读,想必你对此有了一定的认识。未来在使用 trait 构建你自己的接口时,你也可以将 SOLID 原则作为一个备忘清单,随时检查。
思考题
Rust 下有一个处理 Web 前端的库叫 yew。请 clone 到你本地,然后使用 ag 或者 rgrep(eat our own dogfood)查找一下所有的 trait 定义,看看这些 trait 被设计的目的和意义,并且着重阅读一下它最核心的 Component trait,思考几个问题:
- Component trait 可以做 trait object 么?
- 关联类型 Message 和 Properties 的作用是什么?
- 作为使用者,该如何用 Component trait?它的 lifecycle 是什么样子的?
- 如果你之前有前端开发的经验,比较一下 React / Vue / Elm component 和 yew component 的区别?
#![allow(unused)] fn main() { yew on master via 🦀 v1.55.0 ❯ rgrep "pub trait" "**/*.rs" examples/router/src/generator.rs 155:1 pub trait Generated: Sized { packages/yew/src/html/component/mod.rs 42:1 pub trait Component: Sized + 'static { packages/yew/src/html/component/properties.rs 6:1 pub trait Properties: PartialEq { examples/boids/src/math.rs 128:1 pub trait WeightedMean<T = Self>: Sized { 152:1 pub trait Mean<T = Self>: Sized { packages/yew/src/functional/mod.rs 69:1 pub trait FunctionProvider { packages/yew/src/html/conversion.rs 5:1 pub trait ImplicitClone: Clone {} 18:1 pub trait IntoPropValue<T> { packages/yew/src/html/listener/mod.rs 27:1 pub trait TargetCast 136:1 pub trait IntoEventCallback<EVENT> { packages/yew/src/scheduler.rs 11:1 pub trait Runnable { packages/yew-router/src/routable.rs 16:1 pub trait Routable: Sized + Clone { packages/yew-agent/src/pool.rs 60:1 pub trait Dispatched: Agent + Sized + 'static { 78:1 pub trait Dispatchable {} packages/yew/src/html/component/scope.rs 508:1 pub trait SendAsMessage<COMP: Component> { packages/yew-macro/src/stringify.rs 16:1 pub trait Stringify { packages/yew-agent/src/lib.rs 22:1 pub trait Agent: Sized + 'static { 82:1 pub trait Discoverer { 92:1 pub trait Bridge<AGN: Agent> { 98:1 pub trait Bridged: Agent + Sized + 'static { packages/yew-agent/src/utils/store.rs 20:1 pub trait Store: Sized + 'static { 138:1 pub trait Bridgeable: Sized + 'static { packages/yew-macro/src/html_tree/mod.rs 178:1 pub trait ToNodeIterator { packages/yew/src/virtual_dom/listeners.rs 42:1 pub trait Listener { packages/yew-agent/src/worker/mod.rs 17:1 pub trait Threaded { 24:1 pub trait Packed { }
感谢你的阅读,如果你觉得有收获,也欢迎你分享给身边的朋友,邀他一起讨论。今天你已经完成Rust学习的第25次打卡啦,我们下节课见!
加餐|Rust2021版次问世了!
你好,我是陈天。
千呼万唤始出来的 Rust 2021 edition(下称版次),终于伴随着 1.56 版本出来了。在使用 rustup update stable 完成工具链的升级之后,小伙伴们就可以尝试着把自己之前的代码升级到 2021 版了。
具体做法很简单:
cargo fix --edition- 修改 Cargo.toml,替换 edition = “2021”
cargo build/cargo test确保一切正常
在做第一步之前,记得先把未提交的代码提交。
如果你是初次涉猎 Rust 的同学,可能不清楚 Rust 中“版次”的作用,它是一个非常巧妙的、向后兼容的发布工具。
不知道在其它编程语言中有没有类似的概念,反正我所了解的语言,没有类似的东西。C++ 虽然允许你编译 lib A 时用 --std=C++17,编译 lib B 时用 --std=C++20,但这种用法有不少局限,用起来也没有版次这么清爽。我们先对它的理解达成一致,再聊这次“版次”更新的重点内容。
在 Rust 中,版次之间可能会有不同的保留字和缺省行为。比如 2018的 async / await / dyn,在 2015 中就没有严格保留成关键字。
假设语言在迭代的过程中发现 actor 需要成为保留字,但如果将其设置为保留字就会破坏兼容性,会让之前把 actor 当成普通名称使用的代码无法编译通过。怎么办呢?升级大版本,让代码分裂成不兼容的 v1 和 v2 么?这个问题是令所有语言开发者头疼的事情。
语言总是要发展的,总会从不完善到完善,所以,一开始考虑不周,后来不得不通过破坏性更新来弥补的事情,屡见不鲜。
升级大版本号,是之前处理这类问题的惯常手段。
然而,对于库的作者来说,如果他不想升级大版本或者受限于某些原因无法很快升级,最终,要么是使用这个库的开发者只好坚守在 v1,要么是使用这个库的开发者不得不找到对应的和 v2 兼容的替代品。但无论哪种方式,整个生态环境都会受到撕裂。
Rust 通过“版次”非常聪明地解决了这个问题。库的作者还是以旧的版次发布他的代码,使用库的开发者可以选择他们想使用最新的版次,二者可以完全不一致, 编译时,Rust 编译器以旧的版次的功能编译旧的库,而以新的版次编译使用者的代码。
看一个实际例子吧。在 crates.io 里我随便搜了一个最后更新止步于三年前的库 rbpf。看它的 Cargo.toml,这是个 2015 版次的库(不声明版次就意味着 2015),和现在的代码断了两代。我们来尝试创建一个 2021 版次的 crate,同时引入这个库,以及 2018 版次的 futures 库,看有没有问题。
首先,确保你的 Rust 升级到了 1.56。然后 cargo new test-rust-edition。在生成的项目里,为 Cargo.toml 加入:
#![allow(unused)] fn main() { [package] name = "test-rust-edition" version = "0.1.0" edition = "2021" [dependencies] rbpf = "0.1.0" futures = "0.3" }
这里我故意让两个本来是不兼容的 crate 放在一起看看是否可以协同工作。futures 使用了 async/await,这是 Rust 2018 才引入的关键字,但 rbpf 使用的 2015 版次。
修改好 Cargo.toml 后,我们在 src/main.rs 中拷入:
use futures::executor::block_on; fn main() { // This is the eBPF program, in the form of bytecode instructions. let prog = &[ 0xb4, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, // mov32 r0, 0 0xb4, 0x01, 0x00, 0x00, 0x02, 0x00, 0x00, 0x00, // mov32 r1, 2 0x04, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00, 0x00, // add32 r0, 1 0x0c, 0x10, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, // add32 r0, r1 0x95, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, // exit ]; // Instantiate a struct EbpfVmNoData. This is an eBPF VM for programs that // takes no packet data in argument. // The eBPF program is passed to the constructor. let vm = rbpf::EbpfVmNoData::new(Some(prog)).unwrap(); block_on(async move { dummy(vm.execute_program().unwrap()).await; }); } async fn dummy(result: u64) { println!("hello world! Result is {} (should be 0x3)", result); }
这个代码在做什么我们不用关心,只需要关心它能不能在 2021 版次的 crate 里跑起来, cargo run 后,发现 rbpf 和 futures 融洽地处在了一起。
一份代码,使用了三个版次的代码,却能够无缝对接,我们使用的时候甚至可以不用关心谁是什么版次,你说厉害不厉害?
所以你看,版次起到了防火墙的作用,使得整个生态系统不用分裂,大家无需改动,依旧能够各司其职。这就是版次对 Rust 最大的贡献。如果你经历过 Python2 到 Python3 升级过程中的巨大阵痛,那应该能够非常感激 Rust 引入了这么个非常重要的概念。
Rust 2021 包括了什么新东西?
在你理解 Rust 2021 版次的意义之后,再来看看对我们影响最大的几个更新。
闭包的不相交捕获
在 2021 之前,哪怕你只用到了其中一个域,闭包也需要捕获整个数据结构,即使是引用。但是 2021 之后,闭包可以只捕获需要的域。
比如下面的 代码:
struct Employee { name: String, title: String, } fn main() { let tom = Employee { name: "Tom".into(), title: "Engineer".into(), }; drop(tom.name); println!("title: {}", tom.title); // 之前这句不能工作,2021 可以编译 let c = || println!("{}", tom.title); c(); }
闭包的不相交捕获对我们使用的好处是,那些闭包中捕获了结构体的一部分字段,而其它地方又用了另一部分与之不相交的字段,原本在 2018 中是编译不过的,你只能 clone() 这个结构体满足双方的需要,现在可以编译通过。
feature resolver
依赖管理是一个难题,其中最困难的部分之一就是在依赖两个不同的包时,选择要使用的依赖版本。这里指的不仅包括其版本号,还包括为该软件包启用或未启用的功能(feature)。因为Cargo 的默认行为是在依赖中多次引用单个包时合并所用到的功能。
例如,假设你有一个名为 Foo 的 crate,其中有 A 和 B 两个功能,该依赖项被包 bar 和 baz 使用,但 bar 依赖 Foo + A,而 baz 依赖 Foo + B。Cargo 会合并这两个功能并编译 Foo + A B。
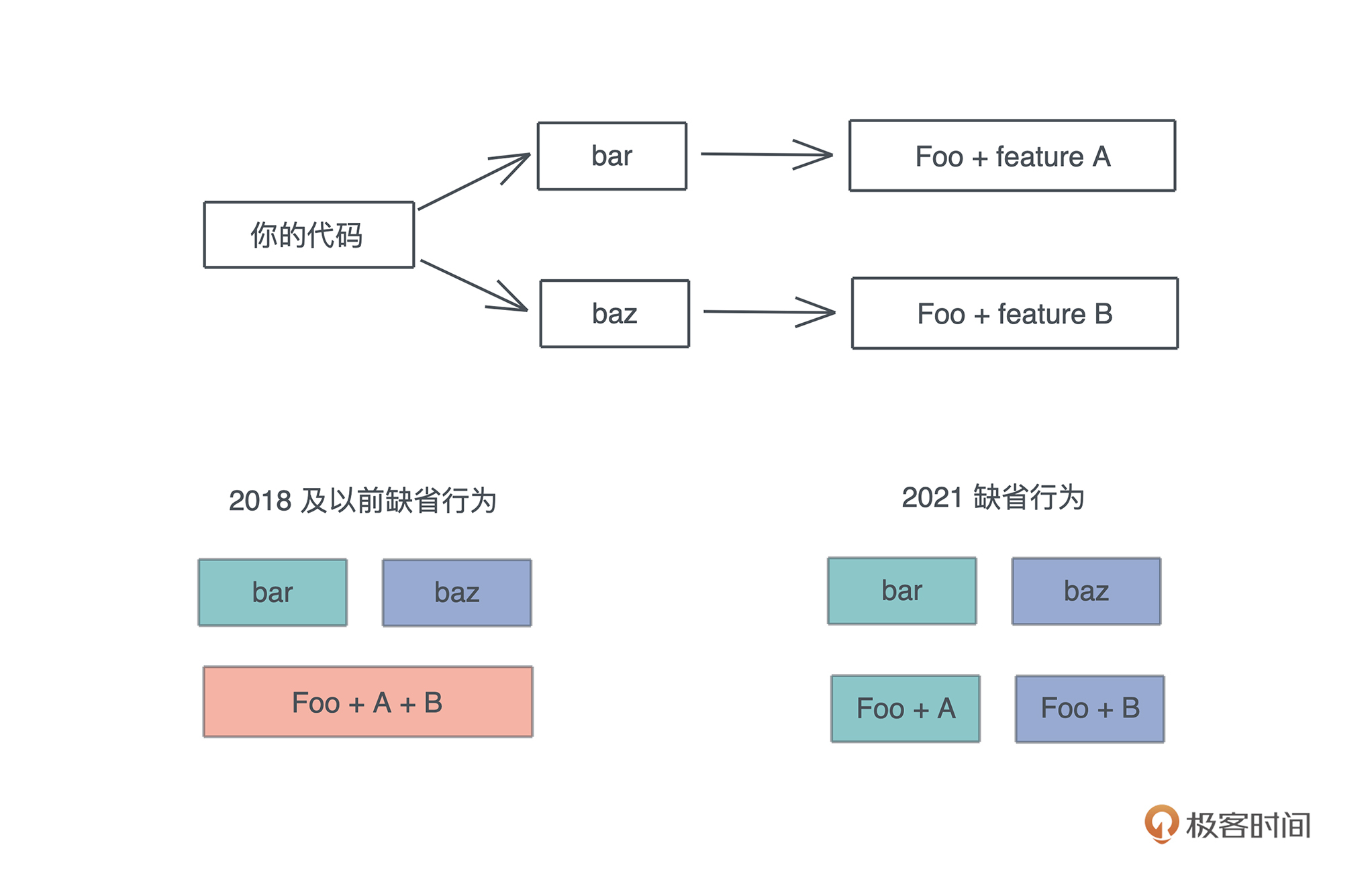
这确实有一个好处,你只需要编译一次 Foo,就可以被 bar 和 baz 使用。但是,如果 A 和 B 不应该一起编译呢?如果你对这样的场景感兴趣,可以看下面的 Rust 1.51 编译策略的链接。这是 Rust 一个长期存在并困扰社区的问题。
之前 Rust 1.51 终于提供了新的方法,通过不同的 编译策略 解决这一问题。如今,这个策略已经成为 2021 的缺省行为,它会带来一些编译速度的损失,但会让编译结果更加精确。
新的 prelude
任何语言都会缺省引入某些命名空间下的一些非常常见的行为,这样让开发者使用起来很方便。Rust 也不例外,它会缺省引入一些 trait 、数据结构和宏,比如我们使用的 From / Into 这样的 trait、Vec 这样的数据结构,以及 println! / vec! 这样的宏。这样在写代码的时候,就不需要频繁地使用 use。
在 2021 版次中,TryInto、TryFrom 和 FromIterator 默认被引入到 prelude 中,我们不再需要使用 use 声明了。比如现在下面的语句就没必要了,因为 prelude 已经包含了:
#![allow(unused)] fn main() { use std::convert::TryFrom; }
小结
总的来说,Rust 2021 不是一个大的版次更新,里面只包含了少量和之前版本不兼容的地方。未来 3 年,Rust 都将稳定在这个版次上。
也许你会不理解:搞这么大动静,就这?但这正是 Rust 当初设计用心良苦的地方。
三年内,以 6 周为单位,不断迭代新的功能,风雨无阻,但不引入破坏性更新,或者用某些编译选项将其隔离,使用者必须手工打开(比如 resolver = “2”);三年期满,升级版次,一次性把这三年内潜在的破坏性更新,以及可预见的未来会引入的破坏性更新(比如保留新的关键字),通过版次来区隔。
版次中出现的大动作越少,就说明语言越趋向成熟。
好,关于 2021 版次的介绍就到这里,还有一些其它的修改,这里我就不赘述了,感兴趣的可以看 发布文档。这门课的代码仓库 tyrchen/geektime-rust 也随之升级到了 2021 版次,具体修改你可以看这个 pull request。
阶段实操(3):构建一个简单的KV server-高级trait技巧
你好,我是陈天。
到现在,泛型的基础知识、具体如何使用以及设计理念,我们已经学得差不多了,也和函数作了类比帮助你理解,泛型就是数据结构的函数。
如果你觉得泛型难学,是因为它的抽象层级比较高,需要足够多的代码阅读和撰写的历练。所以,通过学习,现阶段你能够看懂包含泛型的代码就够了,至于使用,只能靠你自己在后续练习中不断体会总结。如果实在觉得不好懂, 某种程度上说,你缺乏的不是泛型的能力,而是设计和架构的能力。
今天我们就用之前1.0版简易的 KV store 来历练一把,看看怎么把之前学到的知识融入代码中。
在 21 讲、 22讲 中,我们已经完成了 KV store 的基本功能,但留了两个小尾巴:
- Storage trait 的 get_iter() 方法没有实现;
- Service 的 execute() 方法里面还有一些 TODO,需要处理事件的通知。
我们一个个来解决。先看 get_iter() 方法。
处理 Iterator
在开始撰写代码之前,先把之前在 src/storage/mod.rs 里注掉的测试,加回来:
#![allow(unused)] fn main() { #[test] fn memtable_iter_should_work() { let store = MemTable::new(); test_get_iter(store); } }
然后在 src/storge/memory.rs 里尝试实现它。
#![allow(unused)] fn main() { impl Storage for MemTable { ... fn get_iter(&self, table: &str) -> Result<Box<dyn Iterator<Item = Kvpair>>, KvError> { // 使用 clone() 来获取 table 的 snapshot let table = self.get_or_create_table(table).clone(); let iter = table .iter() .map(|v| Kvpair::new(v.key(), v.value().clone())); Ok(Box::new(iter)) // <-- 编译出错 } } }
很不幸的,编译器提示我们 Box::new(iter) 不行,“cannot return value referencing local variable table” 。这让人很不爽,究其原因,table.iter() 使用了 table 的引用,我们返回 iter,但 iter 引用了作为局部变量的 table,所以无法编译通过。
此刻,我们需要有一个能够完全占有 table 的迭代器。Rust 标准库里提供了一个 trait IntoIterator,它可以把数据结构的所有权转移到 Iterator 中,看它的声明( 代码):
#![allow(unused)] fn main() { pub trait IntoIterator { type Item; type IntoIter: Iterator<Item = Self::Item>; fn into_iter(self) -> Self::IntoIter; } }
绝大多数的集合类数据结构都 实现了它。DashMap 也实现了它,所以我们可以用 table.into_iter() 把 table 的所有权转移给 iter:
#![allow(unused)] fn main() { impl Storage for MemTable { ... fn get_iter(&self, table: &str) -> Result<Box<dyn Iterator<Item = Kvpair>>, KvError> { // 使用 clone() 来获取 table 的 snapshot let table = self.get_or_create_table(table).clone(); let iter = table.into_iter().map(|data| data.into()); Ok(Box::new(iter)) } } }
这里又遇到了数据转换,从 DashMap 中 iterate 出来的值 (String, Value) 需要转换成 Kvpair,我们依旧用 into() 来完成这件事。为此,需要为 Kvpair 实现这个简单的 From trait:
#![allow(unused)] fn main() { impl From<(String, Value)> for Kvpair { fn from(data: (String, Value)) -> Self { Kvpair::new(data.0, data.1) } } }
这两段代码都放在 src/storage/memory.rs 下。
Bingo!这个代码可以编译通过。现在如果运行 cargo test 进行测试的话,对 get_iter() 接口的测试也能通过。
虽然这个代码可以通过测试,并且本身也非常精简,我们 还是有必要思考一下,如果以后想为更多的 data store 实现 Storage trait,都会怎样处理 get_iter() 方法?
我们会:
- 拿到一个关于某个 table 下的拥有所有权的 Iterator
- 对 Iterator 做 map
- 将 map 出来的每个 item 转换成 Kvpair
这里的第 2 步对于每个 Storage trait 的 get_iter() 方法的实现来说,都是相同的。有没有可能把它封装起来呢?使得 Storage trait 的实现者只需要提供它们自己的拥有所有权的 Iterator,并对 Iterator 里的 Item 类型提供 Into
来尝试一下,在 src/storage/mod.rs 中,构建一个 StorageIter,并实现 Iterator trait:
#![allow(unused)] fn main() { /// 提供 Storage iterator,这样 trait 的实现者只需要 /// 把它们的 iterator 提供给 StorageIter,然后它们保证 /// next() 传出的类型实现了 Into<Kvpair> 即可 pub struct StorageIter<T> { data: T, } impl<T> StorageIter<T> { pub fn new(data: T) -> Self { Self { data } } } impl<T> Iterator for StorageIter<T> where T: Iterator, T::Item: Into<Kvpair>, { type Item = Kvpair; fn next(&mut self) -> Option<Self::Item> { self.data.next().map(|v| v.into()) } } }
这样,我们在 src/storage/memory.rs 里对 get_iter() 的实现,就可以直接使用 StorageIter 了。不过,还要为 DashMap 的 Iterator 每次调用 next() 得到的值 (String, Value) ,做个到 Kvpair 的转换:
#![allow(unused)] fn main() { impl Storage for MemTable { ... fn get_iter(&self, table: &str) -> Result<Box<dyn Iterator<Item = Kvpair>>, KvError> { // 使用 clone() 来获取 table 的 snapshot let table = self.get_or_create_table(table).clone(); let iter = StorageIter::new(table.into_iter()); // 这行改掉了 Ok(Box::new(iter)) } } }
我们可以再次使用 cargo test 测试,同样通过!
如果回顾刚才撰写的代码,你可能会哑然一笑:我辛辛苦苦又写了 20 行代码,创建了一个新的数据结构,就是为了 get_iter() 方法里的一行代码改得更漂亮?何苦呢?
的确,在这个 KV server 的例子里,这样的抽象收益不大。但是,如果刚才那个步骤不是 3 步,而是 5 步/10 步,其中大量的步骤都是相同的,也就是说,我们每实现一个新的 store,就要撰写相同的代码逻辑,那么,这个抽象就非常有必要了。
支持事件通知
好,我们再来看事件通知。在 src/service/mod.rs 中(以下代码,如无特殊声明,都是在 src/service/mod.rs 中),目前的 execute() 方法还有很多 TODO 需要解决:
#![allow(unused)] fn main() { pub fn execute(&self, cmd: CommandRequest) -> CommandResponse { debug!("Got request: {:?}", cmd); // TODO: 发送 on_received 事件 let res = dispatch(cmd, &self.inner.store); debug!("Executed response: {:?}", res); // TODO: 发送 on_executed 事件 res } }
为了解决这些 TODO,我们需要提供事件通知的机制:
- 在创建 Service 时,注册相应的事件处理函数;
- 在 execute() 方法执行时,做相应的事件通知,使得注册的事件处理函数可以得到执行。
先看事件处理函数如何注册。
如果想要能够注册,那么倒推也就是,Service/ServiceInner 数据结构就需要有地方能够承载事件注册函数。可以尝试着把它加在 ServiceInner 结构里:
#![allow(unused)] fn main() { /// Service 内部数据结构 pub struct ServiceInner<Store> { store: Store, on_received: Vec<fn(&CommandRequest)>, on_executed: Vec<fn(&CommandResponse)>, on_before_send: Vec<fn(&mut CommandResponse)>, on_after_send: Vec<fn()>, } }
按照 21 讲的设计,我们提供了四个事件:
- on_received:当服务器收到 CommandRequest 时触发;
- on_executed:当服务器处理完 CommandRequest 得到 CommandResponse 时触发;
- on_before_send:在服务器发送 CommandResponse 之前触发。注意这个接口提供的是 &mut CommandResponse,这样事件的处理者可以根据需要,在发送前,修改 CommandResponse。
- on_after_send:在服务器发送完 CommandResponse 后触发。
在撰写事件注册的代码之前,还是先写个测试,从使用者的角度,考虑如何进行注册:
#![allow(unused)] fn main() { #[test] fn event_registration_should_work() { fn b(cmd: &CommandRequest) { info!("Got {:?}", cmd); } fn c(res: &CommandResponse) { info!("{:?}", res); } fn d(res: &mut CommandResponse) { res.status = StatusCode::CREATED.as_u16() as _; } fn e() { info!("Data is sent"); } let service: Service = ServiceInner::new(MemTable::default()) .fn_received(|_: &CommandRequest| {}) .fn_received(b) .fn_executed(c) .fn_before_send(d) .fn_after_send(e) .into(); let res = service.execute(CommandRequest::new_hset("t1", "k1", "v1".into())); assert_eq!(res.status, StatusCode::CREATED.as_u16() as _); assert_eq!(res.message, ""); assert_eq!(res.values, vec![Value::default()]); } }
从测试代码中可以看到,我们希望通过 ServiceInner 结构,不断调用 fn_xxx 方法,为 ServiceInner 注册相应的事件处理函数;添加完毕后,通过 into() 方法,我们再把 ServiceInner 转换成 Service。这是一个经典的 构造者模式(Builder Pattern),在很多 Rust 代码中,都能看到它的身影。
那么,诸如 fn_received() 这样的方法有什么魔力呢?它为什么可以一路做链式调用呢?答案很简单,它把 self 的所有权拿过来,处理完之后,再返回 self。所以,我们继续添加如下代码:
#![allow(unused)] fn main() { impl<Store: Storage> ServiceInner<Store> { pub fn new(store: Store) -> Self { Self { store, on_received: Vec::new(), on_executed: Vec::new(), on_before_send: Vec::new(), on_after_send: Vec::new(), } } pub fn fn_received(mut self, f: fn(&CommandRequest)) -> Self { self.on_received.push(f); self } pub fn fn_executed(mut self, f: fn(&CommandResponse)) -> Self { self.on_executed.push(f); self } pub fn fn_before_send(mut self, f: fn(&mut CommandResponse)) -> Self { self.on_before_send.push(f); self } pub fn fn_after_send(mut self, f: fn()) -> Self { self.on_after_send.push(f); self } } }
这样处理之后呢,Service 之前的 new() 方法就没有必要存在了,可以把它删除。同时,我们需要为 Service 类型提供一个 From
#![allow(unused)] fn main() { impl<Store: Storage> From<ServiceInner<Store>> for Service<Store> { fn from(inner: ServiceInner<Store>) -> Self { Self { inner: Arc::new(inner), } } } }
目前,代码中几处使用了 Service::new() 的地方需要改成使用 ServiceInner::new(),比如:
#![allow(unused)] fn main() { // 我们需要一个 service 结构至少包含 Storage // let service = Service::new(MemTable::default()); let service: Service = ServiceInner::new(MemTable::default()).into(); }
全部改动完成后,代码可以编译通过。
然而,如果运行 cargo test,新加的测试会失败:
test service::tests::event_registration_should_work ... FAILED
这是因为,我们虽然完成了事件处理函数的注册,但现在还没有发事件通知。
另外因为我们的事件包括不可变事件(比如 on_received)和可变事件(比如 on_before_send),所以事件通知需要把二者分开。来定义两个 trait:Notify 和 NotifyMut:
#![allow(unused)] fn main() { /// 事件通知(不可变事件) pub trait Notify<Arg> { fn notify(&self, arg: &Arg); } /// 事件通知(可变事件) pub trait NotifyMut<Arg> { fn notify(&self, arg: &mut Arg); } }
这两个 trait 是泛型 trait,其中的 Arg 参数,对应事件注册函数里的 arg,比如:
fn(&CommandRequest);
由此,我们可以特地为 Vec<fn(&Arg)> 和 Vec<fn(&mut Arg)> 实现事件处理,它们涵盖了目前支持的几种事件:
#![allow(unused)] fn main() { impl<Arg> Notify<Arg> for Vec<fn(&Arg)> { #[inline] fn notify(&self, arg: &Arg) { for f in self { f(arg) } } } impl<Arg> NotifyMut<Arg> for Vec<fn(&mut Arg)> { #[inline] fn notify(&self, arg: &mut Arg) { for f in self { f(arg) } } } }
Notify / NotifyMut trait 实现好之后,我们就可以修改 execute() 方法了:
#![allow(unused)] fn main() { impl<Store: Storage> Service<Store> { pub fn execute(&self, cmd: CommandRequest) -> CommandResponse { debug!("Got request: {:?}", cmd); self.inner.on_received.notify(&cmd); let mut res = dispatch(cmd, &self.inner.store); debug!("Executed response: {:?}", res); self.inner.on_executed.notify(&res); self.inner.on_before_send.notify(&mut res); if !self.inner.on_before_send.is_empty() { debug!("Modified response: {:?}", res); } res } } }
现在,相应的事件就可以被通知到相应的处理函数中了。这个通知机制目前还是同步的函数调用,未来如果需要,我们可以将其改成消息传递,进行异步处理。
好,现在测试应该可以工作了,cargo test 所有的测试都通过。
为持久化数据库实现 Storage trait
到目前为止,我们的 KV store 还都是一个在内存中的 KV store。一旦终止应用程序,用户存储的所有 key / value 都会消失。我们希望存储能够持久化。
一个方案是为 MemTable 添加 WAL 和 disk snapshot 支持,让用户发送的所有涉及更新的命令都按顺序存储在磁盘上,同时定期做 snapshot,便于数据的快速恢复;另一个方案是使用已有的 KV store,比如 RocksDB,或者 sled。
RocksDB 是 Facebook 在 Google 的 levelDB 基础上开发的嵌入式 KV store,用 C++ 编写,而 sled 是 Rust 社区里涌现的优秀的 KV store,对标 RocksDB。二者功能很类似,从演示的角度,sled 使用起来更简单,更加适合今天的内容,如果在生产环境中使用,RocksDB 更加合适,因为它在各种复杂的生产环境中经历了千锤百炼。
所以,我们今天就尝试为 sled 实现 Storage trait,让它能够适配我们的 KV server。
首先在 Cargo.toml 里引入 sled:
#![allow(unused)] fn main() { sled = "0.34" # sled db }
然后创建 src/storage/sleddb.rs,并添加如下代码:
#![allow(unused)] fn main() { use sled::{Db, IVec}; use std::{convert::TryInto, path::Path, str}; use crate::{KvError, Kvpair, Storage, StorageIter, Value}; #[derive(Debug)] pub struct SledDb(Db); impl SledDb { pub fn new(path: impl AsRef<Path>) -> Self { Self(sled::open(path).unwrap()) } // 在 sleddb 里,因为它可以 scan_prefix,我们用 prefix // 来模拟一个 table。当然,还可以用其它方案。 fn get_full_key(table: &str, key: &str) -> String { format!("{}:{}", table, key) } // 遍历 table 的 key 时,我们直接把 prefix: 当成 table fn get_table_prefix(table: &str) -> String { format!("{}:", table) } } /// 把 Option<Result<T, E>> flip 成 Result<Option<T>, E> /// 从这个函数里,你可以看到函数式编程的优雅 fn flip<T, E>(x: Option<Result<T, E>>) -> Result<Option<T>, E> { x.map_or(Ok(None), |v| v.map(Some)) } impl Storage for SledDb { fn get(&self, table: &str, key: &str) -> Result<Option<Value>, KvError> { let name = SledDb::get_full_key(table, key); let result = self.0.get(name.as_bytes())?.map(|v| v.as_ref().try_into()); flip(result) } fn set(&self, table: &str, key: String, value: Value) -> Result<Option<Value>, KvError> { let name = SledDb::get_full_key(table, &key); let data: Vec<u8> = value.try_into()?; let result = self.0.insert(name, data)?.map(|v| v.as_ref().try_into()); flip(result) } fn contains(&self, table: &str, key: &str) -> Result<bool, KvError> { let name = SledDb::get_full_key(table, &key); Ok(self.0.contains_key(name)?) } fn del(&self, table: &str, key: &str) -> Result<Option<Value>, KvError> { let name = SledDb::get_full_key(table, &key); let result = self.0.remove(name)?.map(|v| v.as_ref().try_into()); flip(result) } fn get_all(&self, table: &str) -> Result<Vec<Kvpair>, KvError> { let prefix = SledDb::get_table_prefix(table); let result = self.0.scan_prefix(prefix).map(|v| v.into()).collect(); Ok(result) } fn get_iter(&self, table: &str) -> Result<Box<dyn Iterator<Item = Kvpair>>, KvError> { let prefix = SledDb::get_table_prefix(table); let iter = StorageIter::new(self.0.scan_prefix(prefix)); Ok(Box::new(iter)) } } impl From<Result<(IVec, IVec), sled::Error>> for Kvpair { fn from(v: Result<(IVec, IVec), sled::Error>) -> Self { match v { Ok((k, v)) => match v.as_ref().try_into() { Ok(v) => Kvpair::new(ivec_to_key(k.as_ref()), v), Err(_) => Kvpair::default(), }, _ => Kvpair::default(), } } } fn ivec_to_key(ivec: &[u8]) -> &str { let s = str::from_utf8(ivec).unwrap(); let mut iter = s.split(":"); iter.next(); iter.next().unwrap() } }
这段代码主要就是在实现 Storage trait。每个方法都很简单,就是在 sled 提供的功能上增加了一次封装。如果你对代码中某个调用有疑虑,可以参考 sled 的文档。
在 src/storage/mod.rs 里引入 sleddb,我们就可以加上相关的测试,测试新的 Storage 实现啦:
#![allow(unused)] fn main() { mod sleddb; pub use sleddb::SledDb; #[cfg(test)] mod tests { use tempfile::tempdir; use super::*; ... #[test] fn sleddb_basic_interface_should_work() { let dir = tempdir().unwrap(); let store = SledDb::new(dir); test_basi_interface(store); } #[test] fn sleddb_get_all_should_work() { let dir = tempdir().unwrap(); let store = SledDb::new(dir); test_get_all(store); } #[test] fn sleddb_iter_should_work() { let dir = tempdir().unwrap(); let store = SledDb::new(dir); test_get_iter(store); } } }
因为 SledDb 创建时需要指定一个目录,所以要在测试中使用 tempfile 库,它能让文件资源在测试结束时被回收。我们在 Cargo.toml 中引入它:
#![allow(unused)] fn main() { [dev-dependencies] ... tempfile = "3" # 处理临时目录和临时文件 ... }
代码目前就可以编译通过了。如果你运行 cargo test 测试,会发现所有测试都正常通过!
构建新的 KV server
现在完成了 SledDb 和事件通知相关的实现,我们可以尝试构建支持事件通知,并且使用 SledDb 的 KV server 了。把 examples/server.rs 拷贝出 examples/server_with_sled.rs,然后修改 let service 那一行:
#![allow(unused)] fn main() { // let service: Service = ServiceInner::new(MemTable::new()).into(); let service: Service<SledDb> = ServiceInner::new(SledDb::new("/tmp/kvserver")) .fn_before_send(|res| match res.message.as_ref() { "" => res.message = "altered. Original message is empty.".into(), s => res.message = format!("altered: {}", s), }) .into(); }
当然,需要引入 SledDb 让编译通过。你看,只需要在创建 KV server 时使用 SledDb,就可以实现 data store 的切换,未来还可以进一步通过配置文件,来选择使用什么样的 store。非常方便。
新的 examples/server_with_sled.rs 的完整的代码:
use anyhow::Result; use async_prost::AsyncProstStream; use futures::prelude::*; use kv1::{CommandRequest, CommandResponse, Service, ServiceInner, SledDb}; use tokio::net::TcpListener; use tracing::info; #[tokio::main] async fn main() -> Result<()> { tracing_subscriber::fmt::init(); let service: Service<SledDb> = ServiceInner::new(SledDb::new("/tmp/kvserver")) .fn_before_send(|res| match res.message.as_ref() { "" => res.message = "altered. Original message is empty.".into(), s => res.message = format!("altered: {}", s), }) .into(); let addr = "127.0.0.1:9527"; let listener = TcpListener::bind(addr).await?; info!("Start listening on {}", addr); loop { let (stream, addr) = listener.accept().await?; info!("Client {:?} connected", addr); let svc = service.clone(); tokio::spawn(async move { let mut stream = AsyncProstStream::<_, CommandRequest, CommandResponse, _>::from(stream).for_async(); while let Some(Ok(cmd)) = stream.next().await { info!("Got a new command: {:?}", cmd); let res = svc.execute(cmd); stream.send(res).await.unwrap(); } info!("Client {:?} disconnected", addr); }); } }
它和之前的 server 几乎一样,只有 11 行生成 service 的代码应用了新的 storage,并且引入了事件通知。
完成之后,我们可以打开一个命令行窗口,运行: RUST_LOG=info cargo run --example server_with_sled --quiet。然后在另一个命令行窗口,运行: RUST_LOG=info cargo run --example client --quiet。
此时,服务器和客户端都收到了彼此的请求和响应,并且处理正常。如果你停掉服务器,再次运行,然后再运行客户端,会发现,客户端在尝试 HSET 时得到了服务器旧的值,我们的新版 KV server 可以对数据进行持久化了。
此外,如果你注意看 client 的日志,会发现原本应该是空字符串的 messag 包含了 “altered. Original message is empty.”:
❯ RUST_LOG=info cargo run --example client --quiet
Sep 23 22:09:12.215 INFO client: Got response CommandResponse { status: 200, message: "altered. Original message is empty.", values: [Value { value: Some(String("world")) }], pairs: [] }
这是因为,我们的服务器注册了 fn_before_send 的事件通知,对返回的数据做了修改。未来我们可以用这些事件做很多事情,比如监控数据的发送,甚至写 WAL。
小结
今天的课程我们进一步认识到了 trait 的威力。当为系统设计了合理的 trait ,整个系统的可扩展性就大大增强,之后在添加新的功能的时候,并不需要改动多少已有的代码。
在使用 trait 做抽象时,我们要衡量,这么做的好处是什么,它未来可以为实现者带来什么帮助。就像我们撰写的 StorageIter,它实现了 Iterator trait,并封装了 map 的处理逻辑,让这个公共的步骤可以在 Storage trait 中复用。
除此之外,也进一步熟悉了如何为带泛型参数的数据结构实现 trait。我们不仅可以为具体的数据结构实现 trait,也可以为更笼统的泛型参数实现 trait。除了文中这个例子:
#![allow(unused)] fn main() { impl<Arg> Notify<Arg> for Vec<fn(&Arg)> { #[inline] fn notify(&self, arg: &Arg) { for f in self { f(arg) } } } }
其实之前还见到过:
#![allow(unused)] fn main() { impl<T, U> Into<U> for T where U: From<T>, { fn into(self) -> U { U::from(self) } } }
也是一样的道理。
如果结合这一讲和第 21、 22 讲,你会发现,我们目前完成了一个功能比较完整的 KV server 的核心逻辑,但是,整体的代码似乎没有太多复杂的生命周期标注,或者太过抽象的泛型结构。
是的,别看我们在介绍 Rust 的基础知识时,扎的比较深,但是大多数写代码的时候,并不会用到那么深的知识。Rust 编译器会尽最大的努力,让你的代码简单。如果你用 clippy 这样的 linter 的话,它还会进一步给你提一些建议,让你的代码更加简单。
那么,为什么我们还要讲那么深入呢?
这是因为我们在写代码的时候不可避免地要引入第三方库,你也看到了, 在写这个项目的时候用了不少依赖,当你使用这些库的时候,又不可避免地要阅读一些它们的源码,而这些源码,可能有各种各样复杂的写法。这也是为什么在开头我会说,现阶段能看懂包含泛型的代码就可以了。
深入地了解 Rust 的基础知识,可以帮我们更快更清晰地阅读源码,而更快更清晰地读懂别人的源码,又可以更快地帮助我们用好别人的库,从而写好我们的代码。
思考题
- 如果你在 21 讲已经完成了 KV server 其它的 6 个命令,可以对照着我在 GitHub repo 里的代码和测试,看看你写的结果。
- 我们的 Notify 和 NotifyMut trait 目前只能做到通知,无法告诉 execute 提前结束处理并直接给客户端返回错误。试着修改一下这两个 trait,让它具备提前结束整个 pipeline 的能力。
- RocksDB 是一个非常优秀的 KV DB,它有对应的 rust 库。尝试着为 RocksDB 实现 Storage trait,然后写个 example server 应用它。
感谢你的收听,你已经完成了Rust学习的第26次打卡,如果你觉得有收获,也欢迎你分享给身边的朋友,邀他一起讨论。我们下节课见~
生态系统:有哪些常有的Rust库可以为我所用?
你好,我是陈天。
一门编程语言的能力,语言本身的设计占了四成,围绕着语言打造的生态系统占了六成。
之前 我们对比过 Golang 和 Rust,在我看来,Golang 是一门优点和缺点同样突出的语言,Golang 的某些缺点甚至是很严重的,然而,在 Google 的大力加持下,借助微服务和云原生的春风,Golang 构建了一个非常宏大的生态系统。基本上,如果你要做微服务,Golang 完善的第三方库能够满足你几乎所有的需求。
所以,生态可以弥补语言的劣势, 编程语言对外展现出来的能力是语言+生态的一个合集。
举个例子,由于不支持宏编程,Golang 在开发很多项目时不得不引入大量的脚手架代码,这些脚手架代码如果自己写,费时费力,但是社区里会有一大票优秀的框架,帮助你生成这些脚手架代码。
典型的比如 kubebuilder,它直接把开发 Kubernetes 下 operator 的门槛降了一大截,如果没有类似的工具,用 Golang 开发 Kubernetes 并不比 Python 来得容易。反之,承蒙在 data science 和 machine learning 上无比优秀且简洁实用的生态系统,Python 才得以在这两个领域笑傲江湖,独孤求败。
那么,Rust 的生态是什么样子呢?我们可以用 Rust 做些什么事情呢?为什么我说 Rust 生态系统已经不错,且潜力无穷、后劲很足呢?我们就聊聊这个话题。
今天的内容主要是丰富你对Rust生态系统的了解,方便你在做不同的项目时,可以快速找到适合的库和工具。当然,我无法把所有重要的 crate 都罗列出来,如果本文中的内容无法涵盖到你的需求,也可以去 crates.io 自行查找。
基础库
首先我们来介绍一些在各类应用中可能都会用到的库。
先按照重要程度依次简单说一下,方便你根据需要自行跳转:序列化和反序列化工具 serde、网络和高性能 I/O 库 tokio、用于错误处理的 thiserror 和 anyhow、用于命令行处理的 clap 以及其他、用于处理异步的 futures 和 async-trait、用于提供并发相关的数据结构和算法的 crossbeam,以及用于撰写解析器的 nom 及其他。

serde
每一个从其他语言转移到 Rust 的开发者,都会惊叹于 serde 及其周边库的强大能力。只需要在数据结构上使用 #[derive(Serialize, Deserialize)] 宏,你的数据结构就能够被序列化和反序列化成绝大多数格式: JSON / YAML / TOML / MsgPack / CSV / Bincode 等等。
你还可以为自己的格式撰写对 serde 的支持,比如使用 DynamoDB,你可以用 serde_dynamo:
#![allow(unused)] fn main() { #[derive(Serialize, Deserialize)] pub struct User { id: String, name: String, age: u8, }; // Get documents from DynamoDB let input = ScanInput { table_name: "users".to_string(), ..ScanInput::default() }; let result = client.scan(input).await?; if let Some(items) = result.items { // 直接一句话,就拿到 User 列表 let users: Vec<User> = serde_dynamo::from_items(items)?; println!("Got {} users", users.len()); } }
如果你用过其它语言的 ORM,那么,你可以把 serde 理解成增强版的、普适性的 ORM,它可以把任意可序列化的数据结构,序列化成任意格式,或者从任意格式中反序列化。
那么什么不是“可序列化的数据结构”呢?很简单, 任何状态无法简单重建的数据结构,比如一个 TcpStream、一个文件描述符、一个 Mutex, 是不可序列化的,而一个 HashMap<String, Vec
tokio
如果你要用 Rust 处理高性能网络,那么 tokio 以及 tokio 的周边库,不能不了解。
tokio 在 Rust 中的地位,相当于 Golang 处理并发的运行时,只不过 Golang 的开发者没得选用不用运行时,而 Rust 开发者可以不用任何运行时,或者在需要的时候有选择地引入 tokio / async-std / smol 等。
在所有这些运行时中,最通用使用最广的是 tokio,围绕着它有: tonic / axum / tokio-uring / tokio-rustls / tokio-stream / tokio-util 等网络和异步 IO 库,以及 bytes / tracing / prost / mio / slab 等。我们在介绍 如何阅读 Rust 代码 时,简单读了 bytes,在 KV server 的撰写过程中,也遇到了这里提到的很多库。
thiserror / anyhow
错误处理的两个库 thiserror / anyhow 建议掌握,目前 Rust 生态里它们是最主流的错误处理工具。
如果你对它们的使用还不太了解,可以再回顾一下 错误处理 那堂课,并且看看在 KV server 中,我们是如何使用 thiserror 和 anyhow 的。
clap / structopt / dialoguer / indicatif
clap 和 structopt 依旧是 Rust 命令行处理的主要选择,其中 clap 3 已经整合了 structopt,所以,一旦它发布正式版本,structopt 的用户可以放心切换过去。
如果你要做交互式的命令行, dialoguer 是一个不错的选择。如果你希望在命令行中还能提供友好的进度条,试试 indicatif。
futures/async-trait
虽然我们还没有正式学习 future,但已经在很多场合使用过 futures 库和 async-trait 库。
标准库中已经采纳了 futures 库的 Future trait,并通过 async/await 关键字,使异步处理成为语言的一部分。然而,futures 库中还有很多其它重要的 trait 和数据结构,比如我们之前使用过的 Stream / Sink。futures 库还自带一个简单的 executor,可以在测试时取代 tokio。
async-trait 库顾名思义,就是为了解决 Rust 目前还不支持在 trait 中带有 async fn 的问题。
crossbeam
crossbeam 是 Rust 下一个非常优秀的处理并发,以及和并发相关的数据结构的库。当你需要撰写自己的调度器时,可以考虑使用 deque,当你需要性能更好的 MPMC channel 时,可以使用 channel,当你需要一个 epoch-based GC 时,可以使用 epoch。
nom/pest/combine
这三者都是非常优秀的 parser 库,可以用来撰写高效的解析器。
在 Rust 下,当你需要处理某些文件格式时,首先可以考虑 serde,其次可以考虑这几个库;如果你要处理语法,那么它们是最好的选择。我个人偏爱 nom,其次是 combine,它们是 parser combinator 库, pest 是 PEG 库,你可以用类似 EBNF 的结构定义语法,然后访问生成的代码。
Web 和 Web 服务开发
虽然 Rust 相对很多语言要年轻很多,但 Rust 下 Web 开发工具厮杀的惨烈程度一点也不亚于 Golang / Python 等更成熟的语言。
从 Web 协议支持的角度看,Rust 有 hyper 处理 http1/http2, quinn / quiche 处理 QUIC/http3, tonic 处理 gRPC,以及 tungstenite / tokio-tungstenite 处理 websocket。
从协议序列化/反序列化的角度看,Rust 有 avro-rs 处理 apache avro, capnp 处理 Cap’n Proto, prost 处理 protobuf, flatbuffers 处理 google flatbuffers, thrift 处理 apache thrift,以及 serde_json 处理我们最熟悉的 JSON。
一般来说,如果你提供 REST / GraphQL API,JSON 是首选的序列化工具,如果你提供二进制协议,没有特殊情况(比如做游戏,倾向于 flatbuffers),建议使用 protobuf。
从 Web 框架的角度,有号称性能宇宙第一的 actix-web;有简单好用且即将支持异步,性能会大幅提升的 rocket;还有 tokio 社区刚刚发布没多久的后起之秀 axum。
在 get hands dirty 用 Rust 实现 thumbor 的过程中,我们使用了 axum。如果你喜欢 Django 这样的大而全的 Web 框架,可以尝试 rocket 0.5 及以上版本。如果你特别在意 Web 性能,可以考虑 actix-web。
从数据库的支持角度看,Rust 支持几乎所有主流的数据库,包括但不限于 MySQL、Postgres、Redis、RocksDB、Cassandra、MongoDB、ScyllaDB、CouchDB 等等。如果你喜欢使用 ORM,可以用 diesel,或者 sea-orm。如果你享受直接但安全的 SQL 查询,可以使用 sqlx。
从模板引擎的角度,Rust 有支持 jinja 语法的 askama,有类似 jinja2 的 tera,还有处理 markdown 的 comrak。
从 Web 前端的角度,Rust 有纯前端的 yew 和 seed,以及更偏重全栈的 MoonZoon。其中,yew 更加成熟一些,熟悉 react/elm 的同学更容易用得起来。
从 Web 测试的角度看,Rust 有对标 puppeteer 的 headless_chrome,以及对标 selenium 的 thirtyfour 和 fantoccini。
从云平台部署的角度看,Rust 有支持 aws 的 rusoto 和 aws-sdk-rust、azure 的 azure-sdk-for-rust。目前 Google Cloud、阿里云、腾讯云还没有官方的 SDK 支持。
在静态网站生成领域,Rust 有对标 hugo 的 zola 和对标 gitbook 的 mdbook。它们都是非常成熟的产品,可以放心使用。
客户端开发
这里的客户端,我特指带 GUI 的客户端开发。CLI 在 之前 已经提及,就不多介绍了。
在 areweguiyet.com 页面中,我们可以看到大量的 GUI 库。我个人觉得比较有前景的跨平台解决方案是 tauri、 druid、 iced 和 sixtyfps。
其中,tauri 是 electron 的替代品,如果你厌倦了 electron 庞大的身躯和贪婪的内存占用,但又喜欢使用 Web 技术栈构建客户端 GUI,那么可以试试 tauri,它使用了系统自身的 webview,再加上 Rust 本身极其克制的内存使用,性能和内存使用能甩 electron 好几个身位。
剩下三个都是提供原生 GUI,其中 sixtyfps 是一个非常不错的对嵌入式系统有很好支持的原生 GUI 库,不过要注意它的授权是 GPLv3,在商业产品上要谨慎使用(它有商业授权)。
如果你希望能够创建更加丰富,更加出众的 GUI,你可以使用 skia-safe 和 tiny-skia。前者是 Google 的 skia 图形引擎的 rust binding,后者是兼容 skia 的一个子集。skia 是目前在跨平台 GUI 领域炙手可热的 Flutter 的底层图形引擎,通过它你可以做任何复杂的对图层的处理。
当然,你也可以用 Flutter 绘制 UI,用 Rust 构建逻辑层。Rust 可以输出 C FFI,dart 可以生成 C FFI 的包装,供 Flutter 使用。
云原生开发
云原生一直是 Golang 的天下,如果你统计用到的 Kubernetes 生态中的 operator,几乎清一色是使用 Golang 撰写的。
然而,Rust 在这个领域渐渐有冒头的趋势。这要感谢之前提到的 serde,以及处理 Kubernetes API 的 kube-rs 项目做出的巨大努力,还有 Rust 强大的宏编程能力,它使得我们跟 Kubernetes 打交道无比轻松。
举个例子,比如要构建一个 CRD:
use kube::{CustomResource, CustomResourceExt}; use schemars::JsonSchema; use serde::{Deserialize, Serialize}; // Book 作为一个新的 Custom resource #[derive(CustomResource, Debug, Clone, Serialize, Deserialize, JsonSchema)] #[kube(group = "k8s.tyr.app", version = "v1", kind = "Book", namespaced)] pub struct BookSpec { pub title: String, pub authors: Option<Vec<String>>, } fn main() { let book = Book::new( "rust-programming", BookSpec { title: "Rust programming".into(), authors: Some(vec!["Tyr Chen".into()]), }, ); println!("{}", serde_yaml::to_string(&Book::crd()).unwrap()); println!("{}", serde_yaml::to_string(&book).unwrap()); }
短短 20 行代码就创建了一个 crd,是不是干净利落,写起来一气呵成?
❯ cargo run | kubectl apply -f -
Finished dev [unoptimized + debuginfo] target(s) in 0.14s
Running `/Users/tchen/.target/debug/k8s-controller`
customresourcedefinition.apiextensions.k8s.io/books.k8s.tyr.app configured
book.k8s.tyr.app/rust-programming created
❯ kubectl get crds
NAME CREATED AT
books.k8s.tyr.app 2021-10-20T01:44:57Z
❯ kubectl get book
NAME AGE
rust-programming 5m22s
如果你用 Golang 的 kubebuilder 做过类似的事情,是不是发现 Golang 那些生成大量脚手架代码和大量 YAML 文件的过程,顿时就不香了?
虽然在云原生方面,Rust 还是个小弟,但这个小弟有着强大的降维打击能力。同样的功能,Rust 可以只用 Golang 大概 1/4-1/10 的代码完成功能,这得益于 Rust 宏编程的强大能力。
除了 kube 这样的基础库,Rust 还有刚刚崭露头角的 krator 和 krustlet。krator 可以帮助你更好地构建 kubernetes operator。虽然 operator 并不太强调效率,但用更少的代码,完成更多的功能,还有更低的内存占用,我还是非常看好未来会有更多的 kubernetes operator 用 Rust 开发。
krustlet 顾名思义,是用来替换 kubelet 的。krustlet 使用了 wasmtime 作为数据平台(dataplane)的运行时,而非传统的 containerd。这也就意味着,你可以用更高效、更精简的 WebAssembly 来处理原本只能使用 container 处理的工作。
目前,WebAssembly 在云原生领域的使用还处在早期,生态还不够完善,但是它相对于厚重的 container 来说,绝对是一个降维打击。
云原生另一个主要的方向是 serverless。在这个领域,由于 amazon 开源了用 Rust 开发的高性能 micro VM firecracker,使得 Rust 在 serverless/FAAS 方面处于领先地位。
WebAssembly 开发
如果说 Web 开发,云原生是 Rust 擅长的领域,那么 WebAssembly 可以说是 Rust 主战场之一。
Rust 内置了 wasm32-unknown-unknown 作为编译目标,如果你没添加,可以用 rustup 添加,然后在编译的时候指明目标,就可以得到 wasm:
$ rustup target add wasm32-unknown-unknown
$ cargo build --target wasm32-unknown-unknown --release
你可以用 wasm-pack 和 wasm-bindgen,不但生成 wasm,同时还生成 ts/js 调用 wasm 的代码。你可以在 rustwasm 下找到更多相关的项目。
WebAssembly 社区一个很重要的组织是 Bytecode Alliance。前文提到的 wasmtime 就是他们的主要开源产品。wasmtime 可以让 WebAssembly 代码以沙箱的形式运行在服务器。
另外一个 WebAssembly 的运行时 wasmer,是 wasmtime 的主要竞争者。目前,WebAssembly 在服务器领域,尤其是 serverless / FAAS 领域,有着很大的发展空间。
嵌入式开发
如果你要用 Rust 做嵌入式开发,那么 embedded WG 不可不关注。
你也可以在 Awesome embedded rust 里找感兴趣的嵌入式开发工具。现在很多嵌入式开发其实不是纯粹的嵌入式设备开发,所以云原生、边缘计算、WebAssembly 也在这个领域有很多应用。比如被接纳为 CNCF sandbox 项目不久的 akri,它就是一个管理嵌入式设备的云原生项目。
机器学习开发
机器学习/深度学习是 Rust 很有潜力,但目前生态还很匮乏的领域。
Rust 有 tensorflow 的绑定,也有 tch-rs 这个 libtorch(PyTorch)的绑定。除了这些著名的 ML 库的 Rust 绑定外,Rust 下还有对标 scikit-learn 的 linfa。
我觉得 Rust 在机器学习领域未来会有很大突破的地方能是 ML infra,因为最终 ML 构建出来的模型,还是需要一个高性能的 API 系统对外提供服务,而 Rust 将是目前这个领域的玩家们的主要挑战者。
小结:Rust 生态的未来
今天我们讲了 Rust 主要的几个方向上的生态。在我撰写这篇内容时, crates.io 上有差不多七万个 rust crate,足以涵盖我们工作中遇到的方方面面的需求。
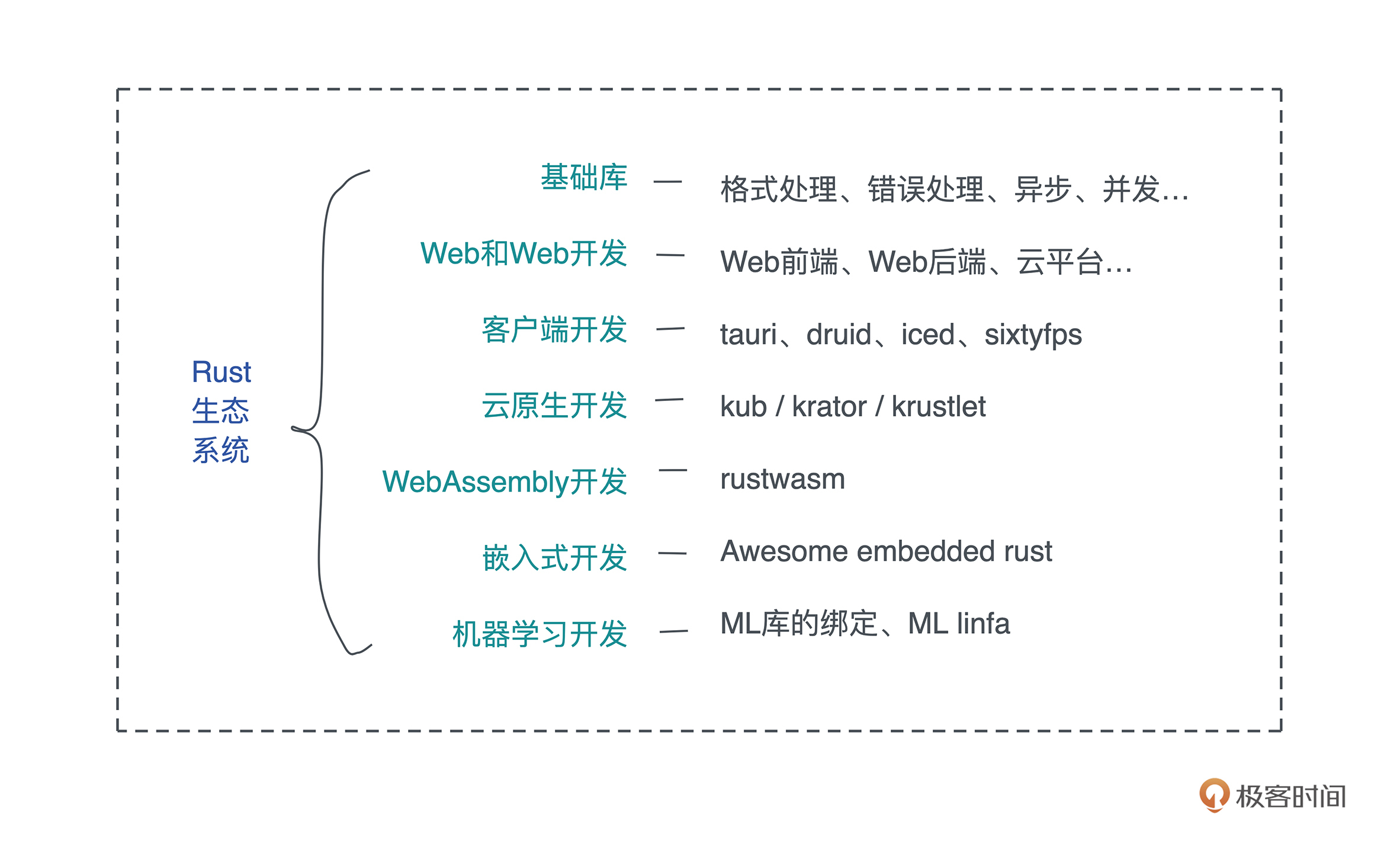
目前 Rust 在 WebAssembly 开发领域处于领先,在 Web 和 Web 服务开发领域已经有非常扎实的基础,而在云原生领域正在奋起直追,后劲十足。这三个领域,加上机器学习领域,是未来几年主流的后端开发方向。
作为一门依旧非常年轻的语言,Rust 的生态还在蓬勃发展中。要知道 Rust 的异步开发是2019年底才进入到稳定版本,在这不到两年的时间里,就出现了大量优秀的、基于异步开发的库被创造出来。
如果给 Rust 更长的时间,我们会看到更多的高性能优秀库会用 Rust 创造,或者用 Rust 改写。
思考题
在今天提到的某个领域下,找一个你感兴趣的库,阅读它的文档,将其 clone 到本地,运行它的 examples,大致浏览一下它的代码。欢迎结合之前讲的 阅读源码的技巧,分享自己的收获。
感谢你的收听,你已经完成Rust学习的第27次打卡。坚持学习,我们下节课见~
网络开发(上):如何使用Rust处理网络请求?
你好,我是陈天。今天我们学习如何使用 Rust 做网络开发。
在互联网时代,谈到网络开发,我们想到的首先是 Web 开发以及涉及的部分 HTTP 协议和 WebSocket 协议。
之所以说部分,是因为很多协议考虑到的部分,比如更新时的 并发控制,大多数 Web 开发者并不知道。当谈论到 gRPC 时,很多人就会认为这是比较神秘的“底层”协议了,其实只不过是 HTTP/2 下的一种对二进制消息格式的封装。
所以对于网络开发,这个非常宏大的议题,我们当然是不可能、也没有必要覆盖全部内容的,今天我们会先简单聊聊网络开发的大全景图,然后重点学习如何使用Rust标准库以及生态系统中的库来做网络处理,包括网络连接、网络数据处理的一些方法,最后也会介绍几种典型的网络通讯模型的使用。
但即使这样,内容也比较多,我们会分成上下两讲来学习。如果你之前只关注 Web 开发,文中很多内容读起来可能会有点吃力,建议先去弥补相关的知识和概念,再学习会比较容易理解。
好,我们先来简单回顾一下 ISO/OSI 七层模型以及对应的协议,物理层主要跟 PHY 芯片 有关,就不多提了:
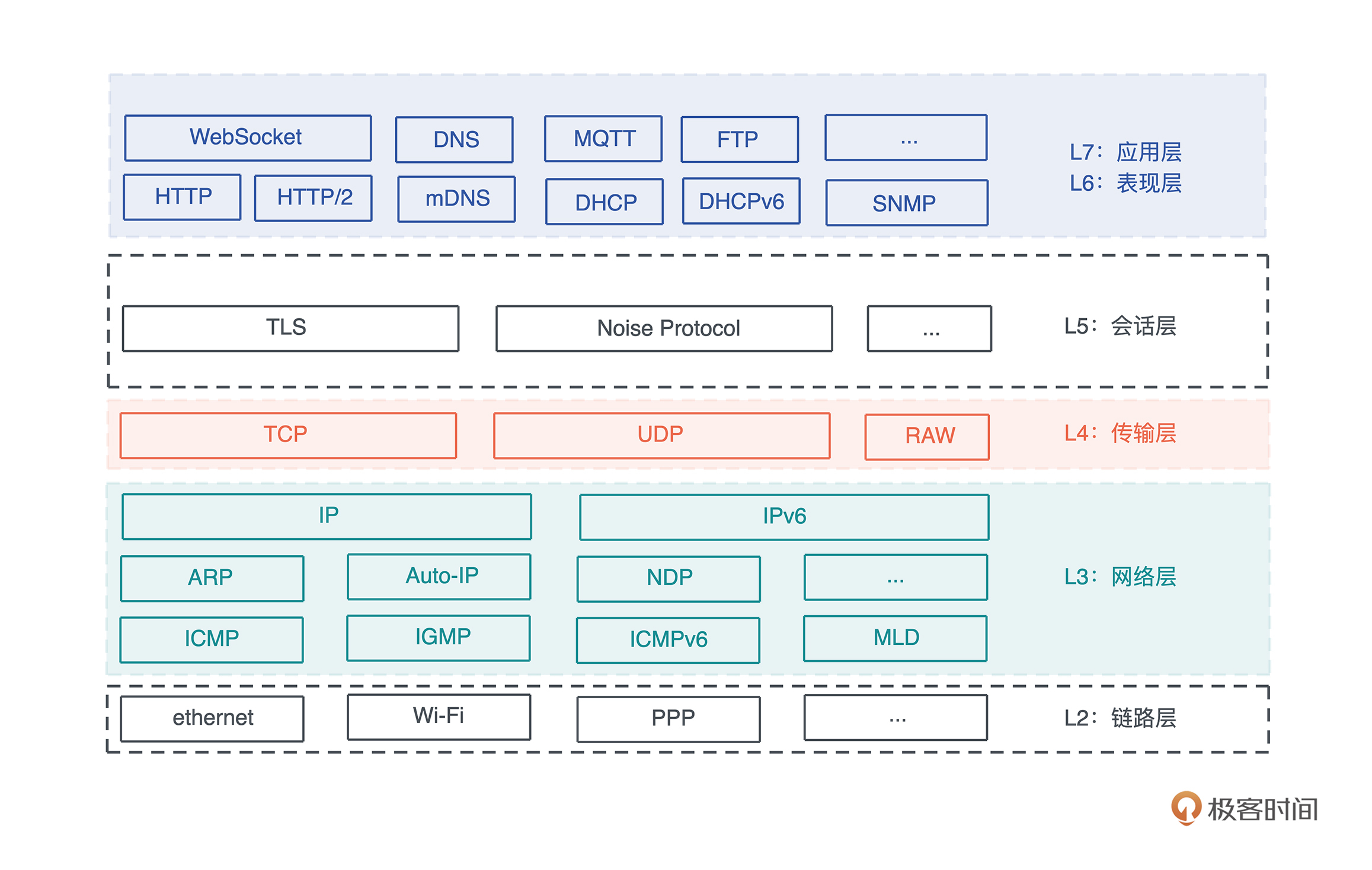
七层模型中,链路层和网络层一般构建在操作系统之中,我们并不需要直接触及,而表现层和应用层关系紧密,所以在实现过程中, 大部分应用程序只关心网络层、传输层和应用层。
网络层目前 IPv4 和 IPv6 分庭抗礼,IPv6 还未完全对 IPv4 取而代之;传输层除了对延迟非常敏感的应用(比如游戏),绝大多数应用都使用 TCP;而在应用层,对用户友好,且对防火墙友好的 HTTP 协议家族:HTTP、WebSocket、HTTP/2,以及尚处在草案之中的 HTTP/3,在漫长的进化中,脱颖而出,成为应用程序主流的选择。
我们来看看 Rust 生态对网络协议的支持:
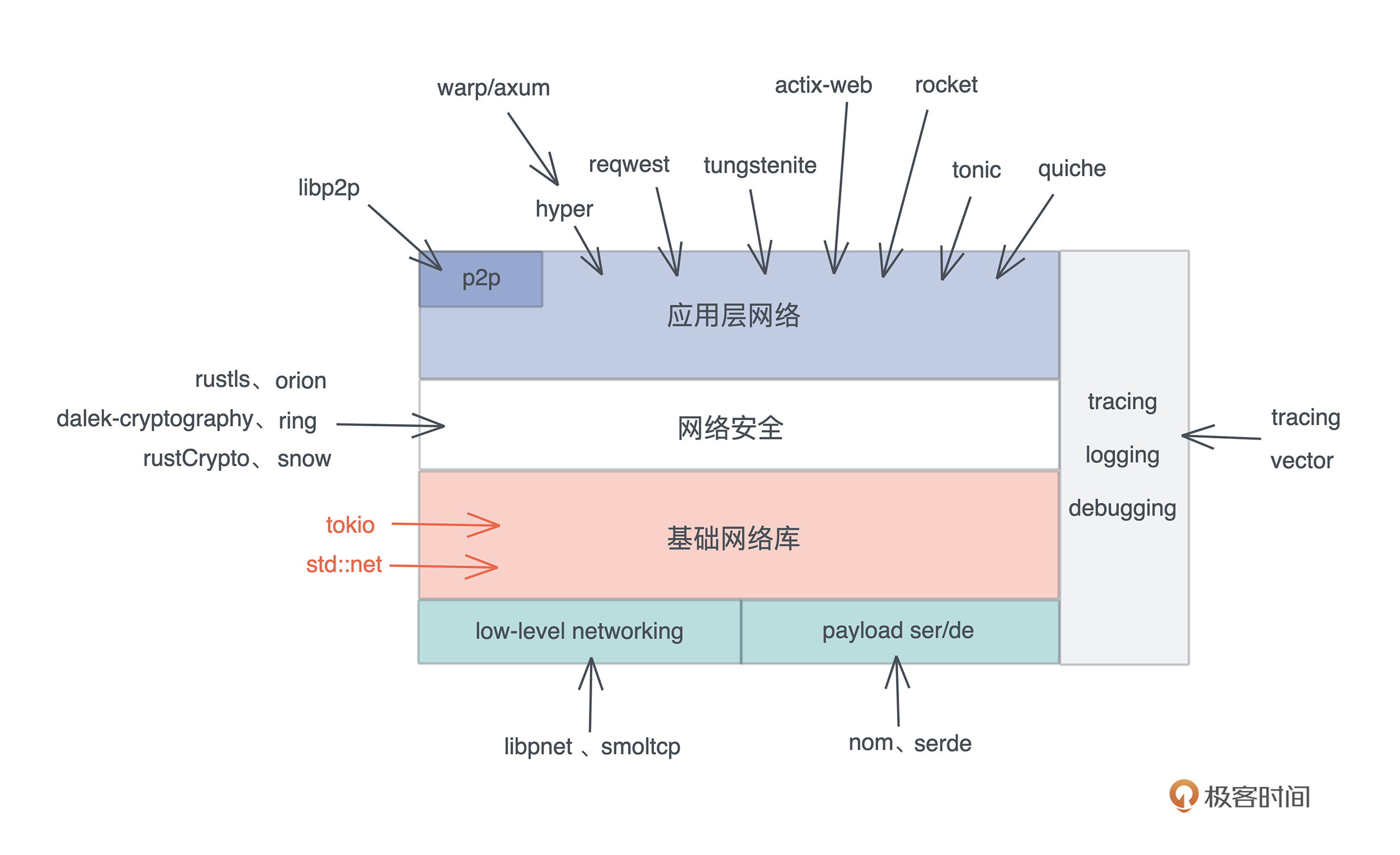
Rust 标准库提供了 std::net,为整个 TCP/IP 协议栈的使用提供了封装。然而 std::net 是同步的,所以,如果你要构建一个高性能的异步网络,可以使用 tokio。tokio::net 提供了和 std::net 几乎一致的封装,一旦你熟悉了 std::net,tokio::net 里的功能对你来说都并不陌生。所以,我们先从std::net开始了解。
std::net
std::net 下提供了处理 TCP / UDP 的数据结构,以及一些辅助结构:
- TCP:TcpListener / TcpStream,处理服务器的监听以及客户端的连接
- UDP:UdpSocket,处理 UDP socket
- 其它:IpAddr 是 IPv4 和 IPv6 地址的封装;SocketAddr,表示 IP 地址 + 端口的数据结构
这里就主要介绍一下 TCP 的处理,顺带会使用到 IpAddr / SocketAddr。
TcpListener/TcpStream
如果要创建一个 TCP server,我们可以使用 TcpListener 绑定某个端口,然后用 loop 循环处理接收到的客户端请求。接收到请求后,会得到一个 TcpStream,它实现了 Read / Write trait,可以像读写文件一样,进行 socket 的读写:
use std::{ io::{Read, Write}, net::TcpListener, thread, }; fn main() { let listener = TcpListener::bind("0.0.0.0:9527").unwrap(); loop { let (mut stream, addr) = listener.accept().unwrap(); println!("Accepted a new connection: {}", addr); thread::spawn(move || { let mut buf = [0u8; 12]; stream.read_exact(&mut buf).unwrap(); println!("data: {:?}", String::from_utf8_lossy(&buf)); // 一共写了 17 个字节 stream.write_all(b"glad to meet you!").unwrap(); }); } }
对于客户端,我们可以用 TcpStream::connect() 得到一个 TcpStream。一旦客户端的请求被服务器接受,就可以发送或者接收数据:
use std::{ io::{Read, Write}, net::TcpStream, }; fn main() { let mut stream = TcpStream::connect("127.0.0.1:9527").unwrap(); // 一共写了 12 个字节 stream.write_all(b"hello world!").unwrap(); let mut buf = [0u8; 17]; stream.read_exact(&mut buf).unwrap(); println!("data: {:?}", String::from_utf8_lossy(&buf)); }
在这个例子中,客户端在连接成功后,会发送 12 个字节的 "hello world!"给服务器,服务器读取并回复后,客户端会尝试接收完整的、来自服务器的 17个字节的 “glad to meet you!”。
但是,目前客户端和服务器都需要硬编码要接收数据的大小,这样不够灵活,后续我们会看到如何通过使用消息帧(frame)更好地处理。
从客户端的代码中可以看到,我们无需显式地关闭 TcpStream,因为 TcpStream 的内部实现也处理了 Drop trait,使得其离开作用域时会被关闭。
但如果你去看 TcpStream 的文档,会发现它并没有实现 Drop。这是因为 TcpStream 内部包装了 sys_common::net::TcpStream ,然后它又包装了 Socket。而Socket 是一个平台相关的结构,比如,在 Unix 下的实现是 FileDesc,然后它内部是一个 OwnedFd,最终会调用 libc::close(self.fd) 来关闭 fd,也就关闭了 TcpStream。
处理网络连接的一般方法
如果你使用某个 Web Framework 处理 Web 流量,那么无需关心网络连接,框架会帮你打点好一切,你只需要关心某个路由或者某个 RPC 的处理逻辑就可以了。但如果你要在 TCP 之上构建自己的协议,那么你需要认真考虑如何妥善处理网络连接。
我们在之前的 listener 代码中也看到了,在网络处理的主循环中,会不断 accept() 一个新的连接:
fn main() { ... loop { let (mut stream, addr) = listener.accept().unwrap(); println!("Accepted a new connection: {}", addr); thread::spawn(move || { ... }); } }
但是,处理连接的过程,需要放在另一个线程或者另一个异步任务中进行,而不要在主循环中直接处理,因为这样会阻塞主循环,使其在处理完当前的连接前,无法 accept() 新的连接。
所以,loop + spawn 是处理网络连接的基本方式:
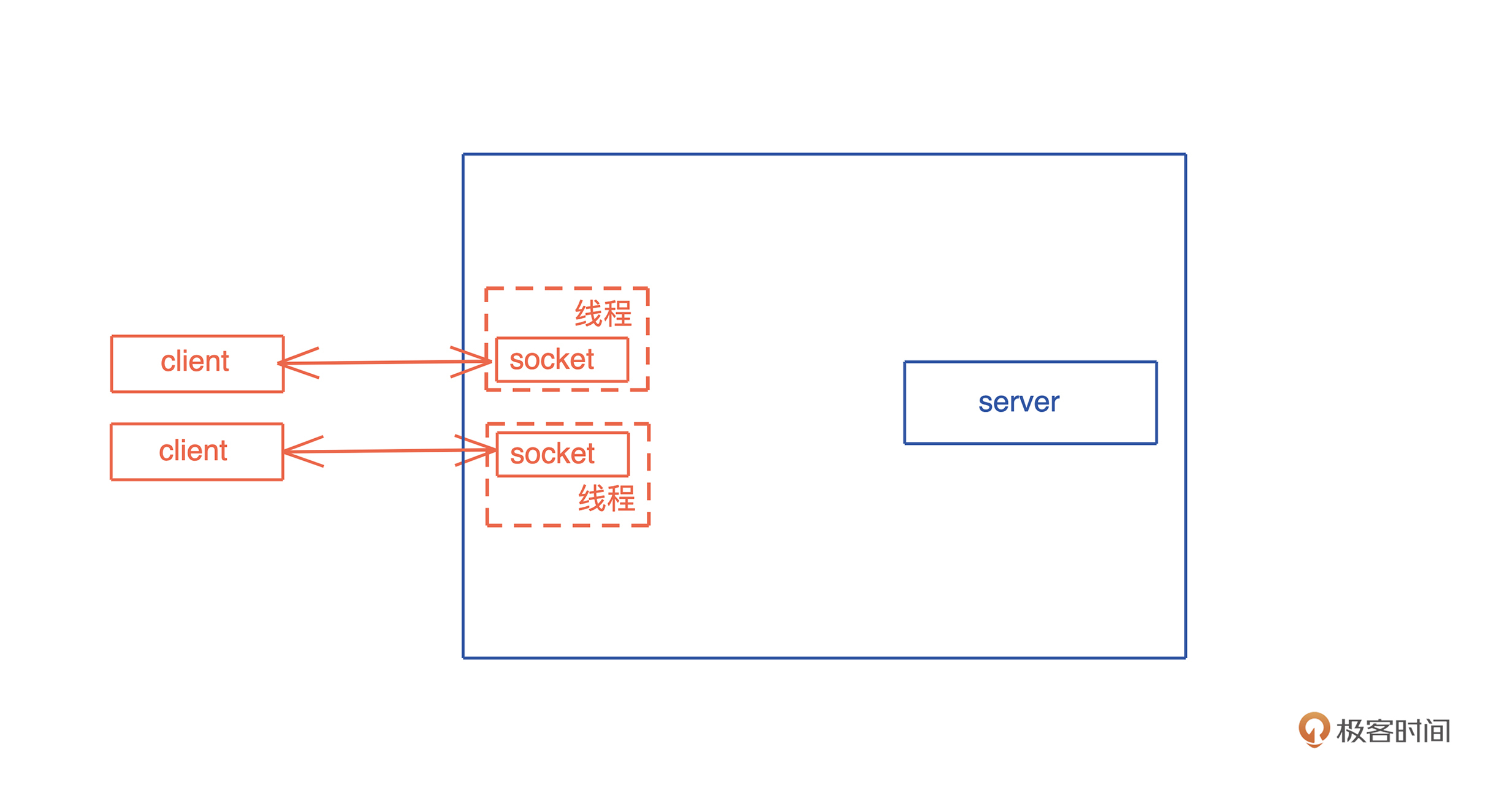
但是使用线程处理频繁连接和退出的网络连接,一来会有效率上的问题,二来线程间如何共享公共的数据也让人头疼,我们来详细看看。
如何处理大量连接?
如果不断创建线程,那么当连接数一高,就容易把系统中可用的线程资源吃光。此外,因为线程的调度是操作系统完成的,每次调度都要经历一个复杂的、不那么高效的 save and load 的 上下文切换 过程,所以 如果使用线程,那么,在遭遇到 C10K 的瓶颈,也就是连接数到万这个级别,系统就会遭遇到资源和算力的双重瓶颈。
从资源的角度,过多的线程占用过多的内存,Rust 缺省的栈大小是 2M,10k 连接就会占用 20G 内存(当然缺省栈大小也可以 根据需要修改);从算力的角度,太多线程在连接数据到达时,会来来回回切换线程,导致 CPU 过分忙碌,无法处理更多的连接请求。
所以,对于潜在的有大量连接的网络服务,使用线程不是一个好的方式。
如果要突破 C10K 的瓶颈,达到 C10M,我们就只能使用在用户态的协程来处理,要么是类似 Erlang/Golang 那样的有栈协程(stackful coroutine),要么是类似 Rust 异步处理这样的无栈协程(stackless coroutine)。
所以,在 Rust 下大部分处理网络相关的代码中,你会看到,很少直接有用 std::net 进行处理的,大部分都是用某个异步网络运行时,比如 tokio。
如何处理共享信息?
第二个问题,在构建服务器时,我们总会有一些共享的状态供所有的连接使用,比如数据库连接。对于这样的场景,如果共享数据不需要修改,我们可以考虑使用 Arc
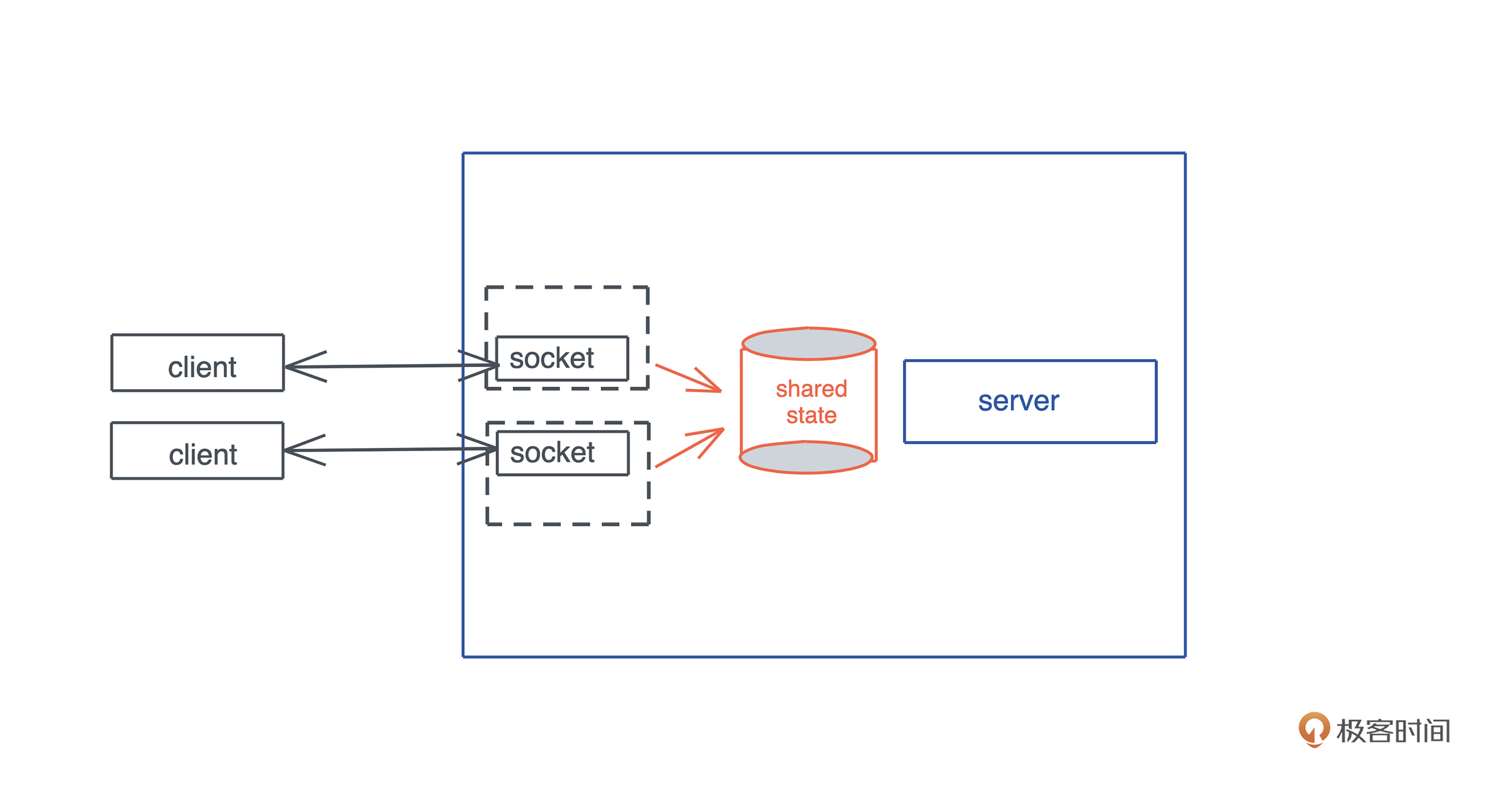
但使用锁,就意味着一旦在关键路径上需要访问被锁住的资源,整个系统的吞吐量都会受到很大的影响。
一种思路是,我们 把锁的粒度降低,这样冲突就会减少。比如在 kv server 中,我们把 key 哈希一下模 N,将不同的 key 分摊到 N 个 memory store 中,这样,锁的粒度就降低到之前的 1/N 了:
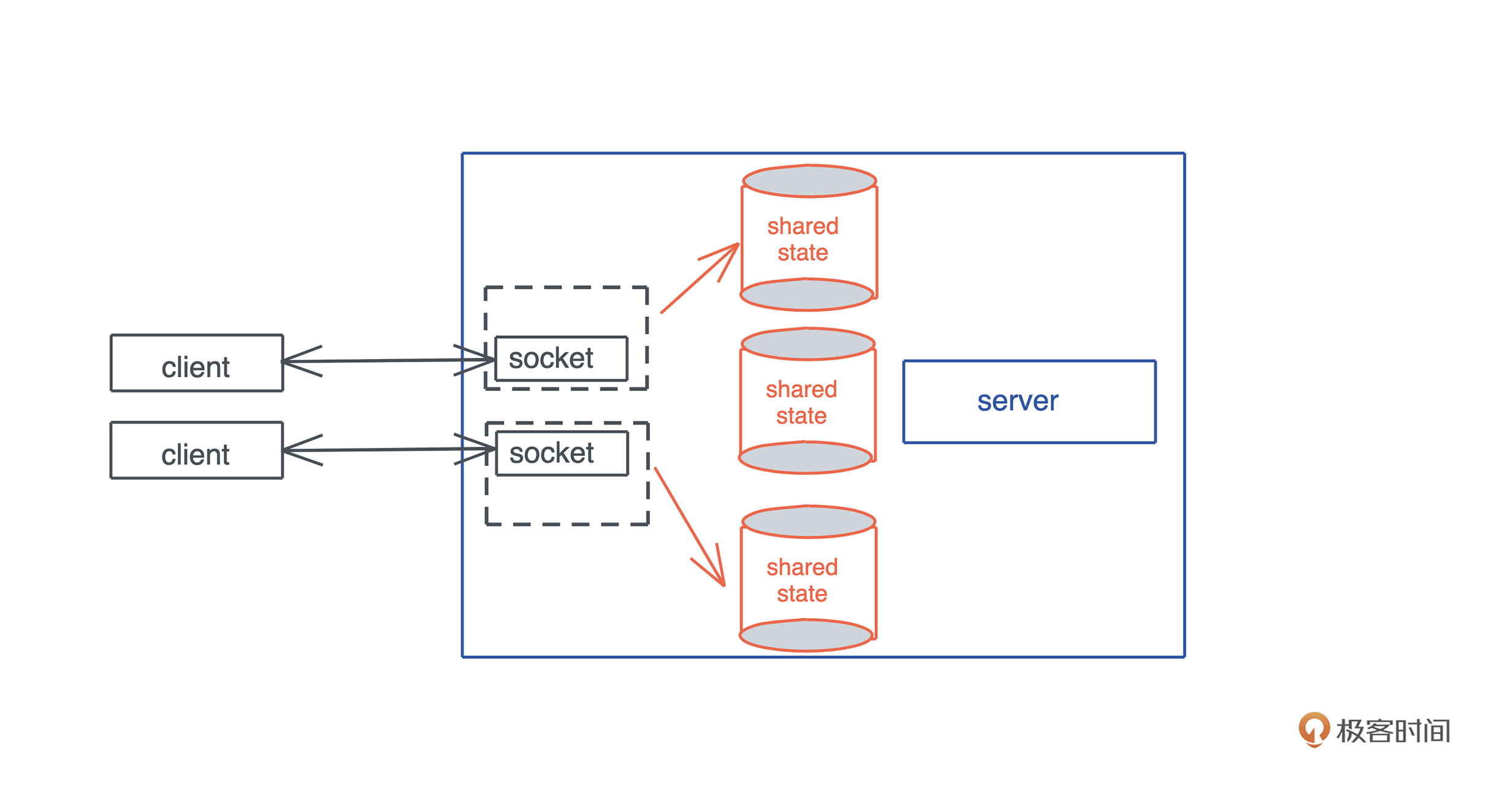
另一种思路是我们 改变共享资源的访问方式,使其只被一个特定的线程访问;其它线程或者协程只能通过给其发消息的方式与之交互。如果你用 Erlang / Golang,这种方式你应该不陌生,在 Rust 下,可以使用 channel 数据结构。
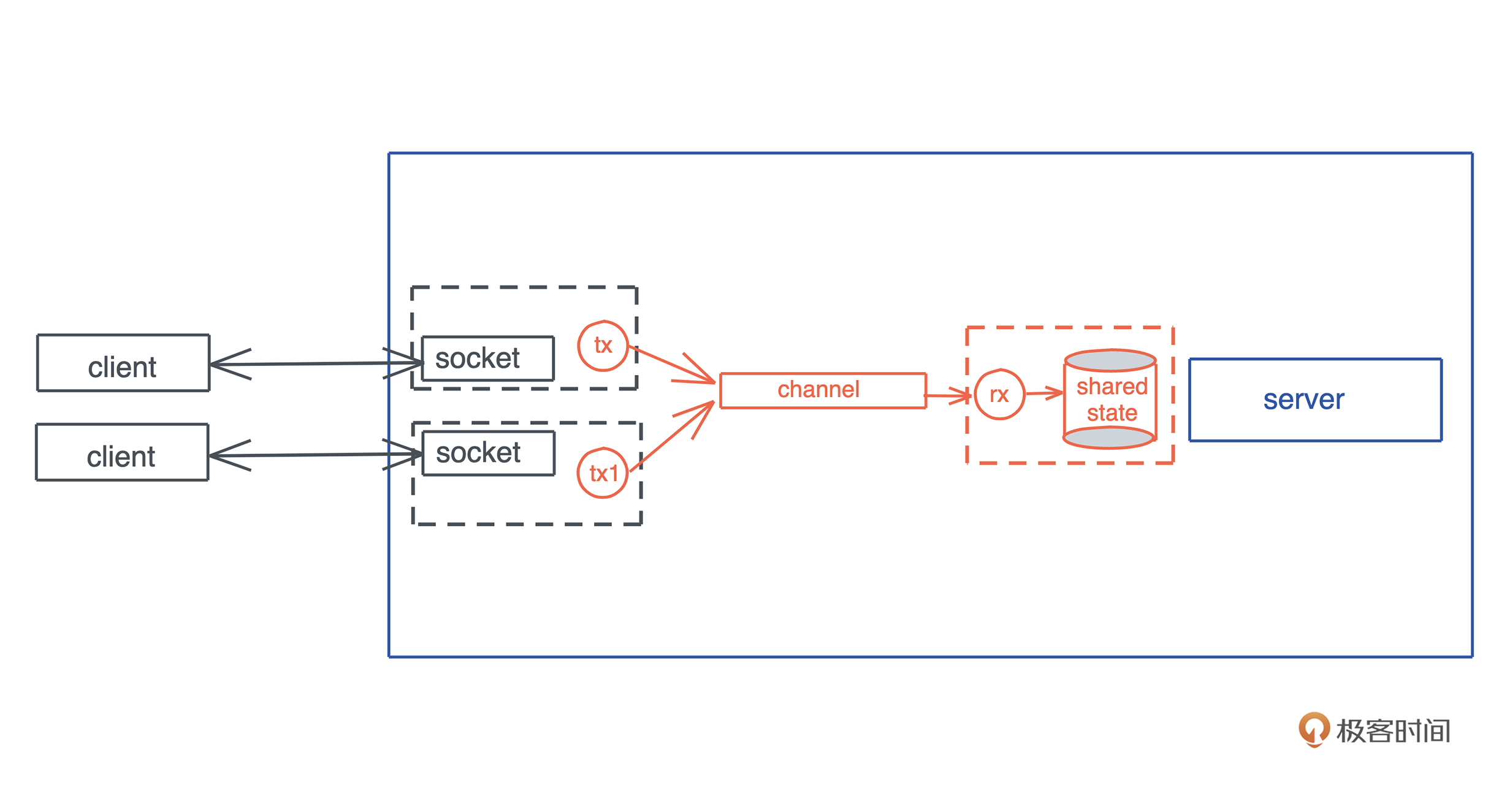
Rust 下 channel,无论是标准库,还是第三方库,都有非常棒的的实现。同步 channel 的有标准库的 mpsc:channel 和第三方的 crossbeam_channel,异步 channel 有tokio 下的 mpsc:channel,以及 flume。
处理网络数据的一般方法
我们再来看看如何处理网络数据。大部分时候,我们可以使用已有的应用层协议来处理网络数据,比如 HTTP。
在 HTTP 协议下,基本上使用 JSON 构建 REST API / JSON API 是业界的共识,客户端和服务器也有足够好的生态系统来支持这样的处理。你只需要使用 serde 让你定义的 Rust 数据结构具备 Serialize/Deserialize 的能力,然后用 serde_json 生成序列化后的 JSON 数据。
下面是一个使用 rocket 来处理 JSON 数据的例子。首先在 Cargo.toml 中引入:
rocket = { version = "0.5.0-rc.1", features = ["json"] }
然后在 main.rs 里添加代码:
#![allow(unused)] fn main() { #[macro_use] extern crate rocket; use rocket::serde::json::Json; use rocket::serde::{Deserialize, Serialize}; #[derive(Serialize, Deserialize)] #[serde(crate = "rocket::serde")] struct Hello { name: String, } #[get("/", format = "json")] fn hello() -> Json<Hello> { Json(Hello { name: "Tyr".into() }) } #[launch] fn rocket() -> _ { rocket::build().mount("/", routes![hello]) } }
Rocket 是 Rust 的一个全功能的 Web 框架,类似于 Python 的 Django。可以看到,使用 rocket,10 多行代码,我们就可以运行起一个 Web Server。
如果你出于性能或者其他原因,可能需要定义自己的客户端/服务器间的协议,那么,可以使用传统的 TLV(Type-Length-Value)来描述协议数据,或者使用更加高效简洁的 protobuf。
使用 protobuf 自定义协议
protobuf 是一种非常方便的定义向后兼容协议的工具,它不仅能使用在构建 gRPC 服务的场景,还能用在其它网络服务中。
在之前的实战中,无论是 thumbor 的实现,还是 kv server 的实现,都用到了 protobuf。在 kv server 的实战中,我们在 TCP 之上构建了基于 protobuf 的协议,支持一系列 HXXX 命令。如何使用 protobuf 之前讲过,这里也不再赘述。
不过,使用 protobuf 构建协议消息的时候需要注意,因为 protobuf 生成的是不定长消息,所以你需要在客户端和服务器之间约定好, 如何界定一个消息帧(frame)。
常用的界定消息帧的方法有在消息尾添加 “\r\n”,以及在消息头添加长度。
消息尾添加 “\r\n” 一般用于基于文本的协议,比如 HTTP 头 / POP3 / Redis 的 RESP 协议等。但对于 二进制协议,更好的方式是在消息前面添加固定的长度,比如对于 protobuf 这样的二进制而言,消息中的数据可能正好出现连续的"\r\n",如果使用 “\r\n” 作为消息的边界,就会发生紊乱,所以不可取。
不过两种方式也可以混用,比如 HTTP 协议,本身使用 “\r\n” 界定头部,但它的 body 会使用长度界定,只不过这个长度在 HTTP 头中的 Content-Length 来声明。
前面说到 gRPC 使用 protobuf,那么 gRPC 是怎么界定消息帧呢?
gRPC 使用了五个字节的 Length-Prefixed-Message,其中包含一个字节的压缩标志和四个字节的消息长度。 这样,在处理 gRPC 消息时,我们先读取 5 个字节,取出其中的长度 N,再读取 N 个字节就得到一个完整的消息了。
所以我们也可以采用这样的方法来处理使用 protobuf 自定义的协议。
因为这种处理方式很常见,所以 tokio 提供了 length_delimited codec,来处理用长度隔离的消息帧,它可以和 Framed 结构配合使用。如果你看它的文档,会发现它除了简单支持在消息前加长度外,还支持各种各样复杂的场景。
比如消息有一个固定的消息头,其中包含 3 字节长度,5 字节其它内容,LengthDelimitedCodec 处理完后,会把完整的数据给你。你也可以通过 num_skip(3) 把长度丢弃,总之非常灵活:

下面是我使用 tokio / tokio_util 撰写的服务器和客户端,你可以看到,服务器和客户端都使用了 LengthDelimitedCodec 来处理消息帧。
服务器的代码:
use anyhow::Result; use bytes::Bytes; use futures::{SinkExt, StreamExt}; use tokio::net::TcpListener; use tokio_util::codec::{Framed, LengthDelimitedCodec}; #[tokio::main] async fn main() -> Result<()> { let listener = TcpListener::bind("127.0.0.1:9527").await?; loop { let (stream, addr) = listener.accept().await?; println!("accepted: {:?}", addr); // LengthDelimitedCodec 默认 4 字节长度 let mut stream = Framed::new(stream, LengthDelimitedCodec::new()); tokio::spawn(async move { // 接收到的消息会只包含消息主体(不包含长度) while let Some(Ok(data)) = stream.next().await { println!("Got: {:?}", String::from_utf8_lossy(&data)); // 发送的消息也需要发送消息主体,不需要提供长度 // Framed/LengthDelimitedCodec 会自动计算并添加 stream.send(Bytes::from("goodbye world!")).await.unwrap(); } }); } }
以及客户端代码:
use anyhow::Result; use bytes::Bytes; use futures::{SinkExt, StreamExt}; use tokio::net::TcpStream; use tokio_util::codec::{Framed, LengthDelimitedCodec}; #[tokio::main] async fn main() -> Result<()> { let stream = TcpStream::connect("127.0.0.1:9527").await?; let mut stream = Framed::new(stream, LengthDelimitedCodec::new()); stream.send(Bytes::from("hello world")).await?; // 接收从服务器返回的数据 if let Some(Ok(data)) = stream.next().await { println!("Got: {:?}", String::from_utf8_lossy(&data)); } Ok(()) }
和刚才的TcpListener / TcpStream代码相比,双方都不需要知道对方发送的数据的长度,就可以通过 StreamExt trait 的 next() 接口得到下一个消息;在发送时,只需要调用 SinkExt trait 的 send() 接口发送,相应的长度就会被自动计算并添加到要发送的消息帧的开头。
当然啦,如果你想自己运行这两段代码,记得在 Cargo.toml 里添加:
#![allow(unused)] fn main() { [dependencies] anyhow = "1" bytes = "1" futures = "0.3" tokio = { version = "1", features = ["full"] } tokio-util = { version = "0.6", features = ["codec"] } }
完整的代码可以在这门课程 GitHub repo 这一讲的目录中找到。
这里为了代码的简便,我并没有直接使用 protobuf。你可以把发送和接收到的 Bytes 里的内容视作 protobuf 序列化成的二进制(如果你想看 protobuf 的处理,可以回顾 thumbor 和 kv server 的源代码)。我们可以看到,使用 LengthDelimitedCodec,构建一个自定义协议,变得非常简单。短短二十行代码就完成了非常繁杂的工作。
小结
今天我们聊了用Rust做网络开发的生态系统,简单学习了Rust 标准库提供的 std::net 和对异步有优秀支持的 tokio 库,以及如何用它们来处理网络连接和网络数据。
绝大多数情况下,我们应该使用支持异步的网络开发,所以你会在各种网络相关的代码中,看到 tokio 的身影。作为 Rust 下主要的异步网络运行时,你可以多花点时间了解它的功能。
在接下来的 KV server 的实现中,我们会看到更多有关网络方面的详细处理。你也会看到,我们如何实现自己的 Stream 来处理消息帧。
思考题
在之前做的 kv server 的 examples 里,我们使用 async_prost。根据今天我们所学的内容,你能不能尝试使用使用 tokio_util 下的 LengthDelimitedCodec 来改写这个 example 呢?
use anyhow::Result; use async_prost::AsyncProstStream; use futures::prelude::*; use kv1::{CommandRequest, CommandResponse, Service, ServiceInner, SledDb}; use tokio::net::TcpListener; use tracing::info; #[tokio::main] async fn main() -> Result<()> { tracing_subscriber::fmt::init(); let service: Service<SledDb> = ServiceInner::new(SledDb::new("/tmp/kvserver")) .fn_before_send(|res| match res.message.as_ref() { "" => res.message = "altered. Original message is empty.".into(), s => res.message = format!("altered: {}", s), }) .into(); let addr = "127.0.0.1:9527"; let listener = TcpListener::bind(addr).await?; info!("Start listening on {}", addr); loop { let (stream, addr) = listener.accept().await?; info!("Client {:?} connected", addr); let svc = service.clone(); tokio::spawn(async move { let mut stream = AsyncProstStream::<_, CommandRequest, CommandResponse, _>::from(stream).for_async(); while let Some(Ok(cmd)) = stream.next().await { info!("Got a new command: {:?}", cmd); let res = svc.execute(cmd); stream.send(res).await.unwrap(); } info!("Client {:?} disconnected", addr); }); } }
感谢你的阅读,下一讲我们继续学习网络开发的通讯模型,我们下一讲见~
网络开发(下):如何使用Rust处理网络请求?
你好,我是陈天。
上一讲介绍了如何用Rust做基于 TCP 的网络开发,通过 TcpListener 监听,使用 TcpStream 连接。在 *nix 操作系统层面,一个 TcpStream 背后就是一个文件描述符。值得注意的是,当我们在处理网络应用的时候,有些问题一定要正视:
- 网络是不可靠的
- 网络的延迟可能会非常大
- 带宽是有限的
- 网络是非常不安全的
我们可以使用 TCP 以及构建在 TCP 之上的协议应对网络的不可靠;使用队列和超时来应对网络的延时;使用精简的二进制结构、压缩算法以及某些技巧(比如 HTTP 的 304)来减少带宽的使用,以及不必要的网络传输;最后,需要使用 TLS 或者 noise protocol 这样的安全协议来保护传输中的数据。
好今天我们接着看在网络开发中,主要会涉及的网络通讯模型。
双向通讯
上一讲 TCP 服务器的例子里,所做的都是双向通讯。这是最典型的一种通讯方式:
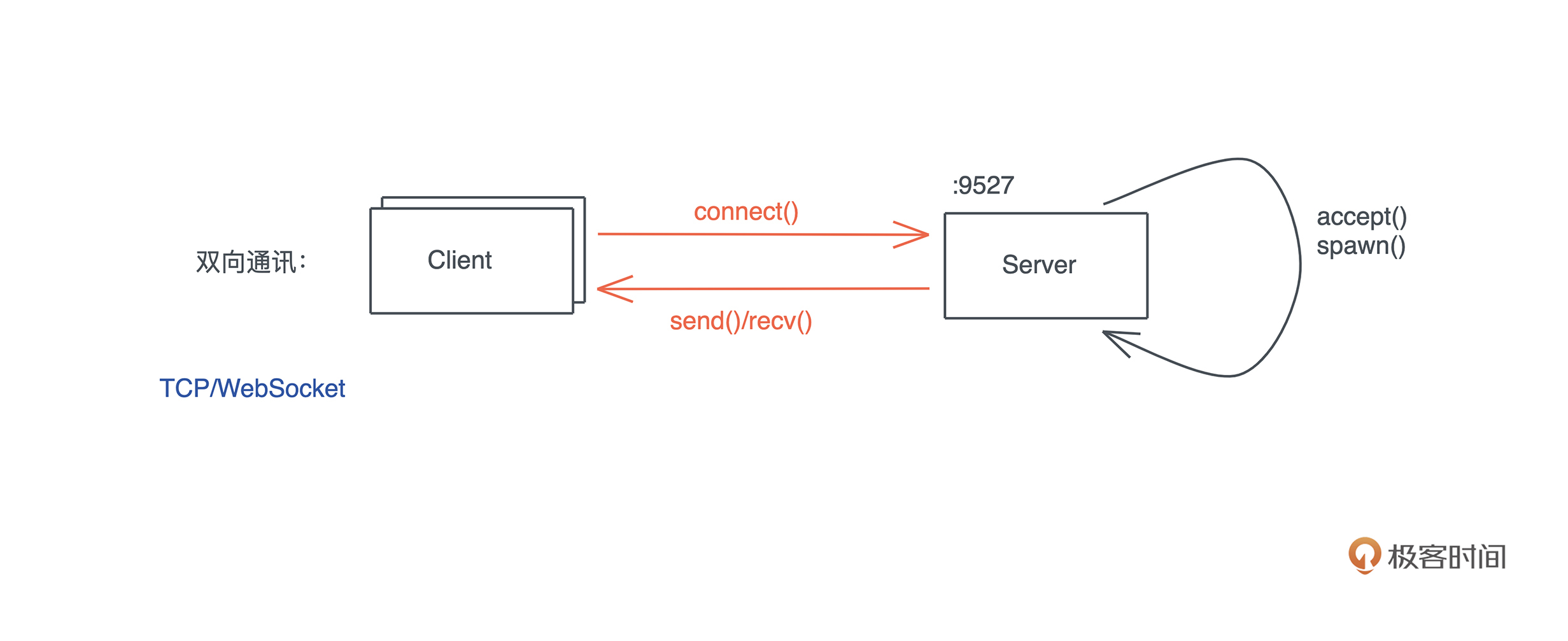
一旦连接建立,服务器和客户端都可以根据需要主动向对方发起传输。整个网络运行在全双工模式下(full duplex)。我们熟悉的 TCP / WebSocket 就运行在这种模型下。
双向通讯这种方式的好处是,数据的流向是没有限制的,一端不必等待另一端才能发送数据,网络可以进行比较实时地处理。
请求响应
在 Web 开发的世界里,请求-响应模型是我们最熟悉的模型。客户端发送请求,服务器根据请求返回响应。整个网络处在半双工模式下(half duplex)。HTTP/1.x 就运行在这种模式下。
一般而言,请求响应模式下,在客户端没有发起请求时,服务器不会也无法主动向客户端发送数据。除此之外,请求发送的顺序和响应返回的顺序是一一对应的,不会也不能乱序,这种处理方式会导致应用层的 队头阻塞(Head-Of-Line blocking)。
请求响应模型处理起来很简单,由于 HTTP 协议的流行,尽管有很多限制,请求响应模型还是得到了非常广泛的应用。
控制平面/数据平面分离
但有时候,服务器和客户端之间会进行复杂的通讯,这些通讯包含控制信令和数据流。因为 TCP 有天然的网络层的队头阻塞,所以当控制信令和数据交杂在同一个连接中时,过大的数据流会阻塞控制信令,使其延迟加大,无法及时响应一些重要的命令。
以 FTP 为例,如果用户在传输一个 1G 的文件后,再进行 ls 命令,如果文件传输和 ls 命令都在同一个连接中进行,那么,只有文件传输结束,用户才会看到 ls 命令的结果,这样显然对用户非常不友好。
所以,我们会采用控制平面和数据平面分离的方式,进行网络处理。
客户端会首先连接服务器,建立控制连接, 控制连接 是一个长连接,会一直存在,直到交互终止。然后,二者会根据需要额外创建 新的临时的数据连接,用于传输大容量的数据,数据连接在完成相应的工作后,会自动关闭。
除 FTP 外,还有很多协议都是类似的处理方式,比如多媒体通讯协议 SIP 协议。
HTTP/2 和借鉴了HTTP/2 的用于多路复用的 Yamux 协议,虽然运行在同一个 TCP 连接之上,它们在应用层也构建了类似的控制平面和数据平面。
以 HTTP/2 为例,控制平面(ctrl stream)可以创建很多新的 stream,用于并行处理多个应用层的请求,比如使用 HTTP/2 的 gRPC,各个请求可以并行处理,不同 stream 之间的数据可以乱序返回,而不必受请求响应模型的限制。虽然 HTTP/2 依旧受困于 TCP 层的队头阻塞,但它解决了应用层的队头阻塞。
P2P 网络
前面我们谈论的网络通讯模型,都是传统的客户端/服务器交互模型(C/S 或 B/S),客户端和服务器在网络中的作用是不对等的,客户端永远是连接的发起方,而服务器是连接的处理方。
不对等的网络模型有很多好处,比如客户端不需要公网地址,可以隐藏在网络地址转换(NAT)设备(比如 NAT 网关、防火墙)之后,只要服务器拥有公网地址,这个网络就可以连通。所以, 客户端/服务器模型是天然中心化的,所有连接都需要经过服务器这个中间人,即便是两个客户端的数据交互也不例外。这种模型随着互联网的大规模使用成为了网络世界的主流。
然而,很多应用场景需要通讯的两端可以直接交互,而无需一个中间人代为中转。比如 A和B 分享一个 1G 的文件,如果通过服务器中转,数据相当于传输了两次,效率很低。
P2P 模型打破了这种不对等的关系,使得任意两个节点在理论上可以直接连接,每个节点既是客户端,又是服务器。
如何构建P2P网络
可是由于历史上 IPv4 地址的缺乏,以及对隐私和网络安全的担忧,互联网的运营商在接入端,大量使用了 NAT 设备,使得普通的网络用户,缺乏直接可以访问的公网 IP。因而, 构建一个 P2P 网络首先需要解决网络的连通性。
主流的解决方法是,P2P 网络的每个节点,都会首先会通过 STUN 服务器探索自己的公网 IP/port,然后在 bootstrap/signaling server 上注册自己的公网 IP/port,让别人能发现自己,从而和潜在的“邻居”建立连接。
在一个大型的 P2P 网络中,一个节点常常会拥有几十个邻居,通过这些邻居以及邻居掌握的网络信息,每个节点都能构建一张如何找到某个节点(某个数据)的路由表。在此之上,节点还可以加入某个或者某些 topic,然后通过某些协议(比如 gossip)在整个 topic 下扩散消息:
P2P 网络的构建,一般要比客户端/服务器网络复杂,因为节点间的连接要承载很多协议:节点发现(mDNS、bootstrap、Kad DHT)、节点路由(Kad DHT)、内容发现(pubsub、Kad DHT)以及应用层协议。同时,连接的安全性受到的挑战也和之前不同。
所以我们会看到,P2P 协议的连接,往往在一个 TCP 连接中,使用类似 yamux 的多路复用协议来承载很多其他协议:
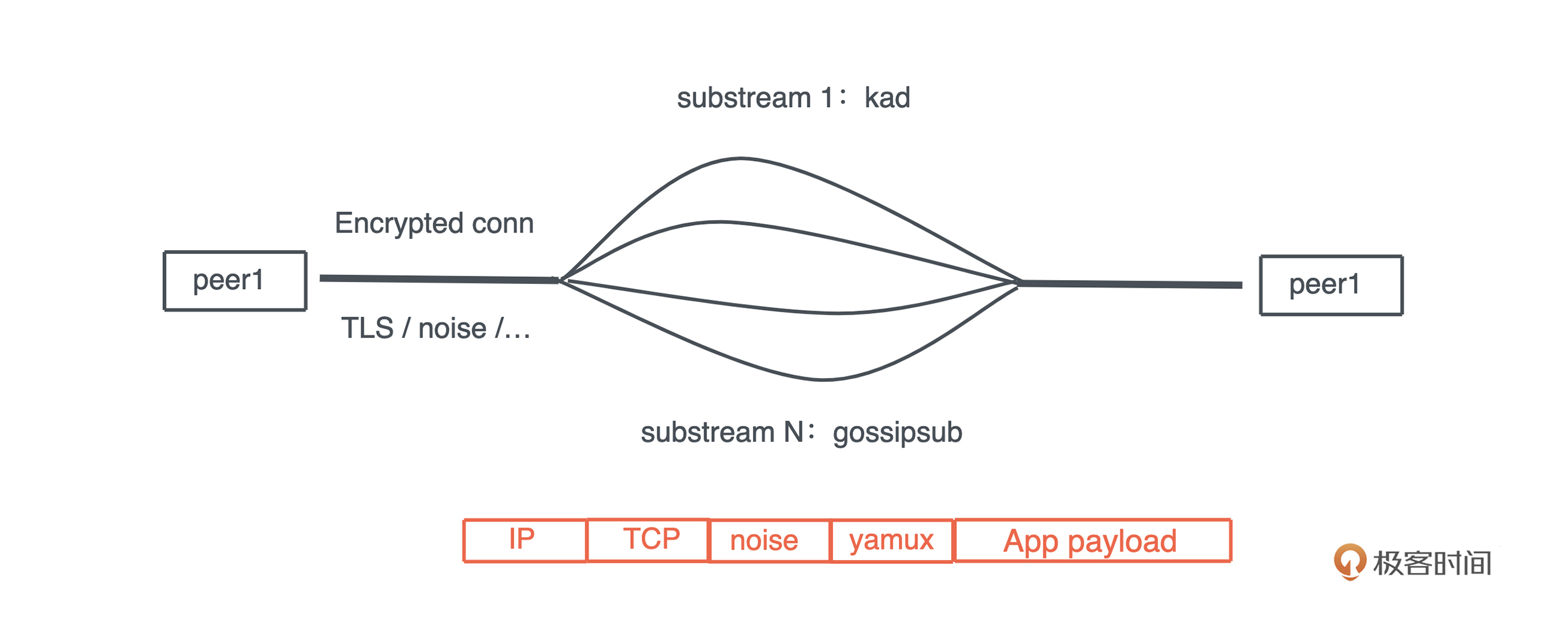
在网络安全方面,TLS 虽然能很好地保护客户端/服务器模型,然而证书的创建、发放以及信任对 P2P 网络是个问题,所以 P2P 网络倾向于使用自己的安全协议,或者使用 noise protocol,来构建安全等级可以媲美 TLS 1.3 的安全协议。
Rust 如何处理P2P网络
在 Rust 下,有 libp2p 这个比较成熟的库来处理 P2P 网络。
下面是一个简单的P2P 聊天应用,在本地网络中通过 MDNS 做节点发现,使用 floodpub 做消息传播。在关键位置都写了注释:
use anyhow::Result; use futures::StreamExt; use libp2p::{ core::upgrade, floodsub::{self, Floodsub, FloodsubEvent, Topic}, identity, mdns::{Mdns, MdnsEvent}, noise, swarm::{NetworkBehaviourEventProcess, SwarmBuilder, SwarmEvent}, tcp::TokioTcpConfig, yamux, NetworkBehaviour, PeerId, Swarm, Transport, }; use std::borrow::Cow; use tokio::io::{stdin, AsyncBufReadExt, BufReader}; /// 处理 p2p 网络的 behavior 数据结构 /// 里面的每个域需要实现 NetworkBehaviour,或者使用 #[behaviour(ignore)] #[derive(NetworkBehaviour)] #[behaviour(event_process = true)] struct ChatBehavior { /// flood subscription,比较浪费带宽,gossipsub 是更好的选择 floodsub: Floodsub, /// 本地节点发现机制 mdns: Mdns, // 在 behavior 结构中,你也可以放其它数据,但需要 ignore // #[behaviour(ignore)] // _useless: String, } impl ChatBehavior { /// 创建一个新的 ChatBehavior pub async fn new(id: PeerId) -> Result<Self> { Ok(Self { mdns: Mdns::new(Default::default()).await?, floodsub: Floodsub::new(id), }) } } impl NetworkBehaviourEventProcess<FloodsubEvent> for ChatBehavior { // 处理 floodsub 产生的消息 fn inject_event(&mut self, event: FloodsubEvent) { if let FloodsubEvent::Message(msg) = event { let text = String::from_utf8_lossy(&msg.data); println!("{:?}: {:?}", msg.source, text); } } } impl NetworkBehaviourEventProcess<MdnsEvent> for ChatBehavior { fn inject_event(&mut self, event: MdnsEvent) { match event { MdnsEvent::Discovered(list) => { // 把 mdns 发现的新的 peer 加入到 floodsub 的 view 中 for (id, addr) in list { println!("Got peer: {} with addr {}", &id, &addr); self.floodsub.add_node_to_partial_view(id); } } MdnsEvent::Expired(list) => { // 把 mdns 发现的离开的 peer 加入到 floodsub 的 view 中 for (id, addr) in list { println!("Removed peer: {} with addr {}", &id, &addr); self.floodsub.remove_node_from_partial_view(&id); } } } } } #[tokio::main] async fn main() -> Result<()> { // 如果带参数,当成一个 topic let name = match std::env::args().nth(1) { Some(arg) => Cow::Owned(arg), None => Cow::Borrowed("lobby"), }; // 创建 floodsub topic let topic = floodsub::Topic::new(name); // 创建 swarm let mut swarm = create_swarm(topic.clone()).await?; swarm.listen_on("/ip4/127.0.0.1/tcp/0".parse()?)?; // 获取 stdin 的每一行 let mut stdin = BufReader::new(stdin()).lines(); // main loop loop { tokio::select! { line = stdin.next_line() => { let line = line?.expect("stdin closed"); swarm.behaviour_mut().floodsub.publish(topic.clone(), line.as_bytes()); } event = swarm.select_next_some() => { if let SwarmEvent::NewListenAddr { address, .. } = event { println!("Listening on {:?}", address); } } } } } async fn create_swarm(topic: Topic) -> Result<Swarm<ChatBehavior>> { // 创建 identity(密钥对) let id_keys = identity::Keypair::generate_ed25519(); let peer_id = PeerId::from(id_keys.public()); println!("Local peer id: {:?}", peer_id); // 使用 noise protocol 来处理加密和认证 let noise_keys = noise::Keypair::<noise::X25519Spec>::new().into_authentic(&id_keys)?; // 创建传输层 let transport = TokioTcpConfig::new() .nodelay(true) .upgrade(upgrade::Version::V1) .authenticate(noise::NoiseConfig::xx(noise_keys).into_authenticated()) .multiplex(yamux::YamuxConfig::default()) .boxed(); // 创建 chat behavior let mut behavior = ChatBehavior::new(peer_id.clone()).await?; // 订阅某个主题 behavior.floodsub.subscribe(topic.clone()); // 创建 swarm let swarm = SwarmBuilder::new(transport, behavior, peer_id) .executor(Box::new(|fut| { tokio::spawn(fut); })) .build(); Ok(swarm) }
要运行这段代码,你需要在 Cargo.toml 中使用 futures 和 libp2p:
#![allow(unused)] fn main() { futures = "0.3" libp2p = { version = "0.39", features = ["tcp-tokio"] } }
完整的代码可以在这门课程 GitHub repo 这一讲的目录中找到。
如果你开一个窗口 A 运行:
❯ cargo run --example p2p_chat --quiet
Local peer id: PeerId("12D3KooWDJtZVKBCa7B9C8ZQmRpP7cB7CgeG7PWLXYCnN3aXkaVg")
Listening on "/ip4/127.0.0.1/tcp/51654"
// 下面的内容在新节点加入时逐渐出现
Got peer: 12D3KooWAw1gTLCesw1bvTiKNYFyacwbAcjvKwfDsJiH8AuBFgFA with addr /ip4/192.168.86.23/tcp/51656
Got peer: 12D3KooWAw1gTLCesw1bvTiKNYFyacwbAcjvKwfDsJiH8AuBFgFA with addr /ip4/127.0.0.1/tcp/51656
Got peer: 12D3KooWMRQvxJcjcexCrNfgSVd2iChpiDWzbgRRS6c5mn9bBzdT with addr /ip4/192.168.86.23/tcp/51661
Got peer: 12D3KooWMRQvxJcjcexCrNfgSVd2iChpiDWzbgRRS6c5mn9bBzdT with addr /ip4/127.0.0.1/tcp/51661
Got peer: 12D3KooWRy9r8j7UQMxavqTcNmoz1JmnLcTU5UZvzvE5jz4Zw3eh with addr /ip4/192.168.86.23/tcp/51670
Got peer: 12D3KooWRy9r8j7UQMxavqTcNmoz1JmnLcTU5UZvzvE5jz4Zw3eh with addr /ip4/127.0.0.1/tcp/51670
然后窗口 B / C 分别运行:
❯ cargo run --example p2p_chat --quiet
Local peer id: PeerId("12D3KooWAw1gTLCesw1bvTiKNYFyacwbAcjvKwfDsJiH8AuBFgFA")
Listening on "/ip4/127.0.0.1/tcp/51656"
Got peer: 12D3KooWDJtZVKBCa7B9C8ZQmRpP7cB7CgeG7PWLXYCnN3aXkaVg with addr /ip4/192.168.86.23/tcp/51654
Got peer: 12D3KooWDJtZVKBCa7B9C8ZQmRpP7cB7CgeG7PWLXYCnN3aXkaVg with addr /ip4/127.0.0.1/tcp/51654
// 下面的内容在新节点加入时逐渐出现
Got peer: 12D3KooWMRQvxJcjcexCrNfgSVd2iChpiDWzbgRRS6c5mn9bBzdT with addr /ip4/192.168.86.23/tcp/51661
Got peer: 12D3KooWMRQvxJcjcexCrNfgSVd2iChpiDWzbgRRS6c5mn9bBzdT with addr /ip4/127.0.0.1/tcp/51661
Got peer: 12D3KooWRy9r8j7UQMxavqTcNmoz1JmnLcTU5UZvzvE5jz4Zw3eh with addr /ip4/192.168.86.23/tcp/51670
Got peer: 12D3KooWRy9r8j7UQMxavqTcNmoz1JmnLcTU5UZvzvE5jz4Zw3eh with addr /ip4/127.0.0.1/tcp/51670
❯ cargo run --example p2p_chat --quiet
Local peer id: PeerId("12D3KooWMRQvxJcjcexCrNfgSVd2iChpiDWzbgRRS6c5mn9bBzdT")
Listening on "/ip4/127.0.0.1/tcp/51661"
Got peer: 12D3KooWAw1gTLCesw1bvTiKNYFyacwbAcjvKwfDsJiH8AuBFgFA with addr /ip4/192.168.86.23/tcp/51656
Got peer: 12D3KooWAw1gTLCesw1bvTiKNYFyacwbAcjvKwfDsJiH8AuBFgFA with addr /ip4/127.0.0.1/tcp/51656
Got peer: 12D3KooWDJtZVKBCa7B9C8ZQmRpP7cB7CgeG7PWLXYCnN3aXkaVg with addr /ip4/192.168.86.23/tcp/51654
Got peer: 12D3KooWDJtZVKBCa7B9C8ZQmRpP7cB7CgeG7PWLXYCnN3aXkaVg with addr /ip4/127.0.0.1/tcp/51654
// 下面的内容在新节点加入时逐渐出现
Got peer: 12D3KooWRy9r8j7UQMxavqTcNmoz1JmnLcTU5UZvzvE5jz4Zw3eh with addr /ip4/192.168.86.23/tcp/51670
Got peer: 12D3KooWRy9r8j7UQMxavqTcNmoz1JmnLcTU5UZvzvE5jz4Zw3eh with addr /ip4/127.0.0.1/tcp/51670
然后窗口 D 使用 topic 参数,让它和其它的 topic 不同:
❯ cargo run --example p2p_chat --quiet -- hello
Local peer id: PeerId("12D3KooWRy9r8j7UQMxavqTcNmoz1JmnLcTU5UZvzvE5jz4Zw3eh")
Listening on "/ip4/127.0.0.1/tcp/51670"
Got peer: 12D3KooWMRQvxJcjcexCrNfgSVd2iChpiDWzbgRRS6c5mn9bBzdT with addr /ip4/192.168.86.23/tcp/51661
Got peer: 12D3KooWMRQvxJcjcexCrNfgSVd2iChpiDWzbgRRS6c5mn9bBzdT with addr /ip4/127.0.0.1/tcp/51661
Got peer: 12D3KooWAw1gTLCesw1bvTiKNYFyacwbAcjvKwfDsJiH8AuBFgFA with addr /ip4/192.168.86.23/tcp/51656
Got peer: 12D3KooWAw1gTLCesw1bvTiKNYFyacwbAcjvKwfDsJiH8AuBFgFA with addr /ip4/127.0.0.1/tcp/51656
Got peer: 12D3KooWDJtZVKBCa7B9C8ZQmRpP7cB7CgeG7PWLXYCnN3aXkaVg with addr /ip4/192.168.86.23/tcp/51654
Got peer: 12D3KooWDJtZVKBCa7B9C8ZQmRpP7cB7CgeG7PWLXYCnN3aXkaVg with addr /ip4/127.0.0.1/tcp/51654
你会看到,每个节点运行时,都会通过 MDNS 广播,来发现本地已有的 P2P 节点。现在 A/B/C/D 组成了一个 P2P 网络,其中 A/B/C 都订阅了 lobby,而 D 订阅了 hello。
我们在 A/B/C/D 四个窗口中分别输入 “Hello from X”,可以看到:
窗口 A:
hello from A
PeerId("12D3KooWAw1gTLCesw1bvTiKNYFyacwbAcjvKwfDsJiH8AuBFgFA"): "hello from B"
PeerId("12D3KooWMRQvxJcjcexCrNfgSVd2iChpiDWzbgRRS6c5mn9bBzdT"): "hello from C"
窗口 B:
PeerId("12D3KooWDJtZVKBCa7B9C8ZQmRpP7cB7CgeG7PWLXYCnN3aXkaVg"): "hello from A"
hello from B
PeerId("12D3KooWMRQvxJcjcexCrNfgSVd2iChpiDWzbgRRS6c5mn9bBzdT"): "hello from C"
窗口 C:
PeerId("12D3KooWDJtZVKBCa7B9C8ZQmRpP7cB7CgeG7PWLXYCnN3aXkaVg"): "hello from A"
PeerId("12D3KooWAw1gTLCesw1bvTiKNYFyacwbAcjvKwfDsJiH8AuBFgFA"): "hello from B"
hello from C
窗口 D:
hello from D
可以看到,在 lobby 下的 A/B/C 都收到了各自的消息。
这个使用 libp2p 的聊天代码,如果你读不懂,没关系。P2P 有大量的新的概念和协议需要预先掌握,这堂课我们也不是专门讲 P2P 的,所以如果你对这些概念和协议感兴趣,可以自行阅读 libp2p 的文档,以及它的 示例代码。
小结
从这上下两讲的代码中,我们可以看到,无论是处理高层的 HTTP 协议,还是处理比较底层的网络,Rust 都有非常丰富的工具供你使用。
通过 Rust 的网络生态,我们可以通过几十行代码就构建一个完整的 TCP 服务器,或者上百行代码构建一个简单的 P2P 聊天工具。如果你要构建自己的高性能网络服务器处理已知的协议,或者构建自己的协议,Rust 都可以很好地胜任。
我们需要使用各种手段来应对网络开发中的四个问题:网络是不可靠的、网络的延迟可能会非常大、带宽是有限的、网络是非常不安全的。同样,在之后 KV server 的实现中,我们也会用一讲来介绍如何使用 TLS 来构建安全的网络。
思考题
- 看一看 libp2p 的文档和示例代码,把 libp2p clone 到本地,运行每个示例代码。
- 阅读 libp2p 的 NetworkBehaviour trait,以及 floodsub 对应的 实现。
- 如有余力和兴趣,尝试把这个例子中的 floodsub 替换成更高效更节省带宽的 gossipsub。
恭喜你已经完成了Rust学习的第29次打卡,如果你觉得有收获,也欢迎你分享给身边的朋友,邀他一起讨论。我们下节课见~
Unsafe Rust:如何用C++的方式打开Rust?
你好,我是陈天。
到目前为止,我们撰写的代码都在 Rust 精心构造的内存安全的国度里做一个守法好公民。通过遵循所有权、借用检查、生命周期等规则,我们自己的代码一旦编译通过,就相当于信心满满地向全世界宣布:这个代码是安全的!
然而,安全的 Rust 并不能适应所有的使用场景。
首先, 为了内存安全,Rust 所做的这些规则往往是普适性的,编译器会把一切可疑的行为都严格地制止掉。可是,这种一丝不苟的铁面无情往往会过于严苛,导致错杀。
就好比“屋子的主人只会使用钥匙开门,如果一个人尝试着撬门,那一定是坏人”,正常情况下,这个逻辑是成立的,所有尝试撬门的小偷,都会被抓获(编译错误);然而,有时候主人丢了钥匙,不得不请开锁匠开门(unsafe code),此时,是正常的诉求,是可以网开一面的。
其次,无论 Rust 将其内部的世界构建得多么纯粹和完美,它总归是 要跟不纯粹也不完美的外界打交道,无论是硬件还是软件。
计算机硬件本身是 unsafe 的,比如操作 IO 访问外设,或者使用汇编指令进行特殊操作(操作 GPU或者使用 SSE 指令集)。这样的操作,编译器是无法保证内存安全的,所以我们需要 unsafe 来告诉编译器要法外开恩。
同样的,当 Rust 要访问其它语言比如 C/C++ 的库,因为它们并不满足 Rust 的安全性要求,这种跨语言的 FFI(Foreign Function Interface),也是 unsafe 的。
这两种使用 unsafe Rust 的方式是不得而为之,所以情有可原,是我们需要使用 unsafe Rust 的主要原因。
还有一大类使用 unsafe Rust 纯粹是为了性能。比如略过边界检查、使用未初始化内存等。 这样的 unsafe 我们要尽量不用,除非通过 benchmark 发现用 unsafe 可以解决某些性能瓶颈,否则使用起来得不偿失。因为,在使用 unsafe 代码的时候,我们已经把 Rust 的内存安全性,降低到了和 C++ 同等的水平。
可以使用 unsafe 的场景
好,在了解了为什么需要 unsafe Rust 之后,我们再来看看在日常工作中,都具体有哪些地方会用到 unsafe Rust。
我们先看可以使用、也推荐使用 unsafe 的场景,根据重要/常用程度,会依次介绍:实现 unsafe trait,主要是 Send / Sync 这两个 trait、调用已有的 unsafe 接口、对裸指针做解引用,以及使用 FFI。
实现 unsafe trait
Rust 里,名气最大的 unsafe 代码应该就是 Send / Sync 这两个 trait 了:
#![allow(unused)] fn main() { pub unsafe auto trait Send {} pub unsafe auto trait Sync {} }
相信你应该对这两个 trait 非常了解了,但凡遇到和并发相关的代码,尤其是接口的类型声明时,少不了要使用 Send / Sync 来约束。我们也知道,绝大多数数据结构都实现了 Send / Sync,但有一些例外,比如 Rc / RefCell /裸指针等。
因为 Send / Sync 是 auto trait,所以大部分情况下,你自己的数据结构不需要实现 Send / Sync,然而,当你在数据结构里使用裸指针时, 因为裸指针是没有实现 Send/Sync 的,连带着你的数据结构也就没有实现 Send/Sync。但很可能你的结构是线程安全的,你也需要它线程安全。
此时,如果你可以保证它能在线程中安全地移动,那可以实现 Send;如果可以保证它能在线程中安全地共享,也可以去实现 Sync。之前我们讨论过的 Bytes 就在使用裸指针的情况下实现了 Send / Sync:
#![allow(unused)] fn main() { pub struct Bytes { ptr: *const u8, len: usize, // inlined "trait object" data: AtomicPtr<()>, vtable: &'static Vtable, } // Vtable must enforce this behavior unsafe impl Send for Bytes {} unsafe impl Sync for Bytes {} }
但是,在实现 Send/Sync 的时候要特别小心, 如果你无法保证数据结构的线程安全,错误实现 Send/Sync之后,会导致程序出现莫名其妙的还不太容易复现的崩溃。
比如下面的代码,强行为 Evil 实现了 Send,而 Evil 内部携带的 Rc 是不允许实现 Send 的。这段代码通过实现 Send 而规避了 Rust 的并发安全检查,使其可以编译通过( 代码):
use std::{cell::RefCell, rc::Rc, thread}; #[derive(Debug, Default, Clone)] struct Evil { data: Rc<RefCell<usize>>, } // 为 Evil 强行实现 Send,这会让 Rc 整个紊乱 unsafe impl Send for Evil {} fn main() { let v = Evil::default(); let v1 = v.clone(); let v2 = v.clone(); let t1 = thread::spawn(move || { let v3 = v.clone(); let mut data = v3.data.borrow_mut(); *data += 1; println!("v3: {:?}", data); }); let t2 = thread::spawn(move || { let v4 = v1.clone(); let mut data = v4.data.borrow_mut(); *data += 1; println!("v4: {:?}", data); }); t2.join().unwrap(); t1.join().unwrap(); let mut data = v2.data.borrow_mut(); *data += 1; println!("v2: {:?}", data); }
然而在运行的时候,有一定的几率出现崩溃:
❯ cargo run --example rc_send
v4: 1
v3: 2
v2: 3
❯ cargo run --example rc_send
v4: 1
thread '<unnamed>' panicked at 'already borrowed: BorrowMutError', examples/rc_send.rs:18:32
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
thread 'main' panicked at 'called `Result::unwrap()` on an `Err` value: Any { .. }', examples/rc_send.rs:31:15
所以,如果你没有十足的把握,不宜胡乱实现 Send/Sync。
既然我们提到了 unsafe trait,你也许会好奇,什么 trait 会是 unsafe 呢?除了 Send/Sync 外,还会有其他 unsafe trait 么?当然会有。
任何 trait,只要声明成 unsafe,它就是一个 unsafe trait。而一个正常的 trait 里也可以包含 unsafe 函数,我们看下面的示例( 代码):
// 实现这个 trait 的开发者要保证实现是内存安全的 unsafe trait Foo { fn foo(&self); } trait Bar { // 调用这个函数的人要保证调用是安全的 unsafe fn bar(&self); } struct Nonsense; unsafe impl Foo for Nonsense { fn foo(&self) { println!("foo!"); } } impl Bar for Nonsense { unsafe fn bar(&self) { println!("bar!"); } } fn main() { let nonsense = Nonsense; // 调用者无需关心 safety nonsense.foo(); // 调用者需要为 safety 负责 unsafe { nonsense.bar() }; }
可以看到, unsafe trait 是对 trait 的实现者的约束,它告诉 trait 的实现者:实现我的时候要小心,要保证内存安全,所以实现的时候需要加 unsafe 关键字。
但 unsafe trait 对于调用者来说,可以正常调用,不需要任何 unsafe block,因为这里的 safety 已经被实现者保证了,毕竟如果实现者没保证,调用者也做不了什么来保证 safety,就像我们使用 Send/Sync 一样。
而 unsafe fn 是函数对调用者的约束,它告诉函数的调用者:如果你胡乱使用我,会带来内存安全方面的问题,请妥善使用,所以调用 unsafe fn 时,需要加 unsafe block 提醒别人注意。
再来看一个实现和调用都是 unsafe 的 trait:GlobalAlloc。
下面这段代码在智能指针的 那一讲 中我们见到过,通过 GlobalAlloc 我们可以实现自己的内存分配器。因为内存分配器对内存安全的影响很大,所以实现者需要保证每个实现都是内存安全的。同时,alloc/dealloc 这样的方法,使用不正确的姿势去调用,也会发生内存安全的问题,所以这两个方法也是 unsafe 的:
#![allow(unused)] fn main() { use std::alloc::{GlobalAlloc, Layout, System}; struct MyAllocator; unsafe impl GlobalAlloc for MyAllocator { unsafe fn alloc(&self, layout: Layout) -> *mut u8 { let data = System.alloc(layout); eprintln!("ALLOC: {:p}, size {}", data, layout.size()); data } unsafe fn dealloc(&self, ptr: *mut u8, layout: Layout) { System.dealloc(ptr, layout); eprintln!("FREE: {:p}, size {}", ptr, layout.size()); } } #[global_allocator] static GLOBAL: MyAllocator = MyAllocator; }
好,unsafe trait 就讲这么多,如果你想了解更多详情,可以看 Rust RFC2585。如果你想看一个完整的 unsafe trait 定义到实现的过程,可以看 BufMut。
调用已有的 unsafe 函数
接下来我们讲 unsafe 函数。有些时候,你会发现,标准库或者第三方库提供给你的函数本身就标明了 unsafe。比如我们之前为了打印 HashMap 结构所使用的 transmute 函数:
use std::collections::HashMap; fn main() { let map = HashMap::new(); let mut map = explain("empty", map); map.insert(String::from("a"), 1); explain("added 1", map); } // HashMap 结构有两个 u64 的 RandomState,然后是四个 usize, // 分别是 bucket_mask, ctrl, growth_left 和 items // 我们 transmute 打印之后,再 transmute 回去 fn explain<K, V>(name: &str, map: HashMap<K, V>) -> HashMap<K, V> { let arr: [usize; 6] = unsafe { std::mem::transmute(map) }; println!( "{}: bucket_mask 0x{:x}, ctrl 0x{:x}, growth_left: {}, items: {}", name, arr[2], arr[3], arr[4], arr[5] ); // 因为 std:mem::transmute 是一个 unsafe 函数,所以我们需要 unsafe unsafe { std::mem::transmute(arr) } }
前面已经说过,要调用一个 unsafe 函数,你需要使用 unsafe block 把它包裹起来。这相当于在提醒大家,注意啊,这里有 unsafe 代码!
另一种调用 unsafe 函数的方法是定义 unsafe fn,然后在这个 unsafe fn 里调用其它 unsafe fn。
如果你阅读一些标准库的代码会发现,有时候同样的功能,Rust 会提供 unsafe 和 safe 的版本,比如,把 &[u8] 里的数据 转换成字符串:
#![allow(unused)] fn main() { // safe 版本,验证合法性,如果不合法返回错误 pub fn from_utf8(v: &[u8]) -> Result<&str, Utf8Error> { run_utf8_validation(v)?; // SAFETY: Just ran validation. Ok(unsafe { from_utf8_unchecked(v) }) } // 不验证合法性,调用者需要确保 &[u8] 里都是合法的字符 pub const unsafe fn from_utf8_unchecked(v: &[u8]) -> &str { // SAFETY: the caller must guarantee that the bytes `v` are valid UTF-8. // Also relies on `&str` and `&[u8]` having the same layout. unsafe { mem::transmute(v) } } }
安全的 str::from_utf8() 内部做了一些检查后,实际调用了 str::from_utf8_unchecked()。如果我们不需要做这一层检查,这个调用可以高效很多(可能是一个量级的区别),因为 unsafe 的版本就只是一个类型的转换而已。
那么这样有两个版本的接口,我们该如何调用呢?
如果你并不是特别明确,一定要调用安全的版本,不要为了性能的优势而去调用不安全的版本。如果你清楚地知道,&[u8] 你之前已经做过检查,或者它本身就来源于你从 &str 转换成的 &[u8],现在只不过再转换回去,那可以调用不安全的版本,并在注释中注明为什么这里是安全的。
对裸指针解引用
unsafe trait 和 unsafe fn 的使用就了解到这里啦,我们再看裸指针。很多时候,如果需要进行一些特殊处理,我们会把得到的数据结构转换成裸指针,比如刚才的 Bytes。
裸指针在生成的时候无需 unsafe,因为它并没有内存不安全的操作,但裸指针的解引用操作是不安全的,潜在有风险,它也需要使用 unsafe 来明确告诉编译器,以及代码的阅读者,也就是说要使用 unsafe block 包裹起来。
下面是一段对裸指针解引用的操作( 代码):
fn main() { let mut age = 18; // 不可变指针 let r1 = &age as *const i32; // 可变指针 let r2 = &mut age as *mut i32; // 使用裸指针,可以绕过 immutable / mutable borrow rule // 然而,对指针解引用需要使用 unsafe unsafe { println!("r1: {}, r2: {}", *r1, *r2); } } fn immutable_mutable_cant_coexist() { let mut age = 18; let r1 = &age; // 编译错误 let r2 = &mut age; println!("r1: {}, r2: {}", *r1, *r2); }
我们可以看到,使用裸指针,可变指针和不可变指针可以共存,不像可变引用和不可变引用无法共存。这是因为裸指针的任何对内存的操作,无论是 ptr::read / ptr::write,还是解引用,都是unsafe 的操作,所以只要读写内存,裸指针的使用者就需要对内存安全负责。
你也许会觉得奇怪,这里也没有内存不安全的操作啊,为啥需要 unsafe 呢?是的,虽然在这个例子里,裸指针来源于一个可信的内存地址,所有的代码都是安全的,但是,下面的代码就是不安全的,会导致 segment fault( 代码):
fn main() { // 裸指针指向一个有问题的地址 let r1 = 0xdeadbeef as *mut u32; println!("so far so good!"); unsafe { // 程序崩溃 *r1 += 1; println!("r1: {}", *r1); } }
这也是为什么我们在撰写 unsafe Rust 的时候,要慎之又慎,并且在 unsafe 代码中添加足够的注释来阐述为何你觉得可以保证这段代码的安全。
使用裸指针的时候,大部分操作都是 unsafe 的(下图里表三角惊叹号的):

如果你对此感兴趣,可以查阅 std::ptr 的文档。
使用 FFI
最后一种可以使用 unsafe 的地方是 FFI。
当 Rust 要使用其它语言的能力时,Rust 编译器并不能保证那些语言具备内存安全,所以和第三方语言交互的接口,一律要使用 unsafe,比如,我们调用 libc 来进行 C 语言开发者熟知的 malloc/free( 代码):
use std::mem::transmute; fn main() { let data = unsafe { let p = libc::malloc(8); let arr: &mut [u8; 8] = transmute(p); arr }; data.copy_from_slice(&[1, 2, 3, 4, 5, 6, 7, 8]); println!("data: {:?}", data); unsafe { libc::free(transmute(data)) }; }
从代码中可以看到,所有的对 libc 函数的调用,都需要使用 unsafe block。下节课我们会花一讲的时间谈谈 Rust 如何做 FFI,到时候细讲。
不推荐的使用 unsafe 的场景
以上是我们可以使用 unsafe 的场景。还有一些情况可以使用 unsafe,但是,我并不推荐。比如处理未初始化数据、访问可变静态变量、使用 unsafe 提升性能。
虽然不推荐使用,但它们作为一种用法,在标准库和第三方库中还是会出现,我们即便自己不写,在遇到的时候,也最好能够读懂它们。
访问或者修改可变静态变量
首先是可变静态变量。之前的课程中,我们见识过全局的 static 变量,以及使用 lazy_static 来声明复杂的 static 变量。然而之前遇到的 static 变量都是不可变的。
Rust 还支持可变的 static 变量,可以使用 static mut 来声明。
显而易见的是,全局变量如果可写,会潜在有线程不安全的风险,所以如果你声明 static mut 变量,在访问时,统统都需要使用 unsafe。以下的代码就使用了 static mut,并试图在两个线程中分别改动它。你可以感受到,这个代码的危险( 代码):
use std::thread; static mut COUNTER: usize = 1; fn main() { let t1 = thread::spawn(move || { unsafe { COUNTER += 10 }; }); let t2 = thread::spawn(move || { unsafe { COUNTER *= 10 }; }); t2.join().unwrap(); t1.join().unwrap(); unsafe { println!("COUNTER: {}", COUNTER) }; }
其实我们完全没必要这么做。对于上面的场景,我们可以使用 AtomicXXX 来改进:
use std::{ sync::atomic::{AtomicUsize, Ordering}, thread, }; static COUNTER: AtomicUsize = AtomicUsize::new(1); fn main() { let t1 = thread::spawn(move || { COUNTER.fetch_add(10, Ordering::SeqCst); }); let t2 = thread::spawn(move || { COUNTER .fetch_update(Ordering::SeqCst, Ordering::SeqCst, |v| Some(v * 10)) .unwrap(); }); t2.join().unwrap(); t1.join().unwrap(); println!("COUNTER: {}", COUNTER.load(Ordering::Relaxed)); }
有同学可能会问:如果我的数据结构比较复杂,无法使用 AtomicXXX 呢?
如果你需要定义全局的可变状态,那么,你还可以使用 Mutex
use lazy_static::lazy_static; use std::{collections::HashMap, sync::Mutex, thread}; // 使用 lazy_static 初始化复杂的结构 lazy_static! { // 使用 Mutex / RwLock 来提供安全的并发写访问 static ref STORE: Mutex<HashMap<&'static str, &'static [u8]>> = Mutex::new(HashMap::new()); } fn main() { let t1 = thread::spawn(move || { let mut store = STORE.lock().unwrap(); store.insert("hello", b"world"); }); let t2 = thread::spawn(move || { let mut store = STORE.lock().unwrap(); store.insert("goodbye", b"world"); }); t2.join().unwrap(); t1.join().unwrap(); println!("store: {:?}", STORE.lock().unwrap()); }
所以,我非常不建议你使用 static mut。 任何需要 static mut 的地方,都可以用 AtomicXXX / Mutex / RwLock 来取代。千万不要为了一时之快,给程序种下长远的祸根。
在宏里使用 unsafe
虽然我们并没有介绍宏编程,但已经在很多场合使用过宏了,宏可以在编译时生成代码。
在宏中使用 unsafe,是非常危险的。
首先使用你的宏的开发者,可能压根不知道 unsafe 代码的存在;其次,含有 unsafe 代码的宏在被使用到的时候,相当于把 unsafe 代码注入到当前上下文中。在不知情的情况下,开发者到处调用这样的宏,会导致 unsafe 代码充斥在系统的各个角落,不好处理;最后,一旦 unsafe 代码出现问题,你可能都很难找到问题的根本原因。
以下是 actix_web 代码库中的 downcast_dyn 宏,你可以感受到本来就比较晦涩的宏,跟 unsafe 碰撞在一起,那种令空气都凝固了的死亡气息:
#![allow(unused)] fn main() { // Generate implementation for dyn $name macro_rules! downcast_dyn { ($name:ident) => { /// A struct with a private constructor, for use with /// `__private_get_type_id__`. Its single field is private, /// ensuring that it can only be constructed from this module #[doc(hidden)] #[allow(dead_code)] pub struct PrivateHelper(()); impl dyn $name + 'static { /// Downcasts generic body to a specific type. #[allow(dead_code)] pub fn downcast_ref<T: $name + 'static>(&self) -> Option<&T> { if self.__private_get_type_id__(PrivateHelper(())).0 == std::any::TypeId::of::<T>() { // SAFETY: external crates cannot override the default // implementation of `__private_get_type_id__`, since // it requires returning a private type. We can therefore // rely on the returned `TypeId`, which ensures that this // case is correct. unsafe { Some(&*(self as *const dyn $name as *const T)) } } else { None } } /// Downcasts a generic body to a mutable specific type. #[allow(dead_code)] pub fn downcast_mut<T: $name + 'static>(&mut self) -> Option<&mut T> { if self.__private_get_type_id__(PrivateHelper(())).0 == std::any::TypeId::of::<T>() { // SAFETY: external crates cannot override the default // implementation of `__private_get_type_id__`, since // it requires returning a private type. We can therefore // rely on the returned `TypeId`, which ensures that this // case is correct. unsafe { Some(&mut *(self as *const dyn $name as *const T as *mut T)) } } else { None } } } }; } }
所以,除非你是一个 unsafe 以及宏编程的老手,否则不建议这么做。
使用 unsafe 提升性能
unsafe 代码在很多 Rust 基础库中有大量的使用,比如哈希表那一讲提到的 hashbrown,如果看它的代码库,你会发现一共有 222 处使用 unsafe:
hashbrown on master
❯ ag "unsafe" | wc -l
222
这些 unsafe 代码,大多是为了性能而做的妥协。
比如下面的代码就使用了 SIMD 指令来加速处理:
#![allow(unused)] fn main() { unsafe { // A byte is EMPTY or DELETED iff the high bit is set BitMask(x86::_mm_movemask_epi8(self.0) as u16) } }
然而,如果你不是在撰写非常基础的库,并且这个库处在系统的关键路径上,我也很不建议使用 unsafe 来提升性能。
性能,是一个系统级的问题。在你没有解决好架构、设计、算法、网络、存储等其他问题时,就来抠某个函数的实现细节的性能,我认为是不妥的,尤其是试图通过使用 unsafe 代码,跳过一些检查来提升性能。
要知道,好的算法和不好的算法可以有数量级上的性能差异。 而有些时候,即便你能够使用 unsafe 让局部性能达到最优,但作为一个整体看的时候,这个局部的优化可能根本没有意义。
所以,如果你用 Rust 做 Web 开发、做微服务、做客户端,很可能都不需要专门撰写 unsafe 代码来提升性能。
撰写 unsafe 代码
了解了unsafe可以使用和不建议使用的具体场景,最后,我们来写一段小小的代码,看看如果实际工作中,遇到不得不写 unsafe 代码时,该怎么做。
需求是要实现一个 split() 函数,得到一个字符串 s,按照字符 sep 第一次出现的位置,把字符串 s 截成前后两个字符串。这里,当找到字符 sep 的位置 pos 时,我们需要使用一个函数,得到从字符串开头到 pos 的子串,以及从字符 sep 之后到字符串结尾的子串。
要获得这个子串,Rust 有安全的 get 方法,以及不安全的 get_unchecked 方法。正常情况下,我们应该使用 get() 方法,但这个实例,我们就强迫自己使用 get_unchecked() 来跳过检查。
先看这个函数的安全性要求:

在遇到 unsafe 接口时,我们都应该仔细阅读其安全须知,然后思考如何能满足它。如果你自己对外提供 unsafe 函数,也应该在文档中详细地给出类似的安全须知,告诉调用者,怎么样调用你的函数才算安全。
对于 split 的需求,我们完全可以满足 get_unchecked() 的安全要求,以下是实现( 代码):
fn main() { let mut s = "我爱你!中国".to_string(); let r = s.as_mut(); if let Some((s1, s2)) = split(r, '!') { println!("s1: {}, s2: {}", s1, s2); } } fn split(s: &str, sep: char) -> Option<(&str, &str)> { let pos = s.find(sep); pos.map(|pos| { let len = s.len(); let sep_len = sep.len_utf8(); // SAFETY: pos 是 find 得到的,它位于字符的边界处,同样 pos + sep_len 也是如此 // 所以以下代码是安全的 unsafe { (s.get_unchecked(0..pos), s.get_unchecked(pos + sep_len..len)) } }) }
同样的,在撰写 unsafe 代码调用别人的 unsafe 函数时,我们一定要用注释声明代码的安全性,这样,别人在阅读我们的代码时,可以明白为什么此处是安全的、是符合这个 unsafe 函数的预期的。
小结
unsafe 代码,是 Rust 这样的系统级语言必须包含的部分,当 Rust 跟硬件、操作系统,以及其他语言打交道,unsafe 是必不可少的。
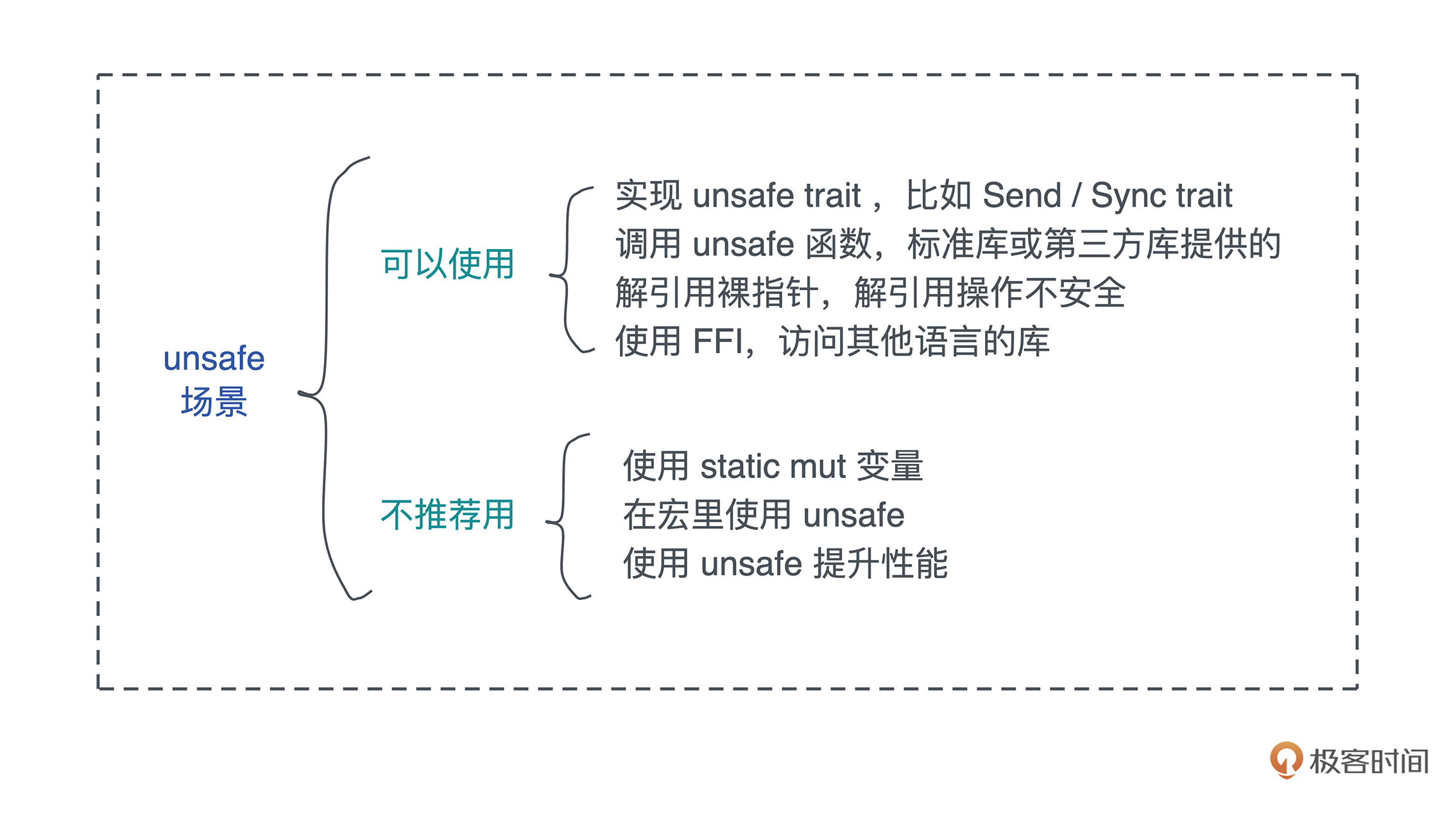
当我们使用 unsafe 撰写 Rust 代码时,要格外小心,因为此时编译器已经把内存安全的权杖完全交给了你,在打开 unsafe block 的那一刻,你会获得 C/C++ 代码般的自由度,但这个自由背后的代价就是安全性上的妥协。
好的 unsafe 代码,足够短小、精简,只包含不得不包含的内容。unsafe 代码是开发者对编译器和其它开发者的一种庄重的承诺:我宣誓,这段代码是安全的。
今天讲的内容里的很多代码都是反面教材,并不建议你大量使用,尤其是初学者。那为什么我们还要讲 unsafe 代码呢?老子说:知其雄守其雌。我们要知道 Rust 的阴暗面(unsafe rust),才更容易守得住它光明的那一面(safe rust)。
这一讲了解了 unsafe 代码的使用场景,希望你日后,在阅读 unsafe 代码的时候,不再心里发怵;同时,在撰写 unsafe 代码时,能够对其足够敬畏。
思考题
上文中,我们使用 s.get_unchecked() 来获取一个子字符串,通过使用合适的 pos,可以把一个字符串 split 成两个。如果我们需要一个 split_mut 接口怎么实现?
#![allow(unused)] fn main() { fn split_mut(s: &mut str, sep: char) -> (&mut str, &mut str) }
你可以尝试使用 get_unchecked_mut(),看看代码能否编译通过?想想为什么?然后,试着自己构建 unsafe 代码实现一下?
小提示,你可以把 s 先转换成裸指针,然后再用 std::slice::from_raw_parts_mut() 通过一个指针和一个长度,构建出一个 slice(还记得 &[u8] 其实内部就是一个 ptr + len 么?)。然后,再通过 std::str::from_utf8_unchecked_mut() 构建出 &mut str。
感谢你的收听,今天你完成了Rust学习的第30次打卡。如果你觉得有收获,也欢迎你分享给身边的朋友,邀他一起讨论。我们下节课见~
FFI:Rust如何和你的语言架起沟通桥梁?
你好,我是陈天。
FFI(Foreign Function Interface),也就是外部函数接口,或者说语言交互接口,对于大部分开发者来说,是一个神秘的存在,平时可能几乎不会接触到它,更别说撰写 FFI 代码了。
其实你用的语言生态有很大一部分是由 FFI 构建的。比如你在 Python 下使用着 NumPy 愉快地做着数值计算,殊不知 NumPy 的底层细节都是由 C 构建的;当你用 Rust 时,能开心地使用着 OpenSSL 为你的 HTTP 服务保驾护航,其实底下也是 C 在处理着一切协议算法。
我们现在所处的软件世界,几乎所有的编程语言都在和 C 打造出来的生态系统打交道,所以, 一门语言,如果能跟 C ABI(Application Binary Interface)处理好关系,那么就几乎可以和任何语言互通。
当然,对于大部分其他语言的使用者来说,不知道如何和 C 互通也无所谓,因为开源世界里总有“前辈”们替我们铺好路让我们前进;但对于 Rust 语言的使用者来说,在别人铺好的路上前进之余,偶尔,我们自己也需要为自己、为别人铺一铺路。谁让 Rust 是一门系统级别的语言呢。所谓,能力越大,责任越大嘛。
也正因为此,当大部分语言都还在吸血 C 的生态时,Rust 在大大方方地极尽所能反哺生态。比如 cloudflare 和百度的 mesalink 就分别把纯 Rust 的 HTTP/3 实现 quiche 和 TLS 实现 Rustls,引入到 C/C++ 的生态里,让 C/C++ 的生态更美好、更安全。
所以现在,除了用 C/C++ 做底层外,越来越多的库会先用 Rust 实现,再构建出对应 Python( pyo3)、JavaScript(wasm)、Node.js( neon)、Swift( uniffi)、Kotlin(uniffi)等实现。
所以学习 Rust 有一个好处就是,学着学着,你会发现,不但能造一大堆轮子给自己用,还能造一大堆轮子给其它语言用,并且 Rust 的生态还很支持和鼓励你造轮子给其它语言用。于是乎,Java 的理想“一次撰写,到处使用”, 在 Rust 这里成了“一次撰写,到处调用”。
好,聊了这么多,你是不是已经非常好奇 Rust FFI 能力到底如何?其实之前我们见识过冰山一角,在 第 6 讲 get hands dirty 做的那个 SQL 查询工具,我们实现了 Python 和 Node.js 的绑定。今天,就来更广泛地学习一下 Rust 如何跟你的语言架构起沟通的桥梁。
Rust 调用C的库
首先看 Rust 和 C/C++ 的互操作。一般而言,当看到一个 C/C++ 库,我们想在 Rust 中使用它的时候,可以先撰写一些简单的 shim 代码,把想要暴露出来的接口暴露出来,然后使用 bindgen 来生成对应的 Rust FFI 代码。
bindgen 会生成低层的 Rust API,Rust 下约定俗成的方式是 将使用 bindgen 的 crate 命名为 xxx-sys,里面包含因为 FFI 而导致的大量 unsafe 代码。然后, 在这个基础上生成 xxx crate,用更高层的代码来封装这些低层的代码,为其它 Rust 开发者提供一套感觉更加 Rusty 的代码。
比如,围绕着低层的数据结构和函数,提供 Rust 自己的 struct / enum / trait 接口。
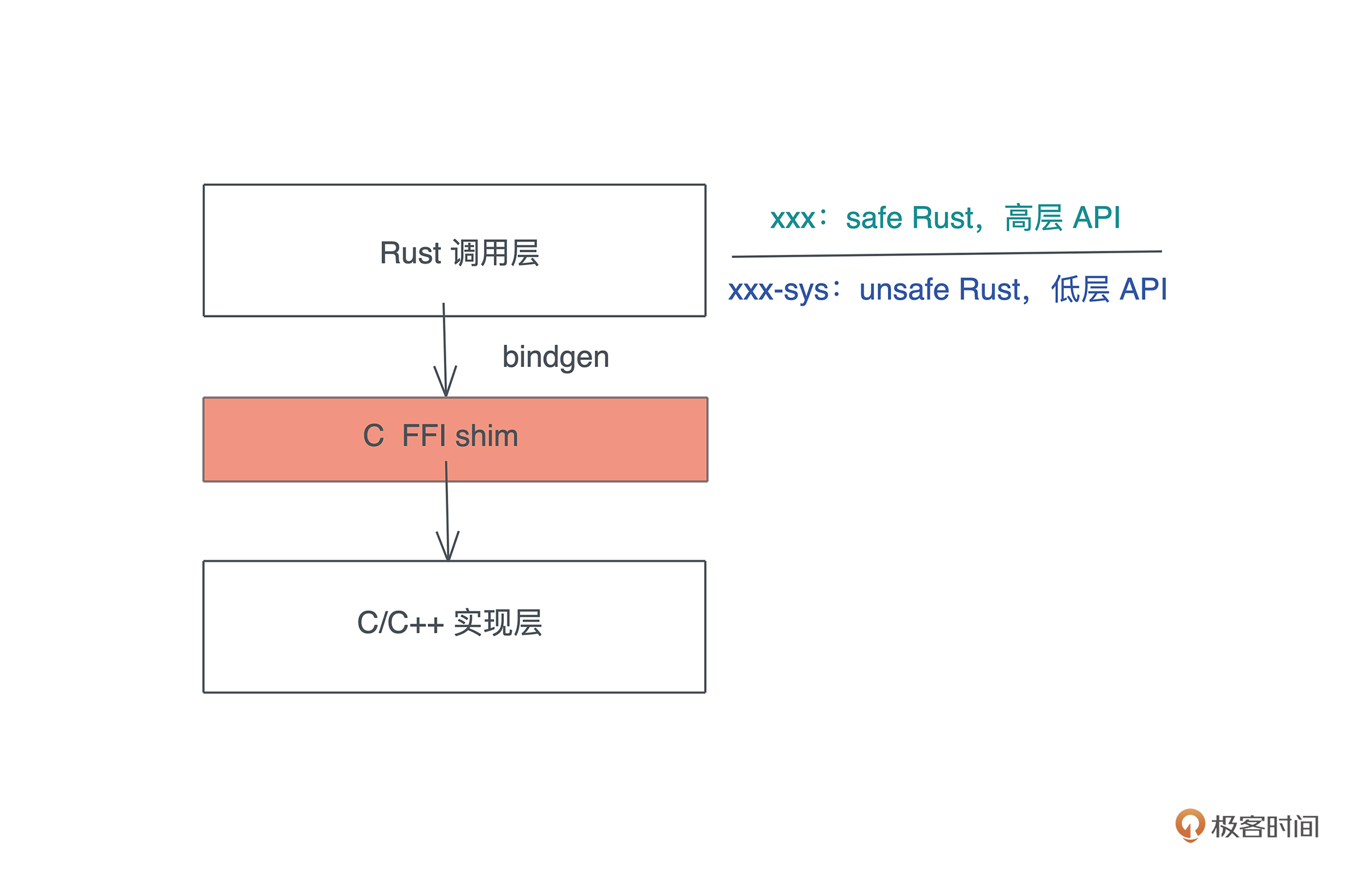
我们以使用 bindgen 来封装用于压缩/解压缩的 bz2 为例,看看 Rust 如何调用 C 的库(以下代码请在 OS X/Linux 下测试,使用 Windows 的同学可以参考 bzip2-sys)。
首先 cargo new bzlib-sys --lib 创建一个项目,然后在 Cargo.toml 中添入:
#![allow(unused)] fn main() { [dependencies] anyhow = "1" [build-dependencies] bindgen = "0.59" }
其中 bindgen 需要在编译期使用, 所以我们在根目录下创建一个 build.rs 使其在编译期运行:
fn main() { // 告诉 rustc 需要 link bzip2 println!("cargo:rustc-link-lib=bz2"); // 告诉 cargo 当 wrapper.h 变化时重新运行 println!("cargo:rerun-if-changed=wrapper.h"); // 配置 bindgen,并生成 Bindings 结构 let bindings = bindgen::Builder::default() .header("wrapper.h") .parse_callbacks(Box::new(bindgen::CargoCallbacks)) .generate() .expect("Unable to generate bindings"); // 生成 Rust 代码 bindings .write_to_file("src/bindings.rs") .expect("Failed to write bindings"); }
在 build.rs 里,引入了一个 wrapper.h,我们在根目录创建它,并引用 bzlib.h:
#include <bzlib.h>
此时运行 cargo build,会在 src 目录下生成 src/bindings.rs,里面大概有两千行代码,是 bindgen 根据 bzlib.h 中暴露的常量定义、数据结构和函数等生成的 Rust 代码。感兴趣的话,你可以看看。
有了生成好的代码,我们在 src/lib.rs 中引用它:
#![allow(unused)] fn main() { // 生成的 bindings 代码根据 C/C++ 代码生成,里面有一些不符合 Rust 约定,我们不让编译期报警 #![allow(non_upper_case_globals)] #![allow(non_camel_case_types)] #![allow(non_snake_case)] #![allow(deref_nullptr)] use anyhow::{anyhow, Result}; use std::mem; mod bindings; pub use bindings::*; }
接下来就可以撰写两个高阶的接口 compress / decompress,正常情况下应该创建另一个 crate 来撰写这样的接口,之前讲这是 Rust 处理 FFI 的惯例,有助于把高阶接口和低阶接口分离。在这里,我们就直接写在 src/lib.rs 中:
#![allow(unused)] fn main() { // 高层的 API,处理压缩,一般应该出现在另一个 crate pub fn compress(input: &[u8]) -> Result<Vec<u8>> { let output = vec![0u8; input.len()]; unsafe { let mut stream: bz_stream = mem::zeroed(); let result = BZ2_bzCompressInit(&mut stream as *mut _, 1, 0, 0); if result != BZ_OK as _ { return Err(anyhow!("Failed to initialize")); } // 传入 input / output 进行压缩 stream.next_in = input.as_ptr() as *mut _; stream.avail_in = input.len() as _; stream.next_out = output.as_ptr() as *mut _; stream.avail_out = output.len() as _; let result = BZ2_bzCompress(&mut stream as *mut _, BZ_FINISH as _); if result != BZ_STREAM_END as _ { return Err(anyhow!("Failed to compress")); } // 结束压缩 let result = BZ2_bzCompressEnd(&mut stream as *mut _); if result != BZ_OK as _ { return Err(anyhow!("Failed to end compression")); } } Ok(output) } // 高层的 API,处理解压缩,一般应该出现在另一个 crate pub fn decompress(input: &[u8]) -> Result<Vec<u8>> { let output = vec![0u8; input.len()]; unsafe { let mut stream: bz_stream = mem::zeroed(); let result = BZ2_bzDecompressInit(&mut stream as *mut _, 0, 0); if result != BZ_OK as _ { return Err(anyhow!("Failed to initialize")); } // 传入 input / output 进行解压缩 stream.next_in = input.as_ptr() as *mut _; stream.avail_in = input.len() as _; stream.next_out = output.as_ptr() as *mut _; stream.avail_out = output.len() as _; let result = BZ2_bzDecompress(&mut stream as *mut _); if result != BZ_STREAM_END as _ { return Err(anyhow!("Failed to compress")); } // 结束解压缩 let result = BZ2_bzDecompressEnd(&mut stream as *mut _); if result != BZ_OK as _ { return Err(anyhow!("Failed to end compression")); } } Ok(output) } }
最后,不要忘记了我们的好习惯,写个测试确保工作正常:
#![allow(unused)] fn main() { #[cfg(test)] mod tests { use super::*; #[test] fn compression_decompression_should_work() { let input = include_str!("bindings.rs").as_bytes(); let compressed = compress(input).unwrap(); let decompressed = decompress(&compressed).unwrap(); assert_eq!(input, &decompressed); } } }
运行 cargo test,测试能够正常通过。你可以看到,生成的 bindings.rs 里也有不少测试,cargo test 总共执行了 16 个测试。
怎么样,我们总共写了大概 100 行代码,就用 Rust 集成了 bz2 这个 C 库。是不是非常方便?如果你曾经处理过其他语言类似的 C 绑定,对比之下,就会发现用 Rust 做 FFI 开发真是太方便,太贴心了。
如果你觉得这个例子过于简单,不够过瘾,可以看看 Rust RocksDB 的实现,它非常适合你进一步了解复杂的、需要额外集成 C 源码的库如何集成到 Rust 中。
处理 FFI 的注意事项
bindgen 这样的工具,帮我们干了很多脏活累活,虽然大部分时候我们不太需要关心生成的 FFI 代码,但在使用它们构建更高层的 API 时,还是要注意三个关键问题。
- 如何处理数据结构的差异?
比如 C string 是 NULL 结尾,而 Rust String 是完全不同的结构。我们要清楚数据结构在内存中组织的差异,才能妥善地处理它们。Rust 提供了 std::ffi 来处理这样的问题,比如 CStr 和 CString 来处理字符串。
- 谁来释放内存?
没有特殊的情况,谁分配的内存,谁要负责释放。Rust 的内存分配器和其它语言的可能不一样,所以,Rust 分配的内存在 C 的上下文中释放,可能会导致未定义的行为。
- 如何进行错误处理?
在上面的代码里我们也看到了,C 通过返回的 error code 来报告执行过程中的错误,我们使用了 anyhow! 宏来随手生成了错误,这是不好的示例。在正式的代码中,应该使用 thiserror 或者类似的机制来定义所有 error code 对应的错误情况,然后相应地生成错误。
Rust 调用其它语言
目前说了半天,都是在说 Rust 如何调用 C/C++。那么,Rust,调用其他语言呢?
前面也提到,因为 C ABI 深入人心,两门语言之间的接口往往采用 C ABI。从这个角度说,如果我们需要 Rust 调用 Golang 的代码(先不管这合不合理),那么, 首先把 Golang 的代码使用 cgo 编译成兼容 C 的库;然后,Rust 就可以像调用 C/C++ 那样,使用 bindgen 来生成对应的 API 了。
至于 Rust 调用其它语言,也是类似,只不过像 JavaScript / Python 这样的,与其把它们的代码想办法编译成 C 库,不如把他们的解释器编译成 C 库或者 WASM,然后在 Rust 里调用其解释器使用相关的代码,来的方便和痛快。毕竟,JavaScript / Python 是脚本语言。
把 Rust 代码编译成 C 库
讲完了 Rust 如何使用其它语言,我们再来看看如何把 Rust 代码编译成符合 C ABI 的库,这样其它语言就可以像使用 C 那样使用 Rust 了。
这里的处理逻辑和上面的 Rust 调用 C 是类似的,只不过角色对调了一下:
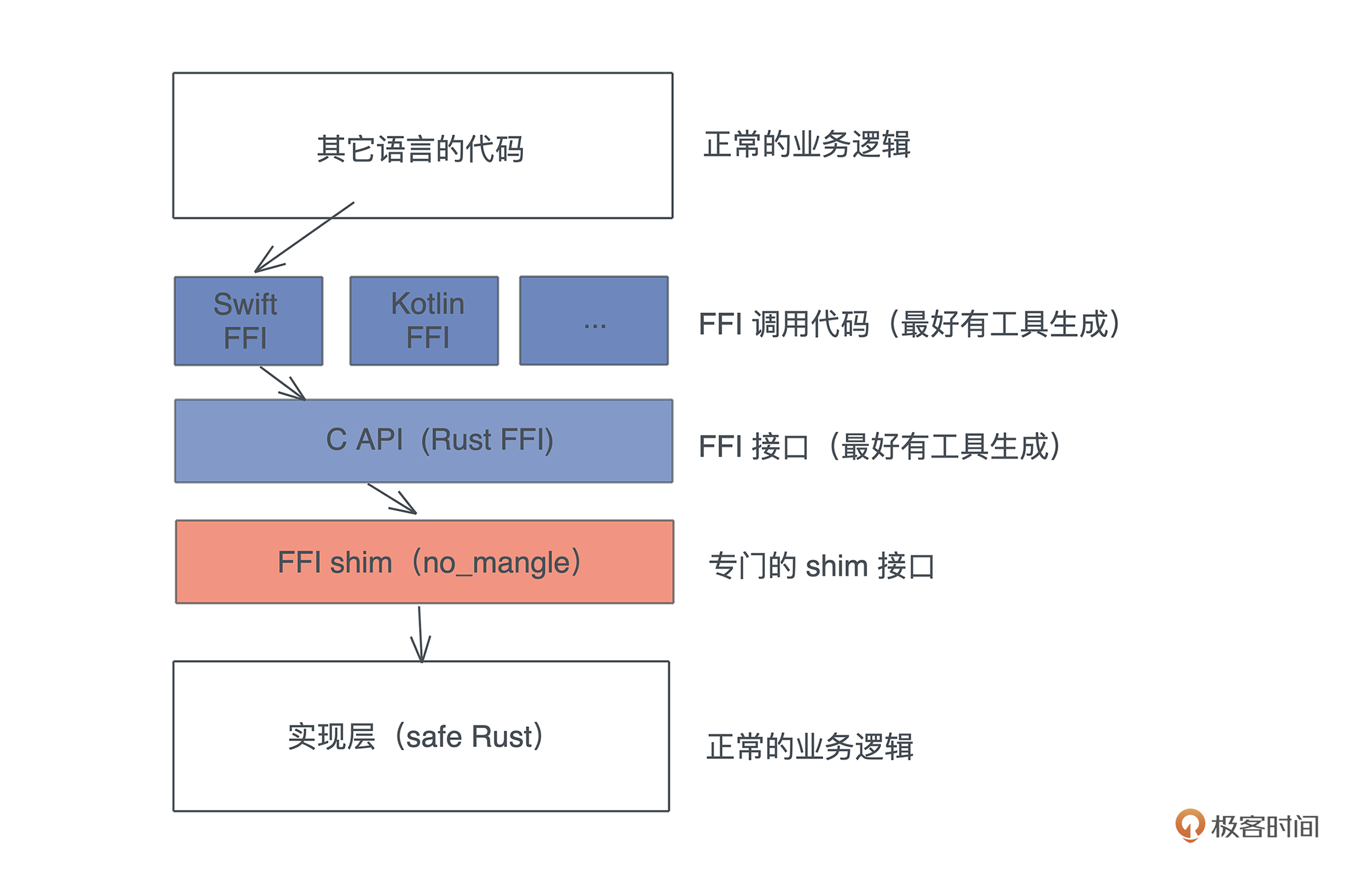
要把 Rust 代码和数据结构提供给 C 使用,我们首先要构造相应的 Rust shim 层,把原有的、正常的 Rust 实现封装一下,便于 C 调用。
Rust shim 主要做四件事情:
- 提供 Rust 方法、trait 方法等公开接口的独立函数。注意 C 是不支持泛型的,所以对于泛型函数,需要提供具体的用于某个类型的 shim 函数。
- 所有要暴露给 C 的独立函数,都要声明成 #[no_mangle],不做函数名称的改写。
如果不用 #[no_mangle],Rust 编译器会为函数生成很复杂的名字,我们很难在 C 中得到正确的改写后的名字。同时,这些函数的接口要使用 C 兼容的数据结构。
- 数据结构需要处理成和 C 兼容的结构。
如果是你自己定义的结构体,需要使用 #[repr©],对于要暴露给 C 的函数,不能使用 String / Vec / Result 这些 C 无法正确操作的数据结构。
- 要使用 catch_unwind 把所有可能产生 panic! 的代码包裹起来。
切记,其它语言调用 Rust 时,遇到 Rust 的 panic!(),会导致未定义的行为,所以在 FFI 的边界处,要 catch_unwind,阻止 Rust 栈回溯跑出 Rust 的世界。
来看个例子:
#![allow(unused)] fn main() { // 使用 no_mangle 禁止函数名改编,这样其它语言可以通过 C ABI 调用这个函数 #[no_mangle] pub extern "C" fn hello_world() -> *const c_char { // C String 以 "\\0" 结尾,你可以把 "\\0" 去掉看看会发生什么 "hello world!\\0".as_ptr() as *const c_char } }
这段代码使用了 #[no_mangle] ,在传回去字符串时使用 “\0” 结尾的字符串。由于这个字符串在 RODATA 段,是 'static 的生命周期,所以将其转换成裸指针返回,没有问题。如果要把这段代码编译为一个可用的 C 库,在 Cargo.toml 中,crate 类型要设置为 crate-type = [“cdylib”]。
刚才那个例子太简单,我们再来看一个进阶的例子。在这个例子里,C 语言那端会传过来一个字符串指针, format!() 一下后,返回一个字符串指针:
#![allow(unused)] fn main() { #[no_mangle] pub extern "C" fn hello_bad(name: *const c_char) -> *const c_char { let s = unsafe { CStr::from_ptr(name).to_str().unwrap() }; format!("hello {}!\\0", s).as_ptr() as *const c_char } }
你能发现这段代码的问题么?它犯了初学者几乎会犯的所有问题。
首先,传入的 name 会不会是一个 NULL 指针?是不是一个合法的地址?虽然是否是合法的地址我们无法检测,但起码我们可以检测 NULL。
其次,unwrap() 会造成 panic!(),如果把 CStr 转换成 &str 时出现错误,这个 panic!() 就会造成未定义的行为。我们可以做 catch_unwind(),但更好的方式是进行错误处理。
最后, format!("hello {}!\\0", s) 生成了一个字符串结构,as_ptr() 取到它堆上的起始位置,我们也保证了堆上的内存以 NULL 结尾,看上去没有问题。然而, 在这个函数结束执行时,由于字符串 s 退出作用域,所以它的堆内存会被连带 drop 掉。因此,这个函数返回的是一个悬空的指针,在 C 那侧调用时就会崩溃。
所以,正确的写法应该是:
#![allow(unused)] fn main() { #[no_mangle] pub extern "C" fn hello(name: *const c_char) -> *const c_char { if name.is_null() { return ptr::null(); } if let Ok(s) = unsafe { CStr::from_ptr(name).to_str() } { let result = format!("hello {}!", s); // 可以使用 unwrap,因为 result 不包含 \\0 let s = CString::new(result).unwrap(); s.into_raw() // 相当于: // let p = s.as_ptr(); // std::mem::forget(s); // p } else { ptr::null() } } }
在这段代码里,我们检查了 NULL 指针,进行了错误处理,还用 into_raw() 来让 Rust 侧放弃对内存的所有权。
注意前面的三个关键问题说过,谁分配的内存,谁来释放,所以,我们还需要提供另一个函数,供 C 语言侧使用,来释放 Rust 分配的字符串:
#![allow(unused)] fn main() { #[no_mangle] pub extern "C" fn free_str(s: *mut c_char) { if !s.is_null() { unsafe { CString::from_raw(s) }; } } }
C 代码必须要调用这个接口安全释放 Rust 创建的 CString。如果不调用,会有内存泄漏;如果使用 C 自己的 free(),会导致未定义的错误。
有人可能会好奇,CString::from_raw(s) 只是从裸指针中恢复出 CString,也没有释放啊?
你要习惯这样的“释放内存”的写法,因为它实际上借助了 Rust 的所有权规则:当所有者离开作用域时,拥有的内存会被释放。 这里我们创建一个有所有权的对象,就是为了函数结束时的自动释放。如果你看标准库或第三方库,经常有类似的“释放内存”的代码。
上面的 hello 代码,其实还不够安全。因为虽然看上去没有使用任何会导致直接或者间接 panic! 的代码,但难保代码复杂后,隐式地调用了 panic!()。比如,如果以后我们新加一些逻辑,使用了 copy_from_slice(),这个函数内部会调用 panic!(),就会导致问题。所以,最好的方法是把主要的逻辑封装在 catch_unwind 里:
#![allow(unused)] fn main() { #[no_mangle] pub extern "C" fn hello(name: *const c_char) -> *const c_char { if name.is_null() { return ptr::null(); } let result = catch_unwind(|| { if let Ok(s) = unsafe { CStr::from_ptr(name).to_str() } { let result = format!("hello {}!", s); // 可以使用 unwrap,因为 result 不包含 \\0 let s = CString::new(result).unwrap(); s.into_raw() } else { ptr::null() } }); match result { Ok(s) => s, Err(_) => ptr::null(), } } }
这几段代码你可以多多体会,完整例子放在 playground。
写好 Rust shim 代码后,接下来就是生成 C 的 FFI 接口了。一般来说,这个环节可以用工具来自动生成。我们可以使用 cbindgen。如果使用 cbindgen,上述的代码会生成类似这样的 bindings.h:
#include <cstdarg>
#include <cstdint>
#include <cstdlib>
#include <ostream>
#include <new>
extern "C" {
const char *hello_world();
const char *hello_bad(const char *name);
const char *hello(const char *name);
void free_str(char *s);
} // extern "C"
有了编译好的库代码以及头文件后,在其他语言中,就可以用该语言的工具进一步生成那门语言的 FFI 绑定,然后正常使用。
和其它语言的互操作
好,搞明白 Rust 代码如何编译成 C 库供 C/C++ 和其它语言使用,我们再看看具体语言有没有额外的工具更方便地和 Rust 互操作。
对于 Python 和 Node.js,我们之前已经见到了 PyO3 和 Neon 这两个库,用起来都非常简单直观,下一讲会再深入使用一下。
对于 Erlang/Elixir,可以使用非常不错的 rustler。如果你对此感兴趣,可以看这个 repo 中的演示文稿和例子。下面是一个把 Rust 代码安全地给 Erlang/Elixir 使用的简单例子:
#![allow(unused)] fn main() { #[rustler::nif] fn add(a: i64, b: i64) -> i64 { a + b } rustler::init!("Elixir.Math", [add]); }
对于 C++,虽然 cbindgen 就足够,但社区里还有 cxx,它可以帮助我们很方便地对 Rust 和 C++ 进行互操作。
如果你要做 Kotlin / Swift 开发,可以尝试一下 mozilla 用在生产环境下的 uniffi。使用 uniffi,你需要定义一个 UDL,这样 uniffi-bindgen 会帮你生成各种语言的 FFI 代码。
具体怎么用可以看这门课的 GitHub repo 下这一讲的 ffi-math crate 的完整代码。这里就讲一下重点,我写了个简单的 uniffi 接口(math.udl):
#![allow(unused)] fn main() { namespace math { u32 add(u32 a, u32 b); string hello([ByRef]string name); }; }
并提供了 Rust 实现:
#![allow(unused)] fn main() { uniffi_macros::include_scaffolding!("math"); pub fn add(a: u32, b: u32) -> u32 { a + b } pub fn hello(name: &str) -> String { format!("hello {}!", name) } }
之后就可以用:
uniffi-bindgen generate src/math.udl --language swift
uniffi-bindgen generate src/math.udl --language kotlin
生成对应的 Swift 和 Kotlin 代码。
我们看生成的 hello() 函数的代码。比如 Kotlin 代码:
fun hello(name: String): String {
val _retval =
rustCall() { status ->
_UniFFILib.INSTANCE.math_6c3d_hello(name.lower(), status)
}
return String.lift(_retval)
}
再比如 Swift 代码:
public func hello(name: String) -> String {
let _retval = try!
rustCall {
math_6c3d_hello(name.lower(), $0)
}
return try! String.lift(_retval)
}
你也许注意到了这个 RustCall,它是用来调用 Rust FFI 代码的,看源码:
private func rustCall<T>(_ callback: (UnsafeMutablePointer<RustCallStatus>) -> T) throws -> T {
try makeRustCall(callback, errorHandler: {
$0.deallocate()
return UniffiInternalError.unexpectedRustCallError
})
}
private func makeRustCall<T>(_ callback: (UnsafeMutablePointer<RustCallStatus>) -> T, errorHandler: (RustBuffer) throws -> Error) throws -> T {
var callStatus = RustCallStatus()
let returnedVal = callback(&callStatus)
switch callStatus.code {
case CALL_SUCCESS:
return returnedVal
case CALL_ERROR:
throw try errorHandler(callStatus.errorBuf)
case CALL_PANIC:
// When the rust code sees a panic, it tries to construct a RustBuffer
// with the message. But if that code panics, then it just sends back
// an empty buffer.
if callStatus.errorBuf.len > 0 {
throw UniffiInternalError.rustPanic(try String.lift(callStatus.errorBuf))
} else {
callStatus.errorBuf.deallocate()
throw UniffiInternalError.rustPanic("Rust panic")
}
default:
throw UniffiInternalError.unexpectedRustCallStatusCode
}
}
你可以看到,它还考虑了如果 Rust 代码 panic! 后的处理。那么 Rust 申请的内存会被 Rust 释放么?
会的。hello() 里的 String.lift() 就在做这个事情,我们看生成的代码:
extension String: ViaFfi {
fileprivate typealias FfiType = RustBuffer
fileprivate static func lift(_ v: FfiType) throws -> Self {
defer {
v.deallocate()
}
if v.data == nil {
return String()
}
let bytes = UnsafeBufferPointer<UInt8>(start: v.data!, count: Int(v.len))
return String(bytes: bytes, encoding: String.Encoding.utf8)!
}
...
}
private extension RustBuffer {
...
// Frees the buffer in place.
// The buffer must not be used after this is called.
func deallocate() {
try! rustCall { ffi_math_6c3d_rustbuffer_free(self, $0) }
}
}
在 lift 时,它会分配一个 swift String,然后在函数退出时调用 deallocate(),此时会发送一个 rustCall 给 ffi_math_rustbuffer_free()。
你看,uniffi 把前面说的处理 FFI 的三个关键问题: 处理数据结构的差异、释放内存、错误处理,都妥善地解决了。所以,如果你要在 Swift / Kotlin 代码中使用 Rust,非常建议你使用 uniffi。此外,uniffi 还支持 Python 和 Ruby。
FFI 的其它方式
最后,我们来简单聊一聊处理 FFI 的其它方式。其实代码的跨语言共享并非只有 FFI 一条路子。你也可以使用 REST API、gRPC 来达到代码跨语言使用的目的。不过,这样要额外走一圈网络,即便是本地网络,也效率太低,且不够安全。有没有更高效一些的方法?
有!我们可以在两个语言中使用 protobuf 来序列化/反序列化要传递的数据。在 Mozilla 的一篇博文 Crossing the Rust FFI frontier with Protocol Buffers,提到了这种方法:
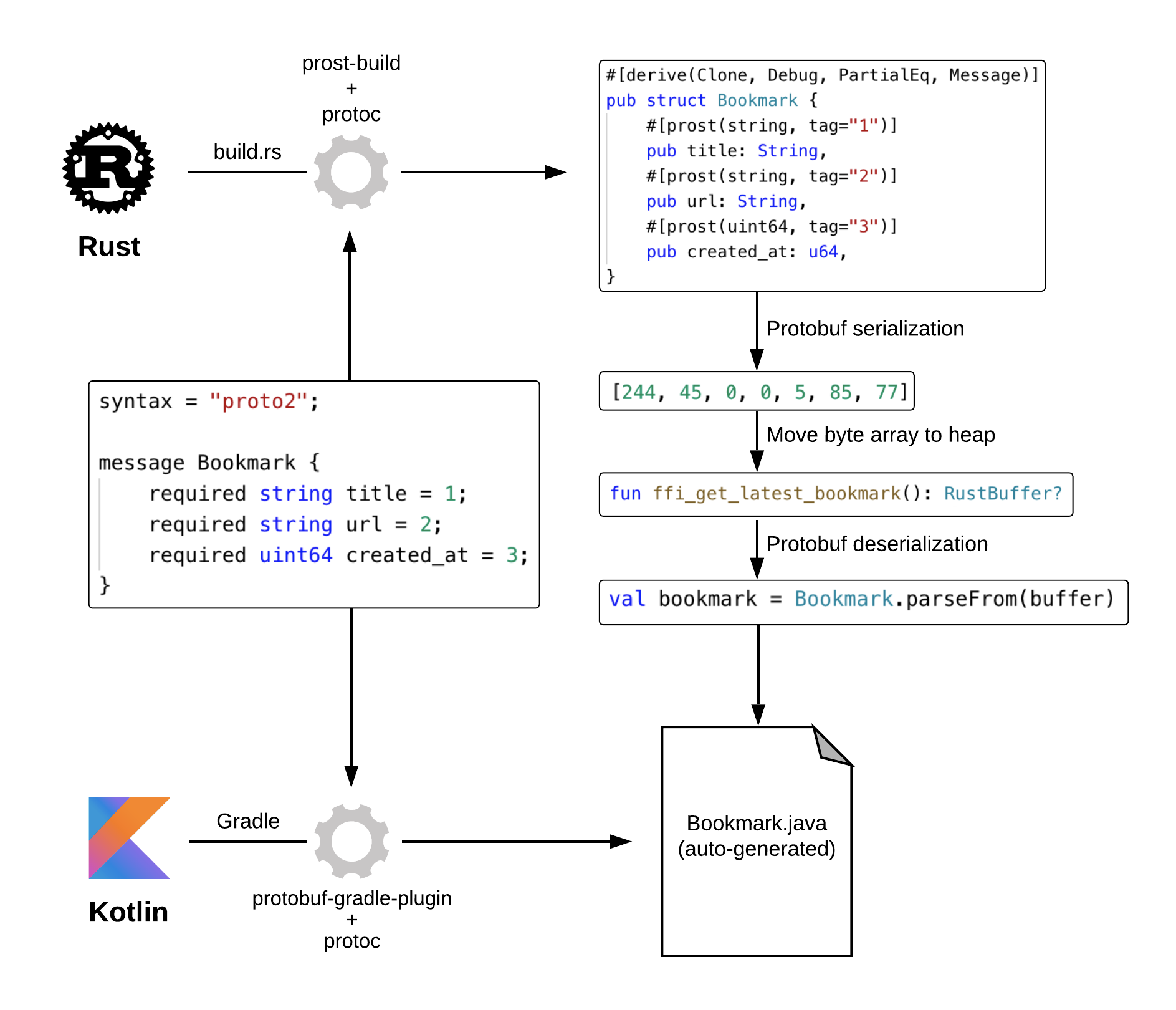
感兴趣的同学,可以读读这篇文章。也可以看看我之前写的文章 深度探索:前端中的后端,详细探讨了把 Rust 用在客户端项目中的可能性以及如何做 Rust bridge。
小结
FFI 是 Rust 又一个处于领先地位的领域。
从这一讲的示例中我们可以看到,在支持很方便地使用 C/C++ 社区里的成果外,Rust 也可以非常方便地在很多地方取代 C/C++,成为其它语言使用底层库的首选。 除了方便的 FFI 接口和工具链,使用 Rust 为其它语言提供底层支持,其实还有安全性这个杀手锏。
比如在 Erlang/Elixir 社区,高性能的底层 NIF 代码,如果用 C/C++ 撰写的话,一个不小心就可能导致整个 VM 的崩溃;但是用 Rust 撰写,因为其严格的内存安全保证(只要保证 unsafe 代码的正确性),NIF 不会导致 VM 的崩溃。
所以,现在 Rust 越来越受到各个高级语言的青睐,用来开发高性能的底层库。
与此同时,当需要开发跨越多个端的公共库时,使用 Rust 也会是一个很好的选择,我们在前面的内容中也看到了用 uniffi 为 Android 和 iOS 构建公共代码是多么简单的一件事。
思考题
- 阅读 std::ffi 的文档,想想 Vec
如何传递给 C?再想想 HashMap<K,V> 该如何传递?有必要传递一个 HashMap 到 C 那一侧么? - 阅读 rocksdb 的代码,看看 Rust 如何提供 rocksDB 的绑定。
- 如果你是个 iOS/Android 开发者,尝试使用 Rust 的 reqwest 构建 REST API 客户端,然后把得到的数据通过 FFI 传递给 Swift/Kotlin 侧。
感谢你的收听,今天完成了第31次Rust学习打卡啦。如果你觉得有收获,也欢迎你分享给身边的朋友,邀他一起讨论。我们下节课见~
实操项目:使用PyO3开发Python3模块
你好,我是陈天。
上一讲介绍了 FFI 的基本用法,今天我们就趁热打铁来做个实操项目,体验一下如何把 Rust 生态中优秀的库介绍到 Python/Node.js 的社区。
由于社区里已经有 PyO3 和 Neon 这样的工具,我们并不需要处理 Rust 代码兼容 C ABI 的细节,这些工具就可以直接处理。所以,今天会主要撰写 FFI shim 这一层的代码:
另外,PyO3和Neon的基本操作都是一样的,你会用一个,另一个的使用也就很容易理解了。这一讲我们就以 PyO3 为例。
那么,做个什么库提供给 Python 呢?
思来想去,我觉得 Python 社区里可以内嵌在程序中的搜索引擎,目前还是一块短板。我所知道的 whoosh 已经好多年没有更新了, pylucene 需要在 Python 里运行个 JVM,总是让人有种说不出的不舒服。虽然 Node.js 的 flexsearch 看上去还不错(我没有用过),但整体来说,这两个社区都需要有更强大的搜索引擎。
Rust 下,嵌入式的搜索引擎有 tantivy,我们就使用它来提供搜索引擎的功能。
不过,tanvity 的接口比较复杂,今天的主题也不是学习如何使用一个搜索引擎的接口,所以我做了基于 tanvity 的 crate xunmi,提供一套非常简单的接口, 今天,我们的目标就是:为这些接口提供对应的 Python 接口,并且让使用起来的感觉和 Python 一致。
下面是 xunmi 用 Rust 调用的例子:
use std::{str::FromStr, thread, time::Duration}; use xunmi::*; fn main() { // 可以通过 yaml 格式的配置文件加载定义好的 schema let config = IndexConfig::from_str(include_str!("../fixtures/config.yml")).unwrap(); // 打开或者创建 index let indexer = Indexer::open_or_create(config).unwrap(); // 要 index 的数据,可以是 xml / yaml / json let content = include_str!("../fixtures/wiki_00.xml"); // 我们使用的 wikipedia dump 是 xml 格式的,所以 InputType::Xml // 这里,wikipedia 的数据结构 id 是字符串,但 index 的 schema 里是 u64 // wikipedia 里没有 content 字段,节点的内容($value)相当于 content // 所以我们需要对数据定义一些格式转换 let config = InputConfig::new( InputType::Xml, vec![("$value".into(), "content".into())], vec![("id".into(), (ValueType::String, ValueType::Number))], ); // 获得 index 的 updater,用于更新 index let mut updater = indexer.get_updater(); // 你可以使用多个 updater 在不同上下文更新同一个 index let mut updater1 = indexer.get_updater(); // 可以通过 add / update 来更新 index,add 直接添加,update 会删除已有的 doc // 然后添加新的 updater.update(content, &config).unwrap(); // 你可以添加多组数据,最后统一 commit updater.commit().unwrap(); // 在其他上下文下更新 index thread::spawn(move || { let config = InputConfig::new(InputType::Yaml, vec![], vec![]); let text = include_str!("../fixtures/test.yml"); updater1.update(text, &config).unwrap(); updater1.commit().unwrap(); }); // indexer 默认会自动在每次 commit 后重新加载,但这会有上百毫秒的延迟 // 在这个例子里我们会等一段时间再查询 while indexer.num_docs() == 0 { thread::sleep(Duration::from_millis(100)); } println!("total: {}", indexer.num_docs()); // 你可以提供查询来获取搜索结果 let result = indexer.search("历史", &["title", "content"], 5, 0).unwrap(); for (score, doc) in result.iter() { // 因为 schema 里 content 只索引不存储,所以输出里没有 content println!("score: {}, doc: {:?}", score, doc); } }
以下是索引的配置文件的样子:
---
path: /tmp/searcher_index # 索引路径
schema: # 索引的 schema,对于文本,使用 CANG_JIE 做中文分词
- name: id
type: u64
options:
indexed: true
fast: single
stored: true
- name: url
type: text
options:
indexing: ~
stored: true
- name: title
type: text
options:
indexing:
record: position
tokenizer: CANG_JIE
stored: true
- name: content
type: text
options:
indexing:
record: position
tokenizer: CANG_JIE
stored: false # 对于 content,我们只索引,不存储
text_lang:
chinese: true # 如果是 true,自动做繁体到简体的转换
writer_memory: 100000000
目标是,使用 PyO3 让 Rust 代码可以这样在 Python 中使用:
好,废话不多说,我们开始今天的项目挑战。
首先 cargo new xunmi-py --lib 创建一个新的项目,在 Cargo.toml 中添入:
[package]
name = "xunmi-py"
version = "0.1.0"
edition = "2021"
[lib]
name = "xunmi"
crate-type = ["cdylib"]
[dependencies]
pyo3 = {version = "0.14", features = ["extension-module"]}
serde_json = "1"
xunmi = "0.2"
[build-dependencies]
pyo3-build-config = "0.14"
要定义好 lib 的名字和类型。lib 的名字,我们就定义成 xunmi,这样在 Python 中 import 时就用这个名称;crate-type 是 cdylib,我们需要 pyo3-build-config 这个 crate 来做编译时的一些简单处理( macOS 需要)。
准备工作
接下来在写代码之前,还要做一些准备工作,主要是 build 脚本和 Makefile,让我们能方便地生成 Python 库。
创建 build.rs,并添入:
fn main() { println!("cargo:rerun-if-changed=build.rs"); pyo3_build_config::add_extension_module_link_args(); }
它会在编译的时候添加一些编译选项。如果你不想用 build.rs 来额外处理,也可以创建 .cargo/config,然后添加:
#![allow(unused)] fn main() { [target.x86_64-apple-darwin] rustflags = [ "-C", "link-arg=-undefined", "-C", "link-arg=dynamic_lookup", ] }
二者的作用是等价的。
然后我们创建一个目录 xunmi,再创建 xunmi/_ init_.py,添入:
from .xunmi import *
最后创建一个 Makefile,添入:
# 如果你的 BUILD_DIR 不同,可以 make BUILD_DIR=<your-dir>
BUILD_DIR := target/release
SRCS := $(wildcard src/*.rs) Cargo.toml
NAME = xunmi
TARGET = lib$(NAME)
BUILD_FILE = $(BUILD_DIR)/$(TARGET).dylib
BUILD_FILE1 = $(BUILD_DIR)/$(TARGET).so
TARGET_FILE = $(NAME)/$(NAME).so
all: $(TARGET_FILE)
test: $(TARGET_FILE)
python3 -m pytest
$(TARGET_FILE): $(BUILD_FILE1)
@cp $(BUILD_FILE1) $(TARGET_FILE)
$(BUILD_FILE1): $(SRCS)
@cargo build --release
@mv $(BUILD_FILE) $(BUILD_FILE1)|| true
PHONY: test all
这个 Makefile 可以帮我们自动化一些工作,基本上,就是把编译出来的 .dylib 或者 .so 拷贝到 xunmi 目录下,被 python 使用。
撰写代码
接下来就是如何撰写 FFI shim 代码了。PyO3 为我们提供了一系列宏,可以很方便地把 Rust 的数据结构、函数、数据结构的方法,以及错误类型,映射成 Python 的类、函数、类的方法,以及异常。我们来一个个看。
将 Rust struct 注册为 Python class
之前在 第 6 讲,我们简单介绍了函数是如何被引入到 pymodule 中的:
#![allow(unused)] fn main() { use pyo3::{exceptions, prelude::*}; #[pyfunction] pub fn example_sql() -> PyResult<String> { Ok(queryer::example_sql()) } #[pyfunction] pub fn query(sql: &str, output: Option<&str>) -> PyResult<String> { let rt = tokio::runtime::Runtime::new().unwrap(); let data = rt.block_on(async { queryer::query(sql).await.unwrap() }); match output { Some("csv") | None => Ok(data.to_csv().unwrap()), Some(v) => Err(exceptions::PyTypeError::new_err(format!( "Output type {} not supported", v ))), } } #[pymodule] fn queryer_py(_py: Python, m: &PyModule) -> PyResult<()> { m.add_function(wrap_pyfunction!(query, m)?)?; m.add_function(wrap_pyfunction!(example_sql, m)?)?; Ok(()) } }
使用了 #[pymodule] 宏,来提供 python module 入口函数,它负责注册这个 module 下的类和函数。通过 m.add_function 可以注册函数,之后,在 Python 里就可以这么调用:
import queryer_py
queryer_py.query("select * from file:///test.csv")
但当时我们想暴露出来的接口功能很简单,让用户传入一个 SQL 字符串和输出类型的字符串,返回一个按照 SQL 查询处理过的、符合输出类型的字符串。所以为 Python 模块提供了两个接口 example_sql 和 query。
不过,我们今天要做的事情远比第 6 讲中对 PyO3 的使用复杂。比如说要在两门语言中传递数据结构,让 Python 类可以使用 Rust 方法等,所以需要注册一些类以及对应的类方法。
看上文使用截图中的一些代码(复制到这里了):
from xunmi import *
indexer = Indexer("./fixtures/config.yml")
updater = indexer.get_updater()
f = open("./fixtures/wiki_00.xml")
data = f.read()
f.close()
input_config = InputConfig("xml", [("$value", "content")], [("id", ("string", "number"))])
updater.update(data, input_config)
updater.commit()
result = indexer.search("历史", ["title", "content"], 5, 0)
你会发现, 我们需要注册 Indexer、IndexUpdater 和 InputConfig 这三个类,它们都有自己的成员函数,其中,Indexer 和 InputConfig 还要有类的构造函数。
但是因为 xunmi 是 xunmi-py 外部引入的一个 crate,我们无法直接动 xunmi 的数据结构,把这几个类注册进去。怎么办?我们需要封装一下:
#![allow(unused)] fn main() { use pyo3::{exceptions, prelude::*}; use xunmi::{self as x}; #[pyclass] pub struct Indexer(x::Indexer); #[pyclass] pub struct InputConfig(x::InputConfig); #[pyclass] pub struct IndexUpdater(x::IndexUpdater); }
这里有个小技巧,可以把 xunmi 的命名空间临时改成 x,这样,xunmi 自己的结构用 x:: 来引用,就不会有命名的冲突了。
有了这三个定义,我们就可以通过 m.add_class 把它们引入到模块中:
#![allow(unused)] fn main() { #[pymodule] fn xunmi(_py: Python, m: &PyModule) -> PyResult<()> { m.add_class::<Indexer>()?; m.add_class::<InputConfig>()?; m.add_class::<IndexUpdater>()?; Ok(()) } }
注意, 这里的函数名要和 crate lib name 一致,如果你没有定义 lib name,默认会使用 crate name。我们为了区别,crate name 使用了 “xunmi-py”,所以前面在 Cargo.toml 里,会单独声明一下 lib name:
[lib]
name = "xunmi"
crate-type = ["cdylib"]
把 struct 的方法暴露成 class 的方法
注册好Python的类,继续写功能的实现,基本上是 shim 代码,也就是把 xunmi 里对应的数据结构的方法暴露给 Python。先看个简单的,IndexUpdater 的实现:
#![allow(unused)] fn main() { #[pymethods] impl IndexUpdater { pub fn add(&mut self, input: &str, config: &InputConfig) -> PyResult<()> { Ok(self.0.add(input, &config.0).map_err(to_pyerr)?) } pub fn update(&mut self, input: &str, config: &InputConfig) -> PyResult<()> { Ok(self.0.update(input, &config.0).map_err(to_pyerr)?) } pub fn commit(&mut self) -> PyResult<()> { Ok(self.0.commit().map_err(to_pyerr)?) } pub fn clear(&self) -> PyResult<()> { Ok(self.0.clear().map_err(to_pyerr)?) } } }
首先,需要用 #[pymethods] 来包裹 impl IndexUpdater {},这样,里面所有的 pub 方法都可以在 Python 侧使用。我们暴露了 add / update / commit / clear 这几个方法。方法的类型签名正常撰写即可,Rust 的基本类型都能通过 PyO3 对应到 Python,使用到的 InputConfig 之前也注册成 Python class 了。
所以,通过这些方法,一个 Python 用户就可以轻松地在 Python 侧生成字符串,生成 InputConfig 类,然后传给 update() 函数,交给 Rust 侧处理。比如这样:
f = open("./fixtures/wiki_00.xml")
data = f.read()
f.close()
input_config = InputConfig("xml", [("$value", "content")], [("id", ("string", "number"))])
updater.update(data, input_config)
错误处理
还记得上一讲强调的三个要点吗,在写FFI的时候要注意Rust的错误处理。这里,所有函数如果要返回 Result<T, E>,需要使用 PyResult
我们可以用 map_err 处理,其中 to_pyerr 实现如下:
#![allow(unused)] fn main() { pub(crate) fn to_pyerr<E: ToString>(err: E) -> PyErr { exceptions::PyValueError::new_err(err.to_string()) } }
通过使用 PyO3 提供的 PyValueError,在 Rust 侧生成的 err,会被 PyO3 转化成 Python 侧的异常。比如我们在创建 indexer 时提供一个不存在的 config:
In [3]: indexer = Indexer("./fixtures/config.ymla")
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-3-bde6b0e501ea> in <module>
----> 1 indexer = Indexer("./fixtures/config.ymla")
ValueError: No such file or directory (os error 2)
即使你在 Rust 侧使用了 panic!,PyO3 也有很好的处理:
In [3]: indexer = Indexer("./fixtures/config.ymla")
---------------------------------------------------------------------------
PanicException Traceback (most recent call last)
<ipython-input-11-082d933e67e2> in <module>
----> 1 indexer = Indexer("./fixtures/config.ymla")
2 updater = indexer.get_updater()
PanicException: called `Result::unwrap()` on an `Err` value: Os { code: 2, kind: NotFound, message: "No such file or directory" }
它也是在 Python 侧抛出一个异常。
构造函数
好,接着看 Indexer 怎么实现:
#![allow(unused)] fn main() { #[pymethods] impl Indexer { // 创建或载入 index #[new] pub fn open_or_create(filename: &str) -> PyResult<Indexer> { let content = fs::read_to_string(filename).unwrap(); let config = x::IndexConfig::from_str(&content).map_err(to_pyerr)?; let indexer = x::Indexer::open_or_create(config).map_err(to_pyerr)?; Ok(Indexer(indexer)) } // 获取 updater pub fn get_updater(&self) -> IndexUpdater { IndexUpdater(self.0.get_updater()) } // 搜索 pub fn search( &self, query: String, fields: Vec<String>, limit: usize, offset: Option<usize>, ) -> PyResult<Vec<(f32, String)>> { let default_fields: Vec<_> = fields.iter().map(|s| s.as_str()).collect(); let data: Vec<_> = self .0 .search(&query, &default_fields, limit, offset.unwrap_or(0)) .map_err(to_pyerr)? .into_iter() .map(|(score, doc)| (score, serde_json::to_string(&doc).unwrap())) .collect(); Ok(data) } // 重新加载 index pub fn reload(&self) -> PyResult<()> { self.0.reload().map_err(to_pyerr) } } }
你看,我们可以用 #[new] 来标记要成为构造函数的方法,所以,在 Python 侧,当你调用:
indexer = Indexer("./fixtures/config.yml")
其实,它在 Rust 侧就调用了 open_or_crate 方法。把某个用来构建数据结构的方法,标记为一个构造函数,可以让 Python 用户感觉用起来更加自然。
缺省参数
好,最后来看看缺省参数的实现。Python 支持缺省参数,但 Rust 不支持缺省参数,怎么破?
别着急,PyO3 巧妙使用了 Option
#![allow(unused)] fn main() { #[pymethods] impl InputConfig { #[new] fn new( input_type: String, mapping: Option<Vec<(String, String)>>, conversion: Option<Vec<(String, (String, String))>>, ) -> PyResult<Self> { let input_type = match input_type.as_ref() { "yaml" | "yml" => x::InputType::Yaml, "json" => x::InputType::Json, "xml" => x::InputType::Xml, _ => return Err(exceptions::PyValueError::new_err("Invalid input type")), }; let conversion = conversion .unwrap_or_default() .into_iter() .filter_map(|(k, (t1, t2))| { let t = match (t1.as_ref(), t2.as_ref()) { ("string", "number") => (x::ValueType::String, x::ValueType::Number), ("number", "string") => (x::ValueType::Number, x::ValueType::String), _ => return None, }; Some((k, t)) }) .collect::<Vec<_>>(); Ok(Self(x::InputConfig::new( input_type, mapping.unwrap_or_default(), conversion, ))) } } }
这段代码是典型的 shim 代码,它就是把接口包装成更简单的形式提供给 Python,然后内部做转换适配原本的接口。
在 Python 侧,当 mapping 或 conversion 不需要时,可以不提供。这里我们使用 unwrap_or_default() 来得到缺省值(对 Vecvec![])。这样,在 Python 侧这么调用都是合法的:
input_config = InputConfig("xml", [("$value", "content")], [("id", ("string", "number"))])
input_config = InputConfig("xml", [("$value", "content")])
input_config = InputConfig("xml")
完整代码
好了,到这里今天的主要目标就基本完成啦。 xunmi-py 里 src/lib.rs 的完整代码也展示一下供你对比参考:
#![allow(unused)] fn main() { use pyo3::{ exceptions, prelude::*, types::{PyDict, PyTuple}, }; use std::{fs, str::FromStr}; use xunmi::{self as x}; pub(crate) fn to_pyerr<E: ToString>(err: E) -> PyErr { exceptions::PyValueError::new_err(err.to_string()) } #[pyclass] pub struct Indexer(x::Indexer); #[pyclass] pub struct InputConfig(x::InputConfig); #[pyclass] pub struct IndexUpdater(x::IndexUpdater); #[pymethods] impl Indexer { #[new] pub fn open_or_create(filename: &str) -> PyResult<Indexer> { let content = fs::read_to_string(filename).map_err(to_pyerr)?; let config = x::IndexConfig::from_str(&content).map_err(to_pyerr)?; let indexer = x::Indexer::open_or_create(config).map_err(to_pyerr)?; Ok(Indexer(indexer)) } pub fn get_updater(&self) -> IndexUpdater { IndexUpdater(self.0.get_updater()) } pub fn search( &self, query: String, fields: Vec<String>, limit: usize, offset: Option<usize>, ) -> PyResult<Vec<(f32, String)>> { let default_fields: Vec<_> = fields.iter().map(|s| s.as_str()).collect(); let data: Vec<_> = self .0 .search(&query, &default_fields, limit, offset.unwrap_or(0)) .map_err(to_pyerr)? .into_iter() .map(|(score, doc)| (score, serde_json::to_string(&doc).unwrap())) .collect(); Ok(data) } pub fn reload(&self) -> PyResult<()> { self.0.reload().map_err(to_pyerr) } } #[pymethods] impl IndexUpdater { pub fn add(&mut self, input: &str, config: &InputConfig) -> PyResult<()> { self.0.add(input, &config.0).map_err(to_pyerr) } pub fn update(&mut self, input: &str, config: &InputConfig) -> PyResult<()> { self.0.update(input, &config.0).map_err(to_pyerr) } pub fn commit(&mut self) -> PyResult<()> { self.0.commit().map_err(to_pyerr) } pub fn clear(&self) -> PyResult<()> { self.0.clear().map_err(to_pyerr) } } #[pymethods] impl InputConfig { #[new] fn new( input_type: String, mapping: Option<Vec<(String, String)>>, conversion: Option<Vec<(String, (String, String))>>, ) -> PyResult<Self> { let input_type = match input_type.as_ref() { "yaml" | "yml" => x::InputType::Yaml, "json" => x::InputType::Json, "xml" => x::InputType::Xml, _ => return Err(exceptions::PyValueError::new_err("Invalid input type")), }; let conversion = conversion .unwrap_or_default() .into_iter() .filter_map(|(k, (t1, t2))| { let t = match (t1.as_ref(), t2.as_ref()) { ("string", "number") => (x::ValueType::String, x::ValueType::Number), ("number", "string") => (x::ValueType::Number, x::ValueType::String), _ => return None, }; Some((k, t)) }) .collect::<Vec<_>>(); Ok(Self(x::InputConfig::new( input_type, mapping.unwrap_or_default(), conversion, ))) } } #[pymodule] fn xunmi(_py: Python, m: &PyModule) -> PyResult<()> { m.add_class::<Indexer>()?; m.add_class::<InputConfig>()?; m.add_class::<IndexUpdater>()?; Ok(()) } }
整体的代码除了使用了一些 PyO3 提供的宏,没有什么特别之处,就是把 xunmi crate 的接口包装了一下(Indexer / InputConfig / IndexUpdater),然后把它们呈现在 pymodule 中。
你可以去这门课的 GitHub repo 里,下载可以用于测试的 fixtures,以及 Jupyter Notebook(index_wiki.ipynb)。
如果要测试 Python 代码,请运行 make,这样会编译出一个 release 版本的 .so 放在 xunmi 目录下,之后你就可以在 ipython 或者 jupyter-lab 里 from xunmi import * 来使用了。当然,你也可以使用第 6 讲介绍的 maturin 来测试和发布。
One more thing
作为一个 Python 老手,你可能会问,如果在 Python 侧,我要传入 *args(变长参数) 或者 **kwargs(变长字典)怎么办?这可是 Python 的精髓啊!别担心,pyo3 提供了对应的 PyTuple / PyDict 类型,以及相应的宏。
我们可以这么写:
#![allow(unused)] fn main() { use pyo3::types::{PyDict, PyTuple}; #[pyclass] struct MyClass {} #[pymethods] impl MyClass { #[staticmethod] #[args(kwargs = "**")] fn test1(kwargs: Option<&PyDict>) -> PyResult<()> { if let Some(kwargs) = kwargs { for kwarg in kwargs { println!("{:?}", kwarg); } } else { println!("kwargs is none"); } Ok(()) } #[staticmethod] #[args(args = "*")] fn test2(args: &PyTuple) -> PyResult<()> { for arg in args { println!("{:?}", arg); } Ok(()) } } }
感兴趣的同学可以尝试一下(记得要 m.add_class 注册一下)。下面是运行结果:
In [6]: MyClass.test1()
kwargs is none
In [7]: MyClass.test1(a=1, b=2)
('a', 1)
('b', 2)
In [8]: MyClass.test2(1,2,3)
1
2
3
小结
PyO3 是一个非常成熟的让 Python 和 Rust 互操作的库。很多 Rust 的库都是通过 PyO3 被介绍到 Python 社区的。所以如果你是一名 Python 开发者,喜欢在 Jupyter Notebook 上开发,不妨把一些需要高性能的库用 Rust 实现。其实 tantivy 也有自己的 tantivy-py,你也可以看看它的实现源码。
当然啦,这一讲我们对 PyO3 的使用也仅仅是冰山一角。PyO3 还允许你在 Rust 下调用 Python 代码。
比如你可以提供一个库给 Python,让 Python 调用这个库的能力。在需要的时候,这个库还可以接受一个来自 Python 的闭包函数,让 Python 用户享受到 Rust 库的高性能之外,还可以拥有足够的灵活性。我们之前使用过的 polars 就有不少这样 Rust 和 Python 的深度交互。感兴趣的同学可以看看它的代码。
思考题
今天我们实现了 xunmi-py,按照类似的思路,你可以试着边看 neon 的文档,边实现一个 xunmi-js,让它也可以被用在 Node.js 社区。
欢迎在留言区分享讨论。感谢你的收听,今天你完成了第32次Rust打卡啦,继续坚持。我们下节课见~
并发处理(上):从atomics到Channel,Rust都提供了什么工具?
你好,我是陈天。
不知不觉我们已经并肩作战三十多讲了,希望你通过这段时间的学习,有一种“我成为更好的程序员啦!”这样的感觉。这是我想通过介绍 Rust 的思想、处理问题的思路、设计接口的理念等等传递给你的。如今,我们终于来到了备受期待的并发和异步的篇章。
很多人分不清并发和并行的概念,Rob Pike,Golang 的创始人之一,对此有很精辟很直观的解释:
Concurrency is about dealing with lots of things at once. Parallelism is about doing lots of things at once.
并发是一种同时处理很多事情的能力,并行是一种同时执行很多事情的手段。
我们把要做的事情放在多个线程中,或者多个异步任务中处理,这是并发的能力。在多核多 CPU 的机器上同时运行这些线程或者异步任务,是并行的手段。可以说,并发是为并行赋能。当我们具备了并发的能力,并行就是水到渠成的事情。
其实之前已经涉及了很多和并发相关的内容。比如用 std::thread 来创建线程、用 std::sync 下的并发原语(Mutex)来处理并发过程中的同步问题、用 Send/Sync trait 来保证并发的安全等等。
在处理并发的过程中, 难点并不在于如何创建多个线程来分配工作,在于如何在这些并发的任务中进行同步。我们来看并发状态下几种常见的工作模式:自由竞争模式、map/reduce 模式、DAG 模式:
在自由竞争模式下,多个并发任务会竞争同一个临界区的访问权。任务之间在何时、以何种方式去访问临界区,是不确定的,或者说是最为灵活的,只要在进入临界区时获得独占访问即可。
在自由竞争的基础上,我们可以限制并发的同步模式,典型的有 map/reduce 模式和 DAG 模式。map/reduce 模式,把工作打散,按照相同的处理完成后,再按照一定的顺序将结果组织起来;DAG 模式,把工作切成不相交的、有依赖关系的子任务,然后按依赖关系并发执行。
这三种基本模式组合起来,可以处理非常复杂的并发场景。所以,当我们处理复杂问题的时候,应该 先厘清其脉络,用分治的思想把问题拆解成正交的子问题,然后组合合适的并发模式来处理这些子问题。
在这些并发模式背后,都有哪些并发原语可以为我们所用呢,这两讲会重点讲解和深入五个概念Atomic、Mutex、Condvar、Channel 和 Actor model。今天先讲前两个Atomic和Mutex。
Atomic
Atomic 是所有并发原语的基础,它为并发任务的同步奠定了坚实的基础。
谈到同步,相信你首先会想到锁,所以在具体介绍 atomic 之前,我们从最基本的锁该如何实现讲起。自由竞争模式下,我们需要用互斥锁来保护某个临界区,使进入临界区的任务拥有独占访问的权限。
为了简便起见,在获取这把锁的时候,如果获取不到,就一直死循环,直到拿到锁为止( 代码):
use std::{cell::RefCell, fmt, sync::Arc, thread}; struct Lock<T> { locked: RefCell<bool>, data: RefCell<T>, } impl<T> fmt::Debug for Lock<T> where T: fmt::Debug, { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "Lock<{:?}>", self.data.borrow()) } } // SAFETY: 我们确信 Lock<T> 很安全,可以在多个线程中共享 unsafe impl<T> Sync for Lock<T> {} impl<T> Lock<T> { pub fn new(data: T) -> Self { Self { data: RefCell::new(data), locked: RefCell::new(false), } } pub fn lock(&self, op: impl FnOnce(&mut T)) { // 如果没拿到锁,就一直 spin while *self.locked.borrow() != false {} // **1 // 拿到,赶紧加锁 *self.locked.borrow_mut() = true; // **2 // 开始干活 op(&mut self.data.borrow_mut()); // **3 // 解锁 *self.locked.borrow_mut() = false; // **4 } } fn main() { let data = Arc::new(Lock::new(0)); let data1 = data.clone(); let t1 = thread::spawn(move || { data1.lock(|v| *v += 10); }); let data2 = data.clone(); let t2 = thread::spawn(move || { data2.lock(|v| *v *= 10); }); t1.join().unwrap(); t2.join().unwrap(); println!("data: {:?}", data); }
这段代码模拟了 Mutex 的实现,它的核心部分是 lock() 方法。
我们之前说过,Mutex 在调用 lock() 后,会得到一个 MutexGuard 的 RAII 结构,这里为了简便起见,要求调用者传入一个闭包,来处理加锁后的事务。 在 lock() 方法里,拿不到锁的并发任务会一直 spin,拿到锁的任务可以干活,干完活后会解锁,这样之前 spin 的任务会竞争到锁,进入临界区。
这样的实现看上去似乎问题不大,但是你细想,它有好几个问题:
- 在多核情况下,
**1和**2之间,有可能其它线程也碰巧 spin 结束,把 locked 修改为 true。这样,存在多个线程拿到这把锁,破坏了任何线程都有独占访问的保证。 - 即便在单核情况下,
**1和**2之间,也可能因为操作系统的可抢占式调度,导致问题1发生。 - 如今的编译器会最大程度优化生成的指令,如果操作之间没有依赖关系,可能会生成乱序的机器码,比如
**3被优化放在**1之前,从而破坏了这个 lock 的保证。 - 即便编译器不做乱序处理,CPU 也会最大程度做指令的乱序执行,让流水线的效率最高。同样会发生 3 的问题。
所以,我们实现这个锁的行为是未定义的。可能大部分时间如我们所愿,但会随机出现奇奇怪怪的行为。一旦这样的事情发生,bug 可能会以各种不同的面貌出现在系统的各个角落。而且,这样的 bug 几乎是无解的,因为它很难稳定复现,表现行为很不一致,甚至,只在某个 CPU 下出现。
这里再强调一下 unsafe 代码需要足够严谨,需要非常有经验的工程师去审查,这段代码之所以破快了并发安全性,是因为我们错误地认为:为 Lock
为了解决上面这段代码的问题,我们必须在 CPU 层面做一些保证,让某些操作成为原子操作。
最基础的保证是: 可以通过一条指令读取某个内存地址,判断其值是否等于某个前置值,如果相等,将其修改为新的值。这就是 Compare-and-swap 操作,简称 CAS。它是操作系统的几乎所有并发原语的基石,使得我们能实现一个可以正常工作的锁。
所以,刚才的代码,我们可以把一开始的循环改成:
#![allow(unused)] fn main() { while self .locked .compare_exchange(false, true, Ordering::Acquire, Ordering::Relaxed) .is_err() {} }
这句的意思是:如果 locked 当前的值是 false,就将其改成 true。这整个操作在一条指令里完成,不会被其它线程打断或者修改;如果 locked 的当前值不是 false,那么就会返回错误,我们会在此不停 spin,直到前置条件得到满足。这里, compare_exchange 是 Rust 提供的 CAS 操作,它会被编译成 CPU 的对应 CAS 指令。
当这句执行成功后,locked 必然会被改变为 true,我们成功拿到了锁,而任何其他线程都会在这句话上 spin。
同样在释放锁的时候,相应地需要使用 atomic 的版本,而非直接赋值成 false:
#![allow(unused)] fn main() { self.locked.store(false, Ordering::Release); }
当然,为了配合这样的改动,我们还需要把 locked 从 bool 改成 AtomicBool。在 Rust里, std::sync::atomic 有大量的 atomic 数据结构,对应各种基础结构。我们看使用了 AtomicBool 的新实现( 代码):
use std::{ cell::RefCell, fmt, sync::{ atomic::{AtomicBool, Ordering}, Arc, }, thread, }; struct Lock<T> { locked: AtomicBool, data: RefCell<T>, } impl<T> fmt::Debug for Lock<T> where T: fmt::Debug, { fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { write!(f, "Lock<{:?}>", self.data.borrow()) } } // SAFETY: 我们确信 Lock<T> 很安全,可以在多个线程中共享 unsafe impl<T> Sync for Lock<T> {} impl<T> Lock<T> { pub fn new(data: T) -> Self { Self { data: RefCell::new(data), locked: AtomicBool::new(false), } } pub fn lock(&self, op: impl FnOnce(&mut T)) { // 如果没拿到锁,就一直 spin while self .locked .compare_exchange(false, true, Ordering::Acquire, Ordering::Relaxed) .is_err() {} // **1 // 已经拿到并加锁,开始干活 op(&mut self.data.borrow_mut()); // **3 // 解锁 self.locked.store(false, Ordering::Release); } } fn main() { let data = Arc::new(Lock::new(0)); let data1 = data.clone(); let t1 = thread::spawn(move || { data1.lock(|v| *v += 10); }); let data2 = data.clone(); let t2 = thread::spawn(move || { data2.lock(|v| *v *= 10); }); t1.join().unwrap(); t2.join().unwrap(); println!("data: {:?}", data); }
可以看到,通过使用 compare_exchange ,规避了 1 和 2 面临的问题,但对于和编译器/CPU自动优化相关的 3 和 4,我们还需要一些额外处理。这就是这个函数里额外的两个和 Ordering 有关的奇怪参数。
如果你查看 atomic 的文档,可以看到 Ordering 是一个 enum:
#![allow(unused)] fn main() { pub enum Ordering { Relaxed, Release, Acquire, AcqRel, SeqCst, } }
文档里解释了几种 Ordering 的用途,我来稍稍扩展一下。
第一个Relaxed,这是最宽松的规则,它对编译器和 CPU 不做任何限制,可以乱序执行。
Release,当我们 写入数据(比如上面代码里的 store)的时候,如果用了 Release order,那么:
- 对于当前线程,任何读取或写入操作都不能被乱序排在这个 store 之后。也就是说,在上面的例子里,CPU 或者编译器不能把
**3挪到**4之后执行。 - 对于其它线程,如果使用了
Acquire来读取这个 atomic 的数据, 那么它们看到的是修改后的结果。上面代码我们在compare_exchange里使用了Acquire来读取,所以能保证读到最新的值。
而Acquire是当我们 读取数据 的时候,如果用了 Acquire order,那么:
- 对于当前线程,任何读取或者写入操作都不能被乱序排在这个读取 之前。在上面的例子里,CPU 或者编译器不能把
**3挪到**1之前执行。 - 对于其它线程,如果使用了
Release来修改数据,那么,修改的值对当前线程可见。
第四个AcqRel是Acquire 和 Release 的结合,同时拥有 Acquire 和 Release 的保证。这个一般用在 fetch_xxx 上,比如你要对一个 atomic 自增 1,你希望这个操作之前和之后的读取或写入操作不会被乱序,并且操作的结果对其它线程可见。
最后的SeqCst是最严格的 ordering,除了 AcqRel 的保证外,它还保证所有线程看到的所有 SeqCst 操作的顺序是一致的。
因为 CAS 和 ordering 都是系统级的操作,所以这里描述的 Ordering 的用途在各种语言中都大同小异。对于 Rust 来说,它的 atomic 原语 继承于 C++。如果读 Rust 的文档你感觉云里雾里,那么 C++ 关于 ordering 的文档要清晰得多。
其实上面获取锁的 spin 过程性能不够好,更好的方式是这样处理一下:
#![allow(unused)] fn main() { while self .locked .compare_exchange(false, true, Ordering::Acquire, Ordering::Relaxed) .is_err() { // 性能优化:compare_exchange 需要独占访问,当拿不到锁时,我们 // 先不停检测 locked 的状态,直到其 unlocked 后,再尝试拿锁 while self.locked.load(Ordering::Relaxed) == true {} } }
注意,我们在 while loop 里,又嵌入了一个 loop。这是因为 CAS 是个代价比较高的操作,它需要获得对应内存的独占访问(exclusive access),我们希望失败的时候只是简单读取 atomic 的状态,只有符合条件的时候再去做独占访问,进行 CAS。所以,看上去多做了一层循环,实际代码的效率更高。
以下是两个线程同步的过程,一开始 t1 拿到锁、t2 spin,之后 t1 释放锁、t2 进入到临界区执行:

讲到这里,相信你对 atomic 以及其背后的 CAS 有初步的了解了。那么,atomic 除了做其它并发原语,还有什么作用?
我个人用的最多的是做各种 lock-free 的数据结构。比如,需要一个全局的 ID 生成器。当然可以使用 UUID 这样的模块来生成唯一的 ID,但如果我们同时需要这个 ID 是有序的,那么 AtomicUsize 就是最好的选择。
你可以用 fetch_add 来增加这个 ID,而 fetch_add 返回的结果就可以用于当前的 ID。这样,不需要加锁,就得到了一个可以在多线程中安全使用的 ID 生成器。
另外,atomic 还可以用于记录系统的各种 metrics。比如一个简单的 in-memory Metrics 模块:
#![allow(unused)] fn main() { use std::{ collections::HashMap, sync::atomic::{AtomicUsize, Ordering}, }; // server statistics pub struct Metrics(HashMap<&'static str, AtomicUsize>); impl Metrics { pub fn new(names: &[&'static str]) -> Self { let mut metrics: HashMap<&'static str, AtomicUsize> = HashMap::new(); for name in names.iter() { metrics.insert(name, AtomicUsize::new(0)); } Self(metrics) } pub fn inc(&self, name: &'static str) { if let Some(m) = self.0.get(name) { m.fetch_add(1, Ordering::Relaxed); } } pub fn add(&self, name: &'static str, val: usize) { if let Some(m) = self.0.get(name) { m.fetch_add(val, Ordering::Relaxed); } } pub fn dec(&self, name: &'static str) { if let Some(m) = self.0.get(name) { m.fetch_sub(1, Ordering::Relaxed); } } pub fn snapshot(&self) -> Vec<(&'static str, usize)> { self.0 .iter() .map(|(k, v)| (*k, v.load(Ordering::Relaxed))) .collect() } } }
它允许你初始化一个全局的 metrics 表,然后在程序的任何地方,无锁地操作相应的 metrics:
lazy_static! { pub(crate) static ref METRICS: Metrics = Metrics::new(&[ "topics", "clients", "peers", "broadcasts", "servers", "states", "subscribers" ]); } fn main() { METRICS.inc("topics"); METRICS.inc("subscribers"); println!("{:?}", METRICS.snapshot()); }
完整代码见 GitHub repo 或者 playground。
Mutex
Atomic 虽然可以处理自由竞争模式下加锁的需求,但毕竟用起来不那么方便,我们需要更高层的并发原语,来保证软件系统控制多个线程对同一个共享资源的访问,使得每个线程在访问共享资源的时候,可以独占或者说互斥访问(mutual exclusive access)。
我们知道,对于一个共享资源,如果所有线程只做读操作,那么无需互斥,大家随时可以访问,很多 immutable language(如 Erlang / Elixir)做了语言层面的只读保证,确保了并发环境下的无锁操作。这牺牲了一些效率(常见的 list/hashmap 需要使用 persistent data structure),额外做了不少内存拷贝,换来了并发控制下的简单轻灵。
然而, 一旦有任何一个或多个线程要修改共享资源,不但写者之间要互斥,读写之间也需要互斥。毕竟如果读写之间不互斥的话,读者轻则读到脏数据,重则会读到已经被破坏的数据,导致 crash。比如读者读到链表里的一个节点,而写者恰巧把这个节点的内存释放掉了,如果不做互斥访问,系统一定会崩溃。
所以操作系统提供了用来解决这种读写互斥问题的基本工具:Mutex(RwLock 我们放下不表)。
其实上文中,为了展示如何使用 atomic,我们制作了一个非常粗糙简单的 SpinLock,就可以看做是一个广义的 Mutex。 SpinLock,顾名思义,就是线程通过 CPU 空转(spin,就像前面的 while loop)忙等(busy wait),来等待某个临界区可用的一种锁。
然而,这种通过 SpinLock 做互斥的实现方式有使用场景的限制:如果受保护的临界区太大,那么整体的性能会急剧下降, CPU 忙等,浪费资源还不干实事,不适合作为一种通用的处理方法。
更通用的解决方案是:当多个线程竞争同一个 Mutex 时,获得锁的线程得到临界区的访问,其它线程被挂起,放入该 Mutex 上的一个等待队列里。 当获得锁的线程完成工作,退出临界区时,Mutex 会给等待队列发一个信号,把队列中第一个线程唤醒,于是这个线程可以进行后续的访问。整个过程如下:
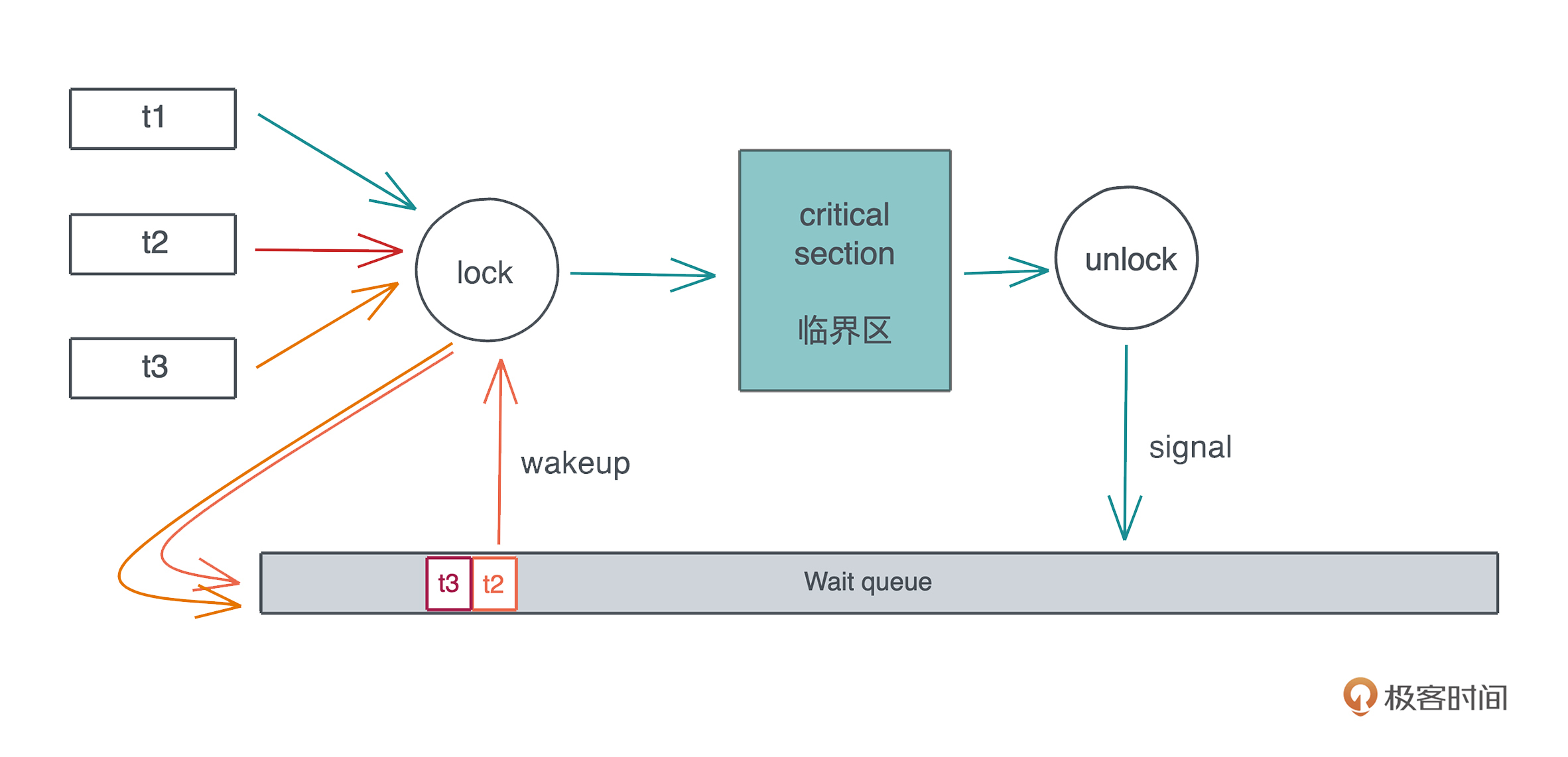
我们前面也讲过,线程的上下文切换代价很大,所以频繁将线程挂起再唤醒,会降低整个系统的效率。所以很多 Mutex 具体的实现会将 SpinLock(确切地说是 spin wait)和线程挂起结合使用: 线程的 lock 请求如果拿不到会先尝试 spin 一会,然后再挂起添加到等待队列。Rust 下的 parking_lot 就是这样实现的。
当然,这样实现会带来公平性的问题:如果新来的线程恰巧在 spin 过程中拿到了锁,而当前等待队列中还有其它线程在等待锁,那么等待的线程只能继续等待下去,这不符合 FIFO,不适合那些需要严格按先来后到排队的使用场景。为此,parking_lot 提供了 fair mutex。
Mutex 的实现依赖于 CPU 提供的 atomic。你可以把 Mutex 想象成一个粒度更大的 atomic,只不过这个 atomic 无法由 CPU 保证,而是通过软件算法来实现。
至于操作系统里另一个重要的概念信号量(semaphore),你可以认为是 Mutex 更通用的表现形式。比如在新冠疫情下,图书馆要控制同时在馆内的人数,如果满了,其他人就必须排队,出来一个才能再进一个。这里,如果总人数限制为 1,就是 Mutex,如果 > 1,就是 semaphore。
小结
今天我们学习了两个基本的并发原语 Atomic 和 Mutex。Atomic 是一切并发同步的基础,通过CPU 提供特殊的 CAS 指令,操作系统和应用软件可以构建更加高层的并发原语,比如 SpinLock 和 Mutex。
SpinLock和 Mutex 最大的不同是, 使用 SpinLock,线程在忙等(busy wait),而使用 Mutex lock,线程在等待锁的时候会被调度出去,等锁可用时再被调度回来。
听上去 SpinLock 似乎效率很低,其实不是,这要具体看锁的临界区大小。如果临界区要执行的代码很少,那么和 Mutex lock 带来的上下文切换(context switch)相比,SpinLock 是值得的。在 Linux Kernel 中,很多时候我们只能使用 SpinLock。
思考题
你可以想想可以怎么实现 semaphore,也可以想想像图书馆里那样的人数控制系统怎么用信号量实现(提示:Rust 下 tokio 提供了 tokio::sync::Semaphore)。
欢迎在留言区分享你的思考,感谢你的阅读。下一讲我们继续学习并发的另外三个概念Condvar、Channel 和 Actor model,下一讲见~
参考资料
- Robe Pike的演讲 concurrency is not parallelism,如果你没有看过,建议去看看。
- 通过今天的例子,相信你对 atomic 以及其背后的 CAS 有个初步的了解,如果你还想更深入学习 Rust 下如何使用 atomic,可以看 Jon Gjengset 的视频: Crust of Rust: Atomics and Memory Ordering。
- Rust 的 spin-rs crate 提供了 Spinlock 的实现,感兴趣的可以看看它的实现。
并发处理(下):从atomics到Channel,Rust都提供了什么工具?
你好,我是陈天。
对于并发状态下这三种常见的工作模式:自由竞争模式、map/reduce 模式、DAG 模式,我们的难点是如何在这些并发的任务中进行同步。atomic / Mutex 解决了自由竞争模式下并发任务的同步问题,也能够很好地解决 map/reduce 模式下的同步问题,因为此时同步只发生在 map 和 reduce 两个阶段。
然而,它们没有解决一个更高层次的问题,也就是 DAG 模式:如果这种访问需要按照一定顺序进行或者前后有依赖关系,该怎么做?
这个问题的典型场景是 生产者-消费者模式:生产者生产出来内容后,需要有机制通知消费者可以消费。比如 socket 上有数据了,通知处理线程来处理数据,处理完成之后,再通知 socket 收发的线程发送数据。
Condvar
所以,操作系统还提供了 Condvar。Condvar 有两种状态:
- 等待(wait):线程在队列中等待,直到满足某个条件。
- 通知(notify):当 condvar 的条件满足时,当前线程通知其他等待的线程可以被唤醒。通知可以是单个通知,也可以是多个通知,甚至广播(通知所有人)。
在实践中,Condvar 往往和 Mutex 一起使用: Mutex 用于保证条件在读写时互斥,Condvar 用于控制线程的等待和唤醒。我们来看一个例子:
use std::sync::{Arc, Condvar, Mutex}; use std::thread; use std::time::Duration; fn main() { let pair = Arc::new((Mutex::new(false), Condvar::new())); let pair2 = Arc::clone(&pair); thread::spawn(move || { let (lock, cvar) = &*pair2; let mut started = lock.lock().unwrap(); *started = true; eprintln!("I'm a happy worker!"); // 通知主线程 cvar.notify_one(); loop { thread::sleep(Duration::from_secs(1)); println!("working..."); } }); // 等待工作线程的通知 let (lock, cvar) = &*pair; let mut started = lock.lock().unwrap(); while !*started { started = cvar.wait(started).unwrap(); } eprintln!("Worker started!"); }
这段代码通过 condvar,我们实现了 worker 线程在执行到一定阶段后通知主线程,然后主线程再做一些事情。
这里,我们使用了一个 Mutex 作为互斥条件,然后在 cvar.wait() 中传入这个 Mutex。这个接口需要一个 MutexGuard,以便于知道需要唤醒哪个 Mutex 下等待的线程:
#![allow(unused)] fn main() { pub fn wait<'a, T>( &self, guard: MutexGuard<'a, T> ) -> LockResult<MutexGuard<'a, T>> }
Channel
但是用 Mutex 和 Condvar 来处理复杂的 DAG 并发模式会比较吃力。所以,Rust 还提供了各种各样的 Channel 用于处理并发任务之间的通讯。
由于 Golang 不遗余力地推广,Channel 可能是最广为人知的并发手段。相对于 Mutex,Channel 的抽象程度最高,接口最为直观,使用起来的心理负担也没那么大。使用 Mutex 时,你需要很小心地避免死锁,控制临界区的大小,防止一切可能发生的意外。
虽然在 Rust 里,我们可以“无畏并发”(Fearless concurrency)—— 当代码编译通过,绝大多数并发问题都可以规避,但性能上的问题、逻辑上的死锁还需要开发者照料。
Channel 把锁封装在了队列写入和读取的小块区域内,然后把读者和写者完全分离,使得读者读取数据和写者写入数据,对开发者而言,除了潜在的上下文切换外,完全和锁无关,就像访问一个本地队列一样。所以,对于大部分并发问题,我们都可以用 Channel 或者类似的思想来处理(比如 actor model)。
Channel 在具体实现的时候,根据不同的使用场景,会选择不同的工具。Rust 提供了以下四种 Channel:
- oneshot:这可能是最简单的 Channel,写者就只发一次数据,而读者也只读一次。这种一次性的、多个线程间的同步可以用 oneshot channel 完成。由于 oneshot 特殊的用途,实现的时候可以直接用 atomic swap 来完成。
- rendezvous:很多时候,我们只需要通过 Channel 来控制线程间的同步,并不需要发送数据。rendezvous channel 是 channel size 为 0 的一种特殊情况。
这种情况下,我们用 Mutex + Condvar 实现就足够了,在具体实现中,rendezvous channel 其实也就是 Mutex + Condvar 的一个包装。
- bounded: bounded channel 有一个队列,但队列有上限。一旦队列被写满了,写者也需要被挂起等待。当阻塞发生后,读者一旦读取数据,channel 内部就会使用 Condvar 的
notify_one通知写者,唤醒某个写者使其能够继续写入。
因此,实现中,一般会用到 Mutex + Condvar + VecDeque 来实现;如果不用 Condvar,可以直接使用 thread::park + thread::notify 来完成( flume 的做法);如果不用 VecDeque,也可以使用双向链表或者其它的 ring buffer 的实现。
- unbounded:queue 没有上限,如果写满了,就自动扩容。我们知道,Rust 的很多数据结构如
Vec、VecDeque都是自动扩容的。unbounded 和 bounded 相比,除了不阻塞写者,其它实现都很类似。
所有这些 channel 类型,同步和异步的实现思路大同小异,主要的区别在于挂起/唤醒的对象。 在同步的世界里,挂起/唤醒的对象是线程;而异步的世界里,是粒度很小的 task。
根据 Channel 读者和写者的数量,Channel 又可以分为:
- SPSC:Single-Producer Single-Consumer,单生产者,单消费者。最简单,可以不依赖于 Mutex,只用 atomics 就可以实现。
- SPMC:Single-Producer Multi-Consumer,单生产者,多消费者。需要在消费者这侧读取时加锁。
- MPSC:Multi-Producer Single-Consumer,多生产者,单消费者。需要在生产者这侧写入时加锁。
- MPMC:Multi-Producer Multi-Consumer。多生产者,多消费者。需要在生产者写入或者消费者读取时加锁。
在众多 Channel 类型中,使用最广的是 MPSC channel,多生产者,单消费者, 因为往往我们希望通过单消费者来保证,用于处理消息的数据结构有独占的写访问。
比如,在 xunmi 的实现中,index writer 内部是一个多线程的实现,但在使用时,我们需要用到它的可写引用。
如果要能够在各种上下文中使用 index writer,我们就不得不将其用 Arc<Mutex
#![allow(unused)] fn main() { pub struct IndexInner { index: Index, reader: IndexReader, config: IndexConfig, updater: Sender<Input>, } pub struct IndexUpdater { sender: Sender<Input>, t2s: bool, schema: Schema, } impl Indexer { // 打开或者创建一个 index pub fn open_or_create(config: IndexConfig) -> Result<Self> { let schema = config.schema.clone(); let index = if let Some(dir) = &config.path { fs::create_dir_all(dir)?; let dir = MmapDirectory::open(dir)?; Index::open_or_create(dir, schema.clone())? } else { Index::create_in_ram(schema.clone()) }; Self::set_tokenizer(&index, &config); let mut writer = index.writer(config.writer_memory)?; // 创建一个 unbounded MPSC channel let (s, r) = unbounded::<Input>(); // 启动一个线程,从 channel 的 reader 中读取数据 thread::spawn(move || { for input in r { // 然后用 index writer 处理这个 input if let Err(e) = input.process(&mut writer, &schema) { warn!("Failed to process input. Error: {:?}", e); } } }); // 把 channel 的 sender 部分存入 IndexInner 结构 Self::new(index, config, s) } pub fn get_updater(&self) -> IndexUpdater { let t2s = TextLanguage::Chinese(true) == self.config.text_lang; // IndexUpdater 内部包含 channel 的 sender 部分 // 由于是 MPSC channel,所以这里可以简单 clone 一下 sender // 这也意味着,我们可以创建任意多个 IndexUpdater 在不同上下文发送数据 // 而数据最终都会通过 channel 给到上面创建的线程,由 index writer 处理 IndexUpdater::new(self.updater.clone(), self.index.schema(), t2s) } } }
Actor
最后我们简单介绍一下 actor model,它在业界主要的使用者是 Erlang VM以及 akka。
actor 是一种有栈协程。每个 actor,有自己的一个独立的、轻量级的调用栈,以及一个用来接受消息的消息队列(mailbox 或者 message queue),外界跟 actor 打交道的唯一手段就是,给它发送消息。
Rust 标准库没有 actor 的实现,但是社区里有比较成熟的 actix(大名鼎鼎的 actix-web 就是基于 actix 实现的),以及 bastion。
下面的代码用 actix 实现了一个简单的 DummyActor,它可以接收一个 InMsg,返回一个 OutMsg:
use actix::prelude::*; use anyhow::Result; // actor 可以处理的消息 #[derive(Message, Debug, Clone, PartialEq)] #[rtype(result = "OutMsg")] enum InMsg { Add((usize, usize)), Concat((String, String)), } #[derive(MessageResponse, Debug, Clone, PartialEq)] enum OutMsg { Num(usize), Str(String), } // Actor struct DummyActor; impl Actor for DummyActor { type Context = Context<Self>; } // 实现处理 InMsg 的 Handler trait impl Handler<InMsg> for DummyActor { type Result = OutMsg; // <- 返回的消息 fn handle(&mut self, msg: InMsg, _ctx: &mut Self::Context) -> Self::Result { match msg { InMsg::Add((a, b)) => OutMsg::Num(a + b), InMsg::Concat((mut s1, s2)) => { s1.push_str(&s2); OutMsg::Str(s1) } } } } #[actix::main] async fn main() -> Result<()> { let addr = DummyActor.start(); let res = addr.send(InMsg::Add((21, 21))).await?; let res1 = addr .send(InMsg::Concat(("hello, ".into(), "world".into()))) .await?; println!("res: {:?}, res1: {:?}", res, res1); Ok(()) }
可以看到,对 DummyActor,我们只需要实现 Actor trait和Handler
一点小结
学完这前后两讲,我们小结一下各种并发原语的使用场景Atomic、Mutex、RwLock、Semaphore、Condvar、Channel、Actor。
- Atomic 在处理简单的原生类型时非常有用,如果你可以通过 AtomicXXX 结构进行同步,那么它们是最好的选择。
- 当你的数据结构无法简单通过 AtomicXXX 进行同步,但你又的确需要在多个线程中共享数据,那么 Mutex / RwLock 可以是一种选择。不过,你需要考虑锁的粒度,粒度太大的 Mutex / RwLock 效率很低。
- 如果你有 N 份资源可以供多个并发任务竞争使用,那么,Semaphore 是一个很好的选择。比如你要做一个 DB 连接池。
- 当你需要在并发任务中通知、协作时,Condvar 提供了最基本的通知机制,而Channel 把这个通知机制进一步广泛扩展开,于是你可以用 Condvar 进行点对点的同步,用 Channel 做一对多、多对一、多对多的同步。
所以,当我们做大部分复杂的系统设计时,Channel 往往是最有力的武器,除了可以让数据穿梭于各个线程、各个异步任务间,它的接口还可以很优雅地跟 stream 适配。
如果说在做整个后端的系统架构时,我们着眼的是:有哪些服务、服务和服务之间如何通讯、数据如何流动、服务和服务间如何同步;那么 在做某一个服务的架构时,着眼的是有哪些功能性的线程(异步任务)、它们之间的接口是什么样子、数据如何流动、如何同步。
在这里,Channel 兼具接口、同步和数据流三种功能,所以我说是最有力的武器。
然而它不该是唯一的武器。我们面临的真实世界的并发问题是多样的,解决方案也应该是多样的,计算机科学家们在过去的几十年里不断探索,构建了一系列的并发原语,也说明了很难有一种银弹解决所有问题。
就连 Mutex 本身,在实现中,还会根据不同的场景做不同的妥协(比如做 faireness 的妥协),因为这个世界就是这样,鱼与熊掌不可兼得,没有完美的解决方案,只有妥协出来的解决方案。所以 Channel 不是银弹,actor model 不是银弹,lock 不是银弹。
一门好的编程语言,可以提供大部分场景下的最佳实践(如 Erlang/Golang),但不该营造一种气氛,只有某个最佳实践才是唯一方案。我很喜欢 Erlang 的 actor model 和 Golang 的 Channel,但很可惜,它们过分依赖特定的、唯一的并发方案,使得开发者拿着榔头,看什么都是钉子。
相反,Rust 提供几乎你需要的所有解决方案,并且并不鼓吹它们的优劣,完全交由你按需选择。我在用 Rust 撰写多线程应用时,Channel 仍然是第一选择,但我还是会在合适的时候使用 Mutex、RwLock、Semaphore、Condvar、Atomic 等工具,而不是试图笨拙地用 Channel 叠加 Channel 来应对所有的场景。
思考题
- 请仔细阅读标准库的文档 std::sync,以及 std::sync::atomic 和 std::sync::mpsc。 尝试着使用 mpsc::channel 在两个线程中 来回 发送消息。比如线程 A 给线程 B 发送:hello world!,线程 B 收到之后回复 goodbye!。
- 想想看,如果要你实现 actor model,利用现有的并发原语,你该如何实现呢?
欢迎在留言区分享你的思考,感谢你的阅读。你已经完成Rust学习的第34次打卡啦,如果觉得有收获,也欢迎你分享给身边的朋友,邀他一起讨论。我们下节课见。
实操项目:如何实现一个基本的MPSC channel?
你好,我是陈天。
通过上两讲的学习,相信你已经意识到,虽然并发原语看上去是很底层、很神秘的东西,但实现起来也并不像想象中的那么困难,尤其是在 Rust 下,在 第 33 讲 中,我们用了几十行代码就实现了一个简单的 SpinLock。
你也许会觉得不太过瘾,而且 SpinLock 也不是经常使用的并发原语,那么今天,我们试着实现一个使用非常广泛的 MPSC channel 如何?
之前我们谈论了如何在搜索引擎的 Index writer 上使用 MPSC channel:要更新 index 的上下文有很多(可以是线程也可以是异步任务),而 IndexWriter 只能是唯一的。为了避免在访问 IndexWriter 时加锁,我们可以使用 MPSC channel,在多个上下文中给 channel 发消息,然后在唯一拥有 IndexWriter 的线程中读取这些消息,非常高效。
好,来看看今天要实现的 MPSC channel 的基本功能。为了简便起见,我们只关心 unbounded MPSC channel。也就是说,当队列容量不够时,会自动扩容,所以, 任何时候生产者写入数据都不会被阻塞,但是当队列中没有数据时,消费者会被阻塞:
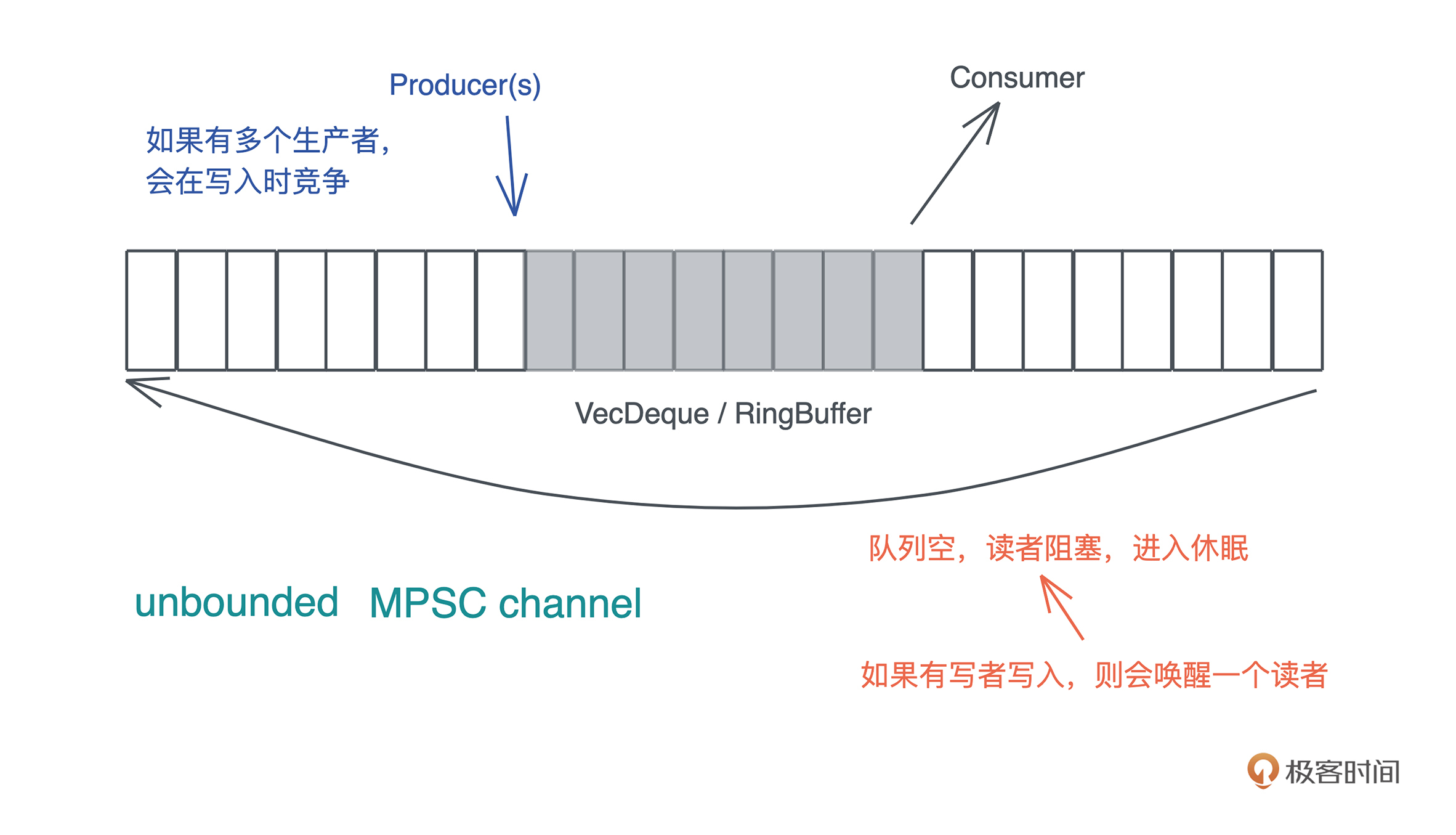
测试驱动的设计
之前我们会从需求的角度来设计接口和数据结构,今天我们就换种方式,完全站在使用者的角度,用使用实例(测试)来驱动接口和数据结构的设计。
需求 1
要实现刚才说的 MPSC channel,都有什么需求呢?首先,生产者可以产生数据,消费者能够消费产生出来的数据,也就是基本的 send/recv,我们以下面这个单元测试 1 来描述这个需求:
#![allow(unused)] fn main() { #[test] fn channel_should_work() { let (mut s, mut r) = unbounded(); s.send("hello world!".to_string()).unwrap(); let msg = r.recv().unwrap(); assert_eq!(msg, "hello world!"); } }
这里,通过 unbounded() 方法, 可以创建一个 sender和一个 receiver,sender 有 send() 方法,可以发送数据,receiver 有 recv() 方法,可以接受数据。整体的接口,我们设计和 std::sync::mpsc 保持一致,避免使用者使用上的心智负担。
为了实现这样一个接口,需要什么样的数据结构呢?首先,生产者和消费者之间会共享一个队列,上一讲我们说到,可以用 VecDeque。显然,这个队列在插入和取出数据时需要互斥,所以需要用 Mutex 来保护它。所以,我们大概可以得到这样一个结构:
#![allow(unused)] fn main() { struct Shared<T> { queue: Mutex<VecDeque<T>>, } pub struct Sender<T> { shared: Arc<Shared<T>>, } pub struct Receiver<T> { shared: Arc<Shared<T>>, } }
这样的数据结构应该可以满足单元测试 1。
需求 2
由于需要的是 MPSC,所以,我们允许多个 sender 往 channel 里发送数据,用单元测试 2 来描述这个需求:
#![allow(unused)] fn main() { #[test] fn multiple_senders_should_work() { let (mut s, mut r) = unbounded(); let mut s1 = s.clone(); let mut s2 = s.clone(); let t = thread::spawn(move || { s.send(1).unwrap(); }); let t1 = thread::spawn(move || { s1.send(2).unwrap(); }); let t2 = thread::spawn(move || { s2.send(3).unwrap(); }); for handle in [t, t1, t2] { handle.join().unwrap(); } let mut result = [r.recv().unwrap(), r.recv().unwrap(), r.recv().unwrap()]; // 在这个测试里,数据到达的顺序是不确定的,所以我们排个序再 assert result.sort(); assert_eq!(result, [1, 2, 3]); } }
这个需求,刚才的数据结构就可以满足,只是 Sender 需要实现 Clone trait。不过我们在写这个测试的时候稍微有些别扭,因为这一行有不断重复的代码:
#![allow(unused)] fn main() { let mut result = [r.recv().unwrap(), r.recv().unwrap(), r.recv().unwrap()]; }
注意,测试代码的 DRY 也很重要,我们之前强调过。所以,当写下这个测试的时候,也许会想,我们可否提供 Iterator 的实现?恩这个想法先暂存下来。
需求 3
接下来考虑当队列空的时候,receiver 所在的线程会被阻塞这个需求。那么,如何对这个需求进行测试呢?这并不简单,我们没有比较直观的方式来检测线程的状态。
不过,我们可以通过检测“线程是否退出”来间接判断线程是否被阻塞。理由很简单,如果线程没有继续工作,又没有退出,那么一定被阻塞住了。阻塞住之后,我们继续发送数据,消费者所在的线程会被唤醒,继续工作,所以最终队列长度应该为 0。我们看单元测试 3:
#![allow(unused)] fn main() { #[test] fn receiver_should_be_blocked_when_nothing_to_read() { let (mut s, r) = unbounded(); let mut s1 = s.clone(); thread::spawn(move || { for (idx, i) in r.into_iter().enumerate() { // 如果读到数据,确保它和发送的数据一致 assert_eq!(idx, i); } // 读不到应该休眠,所以不会执行到这一句,执行到这一句说明逻辑出错 assert!(false); }); thread::spawn(move || { for i in 0..100usize { s.send(i).unwrap(); } }); // 1ms 足够让生产者发完 100 个消息,消费者消费完 100 个消息并阻塞 thread::sleep(Duration::from_millis(1)); // 再次发送数据,唤醒消费者 for i in 100..200usize { s1.send(i).unwrap(); } // 留点时间让 receiver 处理 thread::sleep(Duration::from_millis(1)); // 如果 receiver 被正常唤醒处理,那么队列里的数据会都被读完 assert_eq!(s1.total_queued_items(), 0); } }
这个测试代码中,我们假定 receiver 实现了 Iterator,还假定 sender 提供了一个方法total_queued_items()。这些可以在实现的时候再处理。
你可以花些时间仔细看看这段代码,想想其中的处理逻辑。虽然代码很简单,不难理解,但是把一个完整的需求转化成合适的测试代码,还是要颇费些心思的。
好,如果要能支持队列为空时阻塞,我们需要使用 Condvar。所以 Shared
#![allow(unused)] fn main() { struct Shared<T> { queue: Mutex<VecDeque<T>>, available: Condvar, } }
这样当实现 Receiver 的 recv() 方法后,我们可以在读不到数据时阻塞线程:
#![allow(unused)] fn main() { // 拿到锁 let mut inner = self.shared.queue.lock().unwrap(); // ... 假设读不到数据 // 使用 condvar 和 MutexGuard 阻塞当前线程 self.shared.available.wait(inner) }
需求 4
顺着刚才的多个 sender想,如果现在所有 Sender 都退出作用域,Receiver 继续接收,到没有数据可读了,该怎么处理?是不是应该产生一个错误,让调用者知道,现在 channel 的另一侧已经没有生产者了,再读也读不出数据了?
我们来写单元测试 4:
#![allow(unused)] fn main() { #[test] fn last_sender_drop_should_error_when_receive() { let (s, mut r) = unbounded(); let s1 = s.clone(); let senders = [s, s1]; let total = senders.len(); // sender 即用即抛 for mut sender in senders { thread::spawn(move || { sender.send("hello").unwrap(); // sender 在此被丢弃 }) .join() .unwrap(); } // 虽然没有 sender 了,接收者依然可以接受已经在队列里的数据 for _ in 0..total { r.recv().unwrap(); } // 然而,读取更多数据时会出错 assert!(r.recv().is_err()); } }
这个测试依旧很简单。你可以想象一下,使用什么样的数据结构可以达到这样的目的。
首先,每次 Clone 时,要增加 Sender 的计数;在 Sender Drop 时,减少这个计数;然后,我们为 Receiver 提供一个方法 total_senders(),来读取 Sender 的计数,当计数为 0,且队列中没有数据可读时,recv() 方法就报错。
有了这个思路,你想一想,这个计数器用什么数据结构呢?用锁保护么?
哈,你一定想到了可以使用 atomics。对,我们可以用 AtomicUsize。所以,Shared 数据结构需要更新一下:
#![allow(unused)] fn main() { struct Shared<T> { queue: Mutex<VecDeque<T>>, available: Condvar, senders: AtomicUsize, } }
需求 5
既然没有 Sender 了要报错,那么如果没有 Receiver了,Sender 发送时是不是也应该错误返回?这个需求和上面类似,就不赘述了。看构造的单元测试 5:
#![allow(unused)] fn main() { #[test] fn receiver_drop_should_error_when_send() { let (mut s1, mut s2) = { let (s, _) = unbounded(); let s1 = s.clone(); let s2 = s.clone(); (s1, s2) }; assert!(s1.send(1).is_err()); assert!(s2.send(1).is_err()); } }
这里,我们创建一个 channel,产生两个 Sender 后便立即丢弃 Receiver。两个 Sender 在发送时都会出错。
同样的,Shared 数据结构要更新一下:
#![allow(unused)] fn main() { struct Shared<T> { queue: Mutex<VecDeque<T>>, available: Condvar, senders: AtomicUsize, receivers: AtomicUsize, } }
实现 MPSC channel
现在写了五个单元测试,我们已经把需求摸透了,并且有了基本的接口和数据结构的设计。接下来,我们来写实现的代码。
创建一个新的项目 cargo new con_utils --lib。在 cargo.toml 中添加 anyhow 作为依赖。在 lib.rs 里,我们就写入一句: pub mod channel , 然后创建 src/channel.rs,把刚才设计时使用的 test case、设计的数据结构,以及 test case 里使用到的接口,用代码全部放进来:
#![allow(unused)] fn main() { use anyhow::Result; use std::{ collections::VecDeque, sync::{atomic::AtomicUsize, Arc, Condvar, Mutex}, }; /// 发送者 pub struct Sender<T> { shared: Arc<Shared<T>>, } /// 接收者 pub struct Receiver<T> { shared: Arc<Shared<T>>, } /// 发送者和接收者之间共享一个 VecDeque,用 Mutex 互斥,用 Condvar 通知 /// 同时,我们记录有多少个 senders 和 receivers struct Shared<T> { queue: Mutex<VecDeque<T>>, available: Condvar, senders: AtomicUsize, receivers: AtomicUsize, } impl<T> Sender<T> { /// 生产者写入一个数据 pub fn send(&mut self, t: T) -> Result<()> { todo!() } pub fn total_receivers(&self) -> usize { todo!() } pub fn total_queued_items(&self) -> usize { todo!() } } impl<T> Receiver<T> { pub fn recv(&mut self) -> Result<T> { todo!() } pub fn total_senders(&self) -> usize { todo!() } } impl<T> Iterator for Receiver<T> { type Item = T; fn next(&mut self) -> Option<Self::Item> { todo!() } } /// 克隆 sender impl<T> Clone for Sender<T> { fn clone(&self) -> Self { todo!() } } /// Drop sender impl<T> Drop for Sender<T> { fn drop(&mut self) { todo!() } } impl<T> Drop for Receiver<T> { fn drop(&mut self) { todo!() } } /// 创建一个 unbounded channel pub fn unbounded<T>() -> (Sender<T>, Receiver<T>) { todo!() } #[cfg(test)] mod tests { use std::{thread, time::Duration}; use super::*; // 此处省略所有 test case } }
目前这个代码虽然能够编译通过,但因为没有任何实现,所以 cargo test 全部出错。接下来,我们就来一点点实现功能。
创建 unbounded channel
创建 unbounded channel 的接口很简单:
#![allow(unused)] fn main() { pub fn unbounded<T>() -> (Sender<T>, Receiver<T>) { let shared = Shared::default(); let shared = Arc::new(shared); ( Sender { shared: shared.clone(), }, Receiver { shared }, ) } const INITIAL_SIZE: usize = 32; impl<T> Default for Shared<T> { fn default() -> Self { Self { queue: Mutex::new(VecDeque::with_capacity(INITIAL_SIZE)), available: Condvar::new(), senders: AtomicUsize::new(1), receivers: AtomicUsize::new(1), } } } }
因为这里使用 default() 创建了 Shared
实现消费者
对于消费者,我们主要需要实现 recv 方法。
在 recv 中,如果队列中有数据,那么直接返回;如果没数据,且所有生产者都离开了,我们就返回错误;如果没数据,但还有生产者,我们就阻塞消费者的线程:
#![allow(unused)] fn main() { impl<T> Receiver<T> { pub fn recv(&mut self) -> Result<T> { // 拿到队列的锁 let mut inner = self.shared.queue.lock().unwrap(); loop { match inner.pop_front() { // 读到数据返回,锁被释放 Some(t) => { return Ok(t); } // 读不到数据,并且生产者都退出了,释放锁并返回错误 None if self.total_senders() == 0 => return Err(anyhow!("no sender left")), // 读不到数据,把锁提交给 available Condvar,它会释放锁并挂起线程,等待 notify None => { // 当 Condvar 被唤醒后会返回 MutexGuard,我们可以 loop 回去拿数据 // 这是为什么 Condvar 要在 loop 里使用 inner = self .shared .available .wait(inner) .map_err(|_| anyhow!("lock poisoned"))?; } } } } pub fn total_senders(&self) -> usize { self.shared.senders.load(Ordering::SeqCst) } } }
注意看这里 Condvar 的使用。
在 wait() 方法里,它接收一个 MutexGuard,然后释放这个 Mutex,挂起线程。等得到通知后,它会再获取锁,得到一个 MutexGuard,返回。所以这里是:
#![allow(unused)] fn main() { inner = self.shared.available.wait(inner).map_err(|_| anyhow!("lock poisoned"))?; }
因为 recv() 会返回一个值,所以阻塞回来之后,我们应该循环回去拿数据。这是为什么这段逻辑要被 loop {} 包裹。我们前面在设计时考虑过:当发送者发送数据时,应该通知被阻塞的消费者。所以,在实现 Sender 的 send() 时,需要做相应的 notify 处理。
记得还要处理消费者的 drop:
#![allow(unused)] fn main() { impl<T> Drop for Receiver<T> { fn drop(&mut self) { self.shared.receivers.fetch_sub(1, Ordering::AcqRel); } } }
很简单,消费者离开时,将 receivers 减一。
实现生产者
接下来我们看生产者的功能怎么实现。
首先,在没有消费者的情况下,应该报错。正常应该使用 thiserror 定义自己的错误,不过这里为了简化代码,就使用 anyhow! 宏产生一个 adhoc 的错误。如果消费者还在,那么我们获取 VecDeque 的锁,把数据压入:
#![allow(unused)] fn main() { impl<T> Sender<T> { /// 生产者写入一个数据 pub fn send(&mut self, t: T) -> Result<()> { // 如果没有消费者了,写入时出错 if self.total_receivers() == 0 { return Err(anyhow!("no receiver left")); } // 加锁,访问 VecDeque,压入数据,然后立刻释放锁 let was_empty = { let mut inner = self.shared.queue.lock().unwrap(); let empty = inner.is_empty(); inner.push_back(t); empty }; // 通知任意一个被挂起等待的消费者有数据 if was_empty { self.shared.available.notify_one(); } Ok(()) } pub fn total_receivers(&self) -> usize { self.shared.receivers.load(Ordering::SeqCst) } pub fn total_queued_items(&self) -> usize { let queue = self.shared.queue.lock().unwrap(); queue.len() } } }
这里,获取 total_receivers 时,我们使用了 Ordering::SeqCst,保证所有线程看到同样顺序的对 receivers 的操作。这个值是最新的值。
在压入数据时,需要判断一下之前是队列是否为空,因为队列为空的时候,我们需要用 notify_one() 来唤醒消费者。这个非常重要,如果没处理的话,会导致消费者阻塞后无法复原接收数据。
由于我们可以有多个生产者,所以要允许它 clone:
#![allow(unused)] fn main() { impl<T> Clone for Sender<T> { fn clone(&self) -> Self { self.shared.senders.fetch_add(1, Ordering::AcqRel); Self { shared: Arc::clone(&self.shared), } } } }
实现 Clone trait 的方法很简单,但记得要把 shared.senders 加 1,使其保持和当前的 senders 的数量一致。
当然,在 drop 的时候我们也要维护 shared.senders 使其减 1:
#![allow(unused)] fn main() { impl<T> Drop for Sender<T> { fn drop(&mut self) { self.shared.senders.fetch_sub(1, Ordering::AcqRel); } } }
其它功能
目前还缺乏 Receiver 的 Iterator 的实现,这个很简单,就是在 next() 里调用 recv() 方法,Rust 提供了支持在 Option / Result 之间很方便转换的函数,所以这里我们可以直接通过 ok() 来将 Result 转换成 Option:
#![allow(unused)] fn main() { impl<T> Iterator for Receiver<T> { type Item = T; fn next(&mut self) -> Option<Self::Item> { self.recv().ok() } } }
好,目前所有需要实现的代码都实现完毕, cargo test 测试一下。wow!测试一次性通过!这也太顺利了吧!
最后来仔细审视一下代码。很快,我们发现 Sender 的 Drop 实现似乎有点问题。 如果 Receiver 被阻塞,而此刻所有 Sender 都走了,那么 Receiver 就没有人唤醒,会带来资源的泄露。这是一个很边边角角的问题,所以之前的测试没有覆盖到。
我们来设计一个场景让这个问题暴露:
#![allow(unused)] fn main() { #[test] fn receiver_shall_be_notified_when_all_senders_exit() { let (s, mut r) = unbounded::<usize>(); // 用于两个线程同步 let (mut sender, mut receiver) = unbounded::<usize>(); let t1 = thread::spawn(move || { // 保证 r.recv() 先于 t2 的 drop 执行 sender.send(0).unwrap(); assert!(r.recv().is_err()); }); thread::spawn(move || { receiver.recv().unwrap(); drop(s); }); t1.join().unwrap(); } }
在我进一步解释之前,你可以停下来想想为什么这个测试可以保证暴露这个问题?它是怎么暴露的?如果想不到,再 cargo test 看看会出现什么问题。
来一起分析分析,这里,我们创建了两个线程 t1 和 t2,分别让它们处理消费者和生产者。 t1 读取数据,此时没有数据,所以会阻塞,而t2 直接把生产者 drop 掉。所以,此刻如果没有人唤醒 t1,那么 t1.join() 就会一直等待,因为 t1 一直没有退出。
所以,为了保证一定是 t1 r.recv() 先执行导致阻塞、t2 再 drop(s),我们(eat your own dog food)用另一个 channel 来控制两个线程的执行顺序。这是一种很通用的做法,你可以好好琢磨一下。
运行 cargo test 后,测试被阻塞。这是因为,t1 没有机会得到唤醒,所以这个测试就停在那里不动了。
要修复这个问题,我们需要妥善处理 Sender 的 Drop:
#![allow(unused)] fn main() { impl<T> Drop for Sender<T> { fn drop(&mut self) { let old = self.shared.senders.fetch_sub(1, Ordering::AcqRel); // sender 走光了,唤醒 receiver 读取数据(如果队列中还有的话),读不到就出错 if old <= 1 { // 因为我们实现的是 MPSC,receiver 只有一个,所以 notify_all 实际等价 notify_one self.shared.available.notify_all(); } } } }
这里,如果减一之前,旧的 senders 的数量小于等于 1,意味着现在是最后一个 Sender 要离开了,不管怎样我们都要唤醒 Receiver ,所以这里使用了 notify_all()。如果 Receiver 之前已经被阻塞,此刻就能被唤醒。修改完成, cargo test 一切正常。
性能优化
从功能上来说,目前我们的 MPSC unbounded channel 没有太多的问题,可以应用在任何需要 MPSC channel 的场景。然而,每次读写都需要获取锁,虽然锁的粒度很小,但还是让整体的性能打了个折扣。有没有可能优化锁呢?
之前我们讲到,优化锁的手段无非是 减小临界区的大小,让每次加锁的时间很短,这样冲突的几率就变小。另外,就是 降低加锁的频率, 对于消费者来说,如果我们能够一次性把队列中的所有数据都读完缓存起来,以后在需要的时候从缓存中读取,这样就可以大大减少消费者加锁的频次。
顺着这个思路,我们可以在 Receiver 的结构中放一个 cache:
#![allow(unused)] fn main() { pub struct Receiver<T> { shared: Arc<Shared<T>>, cache: VecDeque<T>, } }
如果你之前有 C 语言开发的经验,也许会想,到了这一步,何必把 queue 中的数据全部读出来,存入 Receiver 的 cache 呢?这样效率太低,如果能够直接 swap 两个结构内部的指针,这样,即便队列中有再多的数据,也是一个 O(1) 的操作。
嗯,别急,Rust 有类似的 std::mem::swap 方法。比如( 代码):
use std::mem; fn main() { let mut x = "hello world".to_string(); let mut y = "goodbye world".to_string(); mem::swap(&mut x, &mut y); assert_eq!("goodbye world", x); assert_eq!("hello world", y); }
好,了解了 swap 方法,我们看看如何修改 Receiver 的 recv() 方法来提升性能:
#![allow(unused)] fn main() { pub fn recv(&mut self) -> Result<T> { // 无锁 fast path if let Some(v) = self.cache.pop_front() { return Ok(v); } // 拿到队列的锁 let mut inner = self.shared.queue.lock().unwrap(); loop { match inner.pop_front() { // 读到数据返回,锁被释放 Some(t) => { // 如果当前队列中还有数据,那么就把消费者自身缓存的队列(空)和共享队列 swap 一下 // 这样之后再读取,就可以从 self.queue 中无锁读取 if !inner.is_empty() { std::mem::swap(&mut self.cache, &mut inner); } return Ok(t); } // 读不到数据,并且生产者都退出了,释放锁并返回错误 None if self.total_senders() == 0 => return Err(anyhow!("no sender left")), // 读不到数据,把锁提交给 available Condvar,它会释放锁并挂起线程,等待 notify None => { // 当 Condvar 被唤醒后会返回 MutexGuard,我们可以 loop 回去拿数据 // 这是为什么 Condvar 要在 loop 里使用 inner = self .shared .available .wait(inner) .map_err(|_| anyhow!("lock poisoned"))?; } } } } }
当 cache 中有数据时,总是从 cache 中读取;当 cache 中没有,我们拿到队列的锁,读取一个数据,然后看看队列是否还有数据,有的话,就 swap cache 和 queue,然后返回之前读取的数据。
好,做完这个重构和优化,我们可以运行 cargo test,看看已有的测试是否正常。如果你遇到报错,应该是 cache 没有初始化,你可以自行解决,也可以参考:
#![allow(unused)] fn main() { pub fn unbounded<T>() -> (Sender<T>, Receiver<T>) { let shared = Shared::default(); let shared = Arc::new(shared); ( Sender { shared: shared.clone(), }, Receiver { shared, cache: VecDeque::with_capacity(INITIAL_SIZE), }, ) } }
虽然现有的测试全数通过,但我们并没有为这个优化写测试,这里补个测试:
#![allow(unused)] fn main() { #[test] fn channel_fast_path_should_work() { let (mut s, mut r) = unbounded(); for i in 0..10usize { s.send(i).unwrap(); } assert!(r.cache.is_empty()); // 读取一个数据,此时应该会导致 swap,cache 中有数据 assert_eq!(0, r.recv().unwrap()); // 还有 9 个数据在 cache 中 assert_eq!(r.cache.len(), 9); // 在 queue 里没有数据了 assert_eq!(s.total_queued_items(), 0); // 从 cache 里读取剩下的数据 for (idx, i) in r.into_iter().take(9).enumerate() { assert_eq!(idx + 1, i); } } }
这个测试很简单,详细注释也都写上了。
小结
今天我们一起研究了如何使用 atomics 和 Condvar,结合 VecDeque 来创建一个 MPSC unbounded channel。完整的代码见 playground,你也可以在 GitHub repo 这一讲的目录中找到。
不同于以往的实操项目,这一讲,我们完全顺着需求写测试,然后在写测试的过程中进行数据结构和接口的设计。和普通的 TDD 不同的是,我们 先一口气把主要需求涉及的行为用测试来表述,然后通过这个表述,构建合适的接口,以及能够运行这个接口的数据结构。
在开发产品的时候,这也是一种非常有效的手段,可以让我们通过测试完善设计,最终得到一个能够让测试编译通过的、完全没有实现代码、只有接口的版本。之后,我们再一个接口一个接口实现,全部实现完成之后,运行测试,看看是否出问题。
在学习这一讲的内容时,你可以多多关注构建测试用例的技巧。之前的课程中,我反复强调过单元测试的重要性,也以身作则在几个重要的实操中都有详尽地测试。不过相比之前写的测试,这一讲中的测试要更难写一些,尤其是在并发场景下那些边边角角的功能测试。
不要小看测试代码,有时候构造测试代码比撰写功能代码还要烧脑。但是,当你有了扎实的单元测试覆盖后,再做重构,比如最后我们做和性能相关的重构,就变得轻松很多, 因为只要 cargo test 通过,起码这个重构没有引起任何回归问题(regression bug)。
当然,重构没有引入回归问题,并不意味着重构完全没有问题,我们还需要考虑撰写新的测试,覆盖重构带来的改动。
思考题
我们实现了一个 unbounded MPSC channel,如果要将其修改为 bounded MPSC channel(队列大小是受限的),需要怎么做?
欢迎在留言区交流你的学习心得和思考,感谢你的收听,今天你已经完成了Rust学习的第35次打卡。如果你觉得有收获,也欢迎你分享给身边的朋友,邀他一起讨论。我们下节课见。
用户故事|绝望之谷:改变从学习开始
你好,我是罗杰,目前在一家游戏公司担任后端开发主程。
到现在我也快工作十年了,作为一个从小学习能力很一般的人,这中间的打怪升级史可以说是相当惨痛。
我是13 年毕业的,在师范类院校学的软件工程专业。大四参加校招,历时三个月不断面试、笔试,勉强找到一份工作,做棋牌游戏后端开发,签到了深圳。这份工作实习不到半个月,我就开始失眠,因为在学校里从来没有深入学习,专业知识非常欠缺,代码几乎看不懂,当时也没有太多可以寻求帮助的途径,进入不了工作状态,非常痛苦。
其实即使我们有再多的知识储备, 换家公司,一定会有特别多的内容需要去学习和掌握,而且学习的过程一定是相当痛苦且枯燥的,之后每次换工作这种体会都会相当明显。
当时失眠了半个月之后,我找到部门领导提出换岗,告诉他觉得自己不太适合做开发。领导耐心地开导了我,也让当时的导师加强对我的关注。领导告诉我:虽然我的技术相对薄弱,但相比零经验的策划岗位而言,显然技术更加适合我,在犹豫之下我决定再尝试一段时间。
但是当时整个部门特别忙,其他同事根本没有时间理会我的困惑。实在没办法了,我开始直接在公司技术群里面寻求解决方案,刚开始没有人愿意搭理我,当然心理也会不舒服,但我还是坚持了,可能是问的太多了,有时候会有一些热心的同事愿意帮我解答。我默默记下了一些大佬的名字,后来有时候遇到问题直接去找他们,基本上问题很快就能解决。
难题可以去向大佬们请教,但是那些之前欠下来的基础知识还是得自己一点点啃,对于一个毕业生而言,要学的东西太多了。
对那些将要用到的技术,我会优先快速学习。印象比较深刻的一个案例是当时项目要使用 Redis,我利用晚上不到四个小时的时间,通过视频学习,加上课后立刻动手的好习惯,就基本掌握了所有高频的命令使用方法。那是我第一次意识到, 课后立刻动手 是如何加深自己的记忆的。之前觉得非常困难的任务,带着兴趣,加上良好的学习习惯,很快就掌握了。
除了常用工具,还有数据结构与算法、计算机网络、计算机组成原理、编译原理等一系列的基本功,这些内容学习之后反馈周期都会特别长。在实际工作中,你的工龄越高,这些知识的重要性一定会越发体现出来,我们需要有 N 年的工作经验,而不是把一个工作经验重复了 N 年。
我听过很多人抱怨:“这些基础知识大佬早在大学的时候都掌握了,我们到工作多少年了才想起来补,学了又记不住,平时也用不上,还不如去摸鱼”。其实即使是科班出身,在学校,教的几乎全都是皮毛,动手真正动手的机会也相对较少, 都是在工作中不断栽了跟头之后,才会意识到这些基本功的重要性。
对于基本功,我的规划是在年初每项都制定目标,年底进行回顾。《三体》说:“一队蚂蚁不停搬运米粒大小的石块,给它们十亿年,就能把泰山搬走。只要把时间拉得足够长,生命比岩石和金属都强壮得多,比飓风和火山更有力。”
但良好的习惯坚持下去非常不容易,所以在开始的时候,不要制定太困难的目标。将大目标拆成小目标,依次去实现,不要死磕在一项任务中,容易自闭,然后放弃。在学习的过程中,灵活调整要学习的内容。
我个人比较喜欢阅读相关的经典书籍,或者去 中国大学慕课 学习各个名校的相关课程,优点就是课程资源丰富,可以任意切换自己喜爱的名校课程,但这些课程的缺陷是比较古老,好在极客时间能完美解决这些问题。
不过像这种时间跨度比较长的计划,很容易丧失学习的兴趣。让自己长久保持兴趣的一个好办法是,在巩固基本功的同时,也制定学习新知识的计划,比如每一两年可以给自己制定一个计划,学习最热门的编程语言或者新技术,紧跟新趋势。关心自己,也关心这个世界。君子不器,全面发展,提高自身的韧性,能更加有反脆弱的能力。
聊到这里,你不会以为我已经升级成大佬了吧,哪有那么简单。前面说的都是我快十年来学习的心路总结。
好不容易在深圳三年过去,工作大致上了正轨,因为和媳妇两地分居也不是长久之计,所以我选择从深圳回到西安。
换了新工作,新的痛苦又来了,我发现又有很多新内容需要重新学。工作环境也完全不是我想象的样子,同事们的不专业、不理解的企业文化,再加上三个小时的通勤时间,我每天充满了怨气,跟家人的关系相当糟糕,整个人处于游离状态,甚至一度压力过大,频繁发烧,还在医院休息过半个月。
不过我很感谢住院的经历,每天晚上十点休息,早晨六点起床,有充足的睡眠,没有工作的压力,我有大把的时光反思自己的各种问题。这是我从开始工作最安逸的一段时光了,媳妇全程在医院陪护,尤其让我意外的是,平时处得非常糟糕的同事们都来医院看望。
出院之后,我决定改变:要改善和同事的关系、更加照顾家人的感受、尝试戒烟。但是切身感受就是 有心无力,虽然努力了,同事们跟我还是充满距离,孩子几乎不愿意和我待在一起、戒烟也还是失败了。
一年又过去了,因为扁桃体手术,又在医院休息了一段时间。我突然领悟到虽然努力了,但是可能方法依然不得当。我要寻找自救的方法。这个时候机缘巧合,媳妇推荐给我一门樊登的课程《可复制的沟通力》,让我试着看看,还挺有意思的。听了这节课,我就彻底改变了接下来的生活。
因为平时时间不够,我开始听各种经典书籍的解读课,学到了很多有用的理论和方法,比如对我影响比较大的一些书籍如《非暴力沟通》、《掌控谈话》、《终身成长》、《刻意练习》、《考试脑科学》、《亲密关系》等等。
有了意愿,也有了理论和方法,之后剩下就是执行。与家人有了更多相处时间,他们给了我爱与包容,让我每天多了更多快乐和动力,陪伴他们也会让我对工作和学习充满热情。把陪伴孩子学到的耐心应用在跟同事的相处里,工作氛围和谐了很多。家庭和工作是不冲突的,平衡好它们,我觉得自己每天都比前一天更加幸福。
但生活总是充满了各种挑战,在我以为已经掌握了控制自己的情绪并且知道如何跟人相处之后,依然跟一位新同事闹了很大的矛盾。即使这样,我也依然相信自己能迅速把心态调整好,通过再次去复习一些书,我很快从崩溃边缘把自己拉了回来。也正因为这一点,我也戒烟成功了。
在后来不停打怪升级的过程中,我遇到过很多问题。好多时候,由于工作安排得满满当当,甚至都找不到学习的时间。但是这并不能成为我不成长的理由,学习的方法太多了,看书、看视频、阅读专栏、看源码、参加线上线下各种分享活动等等,都是不错的方法, 关键是要找到最适合自己当前状态的。甚至写下这段话的时候,我怀里还抱着刚满五个月的小儿子,媳妇在辅导大儿子作业。
之前说我会在年初每项都制定目标,今年我制定的新语言学习目标是 Rust。如果你觉得作为一个工作快十年的人,肯定积累不少,学习Rust一定比较顺畅吧?其实并不是,很多知识点都需要反复去琢磨,不断去消化。
年初我读了一遍 The Book 的 中文翻译版,尝试写过一个非常简单的命令行程序,结果花了三四个小时,净跟编译器斗争了。三月份又重新读了一遍 英文版本,书上所有的源码也都自己动手执行了。但是做完这些,依然没有很好的掌握,无法流畅地写 Rust 代码。
九月份在 B 站上学习了“软件工艺师”的 视频课,相当于把之前看书的内容通过视频课又复习了一遍,这次改善比较明显,对一些之前不太理解的点有了进一步认知。我个人更喜欢视频讲解,虽然学习的时间周期比较长,但通过视觉跟听觉的双重作用,我的记忆比较深刻。
基础虽然掌握的差不多了,但是想要将 Rust 应用于工作,还太远了。
后面就是非常幸运地看到陈老师的专栏,看了目录之后果断入手,该专栏里面的内容几乎都能与实际工作完美地结合,配合上动手环节,学习的效果会非常明显。相信在课程学完之后,我就可以在项目中尝试去使用 Rust 了。
最后我想说,学习 Rust 一定是一场漫长的旅途,过程会相当艰难,肯定会遇到一些暂时不能顺利掌握的内容,但只要不放弃,暂时未掌握内容通过反复学习,多动手,相信我们都能顺利抵达终点。加油,共勉!
阶段实操(4):构建一个简单的KV server-网络处理
你好,我是陈天。
经历了基础篇和进阶篇中两讲的构建和优化,到现在,我们的KV server 核心功能已经比较完善了。不知道你有没有注意,之前一直在使用一个神秘的 async-prost 库,我们神奇地完成了TCP frame 的封包和解包。是怎么完成的呢?
async-prost 是我仿照 Jonhoo 的 async-bincode 做的一个处理 protobuf frame 的库,它可以和各种网络协议适配,包括 TCP / WebSocket / HTTP2 等。由于考虑通用性,它的抽象级别比较高,用了大量的泛型参数,主流程如下图所示:
主要的思路就是在序列化数据的时候,添加一个头部来提供 frame 的长度,反序列化的时候,先读出头部,获得长度,再读取相应的数据。感兴趣的同学可以去看代码,这里就不展开了。
今天我们的挑战就是,在上一次完成的 KV server 的基础上,来试着不依赖 async-prost,自己处理封包和解包的逻辑。如果你掌握了这个能力,配合 protobuf,就可以设计出任何可以承载实际业务的协议了。
如何定义协议的 Frame?
protobuf 帮我们解决了协议消息如何定义的问题,然而一个消息和另一个消息之间如何区分,是个伤脑筋的事情。我们需要定义合适的分隔符。
分隔符 + 消息数据,就是一个 Frame。之前在28网络开发 那一讲 简单说过如何界定一个frame。
很多基于 TCP 的协议会使用 \r\n 做分隔符,比如 FTP;也有使用消息长度做分隔符的,比如 gRPC;还有混用两者的,比如 Redis 的 RESP;更复杂的如 HTTP,header 之间使用 \r\n 分隔,header / body 之间使用 \r\n\r\n,header 中会提供 body 的长度等等。
“\r\n” 这样的分隔符,适合协议报文是 ASCII 数据;而通过长度进行分隔,适合协议报文是二进制数据。 我们的 KV Server 承载的 protobuf 是二进制,所以就在 payload 之前放一个长度,来作为 frame 的分隔。
这个长度取什么大小呢?如果使用 2 个字节,那么 payload 最大是 64k;如果使用 4 个字节,payload 可以到 4G。一般的应用取 4 个字节就足够了。如果你想要更灵活些,也可以使用 varint。
tokio 有个 tokio-util 库,已经帮我们处理了和 frame 相关的封包解包的主要需求,包括 LinesDelimited(处理 \r\n 分隔符)和 LengthDelimited(处理长度分隔符)。我们可以使用它的 LengthDelimitedCodec 尝试一下。
首先在 Cargo.toml 里添加依赖:
#![allow(unused)] fn main() { [dev-dependencies] ... tokio-util = { version = "0.6", features = ["codec"]} ... }
然后创建 examples/server_with_codec.rs 文件,添入如下代码:
use anyhow::Result; use futures::prelude::*; use kv2::{CommandRequest, MemTable, Service, ServiceInner}; use prost::Message; use tokio::net::TcpListener; use tokio_util::codec::{Framed, LengthDelimitedCodec}; use tracing::info; #[tokio::main] async fn main() -> Result<()> { tracing_subscriber::fmt::init(); let service: Service = ServiceInner::new(MemTable::new()).into(); let addr = "127.0.0.1:9527"; let listener = TcpListener::bind(addr).await?; info!("Start listening on {}", addr); loop { let (stream, addr) = listener.accept().await?; info!("Client {:?} connected", addr); let svc = service.clone(); tokio::spawn(async move { let mut stream = Framed::new(stream, LengthDelimitedCodec::new()); while let Some(Ok(mut buf)) = stream.next().await { let cmd = CommandRequest::decode(&buf[..]).unwrap(); info!("Got a new command: {:?}", cmd); let res = svc.execute(cmd); buf.clear(); res.encode(&mut buf).unwrap(); stream.send(buf.freeze()).await.unwrap(); } info!("Client {:?} disconnected", addr); }); } }
你可以对比一下它和之前的 examples/server.rs 的差别,主要改动了这一行:
#![allow(unused)] fn main() { // let mut stream = AsyncProstStream::<_, CommandRequest, CommandResponse, _>::from(stream).for_async(); let mut stream = Framed::new(stream, LengthDelimitedCodec::new()); }
完成之后,我们打开一个命令行窗口,运行: RUST_LOG=info cargo run --example server_with_codec --quiet。然后在另一个命令行窗口,运行: RUST_LOG=info cargo run --example client --quiet。此时,服务器和客户端都收到了彼此的请求和响应,并且处理正常。
你这会是不是有点疑惑,为什么客户端没做任何修改也能和服务器通信?那是因为在目前的使用场景下,使用 AsyncProst 的客户端兼容 LengthDelimitedCodec。
如何撰写处理 Frame 的代码?
LengthDelimitedCodec 非常好用,它的代码也并不复杂,非常建议你有空研究一下。既然这一讲主要围绕网络开发展开,那么我们也来尝试一下撰写自己的对 Frame 处理的代码吧。
按照前面分析,我们在 protobuf payload 前加一个 4 字节的长度,这样,对端读取数据时,可以先读 4 字节,然后根据读到的长度,进一步读取满足这个长度的数据,之后就可以用相应的数据结构解包了。
为了更贴近实际, 我们把4字节长度的最高位拿出来作为是否压缩的信号,如果设置了,代表后续的 payload 是 gzip 压缩过的 protobuf,否则直接是 protobuf:
按照惯例,还是先来定义处理这个逻辑的 trait:
#![allow(unused)] fn main() { pub trait FrameCoder where Self: Message + Sized + Default, { /// 把一个 Message encode 成一个 frame fn encode_frame(&self, buf: &mut BytesMut) -> Result<(), KvError>; /// 把一个完整的 frame decode 成一个 Message fn decode_frame(buf: &mut BytesMut) -> Result<Self, KvError>; } }
定义了两个方法:
- encode_frame() 可以把诸如 CommandRequest 这样的消息 封装 成一个 frame,写入传进来的 BytesMut;
- decode_frame() 可以把收到的一个完整的、放在 BytesMut 中的数据, 解封装 成诸如 CommandRequest 这样的消息。
如果要实现这个 trait,Self 需要实现了 prost::Message,大小是固定的,并且实现了 Default(prost 的需求)。
好,我们再写实现代码。首先创建 src/network 目录,并在其下添加两个文件 mod.rs 和 frame.rs。然后在 src/network/mod.rs 里引入 src/network/frame.rs:
#![allow(unused)] fn main() { mod frame; pub use frame::FrameCoder; }
同时在 lib.rs 里引入 network:
#![allow(unused)] fn main() { mod network; pub use network::*; }
因为要处理 gzip 压缩,还需要在 Cargo.toml 中引入 flate2,同时,因为今天这一讲引入了网络相关的操作和数据结构,我们需要把 tokio 从 dev-dependencies 移到 dependencies 里,为简单起见,就用 full features:
#![allow(unused)] fn main() { [dependencies] ... flate2 = "1" # gzip 压缩 ... tokio = { version = "1", features = ["full"] } # 异步网络库 ... }
然后,在 src/network/frame.rs 里添加 trait 和实现 trait 的代码:
#![allow(unused)] fn main() { use std::io::{Read, Write}; use crate::{CommandRequest, CommandResponse, KvError}; use bytes::{Buf, BufMut, BytesMut}; use flate2::{read::GzDecoder, write::GzEncoder, Compression}; use prost::Message; use tokio::io::{AsyncRead, AsyncReadExt}; use tracing::debug; /// 长度整个占用 4 个字节 pub const LEN_LEN: usize = 4; /// 长度占 31 bit,所以最大的 frame 是 2G const MAX_FRAME: usize = 2 * 1024 * 1024 * 1024; /// 如果 payload 超过了 1436 字节,就做压缩 const COMPRESSION_LIMIT: usize = 1436; /// 代表压缩的 bit(整个长度 4 字节的最高位) const COMPRESSION_BIT: usize = 1 << 31; /// 处理 Frame 的 encode/decode pub trait FrameCoder where Self: Message + Sized + Default, { /// 把一个 Message encode 成一个 frame fn encode_frame(&self, buf: &mut BytesMut) -> Result<(), KvError> { let size = self.encoded_len(); if size >= MAX_FRAME { return Err(KvError::FrameError); } // 我们先写入长度,如果需要压缩,再重写压缩后的长度 buf.put_u32(size as _); if size > COMPRESSION_LIMIT { let mut buf1 = Vec::with_capacity(size); self.encode(&mut buf1)?; // BytesMut 支持逻辑上的 split(之后还能 unsplit) // 所以我们先把长度这 4 字节拿走,清除 let payload = buf.split_off(LEN_LEN); buf.clear(); // 处理 gzip 压缩,具体可以参考 flate2 文档 let mut encoder = GzEncoder::new(payload.writer(), Compression::default()); encoder.write_all(&buf1[..])?; // 压缩完成后,从 gzip encoder 中把 BytesMut 再拿回来 let payload = encoder.finish()?.into_inner(); debug!("Encode a frame: size {}({})", size, payload.len()); // 写入压缩后的长度 buf.put_u32((payload.len() | COMPRESSION_BIT) as _); // 把 BytesMut 再合并回来 buf.unsplit(payload); Ok(()) } else { self.encode(buf)?; Ok(()) } } /// 把一个完整的 frame decode 成一个 Message fn decode_frame(buf: &mut BytesMut) -> Result<Self, KvError> { // 先取 4 字节,从中拿出长度和 compression bit let header = buf.get_u32() as usize; let (len, compressed) = decode_header(header); debug!("Got a frame: msg len {}, compressed {}", len, compressed); if compressed { // 解压缩 let mut decoder = GzDecoder::new(&buf[..len]); let mut buf1 = Vec::with_capacity(len * 2); decoder.read_to_end(&mut buf1)?; buf.advance(len); // decode 成相应的消息 Ok(Self::decode(&buf1[..buf1.len()])?) } else { let msg = Self::decode(&buf[..len])?; buf.advance(len); Ok(msg) } } } impl FrameCoder for CommandRequest {} impl FrameCoder for CommandResponse {} fn decode_header(header: usize) -> (usize, bool) { let len = header & !COMPRESSION_BIT; let compressed = header & COMPRESSION_BIT == COMPRESSION_BIT; (len, compressed) } }
这段代码本身并不难理解。我们直接为 FrameCoder 提供了缺省实现,然后 CommandRequest / CommandResponse 做了空实现。其中使用了之前介绍过的 bytes 库里的 BytesMut,以及新引入的 GzEncoder / GzDecoder。你可以按照 20 讲 介绍的阅读源码的方式,了解这几个数据类型的用法。最后还写了个辅助函数 decode_header(),让 decode_frame() 的代码更直观一些。
如果你有些疑惑为什么 COMPRESSION_LIMIT 设成 1436?
这是因为以太网的 MTU 是 1500,除去 IP 头 20 字节、TCP 头 20 字节,还剩 1460;一般 TCP 包会包含一些 Option(比如 timestamp),IP 包也可能包含,所以我们预留 20 字节;再减去 4 字节的长度,就是 1436,不用分片的最大消息长度。如果大于这个,很可能会导致分片,我们就干脆压缩一下。
现在,CommandRequest / CommandResponse 就可以做 frame 级别的处理了,我们写一些测试验证是否工作。还是在 src/network/frame.rs 里,添加测试代码:
#![allow(unused)] fn main() { #[cfg(test)] mod tests { use super::*; use crate::Value; use bytes::Bytes; #[test] fn command_request_encode_decode_should_work() { let mut buf = BytesMut::new(); let cmd = CommandRequest::new_hdel("t1", "k1"); cmd.encode_frame(&mut buf).unwrap(); // 最高位没设置 assert_eq!(is_compressed(&buf), false); let cmd1 = CommandRequest::decode_frame(&mut buf).unwrap(); assert_eq!(cmd, cmd1); } #[test] fn command_response_encode_decode_should_work() { let mut buf = BytesMut::new(); let values: Vec<Value> = vec![1.into(), "hello".into(), b"data".into()]; let res: CommandResponse = values.into(); res.encode_frame(&mut buf).unwrap(); // 最高位没设置 assert_eq!(is_compressed(&buf), false); let res1 = CommandResponse::decode_frame(&mut buf).unwrap(); assert_eq!(res, res1); } #[test] fn command_response_compressed_encode_decode_should_work() { let mut buf = BytesMut::new(); let value: Value = Bytes::from(vec![0u8; COMPRESSION_LIMIT + 1]).into(); let res: CommandResponse = value.into(); res.encode_frame(&mut buf).unwrap(); // 最高位设置了 assert_eq!(is_compressed(&buf), true); let res1 = CommandResponse::decode_frame(&mut buf).unwrap(); assert_eq!(res, res1); } fn is_compressed(data: &[u8]) -> bool { if let &[v] = &data[..1] { v >> 7 == 1 } else { false } } } }
这个测试代码里面有从 [u8; N] 到 Value( b"data".into()) 以及从 Bytes 到 Value 的转换,所以我们需要在 src/pb/mod.rs 里添加 From trait 的相应实现:
#![allow(unused)] fn main() { impl<const N: usize> From<&[u8; N]> for Value { fn from(buf: &[u8; N]) -> Self { Bytes::copy_from_slice(&buf[..]).into() } } impl From<Bytes> for Value { fn from(buf: Bytes) -> Self { Self { value: Some(value::Value::Binary(buf)), } } } }
运行 cargo test ,所有测试都可以通过。
到这里,我们就完成了 Frame 的序列化(encode_frame)和反序列化(decode_frame),并且用测试确保它的正确性。 做网络开发的时候,要尽可能把实现逻辑和 IO 分离,这样有助于可测性以及应对未来 IO 层的变更。目前,这个代码没有触及任何和 socket IO 相关的内容,只是纯逻辑,接下来我们要将它和我们用于处理服务器客户端的 TcpStream 联系起来。
在进一步写网络相关的代码前,还有一个问题需要解决:decode_frame() 函数使用的 BytesMut,是如何从 socket 里拿出来的?显然,先读 4 个字节,取出长度 N,然后再读 N 个字节。这个细节和 frame 关系很大,所以还需要在 src/network/frame.rs 里写个辅助函数 read_frame():
#![allow(unused)] fn main() { /// 从 stream 中读取一个完整的 frame pub async fn read_frame<S>(stream: &mut S, buf: &mut BytesMut) -> Result<(), KvError> where S: AsyncRead + Unpin + Send, { let header = stream.read_u32().await? as usize; let (len, _compressed) = decode_header(header); // 如果没有这么大的内存,就分配至少一个 frame 的内存,保证它可用 buf.reserve(LEN_LEN + len); buf.put_u32(header as _); // advance_mut 是 unsafe 的原因是,从当前位置 pos 到 pos + len, // 这段内存目前没有初始化。我们就是为了 reserve 这段内存,然后从 stream // 里读取,读取完,它就是初始化的。所以,我们这么用是安全的 unsafe { buf.advance_mut(len) }; stream.read_exact(&mut buf[LEN_LEN..]).await?; Ok(()) } }
在写 read_frame() 时,我们不希望它只能被用于 TcpStream,这样太不灵活, 所以用了泛型参数 S,要求传入的 S 必须满足 AsyncRead + Unpin + Send。我们来看看这3个约束。
AsyncRead 是 tokio 下的一个 trait,用于做异步读取,它有一个方法 poll_read():
#![allow(unused)] fn main() { pub trait AsyncRead { fn poll_read( self: Pin<&mut Self>, cx: &mut Context<'_>, buf: &mut ReadBuf<'_> ) -> Poll<Result<()>>; } }
一旦某个数据结构实现了 AsyncRead,它就可以使用 AsyncReadExt 提供的多达 29 个辅助方法。这是因为任何实现了 AsyncRead 的数据结构,都自动实现了 AsyncReadExt:
#![allow(unused)] fn main() { impl<R: AsyncRead + ?Sized> AsyncReadExt for R {} }
我们虽然还没有正式学怎么做异步处理,但是之前已经看到了很多 async/await 的代码。
异步处理,目前你可以把它想象成一个内部有个状态机的数据结构,异步运行时根据需要不断地对其做 poll 操作,直到它返回 Poll::Ready,说明得到了处理结果;如果它返回 Poll::Pending,说明目前还无法继续,异步运行时会将其挂起,等下次某个事件将这个任务唤醒。
对于 Socket 来说,读取 socket 就是一个不断 poll_read() 的过程,直到读到了满足 ReadBuf 需要的内容。
至于 Send 约束,很好理解,S 需要能在不同线程间移动所有权。对于 Unpin 约束,未来讲 Future 的时候再具体说。现在你就权且记住,如果编译器抱怨一个泛型参数 “cannot be unpinned” ,一般来说,这个泛型参数需要加 Unpin 的约束。你可以试着把 Unpin 去掉,看看编译器的报错。
好,既然又写了一些代码,自然需为其撰写相应的测试。但是,要测 read_frame() 函数,需要一个支持 AsyncRead 的数据结构,虽然 TcpStream 支持它,但是我们不应该在单元测试中引入太过复杂的行为。 为了测试 read_frame() 而建立 TCP 连接,显然没有必要。怎么办?
在 第 25 讲,我们聊过测试代码和产品代码同等的重要性,所以,在开发中,也要为测试代码创建合适的生态环境,让测试简洁、可读性强。那这里,我们就创建一个简单的数据结构,使其实现 AsyncRead,这样就可以“单元”测试 read_frame() 了。
在 src/network/frame.rs 里的 mod tests 下加入:
#![allow(unused)] fn main() { #[cfg(test)] mod tests { struct DummyStream { buf: BytesMut, } impl AsyncRead for DummyStream { fn poll_read( self: std::pin::Pin<&mut Self>, _cx: &mut std::task::Context<'_>, buf: &mut tokio::io::ReadBuf<'_>, ) -> std::task::Poll<std::io::Result<()>> { // 看看 ReadBuf 需要多大的数据 let len = buf.capacity(); // split 出这么大的数据 let data = self.get_mut().buf.split_to(len); // 拷贝给 ReadBuf buf.put_slice(&data); // 直接完工 std::task::Poll::Ready(Ok(())) } } } }
因为只需要保证 AsyncRead 接口的正确性,所以不需要太复杂的逻辑,我们就放一个 buffer,poll_read() 需要读多大的数据,我们就给多大的数据。有了这个 DummyStream,就可以测试 read_frame() 了:
#![allow(unused)] fn main() { #[tokio::test] async fn read_frame_should_work() { let mut buf = BytesMut::new(); let cmd = CommandRequest::new_hdel("t1", "k1"); cmd.encode_frame(&mut buf).unwrap(); let mut stream = DummyStream { buf }; let mut data = BytesMut::new(); read_frame(&mut stream, &mut data).await.unwrap(); let cmd1 = CommandRequest::decode_frame(&mut data).unwrap(); assert_eq!(cmd, cmd1); } }
运行 “cargo test”,测试通过。如果你的代码无法编译,可以看看编译错误,是不是缺了一些 use 语句来把某些数据结构和 trait 引入。你也可以对照 GitHub 上的代码修改。
让网络层可以像 AsyncProst 那样方便使用
现在,我们的 frame 已经可以正常工作了。接下来要构思一下,服务端和客户端该如何封装。
对于服务器,我们期望可以对 accept 下来的 TcpStream 提供一个 process() 方法,处理协议的细节:
#[tokio::main] async fn main() -> Result<()> { tracing_subscriber::fmt::init(); let addr = "127.0.0.1:9527"; let service: Service = ServiceInner::new(MemTable::new()).into(); let listener = TcpListener::bind(addr).await?; info!("Start listening on {}", addr); loop { let (stream, addr) = listener.accept().await?; info!("Client {:?} connected", addr); let stream = ProstServerStream::new(stream, service.clone()); tokio::spawn(async move { stream.process().await }); } }
这个 process() 方法,实际上就是对 examples/server.rs 中 tokio::spawn 里的 while loop 的封装:
#![allow(unused)] fn main() { while let Some(Ok(cmd)) = stream.next().await { info!("Got a new command: {:?}", cmd); let res = svc.execute(cmd); stream.send(res).await.unwrap(); } }
对客户端,我们也希望可以直接 execute() 一个命令,就能得到结果:
#[tokio::main] async fn main() -> Result<()> { tracing_subscriber::fmt::init(); let addr = "127.0.0.1:9527"; // 连接服务器 let stream = TcpStream::connect(addr).await?; let mut client = ProstClientStream::new(stream); // 生成一个 HSET 命令 let cmd = CommandRequest::new_hset("table1", "hello", "world".to_string().into()); // 发送 HSET 命令 let data = client.execute(cmd).await?; info!("Got response {:?}", data); Ok(()) }
这个 execute(),实际上就是对 examples/client.rs 中发送和接收代码的封装:
#![allow(unused)] fn main() { client.send(cmd).await?; if let Some(Ok(data)) = client.next().await { info!("Got response {:?}", data); } }
这样的代码,看起来很简洁,维护起来也很方便。
好,先看服务器处理一个 TcpStream 的数据结构,它需要包含 TcpStream,还有我们之前创建的用于处理客户端命令的 Service。所以,让服务器处理 TcpStream 的结构包含这两部分:
#![allow(unused)] fn main() { pub struct ProstServerStream<S> { inner: S, service: Service, } }
而客户端处理 TcpStream 的结构就只需要包含 TcpStream:
#![allow(unused)] fn main() { pub struct ProstClientStream<S> { inner: S, } }
这里,依旧使用了泛型参数 S。未来,如果要支持 WebSocket,或者在 TCP 之上支持 TLS,它都可以让我们无需改变这一层的代码。
接下来就是具体的实现。有了 frame 的封装,服务器的 process() 方法和客户端的 execute() 方法都很容易实现。我们直接在 src/network/mod.rs 里添加完整代码:
#![allow(unused)] fn main() { mod frame; use bytes::BytesMut; pub use frame::{read_frame, FrameCoder}; use tokio::io::{AsyncRead, AsyncWrite, AsyncWriteExt}; use tracing::info; use crate::{CommandRequest, CommandResponse, KvError, Service}; /// 处理服务器端的某个 accept 下来的 socket 的读写 pub struct ProstServerStream<S> { inner: S, service: Service, } /// 处理客户端 socket 的读写 pub struct ProstClientStream<S> { inner: S, } impl<S> ProstServerStream<S> where S: AsyncRead + AsyncWrite + Unpin + Send, { pub fn new(stream: S, service: Service) -> Self { Self { inner: stream, service, } } pub async fn process(mut self) -> Result<(), KvError> { while let Ok(cmd) = self.recv().await { info!("Got a new command: {:?}", cmd); let res = self.service.execute(cmd); self.send(res).await?; } // info!("Client {:?} disconnected", self.addr); Ok(()) } async fn send(&mut self, msg: CommandResponse) -> Result<(), KvError> { let mut buf = BytesMut::new(); msg.encode_frame(&mut buf)?; let encoded = buf.freeze(); self.inner.write_all(&encoded[..]).await?; Ok(()) } async fn recv(&mut self) -> Result<CommandRequest, KvError> { let mut buf = BytesMut::new(); let stream = &mut self.inner; read_frame(stream, &mut buf).await?; CommandRequest::decode_frame(&mut buf) } } impl<S> ProstClientStream<S> where S: AsyncRead + AsyncWrite + Unpin + Send, { pub fn new(stream: S) -> Self { Self { inner: stream } } pub async fn execute(&mut self, cmd: CommandRequest) -> Result<CommandResponse, KvError> { self.send(cmd).await?; Ok(self.recv().await?) } async fn send(&mut self, msg: CommandRequest) -> Result<(), KvError> { let mut buf = BytesMut::new(); msg.encode_frame(&mut buf)?; let encoded = buf.freeze(); self.inner.write_all(&encoded[..]).await?; Ok(()) } async fn recv(&mut self) -> Result<CommandResponse, KvError> { let mut buf = BytesMut::new(); let stream = &mut self.inner; read_frame(stream, &mut buf).await?; CommandResponse::decode_frame(&mut buf) } } }
这段代码不难阅读,基本上和 frame 的测试代码大同小异。
当然了,我们还是需要写段代码来测试客户端和服务器交互的整个流程:
#![allow(unused)] fn main() { #[cfg(test)] mod tests { use anyhow::Result; use bytes::Bytes; use std::net::SocketAddr; use tokio::net::{TcpListener, TcpStream}; use crate::{assert_res_ok, MemTable, ServiceInner, Value}; use super::*; #[tokio::test] async fn client_server_basic_communication_should_work() -> anyhow::Result<()> { let addr = start_server().await?; let stream = TcpStream::connect(addr).await?; let mut client = ProstClientStream::new(stream); // 发送 HSET,等待回应 let cmd = CommandRequest::new_hset("t1", "k1", "v1".into()); let res = client.execute(cmd).await.unwrap(); // 第一次 HSET 服务器应该返回 None assert_res_ok(res, &[Value::default()], &[]); // 再发一个 HSET let cmd = CommandRequest::new_hget("t1", "k1"); let res = client.execute(cmd).await?; // 服务器应该返回上一次的结果 assert_res_ok(res, &["v1".into()], &[]); Ok(()) } #[tokio::test] async fn client_server_compression_should_work() -> anyhow::Result<()> { let addr = start_server().await?; let stream = TcpStream::connect(addr).await?; let mut client = ProstClientStream::new(stream); let v: Value = Bytes::from(vec![0u8; 16384]).into(); let cmd = CommandRequest::new_hset("t2", "k2", v.clone().into()); let res = client.execute(cmd).await?; assert_res_ok(res, &[Value::default()], &[]); let cmd = CommandRequest::new_hget("t2", "k2"); let res = client.execute(cmd).await?; assert_res_ok(res, &[v.into()], &[]); Ok(()) } async fn start_server() -> Result<SocketAddr> { let listener = TcpListener::bind("127.0.0.1:0").await.unwrap(); let addr = listener.local_addr().unwrap(); tokio::spawn(async move { loop { let (stream, _) = listener.accept().await.unwrap(); let service: Service = ServiceInner::new(MemTable::new()).into(); let server = ProstServerStream::new(stream, service); tokio::spawn(server.process()); } }); Ok(addr) } } }
测试代码基本上是之前 examples 下的 server.rs/client.rs 中的内容。我们测试了不做压缩和做压缩的两种情况。运行 cargo test ,应该所有测试都通过了。
正式创建 kv-server 和 kv-client
我们之前写了很多代码,真正可运行的 server/client 都是 examples 下的代码。现在我们终于要正式创建 kv-server / kv-client 了。
首先在 Cargo.toml 中,加入两个可执行文件:kvs(kv-server)和 kvc(kv-client)。还需要把一些依赖移动到 dependencies 下。修改之后,Cargo.toml 长这个样子:
#![allow(unused)] fn main() { [package] name = "kv2" version = "0.1.0" edition = "2018" [[bin]] name = "kvs" path = "src/server.rs" [[bin]] name = "kvc" path = "src/client.rs" [dependencies] anyhow = "1" # 错误处理 bytes = "1" # 高效处理网络 buffer 的库 dashmap = "4" # 并发 HashMap flate2 = "1" # gzip 压缩 http = "0.2" # 我们使用 HTTP status code 所以引入这个类型库 prost = "0.8" # 处理 protobuf 的代码 sled = "0.34" # sled db thiserror = "1" # 错误定义和处理 tokio = { version = "1", features = ["full" ] } # 异步网络库 tracing = "0.1" # 日志处理 tracing-subscriber = "0.2" # 日志处理 [dev-dependencies] async-prost = "0.2.1" # 支持把 protobuf 封装成 TCP frame futures = "0.3" # 提供 Stream trait tempfile = "3" # 处理临时目录和临时文件 tokio-util = { version = "0.6", features = ["codec"]} [build-dependencies] prost-build = "0.8" # 编译 protobuf }
然后,创建 src/client.rs 和 src/server.rs,分别写入下面的代码。src/client.rs:
use anyhow::Result; use kv2::{CommandRequest, ProstClientStream}; use tokio::net::TcpStream; use tracing::info; #[tokio::main] async fn main() -> Result<()> { tracing_subscriber::fmt::init(); let addr = "127.0.0.1:9527"; // 连接服务器 let stream = TcpStream::connect(addr).await?; let mut client = ProstClientStream::new(stream); // 生成一个 HSET 命令 let cmd = CommandRequest::new_hset("table1", "hello", "world".to_string().into()); // 发送 HSET 命令 let data = client.execute(cmd).await?; info!("Got response {:?}", data); Ok(()) }
src/server.rs:
use anyhow::Result; use kv2::{MemTable, ProstServerStream, Service, ServiceInner}; use tokio::net::TcpListener; use tracing::info; #[tokio::main] async fn main() -> Result<()> { tracing_subscriber::fmt::init(); let addr = "127.0.0.1:9527"; let service: Service = ServiceInner::new(MemTable::new()).into(); let listener = TcpListener::bind(addr).await?; info!("Start listening on {}", addr); loop { let (stream, addr) = listener.accept().await?; info!("Client {:?} connected", addr); let stream = ProstServerStream::new(stream, service.clone()); tokio::spawn(async move { stream.process().await }); } }
这和之前的 client / server 的代码几乎一致,不同的是,我们使用了自己撰写的 frame 处理方法。
完成之后,我们可以打开一个命令行窗口,运行: RUST_LOG=info cargo run --bin kvs --quiet。然后在另一个命令行窗口,运行: RUST_LOG=info cargo run --bin kvc --quiet。此时,服务器和客户端都收到了彼此的请求和响应,并且处理正常。现在,我们的 KV server 越来越像回事了!
小结
网络开发是 Rust 下一个很重要的应用场景。tokio 为我们提供了很棒的异步网络开发的支持。
在开发网络协议时,你要确定你的 frame 如何封装,一般来说,长度 + protobuf 足以应付绝大多数复杂的协议需求。这一讲我们虽然详细介绍了自己该如何处理用长度封装 frame 的方法,其实 tokio-util 提供了 LengthDelimitedCodec,可以完成今天关于 frame 部分的处理。如果你自己撰写网络程序,可以直接使用它。
在网络开发的时候,如何做单元测试是一大痛点,我们可以根据其实现的接口,围绕着接口来构建测试数据结构,比如 TcpStream 实现了 AsycnRead / AsyncWrite。考虑简洁和可读,为了测试read_frame() ,我们构建了 DummyStream 来协助测试。你也可以用类似的方式处理你所做项目的测试需求。
结构良好架构清晰的代码,一定是容易测试的代码,纵观整个项目,从 CommandService trait 和 Storage trait 的测试,一路到现在网络层的测试。如果使用 tarpaulin 来看测试覆盖率,你会发现,这个项目目前已经有 89%了,如果不算 src/server.rs 和 src/client.rs 的话,有接近 92% 的测试覆盖率。即便在生产环境的代码里,这也算是很高质量的测试覆盖率了。
INFO cargo_tarpaulin::report: Coverage Results:
|| Tested/Total Lines:
|| src/client.rs: 0/9 +0.00%
|| src/network/frame.rs: 80/82 +0.00%
|| src/network/mod.rs: 65/66 +4.66%
|| src/pb/mod.rs: 54/75 +0.00%
|| src/server.rs: 0/11 +0.00%
|| src/service/command_service.rs: 120/129 +0.00%
|| src/service/mod.rs: 79/84 +0.00%
|| src/storage/memory.rs: 34/37 +0.00%
|| src/storage/mod.rs: 58/58 +0.00%
|| src/storage/sleddb.rs: 40/43 +0.00%
||
89.23% coverage, 530/594 lines covered
思考题
- 在设计 frame 的时候,如果我们的压缩方法不止 gzip 一种,而是服务器或客户端都会根据各自的情况,在需要的时候做某种算法的压缩。假设服务器和客户端都支持 gzip、lz4 和 zstd 这三种压缩算法。那么 frame 该如何设计呢?需要用几个 bit 来存放压缩算法的信息?
- 目前我们的 client 只适合测试,你可以将其修改成一个完整的命令行程序么?小提示,可以使用 clap 或 structopt,用户可以输入不同的命令;或者做一个交互式的命令行,使用 shellfish 或 rustyline,就像 redis-cli 那样。
- 试着使用 LengthDelimitedCodec 来重写 frame 这一层。
欢迎在留言区分享你的思考,感谢你的收听。你已经完成Rust学习的第36次打卡啦。
延伸阅读
tarpaulin 是 Rust 下做测试覆盖率的工具。因为使用了操作系统和 CPU 的特殊指令追踪代码的执行,所以它目前只支持 x86_64 / Linux。测试覆盖率一般在 CI 中使用,所以有 Linux 的支持也足够了。
一般来说,我们在生产环境中运行的代码,都要求至少有 80% 以上的测试覆盖率。为项目构建足够好的测试覆盖率并不容易,因为这首先意味着写出来的代码要容易测试。所以, 对于新的项目,最好一开始就在 CI 中为测试覆盖率设置一个门槛,这样可以倒逼着大家保证单元测试的数量。同时,单元测试又会倒逼代码要有良好的结构和良好的接口,否则不容易测试。
如果觉得有收获,也欢迎你分享给身边的朋友,邀他一起讨论。我们下节课见~
阶段实操(5):构建一个简单的KV server-网络安全
你好,我是陈天。
上一讲我们完成了KV server整个网络部分的构建。而安全是和网络密不可分的组成部分,在构建应用程序的时候,一定要把网络安全也考虑进去。当然,如果不考虑极致的性能,我们可以使用诸如 gRPC 这样的系统,在提供良好性能的基础上,它还通过 TLS 保证了安全性。
那么,当我们的应用架构在 TCP 上时,如何使用 TLS 来保证客户端和服务器间的安全性呢?
生成 x509 证书
想要使用 TLS,我们首先需要 x509 证书。TLS 需要 x509 证书让客户端验证服务器是否是一个受信的服务器,甚至服务器验证客户端,确认对方是一个受信的客户端。
为了测试方便,我们要有能力生成自己的 CA 证书、服务端证书,甚至客户端证书。证书生成的细节今天就不详细介绍了,我之前做了一个叫 certify 的库,可以用来生成各种证书。我们可以在 Cargo.toml 里加入这个库:
#![allow(unused)] fn main() { [dev-dependencies] ... certify = "0.3" ... }
然后在根目录下创建 fixtures 目录存放证书,再创建 examples/gen_cert.rs 文件,添入如下代码:
use anyhow::Result; use certify::{generate_ca, generate_cert, load_ca, CertType, CA}; use tokio::fs; struct CertPem { cert_type: CertType, cert: String, key: String, } #[tokio::main] async fn main() -> Result<()> { let pem = create_ca()?; gen_files(&pem).await?; let ca = load_ca(&pem.cert, &pem.key)?; let pem = create_cert(&ca, &["kvserver.acme.inc"], "Acme KV server", false)?; gen_files(&pem).await?; let pem = create_cert(&ca, &[], "awesome-device-id", true)?; gen_files(&pem).await?; Ok(()) } fn create_ca() -> Result<CertPem> { let (cert, key) = generate_ca( &["acme.inc"], "CN", "Acme Inc.", "Acme CA", None, Some(10 * 365), )?; Ok(CertPem { cert_type: CertType::CA, cert, key, }) } fn create_cert(ca: &CA, domains: &[&str], cn: &str, is_client: bool) -> Result<CertPem> { let (days, cert_type) = if is_client { (Some(365), CertType::Client) } else { (Some(5 * 365), CertType::Server) }; let (cert, key) = generate_cert(ca, domains, "CN", "Acme Inc.", cn, None, is_client, days)?; Ok(CertPem { cert_type, cert, key, }) } async fn gen_files(pem: &CertPem) -> Result<()> { let name = match pem.cert_type { CertType::Client => "client", CertType::Server => "server", CertType::CA => "ca", }; fs::write(format!("fixtures/{}.cert", name), pem.cert.as_bytes()).await?; fs::write(format!("fixtures/{}.key", name), pem.key.as_bytes()).await?; Ok(()) }
这个代码很简单,它先生成了一个 CA 证书,然后再生成服务器和客户端证书,全部存入刚创建的 fixtures 目录下。你需要 cargo run --examples gen_cert 运行一下这个命令,待会我们会在测试中用到这些证书和密钥。
在 KV server 中使用 TLS
TLS 是目前最主要的应用层安全协议,被广泛用于保护架构在 TCP 之上的,比如 MySQL、HTTP 等各种协议。一个网络应用,即便是在内网使用,如果没有安全协议来保护,都是很危险的。
下图展示了客户端和服务器进行 TLS 握手的过程,来源 wikimedia:
{kind=link}
对于 KV server 来说,使用 TLS 之后,整个协议的数据封装如下图所示:
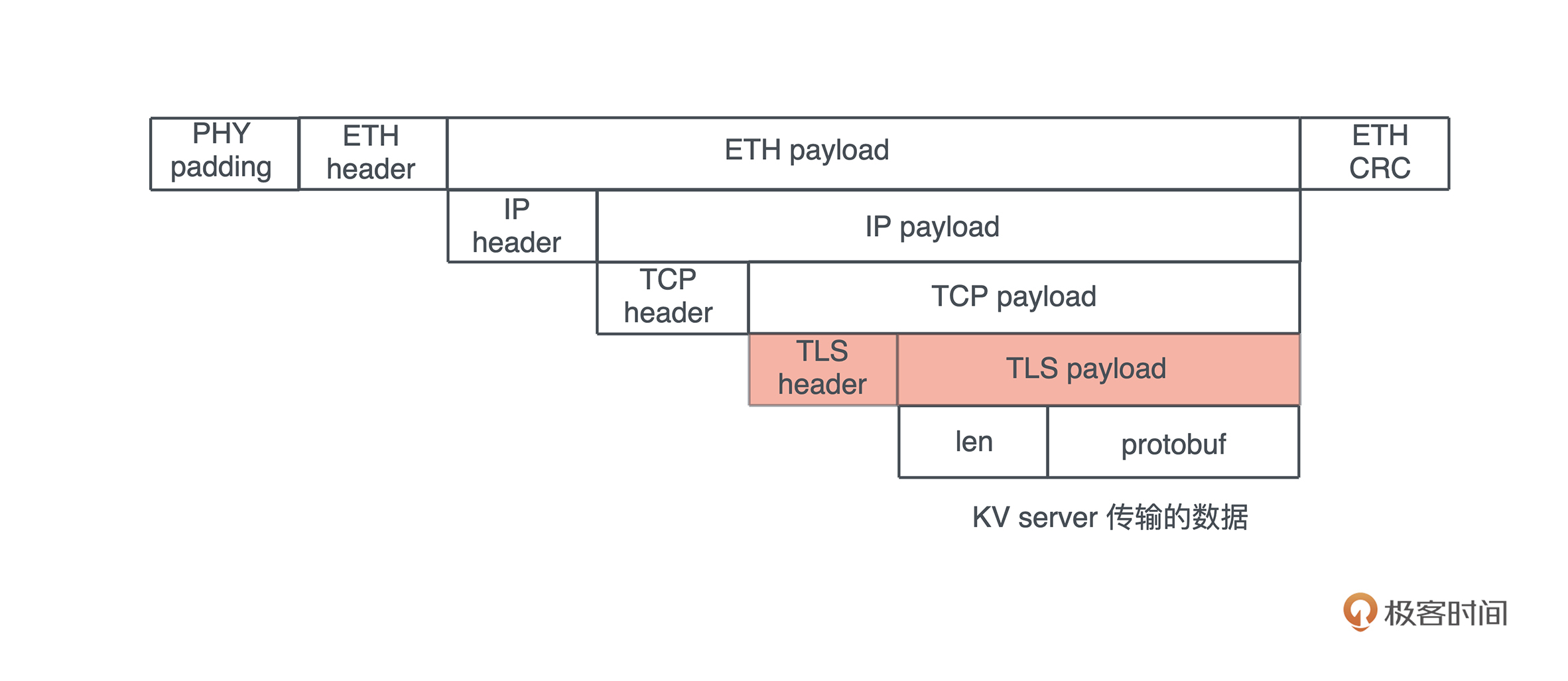
所以今天要做的就是在上一讲的网络处理的基础上,添加 TLS 支持,使得 KV server 的客户端服务器之间的通讯被严格保护起来,确保最大程度的安全,免遭第三方的偷窥、篡改以及仿造。
好,接下来我们看看 TLS 怎么实现。
估计很多人一听 TLS 或者 SSL,就头皮发麻,因为之前跟 openssl 打交道有过很多不好的经历。openssl 的代码库太庞杂,API 不友好,编译链接都很费劲。
不过,在 Rust 下使用 TLS 的体验还是很不错的,Rust 对 openssl 有很不错的 封装,也有不依赖 openssl 用 Rust 撰写的 rustls。tokio 进一步提供了符合 tokio 生态圈的 tls 支持,有 openssl 版本和 rustls 版本可选。
我们今天就用 tokio-rustls 来撰写 TLS 的支持。相信你在实现过程中可以看到,在应用程序中加入 TLS 协议来保护网络层,是多么轻松的一件事情。
先在 Cargo.toml 中添加 tokio-rustls:
#![allow(unused)] fn main() { [dependencies] ... tokio-rustls = "0.22" ... }
然后创建 src/network/tls.rs,撰写如下代码(记得在 src/network/mod.rs 中引入这个文件哦):
#![allow(unused)] fn main() { use std::io::Cursor; use std::sync::Arc; use tokio::io::{AsyncRead, AsyncWrite}; use tokio_rustls::rustls::{internal::pemfile, Certificate, ClientConfig, ServerConfig}; use tokio_rustls::rustls::{AllowAnyAuthenticatedClient, NoClientAuth, PrivateKey, RootCertStore}; use tokio_rustls::webpki::DNSNameRef; use tokio_rustls::TlsConnector; use tokio_rustls::{ client::TlsStream as ClientTlsStream, server::TlsStream as ServerTlsStream, TlsAcceptor, }; use crate::KvError; /// KV Server 自己的 ALPN (Application-Layer Protocol Negotiation) const ALPN_KV: &str = "kv"; /// 存放 TLS ServerConfig 并提供方法 accept 把底层的协议转换成 TLS #[derive(Clone)] pub struct TlsServerAcceptor { inner: Arc<ServerConfig>, } /// 存放 TLS Client 并提供方法 connect 把底层的协议转换成 TLS #[derive(Clone)] pub struct TlsClientConnector { pub config: Arc<ClientConfig>, pub domain: Arc<String>, } impl TlsClientConnector { /// 加载 client cert / CA cert,生成 ClientConfig pub fn new( domain: impl Into<String>, identity: Option<(&str, &str)>, server_ca: Option<&str>, ) -> Result<Self, KvError> { let mut config = ClientConfig::new(); // 如果有客户端证书,加载之 if let Some((cert, key)) = identity { let certs = load_certs(cert)?; let key = load_key(key)?; config.set_single_client_cert(certs, key)?; } // 加载本地信任的根证书链 config.root_store = match rustls_native_certs::load_native_certs() { Ok(store) | Err((Some(store), _)) => store, Err((None, error)) => return Err(error.into()), }; // 如果有签署服务器的 CA 证书,则加载它,这样服务器证书不在根证书链 // 但是这个 CA 证书能验证它,也可以 if let Some(cert) = server_ca { let mut buf = Cursor::new(cert); config.root_store.add_pem_file(&mut buf).unwrap(); } Ok(Self { config: Arc::new(config), domain: Arc::new(domain.into()), }) } /// 触发 TLS 协议,把底层的 stream 转换成 TLS stream pub async fn connect<S>(&self, stream: S) -> Result<ClientTlsStream<S>, KvError> where S: AsyncRead + AsyncWrite + Unpin + Send, { let dns = DNSNameRef::try_from_ascii_str(self.domain.as_str()) .map_err(|_| KvError::Internal("Invalid DNS name".into()))?; let stream = TlsConnector::from(self.config.clone()) .connect(dns, stream) .await?; Ok(stream) } } impl TlsServerAcceptor { /// 加载 server cert / CA cert,生成 ServerConfig pub fn new(cert: &str, key: &str, client_ca: Option<&str>) -> Result<Self, KvError> { let certs = load_certs(cert)?; let key = load_key(key)?; let mut config = match client_ca { None => ServerConfig::new(NoClientAuth::new()), Some(cert) => { // 如果客户端证书是某个 CA 证书签发的,则把这个 CA 证书加载到信任链中 let mut cert = Cursor::new(cert); let mut client_root_cert_store = RootCertStore::empty(); client_root_cert_store .add_pem_file(&mut cert) .map_err(|_| KvError::CertifcateParseError("CA", "cert"))?; let client_auth = AllowAnyAuthenticatedClient::new(client_root_cert_store); ServerConfig::new(client_auth) } }; // 加载服务器证书 config .set_single_cert(certs, key) .map_err(|_| KvError::CertifcateParseError("server", "cert"))?; config.set_protocols(&[Vec::from(&ALPN_KV[..])]); Ok(Self { inner: Arc::new(config), }) } /// 触发 TLS 协议,把底层的 stream 转换成 TLS stream pub async fn accept<S>(&self, stream: S) -> Result<ServerTlsStream<S>, KvError> where S: AsyncRead + AsyncWrite + Unpin + Send, { let acceptor = TlsAcceptor::from(self.inner.clone()); Ok(acceptor.accept(stream).await?) } } fn load_certs(cert: &str) -> Result<Vec<Certificate>, KvError> { let mut cert = Cursor::new(cert); pemfile::certs(&mut cert).map_err(|_| KvError::CertifcateParseError("server", "cert")) } fn load_key(key: &str) -> Result<PrivateKey, KvError> { let mut cursor = Cursor::new(key); // 先尝试用 PKCS8 加载私钥 if let Ok(mut keys) = pemfile::pkcs8_private_keys(&mut cursor) { if !keys.is_empty() { return Ok(keys.remove(0)); } } // 再尝试加载 RSA key cursor.set_position(0); if let Ok(mut keys) = pemfile::rsa_private_keys(&mut cursor) { if !keys.is_empty() { return Ok(keys.remove(0)); } } // 不支持的私钥类型 Err(KvError::CertifcateParseError("private", "key")) } }
这个代码创建了两个数据结构 TlsServerAcceptor / TlsClientConnector。虽然它有 100 多行,但主要的工作其实就是 根据提供的证书,来生成 tokio-tls 需要的 ServerConfig / ClientConfig。
因为 TLS 需要验证证书的 CA,所以还需要加载 CA 证书。虽然平时在做 Web 开发时,我们都只使用服务器证书,但其实 TLS 支持双向验证,服务器也可以验证客户端的证书是否是它认识的 CA 签发的。
处理完 config 后,这段代码的核心逻辑其实就是客户端的 connect() 方法和服务器的 accept() 方法,它们都接受一个满足 AsyncRead + AsyncWrite + Unpin + Send 的 stream。类似上一讲,我们不希望 TLS 代码只能接受 TcpStream,所以这里提供了一个泛型参数 S:
#![allow(unused)] fn main() { /// 触发 TLS 协议,把底层的 stream 转换成 TLS stream pub async fn connect<S>(&self, stream: S) -> Result<ClientTlsStream<S>, KvError> where S: AsyncRead + AsyncWrite + Unpin + Send, { let dns = DNSNameRef::try_from_ascii_str(self.domain.as_str()) .map_err(|_| KvError::Internal("Invalid DNS name".into()))?; let stream = TlsConnector::from(self.config.clone()) .connect(dns, stream) .await?; Ok(stream) } /// 触发 TLS 协议,把底层的 stream 转换成 TLS stream pub async fn accept<S>(&self, stream: S) -> Result<ServerTlsStream<S>, KvError> where S: AsyncRead + AsyncWrite + Unpin + Send, { let acceptor = TlsAcceptor::from(self.inner.clone()); Ok(acceptor.accept(stream).await?) } }
在使用 TlsConnector 或者 TlsAcceptor 处理完 connect/accept 后,我们得到了一个 TlsStream,它也满足 AsyncRead + AsyncWrite + Unpin + Send,后续的操作就可以在其上完成了。百来行代码就搞定了 TLS,是不是很轻松?
我们来顺着往下写段测试:
#![allow(unused)] fn main() { #[cfg(test)] mod tests { use std::net::SocketAddr; use super::*; use anyhow::Result; use tokio::{ io::{AsyncReadExt, AsyncWriteExt}, net::{TcpListener, TcpStream}, }; const CA_CERT: &str = include_str!("../../fixtures/ca.cert"); const CLIENT_CERT: &str = include_str!("../../fixtures/client.cert"); const CLIENT_KEY: &str = include_str!("../../fixtures/client.key"); const SERVER_CERT: &str = include_str!("../../fixtures/server.cert"); const SERVER_KEY: &str = include_str!("../../fixtures/server.key"); #[tokio::test] async fn tls_should_work() -> Result<()> { let ca = Some(CA_CERT); let addr = start_server(None).await?; let connector = TlsClientConnector::new("kvserver.acme.inc", None, ca)?; let stream = TcpStream::connect(addr).await?; let mut stream = connector.connect(stream).await?; stream.write_all(b"hello world!").await?; let mut buf = [0; 12]; stream.read_exact(&mut buf).await?; assert_eq!(&buf, b"hello world!"); Ok(()) } #[tokio::test] async fn tls_with_client_cert_should_work() -> Result<()> { let client_identity = Some((CLIENT_CERT, CLIENT_KEY)); let ca = Some(CA_CERT); let addr = start_server(ca.clone()).await?; let connector = TlsClientConnector::new("kvserver.acme.inc", client_identity, ca)?; let stream = TcpStream::connect(addr).await?; let mut stream = connector.connect(stream).await?; stream.write_all(b"hello world!").await?; let mut buf = [0; 12]; stream.read_exact(&mut buf).await?; assert_eq!(&buf, b"hello world!"); Ok(()) } #[tokio::test] async fn tls_with_bad_domain_should_not_work() -> Result<()> { let addr = start_server(None).await?; let connector = TlsClientConnector::new("kvserver1.acme.inc", None, Some(CA_CERT))?; let stream = TcpStream::connect(addr).await?; let result = connector.connect(stream).await; assert!(result.is_err()); Ok(()) } async fn start_server(ca: Option<&str>) -> Result<SocketAddr> { let acceptor = TlsServerAcceptor::new(SERVER_CERT, SERVER_KEY, ca)?; let echo = TcpListener::bind("127.0.0.1:0").await.unwrap(); let addr = echo.local_addr().unwrap(); tokio::spawn(async move { let (stream, _) = echo.accept().await.unwrap(); let mut stream = acceptor.accept(stream).await.unwrap(); let mut buf = [0; 12]; stream.read_exact(&mut buf).await.unwrap(); stream.write_all(&buf).await.unwrap(); }); Ok(addr) } } }
这段测试代码使用了 include_str! 宏,在编译期把文件加载成字符串放在 RODATA 段。我们测试了三种情况:标准的 TLS 连接、带有客户端证书的 TLS 连接,以及客户端提供了错的域名的情况。运行 cargo test ,所有测试都能通过。
让 KV client/server 支持 TLS
在 TLS 的测试都通过后,就可以添加 kvs和 kvc对 TLS 的支持了。
由于我们一路以来良好的接口设计,尤其是 ProstClientStream / ProstServerStream 都接受泛型参数,使得 TLS 的代码可以无缝嵌入。比如客户端:
#![allow(unused)] fn main() { // 新加的代码 let connector = TlsClientConnector::new("kvserver.acme.inc", None, Some(ca_cert))?; let stream = TcpStream::connect(addr).await?; // 新加的代码 let stream = connector.connect(stream).await?; let mut client = ProstClientStream::new(stream); }
仅仅需要把传给 ProstClientStream 的 stream,从 TcpStream 换成生成的 TlsStream,就无缝支持了 TLS。
我们看完整的代码,src/server.rs:
use anyhow::Result; use kv3::{MemTable, ProstServerStream, Service, ServiceInner, TlsServerAcceptor}; use tokio::net::TcpListener; use tracing::info; #[tokio::main] async fn main() -> Result<()> { tracing_subscriber::fmt::init(); let addr = "127.0.0.1:9527"; // 以后从配置文件取 let server_cert = include_str!("../fixtures/server.cert"); let server_key = include_str!("../fixtures/server.key"); let acceptor = TlsServerAcceptor::new(server_cert, server_key, None)?; let service: Service = ServiceInner::new(MemTable::new()).into(); let listener = TcpListener::bind(addr).await?; info!("Start listening on {}", addr); loop { let tls = acceptor.clone(); let (stream, addr) = listener.accept().await?; info!("Client {:?} connected", addr); let stream = tls.accept(stream).await?; let stream = ProstServerStream::new(stream, service.clone()); tokio::spawn(async move { stream.process().await }); } }
src/client.rs:
use anyhow::Result; use kv3::{CommandRequest, ProstClientStream, TlsClientConnector}; use tokio::net::TcpStream; use tracing::info; #[tokio::main] async fn main() -> Result<()> { tracing_subscriber::fmt::init(); // 以后用配置替换 let ca_cert = include_str!("../fixtures/ca.cert"); let addr = "127.0.0.1:9527"; // 连接服务器 let connector = TlsClientConnector::new("kvserver.acme.inc", None, Some(ca_cert))?; let stream = TcpStream::connect(addr).await?; let stream = connector.connect(stream).await?; let mut client = ProstClientStream::new(stream); // 生成一个 HSET 命令 let cmd = CommandRequest::new_hset("table1", "hello", "world".to_string().into()); // 发送 HSET 命令 let data = client.execute(cmd).await?; info!("Got response {:?}", data); Ok(()) }
和上一讲的代码项目相比,更新后的客户端和服务器代码,各自仅仅多了一行,就把 TcpStream 封装成了 TlsStream。这就是使用 trait 做面向接口编程的巨大威力,系统的各个组件可以来自不同的 crates,但只要其接口一致(或者我们创建 adapter 使其接口一致),就可以无缝插入。
完成之后,打开一个命令行窗口,运行: RUST_LOG=info cargo run --bin kvs --quiet。然后在另一个命令行窗口,运行: RUST_LOG=info cargo run --bin kvc --quiet。此时,服务器和客户端都收到了彼此的请求和响应,并且处理正常。
现在,我们的 KV server 已经具备足够的安全性了!以后,等我们使用配置文件,就可以根据配置文件读取证书和私钥。这样可以在部署的时候,才从 vault 中获取私钥,既保证灵活性,又能保证系统自身的安全。
小结
网络安全是开发网络相关的应用程序中非常重要的一个环节。虽然 KV Server 这样的服务基本上会运行在云端受控的网络环境中,不会对 internet 提供服务,然而云端内部的安全性也不容忽视。你不希望数据在流动的过程中被篡改。
TLS 很好地解决了安全性的问题,可以保证整个传输过程中数据的机密性和完整性。如果使用客户端证书的话,还可以做一定程度的客户端合法性的验证。比如你可以在云端为所有有权访问 KV server 的客户端签发客户端证书,这样,只要客户端的私钥不泄露,就只有拥有证书的客户端才能访问 KV server。
不知道你现在有没有觉得,在 Rust 下使用 TLS 是非常方便的一件事情。并且,我们构建的 ProstServerStream / ProstClientStream,因为 有足够好的抽象,可以在 TcpStream 和 TlsStream 之间游刃有余地切换。当你构建好相关的代码,只需要把 TcpStream 换成 TlsStream,KV server 就可以无缝切换到一个安全的网络协议栈。
思考题
- 目前我们的 kvc / kvs 只做了单向的验证,如果服务器要验证客户端的证书,该怎么做?如果你没有头绪,可以再仔细看看测试 TLS 的代码,然后改动 kvc/kvs 使得双向验证也能通过吧。
- 除了 TLS,另外一个被广泛使用的处理应用层安全的协议是 noise protocol。你可以阅读我的 这篇文章 了解 noise protocol。Rust 下有 snow 这个很优秀的库处理 noise protocol。对于有余力的同学,你们可以看看它的文档,尝试着写段类似 tls.rs 的代码,让我们的 kvs / kvc 可以使用 noise protocol。
欢迎在留言区分享你的思考,感谢你的收听,如果你觉得有收获,也欢迎你分享给身边的朋友,邀他一起讨论。
恭喜你完成了第37次打卡,我们的Rust学习之旅已经过一大半啦,曙光就在前方,坚持下去,我们下节课见~
异步处理:Future是什么?它和async/await是什么关系?
你好,我是陈天。
通过前几讲的学习,我们对并发处理,尤其是常用的并发原语,有了一个比较清晰的认识。并发原语是并发任务之间同步的手段,今天我们要学习的 Future 以及在更高层次上处理 Future 的 async/await,是 产生和运行并发任务 的手段。
不过产生和运行并发任务的手段有很多,async/await 只是其中之一。在一个分布式系统中,并发任务可以运行在系统的某个节点上;在某个节点上,并发任务又可以运行在多个进程中;而在某个进程中,并发任务可以运行在多个线程中;在某个(些)线程上,并发任务可以运行在多个 Promise / Future / Goroutine / Erlang process 这样的协程上。
它们的粒度从大到小如图所示:
在之前的课程里,我们大量应用了线程这种并发工具,在 kv server 的构建过程中,也通过 async/await 用到了 Future 这样的无栈协程。
其实 Rust 的 Future 跟 JavaScript 的 Promise 非常类似。
如果你熟悉 JavaScript,应该熟悉 Promise 的概念, 02 也简单讲过,它代表了 在未来的某个时刻才能得到的结果的值,Promise 一般存在三个状态;
- 初始状态,Promise 还未运行;
- 等待(pending)状态,Promise 已运行,但还未结束;
- 结束状态,Promise 成功解析出一个值,或者执行失败。
只不过 JavaScript 的 Promise 和线程类似,一旦创建就开始执行,对 Promise await 只是为了“等待”并获取解析出来的值;而 Rust 的 Future,只有在主动 await 后才开始执行。
讲到这里估计你也看出来了,谈 Future 的时候,我们总会谈到 async/await。一般而言, async 定义了一个可以并发执行的任务,而 await 则触发这个任务并发执行。大多数语言,包括 Rust,async/await 都是一个语法糖(syntactic sugar),它们使用状态机将 Promise/Future 这样的结构包装起来进行处理。
这一讲我们先把内部的实现放在一边,主要聊 Future/async/await 的基本概念和使用方法,下一讲再来详细介绍它们的原理。
为什么需要 Future?
首先,谈一谈为什么需要 Future 这样的并发结构。
在 Future 出现之前,我们的 Rust 代码都是同步的。也就是说,当你执行一个函数,CPU 处理完函数中的每一个指令才会返回。如果这个函数里有 IO 的操作,实际上,操作系统会把函数对应的线程挂起,放在一个等待队列中,直到 IO 操作完成,才恢复这个线程,并从挂起的位置继续执行下去。
这个模型非常简单直观,代码是一行一行执行的,开发者并不需要考虑哪些操作会阻塞,哪些不会,只关心他的业务逻辑就好。
然而,随着 CPU 技术的不断发展,新世纪应用软件的主要矛盾不再是 CPU 算力不足,而是 过于充沛的 CPU 算力和提升缓慢的 IO 速度之间的矛盾。如果有大量的 IO 操作,你的程序大部分时间并没有在运算,而是在不断地等待 IO。
我们来看一个例子( 代码):
use anyhow::Result; use serde_yaml::Value; use std::fs; fn main() -> Result<()> { // 读取 Cargo.toml,IO 操作 1 let content1 = fs::read_to_string("./Cargo.toml")?; // 读取 Cargo.lock,IO 操作 2 let content2 = fs::read_to_string("./Cargo.lock")?; // 计算 let yaml1 = toml2yaml(&content1)?; let yaml2 = toml2yaml(&content2)?; // 写入 /tmp/Cargo.yml,IO 操作 3 fs::write("/tmp/Cargo.yml", &yaml1)?; // 写入 /tmp/Cargo.lock,IO 操作 4 fs::write("/tmp/Cargo.lock", &yaml2)?; // 打印 println!("{}", yaml1); println!("{}", yaml2); Ok(()) } fn toml2yaml(content: &str) -> Result<String> { let value: Value = toml::from_str(&content)?; Ok(serde_yaml::to_string(&value)?) }
这段代码读取 Cargo.toml 和 Cargo.lock 将其转换成 yaml,再分别写入到 /tmp 下。
虽然说这段代码的逻辑并没有问题,但性能有很大的问题。在读 Cargo.toml 时,整个主线程被阻塞,直到 Cargo.toml 读完,才能继续读下一个待处理的文件。整个主线程,只有在运行 toml2yaml 的时间片内,才真正在执行计算任务,之前的读取文件以及之后的写入文件,CPU 都在闲置。
当然,你会辩解,在读文件的过程中,我们不得不等待,因为 toml2yaml 函数的执行有赖于读取文件的结果。嗯没错,但是,这里还有很大的 CPU 浪费:我们读完第一个文件才开始读第二个文件,有没有可能两个文件同时读取呢?这样总共等待的时间是 max(time_for_file1, time_for_file2),而非 time_for_file1 + time_for_file2 。
这并不难,我们可以把文件读取和写入的操作放入单独的线程中执行,比如( 代码):
use anyhow::{anyhow, Result}; use serde_yaml::Value; use std::{ fs, thread::{self, JoinHandle}, }; /// 包装一下 JoinHandle,这样可以提供额外的方法 struct MyJoinHandle<T>(JoinHandle<Result<T>>); impl<T> MyJoinHandle<T> { /// 等待 thread 执行完(类似 await) pub fn thread_await(self) -> Result<T> { self.0.join().map_err(|_| anyhow!("failed"))? } } fn main() -> Result<()> { // 读取 Cargo.toml,IO 操作 1 let t1 = thread_read("./Cargo.toml"); // 读取 Cargo.lock,IO 操作 2 let t2 = thread_read("./Cargo.lock"); let content1 = t1.thread_await()?; let content2 = t2.thread_await()?; // 计算 let yaml1 = toml2yaml(&content1)?; let yaml2 = toml2yaml(&content2)?; // 写入 /tmp/Cargo.yml,IO 操作 3 let t3 = thread_write("/tmp/Cargo.yml", yaml1); // 写入 /tmp/Cargo.lock,IO 操作 4 let t4 = thread_write("/tmp/Cargo.lock", yaml2); let yaml1 = t3.thread_await()?; let yaml2 = t4.thread_await()?; fs::write("/tmp/Cargo.yml", &yaml1)?; fs::write("/tmp/Cargo.lock", &yaml2)?; // 打印 println!("{}", yaml1); println!("{}", yaml2); Ok(()) } fn thread_read(filename: &'static str) -> MyJoinHandle<String> { let handle = thread::spawn(move || { let s = fs::read_to_string(filename)?; Ok::<_, anyhow::Error>(s) }); MyJoinHandle(handle) } fn thread_write(filename: &'static str, content: String) -> MyJoinHandle<String> { let handle = thread::spawn(move || { fs::write(filename, &content)?; Ok::<_, anyhow::Error>(content) }); MyJoinHandle(handle) } fn toml2yaml(content: &str) -> Result<String> { let value: Value = toml::from_str(&content)?; Ok(serde_yaml::to_string(&value)?) }
这样,读取或者写入多个文件的过程并发执行,使等待的时间大大缩短。
但是,如果要同时读取 100 个文件呢?显然,创建 100 个线程来做这样的事情不是一个好主意。在操作系统中,线程的数量是有限的,创建/阻塞/唤醒/销毁线程,都涉及不少的动作,每个线程也都会被分配一个不小的调用栈,所以从 CPU 和内存的角度来看, 创建过多的线程会大大增加系统的开销。
其实,绝大多数操作系统对 I/O 操作提供了非阻塞接口,也就是说,你可以发起一个读取的指令,自己处理类似 EWOULDBLOCK 这样的错误码,来更好地在同一个线程中处理多个文件的 IO,而不是依赖操作系统通过调度帮你完成这件事。
不过这样就意味着,你需要定义合适的数据结构来追踪每个文件的读取,在用户态进行相应的调度,阻塞等待 IO 的数据结构的运行,让没有等待 IO 的数据结构得到机会使用 CPU,以及当 IO 操作结束后,恢复等待 IO 的数据结构的运行等等。这样的操作粒度更小,可以最大程度利用 CPU 资源。这就是类似 Future 这样的并发结构的主要用途。
然而,如果这么处理,我们需要在用户态做很多事情,包括处理 IO 任务的事件通知、创建 Future、合理地调度 Future。这些事情,统统交给开发者做显然是不合理的。所以,Rust 提供了相应处理手段 async/await : async 来方便地生成 Future,await 来触发 Future 的调度和执行。
我们看看,同样的任务,如何用 async/await 更高效地处理( 代码):
use anyhow::Result; use serde_yaml::Value; use tokio::{fs, try_join}; #[tokio::main] async fn main() -> Result<()> { // 读取 Cargo.toml,IO 操作 1 let f1 = fs::read_to_string("./Cargo.toml"); // 读取 Cargo.lock,IO 操作 2 let f2 = fs::read_to_string("./Cargo.lock"); let (content1, content2) = try_join!(f1, f2)?; // 计算 let yaml1 = toml2yaml(&content1)?; let yaml2 = toml2yaml(&content2)?; // 写入 /tmp/Cargo.yml,IO 操作 3 let f3 = fs::write("/tmp/Cargo.yml", &yaml1); // 写入 /tmp/Cargo.lock,IO 操作 4 let f4 = fs::write("/tmp/Cargo.lock", &yaml2); try_join!(f3, f4)?; // 打印 println!("{}", yaml1); println!("{}", yaml2); Ok(()) } fn toml2yaml(content: &str) -> Result<String> { let value: Value = toml::from_str(&content)?; Ok(serde_yaml::to_string(&value)?) }
在这段代码里,我们使用了 tokio::fs,而不是 std::fs,tokio::fs 的文件操作都会返回一个 Future,然后可以 join 这些 Future,得到它们运行后的结果。join / try_join 是用来轮询多个 Future 的宏,它会依次处理每个 Future,遇到阻塞就处理下一个,直到所有 Future 产生结果。
整个等待文件读取的时间是 max(time_for_file1, time_for_file2),性能和使用线程的版本几乎一致,但是消耗的资源(主要是线程)要少很多。
建议你好好对比这三个版本的代码,写一写,运行一下,感受它们的处理逻辑。注意在最后的 async/await 的版本中,我们不能把代码写成这样:
#![allow(unused)] fn main() { // 读取 Cargo.toml,IO 操作 1 let content1 = fs::read_to_string("./Cargo.toml").await?; // 读取 Cargo.lock,IO 操作 2 let content1 = fs::read_to_string("./Cargo.lock").await?; }
这样写的话,和第一版同步的版本没有区别,因为 await 会运行 Future 直到 Future 执行结束,所以依旧是先读取 Cargo.toml,再读取 Cargo.lock,并没有达到并发的效果。
深入了解
好,了解了 Future 在软件开发中的必要性,来深入研究一下 Future/async/await。
在前面代码撰写过程中,不知道你有没有发现,异步函数(async fn)的返回值是一个奇怪的 impl Future

我们知道,一般会用 impl 关键字为数据结构实现 trait,也就是说接在 impl 关键字后面的东西是一个 trait,所以,显然 Future 是一个 trait,并且还有一个关联类型 Output。
来看 Future 的定义:
#![allow(unused)] fn main() { pub trait Future { type Output; fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>; } pub enum Poll<T> { Ready(T), Pending, } }
除了 Output 外,它还有一个 poll() 方法,这个方法返回 Poll Self::Output。而 Poll
你看,这样一个简单的数据结构,就托起了庞大的 Rust 异步 async/await 处理的生态。
回到 async fn 的返回值我们接着说,显然它是一个 impl Future,那么如果我们给一个普通的函数返回 impl Future
use futures::executor::block_on; use std::future::Future; #[tokio::main] async fn main() { let name1 = "Tyr".to_string(); let name2 = "Lindsey".to_string(); say_hello1(&name1).await; say_hello2(&name2).await; // Future 除了可以用 await 来执行外,还可以直接用 executor 执行 block_on(say_hello1(&name1)); block_on(say_hello2(&name2)); } async fn say_hello1(name: &str) -> usize { println!("Hello {}", name); 42 } // async fn 关键字相当于一个返回 impl Future<Output> 的语法糖 fn say_hello2<'fut>(name: &'fut str) -> impl Future<Output = usize> + 'fut { async move { println!("Hello {}", name); 42 } }
运行这段代码你会发现,say_hello1 和 say_hello2 是等价的,二者都可以使用 await 来执行,也可以将其提供给一个 executor 来执行。
这里我们见到了一个新的名词:executor。
什么是 executor?
你可以把 executor 大致想象成一个 Future 的调度器。对于线程来说,操作系统负责调度;但操作系统不会去调度用户态的协程(比如 Future),所以任何使用了协程来处理并发的程序,都需要有一个 executor 来负责协程的调度。
很多在语言层面支持协程的编程语言,比如 Golang / Erlang,都自带一个用户态的调度器。Rust 虽然也提供 Future 这样的协程,但它 在语言层面并不提供 executor,把要不要使用 executor 和使用什么样的 executor 的自主权交给了开发者。好处是,当我的代码中不需要使用协程时,不需要引入任何运行时;而需要使用协程时,可以在生态系统中选择最合适我应用的 executor。
常见的 executor 有:
- futures 库自带的很简单的 executor,上面的代码就使用了它的 block_on 函数;
- tokio 提供的 executor,当使用 #[tokio::main] 时,就隐含引入了 tokio 的 executor;
- async-std 提供的 executor,和 tokio 类似;
- smol 提供的 async-executor,主要提供了 block_on。
注意,上面的代码我们混用了 #[tokio::main] 和 futures:executor::block_on,这只是为了展示 Future 使用的不同方式, 在正式代码里,不建议混用不同的 executor,会降低程序的性能,还可能引发奇怪的问题。
当我们谈到 executor 时,就不得不提 reactor,它俩都是 Reactor Pattern 的组成部分,作为构建高性能事件驱动系统的一个很典型模式,Reactor pattern 它包含三部分:
- task,待处理的任务。任务可以被打断,并且把控制权交给 executor,等待之后的调度;
- executor,一个调度器。维护等待运行的任务(ready queue),以及被阻塞的任务(wait queue);
- reactor,维护事件队列。当事件来临时,通知 executor 唤醒某个任务等待运行。
executor 会调度执行待处理的任务,当任务无法继续进行却又没有完成时,它会挂起任务,并设置好合适的唤醒条件。之后,如果 reactor 得到了满足条件的事件,它会唤醒之前挂起的任务,然后 executor 就有机会继续执行这个任务。这样一直循环下去,直到任务执行完毕。
怎么用 Future 做异步处理?
理解了 Reactor pattern 后,Rust 使用 Future 做异步处理的整个结构就清晰了,我们以 tokio 为例:async/await 提供语法层面的支持,Future 是异步任务的数据结构,当 fut.await 时,executor 就会调度并执行它。
tokio 的调度器(executor)会运行在多个线程上,运行线程自己的 ready queue 上的任务(Future),如果没有,就去别的线程的调度器上“偷”一些过来运行。当某个任务无法再继续取得进展,此时 Future 运行的结果是 Poll::Pending,那么调度器会挂起任务,并设置好合适的唤醒条件(Waker),等待被 reactor 唤醒。
而 reactor 会利用操作系统提供的异步 I/O,比如 epoll / kqueue / IOCP,来监听操作系统提供的 IO 事件,当遇到满足条件的事件时,就会调用 Waker.wake() 唤醒被挂起的 Future。这个 Future 会回到 ready queue 等待执行。
整个流程如下:
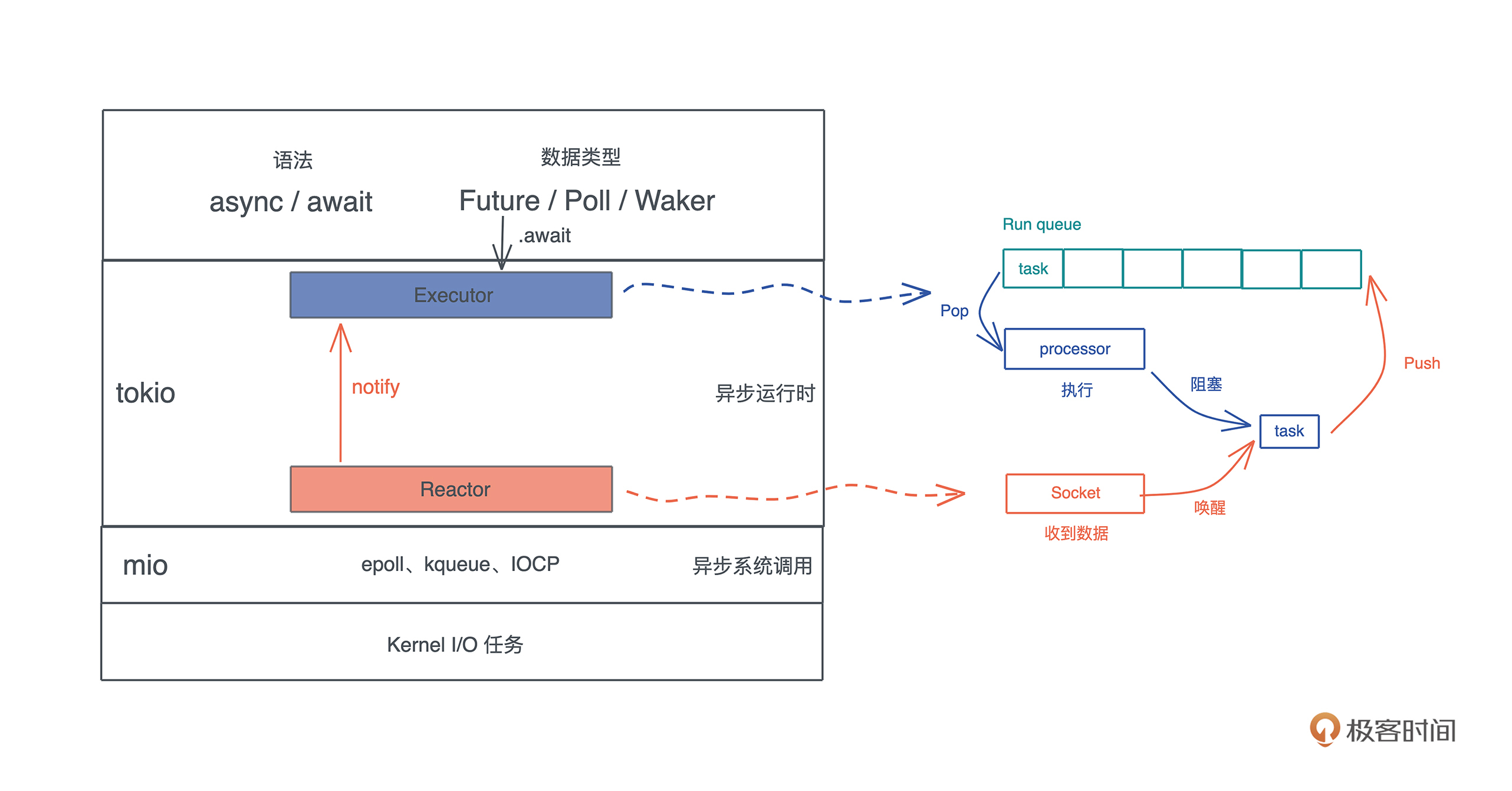
我们以一个具体的代码示例来进一步理解这个过程( 代码):
use anyhow::Result; use futures::{SinkExt, StreamExt}; use tokio::net::TcpListener; use tokio_util::codec::{Framed, LinesCodec}; #[tokio::main] async fn main() -> Result<()> { let addr = "0.0.0.0:8080"; let listener = TcpListener::bind(addr).await?; println!("listen to: {}", addr); loop { let (stream, addr) = listener.accept().await?; println!("Accepted: {:?}", addr); tokio::spawn(async move { // 使用 LinesCodec 把 TCP 数据切成一行行字符串处理 let framed = Framed::new(stream, LinesCodec::new()); // split 成 writer 和 reader let (mut w, mut r) = framed.split(); for line in r.next().await { // 每读到一行就加个前缀发回 w.send(format!("I got: {}", line?)).await?; } Ok::<_, anyhow::Error>(()) }); } }
这是一个简单的 TCP 服务器,服务器每收到一个客户端的请求,就会用 tokio::spawn 创建一个异步任务,放入 executor 中执行。这个异步任务接受客户端发来的按行分隔(分隔符是 “\r\n”)的数据帧,服务器每收到一行,就加个前缀把内容也按行发回给客户端。
你可以用 telnet 和这个服务器交互:
#![allow(unused)] fn main() { ❯ telnet localhost 8080 Trying 127.0.0.1... Connected to localhost. Escape character is '^]'. hello I got: hello Connection closed by foreign host. }
假设我们在客户端输入了很大的一行数据,服务器在做 r.next().await 在执行的时候,收不完一行的数据,因而这个 Future 返回 Poll::Pending,此时它被挂起。当后续客户端的数据到达时,reactor 会知道这个 socket 上又有数据了,于是找到 socket 对应的 Future,将其唤醒,继续接收数据。
这样反复下去,最终 r.next().await 得到 Poll::Ready(Ok(line)),于是它返回 Ok(line),程序继续往下走,进入到 w.send() 的阶段。
从这段代码中你可以看到,在 Rust 下使用异步处理是一件非常简单的事情,除了几个你可能不太熟悉的概念,比如今天讲到的用于创建 Future 的 async 关键字,用于执行和等待 Future 执行完毕的 await 关键字,以及用于调度 Future 执行的运行时 #[tokio:main] 外, 整体的代码和使用线程处理的代码完全一致。所以,它的上手难度非常低,很容易使用。
使用 Future 的注意事项
目前我们已经基本明白 Future 运行的基本原理了,也可以在程序的不同部分自如地使用 Future/async/await 来进行异步处理。
但是要注意, 不是所有的应用场景都适合用 async/await,在使用的时候,有一些不容易注意到的坑需要我们妥善考虑。
1. 处理计算密集型任务时
当你要处理的任务是 CPU 密集型,而非 IO 密集型,更适合使用线程,而非 Future。
这是因为 Future 的调度是协作式多任务(Cooperative Multitasking),也就是说,除非 Future 主动放弃 CPU,不然它就会一直被执行,直到运行结束。我们看一个例子( 代码):
use anyhow::Result; use std::time::Duration; // 强制 tokio 只使用一个工作线程,这样 task 2 不会跑到其它线程执行 #[tokio::main(worker_threads = 1)] async fn main() -> Result<()> { // 先开始执行 task 1 的话会阻塞,让 task 2 没有机会运行 tokio::spawn(async move { eprintln!("task 1"); // 试试把这句注释掉看看会产生什么结果 // tokio::time::sleep(Duration::from_millis(1)).await; loop {} }); tokio::spawn(async move { eprintln!("task 2"); }); tokio::time::sleep(Duration::from_millis(1)).await; Ok(()) }
task 1 里有一个死循环,你可以把它想象成是执行时间很长又不包括 IO 处理的代码。运行这段代码,你会发现,task 2 没有机会得到执行。这是因为 task 1 不执行结束,或者不让出 CPU,task 2 没有机会被调度。
如果你的确需要在 tokio(或者其它异步运行时)下运行运算量很大的代码,那么最好使用 yield 来主动让出 CPU,比如 tokio::task::yield_now()。这样可以避免某个计算密集型的任务饿死其它任务。
2. 异步代码中使用Mutex时
大部分时候,标准库的 Mutex 可以用在异步代码中,而且,这是推荐的用法。
然而,标准库的 MutexGuard 不能安全地跨越 await,所以,当我们需要获得锁之后执行异步操作,必须使用 tokio 自带的 Mutex,看下面的例子( 代码):
use anyhow::Result; use std::{sync::Arc, time::Duration}; use tokio::sync::Mutex; struct DB; impl DB { // 假装在 commit 数据 async fn commit(&mut self) -> Result<usize> { Ok(42) } } #[tokio::main] async fn main() -> Result<()> { let db1 = Arc::new(Mutex::new(DB)); let db2 = Arc::clone(&db1); tokio::spawn(async move { let mut db = db1.lock().await; // 因为拿到的 MutexGuard 要跨越 await,所以不能用 std::sync::Mutex // 只能用 tokio::sync::Mutex let affected = db.commit().await?; println!("db1: Total affected rows: {}", affected); Ok::<_, anyhow::Error>(()) }); tokio::spawn(async move { let mut db = db2.lock().await; let affected = db.commit().await?; println!("db2: Total affected rows: {}", affected); Ok::<_, anyhow::Error>(()) }); // 让两个 task 有机会执行完 tokio::time::sleep(Duration::from_millis(1)).await; Ok(()) }
这个例子模拟了一个数据库的异步 commit() 操作。如果我们需要在多个 tokio task 中使用这个 DB,需要使用 Arc<Mutext
前面讲过,因为 tokio 实现了 work-stealing 调度, Future 有可能在不同的线程中执行,普通的 MutexGuard 编译直接就会出错,所以需要使用 tokio 的 Mutex。更多信息可以看 文档。
在这个例子里,我们又见识到了 Rust 编译器的伟大之处:如果一件事,它觉得你不能做,会通过编译器错误阻止你,而不是任由编译通过,然后让程序在运行过程中听天由命,让你无休止地和捉摸不定的并发 bug 斗争。
3. 在线程和异步任务间做同步时
在一个复杂的应用程序中,会兼有计算密集和 IO 密集的任务。
前面说了,要避免在 tokio 这样的异步运行时中运行大量计算密集型的任务,一来效率不高,二来还容易饿死其它任务。
所以,一般的做法是我们使用 channel 来在线程和future两者之间做同步。看一个例子:
use std::thread; use anyhow::Result; use blake3::Hasher; use futures::{SinkExt, StreamExt}; use rayon::prelude::*; use tokio::{ net::TcpListener, sync::{mpsc, oneshot}, }; use tokio_util::codec::{Framed, LinesCodec}; pub const PREFIX_ZERO: &[u8] = &[0, 0, 0]; #[tokio::main] async fn main() -> Result<()> { let addr = "0.0.0.0:8080"; let listener = TcpListener::bind(addr).await?; println!("listen to: {}", addr); // 创建 tokio task 和 thread 之间的 channel let (sender, mut receiver) = mpsc::unbounded_channel::<(String, oneshot::Sender<String>)>(); // 使用 thread 处理计算密集型任务 thread::spawn(move || { // 读取从 tokio task 过来的 msg,注意这里用的是 blocking_recv,而非 await while let Some((line, reply)) = receiver.blocking_recv() { // 计算 pow let result = match pow(&line) { Some((hash, nonce)) => format!("hash: {}, once: {}", hash, nonce), None => "Not found".to_string(), }; // 把计算结果从 oneshot channel 里发回 if let Err(e) = reply.send(result) { println!("Failed to send: {}", e); } } }); // 使用 tokio task 处理 IO 密集型任务 loop { let (stream, addr) = listener.accept().await?; println!("Accepted: {:?}", addr); let sender1 = sender.clone(); tokio::spawn(async move { // 使用 LinesCodec 把 TCP 数据切成一行行字符串处理 let framed = Framed::new(stream, LinesCodec::new()); // split 成 writer 和 reader let (mut w, mut r) = framed.split(); for line in r.next().await { // 为每个消息创建一个 oneshot channel,用于发送回复 let (reply, reply_receiver) = oneshot::channel(); sender1.send((line?, reply))?; // 接收 pow 计算完成后的 hash 和 nonce if let Ok(v) = reply_receiver.await { w.send(format!("Pow calculated: {}", v)).await?; } } Ok::<_, anyhow::Error>(()) }); } } // 使用 rayon 并发计算 u32 空间下所有 nonce,直到找到有头 N 个 0 的哈希 pub fn pow(s: &str) -> Option<(String, u32)> { let hasher = blake3_base_hash(s.as_bytes()); let nonce = (0..u32::MAX).into_par_iter().find_any(|n| { let hash = blake3_hash(hasher.clone(), n).as_bytes().to_vec(); &hash[..PREFIX_ZERO.len()] == PREFIX_ZERO }); nonce.map(|n| { let hash = blake3_hash(hasher, &n).to_hex().to_string(); (hash, n) }) } // 计算携带 nonce 后的哈希 fn blake3_hash(mut hasher: blake3::Hasher, nonce: &u32) -> blake3::Hash { hasher.update(&nonce.to_be_bytes()[..]); hasher.finalize() } // 计算数据的哈希 fn blake3_base_hash(data: &[u8]) -> Hasher { let mut hasher = Hasher::new(); hasher.update(data); hasher }
在这个例子里,我们使用了之前撰写的 TCP server,只不过这次,客户端输入过来的一行文字,会被计算出一个 POW(Proof of Work)的哈希:调整 nonce,不断计算哈希,直到哈希的头三个字节全是零为止。服务器要返回计算好的哈希和获得该哈希的 nonce。这是一个典型的计算密集型任务,所以我们需要使用线程来处理它。
而在 tokio task 和 thread 间使用 channel 进行同步。我们使用了一个 ubounded MPSC channel 从 tokio task 侧往 thread 侧发送消息,每条消息都附带一个 oneshot channel 用于 thread 侧往 tokio task 侧发送数据。
建议你仔细读读这段代码,最好自己写一遍,感受一下使用 channel 在计算密集型和 IO 密集型任务同步的方式。如果你用 telnet 连接,发送 “hello world!”,会得到不同的哈希和 nonce,它们都是正确的结果:
#![allow(unused)] fn main() { ❯ telnet localhost 8080 Trying 127.0.0.1... Connected to localhost. Escape character is '^]'. hello world! Pow calculated: hash: 0000006e6e9370d0f60f06bdc288efafa203fd99b9af0480d040b2cc89c44df0, once: 403407307 Connection closed by foreign host. ❯ telnet localhost 8080 Trying 127.0.0.1... Connected to localhost. Escape character is '^]'. hello world! Pow calculated: hash: 000000e23f0e9b7aeba9060a17ac676f3341284800a2db843e2f0e85f77f52dd, once: 36169623 Connection closed by foreign host. }
小结
通过拆解async fn 有点奇怪的返回值结构,我们学习了 Reactor pattern,大致了解了 tokio 如何通过 executor 和 reactor 共同作用,完成 Future 的调度、执行、阻塞,以及唤醒。这是一个完整的循环,直到 Future 返回 Poll::Ready(T)。
在学习 Future 的使用时,估计你也发现了,我们可以对比线程来学习,可以看到,下列代码的结构多么相似:
#![allow(unused)] fn main() { fn thread_async() -> JoinHandle<usize> { thread::spawn(move || { println!("hello thread!"); 42 }) } fn task_async() -> impl Future<Output = usize> { async move { println!("hello async!"); 42 } } }
在使用 Future 时,主要有3点注意事项:
- 我们要避免在异步任务中处理大量计算密集型的工作;
- 在使用 Mutex 等同步原语时,要注意标准库的 MutexGuard 无法跨越 .await,所以,此时要使用对异步友好的 Mutex,如 tokio::sync::Mutex;
- 如果要在线程和异步任务间同步,可以使用 channel。
今天为了帮助你深入理解,我们写了很多代码,每一段你都可以再仔细阅读几遍,把它们搞懂,最好自己也能直接写出来,这样你对 Future 才会有更深的理解。
思考题
想想看,为什么标准库的 Mutex 不能跨越 await?你可以把文中使用 tokio::sync::Mutex 的代码改成使用 std::sync::Mutex,并对使用的接口做相应的改动(把 lock().await 改成 lock().unwrap()),看看编译器会报什么错。对着错误提示,你明白为什么了么?
欢迎在留言区分享你的学习感悟和思考。今天你完成Rust学习的第38次打卡啦,感谢你的收听,如果你觉得有收获,也欢迎你分享给身边的朋友,邀他一起讨论。我们下节课见。
异步处理:async/await内部是怎么实现的?
你好,我是陈天。
学完上一讲,我们对 Future 和 async/await 的基本概念有一个比较扎实的理解了,知道在什么情况下该使用 Future、什么情况下该使用 Thread,以及 executor 和 reactor 是怎么联动最终让 Future 得到了一个结果。
然而,我们并不清楚为什么 async fn 或者 async block 就能够产生 Future,也并不明白 Future 是怎么被 executor 处理的。今天我们就继续深入下去,看看 async/await 这两个关键词究竟施了什么样的魔法,能够让一切如此简单又如此自然地运转起来。
提前说明一下,我们会继续围绕着 Future 这个简约却又并不简单的接口,来探讨一些原理性的东西,主要是 Context 和 Pin这两个结构:
#![allow(unused)] fn main() { pub trait Future { type Output; fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>; } }
这堂课的内容即便没有完全弄懂,也并不影响你使用 async/await。如果精力有限,你可以不用理解所有细节,只要抓住这些问题产生的原因,以及解决方案的思路即可。
Waker 的调用机制
先来看这个接口的 Context 是个什么东西。
上节课我们简单讲过 executor 通过调用 poll 方法来让 Future 继续往下执行,如果 poll 方法返回 Poll::Pending,就阻塞 Future,直到 reactor 收到了某个事件,然后调用 Waker.wake() 把 Future 唤醒。这个 Waker 是哪来的呢?
其实,它隐含在 Context 中:
#![allow(unused)] fn main() { pub struct Context<'a> { waker: &'a Waker, _marker: PhantomData<fn(&'a ()) -> &'a ()>, } }
所以,Context 就是 Waker 的一个封装。
如果你去看 Waker 的定义和相关的代码,会发现它非常抽象,内部使用了一个 vtable 来允许各种各样的 waker 的行为:
#![allow(unused)] fn main() { pub struct RawWakerVTable { clone: unsafe fn(*const ()) -> RawWaker, wake: unsafe fn(*const ()), wake_by_ref: unsafe fn(*const ()), drop: unsafe fn(*const ()), } }
这种手工生成 vtable 的做法,我们 之前 阅读 bytes 的源码已经见识过了,它可以最大程度兼顾效率和灵活性。
Rust 自身并不提供异步运行时,它只在标准库里规定了一些基本的接口,至于怎么实现,可以由各个运行时(如 tokio)自行决定。 所以在标准库中,你只会看到这些接口的定义,以及“高层”接口的实现,比如 Waker 下的 wake 方法,只是调用了 vtable 里的 wake() 而已:
#![allow(unused)] fn main() { impl Waker { /// Wake up the task associated with this `Waker`. #[inline] pub fn wake(self) { // The actual wakeup call is delegated through a virtual function call // to the implementation which is defined by the executor. let wake = self.waker.vtable.wake; let data = self.waker.data; // Don't call `drop` -- the waker will be consumed by `wake`. crate::mem::forget(self); // SAFETY: This is safe because `Waker::from_raw` is the only way // to initialize `wake` and `data` requiring the user to acknowledge // that the contract of `RawWaker` is upheld. unsafe { (wake)(data) }; } ... } }
如果你想顺藤摸瓜找到 vtable 是怎么设置的,却发现一切线索都悄无声息地中断了,那是因为,具体的实现并不在标准库中,而是在第三方的异步运行时里,比如 tokio。
不过,虽然我们开发时会使用 tokio,但阅读、理解代码时,我建议看 futures 库,比如 waker vtable 的 定义。futures 库还有一个简单的 executor,也非常适合进一步通过代码理解 executor 的原理。
async究竟生成了什么?
我们接下来看 Pin。这是一个奇怪的数据结构,正常数据结构的方法都是直接使用 self / &self / &mut self,可是 poll() 却使用了 Pin<&mut self>,为什么?
为了讲明白 Pin,我们得往前追踪一步,看看产生 Future的一个 async block/fn 内部究竟生成了什么样的代码?来看下面这个简单的 async 函数:
#![allow(unused)] fn main() { async fn write_hello_file_async(name: &str) -> anyhow::Result<()> { let mut file = fs::File::create(name).await?; file.write_all(b"hello world!").await?; Ok(()) } }
首先它创建一个文件,然后往这个文件里写入 “hello world!”。这个函数有两个 await,创建文件的时候会异步创建,写入文件的时候会异步写入。最终,整个函数对外返回一个 Future。
其它人可以这样调用:
#![allow(unused)] fn main() { write_hello_file_async("/tmp/hello").await?; }
我们知道,executor 处理 Future 时,会不断地调用它的 poll() 方法,于是,上面那句实际上相当于:
#![allow(unused)] fn main() { match write_hello_file_async.poll(cx) { Poll::Ready(result) => return result, Poll::Pending => return Poll::Pending } }
这是单个 await 的处理方法,那更加复杂的,一个函数中有若干个 await,该怎么处理呢?以前面 write_hello_file_async 函数的内部实现为例,显然,我们只有在处理完 create(),才能处理 write_all(),所以,应该是类似这样的代码:
#![allow(unused)] fn main() { let fut = fs::File::create(name); match fut.poll(cx) { Poll::Ready(Ok(file)) => { let fut = file.write_all(b"hello world!"); match fut.poll(cx) { Poll::Ready(result) => return result, Poll::Pending => return Poll::Pending, } } Poll::Pending => return Poll::Pending, } }
但是,前面说过,async 函数返回的是一个 Future,所以,还需要把这样的代码封装在一个 Future 的实现里,对外提供出去。因此,我们需要实现一个数据结构,把内部的状态保存起来,并为这个数据结构实现 Future。比如:
#![allow(unused)] fn main() { enum WriteHelloFile { // 初始阶段,用户提供文件名 Init(String), // 等待文件创建,此时需要保存 Future 以便多次调用 // 这是伪代码,impl Future 不能用在这里 AwaitingCreate(impl Future<Output = Result<fs::File, std::io::Error>>), // 等待文件写入,此时需要保存 Future 以便多次调用 AwaitingWrite(impl Future<Output = Result<(), std::io::Error>>), // Future 处理完毕 Done, } impl WriteHelloFile { pub fn new(name: impl Into<String>) -> Self { Self::Init(name.into()) } } impl Future for WriteHelloFile { type Output = Result<(), std::io::Error>; fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> { todo!() } } fn write_hello_file_async(name: &str) -> WriteHelloFile { WriteHelloFile::new(name) } }
这样,我们就把刚才的 write_hello_file_async 异步函数,转化成了一个返回 WriteHelloFile Future 的函数。来看这个 Future 如何实现(详细注释了):
#![allow(unused)] fn main() { impl Future for WriteHelloFile { type Output = Result<(), std::io::Error>; fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> { let this = self.get_mut(); loop { match this { // 如果状态是 Init,那么就生成 create Future,把状态切换到 AwaitingCreate WriteHelloFile::Init(name) => { let fut = fs::File::create(name); *self = WriteHelloFile::AwaitingCreate(fut); } // 如果状态是 AwaitingCreate,那么 poll create Future // 如果返回 Poll::Ready(Ok(_)),那么创建 write Future // 并把状态切换到 Awaiting WriteHelloFile::AwaitingCreate(fut) => match fut.poll(cx) { Poll::Ready(Ok(file)) => { let fut = file.write_all(b"hello world!"); *self = WriteHelloFile::AwaitingWrite(fut); } Poll::Ready(Err(e)) => return Poll::Ready(Err(e)), Poll::Pending => return Poll::Pending, }, // 如果状态是 AwaitingWrite,那么 poll write Future // 如果返回 Poll::Ready(_),那么状态切换到 Done,整个 Future 执行成功 WriteHelloFile::AwaitingWrite(fut) => match fut.poll(cx) { Poll::Ready(result) => { *self = WriteHelloFile::Done; return Poll::Ready(result); } Poll::Pending => return Poll::Pending, }, // 整个 Future 已经执行完毕 WriteHelloFile::Done => return Poll::Ready(Ok(())), } } } } }
这个 Future 完整实现的内部结构 ,其实就是一个状态机的迁移。
这段(伪)代码和之前异步函数是等价的:
#![allow(unused)] fn main() { async fn write_hello_file_async(name: &str) -> anyhow::Result<()> { let mut file = fs::File::create(name).await?; file.write_all(b"hello world!").await?; Ok(()) } }
Rust 在编译 async fn 或者 async block 时,就会生成类似的状态机的实现。你可以看到,看似简单的异步处理,内部隐藏了一套并不难理解、但是写起来很生硬很啰嗦的状态机管理代码。
好搞明白这个问题,回到pin 。刚才我们手写状态机代码的过程,能帮你理解为什么会需要 Pin 这个问题。
为什么需要 Pin?
在上面实现 Future 的状态机中,我们引用了 file 这样一个局部变量:
#![allow(unused)] fn main() { WriteHelloFile::AwaitingCreate(fut) => match fut.poll(cx) { Poll::Ready(Ok(file)) => { let fut = file.write_all(b"hello world!"); *self = WriteHelloFile::AwaitingWrite(fut); } Poll::Ready(Err(e)) => return Poll::Ready(Err(e)), Poll::Pending => return Poll::Pending, } }
这个代码是有问题的,file 被 fut 引用,但 file 会在这个作用域被丢弃。所以,我们需要把它保存在数据结构中:
#![allow(unused)] fn main() { enum WriteHelloFile { // 初始阶段,用户提供文件名 Init(String), // 等待文件创建,此时需要保存 Future 以便多次调用 AwaitingCreate(impl Future<Output = Result<fs::File, std::io::Error>>), // 等待文件写入,此时需要保存 Future 以便多次调用 AwaitingWrite(AwaitingWriteData), // Future 处理完毕 Done, } struct AwaitingWriteData { fut: impl Future<Output = Result<(), std::io::Error>>, file: fs::File, } }
可以生成一个 AwaitingWriteData 数据结构,把 file 和 fut 都放进去,然后在 WriteHelloFile 中引用它。此时,在同一个数据结构内部,fut 指向了对 file 的引用,这样的数据结构,叫 自引用结构(Self-Referential Structure)。
自引用结构有一个很大的问题是:一旦它被移动,原本的指针就会指向旧的地址。
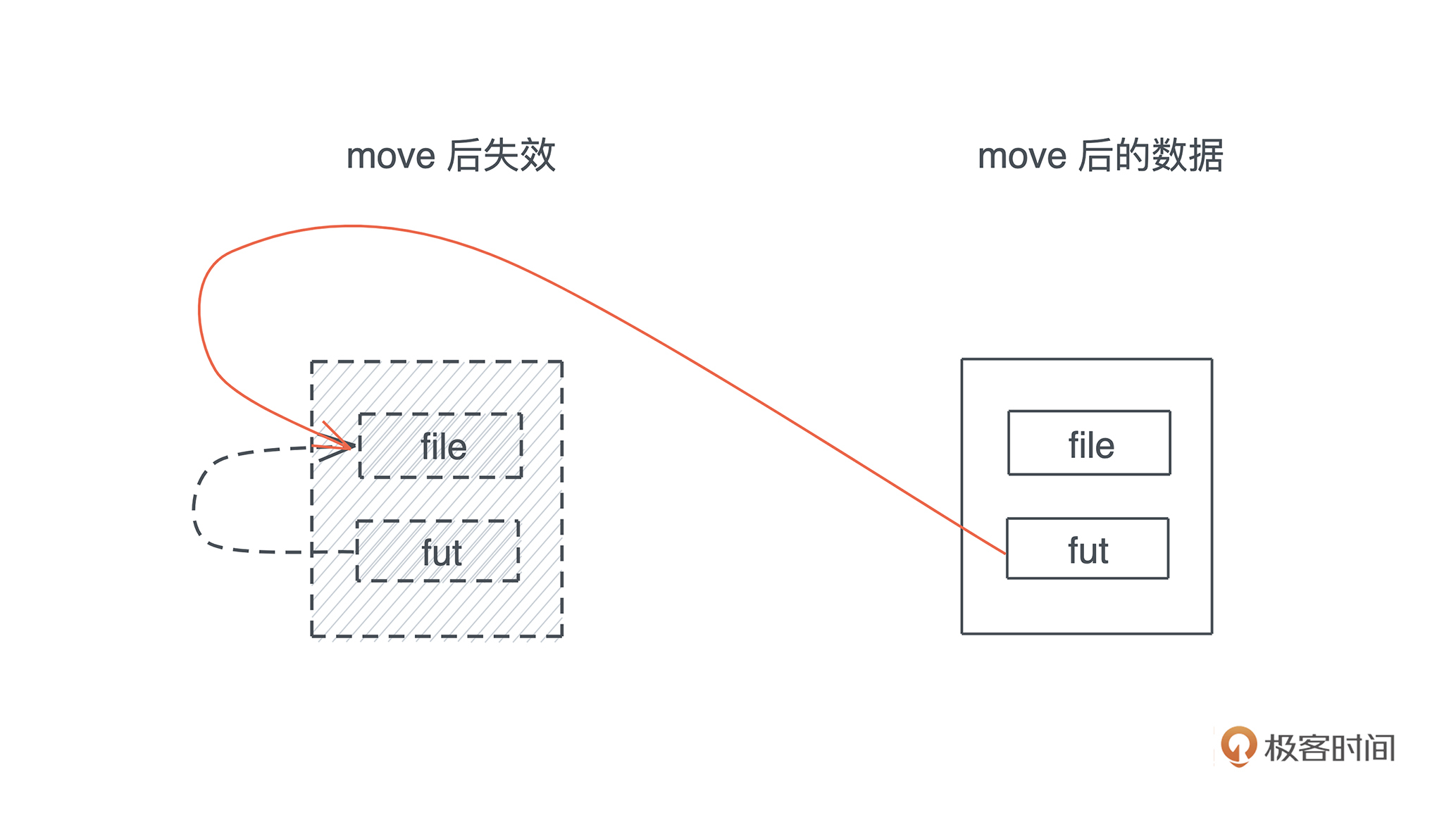
所以需要有某种机制来保证这种情况不会发生。Pin 就是为这个目的而设计的一个数据结构,我们可以 Pin 住指向一个 Future 的指针,看文稿中 Pin 的声明:
#![allow(unused)] fn main() { pub struct Pin<P> { pointer: P, } impl<P: Deref> Deref for Pin<P> { type Target = P::Target; fn deref(&self) -> &P::Target { Pin::get_ref(Pin::as_ref(self)) } } impl<P: DerefMut<Target: Unpin>> DerefMut for Pin<P> { fn deref_mut(&mut self) -> &mut P::Target { Pin::get_mut(Pin::as_mut(self)) } } }
Pin 拿住的是 一个可以解引用成 T 的指针类型 P,而不是直接拿原本的类型 T。所以,对于 Pin 而言,你看到的都是 Pin<Box
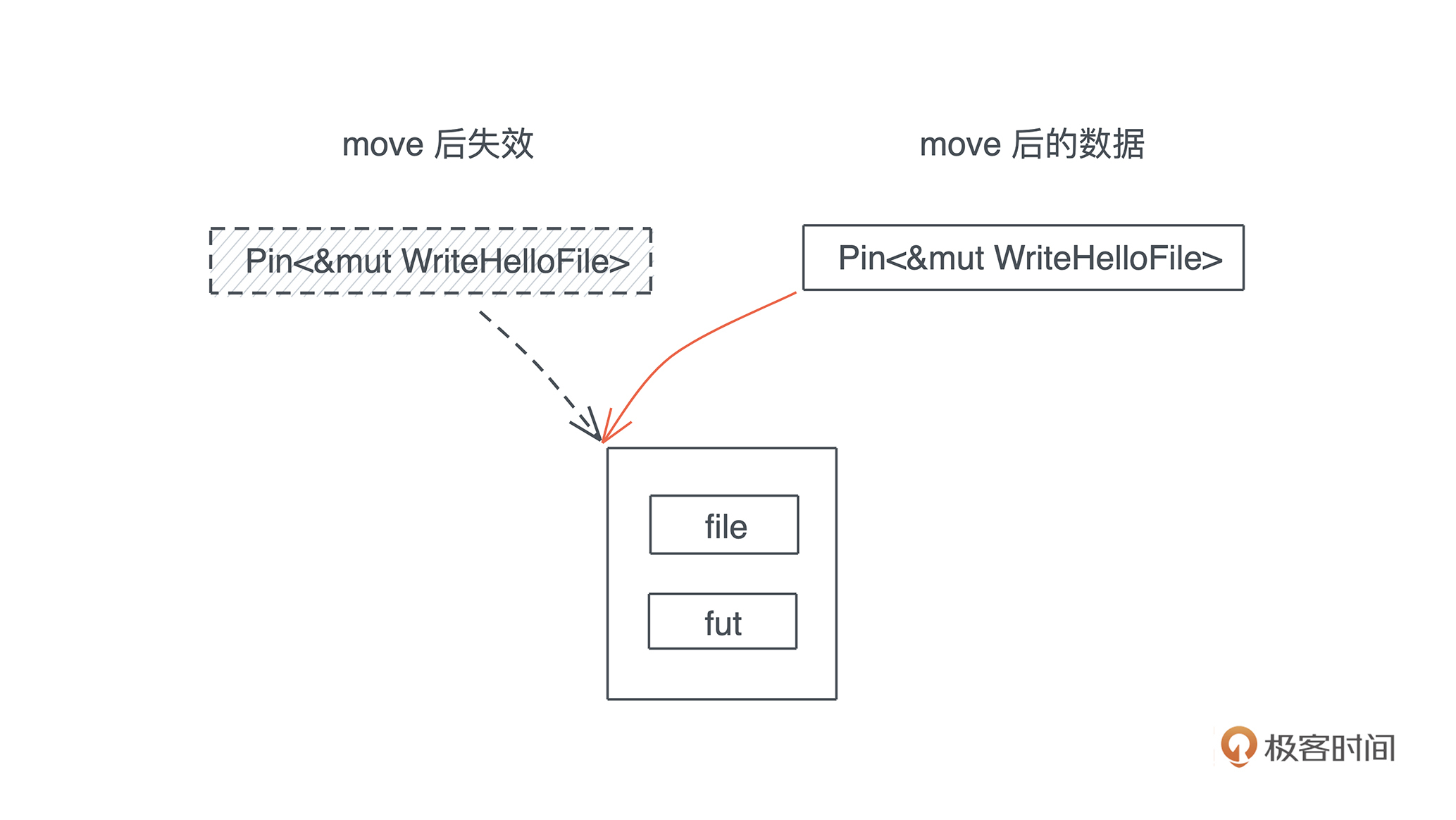
这样数据结构可以正常访问,但是你 无法直接 拿到原来的数据结构进而移动它。
自引用数据结构
当然,自引用数据结构并非只在异步代码里出现,只不过异步代码在内部生成用状态机表述的 Future 时,很容易产生自引用结构。我们看一个和 Future 无关的例子( 代码):
#[derive(Debug)] struct SelfReference { name: String, // 在初始化后指向 name name_ptr: *const String, } impl SelfReference { pub fn new(name: impl Into<String>) -> Self { SelfReference { name: name.into(), name_ptr: std::ptr::null(), } } pub fn init(&mut self) { self.name_ptr = &self.name as *const String; } pub fn print_name(&self) { println!( "struct {:p}: (name: {:p} name_ptr: {:p}), name: {}, name_ref: {}", self, &self.name, self.name_ptr, self.name, // 在使用 ptr 是需要 unsafe // SAFETY: 这里 name_ptr 潜在不安全,会指向旧的位置 unsafe { &*self.name_ptr }, ); } } fn main() { let data = move_creates_issue(); println!("data: {:?}", data); // 如果把下面这句注释掉,程序运行会直接 segment error // data.print_name(); print!("\\n"); mem_swap_creates_issue(); } fn move_creates_issue() -> SelfReference { let mut data = SelfReference::new("Tyr"); data.init(); // 不 move,一切正常 data.print_name(); let data = move_it(data); // move 之后,name_ref 指向的位置是已经失效的地址 // 只不过现在 move 前的地址还没被回收挪作它用 data.print_name(); data } fn mem_swap_creates_issue() { let mut data1 = SelfReference::new("Tyr"); data1.init(); let mut data2 = SelfReference::new("Lindsey"); data2.init(); data1.print_name(); data2.print_name(); std::mem::swap(&mut data1, &mut data2); data1.print_name(); data2.print_name(); } fn move_it(data: SelfReference) -> SelfReference { data }
我们创建了一个自引用结构 SelfReference,它里面的 name_ref 指向了 name。正常使用它时,没有任何问题,但一旦对这个结构做 move 操作,name_ref 指向的位置还会是 move 前 name 的地址,这就引发了问题。看下图:
同样的,如果我们使用 std::mem:swap,也会出现类似的问题,一旦 swap,两个数据的内容交换,然而,由于 name_ref 指向的地址还是旧的,所以整个指针体系都混乱了:
看代码的输出,辅助你理解:
#![allow(unused)] fn main() { struct 0x7ffeea91d6e8: (name: 0x7ffeea91d6e8 name_ptr: 0x7ffeea91d6e8), name: Tyr, name_ref: Tyr struct 0x7ffeea91d760: (name: 0x7ffeea91d760 name_ptr: 0x7ffeea91d6e8), name: Tyr, name_ref: Tyr data: SelfReference { name: "Tyr", name_ptr: 0x7ffeea91d6e8 } struct 0x7ffeea91d6f0: (name: 0x7ffeea91d6f0 name_ptr: 0x7ffeea91d6f0), name: Tyr, name_ref: Tyr struct 0x7ffeea91d710: (name: 0x7ffeea91d710 name_ptr: 0x7ffeea91d710), name: Lindsey, name_ref: Lindsey struct 0x7ffeea91d6f0: (name: 0x7ffeea91d6f0 name_ptr: 0x7ffeea91d710), name: Lindsey, name_ref: Tyr struct 0x7ffeea91d710: (name: 0x7ffeea91d710 name_ptr: 0x7ffeea91d6f0), name: Tyr, name_ref: Lindsey }
可以看到,swap 之后,name_ref 指向的内容确实和 name 不一样了。这就是自引用结构带来的问题。
你也许会奇怪,不是说 move 也会出问题么?为什么第二行打印 name_ref 还是指向了 “Tyr”?这是因为 move 后,之前的内存失效,但是内存地址还没有被挪作它用,所以还能正常显示 “Tyr”。 但这样的内存访问是不安全的,如果你把 main 中这句代码注释掉,程序就会 crash:
fn main() { let data = move_creates_issue(); println!("data: {:?}", data); // 如果把下面这句注释掉,程序运行会直接 segment error // data.print_name(); print!("\\n"); mem_swap_creates_issue(); }
现在你应该了解到在 Rust 下,自引用类型带来的潜在危害了吧。
所以,Pin 的出现,对解决这类问题很关键,如果你试图移动被 Pin 住的数据结构,要么,编译器会通过编译错误阻止你;要么,你强行使用 unsafe Rust,自己负责其安全性。我们来看使用 Pin 后如何避免移动带来的问题:
use std::{marker::PhantomPinned, pin::Pin}; #[derive(Debug)] struct SelfReference { name: String, // 在初始化后指向 name name_ptr: *const String, // PhantomPinned 占位符 _marker: PhantomPinned, } impl SelfReference { pub fn new(name: impl Into<String>) -> Self { SelfReference { name: name.into(), name_ptr: std::ptr::null(), _marker: PhantomPinned, } } pub fn init(self: Pin<&mut Self>) { let name_ptr = &self.name as *const String; // SAFETY: 这里并不会把任何数据从 &mut SelfReference 中移走 let this = unsafe { self.get_unchecked_mut() }; this.name_ptr = name_ptr; } pub fn print_name(self: Pin<&Self>) { println!( "struct {:p}: (name: {:p} name_ptr: {:p}), name: {}, name_ref: {}", self, &self.name, self.name_ptr, self.name, // 在使用 ptr 是需要 unsafe // SAFETY: 因为数据不会移动,所以这里 name_ptr 是安全的 unsafe { &*self.name_ptr }, ); } } fn main() { move_creates_issue(); } fn move_creates_issue() { let mut data = SelfReference::new("Tyr"); let mut data = unsafe { Pin::new_unchecked(&mut data) }; SelfReference::init(data.as_mut()); // 不 move,一切正常 data.as_ref().print_name(); // 现在只能拿到 pinned 后的数据,所以 move 不了之前 move_pinned(data.as_mut()); println!("{:?} ({:p})", data, &data); // 你无法拿回 Pin 之前的 SelfReference 结构,所以调用不了 move_it // move_it(data); } fn move_pinned(data: Pin<&mut SelfReference>) { println!("{:?} ({:p})", data, &data); } #[allow(dead_code)] fn move_it(data: SelfReference) { println!("{:?} ({:p})", data, &data); }
由于数据结构被包裹在 Pin 内部,所以在函数间传递时,变化的只是指向 data 的 Pin:
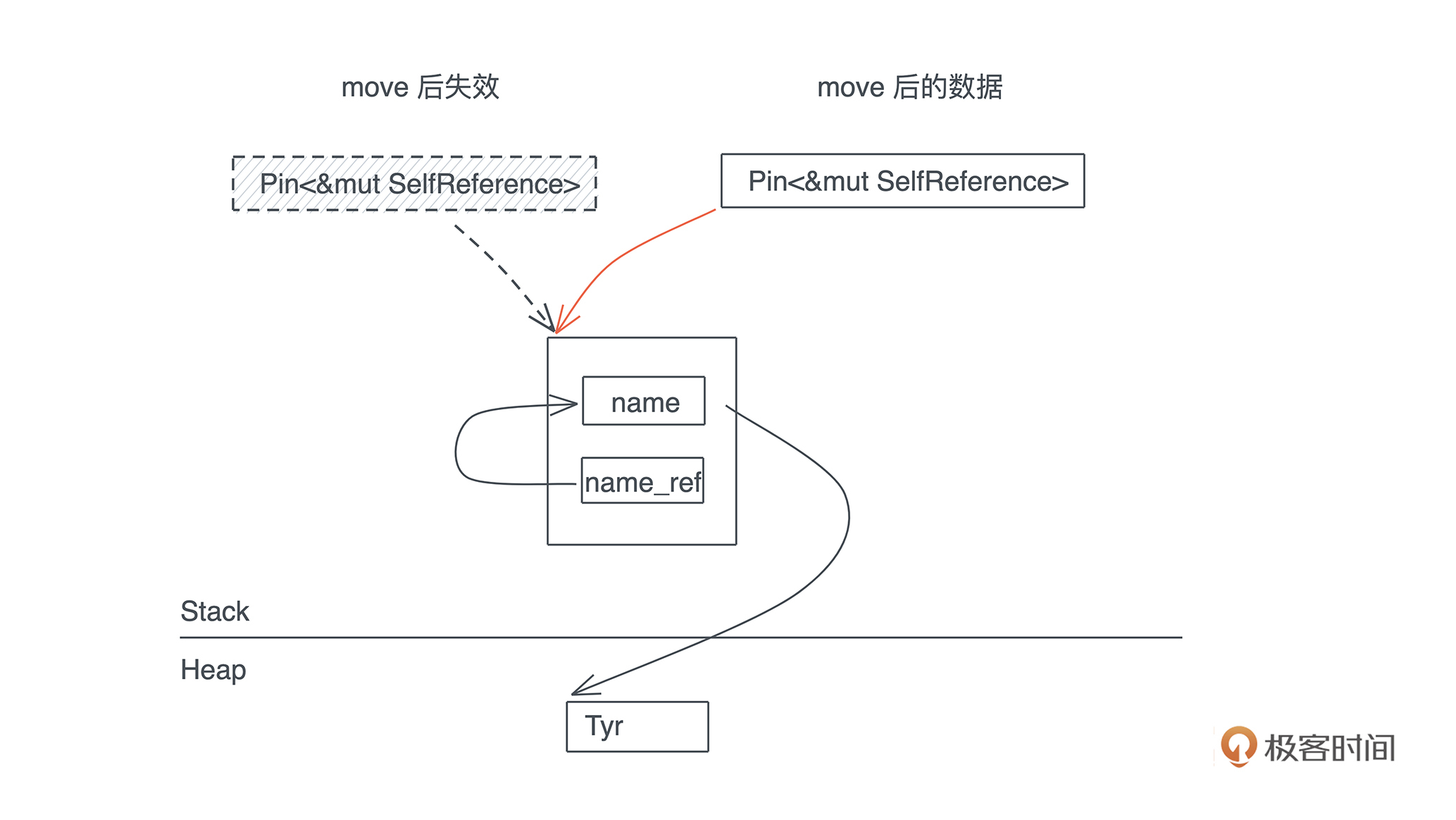
学习了Pin,不知道你有没有想起 Unpin 。
那么,Unpin 是做什么的?
我们在介绍 主要的系统 trait 时,曾经提及 Unpin 这个 marker trait:
#![allow(unused)] fn main() { pub auto trait Unpin {} }
Pin 是为了让某个数据结构无法合法地移动,而 Unpin 则相当于声明数据结构是可以移动的,它的作用类似于 Send / Sync,通过类型约束来告诉编译器哪些行为是合法的、哪些不是。
在 Rust 中,绝大多数数据结构都是可以移动的,所以它们都自动实现了 Unpin。即便这些结构被 Pin 包裹,它们依旧可以进行移动,比如:
#![allow(unused)] fn main() { use std::mem; use std::pin::Pin; let mut string = "this".to_string(); let mut pinned_string = Pin::new(&mut string); // We need a mutable reference to call `mem::replace`. // We can obtain such a reference by (implicitly) invoking `Pin::deref_mut`, // but that is only possible because `String` implements `Unpin`. mem::replace(&mut *pinned_string, "other".to_string()); }
当我们不希望一个数据结构被移动,可以使用 !Unpin。在 Rust 里,实现了 !Unpin 的,除了内部结构(比如 Future),主要就是 PhantomPinned:
#![allow(unused)] fn main() { pub struct PhantomPinned; impl !Unpin for PhantomPinned {} }
所以,如果你希望你的数据结构不能被移动,可以为其添加 PhantomPinned 字段来隐式声明 !Unpin。
当数据结构满足 Unpin 时,创建 Pin 以及使用 Pin(主要是 DerefMut)都可以使用安全接口,否则,需要使用 unsafe 接口:
#![allow(unused)] fn main() { // 如果实现了 Unpin,可以通过安全接口创建和进行 DerefMut impl<P: Deref<Target: Unpin>> Pin<P> { pub const fn new(pointer: P) -> Pin<P> { // SAFETY: the value pointed to is `Unpin`, and so has no requirements // around pinning. unsafe { Pin::new_unchecked(pointer) } } pub const fn into_inner(pin: Pin<P>) -> P { pin.pointer } } impl<P: DerefMut<Target: Unpin>> DerefMut for Pin<P> { fn deref_mut(&mut self) -> &mut P::Target { Pin::get_mut(Pin::as_mut(self)) } } // 如果没有实现 Unpin,只能通过 unsafe 接口创建,不能使用 DerefMut impl<P: Deref> Pin<P> { pub const unsafe fn new_unchecked(pointer: P) -> Pin<P> { Pin { pointer } } pub const unsafe fn into_inner_unchecked(pin: Pin<P>) -> P { pin.pointer } } }
async 产生的 Future 究竟是什么类型?
现在,我们对 Future 的接口有了一个完整的认识,也知道 async 关键字的背后都发生了什么事情:
#![allow(unused)] fn main() { pub trait Future { type Output; fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>; } }
那么,当你写一个 async fn 或者使用了一个 async block 时,究竟得到了一个什么类型的数据呢?比如:
#![allow(unused)] fn main() { let fut = async { 42 }; }
你肯定能拍着胸脯说,这个我知道,不就是 impl Future<Output = i32> 么?
对,但是 impl Future 不是一个具体的类型啊,我们讲过,它相当于 T: Future,那么这个 T 究竟是什么呢?我们来写段代码探索一下( 代码):
fn main() { let fut = async { 42 }; println!("type of fut is: {}", get_type_name(&fut)); } fn get_type_name<T>(_: &T) -> &'static str { std::any::type_name::<T>() }
它的输出如下:
#![allow(unused)] fn main() { type of fut is: core::future::from_generator::GenFuture<xxx::main::{{closure}}> }
哈,我们似乎发现了新大陆,实现 Future trait 的是一个叫 GenFuture 的结构,它内部有一个闭包。猜测这个闭包是 async { 42 } 产生的?
我们看 GenFuture 的定义(感兴趣可以在 Rust 源码中搜 from_generator),可以看到它是一个泛型结构,内部数据 T 要满足 Generator trait:
#![allow(unused)] fn main() { struct GenFuture<T: Generator<ResumeTy, Yield = ()>>(T); pub trait Generator<R = ()> { type Yield; type Return; fn resume( self: Pin<&mut Self>, arg: R ) -> GeneratorState<Self::Yield, Self::Return>; } }
Generator 是 Rust nightly 的一个 trait,还没有进入到标准库。大致看看官网展示的例子,它是怎么用的:
#![feature(generators, generator_trait)] use std::ops::{Generator, GeneratorState}; use std::pin::Pin; fn main() { let mut generator = || { yield 1; return "foo" }; match Pin::new(&mut generator).resume(()) { GeneratorState::Yielded(1) => {} _ => panic!("unexpected return from resume"), } match Pin::new(&mut generator).resume(()) { GeneratorState::Complete("foo") => {} _ => panic!("unexpected return from resume"), } }
可以看到,如果你创建一个闭包,里面有 yield 关键字,就会得到一个 Generator。如果你在 Python 中使用过 yield,二者其实非常类似。因为 Generator 是一个还没进入到稳定版的功能,大致了解一下就行,以后等它的 API 稳定后再仔细研究。
小结
这一讲我们深入地探讨了 Future 接口各个部分Context、Pin/Unpin的含义,以及 async/await 这样漂亮的接口之下会产生什么样子的代码。
对照下面这张图,我们回顾一下过去两讲的内容:
并发任务运行在 Future 这样的协程上时,async/await是产生和运行并发任务的手段,async 定义一个可以并发执行的Future任务,await 触发这个任务并发执行。具体来说:
当我们使用 async 关键字时,它会产生一个 impl Future 的结果。对于一个 async block 或者 async fn 来说,内部的每个 await 都会被编译器捕捉,并成为返回的 Future 的 poll() 方法的内部状态机的一个状态。
Rust 的 Future 需要异步运行时来运行 Future,以 tokio 为例,它的 executor 会从 run queue 中取出 Future 进行 poll(),当 poll() 返回 Pending 时,这个 Future 会被挂起,直到 reactor 得到了某个事件,唤醒这个 Future,将其添加回 run queue 等待下次执行。
tokio 一般会在每个物理线程(或者 CPU core)下运行一个线程,每个线程有自己的 run queue 来处理 Future。为了提供最大的吞吐量,tokio 实现了 work stealing scheduler,这样,当某个线程下没有可执行的 Future,它会从其它线程的 run queue 中“偷”一个执行。
思考题
如果一个数据结构 T: !Unpin,我们为其生成 Box
欢迎在留言区分享你的学习感悟和思考。
拓展阅读
观看 Jon Gjengset 的 The Why, What, and How of Pinning in Rust,进一步了解 Pin 和 Unpin。
感谢你的收听,如果你觉得有收获,也欢迎你分享给身边的朋友,邀他一起讨论。恭喜你完成了Rust学习的第39次打卡,我们下节课见。
异步处理:如何处理异步IO?
你好,我是陈天。
前面两讲我们学习了异步处理基本的功能和原理(Future/async/await),但是还没有正式介绍在具体场合下该用哪些工具来处理异步 IO。不过之前讲 trait 的时候,已经了解和使用过一些处理同步 IO 的结构和 trait。
今天我们就对比同步 IO 来学习异步 IO。毕竟在学习某个新知识的时候,如果能够和头脑中已有的知识联系起来,大脑神经元之间的连接就会被激活,学习的效果会事半功倍。
回忆一下同步环境都有哪些结构和 trait呢?首先,单个的值可以用类型 T 表述,一组值可以用 Iterator trait 表述;同步 IO,我们有标准的 Read/Write/Seek trait。顾名思义,Read/Write 是进行 IO 的读写,而 Seek 是在 IO 中前后移动当前的位置。
那么异步呢?我们已经学习到,对于单个的、在未来某个时刻会得到的值,可以用 Future 来表示:
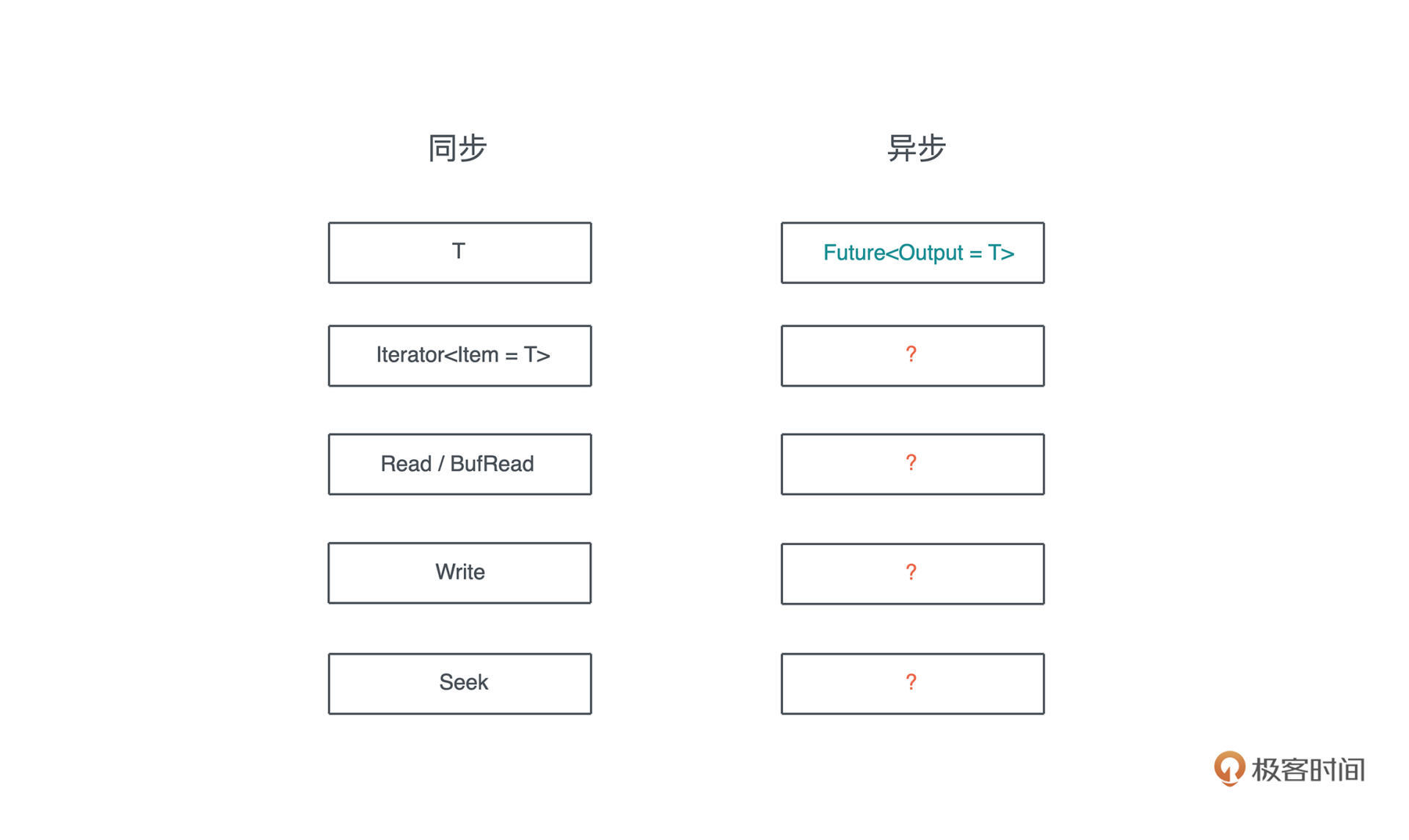
但还不知道一组未来才能得到的值该用什么 trait 来表述,也不知道异步的 Read/Write 该是什么样子。今天,我们就来聊聊这些重要的异步数据类型。
Stream trait
首先来了解一下 Iterator 在异步环境下的表兄弟:Stream。
我们知道,对于 Iterator,可以不断调用其 next() 方法,获得新的值,直到 Iterator 返回 None。Iterator 是阻塞式返回数据的,每次调用 next(),必然独占 CPU 直到得到一个结果, 而异步的 Stream 是非阻塞的,在等待的过程中会空出 CPU 做其他事情。
不过和 Future 已经在标准库稳定下来不同,Stream trait 目前还只能在 nightly 版本使用。一般跟 Stream 打交道,我们会使用 futures 库。来对比 Iterator 和 Stream的源码定义:
#![allow(unused)] fn main() { pub trait Iterator { type Item; fn next(&mut self) -> Option<Self::Item>; fn size_hint(&self) -> (usize, Option<usize>) { ... } fn map<B, F>(self, f: F) -> Map<Self, F> where F: FnMut(Self::Item) -> B { ... } ... // 还有 67 个方法 } pub trait Stream { type Item; fn poll_next(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Option<Self::Item>>; fn size_hint(&self) -> (usize, Option<usize>) { ... } } pub trait StreamExt: Stream { fn next(&mut self) -> Next<'_, Self> where Self: Unpin { ... } fn map<T, F>(self, f: F) -> Map<Self, F> where F: FnMut(Self::Item) -> T { ... } ... // 还有 41 个方法 } }
可以看到,Iterator 把所有方法都放在 Iterator trait 里,而Stream 把需要开发者实现的基本方法和有缺省实现的衍生方法区别开,放在不同的 trait 里。比如 map。
实现 Stream 的时候,和 Iterator 类似,你需要提供 Item 类型,这是每次拿出一个值时,值的类型;此外,还有 poll_next() 方法,它长得和 Future 的 poll() 方法很像,和 Iterator 版本的 next() 的作用类似。
然而,poll_next() 调用起来不方便,我们需要自己处理 Poll 状态,所以,StreamExt 提供了 next() 方法,返回一个实现了 Future trait 的 Next 结构,这样,我们就可以直接通过 stream.next().await 来获取下一个值了。来看 next() 方法以及 Next 结构的实现( 源码):
#![allow(unused)] fn main() { pub trait StreamExt: Stream { fn next(&mut self) -> Next<'_, Self> where Self: Unpin { assert_future::<Option<Self::Item>, _>(Next::new(self)) } } // next 返回了 Next 结构 pub struct Next<'a, St: ?Sized> { stream: &'a mut St, } // 如果 Stream Unpin 那么 Next 也是 Unpin impl<St: ?Sized + Unpin> Unpin for Next<'_, St> {} impl<'a, St: ?Sized + Stream + Unpin> Next<'a, St> { pub(super) fn new(stream: &'a mut St) -> Self { Self { stream } } } // Next 实现了 Future,每次 poll() 实际上就是从 stream 中 poll_next() impl<St: ?Sized + Stream + Unpin> Future for Next<'_, St> { type Output = Option<St::Item>; fn poll(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> { self.stream.poll_next_unpin(cx) } } }
看个小例子( 代码):
use futures::prelude::*; #[tokio::main] async fn main() { let mut st = stream::iter(1..10) .filter(|x| future::ready(x % 2 == 0)) .map(|x| x * x); while let Some(x) = st.next().await { println!("Got item: {}", x); } }
我们使用 stream::iter 生成了一个 Stream,并对其进行 filter / map 的操作。最后,遍历整个 stream,把获得的数据打印出来。从使用的感受来看,Stream 和 Iterator 也很相似,可以对比着来用。
生成 Stream
futures 库提供了一些基本的生成 Stream 的方法,除了上面用到的 iter 方法,还有:
- empty():生成一个空的 Stream
- once():生成一个只包含单个值的 Stream
- pending():生成一个不包含任何值,只返回 Poll::Pending 的 Stream
- repeat():生成一个一直返回相同值的 Stream
- repeat_with():通过闭包函数无穷尽地返回数据的 Stream
- poll_fn():通过一个返回 Poll<Option
> 的闭包来产生 Stream - unfold():通过初始值和返回 Future 的闭包来产生 Stream
前几种产生 Stream 的方法都很好理解,最后三种引入了闭包复杂一点,我们分别使用它们来实现斐波那契数列,对比一下差异( 代码):
use futures::{prelude::*, stream::poll_fn}; use std::task::Poll; #[tokio::main] async fn main() { consume(fib().take(10)).await; consume(fib1(10)).await; // unfold 产生的 Unfold stream 没有实现 Unpin, // 所以我们将其 Pin<Box<T>> 一下,使其满足 consume 的接口 consume(fib2(10).boxed()).await; } async fn consume(mut st: impl Stream<Item = i32> + Unpin) { while let Some(v) = st.next().await { print!("{} ", v); } print!("\\n"); } // 使用 repeat_with 创建 stream,无法控制何时结束 fn fib() -> impl Stream<Item = i32> { let mut a = 1; let mut b = 1; stream::repeat_with(move || { let c = a + b; a = b; b = c; b }) } // 使用 poll_fn 创建 stream,可以通过返回 Poll::Ready(None) 来结束 fn fib1(mut n: usize) -> impl Stream<Item = i32> { let mut a = 1; let mut b = 1; poll_fn(move |_cx| -> Poll<Option<i32>> { if n == 0 { return Poll::Ready(None); } n -= 1; let c = a + b; a = b; b = c; Poll::Ready(Some(b)) }) } fn fib2(n: usize) -> impl Stream<Item = i32> { stream::unfold((n, (1, 1)), |(mut n, (a, b))| async move { if n == 0 { None } else { n -= 1; let c = a + b; // c 作为 poll_next() 的返回值,(n, (a, b)) 作为 state Some((c, (n, (b, c)))) } }) }
值得注意的是, 使用 unfold 的时候,同时使用了局部变量和 Future,所以生成的 Stream 没有实现 Unpin,我们在使用的时候,需要将其 pin 住。怎么做呢?
Pin<Box
除了上面讲的方法,我们还可以为一个数据结构实现 Stream trait,从而使其支持 Stream。看一个例子( 代码):
use futures::prelude::*; use pin_project::pin_project; use std::{ pin::Pin, task::{Context, Poll}, }; use tokio::{ fs, io::{AsyncBufReadExt, AsyncRead, BufReader, Lines}, }; /// LineStream 内部使用 tokio::io::Lines #[pin_project] struct LineStream<R> { #[pin] lines: Lines<BufReader<R>>, } impl<R: AsyncRead> LineStream<R> { /// 从 BufReader 创建一个 LineStream pub fn new(reader: BufReader<R>) -> Self { Self { lines: reader.lines(), } } } /// 为 LineStream 实现 Stream trait impl<R: AsyncRead> Stream for LineStream<R> { type Item = std::io::Result<String>; fn poll_next(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Option<Self::Item>> { self.project() .lines .poll_next_line(cx) .map(Result::transpose) } } #[tokio::main] async fn main() -> std::io::Result<()> { let file = fs::File::open("Cargo.toml").await?; let reader = BufReader::new(file); let mut st = LineStream::new(reader); while let Some(Ok(line)) = st.next().await { println!("Got: {}", line); } Ok(()) }
这段代码封装了 Lines 结构,我们可以通过 AsyncBufReadExt 的 lines() 方法,把一个实现了 AsyncBufRead trait 的 reader 转换成 Lines。
你也许注意到代码中引入的 pin_project 库,它提供了一些便利的宏,方便我们操作数据结构里需要被 pin 住的字段。在数据结构中, 可以使用 #[pin] 来声明某个字段在使用的时候需要被封装为 Pin
在Lines这个结构内部,异步的 next_line() 方法可以读取下一行,它实际上就是比较低阶的 poll_next_line() 接口的一个封装。
虽然 Lines 结构提供了 next_line(),但并没有实现 Stream,所以我们无法像其他 Stream 那样统一用 next() 方法获取下一行。于是,我们将其包裹在自己的 LineStream 下,并且为 LineStream 实现了 Stream 方法。
注意,由于 poll_next_line() 的结果是 Result<Option
异步 IO 接口
在实现 LineStream 时,我们遇到了两个异步 I/O 接口:AsyncRead 以及 AsyncBufRead。回到开头的那张表,相信你现在已经有大致答案了吧: 所有同步的 Read / Write / Seek trait,前面加一个 Async,就构成了对应的异步 IO 接口。
不过,和 Stream 不同的是,如果你对比 futures 下定义的 IO trait 以及 tokio 下定义的 IO trait,会发现它们都有各自的定义,双方并未统一,有些许的差别:
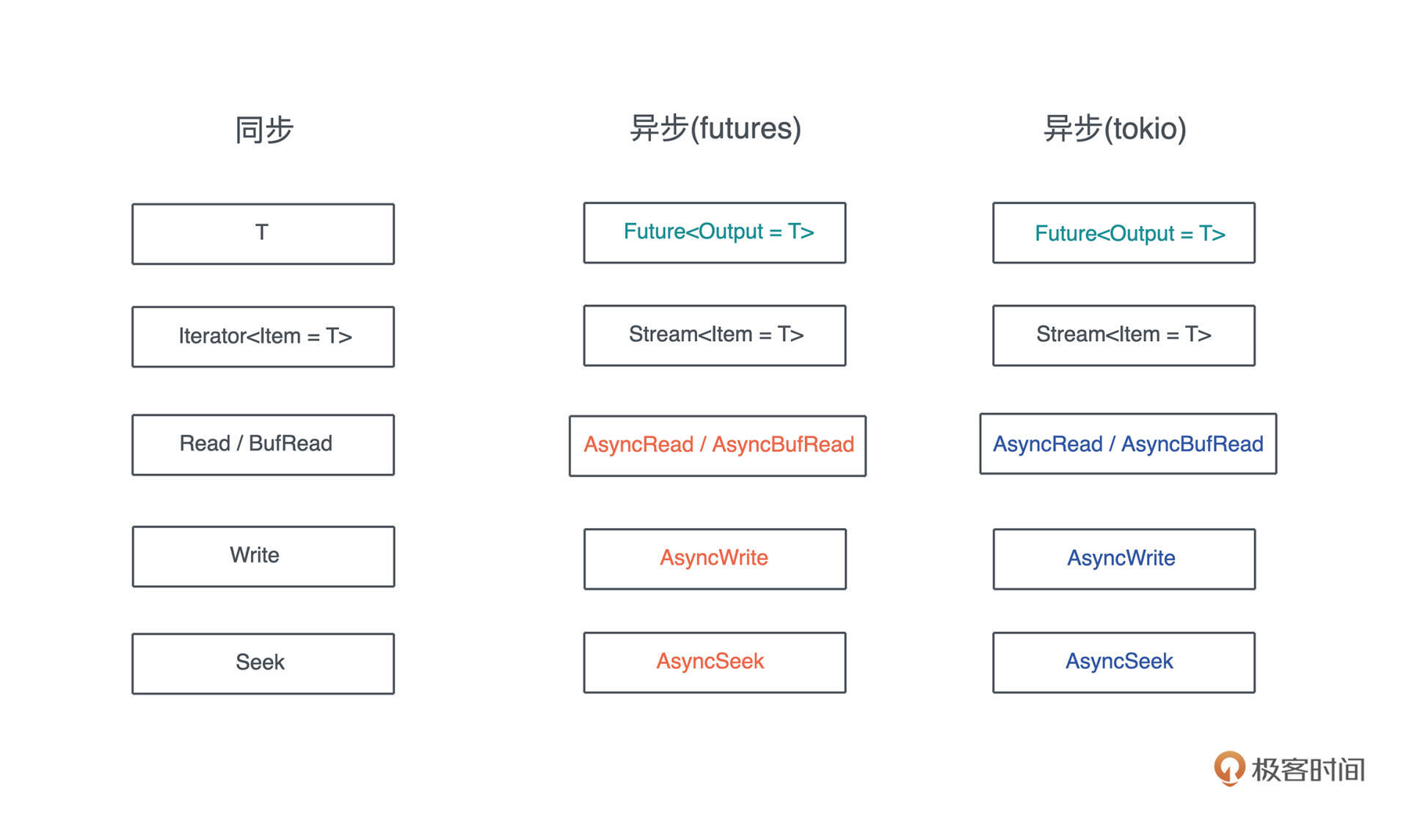
比如 futures 下 AsyncRead 的定义:
#![allow(unused)] fn main() { pub trait AsyncRead { fn poll_read( self: Pin<&mut Self>, cx: &mut Context<'_>, buf: &mut [u8] ) -> Poll<Result<usize, Error>>; unsafe fn initializer(&self) -> Initializer { ... } fn poll_read_vectored( self: Pin<&mut Self>, cx: &mut Context<'_>, bufs: &mut [IoSliceMut<'_>] ) -> Poll<Result<usize, Error>> { ... } } }
而 tokio 下 AsyncRead 的定义:
#![allow(unused)] fn main() { pub trait AsyncRead { fn poll_read( self: Pin<&mut Self>, cx: &mut Context<'_>, buf: &mut ReadBuf<'_> ) -> Poll<Result<()>>; } }
我们看不同之处:tokio 的 poll_read() 方法需要 ReadBuf,而 futures 的 poll_read() 方法需要 &mut [u8]。此外,futures 的 AsyncRead 还多了两个缺省方法。
再看 AsyncWrite。futures 下的 AsyncWrite 接口如下:
#![allow(unused)] fn main() { pub trait AsyncWrite { fn poll_write( self: Pin<&mut Self>, cx: &mut Context<'_>, buf: &[u8] ) -> Poll<Result<usize, Error>>; fn poll_flush( self: Pin<&mut Self>, cx: &mut Context<'_> ) -> Poll<Result<(), Error>>; fn poll_close( self: Pin<&mut Self>, cx: &mut Context<'_> ) -> Poll<Result<(), Error>>; fn poll_write_vectored( self: Pin<&mut Self>, cx: &mut Context<'_>, bufs: &[IoSlice<'_>] ) -> Poll<Result<usize, Error>> { ... } } }
而 tokio 下的 AsyncWrite 的定义:
#![allow(unused)] fn main() { pub trait AsyncWrite { fn poll_write( self: Pin<&mut Self>, cx: &mut Context<'_>, buf: &[u8] ) -> Poll<Result<usize, Error>>; fn poll_flush( self: Pin<&mut Self>, cx: &mut Context<'_> ) -> Poll<Result<(), Error>>; fn poll_shutdown( self: Pin<&mut Self>, cx: &mut Context<'_> ) -> Poll<Result<(), Error>>; fn poll_write_vectored( self: Pin<&mut Self>, cx: &mut Context<'_>, bufs: &[IoSlice<'_>] ) -> Poll<Result<usize, Error>> { ... } fn is_write_vectored(&self) -> bool { ... } } }
可以看到,AsyncWrite 二者的差距就只有 poll_close() 和 poll_shutdown() 命名上的分别。其它的异步 IO 接口我就不一一举例了,你可以自己去看代码对比。
异步 IO 接口的兼容性处理
为什么 Rust 的异步 IO trait 会有这样的分裂?这是因为在 tokio / futures 库实现的早期,社区还没有形成比较统一的异步 IO trait,不同的接口背后也有各自不同的考虑,这种分裂就沿袭下来。
所以,如果我们使用 tokio 进行异步开发,那么,代码需要使用 tokio::io 下的异步 IO trait。也许,未来等 Async IO trait 稳定并进入标准库后,tokio 会更新自己的 trait。
虽然 Rust 的异步 IO trait 有这样的分裂,你也不必过分担心。 tokio-util 提供了相应的 Compat 功能,可以让你的数据结构在二者之间自如切换。看一个使用 yamux 做多路复用的例子,重点位置详细注释了:
use anyhow::Result; use futures::prelude::*; use tokio::net::TcpListener; use tokio_util::{ codec::{Framed, LinesCodec}, compat::{FuturesAsyncReadCompatExt, TokioAsyncReadCompatExt}, }; use tracing::info; use yamux::{Config, Connection, Mode, WindowUpdateMode}; #[tokio::main] async fn main() -> Result<()> { tracing_subscriber::fmt::init(); let addr = "0.0.0.0:8080"; let listener = TcpListener::bind(addr).await?; info!("Listening on: {:?}", addr); loop { let (stream, addr) = listener.accept().await?; info!("Accepted: {:?}", addr); let mut config = Config::default(); config.set_window_update_mode(WindowUpdateMode::OnRead); // 使用 compat() 方法把 tokio AsyncRead/AsyncWrite 转换成 futures 对应的 trait let conn = Connection::new(stream.compat(), config, Mode::Server); // Yamux ctrl stream 可以用来打开新的 stream let _ctrl = conn.control(); tokio::spawn( yamux::into_stream(conn).try_for_each_concurrent(None, move |s| async move { // 使用 compat() 方法把 futures AsyncRead/AsyncWrite 转换成 tokio 对应的 trait let mut framed = Framed::new(s.compat(), LinesCodec::new()); while let Some(Ok(line)) = framed.next().await { println!("Got: {}", line); framed .send(format!("Hello! I got '{}'", line)) .await .unwrap(); } Ok(()) }), ); } }
yamux 是一个类似 HTTP/2 内部多路复用机制的协议,可以让你在一个 TCP 连接上打开多个逻辑 yamux stream,而yamux stream 之间并行工作,互不干扰。
yamux crate 在实现的时候,使用了 futures 下的异步 IO 接口。但是当我们使用 tokio Listener 接受一个客户端,得到对应的 TcpStream 时,这个 TcpStream 使用的是 tokio 下的异步 IO 接口。所以我们需要 tokio_util::compat 来协助接口的兼容。
在代码中,首先我用 stream.compat() 生成一个 Compat 结构,供 yamux Connection 使用:
#![allow(unused)] fn main() { let conn = Connection::new(stream.compat(), config, Mode::Server); }
之后,拿到 yamux connection 下所有 stream 进行处理时,我们想用 tokio 的 Frame 和 Codec 一行行读取和写入,也就需要把使用 futures 异步接口的 yamux stream,转换成使用 tokio 接口的数据结构,这样就可以用在 Framed::new() 中:
#![allow(unused)] fn main() { let mut framed = Framed::new(s.compat(), LinesCodec::new()); }
如果你想运行这段代码,可以看这门课的 GitHub repo 下的完整版,包括依赖以及客户端的代码。
实现异步 IO 接口
异步 IO 主要应用在文件处理、网络处理等场合,而这些场合的数据结构都已经实现了对应的接口,比如 File 或者 TcpStream,它们也已经实现了 AsyncRead / AsyncWrite。所以基本上,我们不用自己实现异步 IO 接口,只需要会用就可以了。
不过有些情况,我们可能会把已有的数据结构封装在自己的数据结构中,此时,也应该实现相应的异步 IO 接口( 代码):
use anyhow::Result; use pin_project::pin_project; use std::{ pin::Pin, task::{Context, Poll}, }; use tokio::{ fs::File, io::{AsyncRead, AsyncReadExt, ReadBuf}, }; #[pin_project] struct FileWrapper { #[pin] file: File, } impl FileWrapper { pub async fn try_new(name: &str) -> Result<Self> { let file = File::open(name).await?; Ok(Self { file }) } } impl AsyncRead for FileWrapper { fn poll_read( self: Pin<&mut Self>, cx: &mut Context<'_>, buf: &mut ReadBuf<'_>, ) -> Poll<std::io::Result<()>> { self.project().file.poll_read(cx, buf) } } #[tokio::main] async fn main() -> Result<()> { let mut file = FileWrapper::try_new("./Cargo.toml").await?; let mut buffer = String::new(); file.read_to_string(&mut buffer).await?; println!("{}", buffer); Ok(()) }
这段代码封装了 tokio::fs::File 结构,我们想读取内部的 file 字段,但又不想把 File 暴露出来,因此实现了 AsyncRead trait。
Sink trait
在同步环境下往 IO 中发送连续的数据,可以一次性发送,也可以使用 Write trait 多次发送,使用起来并没有什么麻烦;但在异步 IO 下,做同样的事情,我们需要更方便的接口。因此异步IO还有一个比较独特的 Sink trait,它是一个用于发送一系列异步值的接口。
看 Sink trait 的定义:
#![allow(unused)] fn main() { pub trait Sink<Item> { type Error; fn poll_ready( self: Pin<&mut Self>, cx: &mut Context<'_> ) -> Poll<Result<(), Self::Error>>; fn start_send(self: Pin<&mut Self>, item: Item) -> Result<(), Self::Error>; fn poll_flush( self: Pin<&mut Self>, cx: &mut Context<'_> ) -> Poll<Result<(), Self::Error>>; fn poll_close( self: Pin<&mut Self>, cx: &mut Context<'_> ) -> Poll<Result<(), Self::Error>>; } pub trait SinkExt<Item>: Sink<Item> { ... fn send(&mut self, item: Item) -> Send<'_, Self, Item> where Self: Unpin { ... } ... } }
和 Stream trait 不同的是,Sink trait 的 Item 是 trait 的泛型参数,而不是关联类型。 一般而言,当 trait 接受某个 input,应该使用泛型参数,比如 Add
Item 对于 Sink 来说是输入,所以使用泛型参数是正确的选择。因为这也意味着,在发送端,可以发送不同类型的数据结构。
看上面的定义源码,Sink trait 有四个方法:
- poll_ready():用来准备 Sink 使其可以发送数据。只有 poll_ready() 返回 Poll::Ready(Ok(())) 后,Sink 才会开展后续的动作。poll_ready() 可以用来控制背压。
- start_send():开始发送数据到 Sink。但是start_send() 并不保证数据被发送完毕,所以调用者要调用 poll_flush() 或者 poll_close() 来保证完整发送。
- poll_flush():将任何尚未发送的数据 flush 到这个 Sink。
- poll_close():将任何尚未发送的数据 flush 到这个 Sink,并关闭这个 Sink。
其中三个方法和 Item 是无关的,这会导致,如果不同的输入类型有多个实现,Sink的poll_ready、poll_flush 和 poll_close 可能会有重复的代码。所以一般我们在使用 Sink 时,如果确实需要处理不同的数据类型,可以用 enum 将它们统一(感兴趣的话,可以进一步阅读这个 讨论)。
我们就用一个简单的 FileSink 的例子,看看如何实现这些方法。tokio::fs 下的 File 结构已经实现了 AsyncRead / AsyncWrite,我们只需要在 Sink 的几个方法中调用 AsyncWrite 的方法即可( 代码):
use anyhow::Result; use bytes::{BufMut, BytesMut}; use futures::{Sink, SinkExt}; use pin_project::pin_project; use std::{ pin::Pin, task::{Context, Poll}, }; use tokio::{fs::File, io::AsyncWrite}; #[pin_project] struct FileSink { #[pin] file: File, buf: BytesMut, } impl FileSink { pub fn new(file: File) -> Self { Self { file, buf: BytesMut::new(), } } } impl Sink<&str> for FileSink { type Error = std::io::Error; fn poll_ready(self: Pin<&mut Self>, _cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>> { Poll::Ready(Ok(())) } fn start_send(self: Pin<&mut Self>, item: &str) -> Result<(), Self::Error> { let this = self.project(); eprint!("{}", item); this.buf.put(item.as_bytes()); Ok(()) } fn poll_flush(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>> { // 如果想 project() 多次,需要先把 self reborrow 一下 let this = self.as_mut().project(); let buf = this.buf.split_to(this.buf.len()); if buf.is_empty() { return Poll::Ready(Ok(())); } // 写入文件 if let Err(e) = futures::ready!(this.file.poll_write(cx, &buf[..])) { return Poll::Ready(Err(e)); } // 刷新文件 self.project().file.poll_flush(cx) } fn poll_close(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>> { let this = self.project(); // 结束写入 this.file.poll_shutdown(cx) } } #[tokio::main] async fn main() -> Result<()> { let file_sink = FileSink::new(File::create("/tmp/hello").await?); // pin_mut 可以把变量 pin 住 futures::pin_mut!(file_sink); file_sink.send("hello\\n").await?; file_sink.send("world!\\n").await?; file_sink.send("Tyr!\\n").await?; Ok(()) }
对于 poll_ready() 方法,直接返回 Poll::Ready(Ok(()))。
在 start_send() 方法中,我们把传入的 item,写入 FileSink 的 BytesMut 中。然后在 poll_flush() 时,我们拿到 buf,把已有的内容调用 split_to(),得到一个包含所有未写入文件的新 buffer。这个 buffer 和 self 无关,所以传入 poll_write() 时,不会有对 self 的引用问题。
在写入文件后,我们再次调用 poll_flush() ,确保写入的内容刷新到磁盘上。最后,在 poll_close() 时调用 poll_shutdown() 关闭文件。
这段代码虽然实现了 Sink trait,也展示了如何实现 Sink 的几个方法,但是这么简单的一个问题,处理起来还是颇为费劲。有没有更简单的方法呢?
有的。futures 里提供了 sink::unfold 方法,类似 stream::unfold,我们来重写上面的 File Sink 的例子( 代码):
use anyhow::Result; use futures::prelude::*; use tokio::{fs::File, io::AsyncWriteExt}; #[tokio::main] async fn main() -> Result<()> { let file_sink = writer(File::create("/tmp/hello").await?); // pin_mut 可以把变量 pin 住 futures::pin_mut!(file_sink); if let Err(_) = file_sink.send("hello\\n").await { println!("Error on send"); } if let Err(_) = file_sink.send("world!\\n").await { println!("Error on send"); } Ok(()) } /// 使用 unfold 生成一个 Sink 数据结构 fn writer<'a>(file: File) -> impl Sink<&'a str> { sink::unfold(file, |mut file, line: &'a str| async move { file.write_all(line.as_bytes()).await?; eprint!("Received: {}", line); Ok::<_, std::io::Error>(file) }) }
可以看到,通过 unfold 方法,我们不需要撰写 Sink 的几个方法了,而且可以在一个返回 Future 的闭包中来提供处理逻辑,这就意味着我们可以不使用 poll_xxx 这样的方法,直接在闭包中使用这样的异步函数:
#![allow(unused)] fn main() { file.write_all(line.as_bytes()).await? }
你看,短短 5 行代码,就实现了刚才五十多行代码要表达的逻辑。
小结
今天我们学习了和异步 IO 相关的 Stream / Sink trait,以及和异步读写相关的 AsyncRead / AsyncWrite 等 trait。在学习异步 IO 时,很多内容都可以和同步 IO 的处理对比着学,这样事半功倍。
在处理异步 IO 时,底层的 poll_xxx() 函数很难写,因为它的约束很多。好在有 pin_project 这个项目,用宏帮我们解决了很多关于 Pin/Unpin 的问题。
一般情况下,我们不太需要直接实现 Stream / Sink / AsyncRead / AsyncWrite trait,如果的确需要,先看看有没有可以使用的辅助函数,比如通过 poll_fn / unfold 创建 Stream、通过 unfold 创建 Sink。
思考题
我们知道 tokio:sync::mpsc 下有支持异步的 MPSC channel,生产者可以通过 send() 发送消息,消费者可以通过 recv() 来接收消息。你能不能为其封装 Sink 和 Stream 的实现,让 MPSC channel 可以像 Stream / Sink 一样使用?(提示:tokio-stream 有 ReceiverStream 的实现)。
欢迎在留言区分享你的思考和学习收获,感谢收听,恭喜你已经完成了rust学习的40次打卡,如果觉得有收获,也欢迎分享给你身边的朋友,邀他一起讨论。我们下节课见。
阶段实操(6):构建一个简单的KV server-异步处理
你好,我是陈天。
到目前为止,我们已经一起完成了一个相对完善的 KV server。还记得是怎么一步步构建这个服务的么?
基础篇学完,我们搭好了KV server 的基础功能( 21讲、 22讲),构造了客户端和服务器间交互的 protobuf,然后设计了 CommandService trait 和 Storage trait,分别处理客户端命令和存储。
在进阶篇掌握了trait的实战使用技巧之后,( 26讲)我们进一步构造了 Service 数据结构,接收 CommandRequest,根据其类型调用相应的 CommandService 处理,并做合适的事件通知,最后返回 CommandResponse。
但所有这一切都发生在同步的世界:不管数据是怎么获得的,数据已经在那里,我们需要做的就是把一种数据类型转换成另一种数据类型的运算而已。
之后我们涉足网络的世界。( 36讲)为 KV server 构造了自己的 frame:一个包含长度和是否压缩的信息的 4 字节的头,以及实际的 payload;还设计了一个 FrameCoder 来对 frame 进行封包和拆包,这为接下来构造网络接口打下了坚实的基础。考虑到网络安全,( 37讲)我们提供了 TLS 的支持。
在构建 ProstStream 的时候,我们开始处理异步:ProstStream 内部的 stream 需要支持 AsyncRead + AsyncWrite,这可以让 ProstStream 适配包括 TcpStream 和 TlsStream 在内的一切实现了 AsyncRead 和 AsyncWrite 的异步网络接口。
至此,我们打通了从远端得到一个命令,历经 TCP、TLS,然后被 FrameCoder 解出来一个 CommandRequest,交由 Service 来处理的过程。 把同步世界和异步世界连接起来的,就是 ProstServerStream 这个结构。
这个从收包处理到处理完成后发包的完整流程和系统结构,可以看下图:
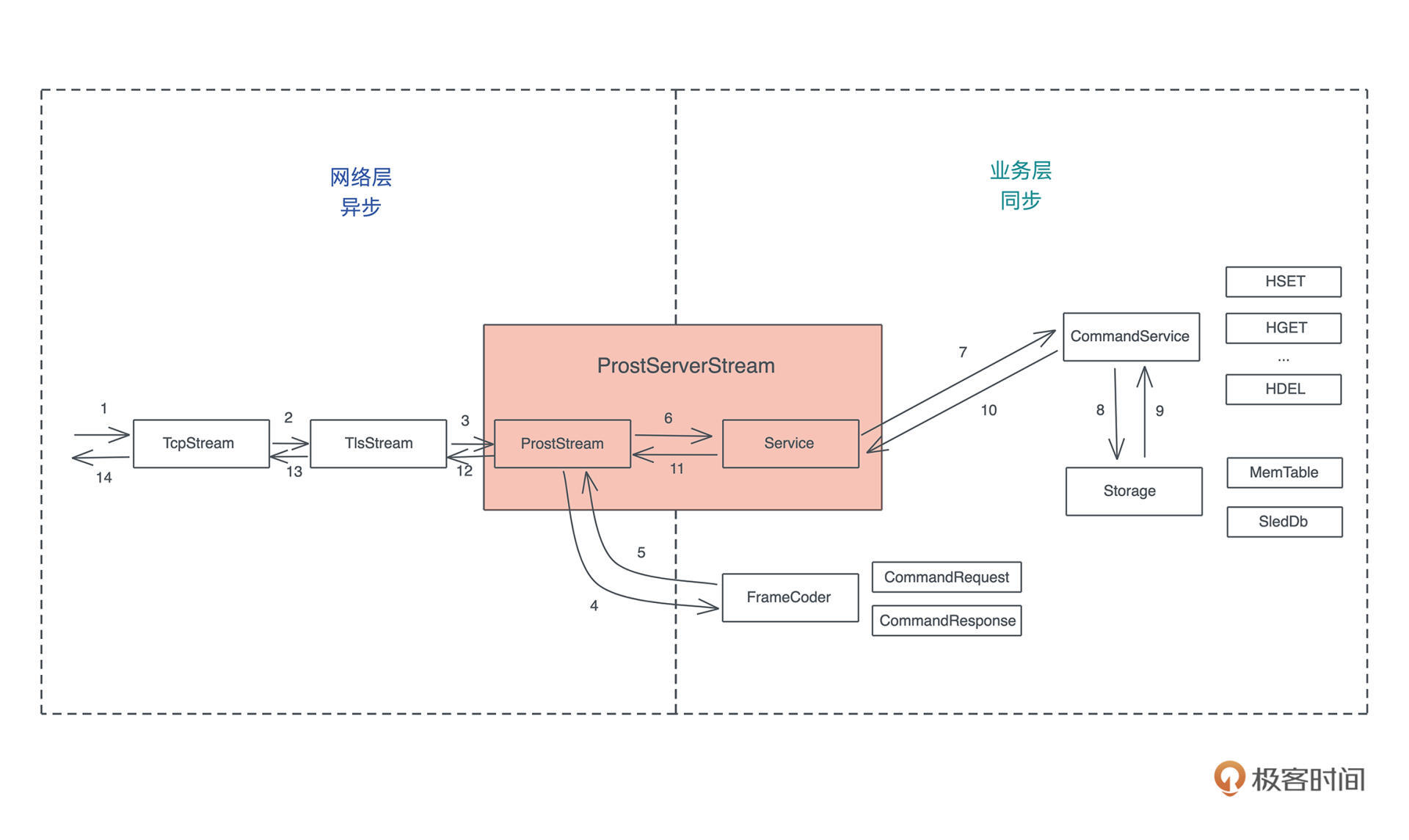
今天做点什么?
虽然我们很早就已经撰写了不少异步或者和异步有关的代码。但是最能体现 Rust 异步本质的 poll()、poll_read()、poll_next() 这样的处理函数还没有怎么写过,之前测试异步的 read_frame() 写过一个 DummyStream,算是体验了一下底层的异步处理函数的复杂接口。不过在 DummyStream 里,我们并没有做任何复杂的动作:
#![allow(unused)] fn main() { struct DummyStream { buf: BytesMut, } impl AsyncRead for DummyStream { fn poll_read( self: std::pin::Pin<&mut Self>, _cx: &mut std::task::Context<'_>, buf: &mut tokio::io::ReadBuf<'_>, ) -> std::task::Poll<std::io::Result<()>> { // 看看 ReadBuf 需要多大的数据 let len = buf.capacity(); // split 出这么大的数据 let data = self.get_mut().buf.split_to(len); // 拷贝给 ReadBuf buf.put_slice(&data); // 直接完工 std::task::Poll::Ready(Ok(())) } } }
上一讲我们学习了异步 IO,这堂课我们就学以致用,对现有的代码做些重构,让核心的 ProstStream 更符合 Rust 的异步 IO 接口逻辑。具体要做点什么呢?
看之前写的 ProstServerStream 的 process() 函数,比较一下它和 async_prost 库的 AsyncProst 的调用逻辑:
#![allow(unused)] fn main() { // process() 函数的内在逻辑 while let Ok(cmd) = self.recv().await { info!("Got a new command: {:?}", cmd); let res = self.service.execute(cmd); self.send(res).await?; } // async_prost 库的 AsyncProst 的调用逻辑 while let Some(Ok(cmd)) = stream.next().await { info!("Got a new command: {:?}", cmd); let res = svc.execute(cmd); stream.send(res).await.unwrap(); } }
可以看到由于 AsyncProst 实现了 Stream 和 Sink,能更加自然地调用 StreamExt trait 的 next() 方法和 SinkExt trait 的 send() 方法,来处理数据的收发,而 ProstServerStream 则自己额外实现了函数 recv() 和 send()。
虽然从代码对比的角度,这两段代码几乎一样,但未来的可扩展性,和整个异步生态的融洽性上,AsyncProst 还是更胜一筹。
所以今天我们就构造一个 ProstStream 结构,让它实现 Stream 和 Sink 这两个 trait,然后让 ProstServerStream 和 ProstClientStream 使用它。
创建 ProstStream
在开始重构之前,先来简单复习一下 Stream trait 和 Sink trait:
#![allow(unused)] fn main() { // 可以类比 Iterator pub trait Stream { // 从 Stream 中读取到的数据类型 type Item; // 从 stream 里读取下一个数据 fn poll_next( self: Pin<&mut Self>, cx: &mut Context<'_> ) -> Poll<Option<Self::Item>>; } // pub trait Sink<Item> { type Error; fn poll_ready( self: Pin<&mut Self>, cx: &mut Context<'_> ) -> Poll<Result<(), Self::Error>>; fn start_send(self: Pin<&mut Self>, item: Item) -> Result<(), Self::Error>; fn poll_flush( self: Pin<&mut Self>, cx: &mut Context<'_> ) -> Poll<Result<(), Self::Error>>; fn poll_close( self: Pin<&mut Self>, cx: &mut Context<'_> ) -> Poll<Result<(), Self::Error>>; } }
那么 ProstStream 具体需要包含什么类型呢?
因为它的主要职责是从底下的 stream 中读取或者发送数据,所以一个支持 AsyncRead 和 AsyncWrite 的泛型参数 S 是必然需要的。
另外 Stream trait 和 Sink 都各需要一个 Item 类型,对于我们的系统来说,Item 是 CommandRequest 或者 CommandResponse,但为了灵活性,我们可以用 In 和 Out 这两个泛型参数来表示。
当然,在处理 Stream 和 Sink 时还需要 read buffer 和 write buffer。
综上所述,我们的 ProstStream 结构看上去是这样子的:
#![allow(unused)] fn main() { pub struct ProstStream<S, In, Out> { // innner stream stream: S, // 写缓存 wbuf: BytesMut, // 读缓存 rbuf: BytesMut, } }
然而,Rust 不允许数据结构有超出需要的泛型参数。怎么办?别急,可以用 PhantomData,之前讲过它是一个零字节大小的占位符,可以让我们的数据结构携带未使用的泛型参数。
好,现在有足够的思路了,我们创建 src/network/stream.rs,添加如下代码(记得在 src/network/mod.rs 添加对 stream.rs 的引用):
#![allow(unused)] fn main() { use bytes::BytesMut; use futures::{Sink, Stream}; use std::{ marker::PhantomData, pin::Pin, task::{Context, Poll}, }; use tokio::io::{AsyncRead, AsyncWrite}; use crate::{FrameCoder, KvError}; /// 处理 KV server prost frame 的 stream pub struct ProstStream<S, In, Out> where { // innner stream stream: S, // 写缓存 wbuf: BytesMut, // 读缓存 rbuf: BytesMut, // 类型占位符 _in: PhantomData<In>, _out: PhantomData<Out>, } impl<S, In, Out> Stream for ProstStream<S, In, Out> where S: AsyncRead + AsyncWrite + Unpin + Send, In: Unpin + Send + FrameCoder, Out: Unpin + Send, { /// 当调用 next() 时,得到 Result<In, KvError> type Item = Result<In, KvError>; fn poll_next(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Option<Self::Item>> { todo!() } } /// 当调用 send() 时,会把 Out 发出去 impl<S, In, Out> Sink<Out> for ProstStream<S, In, Out> where S: AsyncRead + AsyncWrite + Unpin, In: Unpin + Send, Out: Unpin + Send + FrameCoder, { /// 如果发送出错,会返回 KvError type Error = KvError; fn poll_ready(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>> { todo!() } fn start_send(self: Pin<&mut Self>, item: Out) -> Result<(), Self::Error> { todo!() } fn poll_flush(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>> { todo!() } fn poll_close(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>> { todo!() } } }
这段代码包含了为 ProstStream 实现 Stream 和 Sink 的骨架代码。接下来我们就一个个处理。注意对于 In 和 Out 参数,还为其约束了 FrameCoder,这样,在实现里我们可以使用 decode_frame() 和 encode_frame() 来获取一个 Item 或者 encode 一个 Item。
Stream 的实现
先来实现 Stream 的 poll_next() 方法。
poll_next() 可以直接调用我们之前写好的 read_frame(),然后再用 decode_frame() 来解包:
#![allow(unused)] fn main() { fn poll_next(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Option<Self::Item>> { // 上一次调用结束后 rbuf 应该为空 assert!(self.rbuf.len() == 0); // 从 rbuf 中分离出 rest(摆脱对 self 的引用) let mut rest = self.rbuf.split_off(0); // 使用 read_frame 来获取数据 let fut = read_frame(&mut self.stream, &mut rest); ready!(Box::pin(fut).poll_unpin(cx))?; // 拿到一个 frame 的数据,把 buffer 合并回去 self.rbuf.unsplit(rest); // 调用 decode_frame 获取解包后的数据 Poll::Ready(Some(In::decode_frame(&mut self.rbuf))) } }
这个不难理解,但中间这段需要稍微解释一下:
#![allow(unused)] fn main() { // 使用 read_frame 来获取数据 let fut = read_frame(&mut self.stream, &mut rest); ready!(Box::pin(fut).poll_unpin(cx))?; }
因为 poll_xxx() 方法已经是 async/await 的底层 API 实现,所以我们在 poll_xxx() 方法中,是不能直接使用异步函数的,需要把它看作一个 future,然后调用 future 的 poll 函数。因为 future 是一个 trait,所以需要 Box 将其处理成一个在堆上的 trait object,这样就可以调用 FutureExt 的 poll_unpin() 方法了。Box::pin 会生成 Pin
至于 ready! 宏,它会在 Pending 时直接 return Pending,而在 Ready 时,返回 Ready 的值:
#![allow(unused)] fn main() { macro_rules! ready { ($e:expr $(,)?) => { match $e { $crate::task::Poll::Ready(t) => t, $crate::task::Poll::Pending => return $crate::task::Poll::Pending, } }; } }
Stream 我们就实现好了,是不是也没有那么复杂?
Sink 的实现
再写Sink,看上去要实现好几个方法,其实也不算复杂。四个方法 poll_ready、start_send()、poll_flush 和 poll_close 我们再回顾一下。
poll_ready() 是做背压的,你可以根据负载来决定要不要返回 Poll::Ready。对于我们的网络层来说,可以先不关心背压,依靠操作系统的 TCP 协议栈提供背压处理即可,所以这里直接返回 Poll::Ready(Ok(())),也就是说,上层想写数据,可以随时写。
#![allow(unused)] fn main() { fn poll_ready(self: Pin<&mut Self>, _cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>> { Poll::Ready(Ok(())) } }
当 poll_ready() 返回 Ready 后,Sink 就走到 start_send()。我们在 start_send() 里就把必要的数据准备好。这里把 item 封包成字节流,存入 wbuf 中:
#![allow(unused)] fn main() { fn start_send(self: Pin<&mut Self>, item: Out) -> Result<(), Self::Error> { let this = self.get_mut(); item.encode_frame(&mut this.wbuf)?; Ok(()) } }
然后在 poll_flush() 中,我们开始写数据。这里需要记录当前写到哪里,所以需要在 ProstStream 里加一个字段 written,记录写入了多少字节:
#![allow(unused)] fn main() { /// 处理 KV server prost frame 的 stream pub struct ProstStream<S, In, Out> { // innner stream stream: S, // 写缓存 wbuf: BytesMut, // 写入了多少字节 written: usize, // 读缓存 rbuf: BytesMut, // 类型占位符 _in: PhantomData<In>, _out: PhantomData<Out>, } }
有了这个 written 字段, 就可以循环写入:
#![allow(unused)] fn main() { fn poll_flush(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>> { let this = self.get_mut(); // 循环写入 stream 中 while this.written != this.wbuf.len() { let n = ready!(Pin::new(&mut this.stream).poll_write(cx, &this.wbuf[this.written..]))?; this.written += n; } // 清除 wbuf this.wbuf.clear(); this.written = 0; // 调用 stream 的 poll_flush 确保写入 ready!(Pin::new(&mut this.stream).poll_flush(cx)?); Poll::Ready(Ok(())) } }
最后是 poll_close(),我们只需要调用 stream 的 flush 和 shutdown 方法,确保数据写完并且 stream 关闭:
#![allow(unused)] fn main() { fn poll_close(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Result<(), Self::Error>> { // 调用 stream 的 poll_flush 确保写入 ready!(self.as_mut().poll_flush(cx))?; // 调用 stream 的 poll_shutdown 确保 stream 关闭 ready!(Pin::new(&mut self.stream).poll_shutdown(cx))?; Poll::Ready(Ok(())) } }
ProstStream 的创建
我们的 ProstStream 目前已经实现了 Stream 和 Sink,为了方便使用,再构建一些辅助方法,比如 new():
#![allow(unused)] fn main() { impl<S, In, Out> ProstStream<S, In, Out> where S: AsyncRead + AsyncWrite + Send + Unpin, { /// 创建一个 ProstStream pub fn new(stream: S) -> Self { Self { stream, written: 0, wbuf: BytesMut::new(), rbuf: BytesMut::new(), _in: PhantomData::default(), _out: PhantomData::default(), } } } // 一般来说,如果我们的 Stream 是 Unpin,最好实现一下 impl<S, Req, Res> Unpin for ProstStream<S, Req, Res> where S: Unpin {} }
此外,我们还为其实现 Unpin trait,这会给别人在使用你的代码时带来很多方便。 一般来说,为异步操作而创建的数据结构,如果使用了泛型参数,那么只要内部没有自引用数据,就应该实现 Unpin。
测试!
又到了重要的测试环节。我们需要写点测试来确保 ProstStream 能正常工作。因为之前在 src/network/ frame.rs 中写了个 DummyStream,实现了 AsyncRead,我们只需要扩展它,让它再实现 AsyncWrite。
为了让它可以被复用,我们将其从 frame.rs 中移出来,放在 src/network/mod.rs 中,并修改成下面的样子(记得在 frame.rs 的测试里 use 新的 DummyStream):
#![allow(unused)] fn main() { #[cfg(test)] pub mod utils { use bytes::{BufMut, BytesMut}; use std::task::Poll; use tokio::io::{AsyncRead, AsyncWrite}; pub struct DummyStream { pub buf: BytesMut, } impl AsyncRead for DummyStream { fn poll_read( self: std::pin::Pin<&mut Self>, _cx: &mut std::task::Context<'_>, buf: &mut tokio::io::ReadBuf<'_>, ) -> Poll<std::io::Result<()>> { let len = buf.capacity(); let data = self.get_mut().buf.split_to(len); buf.put_slice(&data); Poll::Ready(Ok(())) } } impl AsyncWrite for DummyStream { fn poll_write( self: std::pin::Pin<&mut Self>, _cx: &mut std::task::Context<'_>, buf: &[u8], ) -> Poll<Result<usize, std::io::Error>> { self.get_mut().buf.put_slice(buf); Poll::Ready(Ok(buf.len())) } fn poll_flush( self: std::pin::Pin<&mut Self>, _cx: &mut std::task::Context<'_>, ) -> Poll<Result<(), std::io::Error>> { Poll::Ready(Ok(())) } fn poll_shutdown( self: std::pin::Pin<&mut Self>, _cx: &mut std::task::Context<'_>, ) -> Poll<Result<(), std::io::Error>> { Poll::Ready(Ok(())) } } } }
好,这样我们就可以在 src/network/stream.rs 下写个测试了:
#![allow(unused)] fn main() { #[cfg(test)] mod tests { use super::*; use crate::{utils::DummyStream, CommandRequest}; use anyhow::Result; use futures::prelude::*; #[tokio::test] async fn prost_stream_should_work() -> Result<()> { let buf = BytesMut::new(); let stream = DummyStream { buf }; let mut stream = ProstStream::<_, CommandRequest, CommandRequest>::new(stream); let cmd = CommandRequest::new_hdel("t1", "k1"); stream.send(cmd.clone()).await?; if let Some(Ok(s)) = stream.next().await { assert_eq!(s, cmd); } else { assert!(false); } Ok(()) } } }
运行 cargo test ,一切测试通过!(如果你编译错误,可能缺少 use 的问题,可以自行修改,或者参考 GitHub 上的完整代码)。
使用 ProstStream
接下来,我们可以让 ProstServerStream 和 ProstClientStream 使用新定义的 ProstStream 了,你可以参考下面的对比,看看二者的区别:
#![allow(unused)] fn main() { // 旧的接口 // pub struct ProstServerStream<S> { // inner: S, // service: Service, // } pub struct ProstServerStream<S> { inner: ProstStream<S, CommandRequest, CommandResponse>, service: Service, } // 旧的接口 // pub struct ProstClientStream<S> { // inner: S, // } pub struct ProstClientStream<S> { inner: ProstStream<S, CommandResponse, CommandRequest>, } }
然后删除 send() / recv() 函数,并修改 process() / execute() 函数使其使用 next() 方法和 send() 方法。主要的改动如下:
#![allow(unused)] fn main() { /// 处理服务器端的某个 accept 下来的 socket 的读写 pub struct ProstServerStream<S> { inner: ProstStream<S, CommandRequest, CommandResponse>, service: Service, } /// 处理客户端 socket 的读写 pub struct ProstClientStream<S> { inner: ProstStream<S, CommandResponse, CommandRequest>, } impl<S> ProstServerStream<S> where S: AsyncRead + AsyncWrite + Unpin + Send, { pub fn new(stream: S, service: Service) -> Self { Self { inner: ProstStream::new(stream), service, } } pub async fn process(mut self) -> Result<(), KvError> { let stream = &mut self.inner; while let Some(Ok(cmd)) = stream.next().await { info!("Got a new command: {:?}", cmd); let res = self.service.execute(cmd); stream.send(res).await.unwrap(); } Ok(()) } } impl<S> ProstClientStream<S> where S: AsyncRead + AsyncWrite + Unpin + Send, { pub fn new(stream: S) -> Self { Self { inner: ProstStream::new(stream), } } pub async fn execute(&mut self, cmd: CommandRequest) -> Result<CommandResponse, KvError> { let stream = &mut self.inner; stream.send(cmd).await?; match stream.next().await { Some(v) => v, None => Err(KvError::Internal("Didn't get any response".into())), } } } }
再次运行 cargo test ,所有的测试应该都能通过。同样如果有编译错误,可能是缺少了引用。
我们也可以打开一个命令行窗口,运行: RUST_LOG=info cargo run --bin kvs --quiet。然后在另一个命令行窗口,运行: RUST_LOG=info cargo run --bin kvc --quiet。此时,服务器和客户端都收到了彼此的请求和响应,并且处理正常!
我们重构了 ProstServerStream 和 ProstClientStream 的代码,使其内部使用更符合 futures 库里 Stream / Sink trait 的用法,整体代码改动不小,但是内部实现的变更并不影响系统的其它部分!这简直太棒了!
小结
在实际开发中,进行重构来改善既有代码的质量是必不可少的。之前在开发 KV server 的过程中,我们在不断地进行一些小的重构。
今天我们做了个稍微大一些的重构,为已有的代码提供更加符合异步 IO 接口的功能。从对外使用的角度来说,它并没有提供或者满足任何额外的需求,但是从代码结构和质量的角度,它使得我们的 ProstStream 可以更方便和更直观地被其它接口调用,也更容易跟整个 Rust 的现有生态结合起来。
你可能会好奇,为什么可以这么自然地进行代码重构?这是因为我们有足够的单元测试覆盖来打底。
就像生物的进化一样,好的代码是在良性的重构中不断演进出来的, 而良性的重构,是在优秀的单元测试的监管下,使代码朝着正确方向迈出的步伐。在这里,单元测试扮演着生物进化中自然环境的角色,把重构过程中的错误一一扼杀。
思考题
- 为什么在创建 ProstStream 时,要在数据结构中放 wbuf / rbuf 和 written 字段?为什么不能用局部变量?
- 仔细阅读 Stream 和 Sink 的文档。尝试写代码构造实现 Stream 和 Sink 的简单数据结构。
欢迎在留言区分享你的思考和学习收获,感谢你的收听,你已经完成了Rust学习的第41次打卡啦,我们下节课见。
阶段实操(7):构建一个简单的KV server-如何做大的重构?
你好,我是陈天。
在软件开发的过程中,一开始设计得再精良,也扛不住无缘无故的需求变更。所以我们要妥善做架构设计,让它能满足潜在的需求;但也不能过度设计,让它去适应一些虚无缥缈的需求。好的开发者,要能够把握这个度。
到目前为止,我们的 KV server 已经羽翼丰满,作为一个基本的 KV 存储够用了。
这时候,产品经理突然抽风,想让你在这个 Server 上加上类似 Redis 的 Pub/Sub 支持。你说:别闹,这根本就是两个产品。产品经理回应: Redis 也支持 Pub/Sub。你怼回去:那干脆用 Redis 的 Pub/Sub 得了。产品经理听了哈哈一笑:行,用 Redis 挺好,我们还能把你的工钱省下来呢。天都聊到这份上了,你只好妥协:那啥,姐,我做,我做还不行么?
这虽是个虚构的故事,但类似的大需求变更在我们开发者的日常工作中相当常见。我们就以这个具备不小难度的挑战,来看看,如何对一个已经成形的系统进行大的重构。
现有架构分析
先简单回顾一下 Redis 对 Pub/Sub 的支持:客户端可以随时发起 SUBSCRIBE、PUBLISH 和 UNSUBSCRIBE。如果客户端 A 和 B SUBSCRIBE 了一个叫 lobby 的主题,客户端 C 往 lobby 里发了 “hello”,A 和 B 都将立即收到这个信息。
使用起来是这个样子的:
#![allow(unused)] fn main() { A: SUBSCRIBE "lobby" A: SUBSCRIBE "王者荣耀" B: SUBSCRIBE "lobby" C: PUBLISH "lobby" "hello" // A/B 都收到 "hello" B: UNSUBSCRIBE "lobby" B: SUBSCRIBE "王者荣耀" D: PUBLISH "lobby" "goodbye" // 只有 A 收到 "goodbye" C: PUBLISH "王者荣耀" "good game" // A/B 都收到 "good game" }
带着这个需求,我们重新审视目前的架构:
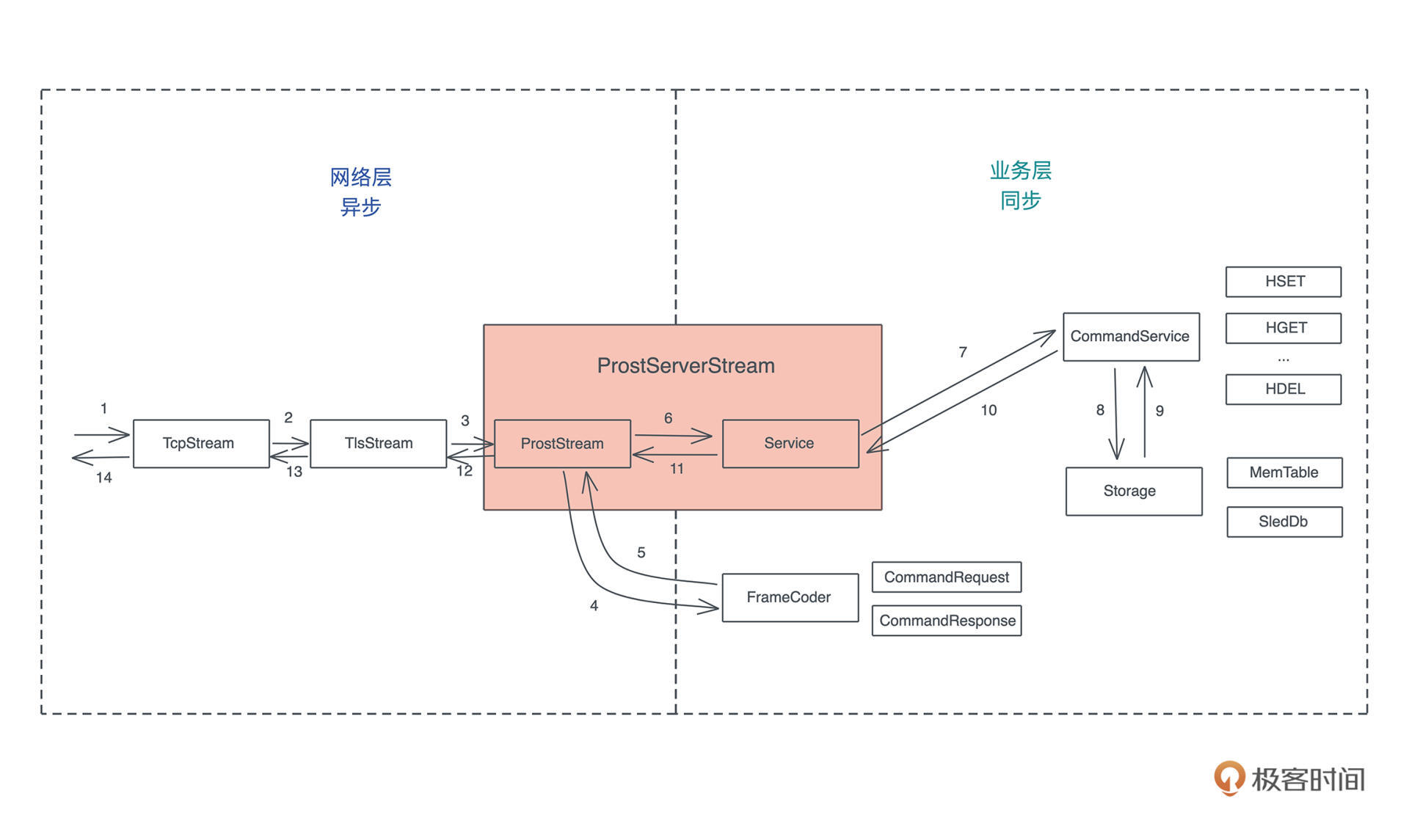
要支持 Pub/Sub,现有架构有两个很大的问题。
首先,CommandService 是一个同步的处理,来一个命令,立刻就能计算出一个值返回。但现在来一个 SUBSCRIBE 命令,它期待的不是一个值,而是未来可能产生的若干个值。我们讲过 Stream 代表未来可能产生的一系列值,所以这里需要返回一个异步的 Stream。
因此,我们要么需要牺牲 CommandService 这个 trait 来适应新的需求,要么构建一个新的、和 CommandService trait 并列的 trait,来处理和 Pub/Sub 有关的命令。
其次, 如果直接在 TCP/TLS 之上构建 Pub/Sub 的支持,我们需要在 Request 和 Response 之间建立“流”的概念,为什么呢?
之前我们的协议运行模式是同步的,一来一回:
但是,如果继续采用这样的方式,就会有应用层的 head of line blocking(队头阻塞)问题,一个 SUBSCRIBE 命令,因为其返回结果不知道什么时候才结束,会阻塞后续的所有命令。所以,我们需要在一个连接里,划分出很多彼此独立的“流”,让它们的收发不受影响:
这种流式处理的典型协议是使用了多路复用(multiplex)的 HTTP/2。所以,一种方案是我们可以把 KV server 构建在使用 HTTP/2 的 gRPC 上。不过,HTTP 是个太过庞杂的协议,对于 KV server 这种性能非常重要的服务来说,不必要的额外开销太多,所以它不太适合。
另一种方式是使用 Yamux 协议,之前介绍过,它是一个简单的、和 HTTP/2 内部多路复用机制非常类似的协议。如果使用它,整个协议的交互看上去是这个样子的:
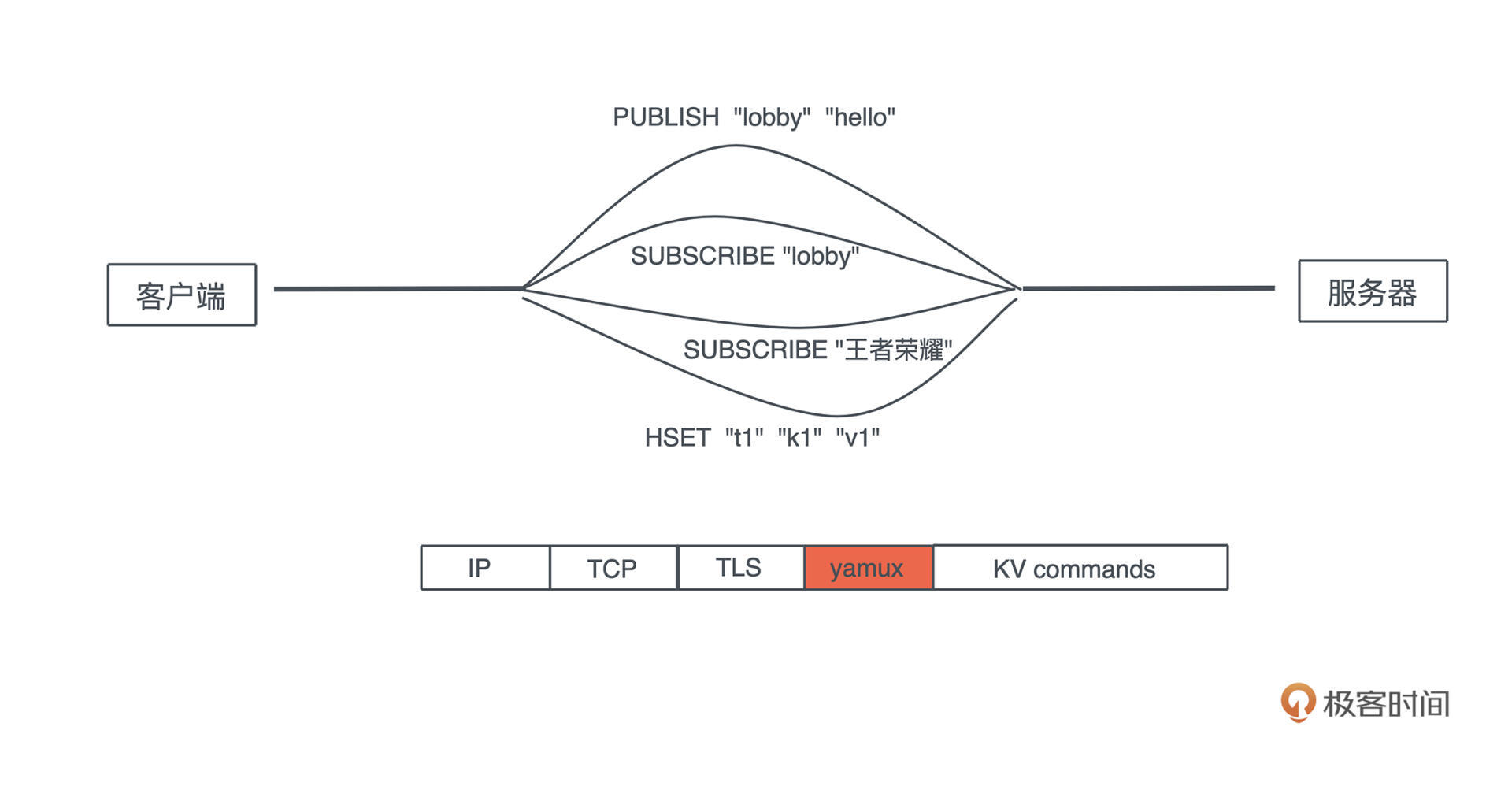
Yamux 适合不希望引入 HTTP 的繁文缛节(大量的头信息),在 TCP 层做多路复用的场景,今天就用它来支持我们所要实现的 Pub/Sub。
使用 yamux 做多路复用
Rust 下有 rust-yamux 这个库,来支持 yamux。除此之外,我们还需要 tokio-util,它提供了 tokio 下的 trait 和 futures 下的 trait 的兼容能力。在 Cargo.toml 中引入它们:
#![allow(unused)] fn main() { [dependencies] ... tokio-util = { version = "0.6", features = ["compat"]} # tokio 和 futures 的兼容性库 ... yamux = "0.9" # yamux 多路复用支持 ... }
然后创建 src/network/multiplex.rs(记得在 mod.rs 里引用),添入如下代码:
#![allow(unused)] fn main() { use futures::{future, Future, TryStreamExt}; use std::marker::PhantomData; use tokio::io::{AsyncRead, AsyncWrite}; use tokio_util::compat::{Compat, FuturesAsyncReadCompatExt, TokioAsyncReadCompatExt}; use yamux::{Config, Connection, ConnectionError, Control, Mode, WindowUpdateMode}; /// Yamux 控制结构 pub struct YamuxCtrl<S> { /// yamux control,用于创建新的 stream ctrl: Control, _conn: PhantomData<S>, } impl<S> YamuxCtrl<S> where S: AsyncRead + AsyncWrite + Unpin + Send + 'static, { /// 创建 yamux 客户端 pub fn new_client(stream: S, config: Option<Config>) -> Self { Self::new(stream, config, true, |_stream| future::ready(Ok(()))) } /// 创建 yamux 服务端,服务端我们需要具体处理 stream pub fn new_server<F, Fut>(stream: S, config: Option<Config>, f: F) -> Self where F: FnMut(yamux::Stream) -> Fut, F: Send + 'static, Fut: Future<Output = Result<(), ConnectionError>> + Send + 'static, { Self::new(stream, config, false, f) } // 创建 YamuxCtrl fn new<F, Fut>(stream: S, config: Option<Config>, is_client: bool, f: F) -> Self where F: FnMut(yamux::Stream) -> Fut, F: Send + 'static, Fut: Future<Output = Result<(), ConnectionError>> + Send + 'static, { let mode = if is_client { Mode::Client } else { Mode::Server }; // 创建 config let mut config = config.unwrap_or_default(); config.set_window_update_mode(WindowUpdateMode::OnRead); // 创建 config,yamux::Stream 使用的是 futures 的 trait 所以需要 compat() 到 tokio 的 trait let conn = Connection::new(stream.compat(), config, mode); // 创建 yamux ctrl let ctrl = conn.control(); // pull 所有 stream 下的数据 tokio::spawn(yamux::into_stream(conn).try_for_each_concurrent(None, f)); Self { ctrl, _conn: PhantomData::default(), } } /// 打开一个新的 stream pub async fn open_stream(&mut self) -> Result<Compat<yamux::Stream>, ConnectionError> { let stream = self.ctrl.open_stream().await?; Ok(stream.compat()) } } }
这段代码提供了 Yamux 的基本处理。如果有些地方你看不明白,比如 WindowUpdateMode,yamux::into_stream() 等,很正常,需要看看 yamux crate 的文档和例子。
这里有一个复杂的接口,我们稍微解释一下:
#![allow(unused)] fn main() { pub fn new_server<F, Fut>(stream: S, config: Option<Config>, f: F) -> Self where F: FnMut(yamux::Stream) -> Fut, F: Send + 'static, Fut: Future<Output = Result<(), ConnectionError>> + Send + 'static, { Self::new(stream, config, false, f) } }
它的意思是,参数 f 是一个 FnMut 闭包,接受一个 yamux::Stream 参数,返回 Future。这样的结构我们之前见过,之所以接口这么复杂,是因为 Rust 还没有把 async 闭包稳定下来。所以,如果要想写一个 async || {},这是最佳的方式。
还是写一段测试测一下(篇幅关系,完整的代码就不放了,你可以到 GitHub repo 下对照 diff_yamux 看修改):
#![allow(unused)] fn main() { #[tokio::test] async fn yamux_ctrl_client_server_should_work() -> Result<()> { // 创建使用了 TLS 的 yamux server let acceptor = tls_acceptor(false)?; let addr = start_yamux_server("127.0.0.1:0", acceptor, MemTable::new()).await?; let connector = tls_connector(false)?; let stream = TcpStream::connect(addr).await?; let stream = connector.connect(stream).await?; // 创建使用了 TLS 的 yamux client let mut ctrl = YamuxCtrl::new_client(stream, None); // 从 client ctrl 中打开一个新的 yamux stream let stream = ctrl.open_stream().await?; // 封装成 ProstClientStream let mut client = ProstClientStream::new(stream); let cmd = CommandRequest::new_hset("t1", "k1", "v1".into()); client.execute(cmd).await.unwrap(); let cmd = CommandRequest::new_hget("t1", "k1"); let res = client.execute(cmd).await.unwrap(); assert_res_ok(res, &["v1".into()], &[]); Ok(()) } }
可以看到,经过简单的封装,yamux 就很自然地融入到我们现有的架构中。因为 open_stream() 得到的是符合 tokio AsyncRead / AsyncWrite 的 stream,所以它可以直接配合 ProstClientStream 使用。也就是说,我们网络层又改动了一下,但后面逻辑依然不用变。
运行 cargo test ,所有测试都能通过。
支持 pub/sub
好,现在网络层已经支持了 yamux,为多路复用打下了基础。我们来看 pub/sub 具体怎么实现。
首先修改 abi.proto,加入新的几个命令:
#![allow(unused)] fn main() { // 来自客户端的命令请求 message CommandRequest { oneof request_data { ... Subscribe subscribe = 10; Unsubscribe unsubscribe = 11; Publish publish = 12; } } // subscribe 到某个主题,任何发布到这个主题的数据都会被收到 // 成功后,第一个返回的 CommandResponse,我们返回一个唯一的 subscription id message Subscribe { string topic = 1; } // 取消对某个主题的订阅 message Unsubscribe { string topic = 1; uint32 id = 2; } // 发布数据到某个主题 message Publish { string topic = 1; repeated Value data = 2; } }
命令的响应我们不用改变。当客户端 Subscribe 时,返回的 stream 里的第一个值包含订阅 ID,这是一个全局唯一的 ID,这样,客户端后续可以用 Unsubscribe 取消。
Pub/Sub 如何设计?
那么,Pub/Sub 该如何实现呢?
我们可以用 两张表:一张 Topic Table,存放主题和对应的订阅列表;一张 Subscription Table,存放订阅 ID 和 channel 的发送端。
当 SUBSCRIBE 时,我们获取一个订阅 ID,插入到 Topic Table,然后再创建一个 MPSC channel,把 channel 的发送端和订阅 ID 存入 subscription table。
这样,当有人 PUBLISH 时,可以从 Topic table 中找到对应的订阅 ID 的列表,然后循环从 subscription table 中找到对应的 Sender,往里面写入数据。此时,channel 的 Receiver 端会得到数据,这个数据会被 yamux stream poll 到,然后发给客户端。
整个流程如下图所示:
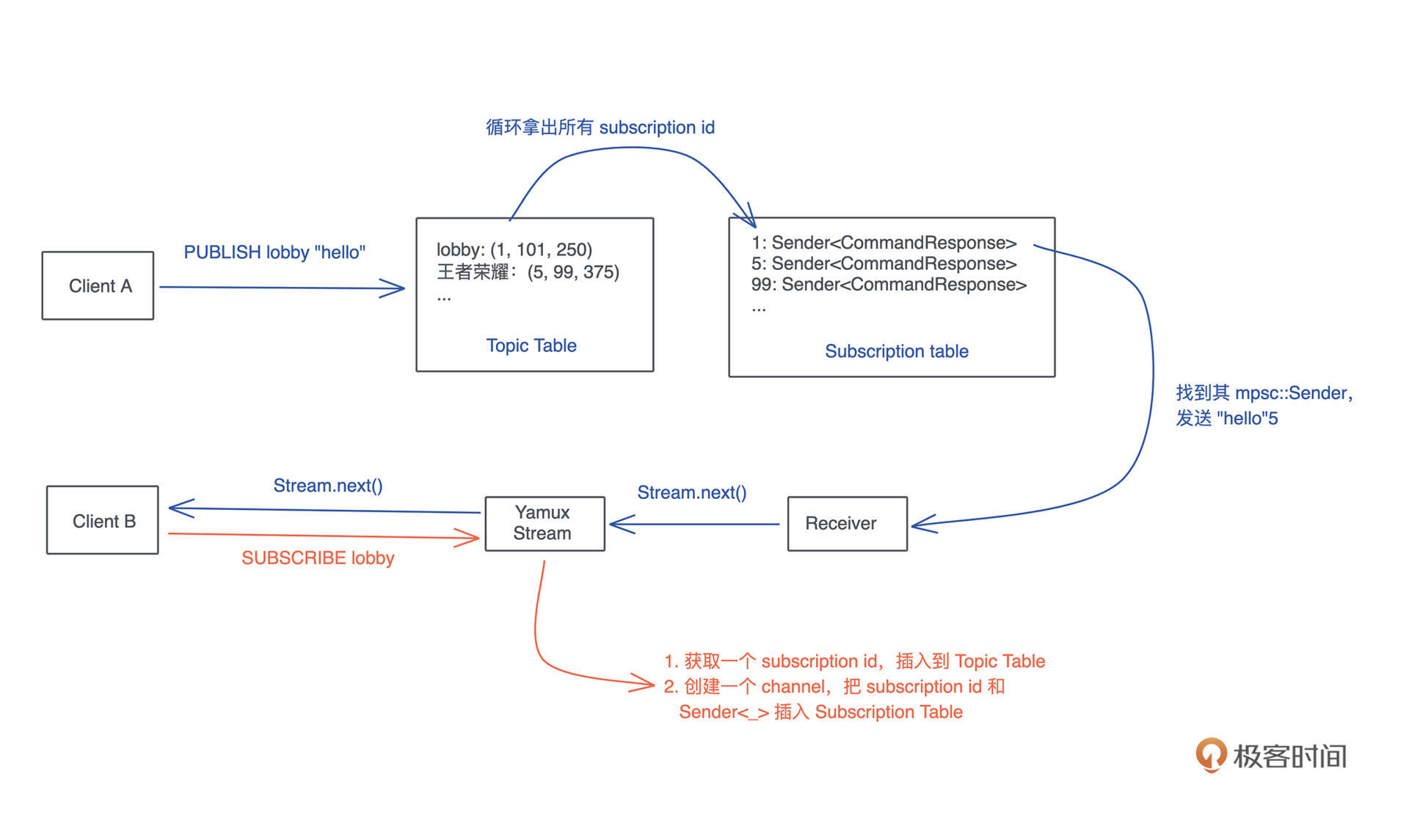
有了这个基本设计,我们可以着手接口和数据结构的构建了:
#![allow(unused)] fn main() { /// 下一个 subscription id static NEXT_ID: AtomicU32 = AtomicU32::new(1); /// 获取下一个 subscription id fn get_next_subscription_id() -> u32 { NEXT_ID.fetch_add(1, Ordering::Relaxed) } pub trait Topic: Send + Sync + 'static { /// 订阅某个主题 fn subscribe(self, name: String) -> mpsc::Receiver<Arc<CommandResponse>>; /// 取消对主题的订阅 fn unsubscribe(self, name: String, id: u32); /// 往主题里发布一个数据 fn publish(self, name: String, value: Arc<CommandResponse>); } /// 用于主题发布和订阅的数据结构 #[derive(Default)] pub struct Broadcaster { /// 所有的主题列表 topics: DashMap<String, DashSet<u32>>, /// 所有的订阅列表 subscriptions: DashMap<u32, mpsc::Sender<Arc<CommandResponse>>>, } }
这里,subscription_id 我们用一个 AtomicU32 来表述。
对于这样一个全局唯一的 ID,很多同学喜欢用 UUID4 来表述。注意使用 UUID 的话,存储时一定不要存它的字符串表现形式,太浪费内存且每次都有额外的堆分配,应该用它 u128 的表现形式。
不过即便 u128,也比 u32 浪费很多空间。假设某个主题 M 下有一万个订阅,要往这个 M 里发送一条消息,就意味着整个 DashSet
另外,我们把 CommandResponse 封装进了一个 Arc。如果一条消息要发送给一万个客户端,那么我们不希望这条消息被复制后,再被发送,而是直接发送同一份数据。
这里对 Pub/Sub 的接口,构建了一个 Topic trait。虽然目前我们只有 Broadcaster 会实现 Topic trait,但未来也许会换不同的实现方式,所以,抽象出 Topic trait 很有意义。
Pub/Sub 的实现
好,我们来写代码。创建 src/service/topic.rs(记得在 mod.rs 里引用),并添入:
#![allow(unused)] fn main() { use dashmap::{DashMap, DashSet}; use std::sync::{ atomic::{AtomicU32, Ordering}, Arc, }; use tokio::sync::mpsc; use tracing::{debug, info, warn}; use crate::{CommandResponse, Value}; /// topic 里最大存放的数据 const BROADCAST_CAPACITY: usize = 128; /// 下一个 subscription id static NEXT_ID: AtomicU32 = AtomicU32::new(1); /// 获取下一个 subscription id fn get_next_subscription_id() -> u32 { NEXT_ID.fetch_add(1, Ordering::Relaxed) } pub trait Topic: Send + Sync + 'static { /// 订阅某个主题 fn subscribe(self, name: String) -> mpsc::Receiver<Arc<CommandResponse>>; /// 取消对主题的订阅 fn unsubscribe(self, name: String, id: u32); /// 往主题里发布一个数据 fn publish(self, name: String, value: Arc<CommandResponse>); } /// 用于主题发布和订阅的数据结构 #[derive(Default)] pub struct Broadcaster { /// 所有的主题列表 topics: DashMap<String, DashSet<u32>>, /// 所有的订阅列表 subscriptions: DashMap<u32, mpsc::Sender<Arc<CommandResponse>>>, } impl Topic for Arc<Broadcaster> { fn subscribe(self, name: String) -> mpsc::Receiver<Arc<CommandResponse>> { let id = { let entry = self.topics.entry(name).or_default(); let id = get_next_subscription_id(); entry.value().insert(id); id }; // 生成一个 mpsc channel let (tx, rx) = mpsc::channel(BROADCAST_CAPACITY); let v: Value = (id as i64).into(); // 立刻发送 subscription id 到 rx let tx1 = tx.clone(); tokio::spawn(async move { if let Err(e) = tx1.send(Arc::new(v.into())).await { // TODO: 这个很小概率发生,但目前我们没有善后 warn!("Failed to send subscription id: {}. Error: {:?}", id, e); } }); // 把 tx 存入 subscription table self.subscriptions.insert(id, tx); debug!("Subscription {} is added", id); // 返回 rx 给网络处理的上下文 rx } fn unsubscribe(self, name: String, id: u32) { if let Some(v) = self.topics.get_mut(&name) { // 在 topics 表里找到 topic 的 subscription id,删除 v.remove(&id); // 如果这个 topic 为空,则也删除 topic if v.is_empty() { info!("Topic: {:?} is deleted", &name); drop(v); self.topics.remove(&name); } } debug!("Subscription {} is removed!", id); // 在 subscription 表中同样删除 self.subscriptions.remove(&id); } fn publish(self, name: String, value: Arc<CommandResponse>) { tokio::spawn(async move { match self.topics.get(&name) { Some(chan) => { // 复制整个 topic 下所有的 subscription id // 这里我们每个 id 是 u32,如果一个 topic 下有 10k 订阅,复制的成本 // 也就是 40k 堆内存(外加一些控制结构),所以效率不算差 // 这也是为什么我们用 NEXT_ID 来控制 subscription id 的生成 let chan = chan.value().clone(); // 循环发送 for id in chan.into_iter() { if let Some(tx) = self.subscriptions.get(&id) { if let Err(e) = tx.send(value.clone()).await { warn!("Publish to {} failed! error: {:?}", id, e); } } } } None => {} } }); } } }
这段代码就是 Pub/Sub 的核心功能了。你可以对照着上面的设计图和代码中的详细注释去理解。我们来写一个测试确保它正常工作:
#![allow(unused)] fn main() { #[cfg(test)] mod tests { use std::convert::TryInto; use crate::assert_res_ok; use super::*; #[tokio::test] async fn pub_sub_should_work() { let b = Arc::new(Broadcaster::default()); let lobby = "lobby".to_string(); // subscribe let mut stream1 = b.clone().subscribe(lobby.clone()); let mut stream2 = b.clone().subscribe(lobby.clone()); // publish let v: Value = "hello".into(); b.clone().publish(lobby.clone(), Arc::new(v.clone().into())); // subscribers 应该能收到 publish 的数据 let id1: i64 = stream1.recv().await.unwrap().as_ref().try_into().unwrap(); let id2: i64 = stream2.recv().await.unwrap().as_ref().try_into().unwrap(); assert!(id1 != id2); let res1 = stream1.recv().await.unwrap(); let res2 = stream2.recv().await.unwrap(); assert_eq!(res1, res2); assert_res_ok(&res1, &[v.clone()], &[]); // 如果 subscriber 取消订阅,则收不到新数据 b.clone().unsubscribe(lobby.clone(), id1 as _); // publish let v: Value = "world".into(); b.clone().publish(lobby.clone(), Arc::new(v.clone().into())); assert!(stream1.recv().await.is_none()); let res2 = stream2.recv().await.unwrap(); assert_res_ok(&res2, &[v.clone()], &[]); } } }
这个测试需要一系列新的改动,比如 assert_res_ok() 的接口变化了,我们需要在 src/pb/mod.rs 里添加新的 TryFrom 支持等等,详细代码你可以看 repo 里的 diff_topic。
在处理流程中引入 Pub/Sub
好,再来看它和用户传入的 CommandRequest 如何发生关系。我们之前设计了 CommandService trait,它虽然可以处理其它命令,但对 Pub/Sub 相关的几个新命令无法处理,因为接口没有任何和 Topic 有关的参数:
#![allow(unused)] fn main() { /// 对 Command 的处理的抽象 pub trait CommandService { /// 处理 Command,返回 Response fn execute(self, store: &impl Storage) -> CommandResponse; } }
但是如果直接修改这个接口,对已有的代码就非常不友好。所以我们还是对比着创建一个新的 trait:
#![allow(unused)] fn main() { pub type StreamingResponse = Pin<Box<dyn Stream<Item = Arc<CommandResponse>> + Send>>; pub trait TopicService { /// 处理 Command,返回 Response fn execute<T>(self, chan: impl Topic) -> StreamingResponse; } }
因为 Stream 是一个 trait,在 trait 的方法里我们无法返回一个 impl Stream,所以用 trait object: Pin<Box\<dyn Stream>>。
实现它很简单,我们创建 src/service/topic_service.rs(记得在 mod.rs 引用),然后添加:
#![allow(unused)] fn main() { use futures::{stream, Stream}; use std::{pin::Pin, sync::Arc}; use tokio_stream::wrappers::ReceiverStream; use crate::{CommandResponse, Publish, Subscribe, Topic, Unsubscribe}; pub type StreamingResponse = Pin<Box<dyn Stream<Item = Arc<CommandResponse>> + Send>>; pub trait TopicService { /// 处理 Command,返回 Response fn execute<T, S>(self, topic: impl Topic) -> StreamingResponse; } impl TopicService for Subscribe { fn execute<T, S>(self, topic: impl Topic) -> StreamingResponse { let rx = topic.subscribe(self.topic); Box::pin(ReceiverStream::new(rx)) } } impl TopicService for Unsubscribe { fn execute<T, S>(self, topic: impl Topic) -> StreamingResponse { topic.unsubscribe(self.topic, self.id); Box::pin(stream::once(async { Arc::new(CommandResponse::ok()) })) } } impl TopicService for Publish { fn execute<T, S>(self, topic: impl Topic) -> StreamingResponse { topic.publish(self.topic, Arc::new(self.data.into())); Box::pin(stream::once(async { Arc::new(CommandResponse::ok()) })) } } }
我们使用了 tokio-stream 的 wrapper 把一个 mpsc::Receiver 转换成 ReceiverStream。这样 Subscribe 的处理就能返回一个 Stream。对于 Unsubscribe 和 Publish,它们都返回单个值,我们使用 stream::once 将其统一起来。
同样地,要在 src/pb/mod.rs 里添加一些新的方法,比如 CommandResponse::ok(),它返回一个状态码是 OK 的 response:
#![allow(unused)] fn main() { impl CommandResponse { pub fn ok() -> Self { let mut result = CommandResponse::default(); result.status = StatusCode::OK.as_u16() as _; result } } }
好,接下来看 src/service/mod.rs,我们可以对应着原来的 dispatch 做一个 dispatch_stream。同样地,已有的接口应该少动,我们平行添加一个新的:
#![allow(unused)] fn main() { /// 从 Request 中得到 Response,目前处理所有 HGET/HSET/HDEL/HEXIST pub fn dispatch(cmd: CommandRequest, store: &impl Storage) -> CommandResponse { match cmd.request_data { Some(RequestData::Hget(param)) => param.execute(store), Some(RequestData::Hgetall(param)) => param.execute(store), Some(RequestData::Hmget(param)) => param.execute(store), Some(RequestData::Hset(param)) => param.execute(store), Some(RequestData::Hmset(param)) => param.execute(store), Some(RequestData::Hdel(param)) => param.execute(store), Some(RequestData::Hmdel(param)) => param.execute(store), Some(RequestData::Hexist(param)) => param.execute(store), Some(RequestData::Hmexist(param)) => param.execute(store), None => KvError::InvalidCommand("Request has no data".into()).into(), // 处理不了的返回一个啥都不包括的 Response,这样后续可以用 dispatch_stream 处理 _ => CommandResponse::default(), } } /// 从 Request 中得到 Response,目前处理所有 PUBLISH/SUBSCRIBE/UNSUBSCRIBE pub fn dispatch_stream(cmd: CommandRequest, topic: impl Topic) -> StreamingResponse { match cmd.request_data { Some(RequestData::Publish(param)) => param.execute(topic), Some(RequestData::Subscribe(param)) => param.execute(topic), Some(RequestData::Unsubscribe(param)) => param.execute(topic), // 如果走到这里,就是代码逻辑的问题,直接 crash 出来 _ => unreachable!(), } } }
为了使用这个新的接口,Service 结构也需要相应改动:
#![allow(unused)] fn main() { /// Service 数据结构 pub struct Service<Store = MemTable> { inner: Arc<ServiceInner<Store>>, broadcaster: Arc<Broadcaster>, } impl<Store> Clone for Service<Store> { fn clone(&self) -> Self { Self { inner: Arc::clone(&self.inner), broadcaster: Arc::clone(&self.broadcaster), } } } impl<Store: Storage> From<ServiceInner<Store>> for Service<Store> { fn from(inner: ServiceInner<Store>) -> Self { Self { inner: Arc::new(inner), broadcaster: Default::default(), } } } impl<Store: Storage> Service<Store> { pub fn execute(&self, cmd: CommandRequest) -> StreamingResponse { debug!("Got request: {:?}", cmd); self.inner.on_received.notify(&cmd); let mut res = dispatch(cmd, &self.inner.store); if res == CommandResponse::default() { dispatch_stream(cmd, Arc::clone(&self.broadcaster)) } else { debug!("Executed response: {:?}", res); self.inner.on_executed.notify(&res); self.inner.on_before_send.notify(&mut res); if !self.inner.on_before_send.is_empty() { debug!("Modified response: {:?}", res); } Box::pin(stream::once(async { Arc::new(res) })) } } } }
这里,为了处理 Pub/Sub,我们引入了一个破坏性的更新。 execute() 方法的返回值变成了 StreamingResponse,这就意味着所有围绕着这个方法的调用,包括测试,都需要相应更新。这是迫不得已的,不过通过构建和 CommandService / dispatch 平行的 TopicService / dispatch_stream,我们已经让这个破坏性更新尽可能地在比较高层,否则,改动会更大。
目前,代码无法编译通过,这是因为如下的代码,res 现在是个 stream,我们需要处理一下:
#![allow(unused)] fn main() { let res = service.execute(CommandRequest::new_hget("t1", "k1")); assert_res_ok(&res, &["v1".into()], &[]); // 需要变更为读取 stream 里的一个值 let res = service.execute(CommandRequest::new_hget("t1", "k1")); let data = res.next().await.unwrap(); assert_res_ok(&data, &["v1".into()], &[]); }
当然,这样的改动也意味着,原本的函数需要变成 async。
如果是个 test,需要使用 #[tokio::test]。你可以自己试着把所有相关的代码都改一下。当你改到 src/network/mod.rs 里 ProstServerStream 的 process 方法时,会发现 stream.send(data) 时,我们目前的 data 是 Arc
#![allow(unused)] fn main() { impl<S> ProstServerStream<S> where S: AsyncRead + AsyncWrite + Unpin + Send + 'static, { ... pub async fn process(mut self) -> Result<(), KvError> { let stream = &mut self.inner; while let Some(Ok(cmd)) = stream.next().await { info!("Got a new command: {:?}", cmd); let mut res = self.service.execute(cmd); while let Some(data) = res.next().await { // 目前 data 是 Arc<CommandResponse>, // 所以我们 send 最好用 &CommandResponse stream.send(&data).await.unwrap(); } } // info!("Client {:?} disconnected", self.addr); Ok(()) } } }
所以我们还需要稍微改动一下 src/network/stream.rs:
#![allow(unused)] fn main() { // impl<S, In, Out> Sink<Out> for ProstStream<S, In, Out> impl<S, In, Out> Sink<&Out> for ProstStream<S, In, Out> }
这会引发一系列的变动,你可以试着自己改一下。
如果你把所有编译错误都改正, cargo test 会全部通过。你也可以看 repo 里的 diff_service,看看所有改动的代码。
继续重构:弥补设计上的小问题
现在看上去大功告成,但你有没有注意,我们在撰写 src/service/topic_service.rs 时,没有写测试。你也许会说:这段代码如此简单,还有必要测试么?
还是那句话,测试是体验和感受接口完备性的一种手段。 测试并不是为了测试实现本身,而是看接口是否好用,是否遗漏了某些产品需求。
当开始写测试的时候,我们就会思考:unsubscribe 接口如果遇到不存在的 subscription,要不要返回一个 404?publish 的时候遇到错误,是不是意味着客户端非正常退出了?我们要不要把它从 subscription 中移除掉?
#![allow(unused)] fn main() { #[cfg(test)] mod tests { use super::*; use crate::{assert_res_error, assert_res_ok, dispatch_stream, Broadcaster, CommandRequest}; use futures::StreamExt; use std::{convert::TryInto, time::Duration}; use tokio::time; #[tokio::test] async fn dispatch_publish_should_work() { let topic = Arc::new(Broadcaster::default()); let cmd = CommandRequest::new_publish("lobby", vec!["hello".into()]); let mut res = dispatch_stream(cmd, topic); let data = res.next().await.unwrap(); assert_res_ok(&data, &[], &[]); } #[tokio::test] async fn dispatch_subscribe_should_work() { let topic = Arc::new(Broadcaster::default()); let cmd = CommandRequest::new_subscribe("lobby"); let mut res = dispatch_stream(cmd, topic); let id: i64 = res.next().await.unwrap().as_ref().try_into().unwrap(); assert!(id > 0); } #[tokio::test] async fn dispatch_subscribe_abnormal_quit_should_be_removed_on_next_publish() { let topic = Arc::new(Broadcaster::default()); let id = { let cmd = CommandRequest::new_subscribe("lobby"); let mut res = dispatch_stream(cmd, topic.clone()); let id: i64 = res.next().await.unwrap().as_ref().try_into().unwrap(); drop(res); id as u32 }; // publish 时,这个 subscription 已经失效,所以会被删除 let cmd = CommandRequest::new_publish("lobby", vec!["hello".into()]); dispatch_stream(cmd, topic.clone()); time::sleep(Duration::from_millis(10)).await; // 如果再尝试删除,应该返回 KvError let result = topic.unsubscribe("lobby".into(), id); assert!(result.is_err()); } #[tokio::test] async fn dispatch_unsubscribe_should_work() { let topic = Arc::new(Broadcaster::default()); let cmd = CommandRequest::new_subscribe("lobby"); let mut res = dispatch_stream(cmd, topic.clone()); let id: i64 = res.next().await.unwrap().as_ref().try_into().unwrap(); let cmd = CommandRequest::new_unsubscribe("lobby", id as _); let mut res = dispatch_stream(cmd, topic); let data = res.next().await.unwrap(); assert_res_ok(&data, &[], &[]); } #[tokio::test] async fn dispatch_unsubscribe_random_id_should_error() { let topic = Arc::new(Broadcaster::default()); let cmd = CommandRequest::new_unsubscribe("lobby", 9527); let mut res = dispatch_stream(cmd, topic); let data = res.next().await.unwrap(); assert_res_error(&data, 404, "Not found: subscription 9527"); } } }
在撰写这些测试,并试图使测试通过的过程中,我们又进一步重构了代码。具体的代码变更,你可以参考 repo 里的 diff_refactor。
让客户端能更好地使用新的接口
目前,我们 ProstClientStream 还是一个统一的 execute() 方法:
#![allow(unused)] fn main() { impl<S> ProstClientStream<S> where S: AsyncRead + AsyncWrite + Unpin + Send, { ... pub async fn execute(&mut self, cmd: CommandRequest) -> Result<CommandResponse, KvError> { let stream = &mut self.inner; stream.send(&cmd).await?; match stream.next().await { Some(v) => v, None => Err(KvError::Internal("Didn't get any response".into())), } } } }
它并没有妥善处理 SUBSCRIBE。为了支持 SUBSCRIBE,我们需要两个接口:execute_unary 和 execute_streaming。在 src/network/mod.rs 修改这个代码:
#![allow(unused)] fn main() { impl<S> ProstClientStream<S> where S: AsyncRead + AsyncWrite + Unpin + Send + 'static, { ... pub async fn execute_unary( &mut self, cmd: &CommandRequest, ) -> Result<CommandResponse, KvError> { let stream = &mut self.inner; stream.send(cmd).await?; match stream.next().await { Some(v) => v, None => Err(KvError::Internal("Didn't get any response".into())), } } pub async fn execute_streaming(self, cmd: &CommandRequest) -> Result<StreamResult, KvError> { let mut stream = self.inner; stream.send(cmd).await?; stream.close().await?; StreamResult::new(stream).await } } }
注意,因为 execute_streaming 里返回 Box:pin(stream),我们需要对 ProstClientStream 的 S 限制是 'static,否则编译器会抱怨。这个改动会导致使用 execute() 方法的测试都无法编译,你可以试着修改掉它们。
此外我们还创建了一个新的文件 src/network/stream_result.rs,用来帮助客户端更好地使用 execute_streaming() 接口。所有改动的具体代码可以看 repo 中的 diff_client。
现在,代码一切就绪。打开一个命令行窗口,运行: RUST_LOG=info cargo run --bin kvs --quiet, 然后在另一个命令行窗口,运行: RUST_LOG=info cargo run --bin kvc --quiet。
此时,服务器和客户端都收到了彼此的请求和响应,即便混合 HSET/HGET 和 PUBLISH/SUBSCRIBE 命令,一切都依旧处理正常!今天我们做了一个比较大的重构,但比预想中对原有代码的改动要小,这简直太棒了!
小结
当一个项目越来越复杂,且新加的功能并不能很好地融入已有的系统时,大的重构是不可避免的。在重构的时候,我们一定要首先要弄清楚现有的流程和架构,然后再思考如何重构,这样对系统的侵入才是最小的。
重构一般会带来对现有测试的破坏,在修复被破坏的测试时,我们要注意不要变动原有测试的逻辑。在做因为新功能添加导致的重构时,如果伴随着大量测试的删除和大量新测试的添加,那么,说明要么原来的测试写得很有问题,要么重构对原有系统的侵入性太强。我们要尽量避免这种事情发生。
在架构和设计都相对不错的情况下,撰写代码的终极目标是对使用者友好的抽象。所谓对使用者友好的抽象,是指让别人调用我们写的接口时,不用想太多,接口本身就是自解释的。
如果你仔细阅读 diff_client,可以看到类似 StreamResult 这样的抽象。它避免了调用者需要了解如何手工从 Stream 中取第一个值作为 subscription_id 这样的实现细节,直接替调用者完成了这个工作,并以一个优雅的 ID 暴露给调用者。
你可以仔细阅读这一讲中的代码,好好品味这些接口的设计。它们并非完美,世上没有完美的代码,只有不断完善的代码。如果把一行行代码比作一段段文字,起码它们都需要努力地推敲和不断地迭代。
思考题
- 现在我们的系统对 Pub/Sub 已经有比较完整的支持,但你有没有注意到,有一个潜在的内存泄漏的 bug。如果客户端 A subscribe 了 Topic M,但客户端意外终止,且随后也没有任何人往 Topic M publish 消息。这样,A 的 subscription 就一直放在表中。你能做一个 GC 来处理这种情况么?
- Redis 还支持 PSUBSCRIBE,也就是说除了可以 subscribe “chat” 这样固定的 topic,还可以是 “chat.*”,一并订阅所有 “chat”、“chat.rust”、“chat.elixir” 。想想看,如果要支持 PSUBSCRIBE,你该怎么设计 Broadcaster 里的两张表?
欢迎在留言区分享你的思考和学习感悟。感谢你的收听,如果觉得有收获,也欢迎分享给你身边的朋友,邀他一起讨论。恭喜你完成了Rust学习的第42次打卡,我们下节课见。
生产环境:真实世界下的一个Rust项目包含哪些要素?
你好,我是陈天。
随着我们的实战项目 KV server 接近尾声,课程也到了收官阶段。掌握一门语言的特性,能写出应用这些特性解决一些小问题的代码,算是初窥门径,就像在游泳池里练习冲浪;真正想把语言融会贯通,还要靠大风大浪中的磨练。所以接下来的三篇文章,我们会偏重了解真实的 Rust 应用环境,看看如何用 Rust 构建复杂的软件系统。
今天,我们首先来学习真实世界下的一个 Rust 项目,应该包含哪些要素。主要介绍和开发阶段相关的内容,包括:代码仓库的管理、测试和持续集成、文档、特性管理、编译期处理、日志和监控,最后会顺便介绍一下如何控制 Rust 代码编译出的可执行文件的大小。
代码仓库的管理
我们先从一个代码仓库的结构和管理入手。之前介绍过,Rust 支持 workspace,可以在一个 workspace 下放置很多 crates。不知道你有没有发现,这门课程在GitHub 上的 repo,就把每节课的代码组织成一个个 crate,放在同一个 workspace 中。
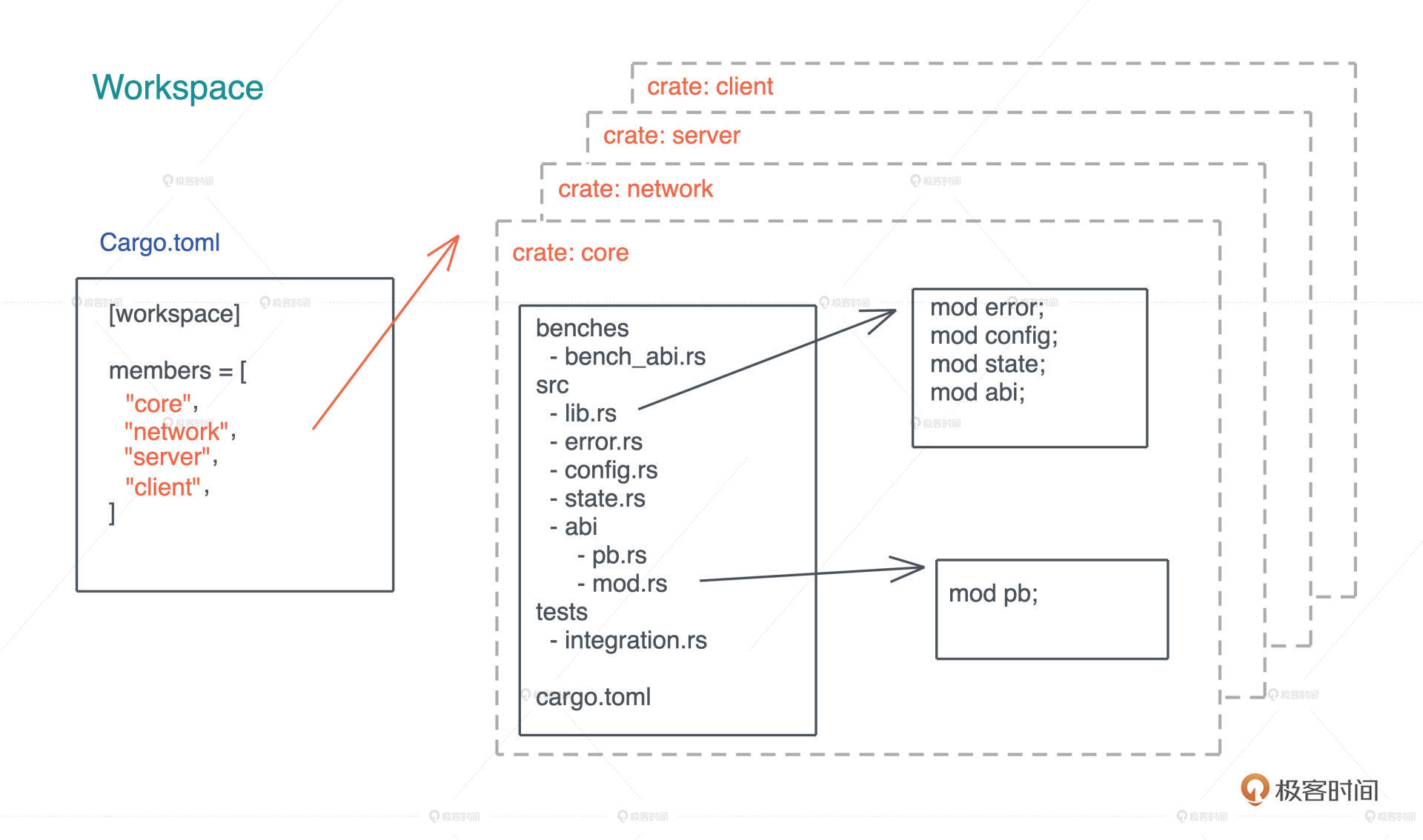
在构建应用程序或者服务的时候,我们要尽量把各个模块划分清楚,然后用不同的 crate 实现它们。这样,一来增量编译的效率更高(没有改动的 crate 无需重编),二来可以通过 crate 强制为模块划分边界,明确公开的接口和私有接口。
一般而言,除了代码仓库的根目录有 README.md 外,workspace 下的每个 crate 也最好要有 README.md 以及 examples,让使用者可以很清晰地理解如何使用这个 crate。如果你的项目的构建过程不是简单通过 cargo build 完成的,建议提供 Makefile 或者类似的脚本来自动化本地构建的流程。
当我们往代码仓库里提交代码时,应该要在本地走一遍基本的检查,包括代码风格检查、编译检查、静态检查,以及单元测试,这样可以最大程度保证每个提交都是完备的,没有基本错误的代码。
如果你使用 Git 来管理代码仓库,那么可以使用 pre-commit hook。一般来说,我们不必自己撰写 pre-commit hook 脚本,可以使用 pre-commit 这个工具。下面是我在 tyrchen/geektime-rust 中使用的 pre-commit 配置,供你参考:
❯ cat .pre-commit-config.yaml
fail_fast: false
repos:
- repo: <https://github.com/pre-commit/pre-commit-hooks>
rev: v2.3.0
hooks:
- id: check-byte-order-marker
- id: check-case-conflict
- id: check-merge-conflict
- id: check-symlinks
- id: check-yaml
- id: end-of-file-fixer
- id: mixed-line-ending
- id: trailing-whitespace
- repo: <https://github.com/psf/black>
rev: 19.3b0
hooks:
- id: black
- repo: local
hooks:
- id: cargo-fmt
name: cargo fmt
description: Format files with rustfmt.
entry: bash -c 'cargo fmt -- --check'
language: rust
files: \\.rs$
args: []
- id: cargo-check
name: cargo check
description: Check the package for errors.
entry: bash -c 'cargo check --all'
language: rust
files: \\.rs$
pass_filenames: false
- id: cargo-clippy
name: cargo clippy
description: Lint rust sources
entry: bash -c 'cargo clippy --all-targets --all-features --tests --benches -- -D warnings'
language: rust
files: \\.rs$
pass_filenames: false
- id: cargo-test
name: cargo test
description: unit test for the project
entry: bash -c 'cargo test --all-features --all'
language: rust
files: \\.rs$
pass_filenames: false
你在根目录生成 .pre-commit-config.yaml 后,运行 pre-commit install,以后 git commit 时就会自动做这一系列的检查,保证提交代码的最基本的正确性。
除此之外,你的代码仓库在根目录下最好还声明一个 deny.toml,使用 cargo-deny 来确保你使用的第三方依赖没有不该出现的授权(比如不使用任何 GPL/APGL 的代码)、没有可疑的来源(比如不是来自某个 fork 的 GitHub repo 下的 commit),以及没有包含有安全漏洞的版本。
cargo-deny 对于生产环境下的代码非常重要,因为现代软件依赖太多,依赖树过于庞杂,靠人眼是很难审查出问题的。通过使用 cargo-deny,我们可以避免很多有风险的第三方库。
测试和持续集成
在课程里,我们不断地在项目中强调单元测试的重要性。单元测试除了是软件质量保证的必要手段外,还是接口设计和迭代的最佳辅助工具。
良好的架构、清晰的接口隔离,必然会让单元测试变得容易直观;而写起来别扭,甚至感觉很难撰写的单元测试,则是在警告你软件的架构或者设计出了问题: 要么是模块之间耦合性太强(状态纠缠不清),要么是接口设计得很难使用。
在 Rust 下撰写单元测试非常直观,测试代码和模块代码放在同一个文件里,很容易阅读和互相印证。我们之前已经写过大量这类的单元测试。
不过还有一种单元测试是和文档放在一起的,doctest,如果你在学习这门课的过程中已经习惯遇到问题就去看源代码的话,会看到很多类似这样的 doctest,比如下面的 HashMap::get 方法的 doctest:
#![allow(unused)] fn main() { /// Returns a reference to the value corresponding to the key. /// /// The key may be any borrowed form of the map's key type, but /// [`Hash`] and [`Eq`] on the borrowed form *must* match those for /// the key type. /// /// # Examples /// /// ``` /// use std::collections::HashMap; /// /// let mut map = HashMap::new(); /// map.insert(1, "a"); /// assert_eq!(map.get(&1), Some(&"a")); /// assert_eq!(map.get(&2), None); /// ``` #[stable(feature = "rust1", since = "1.0.0")] #[inline] pub fn get<Q: ?Sized>(&self, k: &Q) -> Option<&V> where K: Borrow<Q>, Q: Hash + Eq, { self.base.get(k) } }
在之前的代码中,虽然我们没有明确介绍文档注释,但想必你已经知道,可以通过 “///” 来撰写数据结构、trait、方法和函数的文档注释。
这样的注释可以用 markdown 格式撰写,之后通过 “cargo doc” 编译成类似你在 docs.rs 下看到的文档。其中,markdown 里的代码就会被编译成 doctest,然后在 “cargo test” 中进行测试。
除了单元测试,我们往往还需要集成测试和性能测试。在后续 KV server 的实现过程中,我们会引入集成测试来测试服务器的基本功能,以及性能测试来测试 pub/sub 的性能。这个在遇到的时候再详细介绍。
在一个项目的早期,引入持续集成非常必要,哪怕还没有全面的测试覆盖。
如果说 pre-commit 是每个人提交代码的一道守卫,避免一些基本的错误进入到代码库,让大家在团队协作做代码审阅时,不至于还需要关注基本的代码格式;那么, 持续集成就是在团队协作过程中的一道守卫,保证添加到 PR 里或者合并到 master 下的代码,在特定的环境下,也是没有问题的。
如果你用 GitHub 来管理代码仓库,可以使用 github workflow 来进行持续集成,比如下面是一个最基本的 Rust github workflow 的定义:
❯ cat .github/workflows/build.yml
name: build
on:
push:
branches:
- master
pull_request:
branches:
- master
jobs:
build-rust:
strategy:
matrix:
platform: [ubuntu-latest, windows-latest]
runs-on: ${{ matrix.platform }}
steps:
- uses: actions/checkout@v2
- name: Cache cargo registry
uses: actions/cache@v1
with:
path: ~/.cargo/registry
key: ${{ runner.os }}-cargo-registry
- name: Cache cargo index
uses: actions/cache@v1
with:
path: ~/.cargo/git
key: ${{ runner.os }}-cargo-index
- name: Cache cargo build
uses: actions/cache@v1
with:
path: target
key: ${{ runner.os }}-cargo-build-target
- name: Install stable
uses: actions-rs/toolchain@v1
with:
profile: minimal
toolchain: stable
override: true
- name: Check code format
run: cargo fmt -- --check
- name: Check the package for errors
run: cargo check --all
- name: Lint rust sources
run: cargo clippy --all-targets --all-features --tests --benches -- -D warnings
- name: Run tests
run: cargo test --all-features -- --test-threads=1 --nocapture
- name: Generate docs
run: cargo doc --all-features --no-deps
我们会处理代码格式,做基本的静态检查、单元测试和集成测试,以及生成文档。
文档
前面说了,Rust 代码的文档注释可以用 “///” 来标注。对于我们上一讲 KV server 的代码,可以运行 “cargo doc” 来生成对应的文档。
注意,在 cargo doc 时,不光你自己撰写的 crate 的文档会被生成,所有在依赖里使用到的 crate 的文档也会一并生成,所以如果你想在没有网的情况下,参考某些引用了的 crate 文档,可以看本地生成的文档。下图是上一讲的 KV server 文档的截图:
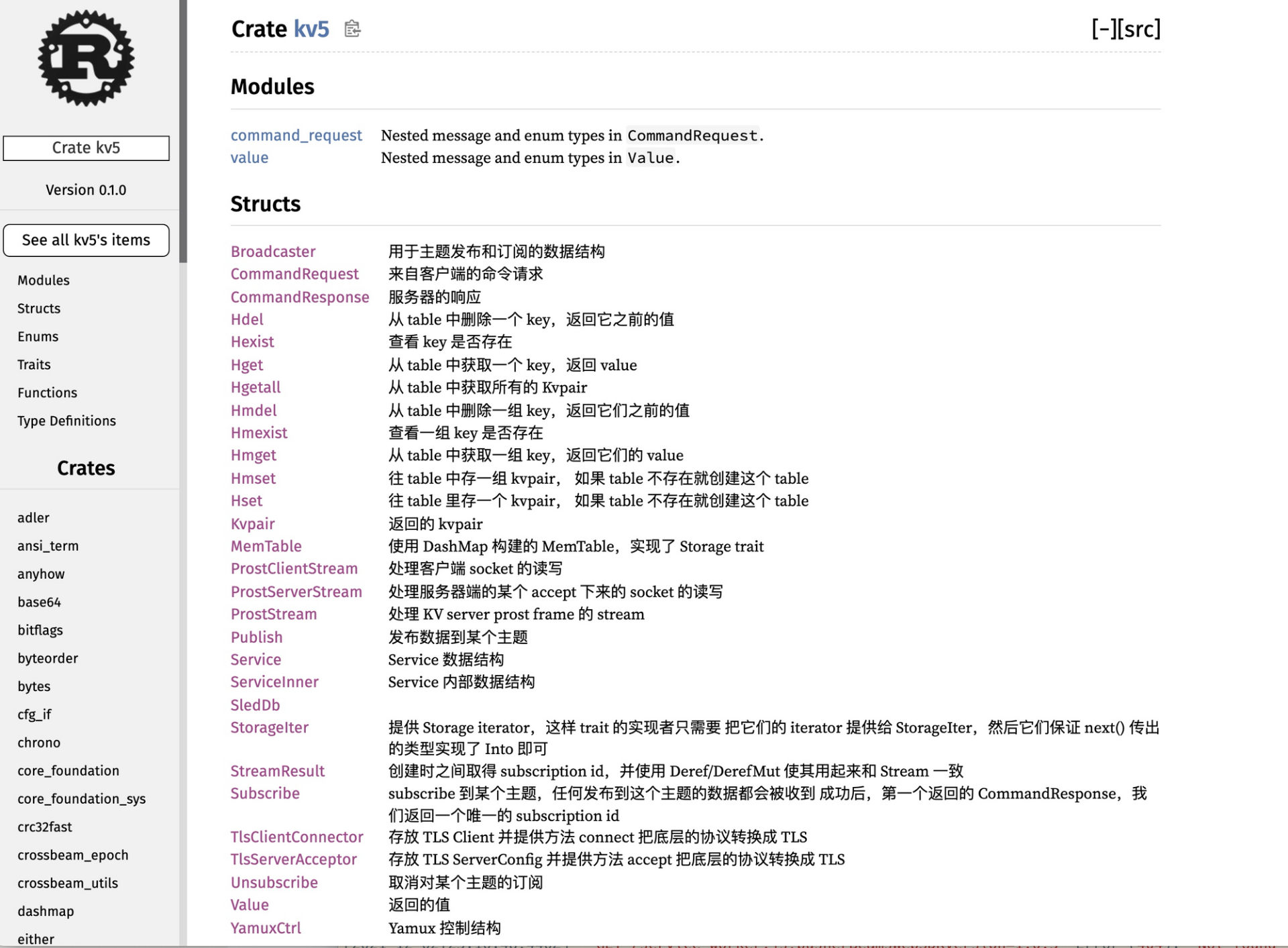
大多数时候,你只需要使用 “///” 来撰写文档就够用了,不过如果你需要撰写 crate 级别的文档,也就是会显示在 crate 文档主页上的内容,可以在 lib.rs 或者 main.rs 的开头用 “//!”,比如:
#![allow(unused)] fn main() { //! 这是 crate 文档 }
如果你想强迫自己要撰写每个公共接口的文档,保持系统有良好的文档覆盖,那么可以使用 ![deny(missing_docs)]。这样,任何时候只要你忘记撰写文档,都会产生编译错误。如果你觉得编译错误太严格,也可以用编译报警: ![warn(missing_docs]。之前我们阅读过 bytes crate 的源码,可以再回过头来看看它的 lib.rs 的开头。
在介绍测试的时候,我们提到了文档测试。
在文档中撰写样例代码并保证这个样例代码可以正常运行非常重要,因为使用者在看你的 crate 文档时,往往先会参考你的样例代码,了解接口如何使用。大部分时候,你的样例代码该怎么写就怎么写, 但是,在进行异步处理和错误处理时,需要稍微做一些额外工作。
我们来看一个文档里异步处理的例子( 代码):
#![allow(unused)] fn main() { use std::task::Poll; use futures::{prelude::*, stream::poll_fn}; /// fibnacci 算法 /// 示例: /// ``` /// use futures::prelude::*; /// use playground::fib; // playground crate 名字叫 playground /// # futures::executor::block_on(async { /// let mut st = fib(10); /// assert_eq!(Some(2), st.next().await); /// # }); /// ``` pub fn fib(mut n: usize) -> impl Stream<Item = i32> { let mut a = 1; let mut b = 1; poll_fn(move |_cx| -> Poll<Option<i32>> { if n == 0 { return Poll::Ready(None); } n -= 1; let c = a + b; a = b; b = c; Poll::Ready(Some(b)) }) } }
注意这段代码中的这两句注释:
#![allow(unused)] fn main() { /// # futures::executor::block_on(async { /// ... /// # }); }
在 /// 后出现了 #,代表这句话不会出现在示例中,但会被包括在生成的测试代码中。之所以需要 block_on,是因为调用我们的测试代码时,需要使用 await,所以需要使用异步运行时来运行它。
实际上,这个的文档测试相当于:
fn main() { fn _doctest_main_xxx() { use futures::prelude::*; use playground::fib; // playground crate 名字叫 playground futures::executor::block_on(async { let mut st = fib(10); assert_eq!(Some(2), st.next().await); }); } _doctest_main_xxx() }
我们再来看一个文档中做错误处理的例子( 代码):
#![allow(unused)] fn main() { use std::io; use std::fs; /// 写入文件 /// 示例: /// ``` /// use playground::write_file; /// write_file("/tmp/dummy_test", "hello world")?; /// # Ok::<_, std::io::Error>(()) /// ``` pub fn write_file(name: &str, contents: &str) -> Result<(), io::Error> { fs::write(name, contents) } }
这个例子中,我们使用 ? 进行了错误处理,所以需要最后补一句 Ok::<_, io::Error> 来明确返回的错误类型。
如果你想了解更多有关 Rust 文档的内容,可以看 rustdoc book。
特性管理
作为一门编译型语言,Rust 支持条件编译。
通过条件编译,我们可以在同一个 crate 中支持不同的特性(feature),以满足不同的需求。比如 reqwest,它默认使用异步接口,但如果你需要同步接口,你可以使用它的 “blocking” 特性。
在生产环境中合理地使用特性,可以让 crate 的核心功能引入较少的依赖,而只有在启动某个特性的时候,才使用某些依赖,这样可以让最终编译出来的库或者可执行文件尽可能地小。
特性作为高级工具,并不在我们这个课程的范围内,感兴趣的话,你可以看 cargo book 深入了解如何在你的 crate 中使用特性,以及在代码撰写过程中,如何使用相应的宏来做条件编译。
编译期处理
在开发软件系统的时候,我们需要考虑哪些事情需要放在编译期处理,哪些事情放在加载期处理,哪些事情放在运行期处理。
有些事情,我们不一定要放在运行期才进行处理,可以在编译期就做一些预处理,让数据能够以更好的形式在运行期被使用。
比如在做中文繁简转换的时候,可以预先把单字对照表从文件中读取出来,处理成 Vec<(char, char)>,然后生成 bincode 存入到可执行文件中。我们看这个例子( 代码):
use std::io::{self, BufRead}; use std::{env, fs::File, path::Path}; fn main() { // 如果 build.rs 或者繁简对照表文件变化,则重新编译 println!("cargo:rerun-if-changed=build.rs"); println!("cargo:rerun-if-changed=src/t2s.txt"); // 生成 OUT_DIR/map.bin 供 lib.rs 访问 let out_dir = env::var_os("OUT_DIR").unwrap(); let out_file = Path::new(&out_dir).join("map.bin"); let f = File::create(&out_file).unwrap(); let v = get_kv("src/t2s.txt"); bincode::serialize_into(f, &v).unwrap(); } // 把 split 出来的 &str 转换成 char fn s2c(s: &str) -> char { let mut chars = s.chars(); let c = chars.next().unwrap(); assert!(chars.next().is_none()); assert!(c.len_utf8() == 3); c } // 读取文件,把每一行繁简对照的字符串转换成 Vec<(char, char)> fn get_kv(filename: &str) -> Vec<(char, char)> { let f = File::open(filename).unwrap(); let lines = io::BufReader::new(f).lines(); let mut v = Vec::with_capacity(4096); for line in lines { let line = line.unwrap(); let kv: Vec<_> = line.split(' ').collect(); v.push((s2c(kv[0]), s2c(kv[1]))); } v }
通过这种方式,我们在编译期额外花费了一些时间,却让运行期的代码和工作大大简化( 代码):
#![allow(unused)] fn main() { static MAP_DATA: &[u8] = include_bytes!(concat!(env!("OUT_DIR"), "/map.bin")); lazy_static! { /// state machine for the translation static ref MAP: HashMap<char, char> = { let data: Vec<(char, char)> = bincode::deserialize(MAP_DATA).unwrap(); data.into_iter().collect() }; ... } }
日志和监控
我们目前撰写的项目,都还只有少量的日志。但对于生产环境下的项目来说,这远远不够。我们需要详尽的、不同级别的日志。
这样,当系统在运行过程中出现问题时,我们可以通过日志得到足够的线索,从而找到问题的源头,进而解决问题。而且在一个分布式系统下,我们往往还需要把收集到的日志集中起来,进行过滤和查询。
除了日志,我们还需要收集系统的行为数据和性能指标,来了解系统运行时的状态。
Rust 有不错的对 prometheus 的支持,比如 rust-prometheus 可以帮助你方便地收集和发送各种指标;而 opentelemetry-rust 更是除了支持 prometheus 外,还支持很多其他商业/非商业的监控工具,比如 datadog,比如 jaeger。
之后我们还会有一讲来让 KV server 更好地处理日志和监控,并且用 jaeger 进行性能分析,找到代码中的性能问题。
可执行文件大小
最后,我们来谈谈可执行文件的大小。
绝大多数使用场景,我们使用 cargo build --release 就够了,生成的 release build 可以用在生产环境下,但有些情况,比如嵌入式环境,或者用 Rust 构建提供给 Android/iOS 的包时,需要可执行文件或者库文件尽可能小,避免浪费文件系统的空间,或者网络流量。
此时,我们需要一些额外的手段来优化文件尺寸。你可以参考 min-sized-rust 提供的方法进行处理。
小结
今天我们蜻蜓点水讨论了,把一个 Rust 项目真正应用在生产环境下,需要考虑的诸多问题。之后会围绕着 KV server 来实践这一讲中我们聊到的内容。
做一个业余项目和做一个实际的、要在生产环境中运行的项目有很大不同。业余项目我们主要关注需求是不是得到了妥善的实现,主要关注的是构建的流程;而在实际项目中,我们除了需要关注构建,还有测量和学习的完整开发流程。
看这张图,一个项目的整体开发流程相信是你所熟悉,包括初始想法、需求分析、排期、设计和实现、持续集成、代码审查、测试、发布、分阶段上线、实验、监控、数据分析等部分,我把它贯穿到精益创业(Lean Startup)“构建 - 测量 - 学习”(Build - Measure - Learn)的三个环节中。
今天介绍的代码仓库的管理、测试和持续集成、文档、日志和监控,和这个流程中的很多环节都有关系,你可以对照着自己公司的开发流程,想一想如何在这些流程中更好地使用 Rust。
思考题
在上面完整开发流程图中,今天只涉及了主要的部分。你可以结合自己现有工作的流程,思考一下如果把 Rust 引入到你的工作中,哪些流程能够很好地适配,哪些流程还需要额外的工作?
欢迎在留言区分享你的思考,感谢你的收听,如果觉得有收获,也欢迎你分享给身边的朋友,邀他一起讨论。你完成了Rust学习的第43次打卡啦,我们下节课见。
数据处理:应用程序和数据如何打交道?
你好,我是陈天。
我们开发者无论是从事服务端的开发,还是客户端的开发,和数据打交道是必不可少的。
对于客户端来说,从服务端读取到的数据,往往需要做缓存(内存缓存或者 SQLite 缓存),甚至需要本地存储(文件或者 SQLite)。
对于服务器来说,跟数据打交道的场景就更加丰富了。除了数据库和缓存外,还有大量文本数据的索引(比如搜索引擎)、实时的消息队列对数据做流式处理,或者非实时的批处理对数据仓库(data warehouse)中的海量数据进行 ETL(Extract、Transform and Load)。
今天我们就来讲讲如何用 Rust 做数据处理,主要讲两部分,如何用 Rust 访问关系数据库,以及如何用 Rust 对半结构化数据进行分析和处理。希望通过学习这一讲的内容,尤其是后半部分的内容,能帮你打开眼界,对数据处理有更加深刻的认识。
访问关系数据库
作为互联网应用的最主要的数据存储和访问工具,关系数据库,是几乎每门编程语言都有良好支持的数据库类型。
在 Rust 下,有几乎所有主流关系数据库的驱动,比如 rust-postgres、rust-mysql-simple 等,不过一般我们不太会直接使用数据库的驱动来访问数据库,因为那样会让应用过于耦合于某个数据库,所以我们会使用 ORM。
Rust 下有 diesel 这个非常成熟的 ORM,还有 sea-orm 这样的后起之秀。diesel 不支持异步,而 sea-orm 支持异步,所以,有理由相信,随着 sea-orm 的不断成熟,会有越来越多的应用在 sea-orm 上构建。
如果你觉得 ORM 太过笨重,繁文缛节太多,但又不想直接使用某个数据库的驱动来访问数据库,那么你还可以用 sqlx。sqlx 提供了对多种数据库(Postgres、MySQL、SQLite、MSSQL)的异步访问支持,并且不使用 DSL 就可以对 SQL query 做编译时检查,非常轻便;它可以从数据库中直接查询出来一行数据,也可以通过派生宏自动把行数据转换成对应的结构。
今天,我们就尝试使用 sqlx 处理用户注册和登录这两个非常常见的功能。
sqlx
构建下面的表结构来处理用户登录信息:
CREATE TABLE IF NOT EXISTS users
(
id INTEGER PRIMARY KEY NOT NULL,
email VARCHAR UNIQUE NOT NULL,
hashed_password VARCHAR NOT NULL
);
特别说明一下,在数据库中存储用户信息需要非常谨慎,尤其是涉及敏感的数据,比如密码,需要使用特定的哈希算法存储。OWASP 对密码的存储有如下 安全建议:
- 如果 Argon2id 可用,那么使用 Argon2id(需要目标机器至少有 15MB 内存)。
- 如果 Argon2id 不可用,那么使用 bcrypt(算法至少迭代 10 次)。
- 之后再考虑 scrypt / PBKDF2。
Argon2id 是 Argon2d 和 Argon2i 的组合,Argon2d 提供了强大的抗 GPU 破解能力,但在特定情况下会容易遭受 旁路攻击(side-channel attacks),而 Argon2i 则可以防止旁路攻击,但抗 GPU 破解稍弱。所以只要是编程语言支持 Argo2id,那么它就是首选的密码哈希工具。
Rust 下有完善的 password-hashes 工具,我们可以使用其中的 argon2 crate,用它生成的一个完整的,包含所有参数的密码哈希长这个样子:
$argon2id$v=19$m=4096,t=3,p=1$l7IEIWV7puJYJAZHyyut8A$OPxL09ODxp/xDQEnlG1NWdOsTr7RzuleBtiYQsnCyXY
这个字符串里包含了 argon2id 的版本(19)、使用的内存大小(4096k)、迭代次数(3 次)、并行程度(1 个线程),以及 base64 编码的 salt 和 hash。
所以,当新用户注册时,我们使用 argon2 把传入的密码哈希一下,存储到数据库中;当用户使用 email/password 登录时,我们通过 email 找到用户,然后再通过 argon2 验证密码。数据库的访问使用 sqlx,为了简单起见,避免安装额外的数据库,就使用 SQLite来存储数据(如果你本地有 MySQL 或者 PostgreSQL,可以自行替换相应的语句)。
有了这个思路,我们创建一个新的项目,添加相关的依赖:
#![allow(unused)] fn main() { [dev-dependencies] anyhow = "1" argon2 = "0.3" lazy_static = "1" rand_core = { version = "0.6", features = ["std"] } sqlx = { version = "0.5", features = ["runtime-tokio-rustls", "sqlite"] } tokio = { version = "1", features = ["full" ] } }
然后创建 examples/user.rs,添入代码,你可以对照详细的注释来理解:
use anyhow::{anyhow, Result}; use argon2::{ password_hash::{rand_core::OsRng, PasswordHash, PasswordHasher, SaltString}, Argon2, PasswordVerifier, }; use lazy_static::lazy_static; use sqlx::{sqlite::SqlitePoolOptions, SqlitePool}; use std::env; /// Argon2 hash 使用的密码 const ARGON_SECRET: &[u8] = b"deadbeef"; lazy_static! { /// Argon2 static ref ARGON2: Argon2<'static> = Argon2::new_with_secret( ARGON_SECRET, argon2::Algorithm::default(), argon2::Version::default(), argon2::Params::default() ) .unwrap(); } /// user 表对应的数据结构,处理 login/register pub struct UserDb { pool: SqlitePool, } /// 使用 FromRow 派生宏把从数据库中读取出来的数据转换成 User 结构 #[allow(dead_code)] #[derive(Debug, sqlx::FromRow)] pub struct User { id: i64, email: String, hashed_password: String, } impl UserDb { pub fn new(pool: SqlitePool) -> Self { Self { pool } } /// 用户注册:在 users 表中存储 argon2 哈希过的密码 pub async fn register(&self, email: &str, password: &str) -> Result<i64> { let hashed_password = generate_password_hash(password)?; let id = sqlx::query("INSERT INTO users(email, hashed_password) VALUES (?, ?)") .bind(email) .bind(hashed_password) .execute(&self.pool) .await? .last_insert_rowid(); Ok(id) } /// 用户登录:从 users 表中获取用户信息,并用验证用户密码 pub async fn login(&self, email: &str, password: &str) -> Result<String> { let user: User = sqlx::query_as("SELECT * from users WHERE email = ?") .bind(email) .fetch_one(&self.pool) .await?; println!("find user: {:?}", user); if let Err(_) = verify_password(password, &user.hashed_password) { return Err(anyhow!("failed to login")); } // 生成 JWT token(此处省略 JWT token 生成的细节) Ok("awesome token".into()) } } /// 重新创建 users 表 async fn recreate_table(pool: &SqlitePool) -> Result<()> { sqlx::query("DROP TABLE IF EXISTS users").execute(pool).await?; sqlx::query( r#"CREATE TABLE IF NOT EXISTS users( id INTEGER PRIMARY KEY NOT NULL, email VARCHAR UNIQUE NOT NULL, hashed_password VARCHAR NOT NULL)"#, ) .execute(pool) .await?; Ok(()) } /// 创建安全的密码哈希 fn generate_password_hash(password: &str) -> Result<String> { let salt = SaltString::generate(&mut OsRng); Ok(ARGON2 .hash_password(password.as_bytes(), &salt) .map_err(|_| anyhow!("failed to hash password"))? .to_string()) } /// 使用 argon2 验证用户密码和密码哈希 fn verify_password(password: &str, password_hash: &str) -> Result<()> { let parsed_hash = PasswordHash::new(password_hash).map_err(|_| anyhow!("failed to parse hashed password"))?; ARGON2 .verify_password(password.as_bytes(), &parsed_hash) .map_err(|_| anyhow!("failed to verify password"))?; Ok(()) } #[tokio::main] async fn main() -> Result<()> { let url = env::var("DATABASE_URL").unwrap_or("sqlite://./data/example.db".into()); // 创建连接池 let pool = SqlitePoolOptions::new() .max_connections(5) .connect(&url) .await?; // 每次运行都重新创建 users 表 recreate_table(&pool).await?; let user_db = UserDb::new(pool.clone()); let email = "tyr@awesome.com"; let password = "hunter42"; // 新用户注册 let id = user_db.register(email, password).await?; println!("registered id: {}", id); // 用户成功登录 let token = user_db.login(email, password).await?; println!("Login succeeded: {}", token); // 登录失败 let result = user_db.login(email, "badpass").await; println!("Login should fail with bad password: {:?}", result); Ok(()) }
在这段代码里,我们把 argon2 的能力稍微包装了一下,提供了 generate_password_hash 和 verify_password 两个方法给注册和登录使用。对于数据库的访问,我们提供了一个连接池 SqlitePool,便于无锁访问。
你可能注意到了这句写法:
#![allow(unused)] fn main() { let user: User = sqlx::query_as("SELECT * from users WHERE email = ?") .bind(email) .fetch_one(&self.pool) .await?; }
是不是很惊讶,一般来说,这是 ORM 才有的功能啊。没错,它再次体现了 Rust trait 的强大:我们并不需要 ORM 就可以把数据库中的数据跟某个 Model 结合起来,只需要在查询时,提供想要转换成的数据结构 T: FromRow 即可。
看 query_as 函数和 FromRow trait 的定义( 代码):
#![allow(unused)] fn main() { pub fn query_as<'q, DB, O>(sql: &'q str) -> QueryAs<'q, DB, O, <DB as HasArguments<'q>>::Arguments> where DB: Database, O: for<'r> FromRow<'r, DB::Row>, { QueryAs { inner: query(sql), output: PhantomData, } } pub trait FromRow<'r, R: Row>: Sized { fn from_row(row: &'r R) -> Result<Self, Error>; } }
要让一个数据结构支持 FromRow,很简单,使用 sqlx::FromRow 派生宏即可:
#![allow(unused)] fn main() { #[derive(Debug, sqlx::FromRow)] pub struct User { id: i64, email: String, hashed_password: String, } }
希望这个例子可以让你体会到 Rust 处理数据库的强大和简约。我们用 Rust 写出了 Node.js / Python 都不曾拥有的直观感受。另外,sqlx 是一个非常漂亮的 crate,有空的话建议你也看看它的源代码,开头介绍的 sea-orm,底层也是使用了 sqlx。
特别说明,以上例子如果运行失败,可以去 GitHub 上把 example.db 拷贝到本地 data 目录下,然后运行。
用 Rust 对半结构化数据进行分析
在生产环境中,我们会累积大量的半结构化数据,比如各种各样的日志、监控数据和分析数据。
以日志为例,虽然通常会将其灌入日志分析工具,通过可视化界面进行分析和问题追踪,但偶尔我们也需要自己写点小工具进行处理,一般,会用 Python 来处理这样的任务,因为 Python 有 pandas 这样用起来非常舒服的工具。然而,pandas 太吃内存,运算效率也不算高。有没有更好的选择呢?
在第 6 讲我们介绍过 polars,也用 polars 和 sqlparser 写了一个处理 csv 的工具,其实 polars 底层使用了 Apache arrow。如果你经常进行大数据处理,那么你对列式存储( columnar datastore)和 Data Frame 应该比较熟悉,arrow 就是一个在内存中进行存储和运算的列式存储,它是构建下一代数据分析平台的基础软件。
由于 Rust 在业界的地位越来越重要,Apache arrow 也构建了完全用 Rust 实现的版本,并在此基础上构建了高效的 in-memory 查询引擎 datafusion ,以及在某些场景下可以取代 Spark 的分布式查询引擎 ballista。
Apache arrow 和 datafusion 目前已经有很多重磅级的应用,其中最令人兴奋的是 InfluxDB IOx,它是 下一代的 InfluxDB 的核心引擎。
来一起感受一下 datafusion 如何使用:
use datafusion::prelude::*; use datafusion::arrow::util::pretty::print_batches; use datafusion::arrow::record_batch::RecordBatch; #[tokio::main] async fn main() -> datafusion::error::Result<()> { // register the table let mut ctx = ExecutionContext::new(); ctx.register_csv("example", "tests/example.csv", CsvReadOptions::new()).await?; // create a plan to run a SQL query let df = ctx.sql("SELECT a, MIN(b) FROM example GROUP BY a LIMIT 100").await?; // execute and print results df.show().await?; Ok(()) }
在这段代码中,我们通过 CsvReadOptions 推断 CSV 的 schema,然后将其注册为一个逻辑上的 example 表,之后就可以通过 SQL 进行查询了,是不是非常强大?
下面我们就使用 datafusion,来构建一个 Nginx 日志的命令行分析工具。
datafusion
在这门课程的 GitHub repo 里,我放了个从网上找到的样本日志,改名为 nginx_logs.csv(注意后缀需要是 csv),其格式如下:
93.180.71.3 - - "17/May/2015:08:05:32 +0000" GET "/downloads/product_1" "HTTP/1.1" 304 0 "-" "Debian APT-HTTP/1.3 (0.8.16~exp12ubuntu10.21)"
93.180.71.3 - - "17/May/2015:08:05:23 +0000" GET "/downloads/product_1" "HTTP/1.1" 304 0 "-" "Debian APT-HTTP/1.3 (0.8.16~exp12ubuntu10.21)"
80.91.33.133 - - "17/May/2015:08:05:24 +0000" GET "/downloads/product_1" "HTTP/1.1" 304 0 "-" "Debian APT-HTTP/1.3 (0.8.16~exp12ubuntu10.17)"
这个日志共有十个域,除了几个 “-”,无法猜测到是什么内容外,其它的域都很好猜测。
由于 nginx_logs 的格式是在 Nginx 配置中构建的,所以,日志文件,并不像 CSV 文件那样有一行 header,没有 header,就无法让 datafusion 直接帮我们推断出 schema,也就是说 我们需要显式地告诉 datafusion 日志文件的 schema 长什么样。
不过对于 datafusuion 来说,创建一个 schema 很简单,比如:
#![allow(unused)] fn main() { let schema = Arc::new(Schema::new(vec![ Field::new("ip", DataType::Utf8, false), Field::new("code", DataType::Int32, false), ])); }
为了最大的灵活性,我们可以对应地构建一个简单的 schema 定义文件,里面每个字段按顺序对应 nginx 日志的字段:
---
- name: ip
type: string
- name: unused1
type: string
- name: unused2
type: string
- name: date
type: string
- name: method
type: string
- name: url
type: string
- name: version
type: string
- name: code
type: integer
- name: len
type: integer
- name: unused3
type: string
- name: ua
type: string
这样,未来如果遇到不一样的日志文件,我们可以修改 schema 的定义,而无需修改程序本身。
对于这个 schema 定义文件,使用 serde 和 serde-yaml 来读取,然后再实现 From trait 把 SchemaField 对应到 datafusion 的 Field 结构:
#![allow(unused)] fn main() { #[derive(Debug, Clone, Serialize, Deserialize, PartialEq, Eq, PartialOrd, Ord, Hash)] #[serde(rename_all = "snake_case")] pub enum SchemaDataType { /// Int64 Integer, /// Utf8 String, /// Date64, Date, } #[derive(Serialize, Deserialize, Debug, Clone, PartialEq, Eq, Hash, PartialOrd, Ord)] struct SchemaField { name: String, #[serde(rename = "type")] pub(crate) data_type: SchemaDataType, } #[derive(Serialize, Deserialize, Debug, Clone, PartialEq, Eq, Hash, PartialOrd, Ord)] struct SchemaFields(Vec<SchemaField>); impl From<SchemaDataType> for DataType { fn from(dt: SchemaDataType) -> Self { match dt { SchemaDataType::Integer => Self::Int64, SchemaDataType::Date => Self::Date64, SchemaDataType::String => Self::Utf8, } } } impl From<SchemaField> for Field { fn from(f: SchemaField) -> Self { Self::new(&f.name, f.data_type.into(), false) } } impl From<SchemaFields> for SchemaRef { fn from(fields: SchemaFields) -> Self { let fields: Vec<Field> = fields.0.into_iter().map(|f| f.into()).collect(); Arc::new(Schema::new(fields)) } } }
有了这个基本的 schema 转换的功能,就可以构建我们的 nginx 日志处理结构及其功能了:
#![allow(unused)] fn main() { /// nginx 日志处理的数据结构 pub struct NginxLog { ctx: ExecutionContext, } impl NginxLog { /// 根据 schema 定义,数据文件以及分隔符构建 NginxLog 结构 pub async fn try_new(schema_file: &str, data_file: &str, delim: u8) -> Result<Self> { let content = tokio::fs::read_to_string(schema_file).await?; let fields: SchemaFields = serde_yaml::from_str(&content)?; let schema = SchemaRef::from(fields); let mut ctx = ExecutionContext::new(); let options = CsvReadOptions::new() .has_header(false) .delimiter(delim) .schema(&schema); ctx.register_csv("nginx", data_file, options).await?; Ok(Self { ctx }) } /// 进行 sql 查询 pub async fn query(&mut self, query: &str) -> Result<Arc<dyn DataFrame>> { let df = self.ctx.sql(query).await?; Ok(df) } } }
仅仅写了 80 行代码,就完成了 nginx 日志文件的读取、解析和查询功能,其中 50 行代码还是为了处理 schema 配置文件。是不是有点不敢相信自己的眼睛?
datafusion/arrow 也太强大了吧?这个简洁的背后,是 10w 行 arrow 代码和 1w 行 datafusion 代码的功劳。
再来写段代码调用它:
#[tokio::main] async fn main() -> Result<()> { let mut nginx_log = NginxLog::try_new("fixtures/log_schema.yml", "fixtures/nginx_logs.csv", b' ').await?; // 从 stdin 中按行读取内容,当做 sql 查询,进行处理 let stdin = io::stdin(); let mut lines = stdin.lock().lines(); while let Some(Ok(line)) = lines.next() { if !line.starts_with("--") { println!("{}", line); // 读到一行 sql,查询,获取 dataframe let df = nginx_log.query(&line).await?; // 简单显示 dataframe df.show().await?; } } Ok(()) }
在这段代码里,我们从 stdin 中获取内容,把每一行输入都作为一个 SQL 语句传给 nginx_log.query,然后显示查询结果。
来测试一下:
❯ echo "SELECT ip, count(*) as total, cast(avg(len) as int) as avg_len FROM nginx GROUP BY ip ORDER BY total DESC LIMIT 10" | cargo run --example log --quiet
SELECT ip, count(*) as total, cast(avg(len) as int) as avg_len FROM nginx GROUP BY ip ORDER BY total DESC LIMIT 10
+-----------------+-------+---------+
| ip | total | avg_len |
+-----------------+-------+---------+
| 216.46.173.126 | 2350 | 220 |
| 180.179.174.219 | 1720 | 292 |
| 204.77.168.241 | 1439 | 340 |
| 65.39.197.164 | 1365 | 241 |
| 80.91.33.133 | 1202 | 243 |
| 84.208.15.12 | 1120 | 197 |
| 74.125.60.158 | 1084 | 300 |
| 119.252.76.162 | 1064 | 281 |
| 79.136.114.202 | 628 | 280 |
| 54.207.57.55 | 532 | 289 |
+-----------------+-------+---------+
是不是挺厉害?我们可以充分利用 SQL 的强大表现力,做各种复杂的查询。不光如此,还可以从一个包含了多个 sql 语句的文件中,一次性做多个查询。比如我创建了这样一个文件 analyze.sql:
-- 查询 ip 前 10 名
SELECT ip, count(*) as total, cast(avg(len) as int) as avg_len FROM nginx GROUP BY ip ORDER BY total DESC LIMIT 10
-- 查询 UA 前 10 名
select ua, count(*) as total from nginx group by ua order by total desc limit 10
-- 查询访问最多的 url 前 10 名
select url, count(*) as total from nginx group by url order by total desc limit 10
-- 查询访问返回 body 长度前 10 名
select len, count(*) as total from nginx group by len order by total desc limit 10
-- 查询 HEAD 请求
select ip, date, url, code, ua from nginx where method = 'HEAD' limit 10
-- 查询状态码是 403 的请求
select ip, date, url, ua from nginx where code = 403 limit 10
-- 查询 UA 为空的请求
select ip, date, url, code from nginx where ua = '-' limit 10
-- 复杂查询,找返回 body 长度的 percentile 在 0.5-0.7 之间的数据
select * from (select ip, date, url, ua, len, PERCENT_RANK() OVER (ORDER BY len) as len_percentile from nginx where code = 200 order by len desc) as t where t.len_percentile > 0.5 and t.len_percentile < 0.7 order by t.len_percentile desc limit 10
那么,我可以这样获取结果:
❯ cat fixtures/analyze.sql | cargo run --example log --quiet
SELECT ip, count(*) as total, cast(avg(len) as int) as avg_len FROM nginx GROUP BY ip ORDER BY total DESC LIMIT 10
+-----------------+-------+---------+
| ip | total | avg_len |
+-----------------+-------+---------+
| 216.46.173.126 | 2350 | 220 |
| 180.179.174.219 | 1720 | 292 |
| 204.77.168.241 | 1439 | 340 |
| 65.39.197.164 | 1365 | 241 |
| 80.91.33.133 | 1202 | 243 |
| 84.208.15.12 | 1120 | 197 |
| 74.125.60.158 | 1084 | 300 |
| 119.252.76.162 | 1064 | 281 |
| 79.136.114.202 | 628 | 280 |
| 54.207.57.55 | 532 | 289 |
+-----------------+-------+---------+
select ua, count(*) as total from nginx group by ua order by total desc limit 10
+-----------------------------------------------+-------+
| ua | total |
+-----------------------------------------------+-------+
| Debian APT-HTTP/1.3 (1.0.1ubuntu2) | 11830 |
| Debian APT-HTTP/1.3 (0.9.7.9) | 11365 |
| Debian APT-HTTP/1.3 (0.8.16~exp12ubuntu10.21) | 6719 |
| Debian APT-HTTP/1.3 (0.8.16~exp12ubuntu10.16) | 5740 |
| Debian APT-HTTP/1.3 (0.8.16~exp12ubuntu10.22) | 3855 |
| Debian APT-HTTP/1.3 (0.8.16~exp12ubuntu10.17) | 1827 |
| Debian APT-HTTP/1.3 (0.8.16~exp12ubuntu10.7) | 1255 |
| urlgrabber/3.9.1 yum/3.2.29 | 792 |
| Debian APT-HTTP/1.3 (0.9.7.8) | 750 |
| urlgrabber/3.9.1 yum/3.4.3 | 708 |
+-----------------------------------------------+-------+
select url, count(*) as total from nginx group by url order by total desc limit 10
+----------------------+-------+
| url | total |
+----------------------+-------+
| /downloads/product_1 | 30285 |
| /downloads/product_2 | 21104 |
| /downloads/product_3 | 73 |
+----------------------+-------+
select len, count(*) as total from nginx group by len order by total desc limit 10
+-----+-------+
| len | total |
+-----+-------+
| 0 | 13413 |
| 336 | 6652 |
| 333 | 3771 |
| 338 | 3393 |
| 337 | 3268 |
| 339 | 2999 |
| 331 | 2867 |
| 340 | 1629 |
| 334 | 1393 |
| 332 | 1240 |
+-----+-------+
select ip, date, url, code, ua from nginx where method = 'HEAD' limit 10
+----------------+----------------------------+----------------------+------+-------------------------+
| ip | date | url | code | ua |
+----------------+----------------------------+----------------------+------+-------------------------+
| 184.173.149.15 | 23/May/2015:15:05:53 +0000 | /downloads/product_2 | 403 | Wget/1.13.4 (linux-gnu) |
| 5.153.24.140 | 23/May/2015:17:05:30 +0000 | /downloads/product_2 | 200 | Wget/1.13.4 (linux-gnu) |
| 5.153.24.140 | 23/May/2015:17:05:33 +0000 | /downloads/product_2 | 403 | Wget/1.13.4 (linux-gnu) |
| 5.153.24.140 | 23/May/2015:17:05:34 +0000 | /downloads/product_2 | 403 | Wget/1.13.4 (linux-gnu) |
| 5.153.24.140 | 23/May/2015:17:05:52 +0000 | /downloads/product_2 | 200 | Wget/1.13.4 (linux-gnu) |
| 5.153.24.140 | 23/May/2015:17:05:43 +0000 | /downloads/product_2 | 200 | Wget/1.13.4 (linux-gnu) |
| 5.153.24.140 | 23/May/2015:17:05:42 +0000 | /downloads/product_2 | 200 | Wget/1.13.4 (linux-gnu) |
| 5.153.24.140 | 23/May/2015:17:05:46 +0000 | /downloads/product_2 | 200 | Wget/1.13.4 (linux-gnu) |
| 5.153.24.140 | 23/May/2015:18:05:10 +0000 | /downloads/product_2 | 200 | Wget/1.13.4 (linux-gnu) |
| 184.173.149.16 | 24/May/2015:18:05:37 +0000 | /downloads/product_2 | 403 | Wget/1.13.4 (linux-gnu) |
+----------------+----------------------------+----------------------+------+-------------------------+
select ip, date, url, ua from nginx where code = 403 limit 10
+----------------+----------------------------+----------------------+-----------------------------------------------------------------------------------------------------+
| ip | date | url | ua |
+----------------+----------------------------+----------------------+-----------------------------------------------------------------------------------------------------+
| 184.173.149.15 | 23/May/2015:15:05:53 +0000 | /downloads/product_2 | Wget/1.13.4 (linux-gnu) |
| 5.153.24.140 | 23/May/2015:17:05:33 +0000 | /downloads/product_2 | Wget/1.13.4 (linux-gnu) |
| 5.153.24.140 | 23/May/2015:17:05:34 +0000 | /downloads/product_2 | Wget/1.13.4 (linux-gnu) |
| 184.173.149.16 | 24/May/2015:18:05:37 +0000 | /downloads/product_2 | Wget/1.13.4 (linux-gnu) |
| 195.88.195.153 | 24/May/2015:23:05:05 +0000 | /downloads/product_2 | curl/7.22.0 (x86_64-pc-linux-gnu) libcurl/7.22.0 OpenSSL/1.0.1 zlib/1.2.3.4 libidn/1.23 librtmp/2.3 |
| 184.173.149.15 | 25/May/2015:04:05:14 +0000 | /downloads/product_2 | Wget/1.13.4 (linux-gnu) |
| 87.85.173.82 | 17/May/2015:14:05:07 +0000 | /downloads/product_2 | Wget/1.13.4 (linux-gnu) |
| 87.85.173.82 | 17/May/2015:14:05:11 +0000 | /downloads/product_2 | Wget/1.13.4 (linux-gnu) |
| 194.76.107.17 | 17/May/2015:16:05:50 +0000 | /downloads/product_2 | Wget/1.13.4 (linux-gnu) |
| 194.76.107.17 | 17/May/2015:17:05:40 +0000 | /downloads/product_2 | Wget/1.13.4 (linux-gnu) |
+----------------+----------------------------+----------------------+-----------------------------------------------------------------------------------------------------+
select ip, date, url, code from nginx where ua = '-' limit 10
+----------------+----------------------------+----------------------+------+
| ip | date | url | code |
+----------------+----------------------------+----------------------+------+
| 217.168.17.150 | 01/Jun/2015:14:06:45 +0000 | /downloads/product_2 | 200 |
| 217.168.17.180 | 01/Jun/2015:14:06:15 +0000 | /downloads/product_2 | 200 |
| 217.168.17.150 | 01/Jun/2015:14:06:18 +0000 | /downloads/product_1 | 200 |
| 204.197.211.70 | 24/May/2015:06:05:02 +0000 | /downloads/product_2 | 200 |
| 91.74.184.74 | 29/May/2015:14:05:17 +0000 | /downloads/product_2 | 403 |
| 91.74.184.74 | 29/May/2015:15:05:43 +0000 | /downloads/product_2 | 403 |
| 91.74.184.74 | 29/May/2015:22:05:53 +0000 | /downloads/product_2 | 403 |
| 217.168.17.5 | 31/May/2015:02:05:16 +0000 | /downloads/product_2 | 200 |
| 217.168.17.180 | 20/May/2015:23:05:22 +0000 | /downloads/product_2 | 200 |
| 204.197.211.70 | 21/May/2015:02:05:34 +0000 | /downloads/product_2 | 200 |
+----------------+----------------------------+----------------------+------+
select * from (select ip, date, url, ua, len, PERCENT_RANK() OVER (ORDER BY len) as len_percentile from nginx where code = 200 order by len desc) as t where t.len_percentile > 0.5 and t.len_percentile < 0.7 order by t.len_percentile desc limit 10
+----------------+----------------------------+----------------------+-----------------------------+------+--------------------+
| ip | date | url | ua | len | len_percentile |
+----------------+----------------------------+----------------------+-----------------------------+------+--------------------+
| 54.229.83.18 | 26/May/2015:00:05:34 +0000 | /downloads/product_1 | urlgrabber/3.9.1 yum/3.4.3 | 2592 | 0.6342190216041719 |
| 54.244.37.198 | 18/May/2015:10:05:39 +0000 | /downloads/product_1 | urlgrabber/3.9.1 yum/3.4.3 | 2592 | 0.6342190216041719 |
| 67.132.206.254 | 29/May/2015:07:05:52 +0000 | /downloads/product_1 | urlgrabber/3.9.1 yum/3.2.29 | 2592 | 0.6342190216041719 |
| 128.199.60.184 | 24/May/2015:00:05:09 +0000 | /downloads/product_1 | urlgrabber/3.10 yum/3.4.3 | 2592 | 0.6342190216041719 |
| 54.173.6.142 | 27/May/2015:14:05:21 +0000 | /downloads/product_1 | urlgrabber/3.9.1 yum/3.4.3 | 2592 | 0.6342190216041719 |
| 104.156.250.12 | 03/Jun/2015:11:06:51 +0000 | /downloads/product_1 | urlgrabber/3.9.1 yum/3.2.29 | 2592 | 0.6342190216041719 |
| 115.198.47.126 | 25/May/2015:11:05:13 +0000 | /downloads/product_1 | urlgrabber/3.10 yum/3.4.3 | 2592 | 0.6342190216041719 |
| 198.105.198.4 | 29/May/2015:07:05:34 +0000 | /downloads/product_1 | urlgrabber/3.9.1 yum/3.2.29 | 2592 | 0.6342190216041719 |
| 107.23.164.80 | 31/May/2015:09:05:34 +0000 | /downloads/product_1 | urlgrabber/3.9.1 yum/3.4.3 | 2592 | 0.6342190216041719 |
| 108.61.251.29 | 31/May/2015:10:05:16 +0000 | /downloads/product_1 | urlgrabber/3.9.1 yum/3.2.29 | 2592 | 0.6342190216041719 |
+----------------+----------------------------+----------------------+-----------------------------+------+--------------------+
小结
今天我们介绍了如何使用 Rust 处理存放在关系数据库中的结构化数据,以及存放在文件系统中的半结构化数据。
虽然在工作中,我们不太会使用 arrow/datafusion 去创建某个“下一代”的数据处理平台,但拥有了处理半结构化数据的能力,可以解决很多非常实际的问题。
比如每隔 10 分钟扫描 Nginx / CDN,以及应用服务器过去 10 分钟的日志,找到某些非正常的访问,然后把该用户/设备的访问切断一阵子。这样的特殊需求,一般的数据平台很难处理,需要我们自己撰写代码来实现。此时,arrow/datafusion 这样的工具就很方便。
思考题
- 请你自己阅读 diesel 或者 sea-orm 的文档,然后尝试把我们直接用 sqlx 构建的用户注册/登录的功能使用 diesel 或者 sea-orm 实现。
- datafusion 不但支持 csv,还支持 ndJSON / parquet / avro 等数据类型。如果你公司的生产环境下有这些类型的半结构化数据,可以尝试着阅读相关文档,使用 datafusion 来读取和查询它们。
感谢你的收听。恭喜你完成了第44次Rust学习,打卡之旅马上就要结束啦,我们下节课见。
阶段实操(8):构建一个简单的KV server-配置/测试/监控/CI/CD
你好,我是陈天。
终于来到了我们这个 KV server 系列的终章。其实原本 KV server 我只计划了 4 讲,但现在 8 讲似乎都还有些意犹未尽。虽然这是一个“简单”的 KV server,它没有复杂的性能优化 —— 我们只用了一句 unsafe;也没有复杂的生命周期处理 —— 只有零星 'static 标注;更没有支持集群的处理。
然而,如果你能够理解到目前为止的代码,甚至能独立写出这样的代码,那么,你已经具备足够的、能在一线大厂开发的实力了,国内我不是特别清楚,但在北美这边,保守一些地说,300k+ USD 的 package 应该可以轻松拿到。
今天我们就给KV server项目收个尾,结合之前梳理的实战中 Rust 项目应该考虑的问题,来聊聊和生产环境有关的一些处理,按开发流程,主要讲五个方面:配置、集成测试、性能测试、测量和监控、CI/CD。
配置
首先在 Cargo.toml 里添加 serde 和 toml。我们计划使用 toml 做配置文件,serde 用来处理配置的序列化和反序列化:
#![allow(unused)] fn main() { [dependencies] ... serde = { version = "1", features = ["derive"] } # 序列化/反序列化 ... toml = "0.5" # toml 支持 ... }
然后来创建一个 src/config.rs,构建 KV server 的配置:
#![allow(unused)] fn main() { use crate::KvError; use serde::{Deserialize, Serialize}; use std::fs; #[derive(Clone, Debug, Serialize, Deserialize, PartialEq)] pub struct ServerConfig { pub general: GeneralConfig, pub storage: StorageConfig, pub tls: ServerTlsConfig, } #[derive(Clone, Debug, Serialize, Deserialize, PartialEq)] pub struct ClientConfig { pub general: GeneralConfig, pub tls: ClientTlsConfig, } #[derive(Clone, Debug, Serialize, Deserialize, PartialEq)] pub struct GeneralConfig { pub addr: String, } #[derive(Clone, Debug, Serialize, Deserialize, PartialEq)] #[serde(tag = "type", content = "args")] pub enum StorageConfig { MemTable, SledDb(String), } #[derive(Clone, Debug, Serialize, Deserialize, PartialEq)] pub struct ServerTlsConfig { pub cert: String, pub key: String, pub ca: Option<String>, } #[derive(Clone, Debug, Serialize, Deserialize, PartialEq)] pub struct ClientTlsConfig { pub domain: String, pub identity: Option<(String, String)>, pub ca: Option<String>, } impl ServerConfig { pub fn load(path: &str) -> Result<Self, KvError> { let config = fs::read_to_string(path)?; let config: Self = toml::from_str(&config)?; Ok(config) } } impl ClientConfig { pub fn load(path: &str) -> Result<Self, KvError> { let config = fs::read_to_string(path)?; let config: Self = toml::from_str(&config)?; Ok(config) } } #[cfg(test)] mod tests { use super::*; #[test] fn server_config_should_be_loaded() { let result: Result<ServerConfig, toml::de::Error> = toml::from_str(include_str!("../fixtures/server.conf")); assert!(result.is_ok()); } #[test] fn client_config_should_be_loaded() { let result: Result<ClientConfig, toml::de::Error> = toml::from_str(include_str!("../fixtures/client.conf")); assert!(result.is_ok()); } } }
你可以看到,在 Rust 下,有了 serde 的帮助,处理任何已知格式的配置文件,是多么容易的一件事情。我们 只需要定义数据结构,并为数据结构使用 Serialize/Deserialize 派生宏,就可以处理任何支持 serde 的数据结构。
我还写了个 examples/gen_config.rs(你可以自行去查阅它的代码),用来生成配置文件,下面是生成的服务端的配置:
#![allow(unused)] fn main() { [general] addr = '127.0.0.1:9527' [storage] type = 'SledDb' args = '/tmp/kv_server' [tls] cert = """ -----BEGIN CERTIFICATE-----\r MIIBdzCCASmgAwIBAgIICpy02U2yuPowBQYDK2VwMDMxCzAJBgNVBAYMAkNOMRIw\r EAYDVQQKDAlBY21lIEluYy4xEDAOBgNVBAMMB0FjbWUgQ0EwHhcNMjEwOTI2MDEy\r NTU5WhcNMjYwOTI1MDEyNTU5WjA6MQswCQYDVQQGDAJDTjESMBAGA1UECgwJQWNt\r ZSBJbmMuMRcwFQYDVQQDDA5BY21lIEtWIHNlcnZlcjAqMAUGAytlcAMhAK2Z2AjF\r A0uiltNuCvl6EVFl6tpaS/wJYB5IdWT2IISdo1QwUjAcBgNVHREEFTATghFrdnNl\r cnZlci5hY21lLmluYzATBgNVHSUEDDAKBggrBgEFBQcDATAMBgNVHRMEBTADAQEA\r MA8GA1UdDwEB/wQFAwMH4AAwBQYDK2VwA0EASGOmOWFPjbGhXNOmYNCa3lInbgRy\r iTNtB/5kElnbKkhKhRU7yQ8HTHWWkyU5WGWbOOIXEtYp+5ERUJC+mzP9Bw==\r -----END CERTIFICATE-----\r """ key = """ -----BEGIN PRIVATE KEY-----\r MFMCAQEwBQYDK2VwBCIEIPMyINaewhXwuTPUufFO2mMt/MvQMHrGDGxgdgfy/kUu\r oSMDIQCtmdgIxQNLopbTbgr5ehFRZeraWkv8CWAeSHVk9iCEnQ==\r -----END PRIVATE KEY-----\r """ }
有了配置文件的支持,就可以在 lib.rs 下写一些辅助函数,让我们创建服务端和客户端更加简单:
#![allow(unused)] fn main() { mod config; mod error; mod network; mod pb; mod service; mod storage; pub use config::*; pub use error::KvError; pub use network::*; pub use pb::abi::*; pub use service::*; pub use storage::*; use anyhow::Result; use tokio::net::{TcpListener, TcpStream}; use tokio_rustls::client; use tokio_util::compat::FuturesAsyncReadCompatExt; use tracing::info; /// 通过配置创建 KV 服务器 pub async fn start_server_with_config(config: &ServerConfig) -> Result<()> { let acceptor = TlsServerAcceptor::new(&config.tls.cert, &config.tls.key, config.tls.ca.as_deref())?; let addr = &config.general.addr; match &config.storage { StorageConfig::MemTable => start_tls_server(addr, MemTable::new(), acceptor).await?, StorageConfig::SledDb(path) => start_tls_server(addr, SledDb::new(path), acceptor).await?, }; Ok(()) } /// 通过配置创建 KV 客户端 pub async fn start_client_with_config( config: &ClientConfig, ) -> Result<YamuxCtrl<client::TlsStream<TcpStream>>> { let addr = &config.general.addr; let tls = &config.tls; let identity = tls.identity.as_ref().map(|(c, k)| (c.as_str(), k.as_str())); let connector = TlsClientConnector::new(&tls.domain, identity, tls.ca.as_deref())?; let stream = TcpStream::connect(addr).await?; let stream = connector.connect(stream).await?; // 打开一个 stream Ok(YamuxCtrl::new_client(stream, None)) } async fn start_tls_server<Store: Storage>( addr: &str, store: Store, acceptor: TlsServerAcceptor, ) -> Result<()> { let service: Service<Store> = ServiceInner::new(store).into(); let listener = TcpListener::bind(addr).await?; info!("Start listening on {}", addr); loop { let tls = acceptor.clone(); let (stream, addr) = listener.accept().await?; info!("Client {:?} connected", addr); let svc = service.clone(); tokio::spawn(async move { let stream = tls.accept(stream).await.unwrap(); YamuxCtrl::new_server(stream, None, move |stream| { let svc1 = svc.clone(); async move { let stream = ProstServerStream::new(stream.compat(), svc1.clone()); stream.process().await.unwrap(); Ok(()) } }); }); } } }
有了 start_server_with_config 和 start_client_with_config 这两个辅助函数,我们就可以简化 src/server.rs 和 src/client.rs 了。下面是 src/server.rs 的新代码:
use anyhow::Result; use kv6::{start_server_with_config, ServerConfig}; #[tokio::main] async fn main() -> Result<()> { tracing_subscriber::fmt::init(); let config: ServerConfig = toml::from_str(include_str!("../fixtures/server.conf"))?; start_server_with_config(&config).await?; Ok(()) }
可以看到,整个代码简洁了很多。在这个重构的过程中,还有一些其它改动,你可以看 GitHub repo 下 45 讲的 diff_config。
集成测试
之前我们写了很多单元测试,但还没有写过一行集成测试。今天就来写一个简单的集成测试,确保客户端和服务器完整的交互工作正常。
之前提到在 Rust 里,集成测试放在 tests 目录下,每个测试编成单独的二进制。所以首先,我们创建和 src 平行的 tests 目录。然后再创建 tests/server.rs,填入以下代码:
#![allow(unused)] fn main() { use anyhow::Result; use kv6::{ start_client_with_config, start_server_with_config, ClientConfig, CommandRequest, ProstClientStream, ServerConfig, StorageConfig, }; use std::time::Duration; use tokio::time; #[tokio::test] async fn yamux_server_client_full_tests() -> Result<()> { let addr = "127.0.0.1:10086"; let mut config: ServerConfig = toml::from_str(include_str!("../fixtures/server.conf"))?; config.general.addr = addr.into(); config.storage = StorageConfig::MemTable; // 启动服务器 tokio::spawn(async move { start_server_with_config(&config).await.unwrap(); }); time::sleep(Duration::from_millis(10)).await; let mut config: ClientConfig = toml::from_str(include_str!("../fixtures/client.conf"))?; config.general.addr = addr.into(); let mut ctrl = start_client_with_config(&config).await.unwrap(); let stream = ctrl.open_stream().await?; let mut client = ProstClientStream::new(stream); // 生成一个 HSET 命令 let cmd = CommandRequest::new_hset("table1", "hello", "world".to_string().into()); client.execute_unary(&cmd).await?; // 生成一个 HGET 命令 let cmd = CommandRequest::new_hget("table1", "hello"); let data = client.execute_unary(&cmd).await?; assert_eq!(data.status, 200); assert_eq!(data.values, &["world".into()]); Ok(()) } }
可以看到, 集成测试的写法和单元测试其实很类似,只不过我们不需要再使用 #[cfg(test)] 来做条件编译。
如果你的集成测试比较复杂,需要比较多的辅助代码,那么你还可以在 tests 下 cargo new 出一个项目,然后在那个项目里撰写辅助代码和测试代码。如果你对此感兴趣,可以看 tonic 的集成测试。不过注意了,集成测试和你的 crate 用同样的条件编译,所以在集成测试里,无法使用单元测试中构建的辅助代码。
性能测试
在之前不断完善 KV server 的过程中,你一定会好奇:我们的 KV server 性能究竟如何呢?那来写一个关于 Pub/Sub 的性能测试吧。
基本的想法是我们连上 100 个 subscriber 作为背景,然后看 publisher publish 的速度。
因为 BROADCAST_CAPACITY 有限,是 128,当 publisher 速度太快,而导致 server 不能及时往 subscriber 发送时,server 接收 client 数据的速度就会降下来,无法接收新的 client,整体的 publish 的速度也会降下来,所以这个测试能够了解 server 处理 publish 的速度。
为了确认这一点,我们在 start_tls_server() 函数中,在 process() 之前,再加个 100ms 的延时,人为减缓系统的处理速度:
#![allow(unused)] fn main() { async move { let stream = ProstServerStream::new(stream.compat(), svc1.clone()); // 延迟 100ms 处理 time::sleep(Duration::from_millis(100)).await; stream.process().await.unwrap(); Ok(()) } }
好,现在可以写性能测试了。
在 Rust 下,我们可以用 criterion 库。它可以处理基本的性能测试,并生成漂亮的报告。所以在 Cargo.toml 中加入:
#![allow(unused)] fn main() { [dev-dependencies] ... criterion = { version = "0.3", features = ["async_futures", "async_tokio", "html_reports"] } # benchmark ... rand = "0.8" # 随机数处理 ... [[bench]] name = "pubsub" harness = false }
最后这个 bench section,描述了性能测试的名字,它对应 benches 目录下的同名文件。
我们创建和 src 平级的 benches,然后再创建 benches/pubsub.rs,添入如下代码:
#![allow(unused)] fn main() { use anyhow::Result; use criterion::{criterion_group, criterion_main, Criterion}; use futures::StreamExt; use kv6::{ start_client_with_config, start_server_with_config, ClientConfig, CommandRequest, ServerConfig, StorageConfig, YamuxCtrl, }; use rand::prelude::SliceRandom; use std::time::Duration; use tokio::net::TcpStream; use tokio::runtime::Builder; use tokio::time; use tokio_rustls::client::TlsStream; use tracing::info; async fn start_server() -> Result<()> { let addr = "127.0.0.1:9999"; let mut config: ServerConfig = toml::from_str(include_str!("../fixtures/server.conf"))?; config.general.addr = addr.into(); config.storage = StorageConfig::MemTable; tokio::spawn(async move { start_server_with_config(&config).await.unwrap(); }); Ok(()) } async fn connect() -> Result<YamuxCtrl<TlsStream<TcpStream>>> { let addr = "127.0.0.1:9999"; let mut config: ClientConfig = toml::from_str(include_str!("../fixtures/client.conf"))?; config.general.addr = addr.into(); Ok(start_client_with_config(&config).await?) } async fn start_subscribers(topic: &'static str) -> Result<()> { let mut ctrl = connect().await?; let stream = ctrl.open_stream().await?; info!("C(subscriber): stream opened"); let cmd = CommandRequest::new_subscribe(topic.to_string()); tokio::spawn(async move { let mut stream = stream.execute_streaming(&cmd).await.unwrap(); while let Some(Ok(data)) = stream.next().await { drop(data); } }); Ok(()) } async fn start_publishers(topic: &'static str, values: &'static [&'static str]) -> Result<()> { let mut rng = rand::thread_rng(); let v = values.choose(&mut rng).unwrap(); let mut ctrl = connect().await.unwrap(); let mut stream = ctrl.open_stream().await.unwrap(); info!("C(publisher): stream opened"); let cmd = CommandRequest::new_publish(topic.to_string(), vec![(*v).into()]); stream.execute_unary(&cmd).await.unwrap(); Ok(()) } fn pubsub(c: &mut Criterion) { // tracing_subscriber::fmt::init(); // 创建 Tokio runtime let runtime = Builder::new_multi_thread() .worker_threads(4) .thread_name("pubsub") .enable_all() .build() .unwrap(); let values = &["Hello", "Tyr", "Goodbye", "World"]; let topic = "lobby"; // 运行服务器和 100 个 subscriber,为测试准备 runtime.block_on(async { eprint!("preparing server and subscribers"); start_server().await.unwrap(); time::sleep(Duration::from_millis(50)).await; for _ in 0..100 { start_subscribers(topic).await.unwrap(); eprint!("."); } eprintln!("Done!"); }); // 进行 benchmark c.bench_function("publishing", move |b| { b.to_async(&runtime) .iter(|| async { start_publishers(topic, values).await }) }); } criterion_group! { name = benches; config = Criterion::default().sample_size(10); targets = pubsub } criterion_main!(benches); }
大部分的代码都很好理解,就是创建服务器和客户端,为测试做准备。说一下这里面核心的 benchmark 代码:
#![allow(unused)] fn main() { c.bench_function("publishing", move |b| { b.to_async(&runtime) .iter(|| async { start_publishers(topic, values).await }) }); }
对于要测试的代码,我们可以封装成一个函数进行测试。 这里因为要做 async 函数的测试,需要使用 runtime。普通的函数不需要调用 to_async。对于更多有关 criterion 的用法,可以参考它的文档。
运行 cargo bench 后,会见到如下打印(如果你的代码无法通过,可以参考 repo 里的 diff_benchmark,我顺便做了一点小重构):
preparing server and subscribers....................................................................................................Done!
publishing time: [419.73 ms 426.84 ms 434.20 ms]
change: [-1.6712% +1.0499% +3.6586%] (p = 0.48 > 0.05)
No change in performance detected.
可以看到,单个 publish 的处理速度要 426ms,好慢!我们把之前在 start_tls_server() 里加的延迟去掉,再次测试:
preparing server and subscribers....................................................................................................Done!
publishing time: [318.61 ms 324.48 ms 329.81 ms]
change: [-25.854% -23.980% -22.144%] (p = 0.00 < 0.05)
Performance has improved.
嗯,这下 324ms,正好是减去刚才加的 100ms。可是这个速度依旧不合理,凭直觉我们感觉一下这个速度,是 Python 这样的语言还正常,如果是 Rust 也太慢了吧?
测量和监控
工业界有句名言:如果你无法测量,那你就无法改进(If you can’t measure it, you can’t improve it)。现在知道了 KV server 性能有问题,但并不知道问题出在哪里。我们需要使用合适的测量方式。
目前, 比较好的端对端的性能监控和测量工具是 jaeger,我们可以在 KV server/client 侧收集监控信息,发送给 jaeger 来查看在服务器和客户端的整个处理流程中,时间都花费到哪里去了。
之前我们在 KV server 里使用的日志工具是 tracing,不过日志只是它的诸多功能之一,它还能做 instrument,然后配合 opentelemetry 库,我们就可以把 instrument 的结果发送给 jaeger 了。
好,在 Cargo.toml 里添加新的依赖:
#![allow(unused)] fn main() { [dependencies] ... opentelemetry-jaeger = "0.15" # opentelemetry jaeger 支持 ... tracing-appender = "0.1" # 文件日志 tracing-opentelemetry = "0.15" # opentelemetry 支持 tracing-subscriber = { version = "0.2", features = ["json", "chrono"] } # 日志处理 }
有了这些依赖后,在 benches/pubsub.rs 里,我们可以在初始化 tracing_subscriber 时,使用 jaeger 和 opentelemetry tracer:
#![allow(unused)] fn main() { fn pubsub(c: &mut Criterion) { let tracer = opentelemetry_jaeger::new_pipeline() .with_service_name("kv-bench") .install_simple() .unwrap(); let opentelemetry = tracing_opentelemetry::layer().with_tracer(tracer); tracing_subscriber::registry() .with(EnvFilter::from_default_env()) .with(opentelemetry) .init(); let root = span!(tracing::Level::INFO, "app_start", work_units = 2); let _enter = root.enter(); // 创建 Tokio runtime ... } }
设置好 tracing 后,就在系统的主流程上添加相应的 instrument:
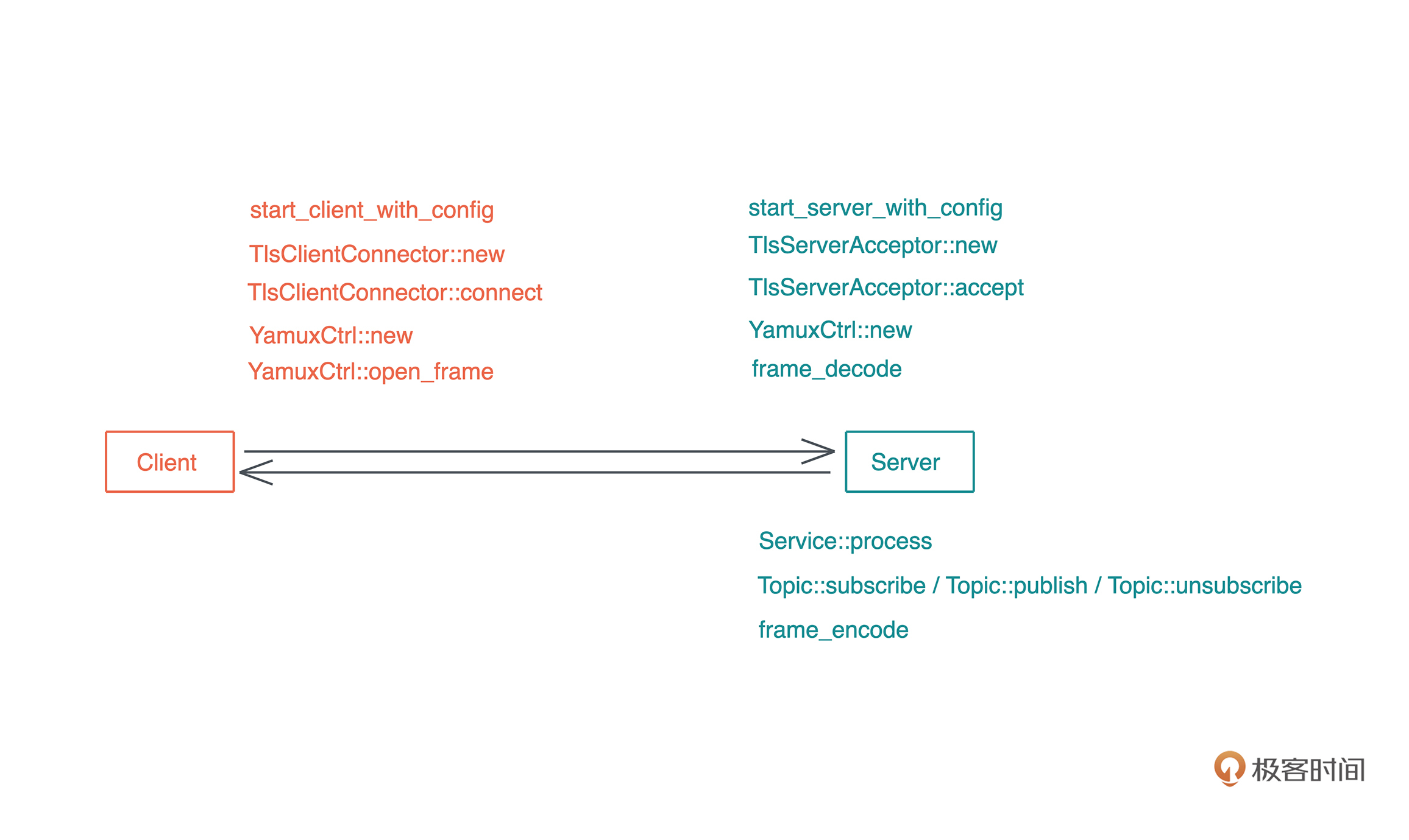
新添加的代码你可以看 repo 中的 diff_telemetry。注意 instrument 可以用不同的名称,比如,对于 TlsConnector::new() 函数,可以用 #[instrument(name = "tls_connector_new")],这样它的名字辨识度高一些。
为主流程中的函数添加完 instrument 后,你需要先打开一个窗口,运行 jaeger(需要 docker):
docker run -d -p6831:6831/udp -p6832:6832/udp -p16686:16686 -p14268:14268 jaegertracing/all-in-one:latest
然后带着 RUST_LOG=info 运行 benchmark:
RUST_LOG=info cargo bench
由于我的 OS X 上没装 docker(docker 不支持 Mac,需要 Linux VM 中转),我就在一个 Ubuntu 虚拟机里运行这两条命令:
preparing server and subscribers....................................................................................................Done!
publishing time: [1.7464 ms 1.9556 ms 2.2343 ms]
Found 2 outliers among 10 measurements (20.00%)
1 (10.00%) high mild
1 (10.00%) high severe
并没有做任何事情,似乎只是换了个系统,性能就提升了很多,这给我们一个 tip:也许问题出在 OS X 和 Linux 系统相关的部分。
不管怎样,已经发送了不少数据给 jaeger,我们到 jaeger 上看看问题出在哪里。
打开 http://localhost:16686/,service 选 kv-bench,Operation 选 app_start,点击 “Find Traces”,我们可以看到捕获的 trace。因为运行了两次 benchmark,所以有两个 app_start 的查询结果:
可以看到,每次 start_client_with_config 都要花 1.6-2.5ms,其中有差不多一小半时间花在了 TlsClientConnector::new() 上:
如果说 TlsClientConnector::connect() 花不少时间还情有可原,因为这是整个 TLS 协议的握手过程,涉及到网络调用、包的加解密等。 但 TlsClientConnector::new() 就是加载一些证书、创建 TlsConnector 这个数据结构而已,为何这么慢?
仔细阅读 TlsClientConnector::new() 的代码,你可以对照注释看:
#![allow(unused)] fn main() { #[instrument(name = "tls_connector_new", skip_all)] pub fn new( domain: impl Into<String> + std::fmt::Debug, identity: Option<(&str, &str)>, server_ca: Option<&str>, ) -> Result<Self, KvError> { let mut config = ClientConfig::new(); // 如果有客户端证书,加载之 if let Some((cert, key)) = identity { let certs = load_certs(cert)?; let key = load_key(key)?; config.set_single_client_cert(certs, key)?; } // 加载本地信任的根证书链 config.root_store = match rustls_native_certs::load_native_certs() { Ok(store) | Err((Some(store), _)) => store, Err((None, error)) => return Err(error.into()), }; // 如果有签署服务器的 CA 证书,则加载它,这样服务器证书不在根证书链 // 但是这个 CA 证书能验证它,也可以 if let Some(cert) = server_ca { let mut buf = Cursor::new(cert); config.root_store.add_pem_file(&mut buf).unwrap(); } Ok(Self { config: Arc::new(config), domain: Arc::new(domain.into()), }) } }
可以发现,它的代码唯一可能影响性能的就是加载本地信任的根证书链的部分。这个代码会和操作系统交互,获取信任的根证书链。也许,这就是影响性能的原因之一?
那我们将其简单重构一下。因为根证书链,只有在客户端没有提供用于验证服务器证书的 CA 证书时,才需要,所以可以在没有 CA 证书时,才加载本地的根证书链:
#![allow(unused)] fn main() { #[instrument(name = "tls_connector_new", skip_all)] pub fn new( domain: impl Into<String> + std::fmt::Debug, identity: Option<(&str, &str)>, server_ca: Option<&str>, ) -> Result<Self, KvError> { let mut config = ClientConfig::new(); // 如果有客户端证书,加载之 if let Some((cert, key)) = identity { let certs = load_certs(cert)?; let key = load_key(key)?; config.set_single_client_cert(certs, key)?; } // 如果有签署服务器的 CA 证书,则加载它,这样服务器证书不在根证书链 // 但是这个 CA 证书能验证它,也可以 if let Some(cert) = server_ca { let mut buf = Cursor::new(cert); config.root_store.add_pem_file(&mut buf).unwrap(); } else { // 加载本地信任的根证书链 config.root_store = match rustls_native_certs::load_native_certs() { Ok(store) | Err((Some(store), _)) => store, Err((None, error)) => return Err(error.into()), }; } Ok(Self { config: Arc::new(config), domain: Arc::new(domain.into()), }) } }
完成这个修改后,我们再运行 RUST_LOG=info cargo bench,现在的性能达到了 1.64ms,相比之前的 1.95ms,提升了 16%。
打开 jaeger,看最新的 app_start 结果,发现 TlsClientConnector::new() 所花时间降到了 ~12us 左右。嗯,虽然没有抓到服务器本身的 bug,但客户端的 bug 倒是解决了一个。
至于服务器,如果我们看 Service::execute 的主流程,执行速度在 40-60us,问题不大:
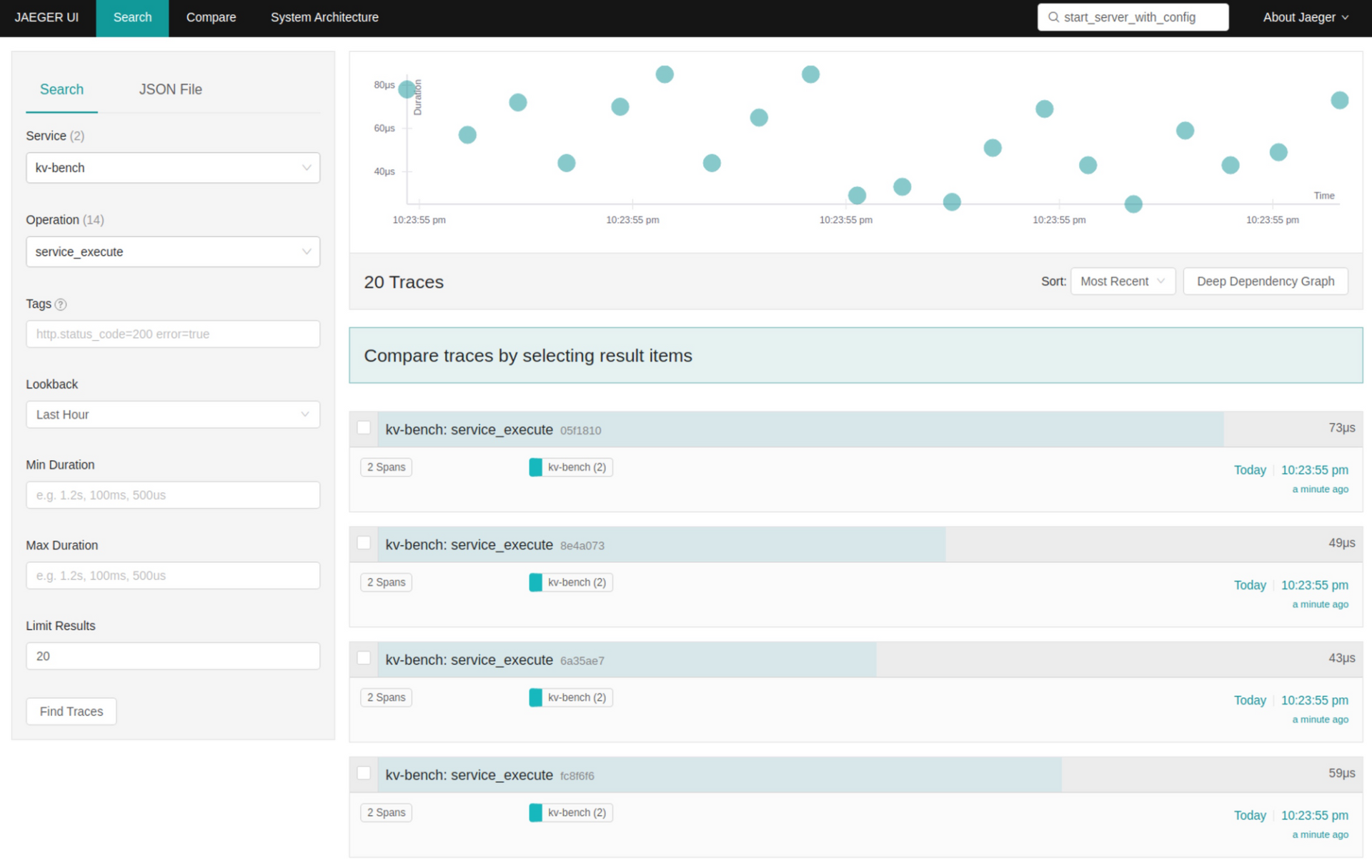
再看服务器的主流程 server_process:
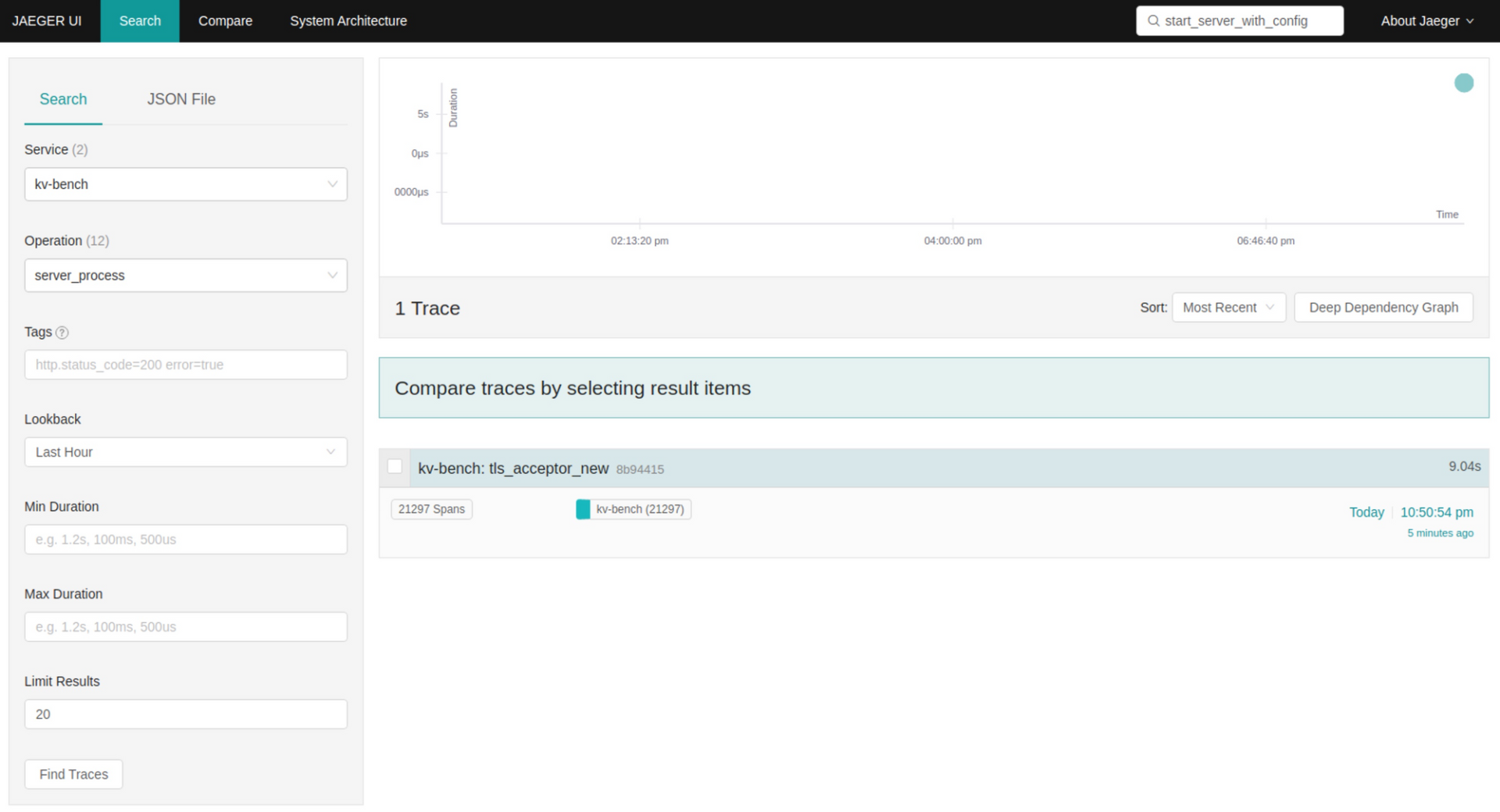
这是我们在 start_tls_server() 里额外添加的 tracing span:
#![allow(unused)] fn main() { loop { let root = span!(tracing::Level::INFO, "server_process"); let _enter = root.enter(); ... } }
把右上角的 trace timeline 改成 trace graph,然后点右侧的 time:
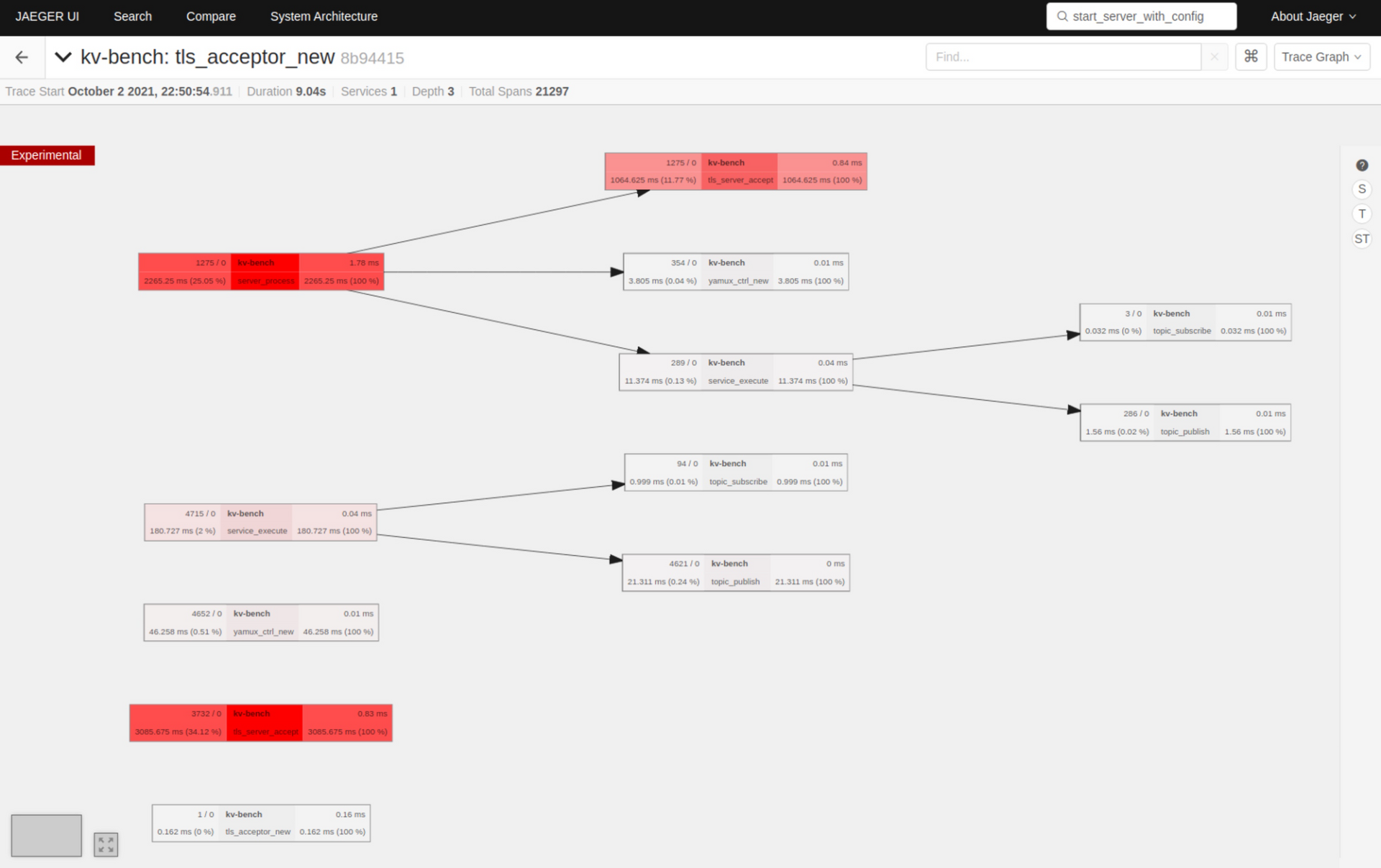
可以看到,主要的服务器时间都花在了 TLS accept 上,所以, 目前服务器没有太多值得优化的地方。
由于 tracing 本身也占用不少 CPU,所以我们直接 cargo bench 看看目前的结果:
preparing server and subscribers....................................................................................................Done!
publishing time: [1.3986 ms 1.4140 ms 1.4474 ms]
change: [-26.647% -19.977% -10.798%] (p = 0.00 < 0.05)
Performance has improved.
Found 2 outliers among 10 measurements (20.00%)
2 (20.00%) high severe
不加 RUST_LOG=info 后,整体性能到了 1.4ms。这是我在 Ubuntu 虚拟机下的结果。
我们再回到 OS X 下测试,看看 TlsClientConnector::new() 的修改,对OS X 是否有效:
preparing server and subscribers....................................................................................................Done!
publishing time: [1.4086 ms 1.4229 ms 1.4315 ms]
change: [-99.570% -99.563% -99.554%] (p = 0.00 < 0.05)
Performance has improved.
嗯,在我的 OS X下,现在整体性能也到了 1.4ms 的水平。这也意味着,在有 100 个 subscribers 的情况下,我们的 KV server 每秒钟可以处理 714k publish 请求;而在 1000 个 subscribers 的情况下,性能在 11.1ms 的水平,也就是每秒可以处理 90k publish 请求:
publishing time: [11.007 ms 11.095 ms 11.253 ms]
change: [-96.618% -96.556% -96.486%] (p = 0.00 < 0.05)
Performance has improved.
你也许会觉得目前 publish 的 value 太小,那换一些更加贴近实际的字符串大小:
#![allow(unused)] fn main() { // let values = &["Hello", "Tyr", "Goodbye", "World"]; let base_str = include_str!("../fixtures/server.conf"); // 891 bytes let values: &'static [&'static str] = Box::leak( vec![ &base_str[..64], &base_str[..128], &base_str[..256], &base_str[..512], ] .into_boxed_slice(), ); }
测试结果差不太多:
publishing time: [10.917 ms 11.098 ms 11.428 ms]
change: [-0.4822% +2.3311% +4.9631%] (p = 0.12 > 0.05)
No change in performance detected.
criterion 还会生成漂亮的 report,你可以用浏览器打开 ./target/criterion/publishing/report/index.html 查看(名字是publishing ,因为 benchmark ID 是 publishing):
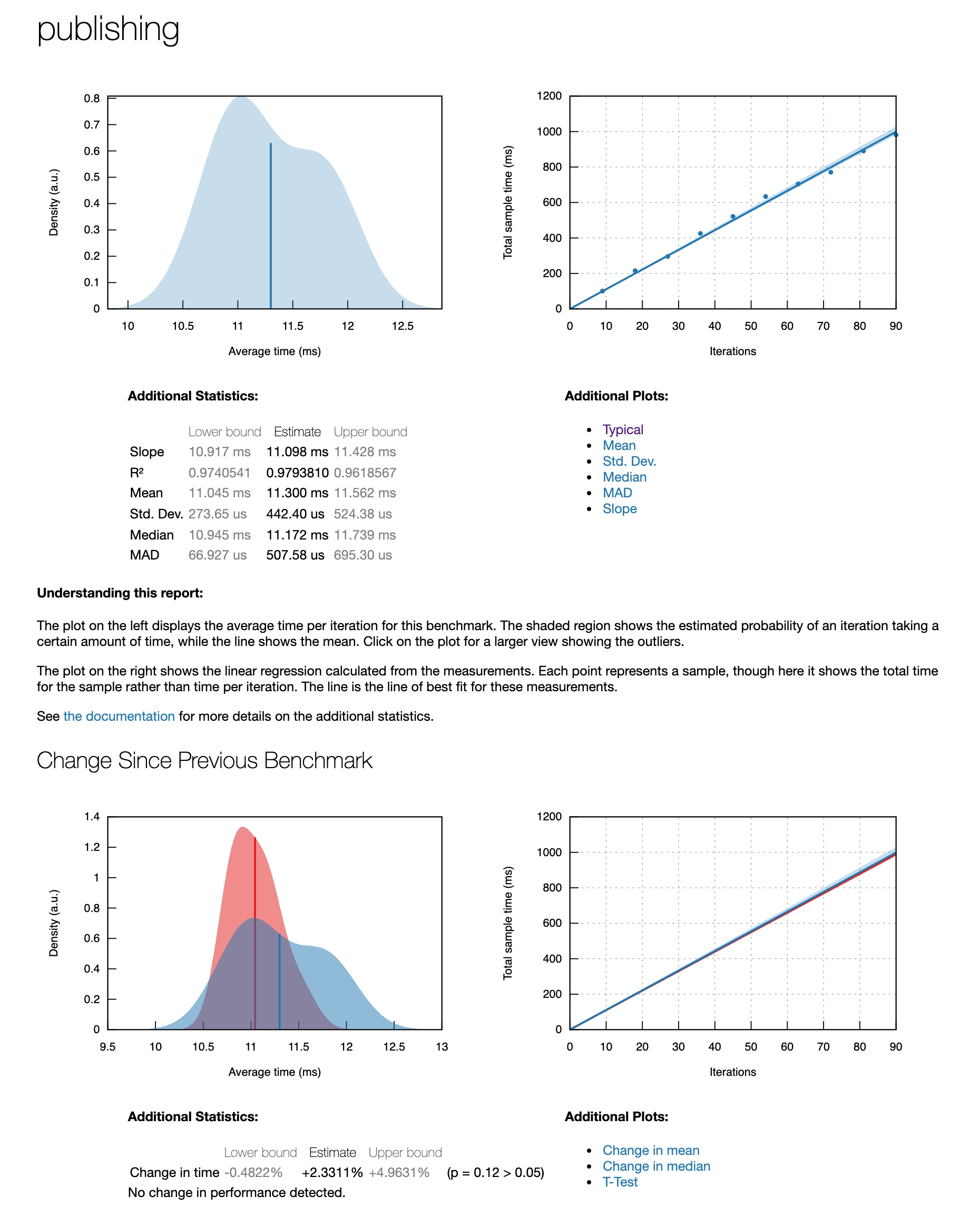
好,处理完性能相关的问题,我们来 为 server 添加日志和性能监测的支持:
use std::env; use anyhow::Result; use kv6::{start_server_with_config, RotationConfig, ServerConfig}; use tokio::fs; use tracing::span; use tracing_subscriber::{ fmt::{self, format}, layer::SubscriberExt, prelude::*, EnvFilter, }; #[tokio::main] async fn main() -> Result<()> { // 如果有环境变量,使用环境变量中的 config let config = match env::var("KV_SERVER_CONFIG") { Ok(path) => fs::read_to_string(&path).await?, Err(_) => include_str!("../fixtures/server.conf").to_string(), }; let config: ServerConfig = toml::from_str(&config)?; let tracer = opentelemetry_jaeger::new_pipeline() .with_service_name("kv-server") .install_simple()?; let opentelemetry = tracing_opentelemetry::layer().with_tracer(tracer); // 添加 let log = &config.log; let file_appender = match log.rotation { RotationConfig::Hourly => tracing_appender::rolling::hourly(&log.path, "server.log"), RotationConfig::Daily => tracing_appender::rolling::daily(&log.path, "server.log"), RotationConfig::Never => tracing_appender::rolling::never(&log.path, "server.log"), }; let (non_blocking, _guard1) = tracing_appender::non_blocking(file_appender); let fmt_layer = fmt::layer() .event_format(format().compact()) .with_writer(non_blocking); tracing_subscriber::registry() .with(EnvFilter::from_default_env()) .with(fmt_layer) .with(opentelemetry) .init(); let root = span!(tracing::Level::INFO, "app_start", work_units = 2); let _enter = root.enter(); start_server_with_config(&config).await?; Ok(()) }
为了让日志能在配置文件中配置,需要更新一下 src/config.rs:
#![allow(unused)] fn main() { #[derive(Clone, Debug, Serialize, Deserialize, PartialEq)] pub struct ServerConfig { pub general: GeneralConfig, pub storage: StorageConfig, pub tls: ServerTlsConfig, pub log: LogConfig, } #[derive(Clone, Debug, Serialize, Deserialize, PartialEq)] pub struct LogConfig { pub path: String, pub rotation: RotationConfig, } #[derive(Clone, Debug, Serialize, Deserialize, PartialEq)] pub enum RotationConfig { Hourly, Daily, Never, } }
你还需要更新 examples/gen_config.rs。相关的改变可以看 repo 下的 diff_logging。
tracing 和 opentelemetry 还支持 prometheus,你可以使用 opentelemetry-prometheus 来和 prometheus 交互,如果有兴趣,你可以自己深入研究一下。
CI/CD
为了讲述方便,我把 CI/CD 放在最后,但 CI/CD 应该是在一开始的时候就妥善设置的。
先说CI吧。这个课程的 repo tyrchen/geektime-rust 在一开始就设置了 github action,每次 commit 都会运行:
- 代码格式检查:cargo fmt
- 依赖 license 检查:cargo deny
- linting:cargo check 和 cargo clippy
- 单元测试和集成测试:cargo test
- 生成文档:cargo doc
github action 配置如下,供你参考:
name: build
on:
push:
branches:
- master
pull_request:
branches:
- master
jobs:
build-rust:
strategy:
matrix:
platform: [ubuntu-latest, windows-latest]
runs-on: ${{ matrix.platform }}
steps:
- uses: actions/checkout@v2
- name: Cache cargo registry
uses: actions/cache@v1
with:
path: ~/.cargo/registry
key: ${{ runner.os }}-cargo-registry
- name: Cache cargo index
uses: actions/cache@v1
with:
path: ~/.cargo/git
key: ${{ runner.os }}-cargo-index
- name: Cache cargo build
uses: actions/cache@v1
with:
path: target
key: ${{ runner.os }}-cargo-build-target
- name: Install stable
uses: actions-rs/toolchain@v1
with:
profile: minimal
toolchain: stable
override: true
- name: Check code format
run: cargo fmt -- --check
- name: Check the package for errors
run: cargo check --all
- name: Lint rust sources
run: cargo clippy --all-targets --all-features --tests --benches -- -D warnings
- name: Run tests
run: cargo test --all-features -- --test-threads=1 --nocapture
- name: Generate docs
run: cargo doc --all-features --no-deps
- name: Deploy docs to gh-page
uses: peaceiris/actions-gh-pages@v3
with:
github_token: ${{ secrets.GITHUB_TOKEN }}
publish_dir: ./target/doc
除此之外,我们还可以在每次 push tag 时做 release:
name: release
on:
push:
tags:
- "v*" # Push events to matching v*, i.e. v1.0, v20.15.10
jobs:
build:
name: Upload Release Asset
runs-on: ${{ matrix.os }}
strategy:
matrix:
os: [ubuntu-latest]
steps:
- name: Cache cargo registry
uses: actions/cache@v1
with:
path: ~/.cargo/registry
key: ${{ runner.os }}-cargo-registry
- name: Cache cargo index
uses: actions/cache@v1
with:
path: ~/.cargo/git
key: ${{ runner.os }}-cargo-index
- name: Cache cargo build
uses: actions/cache@v1
with:
path: target
key: ${{ runner.os }}-cargo-build-target
- name: Checkout code
uses: actions/checkout@v2
with:
token: ${{ secrets.GH_TOKEN }}
submodules: recursive
- name: Build project
run: |
make build-release
- name: Create Release
id: create_release
uses: actions/create-release@v1
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
with:
tag_name: ${{ github.ref }}
release_name: Release ${{ github.ref }}
draft: false
prerelease: false
- name: Upload asset
id: upload-kv-asset
uses: actions/upload-release-asset@v1
env:
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
with:
upload_url: ${{ steps.create_release.outputs.upload_url }}
asset_path: ./target/release/kvs
asset_name: kvs
asset_content_type: application/octet-stream
- name: Set env
run: echo "RELEASE_VERSION=${GITHUB_REF#refs/*/}" >> $GITHUB_ENV
- name: Deploy docs to gh-page
uses: peaceiris/actions-gh-pages@v3
with:
github_token: ${{ secrets.GITHUB_TOKEN }}
publish_dir: ./target/doc/simple_kv
destination_dir: ${{ env.RELEASE_VERSION }}
这样,每次 push tag 时,都可以打包出来 Linux 的 kvs 版本:
如果你不希望直接使用编译出来的二进制,也可以打包成 docker,在 Kubernetes 下使用。
在做 CI 的过程中,我们也可以触发 CD,比如:
- PR merge 到 master,在 build 完成后,触发 dev 服务器的部署,团队内部可以尝试;
- 如果 release tag 包含 alpha,在 build 完成后,触发 staging 服务器的部署,公司内部可以使用;
- 如果 release tag 包含 beta,在 build 完成后,触发 beta 服务器的部署,beta 用户可以使用;
- 正式的 release tag 会触发生产环境的滚动升级,升级覆盖到的用户可以使用。
一般来说,每家企业都有自己的 CI/CD 的工具链,这里为了展示方便,我们演示了如何使用 github action 对 Rust 代码做 CI,你可以按照自己的需要来处理。
在刚才的 action 代码中,还编译并上传了文档,所以我们可以通过 github pages 很方便地访问文档:
小结
我们的 KV server 之旅就到此为止了。在整整 7 堂课里,我们一点点从零构造了一个完整的 KV server,包括注释在内,撰写了近三千行代码:
❯ tokei .
-------------------------------------------------------------------------------
Language Files Lines Code Comments Blanks
-------------------------------------------------------------------------------
Makefile 1 24 16 1 7
Markdown 1 7 7 0 0
Protocol Buffers 1 119 79 23 17
Rust 25 3366 2730 145 491
TOML 2 268 107 142 19
-------------------------------------------------------------------------------
Total 30 3784 2939 311 534
-------------------------------------------------------------------------------
这是一个非常了不起的成就!我们应该为自己感到自豪!
在这个系列里,我们大量使用 trait 和泛型,构建了很多复杂的数据结构;还为自己的类型实现了 AsyncRead / AsyncWrite / Stream / Sink 这些比较高阶的 trait。通过良好的设计,我们把网络层和业务层划分地非常清晰,网络层的变化不会影响到业务层,反之亦然:

我们还模拟了比较真实的开发场景,通过大的需求变更,引发了一次不小的代码重构。
最终,通过性能测试,发现了一个客户端实现的小 bug。在处理这个 bug 的时候,我们欣喜地看到,Rust 有着非常强大的测试工具链,除了我们使用的单元测试、集成测试、性能测试,Rust 还支持模糊测试(fuzzy testing)和基于特性的测试(property testing)。
对于测试过程中发现的问题,Rust 有着非常完善的 tracing 工具链,可以和整个 opentelemetry 生态系统(包括 jaeger、prometheus 等工具)打通。我们就是通过使用 jaeger 找到并解决了问题。除此之外,Rust tracing 工具链还支持生成 flamegraph,篇幅关系,没有演示,你感兴趣的话可以试试。
最后,我们完善了 KV server 的配置、日志以及 CI。完整的代码我放在了 github.com/tyrchen/simple-kv 上,欢迎查看最终的版本。
希望通过这个系列,你对如何使用 Rust 的特性来构造应用程序有了深度的认识。我相信,如果你能够跟得上这个系列的节奏,另外如果遇到新的库,用 第 20 讲 阅读代码的方式快速掌握,那么,大部分 Rust 开发中的挑战,对你而言都不是难事。
思考题
我们目前并未对日志做任何配置。一般来说,怎么做日志,会有相应的开关以及日志级别,如果希望能通过如下的配置记录日志,该怎么做?试试看:
#![allow(unused)] fn main() { [log] enable_log_file = true enable_jaeger = false log_level = 'info' path = '/tmp/kv-log' rotation = 'Daily' }
欢迎在留言区分享自己做 KV server 系列的想法和感悟。你已经完成了第45次打卡,我们下节课见。
软件架构:如何用Rust架构复杂系统?
你好,我是陈天。
对一个软件系统来说,不同部门关心的侧重点不同。产品、运营和销售部门关心产品的功能,测试部门关心产品的缺陷,工程部门除了开发功能、解决缺陷外,还要不断地维护和优化系统的架构,减少之前遗留的技术债。
从长远看,缺陷和技术债对软件系统是负面的作用,而功能和架构对软件系统是正面的作用。
从是否对用户可见来说,相比可见的功能和缺陷,架构和技术债是不可见的,它们往往会被公司的决策层以各种理由忽视,尤其,当他们的 KPI / OKR 上都布满了急功近利的数字,每个季度或者每半个财年都是生死战(win or go home)的时候,只要能实现功能性的中短期目标,他们什么都可以牺牲。 不可见并且很难带来直接收益的架构设计,往往是最先被牺牲掉的。
但架构以及架构相关的工作会带来长期的回报。
因为平时我们往系统里添加新的功能,会不可避免地增加系统的缺陷,潜在引入新的技术债,以及扰乱原本稳定的架构。这是一个熵增的过程。缺陷会拖累功能的表现,进一步恶化系统中的技术债;而技术债会延缓新功能的引入,放大已有的和未来的缺陷,并破坏现有的架构。这样一直持续下去,整个系统会进入到一个下降通道,直到无以为继。
为了避免这样的事情发生, 我们需要通过对架构进行维护性的工作,来减少缺陷,修复技术债,改善功能,最终将整个系统拉回到上升通道。
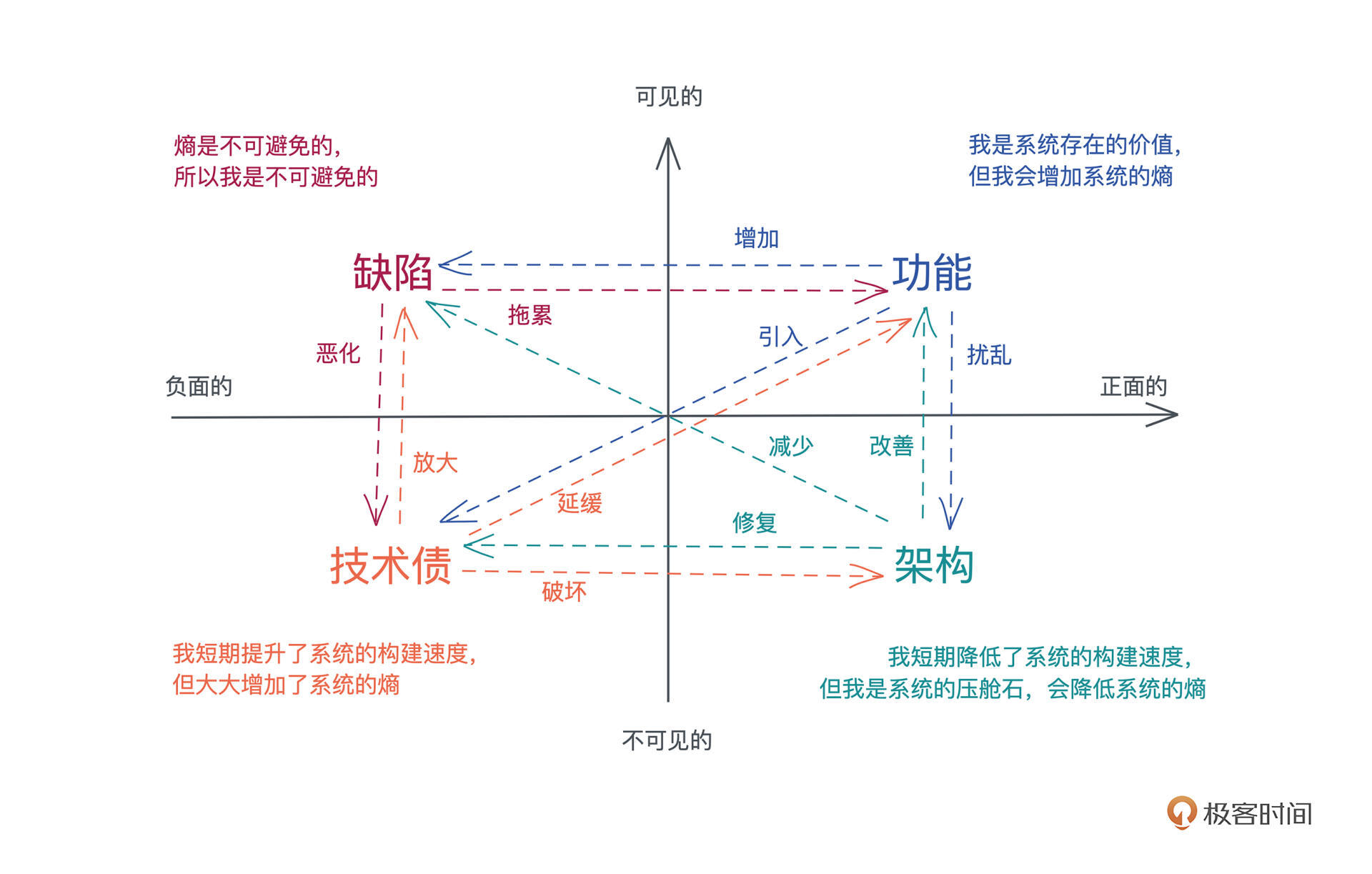
在我看来,软件系统是架构、功能、缺陷,以及技术债之间共同作用,互相拉扯的一个结果。
在一个项目的初期,为了快速达到产品和市场的契合(product market fit),引入技术债来最大程度提高构建的速度,是最佳选择。但这并不意味着我们可以放弃架构的设计,埋头码字。
过去二十年时间,敏捷宣言(Agile Manifesto)和精益创业(Lean startup)对软件社区最大的负面影响就是,一大堆外行或者并没有深刻理解软件工程的从业者,过分追求速度,过度曲解 MVP(Minimum Viable Product),而忽视了从起点出发前,必不可少的架构和设计功夫,导致大部分技术债实际上是架构和设计阶段的债务。
但产品初期,在方向并不明朗的情况下,我们如何架构系统呢?
类似瀑布模型那样的迭代方式,在产品的初期花费大量的精力做架构和设计,往往会导致过度设计,引入不必要的麻烦和可能永远用不上的“精妙”结构;但过分追求敏捷,干了再说,又会让技术债很快就积累到一个难以为继的地步。
所以,对于这样的场景,我们应该采用 渐进式的架构设计,从 MVP 的需求中寻找架构的核心要素,构建一个原始但完整的结构(primitive whole),然后围绕着核心要素演进。 比如(图片来源: 维基百科):
{kind=link}
今天我们就来讲一讲怎么考虑架构设计,以及如何用Rust构建出一些典型的架构风格,希望你在学完这一讲最大的体会是:做任何开发之前,养成习惯,首先要做必要的架构和设计。
如何考虑架构设计?
架构设计是一个非常广泛的概念,很难一言以蔽之。在《Fundamentals of Software Architecture》一书中,作者从四个维度来探讨架构,分别是:
- Structure:架构的风格和结构,比如 MVVM、微服务
- Characteristics:架构的主要指标,比如可伸缩性、容错性和性能
- Decisions:架构的硬性规则,比如服务调用 只能 通过接口完成
- Design Principles:架构的设计原则,比如 优先 使用消息通讯
可以对照下面这张图理解,我们一个个说(来源: Fundamentals of Software Architecture):
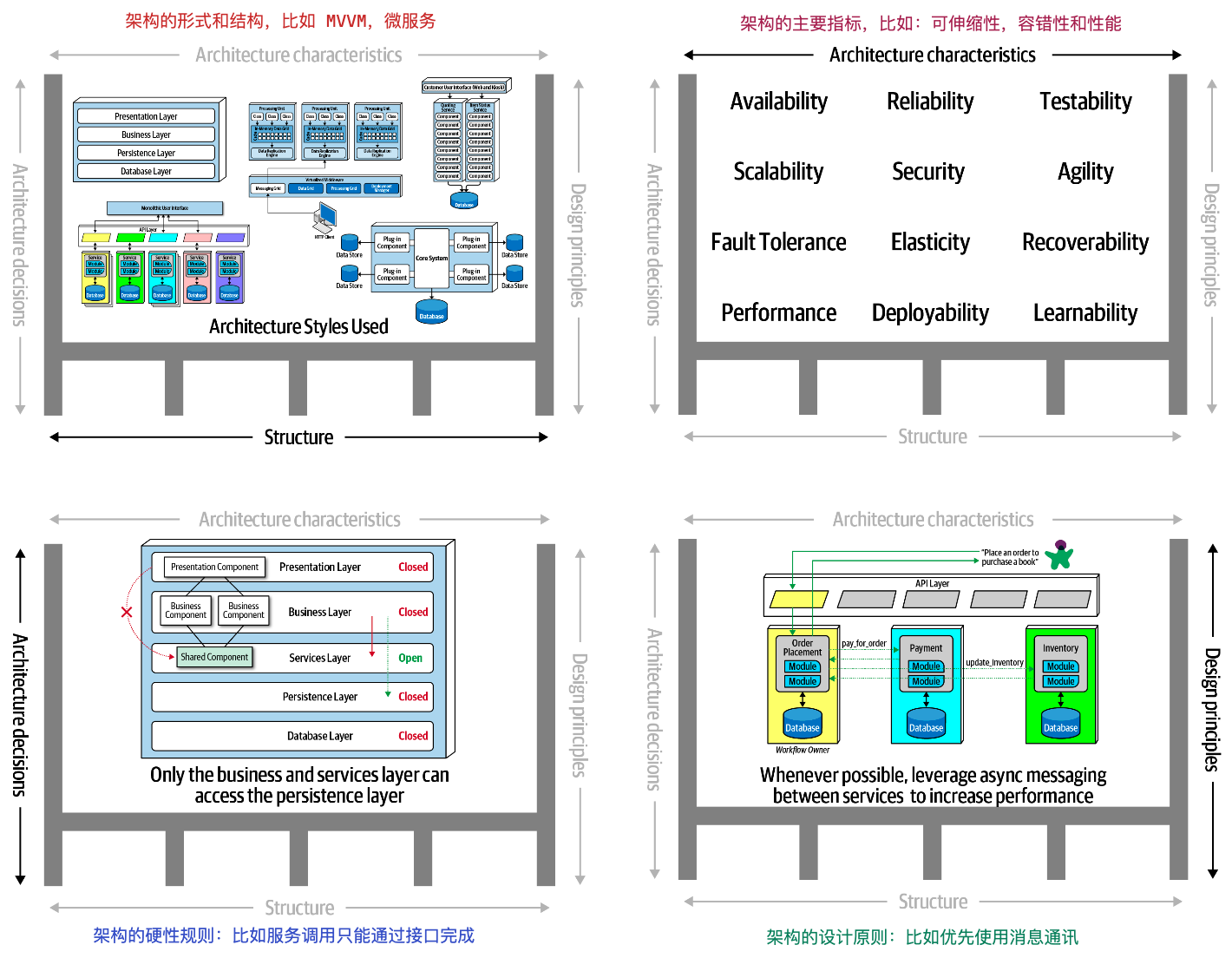
Structure架构的风格
首先是架构的风格。实战课中我们一直在迭代的 KV server,就采取了分层的结构,把网络层、业务层和存储层分隔开。
虽然最开始网络层长什么样子我们并不清楚,但这种分层使得后来不断迭代网络层的时候,不管是加入 TLS 的支持,还是使用 yamux 做多路复用,都不会影响到业务层。
一个复杂的大型系统往往可以使用分治的原则处理。之前展示过这样的图,一个互联网应用的最基本、最普遍的结构:
从业务的大方向上,我们可以进行分层处理,每层又可以选择不同的结构,比如微服务结构、事件驱动结构、管道结构等等,然后拆分出来的每个组件内部又可以用分层,比如把数据层、业务逻辑层和接口层分离,这样一层层延展下去,直到拆分出来的结果可以以“天”为单位执行。
在执行的过程中,我们可以选取跟 MVP 有关的路径进行开发,并在这个过程中不断审视架构的设计,做相应的修改。你如果回顾一下 KV server 的演进过程,从最初构造到目前这个几乎成型的版本,就可以感受到一开始有一个完整但原始的结构,然后围绕着核心演进的重要性。
Characteristics架构的主要指标
再来看架构的主要指标。就像图中展示的那样,一个系统有非常多的指标来衡量其成功,包括并不限于:高性能、可用性、可靠性、可测性、可伸缩性、安全性、灵活性、容错性、自我修复性、可读性等等。
不过,这些指标并不是平等的关系,不同的系统会有不同的优先级。
对于 KV server 来说,我们关心系统的性能 / 安全性 / 可测性,所以使用了最基本的 in-memory hashmap 来保证查询性能、使用 TCP + yamux 来保证网络性能、使用 channel 和 dashmap 来保证并发性能,以及使用 TLS 来保证安全性。同时,一直注重接口的清晰和可测试性。
可以看到,一旦我们做出了架构指标上的决定,那么进一步的设计会优先考虑这些指标的需求。
Decisions架构的硬性规则
在架构设计的过程中,引入硬性约束或者原则非常重要。它就像架构的“基本法”,不可触碰。 很多时候,当你引入了某个结构,你也就引入了这个结构所带来的的约束,比如微服务结构,它的约束就是:服务间的一切访问只能通过公开的接口来完成,任何服务间不能有私下的约定。
这个现在看起来很容易理解的决定,在差不多二十年前,是振聋发聩的呐喊。2002 年,亚马逊还是一家小公司,贝佐斯还离首富差了几个比尔盖茨。作为一个不是特别懂技术的 MBA,他撰写了一个划时代的备忘录,并在亚马逊强制执行,这个备忘录很简单,看它的原文:
- All teams will henceforth expose their data and functionality through service interfaces.
- Teams must communicate with each other through these interfaces.
- There will be no other form of interprocess communication allowed: no direct linking, no direct reads of another team’s data store, no shared-memory model, no back-doors whatsoever. The only communication allowed is via service interface calls over the network.
- It doesn’t matter what technology they use. HTTP, Corba, Pubsub, custom protocols — doesn’t matter.
- All service interfaces, without exception, must be designed from the ground up to be externalizable. That is to say, the team must plan and design to be able to expose the interface to developers in the outside world. No exceptions.
- Anyone who doesn’t do this will be fired.
- Thank you; have a nice day!
这个备忘录促成了 AWS 这个庞大的云服务帝国的诞生。贝佐斯对架构的视野,至今还让我啧啧称奇。他精准地“看”到了云服务的未来,并以架构的硬性约束来促成三个要点:独立的服务、服务间只能通过接口调用、服务的接口要能够被外部开发者调用。
Design Principles架构的设计原则
最后,我们简单说说架构的设计原则。和架构的硬性约束不同的是,设计原则更多是推荐做法,而非不可触碰的雷区。我们在构建系统的时候,要留有余地,这样在开发和迭代的过程中,才能根据情况选择合适的设计。
比如对于 KV server 来说,推荐使用 TCP / yamux 来处理网络,但并不是说 gRPC 甚至 QUIC 就不能使用;推荐用二进制的 protobuf 来在客户端/服务器传输数据,但在某些场景下,如果基于文本的传输方式,或者非 protobuf 的二进制传输方式(比如 flatbuffer)更合适,那么未来完全可以替换这部分的设计。
如何用 Rust 构建典型的架构风格?
再复习一下刚才聊的架构设计的四个方面:
- Structure架构的风格和结构
- Characteristics架构的主要指标
- Decisions架构的硬性规则
- Design Principles架构的设计原则
其中后三点架构的指标、硬性规定以及设计原则,和具体项目的关联度很大,我们并没有模式化的工具来套用它。但架构风格是有很多固定的套路的。这些套路,往往是在日积月累的软件开发实践中,逐渐形成的。
目前比较普遍使用的架构风格有:分层结构、流水线结构、插件结构、微服务结构、事件驱动结构等。
微服务结构相信大家比较熟悉,这里就不赘述;事件驱动结构可以通过 channel 来实现,我们在KV server 中构建的 pub/sub 就有事件驱动的影子,但一个高性能的事件驱动结构需要第三方的消息队列来提供支持,比如 kafka、 nats 等,你可以自己去看它们各自推荐的事件驱动模型。
不过不管你用何种分布式的架构,最终,每个服务内部的架构还是会使用 分层结构、流水线结构和插件结构,我们这里就简单讲讲这三者。
分层结构
开头已经谈到了分层,这是最朴素,也是最实用的架构风格。软件行业的一句 至理名言 是:
All problems in computer science can be solved by another level of indirection.
这种使用分层来漂亮地解决问题的思路,贯穿整个软件行业。
操作系统是应用程序和硬件的中间层;虚拟内存是线性内存和物理内存的中间层;虚拟机是操作系统和裸机的中间层;容器是应用程序和操作系统的中间层;ISO 的 OSI 模型,把网络划分为 7 层,这让我们至今还受益于几十年前就设计出来的网络结构。
分层,意味着明确每一层的职责范围以及层与层之间接口。一旦我们有明晰的层级划分,以及硬性规定层与层之间只能通过公开接口调用,且不能跨层调用,那么,系统就具备了很强的灵活性,某层的内部实现可以完全被不同的实现来替换,而不必担心上下游受到影响。
在 Rust 下,我们可以用 trait 来进行接口的定义,通过接口来分层。就像 KV server 展现的那样,把网络层和业务层分开,网络层或者业务层各自的迭代不会影响对方的行为。
流水线结构
大部分系统的处理流程都可以用流水线结构来表述。我们可以把处理流程中的要素构建成一个个接口一致、功能单一的组件,然后根据不同的输入,来选择合适的组件,将它们组织为一个完整的流水线,然后再依次执行。
这样做的好处是,在执行过程中,我们不需要对输入进行判断来决定执行什么代码,要执行的代码已经包含在流水线之中。而流水线的构建,在编译期、加载期就可以预处理好最常见的流程(fast path),只有不那么常见的输入,才需要在运行时构建合适的流水线(slow path)。一旦一个新的流水线被构建出来,还可以缓存它,下一次就可以直接执行(fast path)。
我们看一个流水线处理的典型结构:
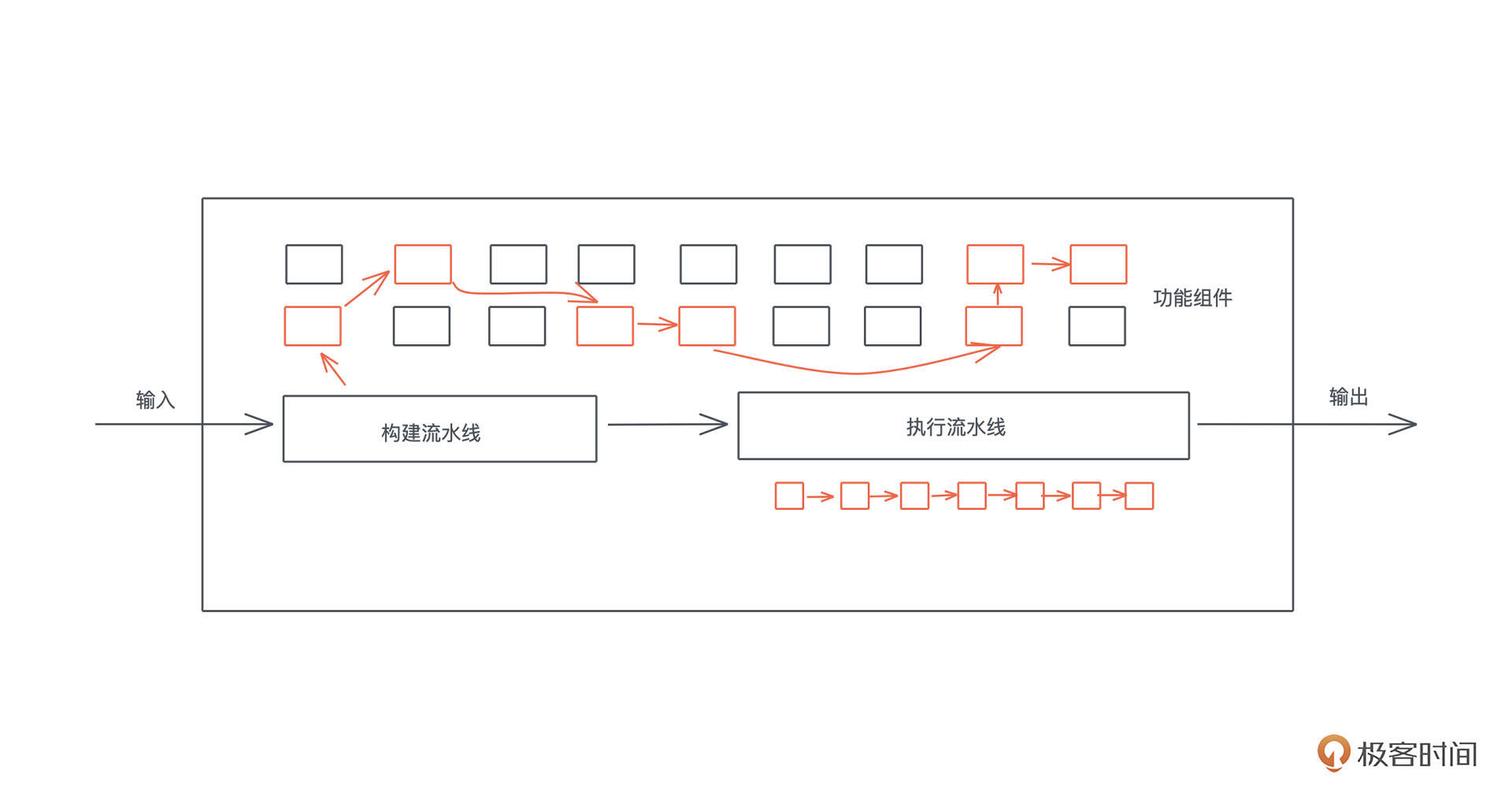
这种结构在实战中非常有用,比如 Elixir 下处理网络流程的 Plug。下图是我之前在处理区块链的 TX 时设计的流水线结构:
流水线可以是架构级的宏观流水线,也可以是函数级的微观流水线。它最大的好处是通过组合不同的基本功能,完成各种各样复杂多变的需求。就像乐高积木,最基本的积木组件是有限的,但我们可以创建出无穷多的组合。
使用 Rust 创建流水线结构并不复杂,你可以利用 enum / trait 构造。比如下面的实例( 代码):
#![allow(unused)] fn main() { use std::fmt; pub use async_trait::async_trait; pub type BoxedError = Box<dyn std::error::Error>; /// rerun 超过 5 次,就视为失败 const MAX_RERUN: usize = 5; /// plug 执行的结果 #[must_use] pub enum PlugResult<Ctx> { Continue, Rerun, Terminate, NewPipe(Vec<Box<dyn Plug<Ctx>>>), Err(BoxedError), } /// plug trait,任何 pipeline 中的组件需要实现这个 trait #[async_trait] pub trait Plug<Ctx>: fmt::Display { async fn call(&self, ctx: &mut Ctx) -> PlugResult<Ctx>; } /// pipeline 结构 #[derive(Default)] pub struct Pipeline<Ctx> { plugs: Vec<Box<dyn Plug<Ctx>>>, pos: usize, rerun: usize, executed: Vec<String>, } impl<Ctx> Pipeline<Ctx> { /// 创建一个新的 pipeline pub fn new(plugs: Vec<Box<dyn Plug<Ctx>>>) -> Self { Self { plugs, pos: 0, rerun: 0, executed: Vec::with_capacity(16), } } /// 执行整个 pipeline,要么执行完毕,要么出错 pub async fn execute(&mut self, ctx: &mut Ctx) -> Result<(), BoxedError> { while self.pos < self.plugs.len() { self.add_execution_log(); let plug = &self.plugs[self.pos]; match plug.call(ctx).await { PlugResult::Continue => { self.pos += 1; self.rerun = 0; } PlugResult::Rerun => { // pos 不往前走,重新执行现有组件,rerun 开始累加 self.rerun += 1; } PlugResult::Terminate => { break; } PlugResult::NewPipe(v) => { self.pos = 0; self.rerun = 0; self.plugs = v; } PlugResult::Err(e) => return Err(e), } // 如果 rerun 5 次,返回错误 if self.rerun >= MAX_RERUN { return Err(anyhow::anyhow!("max rerun").into()); } } Ok(()) } pub fn get_execution_log(&self) -> &[String] { &self.executed } fn add_execution_log(&mut self) { self.executed.push(self.plugs[self.pos].to_string()); } } }
你可以在 playground 里运行包括完整示例代码的 例子。
开始的时候,初始化一个包含 [SecurityChecker, Normalizer] 两个组件的流水线。在执行 SecurityChecker 过程中,流水线被更新为 [CacheLoader, DataLoader, CacheWriter] 的结构,然后在执行到 DataLoader 时,出错退出。所以整个执行流程如下图所示:
插件(微内核)结构
插件结构(Plugin Architecture)也被称为微内核结构(Microkernel Architecture),它可以让你的系统拥有一个足够小的核心,然后围绕着这个核心以插件的方式注入新的功能。
我们平时使用的 VS Code 就是典型的插件结构。它的核心功能就是文本的编辑,但通过各种插件,它可以支持代码的语法高亮、错误检查、格式化等等功能。
在构建插件结构时,我们需要设计一套足够稳定的接口,保证插件和核心之间的交互;还需要设计一套注册机制,让插件可以被注册进系统,或者从系统中删除。
在 Rust 下,除了正常使用 trait 和 trait object 来构建插件机制,在系统内部使用插件结构外,还可以通过 WebAssembly(通过 wasmer 或 wasmtime) 或者 rhai 这样的嵌入式脚本来允许第三方通过插件来扩展系统的能力:
小结
架构是一个复杂的东西,它充满了权衡(trade-off)。我非常推崇 Clojure 创造者 Rich Hickey 的一句话,大意是说“你只有有了足够的替代方案,才谈得上权衡”。
我们在做软件开发时,不要着急上来就甩开膀子写代码,要先让需求在大脑中沉淀,思考这个需求和已有的哪些需求相关、和我见过的哪些系统类似,然后再去思考都有什么样的方案、它们的利弊是什么。
好的架构师了解足够多的架构风格,所以不拘泥于某一种,也不会手里拿着锤子,看什么都是钉子。好的架构师平时还有足够多的阅读、足够多的积累,这样在遇到架构问题时,可以迅速和曾经遇见的系统联系和类比。这也是为什么我非常建议你们多阅读市面上优秀的代码,因为广泛且有深度的阅读才能拓宽你的眼界,才能帮你累积足够多的素材。
当然,阅读仅仅是第一步。 有了阅读的基础,你可以多进行“纸上谈兵”的脑力训练,看到一个系统,就尝试分析它的架构,看看自己能不能自圆其说,架构出类似的产品。这样的脑力训练除了可以更好地帮助你提升架构分析能力外,还可以帮你学到“你不知道你不知道的事情”。
比如我曾经花了些功夫去研究 Notion,顺着这条线更深入地探索 OT 和 CRDT 算法,在深入探索中,我遇见了 yjs、 automerge、 diamond-types 等优秀的工具,这些都是我之前从未使用过的东西。
最后,你还需要去真正把自己设计的架构落地,应用在某些项目中。一个人一生中可以主导某些大项目架构的机会并不多,所以, 在机会来临时,抓住它,把你平生所学应用上去,此时你会渐渐感受到头脑中的架构和真正落地的架构之间的差异。
有同学可能会问,如果机会没有来临怎么办?那么就在业余时间去写各种你感兴趣的东西,以此来磨练自己的能力,默默等待属于自己的机会。当年明月写《明朝那些事儿》,刘慈欣写《三体》,也并不是他们在工作中得到的机会。兴趣最好的老师,热爱是前进的动力。
思考题
请花些时间阅读《Fundamentals of Software Architecture》这本书。
欢迎在留言区分享你今天的学习收获或感悟。如果你觉得有收获,也欢迎分享给身边的朋友,邀他一起讨论。我们下节课见。
大咖助场|开悟之坡(上):Rust的现状、机遇与挑战
你好,我是张汉东。
本月应陈天兄邀请,为他的极客时间课程写一篇加餐文章。2021 年也马上要过去了,我也正好借此机会对 Rust 语言的现状、机遇和挑战来做一次盘点,希望给正在学习 Rust 的朋友提供一个全局视角。这篇文章包含一些客观的数据,也有一些个人观点,仅供参考。
Rust 现状
要比较全面地评价一个语言的现状,我个人认为要从三个方面分析:
-
语言自身的成熟度。从语言自身出发,去看语言的功能特性是否完善、便于开发和学习。
-
语言的生态和应用场景。从语言的生态系统出发,了解该门语言在哪些领域已经开始布局。
-
可持续发展能力。从三方面考虑:了解一门语言是开放的,还是封闭的、这门语言背后的开发者是否可以稳定投入到这门语言、这门语言被常应用的领域是否属于可持续发展的领域。
所以,我们按这个分析方法对 Rust 语言进行分析,你也可以按这个方法来审视其他语言。
语言自身成熟度
Rust 语言 2015年发布 1.0 稳定版开始,已经连续发布了两大版次 2018 Edition 和 2021 Edition。
2015 Edition:Rust 0.1.0 ~ Rust 1.0稳定版,主题是 “稳定性”2018 Edition:Rust 1.0 ~ 1.31.0稳定版,主题是 “生产力”2021 Edition:Rust 1.31.0 ~ 1.56.0稳定版,主题是“成熟”
可以说,Rust 语言已经足够成熟到能将其应用于生产环境。但是判断一门编程语言的成熟度,其实还有很多讲究。
不同语言的成熟度标准可能不太一样,因为成熟度并不是一个绝对的值,它永远是相对而言的。 比如 Java 和 Node.js 哪个成熟度更高呢? Java 生态中 Spring 框架已经发展了十几个年头了,足够成熟。但是 Node.js 生态中,也有类似于 AngularJS、 Ember.js 这些框架,也被认为是非常成熟的。 要说谁更成熟,这是没有答案的。
但是也有一些判断成熟度的思路和对应指标,我们可以通过这些指标来相对评判一下 Rust 的成熟度。大致可以分成这样4类:用户、语言、社区活跃性、应用广泛性。

- 用户:用户数、StackOverflow问题数量、贡献者数量
用户数:Rust 连续六年是用户最受欢迎的语言,但实际用户数,可以从 TIOBE 编程语言排行榜中看出来,截止 2021年11月,Rust 排名 29 ,流行度是 0.54% 。任何没有进入 TIOBE 榜单前20的语言,其实都还需要进行营销和宣传,这意味着 Rust 依旧属于小众语言。
贡献者数量:Rust 贡献者数量截止目前为 3539 个。我们对比一下 Github 开源的其他语言:流行的 Go 语言目前贡献者是 1758 个; Kotlin 目前的贡献者是 516 个。看一下流行的框架 Rails 的贡献者是 4379 个。 相对而言,Rust 语言贡献者是相当多的。
StackOverflow 问题数量:Rust 相关问题一共有 24924 个,平均每周 150 个问题左右,每天 20 个问题左右。 相比其他语言, javascript 问题 2299100 个, Java 问题 1811376 个, Go 问题 57536 个, C 问题 368957 个, Cpp 问题 745313 个。 相比于 Go , Rust 的问题数几乎是它的一半。
- 语言:错误修补/补丁频率、未解决问题数、存储库统计、新特性发布频率、是否稳定、API修改频率、是否存在“核心开发人员”
错误修复/补丁频率。根据 Github issues 相关数据, Rust 目前肉眼可见每小时平均修复一个 issue 问题。从 2010年 6月17号 Rust 创始人 Graydon 的第一个提交开始,一共修复了 33942 个 issues 和 49011 个 PR,十年间按 3832 天计算,平均一天修复 8 个 issue, 13 个 PR。
未解决问题数。目前有 7515 个开放的问题,如果按上面的平均问题修复频率来计算,预计 3 年左右可以修复完毕。3年以后,又是新的 Edition 发布: 2024 Edtion。
存储库统计,目前 star 数有 60500 个, watch 数有 15000 个。新特性发布频率,Rust 稳定版每六周发一个新版。Rust 早已稳定,且稳定版 API 基本不会更改。Rust 核心开发人员非常多,按工作小组来组织分配,参考 Rust 团队治理
- 社区活跃性:文档数量和质量、社区响应频率
文档数量和质量主要看 API 文档、书籍、教程和博客。Rust API 文档相当成熟和先进,目前国内外 Rust 书籍也越来越丰富,Rust Weekly 每周都会发布社区很多 Rust 相关博客、 视频等文章。
社区响应频率考察有经验的用户如何帮助新用户。Rust 社区国内外都有,通过群组织、论坛、线下活动等帮助社区成员进行交流。
- 应用广泛性:商业支持度、知名项目和产品应用的数量、“恐怖事故”的数量
商业支持度方面,Rust 基金会已经成立:Google、华为、微软、亚马逊、 Facebook、Mozilla 、丰田、动视等公司都是其董事成员。
知名项目和产品应用的数量,比如开源 CNCF 的一些知名项目: 数据库( TiKV)、云原生( Linkerd、 Krustlet)、事件流系统( Tremor)、区块链(Near、Solana、 Parity等),还有 Google Andriod,亚马逊、 微软等也都支持 Rust 开发。
国内使用 Rust 的公司:蚂蚁金服、PingCAP、字节跳动、秘猿、溪塔、海致星图、非凸科技等。还有很多优秀的项目或产品这里没有列出来。
最后是“恐怖事故”的数量,如果没有这一项,证明它并未在实际具有挑战性的生产环境中使用。Rust 有专门的信息安全工作组,并且有专门的网站记录 Rust 生态中相关“恐怖事故” : https://rustsec.org/。
通过上面这些标准来判断, Rust 语言都做的相当到位,所以可以说,Rust 语言基本已经迈入“成熟语言”行列。
语言生态与应用场景
当然,一个语言自身的成熟度是一方面,围绕语言的生态也相当重要。
我在今年六月份写的 《Rust 2021 行业调研报告》 中提到了 Rust 语言的生态状况,经过半年的发展,crates 的下载总量达到 11,012,362,794 次,即 110 亿次。
Rust的应用场景基本可以同时覆盖 C/Cpp/Java/Go/Python 的应用领域。大致可以分成十大领域:
- 数据处理与服务。 代表产品和项目包括:
TiKV/Timely Dataflow/Vector/tantivy/tremor-rs/databend等 - 云原生。代表产品和项目包括:
StratoVirt/Firecracker/Krustlet/linkerd2-proxy/Lucet/WasmCloud/Habitat等 - 操作系统:
Rust for Linux/Coreutils/Occulum/Redox/Tock/Theseus等 - 工具类:
rustdesk/ripgrep/NuShell/Alacritty等 - 机器学习:
Linfa/tokenizers/tch-rs/ndarray/Neuronika/tvm-rs/TensorFlow-rs - 游戏:
Veloren/A / B Street/rust-gpu/Bevy/ rg3d - 客户端开发: 飞书
App跨平台组件 /flutter_rust_bridge/Iced/Tauri/egui等 - 区块链/元宇宙:
Diem/Substrate/Nervos CKB/Near/Solana/nannou/makepad/makepad等 - 安全:
rustscan/feroxbuster/rusty-tor/sn0int/sniffglue等 - 其他语言生态基础设施:比如 swc / deno / rome 等前端基础设施工具,WebAssembly 技术等。
可持续发展能力
一个语言的可持续发展能力可以从三方面来了解: 封闭的还是开放的、语言自身的可持续发展能力、语言公司应用的潜力。
Rust 语言是完全开源的,它也是世界上最大的开源社区组织。由不同职责的团队和工作组共同协作。具体可以在 Rust 官网 看到相关信息。目前拥有 3539 个贡献者。Rust 语言目前的工作流程和社区,对于 Rust 良性可持续发展拥有积极推动的作用。
2021 年 2 月 9 号,Rust 基金会宣布成立。华为、 AWS、 Google、微软、 Mozilla、 Facebook 等科技行业领军巨头加入 Rust 基金会,成为白金成员,以致力于在全球范围内推广和发展 Rust 语言,为 Rust 语言的开发者们也提供了强有力的资金后盾。
随后, ARM 、 AUTOMATA、 1PASSword、丰田汽车、动视、 Knoldus 、 Tangram 等各个领域的公司都加入了基金会,为推动 Rust 做贡献。最近 Rust 基金会又推选在非营利组织有十五年经验的 Rebecca 成为了基金会的执行董事(ED)和CEO。相信在 Rust 基金会的领导下,Rust 会有广泛的应用前景。
综合以上三方面, Rust 语言的可持续发展前景非常广阔。
Rust 机遇
我们分析 Rust 的现状,是为了让自己更全面地了解 Rust 。但 Rust 未来如何发展,对于正在学习 Rust 语言的个人来说,明白 Rust 未来机遇在哪,可能对自身职业规划更有帮助。
时代变革中 Rust 有何机遇
当下,互联网技术与可再生能源革命正在开启新一轮工业革命的大幕,人类已经站在新时代的门槛上。世界范围内新一轮科技革命和产业变革正在兴起。5G、低纳米制程芯片技术、物联网技术和人工智能,为智慧城市、智慧制造、智慧交通、智能家居等应用带来更多可能。
这意味着数以百万亿的设备会接入网络,业界在计算、储存和通信能力方面遇到前所未有的异质性,并且在产生数据以及必须交付和使用数据的规模方面也面临新的挑战。
要构建美好的未来,并没有那么容易。头号的挑战就是安全问题。由于联网节点分布广、数量多,应用环境复杂,计算和存储能力有限,无法应用常规的安全防护手段,导致整体安全性相对减弱。如果在工业、能源、 电力、交通等国家战略性基础行业中应用,一旦发生安全问题,将造成难以估量的损失。
基础设施信任链条连接到哪里,安全就能保护到哪里。而Rust 语言正是今天用于构建可信系统的不二选择,可以说,Rust 是 对的时间出现的对的工具(the right tool at the right time)。
Rust 丰富的类型系统和所有权模型,保证了内存安全和线程安全,让我们在编译期就能够消除各种各样的错误,并且在性能上可以媲美 C/Cpp。
理论上,因为 Rust 有比C 更严格的不可变和别名规则,应该比 C 语言有更好的性能优化,不过由于目前在LLVM 中,超越 C语言的优化是一项正在进行的工作,所以Rust仍然没有达到其全部潜力。
Rust 语言由于没有运行时和垃圾回收,它能够胜任对性能要求特别高的服务,可以在嵌入式设备上运行,还能轻松和其他语言集成。但是,最大的潜力是可以无畏(fearless)地并行化大多数 Rust 代码,而等价的 C 代码并行化的风险非常高。在这方面,Rust 语言是比 C 语言更为成熟的。
Rust 语言也支持高并发零成本的异步编程,Rust 应该是首个支持异步编程的系统级语言。
总的来说,Rust 像 C 语言一样也是一门通用型语言,它有极大的潜力成为未来五十年的语言级基础设施。
Rust 造就了哪些工作岗位需求
因为 Rust 的安全属性,目前在金融领域应用 Rust 的公司比较多,所以目前全球 Rust 工作岗位最多的分布就是“区块链”和“量化金融”。
基本上目前全球Rust岗位招聘,种类已经非常多了,按数量排名前三的:
- 区块链/ 量化金融 / 银行业
- 基础设施(云原生平台开发): 数据库 / 存储 / 数据服务 / 操作系统 / 容器 / 分布式系统
- 平台工具类: 远程桌面 / 远程服务类产品 / SaaS / 远程工作类产品(比如Nexthink)
还有AI / 机器学习 / 机器人、客户端跨平台组件开发、区块链安全/ 信息安全的安全工程师、嵌入式工程师、广告服务商类比如 Adinmo、音视频实时通信工程师,以及电商平台、软件咨询。
关于具体的 Rust 职位招聘,你可以在 Rust Weekly / Reddit r/Rust 频道 / Rust Magazine 社区月刊 / Rustcc 论坛,以及各大招聘网站中找到。
Rust 的现状和机遇,我们今天就聊到这里,下半篇会讲一讲 Rust 语言的挑战。
大咖助场|开悟之坡(下):Rust的现状、机遇与挑战
你好,我是张汉东。
上篇我们聊了Rust语言的现状和机遇,从语言自身的成熟度、语言的生态和应用场景,以及语言的可持续发展能力这三个方面,比较系统地说明Rust发展相对成熟的现状。
Rust 语言作为一门新生语言,虽然目前倍受欢迎,但是面临的挑战还很多。我们今天就聊一聊这个话题。
挑战主要来自两个方面:
- 领域的选择。一门语言唱的再好,如果不被应用,也是没有什么用处。Rust 语言当前面临的挑战就是在领域中的应用。而目前最受关注的是,Rust 进入 Linux 内核开发,如果成功,其意义是划时代的。
- 语言自身特性的进化。Rust 语言还有很多特性需要支持和进化,后面也会罗列一些待完善的相关特性。
Rust For Linux 的进展和预判
从 2020 年 6 月,Rust 进入 Linux 就开始成为一个话题。 Linux 创建者 Linus 在当时的开源峰会和嵌入式 Linux 会议上,谈到了为开源内核寻找未来维护者的问题。
简单跟你讲一讲背景情况。
Linus 提到:“内核很无聊,至少大多数人认为它很无聊。许多新技术对很多人来说应该更加有趣。事实证明,开源内核很难找到维护者。虽然有很多人编写代码,但是很难找到站在上游对别人代码进行 Review 的人选。这不仅仅是来自其他维护者的信任,也来自所有编写代码的人的信任……这只是需要时间的”。
而 Rust 作为一门天生安全的语言,作为 C 的备选语言,在帮助内核开发者之间建立彼此的信任,是非常有帮助的。三分之二的 Linux 内核安全漏洞( PDF )来自内存安全问题,在 Linux 中引入 Rust 会让其更加安全,这目前基本已经达成一种共识。
而且在今年(2021)的开源峰会上, Linus 说:“我认为C语言是一种伟大的语言,对我来说,C 语言确实是一种在相当低的水平上控制硬件的方法。因此,当我看到C语言代码时,我可以非常接近地猜测编译器的工作,它是如此接近硬件,以至于你可以用它来做任何事情。”
“但是,C语言微妙的类型交互,并不总是合乎逻辑的,对几乎所有人来说都是陷阱,它们很容易被忽视,而在内核中,这并不总是一件好事。”
“ Rust 语言是我看到的、第一种看起来像是真的可以解决问题的语言。人们现在已经谈论Rust在内核中的应用很久了,但它还没有完成,可能在明年,我们会开始看到一些首次用Rust编写的无畏模块,也许会被整合到主线内核中。”
Linus 认为 Linux 之所以如此长青,其中一个重要的基石就是乐趣(Fun),并且乐趣也是他一直追求的东西。当人们讨论使用Rust编写一些 Linux 内核模块的可能性时,乐趣就出现了。
大会进展
在刚过去的 2021 年 9 月 的 Linux Plumbers 大会上, 再一次讨论了 Rust 进入 Linux 内核的进展。
首先是Rust的参与角色问题。
Rust for Linux 的主力开发者 Miguel Ojedal 说,Rust 如果进入内核,就应该是一等公民的角色。Linus 则回答,内核社区几乎肯定会用该语言进行试验。
对Rust代码的review问题也简单讨论过。
Rust 进入内核肯定会有一些维护者需要学习该语言,用来 review Rust 代码。Linus 说, Rust 并不难懂,内核社区任何有能力 review patch 的人,都应该掌握 Rust 语言到足以 Review 该语言代码的程度。
另外还有一些Rust自身特性的稳定问题:
- 目前内核工作还在使用一些 Unstable 的 Rust 特性,导致兼容性不够好,不能确保以后更新的 Rust 编译器能正常编译相关代码。
Ojedal 说,但是如果 Rust 进入 Linux 内核,就会改变这种情况,对于一些 Unstable Rust 特性,Rust 官方团队也会考虑让其稳定。这是一种推动力,迟早会建立一个只使用 Rust 稳定版的内核,到时候兼容问题就会消失。
- 另一位内核开发者 Thomas Gleixner 担心 Rust 并没有正式支持内存顺序,这可能会有问题。
但是另一位从事三十年cpp 并发编程的 Linux 内核维护者 Paul McKenney 则写了 一系列文章 来探讨 Rust 社区该如何就Rust 进入 Linux 内核这件事正确处理内存顺序模型。对此我也写了另一篇文章 【我读】Rust 语言应该使用什么内存模型? 。
- 关于 Rust 对 GCC 的支持,其中
rustc_codegen_gcc进展最快,目前已通过了部分的rustc测试,rustc_codegen_llvm是目前的主要开发项目,Rust GCC预计在 1~2 年内完成。
这次大会的结论有2点:
- Rust 肯定 会在 Linux 内核中进行一次具有时代意义的实验。
- Rust 进入 Linux 内核,对推动 Rust 进化具有很重要的战略意义。
最新消息
2021 年 11 月 11 日,在 Linux 基金会网站上,又放出另一场录制的网络会议: Rust for Linux:编写安全抽象和驱动程序,该视频中 Miguel Ojedal 介绍了 Rust 如何在内核中工作,包括整体基础设施、编译模型、文档、测试和编码指南等。
我对这部分视频内容做了一个简要总结,你可以对照要点找自己需要的看一看。
- 介绍 Unsafe Rust 和 Safe Rust。
- 在 Linux 内核中使用 Rust ,采用一个理念:封装 Unsafe 操作,提供一个安全抽象给内核开发者使用。这个安全抽象位于 https://github.com/Rust-for-Linux/linux/tree/rust/rust 的
kernel模块中。 - 给出一个简单的示例来说明如何编写内核驱动。
- 对比 C 语言示例,给出在 Rust 中什么是 Safety 的行为。
- 介绍了文档、测试和遵循的编码准则。
综合上面我们了解到的这些信息,可以推测,Rust for Linux 在不远的将来会进入到 Linux 进行一次试验,这次试验的意义是划时代的。如果试验成功,那么就意味着 Rust 正式从 C 语言手里拿到了时代的交接棒。
Rust 语言特性的完善
下面来聊一聊最近Rust语言又完善了哪些特性。特别说明一下,这些本来就是高级知识,是Rust 语言的挑战,所以这些知识点你现在也许不太理解,但不用害怕,这些只是 Rust 语言进化路上必须要完善的东西,改进只是为了让 Rust 更好。目前并不影响你学习和使用 Rust 。
我们会讲4个已完善的特性,最后也顺带介绍一下还有哪些待完善的特性,供你参考。
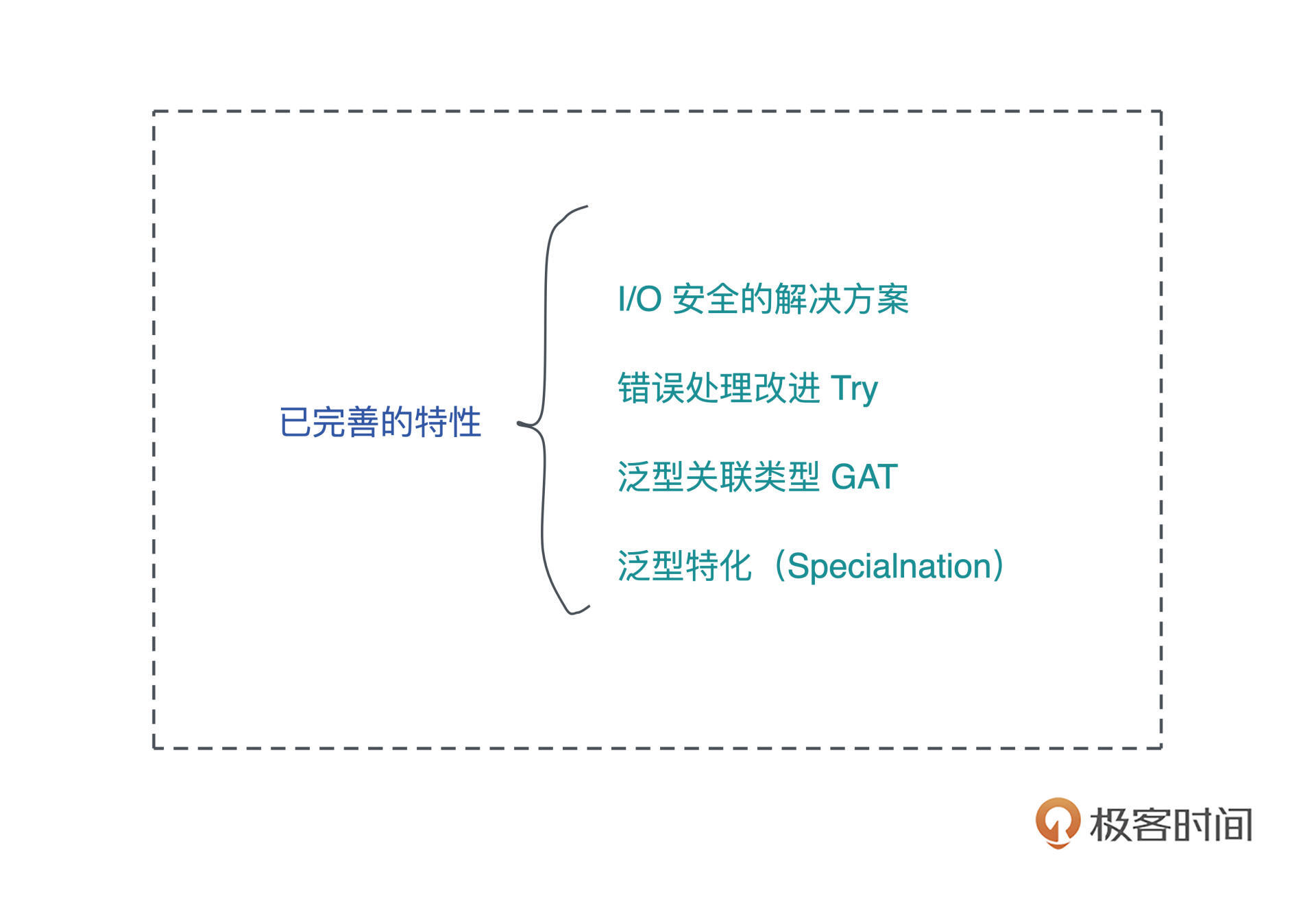
安全 I/O 问题
最近Rust官方合并了一个 RFC ,通过引入I/O安全的概念和一套新的类型和特质,为 AsRawFd 和相关特质的用户提供关于其原始资源句柄的保证,从而弥补Rust中封装边界的漏洞。
之前Rust 标准库提供了 I/O 安全性,保证程序持有私有的原始句柄(raw handle),其他部分无法访问它。
但是 FromRawFd::from_raw_fd 是 Unsafe 的,所以在 Safe Rust中无法做到 File::from_raw(7) 这种事,在这个文件描述符上面进行 I/O 操作,而这个文件描述符可能被程序的其他部分私自持有。
而且,很多 API 通过接受原始句柄来进行 I/O 操作:
#![allow(unused)] fn main() { pub fn do_some_io<FD: AsRawFd>(input: &FD) -> io::Result<()> { some_syscall(input.as_raw_fd()) } }
AsRawFd 并没有限制 as_raw_fd 的返回值,所以 do_some_io 最终可以在任意的 RawFd 值上进行 I/O 操作,甚至可以写 do_some_io(&7),因为 RawFd 本身实现了 AsRawFd。这可能会导致程序访问错误的资源。甚至通过创建在其他部分私有的句柄别名来打破封装边界,导致一些诡异的远隔作用(Action at a distance)。
远隔作用(Action at a distance)是一种程式设计中的反模式,是指程式某一部分的行为会广泛的受到程式其他部分指令的影响,而且要找到影响其他程式的指令很困难,甚至根本无法进行。
在一些特殊的情况下,违反 I/O 安全甚至会导致内存安全。
所以Rust新增了 OwnedFd 和 BorrowedFd<'fd> 这两种类型,用于替代 RawFd ,对句柄值赋予所有权语义,代表句柄值的拥有和借用。 OwnedFd 拥有一个 fd ,会在析构的时候关闭它。 BorrowedFd<'fd> 中的生命周期参数,表示对这个 fd 的访问被借用多长时间。
对于Windows来说,也有类似的类型,但都是 Handle 和 Socket 形式。
和其他类型相比, I/O 类型并不区分可变和不可变。操作系统资源可以在 Rust 的控制之外以各种方式共享,所以 I/O 可以被认为是使用内部可变性。
然后新增了三个概念, AsFd、 Into<OwnedFd> 和 From<OwnedFd>。
这三个概念是 AsRawFd::as_raw_fd、 IntoRawFd::into_raw_fd 和 FromRawFd::from_raw_fd 的概念性替代,分别适用于大多数使用情况。它们以 OwnedFd 和 BorrowedFd 的方式工作,所以它们自动执行其 I/O 安全不变性。
#![allow(unused)] fn main() { pub fn do_some_io<FD: AsFd>(input: &FD) -> io::Result<()> { some_syscall(input.as_fd()) } }
使用这个类型,就会避免之前那个问题。由于 AsFd 只针对那些适当拥有或借用其文件描述符的类型实现,这个版本的 do_some_io 不必担心被传递假的或悬空的文件描述符。
错误处理改进 Try
目前 Rust 允许通过 ? 操作符,自动返回 Result<T,E> 的 Err(e) ,但是对于 Ok(o) 还需要手动包装。
比如:
#![allow(unused)] fn main() { fn foo() -> Result<PathBuf, io::Error> { let base = env::current_dir()?; Ok(base.join("foo")) } }
那么这就引出了一个术语: Ok-Wrapping 。很明显,这个写法不够优雅,还有很大的改进空间。
因此 Rust 官方成员 withoutboats 开发了一个库 fehler,引入了一个 throw 语法。用法如下:
#![allow(unused)] fn main() { #[throws(i32)] fn foo(x: bool) -> i32 { if x { 0 } else { throw!(1); } } // 上面foo函数错误处理等价于下面bar函数 fn bar(x: bool) -> Result<i32, i32> { if x { Ok(0) } else { Err(1) } } }
通过 throw 宏语法,来帮助开发者省略 Ok-wrapping 和 Err-wrapping 的手动操作。这个库一时在社区引起了一些讨论,它也在促进着 Rust 错误处理的体验提升。
于是错误处理就围绕着 Ok-wrapping 和 Err-wrapping 这两条路径发展着,该如何设计语法才更加优雅,成为了讨论的焦点。
经过很久很久的讨论,try-trait-v2 RFC 被合并了,意味着一个确定的方案出现了。在这个方案中,引入了一个新类型 ControlFlow 和一个新的trait FromResidual。
ControlFlow 的源码:
#![allow(unused)] fn main() { enum ControlFlow<B, C = ()> { /// Exit the operation without running subsequent phases. Break(B), /// Move on to the next phase of the operation as normal. Continue(C), } impl<B, C> ControlFlow<B, C> { fn is_break(&self) -> bool; fn is_continue(&self) -> bool; fn break_value(self) -> Option<B>; fn continue_value(self) -> Option<C>; } }
ControlFlow 中包含了两个值:
ControlFlow::Break,表示提前退出。但不一定是Error的情况,也可能是Ok。ControlFlow::Continue,表示继续。
新的trait FromResidual:
#![allow(unused)] fn main() { trait FromResidual<Residual = <Self as Try>::Residual> { fn from_residual(r: Residual) -> Self; } }
Residual 这个单词有“剩余”的意思,因为要把 Result / Option/ ControlFlow 之类的类型,拆分成两部分(两条路径),用这个词也就好理解了。
而 Try trait 继承自 FromResidual trait :
#![allow(unused)] fn main() { pub trait Try: FromResidual { /// The type of the value consumed or produced when not short-circuiting. type Output; /// A type that "colours" the short-circuit value so it can stay associated /// with the type constructor from which it came. type Residual; /// Used in `try{}` blocks to wrap the result of the block. fn from_output(x: Self::Output) -> Self; /// Determine whether to short-circuit (by returning `ControlFlow::Break`) /// or continue executing (by returning `ControlFlow::Continue`). fn branch(self) -> ControlFlow<Self::Residual, Self::Output>; } pub trait FromResidual<Residual = <Self as Try>::Residual> { /// Recreate the type implementing `Try` from a related residual fn from_residual(x: Residual) -> Self; } }
所以,在 Try trait 中有两个关联类型:
Output,如果是 Result 的话,就对应 Ok-wrapping 。Residual,如果是 Result 的话,就对应 Err-wrapping 。
所以,现在 ? 操作符的行为就变成了:
#![allow(unused)] fn main() { match Try::branch(x) { ControlFlow::Continue(v) => v, ControlFlow::Break(r) => return FromResidual::from_residual(r), } }
然后内部给 Rusult 实现 Try :
#![allow(unused)] fn main() { impl<T, E> ops::Try for Result<T, E> { type Output = T; type Residual = Result<!, E>; #[inline] fn from_output(c: T) -> Self { Ok(c) } #[inline] fn branch(self) -> ControlFlow<Self::Residual, T> { match self { Ok(c) => ControlFlow::Continue(c), Err(e) => ControlFlow::Break(Err(e)), } } } impl<T, E, F: From<E>> ops::FromResidual<Result<!, E>> for Result<T, F> { fn from_residual(x: Result<!, E>) -> Self { match x { Err(e) => Err(From::from(e)), } } } }
再给 Option/Poll 实现 Try ,就能达成错误处理大一统。
泛型关联类型 GAT
泛型关联类型在 RFC 1598 中被定义。该功能特性经常被对比于 Haskell 中的 HKT(Higher Kinded Type),也就是高阶类型。
虽然这两个类型相似,但是 Rust 并没有把 Haskell 的 HKT 原样照搬,而是针对 Rust 自身特性给出GAT(Generic associated type) 的概念。目前 GAT 支持的进展可以在 issues #44265 中被跟踪,也许在年内可以稳定。
什么是泛型关联类型? 见下面代码:
#![allow(unused)] fn main() { trait Iterable { type Item<'a>; // 'a 也是泛型参数 } trait Foo { type Bar<T>; } }
就是这样一个简单的语法,让我们在关联类型里也能参与类型构造,就是实现起来却非常复杂。
但无论多复杂,这个特性是 Rust 语言必须要支持的功能,它非常有用。 最典型的就是用来实现流迭代器:
#![allow(unused)] fn main() { trait StreamingIterator { type Item<'a>; fn next<'a>(&'a mut self) -> Option<Self::Item<'a>>; } }
现在 Rust 还不支持这种写法。这种写法可以解决当前迭代器性能慢的问题。
比如标准库中的 std::io::lines 方法,可以为 io::BufRead 类型生成一个迭代器,但是它当前只能返回 io::Result<Vec<u8>>,这就意味着它会为每一行进行内存分配,而产生一个新的 Vec<u8> ,导致迭代器性能很慢。 StackOverflow上有这个问题的讨论和优化方案。
但是如果支持 GAT 的话,解决这个问题将变得非常简单:
#![allow(unused)] fn main() { trait Iterator { type Item<'s>; fn next(&mut self) -> Option<Self::Item<'_>>; } impl<B: BufRead> Iterator for Lines<B> { type Item<'s> = io::Result<&'s str>; fn next(&mut self) -> Option<Self::Item<'_>> { … } } }
GAT 的实现还能推进“异步 trait”的支持。目前 Rust 异步还有很多限制,比如 trait 无法支持 async 方法,也是因为 GAT 功能未完善而导致的。
泛型特化Specialization
泛型特化这个概念,对应 Cpp 的模版特化。但是 Cpp 对特化的支持是相当完善,而 Rust 中特化还未稳定。
在 RFC #1210 中定义了 Rust 的泛型特化的实现标准,在 issue #31844 对其实现状态进行了跟踪。目前还有很多未解决的问题。
什么是泛型特化呢?
#![allow(unused)] fn main() { trait Example { type Output; fn generate(self) -> Self::Output; } impl<T> Example for T { type Output = Box<T>; fn generate(self) -> Box<T> { Box::new(self) } } impl Example for bool { type Output = bool; fn generate(self) -> bool { self } } }
简单来说,就是可以为泛型以及更加具体的类型来实现同一个 trait 。在调用该trait 方法时,倾向于优先使用更具体的类型实现。这就是对“泛型特化”最直观的一个理解。
泛型特化带来两个重要意义:
- 性能优化。特化扩展了零成本抽象的范围,可以为某个统一抽象下的具体实现,定制高性能实现。
- 代码重用。泛型特化可以提供一些默认(但不完整的)实现,某些情况下可以减少重复代码。
其实曾经特化还要为“高效继承(efficient-inheritance)”做为实现基础,但是现在高效继承这个提议并未被正式采纳。但我想,作为代码高效重用的一种手段,在未来肯定会被重新提及。
泛型特化功能,离最终稳定还有很长的路,目前官方正准备稳定特化的一个子集(subset)叫 min_specialization,旨在让泛型特化有一个最小化可用(mvp)的实现,在此基础上再慢慢稳定整体功能。现在 min_specialization 还没有具体稳定的日期,如果要使用此功能,只能在 Nightly Rust 下添加 #![feature(min_specialization)] 来使用。
#![feature(min_specialization)] use std::fmt::Debug; trait Destroy { fn destroy(self); } impl<T: Debug> Destroy for T { default fn destroy(self) { println!("Destroyed something!"); } } struct Special; impl Destroy for Special { fn destroy(self) { println!("Destroyed Special something!"); } } fn main() { "hello".destroy(); // Destroyed something! let sp = Special; sp.destroy(); // Destroyed Special something! }
其他待完善特性
异步 async trait、async drop
Rust 目前异步虽然早已稳定,但还有很多需要完善的地方。为此,官方创建了异步工作组,并且创建了 异步基础计划 来推动这一过程。
对于异步 trait 功能,首先会稳定的一个 mvp 功能是:trait 中的静态的 async fn 方法。
#![allow(unused)] fn main() { trait Service { async fn request(&self, key: i32) -> Response; } struct MyService { db: Database } impl Service for MyService { async fn request(&self, key: i32) -> Response { Response { contents: self.db.query(key).await.to_string() } } } }
在 trait 中支持 async fn 非常有用。但是目前只能通过 async-trait 来支持这个功能。因为当前 trait 中直接写 async fn 不是动态安全的(dyn safety,之前叫对象安全)。
现在这个 mvp 功能提出将 async fn 脱糖为静态分发的 trait,比如这样:
#![allow(unused)] fn main() { trait Service { type RequestFut<'a>: Future<Output = Response> where Self: 'a; fn request(&self, key: i32) -> RequestFut; } impl Service for MyService { type RequestFut<'a> = impl Future + 'a where Self: 'a; fn request<'a>(&'a self, key: i32) -> RequestFut<'a> { async { ... } } } }
对于 异步 drop 功能,目前也给出了一个方案,但没有类似 mvp 的落地计划。更多解释可以去查看异步基础计划的内容。
协程的稳定化
目前 Rust 的异步是基于一种半协程机制生成器( Generator) 来实现的,但生成器特性并未稳定。围绕“生成器特性”稳定的话题,在 Rust 论坛不定期会提出,因为生成器这个特性在其他语言中,也是比较常见且有用的特性。
但目前 Rust 团队对此并没有一个确切的设计,当前 Rust 内部的生成器机制只是为了稳定实现 异步编程而采取的临时设计。 所以这个特性也是 Rust 语言未来的挑战之一。
SIMD
众所周知,计算机程序需要编译成指令才能让 CPU 识别并执行运算。所以,CPU 指令处理数据的能力,是衡量 CPU 性能的重要指标。
为了提高 CPU 指令处理数据的能力,半导体厂商在 CPU 中推出了一些可以同时并行处理多个数据的指令 —— SIMD指令。SIMD 的全称是 Single Instruction Multiple Data,中文名“单指令多数据”。顾名思义,一条指令处理多个数据。
经过多年的发展,支持 SIMD 的指令集有很多。各种 CPU 架构都提供各自的 SIMD 指令集,比如 X86/MMX/SSE/AVX 等指令集。Rust 目前有很多架构平台下的指令集,但目前还未稳定,你可以在 core::arch 模块下找到,但这些都是可以具体架构平台相关的,并不能方便编写跨平台的 SIMD 代码。如果想编写跨平台 SIMD 代码,需要用到第三方库 packed_simd 。
最近几天,Rust 官方团队发布了 portable-simd ,你可以在 Nightly 下使用这个库来代替 packed_simd 了。这个库使得用 Rust 开发跨平台 SIMD 更加容易和安全。在不久的将来,也会引入到标准库中稳定下来。
新的 asm! 支持
asm! 宏允许在 Rust 中内联汇编。
在 RFC #2873 中规定了新的 asm!宏语法,将用于兼容 ARM、x86 和 RISC-V 等架构,方便在未来添加更多架构支持。之前的 asm! 宏被重命名为 llvm_asm!。目前新的 asm! 已经接近稳定状态,可在 issue #72016 中跟踪。
总的来说,就是让 asm! 宏更加通用,相比于 llvm_asm!,它有更好的语法。
#![allow(unused)] fn main() { // 旧的 asm! 宏写法 let i: u64 = 3; let o: u64; unsafe { asm!( "mov {0}, {1}", "add {0}, {number}", out(reg) o, in(reg) i, number = const 5, ); } assert_eq!(o, 8); // 新的 asm! 宏写法: let x: u64 = 3; let y: u64; unsafe { asm!("add {0}, {number}", inout(reg) x => y, number = const 5); } assert_eq!(y, 8); }
上面示例中, inout(reg) x 语句表示编译器应该找到一个合适的通用寄存器,用 x 的当前值准备该寄存器,将加法指令的输出存储在同一个通用寄存器中,然后将该通用寄存器的值存储在 x 中。
新的 asm! 宏的写法更像 println! 宏,这样更加易读。而旧的写法,需要和具体的汇编语法相绑定,并不通用。
Rustdoc 提升
Rust 是一门优雅的语言,并且这份优雅是非常完整的。除了语言的诸多特性设计优雅之外,还有一个亮点就是 Rustdoc,Rust 官方 doc 工作组立志让 Rustdoc 成为一个伟大的工具。
Rustdoc 使用简单,可以创建非常漂亮的页面,使编写文档成为一种乐趣。关于 Rustdoc 详细介绍你可以去看 Rustdoc book 。
Rustdoc 工作组最近在不断更新其功能,宗旨就是让编写文档更加轻松,消除重复的工作。比如,可以把项目的 README 文档,通过 #[doc] 属性来指派给某个模块,从而可以减少没必要的重复。
当然,未来的改进还有很多工作要做,这也算是 Rust 未来一大挑战。
deref pattern
deref pattern 是一个代表,它可以看作是Rust 官方对 Rust 语言诸多持续改进中的一个影子。
该特性简单来说,就是想让 Rust 语言在 match 模式匹配中也支持 deref:
#![allow(unused)] fn main() { let x: Option<Rc<bool>> = ...; match x { Some(deref true) => ..., Some(x) => ..., None => ..., } }
比如上面代码,匹配 Option<Rc<bool>> 的时候,可以无视其中的 Rc,直接透明操作 bool。上面例子里是一种解决方案,就是增加一个 deref 关键字。当然最终使用什么方案并未确定。
这里提到这个特性,是想说,Rust 语言目前在人体工程学方面,还有很多提升的空间;并且,Rust 团队也在不断的努力,让 Rust 语言使用起来更加方便和优雅。
小结
Rust 语言自身相对已经成熟,生态也足够丰富,并且在一些应用领域崭露头角。
Rust在系统语言的地位上,更像是当年的 C 语言。同样是通用语言,Rust现在在操作系统、云原生、物联网等关键系统领域成为刚需。因为“安全”现在已经是必选项了,这是 Rust 语言的时代机遇。同时,Rust 语言也在不同领域造就了新的职业岗位。
我们也看到,Rust 语言还有很多需要完善的地方,但这些都在官方团队的计划之中。我相信,在 Rust 基金会的引领下,Rust 肯定会迈向广泛应用的美好未来。
用户故事|语言不仅是工具,还是思维方式
你好,我是 Pedro,一名普普通通打工人,平平凡凡小码农。
可能你在课程留言区看到过我,也跟我讨论过问题。今天借着这篇用户故事的机会,正好能跟你再多聊几句。
我简单整理了一下自己入坑编程以来的一些思考,主要会从思维、语言和工具三个方面来聊一聊,最后也给你分享一点自己对 Rust 的看法,当然以下观点都是“主观”的,观点本身不重要,重要的是得到观点的过程。
从思维谈起
从接触编程开始,我们就已经开始与编程语言打交道,很多人学习编程的道路往往就是熟悉编程语言的过程。
在这个过程中,很多人会不适应,写出的代码往往都不能运行,更别提设计与抽象。出现这个现象最根本的原因是,代码体现的是计算机思维, 而人脑思维和计算机思维差异巨大,很多人一开始无法接受两种思维差异带来的巨大冲击。
那么,究竟什么是计算机思维?
计算机思维是全方位的,体现在方方面面,我以个人视角来简单概括一下:
- 自顶向下:自顶向下是计算机思维的精髓,人脑更加适合自底向上。计算机通过自顶向下思维将大而难的问题拆解为小问题,再将小问题逐一解决,从而最终解决大问题。
- 多维度、多任务:人脑是线性的,看问题往往是单维的,我们很难同时处理和思考多个问题,但是计算机不一样,它可以有多个 CPU 核心,在保存上下文的基础上能够并发运行成百上千的任务。
- 全局性:人的精力、脑容量是有限的,而计算机的容量几乎是无限的;人在思考问题时,限于自己的局部性,拿到局部解就开始做了,而计算机可以在海量数据的基础上再做决策,从而逼近全局最优。
- 协作性:计算机本身就是一件极其精细化的工程艺术品,它复杂精巧,每个部分都只会做自己最擅长的事情,比如将计算和存储剥离,计算机高效运作的背后是每个部分协作的结果,而人更擅长单体作战,只有通过大量的训练,才能发挥群体的作用。
- 迭代快:人类进化、成长是缓慢的,直到现在,很多人的思维方式仍旧停留在上个世纪,而计算机则不同,进入信息时代后,计算机就遵循着摩尔定律,每 18 个月翻一番,十年前的手机放在今天可能连微信都无法正常运行。
- 取舍:在长期的社会发展中,人过分喜欢强调对与错,喜欢追求绝对的公平,讽刺的是,由二进制组成的计算机却不会做出非黑即白的决策,无论是计算机本身(硬件),还是里面运行的软件,每一个部分都是性能、成本、易用性多角度权衡的结果。
- So on…
当这些思维直接体现在代码里面,比如,自顶向下体现在编程语言中就是递归、分治;多维度、多任务的体现就是分支、跳转、上下文;迭代、协作和取舍在编程中也处处可见。
而这些恰恰是人脑思维不擅长的点,所以很多人无法短时间内做到编程入门。想要熟练掌握编程,就必须认识到人脑与计算机思维的差异,强化计算机思维的训练, 这个训练的过程是不太可能短暂的,因此编程入门必须要消耗大量的时间和精力。
语言
不过思维的训练和评估是需要有载体的,就好比评估你的英文水平,会考察你用英文听/说/读/写的表达能力。那我们的计算机思维怎么表达呢?
于人而言,我们可以通过肢体动作、神情、声音、文字等来表达思维。在漫长的人类史中,动作、神情、声音这几种载体很难传承和传播,直到近代,音、视频的兴起才开始慢慢解决这个问题。
文字,尤其是语言诞生后的文字,成了人类文明延续、发展的主要途径之一,直至今天,我们仍然可以通过文字来与先贤对话。当然,对话的前提是,这些文字你得看得懂。
而看得懂的前提是,我们使用了同一种或类似的语言。
回到计算机上来,现代计算机也是有通用语言的,也就是我们常说的二进制机器语言,专业一点叫指令集。二进制是计算机的灵魂,但是人类却很难理解、记忆和应用,因此为了辅助人类操纵计算机工作,上一代程序员们对机器语言做了第一次抽象,发明了汇编语言。
但伴随着硬件、软件的快速发展,程序代码越来越长,应用变得愈来愈庞大,汇编级别的抽象已经无法满足工程师对快速高效工作的需求了。历史的发展总是如此地相似,当发现语言抽象已经无法满足工作时,工程师们就会在原有层的基础上再抽象出一层,而这一层的著名佼佼者——C语言直接奠定了今天计算机系统的基石。
从此以后,不计其数的编程语言走向计算机的舞台,它们如同满天繁星,吸引了无数的编程爱好者,比如说迈向中年的 Java 和新生代的 Julia。虽然学习计算机最正确的途径不是从语言开始,但学习编程最好、最容易获取成就感的路径确实是应该从语言入手。因此编程语言的重要性不言而喻,它是我们走向编程世界的大门。
C 语言是一种 命令式编程 语言,命令式是一种编程范式;使用 C 写代码时,我们更多是在思考如何描述程序的运行,通过编程语言来告诉计算机如何执行。
举个例子,使用 C 语言来筛选出一个数组中大于 100 的数字。对应代码如下:
int main() {
int arr[5] = { 100, 105, 110, 99, 0 };
for (int i = 0; i < 5; ++i) {
if (arr[i] > 100) {
// do something
}
}
return 0;
}
在这个例子中,代码撰写者需要使用数组、循环、分支判断等逻辑来告诉计算机如何去筛选数字,写代码的过程往往就是计算机的执行过程。
而对于另一种语言而言,比如 JavaScript,筛选出大于 100 的数字的代码大概是这样的:
let arr = [ 100, 105, 110, 99, 0 ]
let result = arr.filter(n => n > 100)
相较于 C 来说,JavaScript 做出了更加高级的抽象,代码撰写者无需关心数组容量、数组遍历,只需将数字丢进容器里面,并在合适的地方加上筛选函数即可,这种编程方式被称为 声明式编程。
可以看到的是,相较于命令式编程,声明式编程更倾向于表达在解决问题时应该做什么,而不是具体怎么做。这种更高级的抽象不仅能够给开发者带来更加良好的体验,也能让更多非专业人士进入编程这个领域。
不过命令式编程和声明式编程其实并没有优劣之分,主要区别体现在 两者的语言特性相较于计算机指令集的抽象程度。
其中,命令式编程语言的抽象程度更低,这意味着该类语言的语法结构可以直接由相应的机器指令来实现,适合对性能极度敏感的场景。而声明式编程语言的抽象程度更高,这类语言更倾向于以叙事的方式来描述程序逻辑,开发者无需关心语言背后在机器指令层面的实现细节,适合于业务快速迭代的场景。
不过语言不是一成不变的。编程语言一直在进化,它的进化速度绝对超过了自然语言的进化速度。
在抽象层面上,编程语言一直都停留在机器码 -> 汇编 -> 高级语言这三层上。而对于我们广大开发者来说,我们的目光一直聚焦在高级语言这一层上,所以,高级编程语言也慢慢成为了狭隘的编程语言(当然,这是一件好事,每一类人都应该各司其职做好自己的事情,不用过多担心指令架构、指令集差异带来的麻烦)。
谈到这里,不知你是否发现了一个规律:抽象越低的编程语言越接近计算机思维,而抽象越高越接近人脑思维。
是的。 现代层出不穷的编程语言,往往都是在人脑、计算机思维之间的平衡做取舍。那些设计语言的专家们似乎在这个毫无硝烟的战场上博弈,彼此对立却又彼此借鉴。不过哪怕再博弈,按照人类自然语言的趋势来看,也几乎不可能出现一家独大的可能,就像人类目前也是汉语、英语等多种语言共存,即使世界语于 1887 年就被发明,但我们似乎从未见过谁说世界语。
既然高级编程语言那么多,对于有选择困难症的我们,又该做出何种选择呢?
工具
一提到选语言,估计你常听这么一句话,语言是工具。很长一段时间里,我也这么告诫自己,无所谓一门语言的优劣,它仅仅只是一门工具,而我需要做的就是将这门工具用好。语言是表达思想的载体,只要有了思想,无论是何种语言,都能表达。
可当我接触了越来越多的编程语言,对代码、指令、抽象有了更深入的理解之后,我推翻了这个想法,认识到了“语言只是工具”这个说法的狭隘性。
编程语言,显然不仅只是工具,它一定程度上桎梏了我们的思维。
举例来说,使用 Java 或者 C# 的人能够很轻易地想到对象的设计与封装,那是因为 Java 和 C# 就是以类作为基本的组织单位,无论你是否有意识地去做这件事,你都已经做了。而对于 C 和 JavaScript 的使用者来说,大家似乎更倾向于使用函数来进行封装。
抛开语言本身的优劣,这是一种思维的惯性,恰恰也印证了上面我谈到的,语言一定程度上桎梏了我们的思维。其实如果从人类语言的角度出发,一个人说中文和说英文的思维方式是大相径庭的,甚至一个人分别说方言和普通话给别人的感觉也像是两个人一样。
Rust
所以如果说思维是我们创造的出发点,那么编程语言,在表达思维的同时,也在一定程度上桎梏了我们的思维。聊到这里,终于到我们今天的主角——Rust这门编程语言出场了。
Rust 是什么?
Rust 是一门高度抽象、性能与安全并重的现代化高级编程语言。我学习、推崇它的主要原因有三点:
- 高度抽象、表达能力强,支持命令式、声明式、元编程、范型等多种编程范式;
- 强大的工程能力,安全与性能并重;
- 良好的底层能力,天然适合内核、数据库、网络。
Rust 很好地迎合了人类思维,对指令集进行了高度抽象,抽象后的表达力能让我们以更接近人类思维的视角去写代码,而 Rust 负责将我们的思维翻译为计算机语言,并且性能和安全得到了极大的保证。简单说就是,完美兼顾了一门语言的思想性和工具性。
仍以前面“选出一个数组中大于 100 的数字”为例,如果使用 Rust,那么代码是这样的:
#![allow(unused)] fn main() { let arr = vec![ 100, 105, 110, 99, 0 ] let result = arr.iter().filter(n => n > 100).collect(); }
如此简洁的代码会不会带来性能损耗,Rust 的答案是不会,甚至可以比 C 做到更快。
我们对应看三个小例子的实现思路/要点,来感受一下 Rust 的语言表达能力、工程能力和底层能力。
简单协程
Rust 可以无缝衔接到 C、汇编代码,这样我们就可以跟下层的硬件打交道从而实现协程。
实现也很清晰。首先,定义出协程的上下文:
#![allow(unused)] fn main() { #[derive(Debug, Default)] #[repr(C)] struct Context { rsp: u64, // rsp 寄存器 r15: u64, r14: u64, r13: u64, r12: u64, rbx: u64, rbp: u64, } #[naked] unsafe fn ctx_switch() { // 注意:16 进制 llvm_asm!( " mov %rsp, 0x00(%rdi) mov %r15, 0x08(%rdi) mov %r14, 0x10(%rdi) mov %r13, 0x18(%rdi) mov %r12, 0x20(%rdi) mov %rbx, 0x28(%rdi) mov %rbp, 0x30(%rdi) mov 0x00(%rsi), %rsp mov 0x08(%rsi), %r15 mov 0x10(%rsi), %r14 mov 0x18(%rsi), %r13 mov 0x20(%rsi), %r12 mov 0x28(%rsi), %rbx mov 0x30(%rsi), %rbp " ); } }
结构体 Context 保存了协程的运行上下文信息(寄存器数据),通过函数 ctx_switch,当前协程就可以交出 CPU 使用权,下一个协程接管 CPU 并进入执行流。
然后我们给出协程的定义:
#![allow(unused)] fn main() { #[derive(Debug)] struct Routine { id: usize, stack: Vec<u8>, state: State, ctx: Context, } }
协程 Routine 有自己唯一的 id、栈 stack、状态 state,以及上下文 ctx。Routine 通过 spawn 函数创建一个就绪协程,yield 函数会交出 CPU 执行权:
#![allow(unused)] fn main() { pub fn spawn(&mut self, f: fn()) { // 找到一个可用的 // let avaliable = .... let sz = avaliable.stack.len(); unsafe { let stack_bottom = avaliable.stack.as_mut_ptr().offset(sz as isize); // 高地址内存是栈顶 let stack_aligned = (stack_bottom as usize & !15) as *mut u8; std::ptr::write(stack_aligned.offset(-16) as *mut u64, guard as u64); std::ptr::write(stack_aligned.offset(-24) as *mut u64, hello as u64); std::ptr::write(stack_aligned.offset(-32) as *mut u64, f as u64); avaliable.ctx.rsp = stack_aligned.offset(-32) as u64; // 16 字节对齐 } avaliable.state = State::Ready; } pub fn r#yield(&mut self) -> bool { // 找到一个 ready 的,然后让其运行 let mut pos = self.current; //..... self.routines[pos].state = State::Running; let old_pos = self.current; self.current = pos; unsafe { let old: *mut Context = &mut self.routines[old_pos].ctx; let new: *const Context = &self.routines[pos].ctx; llvm_asm!( "mov $0, %rdi mov $1, %rsi"::"r"(old), "r"(new) ); ctx_switch(); } self.routines.len() > 0 } }
运行结果如下:
#![allow(unused)] fn main() { 1 STARTING routine: 1 counter: 0 2 STARTING routine: 2 counter: 0 routine: 1 counter: 1 routine: 2 counter: 1 routine: 1 counter: 2 routine: 2 counter: 2 routine: 1 counter: 3 routine: 2 counter: 3 routine: 1 counter: 4 routine: 2 counter: 4 routine: 1 counter: 5 routine: 2 counter: 5 routine: 1 counter: 6 routine: 2 counter: 6 routine: 1 counter: 7 routine: 2 counter: 7 routine: 1 counter: 8 routine: 2 counter: 8 routine: 1 counter: 9 routine: 2 counter: 9 1 FINISHED }
具体代码实现参考 协程 。
简单内核
操作系统内核是一个极为庞大的工程,但是如果只是写个简单内核输出 Hello World,那么 Rust 就能很快完成这个任务。你可以自己体验一下。
首先,添加依赖工具:
#![allow(unused)] fn main() { rustup component add llvm-tools-preview cargo install bootimage }
然后编辑 main.rs 文件输出一个 Hello World:
#![allow(unused)] #![no_std] #![no_main] fn main() { use core::panic::PanicInfo; static HELLO:&[u8] = b"Hello World!"; #[no_mangle] pub extern "C" fn _start() -> ! { let vga_buffer = 0xb8000 as *mut u8; for (i, &byte) in HELLO.iter().enumerate() { unsafe { *vga_buffer.offset(i as isize * 2) = byte; *vga_buffer.offset(i as isize * 2 + 1) = 0xb; } } loop{} } #[panic_handler] fn panic(_info: &PanicInfo) -> ! { loop {} } }
然后编译、打包运行:
cargo bootimage
cargo run
运行结果如下:

具体代码实现参考 内核 。
简单网络协议栈
同操作系统一样,网络协议栈也是一个庞大的工程系统。但是借助 Rust 和其完备的生态,我们可以迅速完成一个小巧的 HTTP 协议栈。
首先,在数据链路层,我们定义 Mac 地址结构体:
#![allow(unused)] fn main() { #[derive(Debug)] pub struct MacAddress([u8; 6]); impl MacAddress { pub fn new() -> MacAddress { let mut octets: [u8; 6] = [0; 6]; rand::thread_rng().fill_bytes(&mut octets); // 1. 随机生成 octets[0] |= 0b_0000_0010; // 2 octets[1] &= 0b_1111_1110; // 3 MacAddress { 0: octets } } } }
MacAddress 用来表示网卡的物理地址,此处的 new 函数通过随机数来生成随机的物理地址。
然后实现 DNS 域名解析函数,通过 IP 地址获取 MAC 地址,如下:
#![allow(unused)] fn main() { pub fn resolve( dns_server_address: &str, domain_name: &str, ) -> Result<Option<std::net::IpAddr>, Box<dyn Error>> { let domain_name = Name::from_ascii(domain_name).map_err(DnsError::ParseDomainName)?; let dns_server_address = format!("{}:53", dns_server_address); let dns_server: SocketAddr = dns_server_address .parse() .map_err(DnsError::ParseDnsServerAddress)?; // .... let mut encoder = BinEncoder::new(&mut request_buffer); request.emit(&mut encoder).map_err(DnsError::Encoding)?; let _n_bytes_sent = localhost .send_to(&request_buffer, dns_server) .map_err(DnsError::Sending)?; loop { let (_b_bytes_recv, remote_port) = localhost .recv_from(&mut response_buffer) .map_err(DnsError::Receiving)?; if remote_port == dns_server { break; } } let response = Message::from_vec(&response_buffer).map_err(DnsError::Decoding)?; for answer in response.answers() { if answer.record_type() == RecordType::A { let resource = answer.rdata(); let server_ip = resource.to_ip_addr().expect("invalid IP address received"); return Ok(Some(server_ip)); } } Ok(None) } }
接着实现 HTTP 协议的 GET 方法:
#![allow(unused)] fn main() { pub fn get( tap: TapInterface, mac: EthernetAddress, addr: IpAddr, url: Url, ) -> Result<(), UpstreamError> { let domain_name = url.host_str().ok_or(UpstreamError::InvalidUrl)?; let neighbor_cache = NeighborCache::new(BTreeMap::new()); // TCP 缓冲区 let tcp_rx_buffer = TcpSocketBuffer::new(vec![0; 1024]); let tcp_tx_buffer = TcpSocketBuffer::new(vec![0; 1024]); let tcp_socket = TcpSocket::new(tcp_rx_buffer, tcp_tx_buffer); let ip_addrs = [IpCidr::new(IpAddress::v4(192, 168, 42, 1), 24)]; let fd = tap.as_raw_fd(); let mut routes = Routes::new(BTreeMap::new()); let default_gateway = Ipv4Address::new(192, 168, 42, 100); routes.add_default_ipv4_route(default_gateway).unwrap(); let mut iface = EthernetInterfaceBuilder::new(tap) .ethernet_addr(mac) .neighbor_cache(neighbor_cache) .ip_addrs(ip_addrs) .routes(routes) .finalize(); let mut sockets = SocketSet::new(vec![]); let tcp_handle = sockets.add(tcp_socket); // HTTP 请求 let http_header = format!( "GET {} HTTP/1.0\r\nHost: {}\r\nConnection: close\r\n\r\n", url.path(), domain_name, ); let mut state = HttpState::Connect; 'http: loop { let timestamp = Instant::now(); match iface.poll(&mut sockets, timestamp) { Ok(_) => {} Err(smoltcp::Error::Unrecognized) => {} Err(e) => { eprintln!("error: {:?}", e); } } { let mut socket = sockets.get::<TcpSocket>(tcp_handle); state = match state { HttpState::Connect if !socket.is_active() => { eprintln!("connecting"); socket.connect((addr, 80), random_port())?; HttpState::Request } HttpState::Request if socket.may_send() => { eprintln!("sending request"); socket.send_slice(http_header.as_ref())?; HttpState::Response } HttpState::Response if socket.can_recv() => { socket.recv(|raw_data| { let output = String::from_utf8_lossy(raw_data); println!("{}", output); (raw_data.len(), ()) })?; HttpState::Response } HttpState::Response if !socket.may_recv() => { eprintln!("received complete response"); break 'http; } _ => state, } } phy_wait(fd, iface.poll_delay(&sockets, timestamp)).expect("wait error"); } Ok(()) } }
最后在 main 函数中使用 HTTP GET 方法:
fn main() { // ... let tap = TapInterface::new(&tap_text).expect( "error: unable to use <tap-device> as a \ network interface", ); let domain_name = url.host_str().expect("domain name required"); let _dns_server: std::net::Ipv4Addr = dns_server_text.parse().expect( "error: unable to parse <dns-server> as an \ IPv4 address", ); let addr = dns::resolve(dns_server_text, domain_name).unwrap().unwrap(); let mac = ethernet::MacAddress::new().into(); http::get(tap, mac, addr, url).unwrap(); }
运行程序,结果如下:
$ ./target/debug/rget http://www.baidu.com tap-rust
HTTP/1.0 200 OK
Accept-Ranges: bytes
Cache-Control: no-cache
Content-Length: 9508
Content-Type: text/html
具体代码实现参考 协议栈 。
通过这三个简单的小例子,无论是协程、内核还是协议栈,这些听上去都很高大上的技术,在 Rust 强大的表现力、生态和底层能力面前显得如此简单和方便。
思维是出发点,语言是表达体,工具是媒介,而 Rust 完美兼顾了一门语言的思想性和工具性,赋予了我们极强的工程表达能力和完成能力。
总结
作为极其现代的语言,Rust 集百家之长而成,将性能、安全、语言表达力都做到了极致,但同时也带来了巨大的学习曲线。
初学时,每天都要和编译器做斗争,每次编译都是满屏的错误信息;攻克一个陡坡后,发现后面有更大的陡坡,学习的道路似乎无穷无尽。那我们为什么要学习 Rust ?
这里引用左耳朵耗子的一句话:
如果你对 Rust 的概念认识得不完整,你完全写不出程序,那怕就是很简单的一段代码。这逼着程序员必须了解所有的概念才能编码。
Rust 是一个对开发者极其严格的语言,严格到你学的不扎实,就不能写程序, 但这无疑也是一个巨大的机会,改掉你不好的编码习惯,锻炼你的思维,让你成为真正的大师。
聊到这里,你是否已经对 Rust 有了更深的认识和更多的激情,那么放手去做吧!期待你与 Rust 擦出更加明亮的火花!
参考资料
- Writing an OS in Rust
- green-threads-explained-in-200-lines-of-rust
- https://github.com/PedroGao/rust-examples
- 《深入理解计算机系统》
- 《Rust in Action》
- 《硅谷来信》
- 《浪潮之巅》
加餐|代码即数据:为什么我们需要宏编程能力?
你好,我是陈天。
应广大同学的呼吁,今天我们来讲讲宏编程。
最初设计课程的时候考虑知识点的系统性,Rust 的元编程能力声明宏、过程宏各安排了一讲,但宏编程是高阶内容后来删减掉了。其实如果你初步学习Rust,不用太深究宏,大多数应用的场景,你会使用标准库或者第三方库提供的宏就行。不会做宏编程,并不影响你日常的开发。
不过很多同学对宏有兴趣,我们今天就深入聊一聊。在讲如何使用宏、如何构建宏之前,我们要先搞清楚为什么会出现宏。
为什么我们需要宏编程能力?
我们从设计非常独特的Lisp语言讲起。在 Lisp 的世界里,有句名言:代码即数据,数据即代码(Code is data, data is code)。
如果你有一点 Lisp 相关的开发经验,或者听说过任何一种 Lisp 方言,你可能知道,和普通编程语言不同的是, Lisp 的语言直接把 AST(抽象语法树)暴露给开发者,开发者写的每一行代码,其实就是在描述这段代码的 AST。
这个特点如果你没有太看明白,我们结合一个具体例子来理解。这段代码是 6 年前,2048 游戏很火的时候,我用 Lisp 的一种方言 Racket 撰写的 2048 的实现 片段:
; e.g. '(2 2 2 4 4 4 8) -> '(4 2 8 4 8)
(define (merge row)
(cond [(<= (length row) 1) row]
[(= (first row) (second row))
(cons (* 2 (first row)) (merge (drop row 2)))]
[else (cons (first row) (merge (rest row)))]))
这段代码的算法不难理解,给定一个 row:
- 如果它只有一个值,那么直接返回;
- 如果头两个元素相等,那么把第一个元素乘以 2,与头两个元素之后的所有元素 merge 的结果(此处有递归),组成一个新的 list 返回;
- 否则,就把第一个元素和之后的所有元素 merge 的结果组成一个新的 list 返回(此处也是递归)。
看着这段代码,相信只要你花些耐心就可以写出对应的语法树:
你会发现,撰写 Lisp 代码,就相当于直接在描述语法树。
从语法树的角度看,编程语言其实也没有什么了不起的,它操作和执行的数据结构不过就是这样的一棵棵树,就跟我们开发者平日里编程操作的各种数据结构一样。
如果一门编程语言把它在解析过程中产生的语法树暴露给开发者,允许开发者对语法树进行裁剪和嫁接这样移花接木的处理,那么这门语言就具备了元编程的能力。
语言对这样处理的限制越少,元编程的能力就越强,当然作为一枚硬币的反面,语言就会过度灵活,无法无天,甚至反噬语言本身;反之,语言对开发者操作语法树的限制越多,元编程能力就越弱,语言虽然丧失了灵活性,但是更加规矩。
Lisp 语言,作为元编程能力的天花板,毫无保留地把语法树像数据一样敞露给开发者,让开发者不光在编译期,甚至在运行期,都可以随意改变代码的行为,这也是Lisp“代码即数据,数据即代码”思路的直接体现。
在《 黑客与画家》一书里(p196),PG 引用了“ 格林斯潘第十定律”:
任何C或Fortran程序复杂到一定程度之后,都会包含一个临时开发的、只有一半功能的、不完全符合规格的、到处都是bug的、运行速度很慢的Common Lisp实现。
虽然这是 Lisp 拥趸对其他语言的极尽嘲讽,不过也说明了一个不争的事实:一门设计再精妙、提供再丰富生态的语言,在实际的使用场景中,都不可避免地需要具备某种用代码生成代码的能力,来大大减轻开发者不断撰写结构和模式相同的重复脚手架代码的需求。
幸运的是,Rust 这门语言提供了足够强大的宏编程能力,让我们在需要的时候,可以通过撰写宏来避免重复的脚手架代码,同时,Rust 对宏的使用还有足够的限制,在保证灵活性的前提下,防止我们过度使用让代码失控。
那Rust到底提供了哪些宏呢?
Rust 对宏编程有哪些支持?
在过去的课程中,我们经历了各种各样的宏,比如创建 Vec#[derive(Debug, Default, ...)]、条件编译时使用的 #[cfg(test)] 宏等等。
其实Rust中的宏就两大类: 对代码模板做简单替换的声明宏(declarative macro)、可以深度定制和生成代码的过程宏(procedural macro)。

声明宏
首先是声明宏(declarative macro),课程里出现过的比如像 vec![]、 println!、以及 info!,它们都是声明宏。
声明宏可以用 macro_rules! 来描述,我们看一个常用的 tracing log 的宏定义( 代码):
#![allow(unused)] fn main() { macro_rules! __tracing_log { (target: $target:expr, $level:expr, $($field:tt)+ ) => { $crate::if_log_enabled! { $level, { use $crate::log; let level = $crate::level_to_log!($level); if level <= log::max_level() { let log_meta = log::Metadata::builder() .level(level) .target($target) .build(); let logger = log::logger(); if logger.enabled(&log_meta) { logger.log(&log::Record::builder() .file(Some(file!())) .module_path(Some(module_path!())) .line(Some(line!())) .metadata(log_meta) .args($crate::__mk_format_args!($($field)+)) .build()); } } }} }; } }
可以看到, 它主要做的就是通过简单的接口,把不断重复的逻辑包装起来,然后在调用的地方展开而已,不涉及语法树的操作。
如果你用过 C/C++,那么Rust的声明宏和 C/C++ 里面的宏类似,承载同样的目的。只不过 Rust 的声明宏更加安全,你无法在需要出现标识符的地方出现表达式,也无法让宏内部定义的变量污染外部的世界。比如在 C 中,你可以这样声明一个宏:
#![allow(unused)] fn main() { define MUL(a, b) a * b }
这个宏是期望调用者传入两个标识符,执行这两个标识符对应值的乘法操作,但实际我们可以对 a 传入 1 + 2,对 b 传入 4 - 3,导致结果完全错误。
过程宏
除了做简单替换的声明宏,Rust 还支持允许我们深度操作和改写 Rust 代码语法树的过程宏(procedural macro),更加灵活,更为强大。
Rust 的过程宏分为三种:
- 函数宏(function-like macro):看起来像函数的宏,但在编译期进行处理。比如我们之前用过的 sqlx 里的 query 宏,它内部展开出一个 expand_query 函数宏。你可能想象不到,看上去一个简单的 query 处理,内部有多么庞大的代码结构。
- 属性宏(attribute macro):可以在其他代码块上添加属性,为代码块提供更多功能。比如 rocket 的 get / put 等路由属性。
- 派生宏(derive macro):为 derive 属性添加新的功能。这是我们平时使用最多的宏,比如
#[derive(Debug)]为我们的数据结构提供 Debug trait 的实现、#[derive(Serialize, Deserialize)]为我们的数据结构提供 serde 相关 trait 的实现。
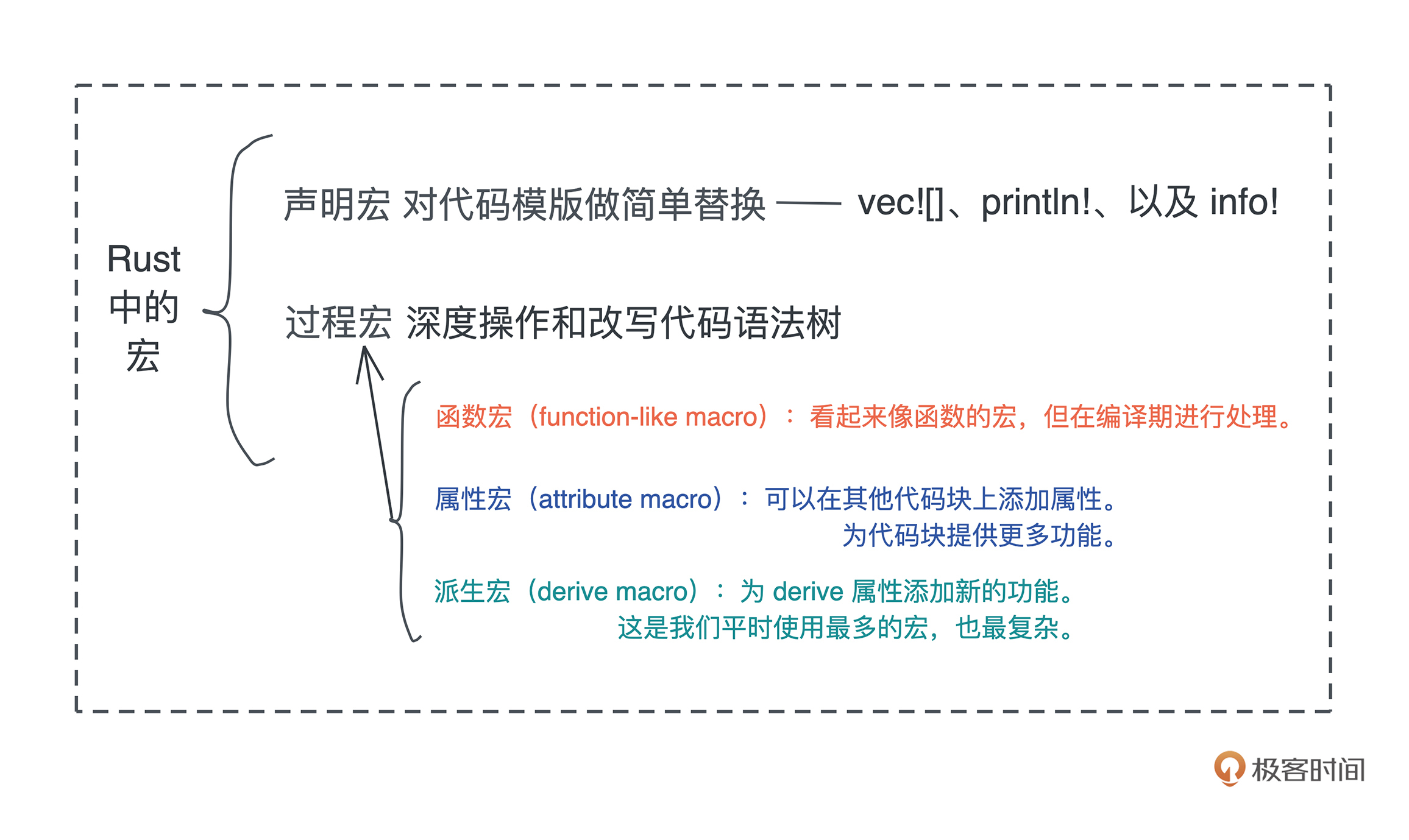
什么情况可以用宏
前面讲过,宏的主要作用是避免我们创建大量结构相同的脚手架代码。那么我们在什么情况下可以使用宏呢?
首先说声明宏。 如果重复性的代码无法用函数来封装,那么声明宏就是一个好的选择,比如 Rust 早期版本中的 try!,它是 ? 操作符的前身。
再比如 futures 库的 ready! 宏:
#![allow(unused)] fn main() { #[macro_export] macro_rules! ready { ($e:expr $(,)?) => { match $e { $crate::task::Poll::Ready(t) => t, $crate::task::Poll::Pending => return $crate::task::Poll::Pending, } }; } }
这样的结构,因为涉及提早 return,无法用函数封装,所以用声明宏就很简洁。
过程宏里,先说最复杂的派生宏,因为派生宏会在特定的场景使用,所以如果你有需要可以使用。
比如一个数据结构,我们希望它能提供 Debug trait 的能力,但为自己定义的每个数据结构实现 Debug trait 太过繁琐,而且代码所做的操作又都是一样的,这时候就可以考虑使用派生宏来简化这个操作。
一般来说,如果你定义的 trait 别人实现起来有固定的模式可循,那么可以考虑为其构建派生宏。serde 在 Rust 的世界里这么流行、这么好用,很大程度上也是因为基本上你的数据结构只需要添加 #[derive(Serialize, Deserialize)],就可以轻松序列化成 JSON、YAML 等好多种类型(或者从这些类型中反序列化)。
函数宏和属性宏并没有特定的使用场景。sqlx 用函数宏来处理 SQL query、tokio 使用属性宏 #[tokio::main] 来引入 runtime。它们可以帮助目标代码的实现逻辑变得更加简单, 但一般除非特别必要,否则我并不推荐写。
好,学到这里你已经了解了足够多的关于宏的基础知识,欢迎在留言区交流你对宏的理解。
如果你对撰写宏有兴趣,下一讲我们会手写声明宏和过程宏来深入理解宏到底做了什么。我们下一讲见!
加餐|宏编程(上):用最“笨”的方式撰写宏
你好,我是陈天。
学过上一讲,相信你现在应该理解为什么在课程的 第 6 讲 我们说,宏的本质其实很简单,抛开 quote/unquote,宏编程主要的工作就是把一棵语法树转换成另一颗语法树,而这个转换的过程深入下去,不过就是数据结构到数据结构的转换。
那在Rust里宏到底是如何做到转换的呢?
接下来,我们就一起尝试构建声明宏和过程宏。希望你能从自己撰写的过程中,感受构建宏的过程中做数据转换的思路和方法,掌握了这个方法,你可以应对几乎所有和宏编程有关的问题。
如何构建声明宏
首先看声明宏是如何创建的。
我们 cargo new macros --lib 创建一个新的项目,然后在新生成的项目下,创建 examples 目录,添加 examples/rule.rs( 代码):
#[macro_export] macro_rules! my_vec { // 没带任何参数的 my_vec,我们创建一个空的 vec () => { std::vec::Vec::new() }; // 处理 my_vec![1, 2, 3, 4] ($($el:expr),*) => ({ let mut v = std::vec::Vec::new(); $(v.push($el);)* v }); // 处理 my_vec![0; 10] ($el:expr; $n:expr) => { std::vec::from_elem($el, $n) } } fn main() { let mut v = my_vec![]; v.push(1); // 调用时可以使用 [], (), {} let _v = my_vec!(1, 2, 3, 4); let _v = my_vec![1, 2, 3, 4]; let v = my_vec! {1, 2, 3, 4}; println!("{:?}", v); println!("{:?}", v); // let v = my_vec![1; 10]; println!("{:?}", v); }
上一讲我们说过对于声明宏可以用 macro_rules! 生成。macro_rules 使用模式匹配,所以你可以提供多个匹配条件以及匹配后对应执行的代码块。
看这段代码,我们写了3个匹配的rules。
第一个 () => (std::vec::Vec::new()) 很好理解,如果没有传入任何参数,就创建一个新的 Vec。注意,由于宏要在调用的地方展开,我们无法预测调用者的环境是否已经做了相关的 use,所以我们使用的代码最好带着完整的命名空间。
这第二个匹配条件 ($($el:expr),*),需要详细介绍一下。
在声明宏中,条件捕获的参数使用 $ 开头的标识符来声明。每个参数都需要提供类型,这里 expr 代表表达式,所以 $el:expr 是说把匹配到的表达式命名为 $el。 $(...),* 告诉编译器可以匹配任意多个以逗号分隔的表达式,然后捕获到的每一个表达式可以用 $el 来访问。
由于匹配的时候匹配到一个 $(...)* (我们可以不管分隔符),在执行的代码块中,我们也要相应地使用 $(...)* 展开。所以这句 $(v.push($el);)* 相当于匹配出多少个 $el 就展开多少句 push 语句。
理解了第二个匹配条件,第三个就很好理解了:如果传入用冒号分隔的两个表达式,那么会用 from_element 构建 Vec。
在使用声明宏时,我们需要为参数明确类型,哪些类型可用也整理在这里了:
item,比如一个函数、结构体、模块等。block,代码块。比如一系列由花括号包裹的表达式和语句。stmt,语句。比如一个赋值语句。pat,模式。expr,表达式。刚才的例子使用过了。ty,类型。比如 Vec。ident,标识符。比如一个变量名。path,路径。比如:foo、::std::mem::replace、transmute::<_, int>。meta,元数据。一般是在#[...]和#![...]属性内部的数据。tt,单个的 token 树。vis,可能为空的一个Visibility修饰符。比如 pub、pub(crate)。
声明宏构建起来很简单, 只要遵循它的基本语法,你可以很快把一个函数或者一些重复的语句片段转换成声明宏。
比如在处理 pipeline 时,我经常会根据某个返回 Result 的表达式的结果,做下面代码里这样的 match,使其在出错时返回 PipelineError 这个 enum 而非 Result:
#![allow(unused)] fn main() { match result { Ok(v) => v, Err(e) => { return pipeline::PlugResult::Err { ctx, err: pipeline::PipelineError::Internal(e.to_string()), } } } }
但是这种写法,在同一个函数内,可能会反复出现,我们又无法用函数将其封装,所以我们可以用声明宏来实现,可以大大简化代码:
#![allow(unused)] fn main() { #[macro_export] macro_rules! try_with { ($ctx:ident, $exp:expr) => { match $exp { Ok(v) => v, Err(e) => { return pipeline::PlugResult::Err { ctx: $ctx, err: pipeline::PipelineError::Internal(e.to_string()), } } } }; } }
如何构建过程宏
接下来我们讲讲如何构建过程宏。
过程宏要比声明宏要复杂很多,不过无论是哪一种过程宏, 本质都是一样的,都涉及要把输入的 TokenStream 处理成输出的 TokenStream。
要构建过程宏,你需要单独构建一个 crate,在 Cargo.toml 中添加 proc-macro 的声明:
#![allow(unused)] fn main() { [lib] proc-macro = true }
这样,编译器才允许你使用 #[proc_macro] 相关的宏。所以我们先在今天这堂课生成的 crate 的 Cargo.toml 中添加这个声明,然后在 lib.rs 里写入如下代码:
#![allow(unused)] fn main() { use proc_macro::TokenStream; #[proc_macro] pub fn query(input: TokenStream) -> TokenStream { println!("{:#?}", input); "fn hello() { println!(\\"Hello world!\\"); }" .parse() .unwrap() } }
这段代码首先声明了它是一个 proc_macro,并且是最基本的、函数式的过程宏。
使用者可以通过 query!(...) 来调用。我们打印传入的 TokenStream,然后把一段包含在字符串中的代码解析成 TokenStream 返回。这里可以非常方便地用字符串的 parse() 方法来获得 TokenStream,是因为 TokenStream 实现了 FromStr trait,感谢Rust。
好,明白这段代码做了什么,我们写个例子尝试使用一下,来创建 examples/query.rs,并写入代码:
use macros::query; fn main() { query!(SELECT * FROM users WHERE age > 10); }
可以看到,尽管 SELECT * FROM user WHERE age > 10 不是一个合法的 Rust 语法,但 Rust 的词法分析器还是把它解析成了 TokenStream,提供给 query 宏。
运行 cargo run --example query,看 query 宏对输入 TokenStream 的打印:
#![allow(unused)] fn main() { TokenStream [ Ident { ident: "SELECT", span: #0 bytes(43..49), }, Punct { ch: '*', spacing: Alone, span: #0 bytes(50..51), }, Ident { ident: "FROM", span: #0 bytes(52..56), }, Ident { ident: "users", span: #0 bytes(57..62), }, Ident { ident: "WHERE", span: #0 bytes(63..68), }, Ident { ident: "age", span: #0 bytes(69..72), }, Punct { ch: '>', spacing: Alone, span: #0 bytes(73..74), }, Literal { kind: Integer, symbol: "10", suffix: None, span: #0 bytes(75..77), }, ] }
这里面,TokenStream 是一个 Iterator,里面包含一系列的 TokenTree:
#![allow(unused)] fn main() { pub enum TokenTree { Group(Group), Ident(Ident), Punct(Punct), Literal(Literal), } }
后三个分别是 Ident(标识符)、Punct(标点符号)和 Literal(字面量)。这里的Group(组),是因为如果你的代码中包含括号,比如 {} [] <> () ,那么内部的内容会被分析成一个 Group(组)。你也可以试试把例子中对 query! 的调用改成这个样子:
#![allow(unused)] fn main() { query!(SELECT * FROM users u JOIN (SELECT * from profiles p) WHERE u.id = p.id and u.age > 10); }
再运行一下 cargo run --example query,看看现在的 TokenStream 长什么样子,是否包含 Group。
好,现在我们对输入的 TokenStream 有了一个概念,那么,输出的 TokenStream 有什么用呢?我们的 query! 宏返回了一个 hello() 函数的 TokenStream,这个函数真的可以直接调用么?
你可以试试在 main() 里加入对 hello() 的调用,再次运行这个 example,可以看到久违的 “Hello world!” 打印。
恭喜你!你的第一个过程宏就完成了!
虽然这并不是什么了不起的结果,但是通过它,我们认识到了过程宏的基本写法,以及TokenStream / TokenTree 的基本结构。
接下来,我们就尝试实现一个派生宏,这是过程宏的三类宏中对大家最有意义的一类,也是工作中如果需要写过程宏主要会用到的宏类型。
如何构建派生宏
我们期望构建一个 Builder 派生宏,实现 proc-macro-workshop 里 如下需求(proc-macro-workshop是 Rust 大牛 David Tolnay 为帮助大家更好地学习宏编程构建的练习):
#[derive(Builder)] pub struct Command { executable: String, args: Vec<String>, env: Vec<String>, current_dir: Option<String>, } fn main() { let command = Command::builder() .executable("cargo".to_owned()) .args(vec!["build".to_owned(), "--release".to_owned()]) .env(vec![]) .build() .unwrap(); assert!(command.current_dir.is_none()); let command = Command::builder() .executable("cargo".to_owned()) .args(vec!["build".to_owned(), "--release".to_owned()]) .env(vec![]) .current_dir("..".to_owned()) .build() .unwrap(); assert!(command.current_dir.is_some()); }
可以看到,我们仅仅是为 Command 这个结构提供了 Builder 宏,就让它支持 builder() 方法,返回了一个 CommandBuilder 结构,这个结构有若干个和 Command 内部每个域名字相同的方法,我们可以链式调用这些方法,最后 build() 出一个 Command 结构。
我们创建一个 examples/command.rs,把这部分代码添加进去。显然,它是无法编译通过的。下面先来手工撰写对应的代码,看看一个完整的、能够让 main() 正确运行的代码长什么样子:
#[allow(dead_code)] #[derive(Debug)] pub struct Command { executable: String, args: Vec<String>, env: Vec<String>, current_dir: Option<String>, } #[derive(Debug, Default)] pub struct CommandBuilder { executable: Option<String>, args: Option<Vec<String>>, env: Option<Vec<String>>, current_dir: Option<String>, } impl Command { pub fn builder() -> CommandBuilder { Default::default() } } impl CommandBuilder { pub fn executable(mut self, v: String) -> Self { self.executable = Some(v.to_owned()); self } pub fn args(mut self, v: Vec<String>) -> Self { self.args = Some(v.to_owned()); self } pub fn env(mut self, v: Vec<String>) -> Self { self.env = Some(v.to_owned()); self } pub fn current_dir(mut self, v: String) -> Self { self.current_dir = Some(v.to_owned()); self } pub fn build(mut self) -> Result<Command, &'static str> { Ok(Command { executable: self.executable.take().ok_or("executable must be set")?, args: self.args.take().ok_or("args must be set")?, env: self.env.take().ok_or("env must be set")?, current_dir: self.current_dir.take(), }) } } fn main() { let command = Command::builder() .executable("cargo".to_owned()) .args(vec!["build".to_owned(), "--release".to_owned()]) .env(vec![]) .build() .unwrap(); assert!(command.current_dir.is_none()); let command = Command::builder() .executable("cargo".to_owned()) .args(vec!["build".to_owned(), "--release".to_owned()]) .env(vec![]) .current_dir("..".to_owned()) .build() .unwrap(); assert!(command.current_dir.is_some()); println!("{:?}", command); }
这个代码很简单,基本就是照着 main() 中的使用方法,一个函数一个函数手写出来的,你可以看到代码中很多重复的部分,尤其是 CommandBuilder 里的方法,这是我们可以用宏来自动生成的。
那怎么生成这样的代码呢?显然,我们要把输入的 TokenStream抽取出来,也就是把在 struct 的定义内部,每个域的名字及其类型都抽出来,然后生成对应的方法代码。
如果把代码看做是字符串的话,不难想象到,实际上就是要通过一个模板和对应的数据,生成我们想要的结果。用模板生成 HTML,想必各位都不陌生,但通过模板生成 Rust 代码,估计你是第一次。
有了这个思路,我们尝试着用 jinja 写一个生成 CommandBuilder 结构的模板。在 Rust 里,我们有 askma 这个非常高效的库来处理 jinja。模板大概长这个样子:
#![allow(unused)] fn main() { #[derive(Debug, Default)] pub struct {{ builder_name }} { {% for field in fields %} {{ field.name }}: Option<{{ field.ty }}>, {% endfor %} } }
这里的 fileds / builder_name 是我们要传入的参数,每个 field 还需要 name 和 ty 两个属性,分别对应 field 的名字和类型。我们也可以为这个结构生成方法:
#![allow(unused)] fn main() { impl {{ builder_name }} { {% for field in fields %} pub fn {{ field.name }}(mut self, v: impl Into<{{ field.ty }}>) -> {{ builder_name }} { self.{{ field.name }} = Some(v.into()); self } {% endfor %} pub fn build(self) -> Result<{{ name }}, &'static str> { Ok({{ name }} { {% for field in fields %} {% if field.optional %} {{ field.name }}: self.{{ field.name }}, {% else %} {{ field.name }}: self.{{ field.name }}.ok_or("Build failed: missing {{ field.name }}")?, {% endif %} {% endfor %} }) } } }
对于原本是 Option
有了这个思路,我们可以构建自己的数据结构来描述 Field:
#![allow(unused)] fn main() { #[derive(Debug, Default)] struct Fd { name: String, ty: String, optional: bool, } }
当我们有了模板,又定义好了为模板提供数据的结构,接下来要处理的核心问题就是:如何从 TokenStream 中抽取出来我们想要的信息?
带着这个问题,我们在 lib.rs 里添加一个 derive macro,把 input 打印出来:
#![allow(unused)] fn main() { #[proc_macro_derive(RawBuilder)] pub fn derive_raw_builder(input: TokenStream) -> TokenStream { println!("{:#?}", input); TokenStream::default() } }
对于 derive macro,要使用 proce_macro_derive 这个宏。我们把这个 derive macro 命名为 RawBuilder。在 examples/command.rs 中,我们修改 Command 结构,使其使用 RawBuilder(注意要 use macros::RawBuilder):
#![allow(unused)] fn main() { use macros::RawBuilder; #[allow(dead_code)] #[derive(Debug, RawBuilder)] pub struct Command { ... } }
运行这个 example 后,我们会看到一大片 TokenStream 的打印(比较长这里就不贴了),仔细阅读这个打印,可以看到:
- 首先有一个 Group,包含了
#[allow(dead_code)]属性的信息。因为我们现在拿到的 derive 下的信息,所以所有不属于#[derive(...)]的属性,都会被放入 TokenStream 中。 - 之后是 pub / struct / Command 三个 ident。
- 随后又是一个 Group,包含了每个 field 的信息。我们看到,field 之间用逗号这个 Punct 分隔,field 的名字和类型又是通过冒号这个 Punct 分隔。而类型,可能是一个 Ident,如 String,或者一系列 Ident / Punct,如 Vec / < / String / >。
我们要做的就是,把这个 TokenStream 中的 struct 名字,以及每个 field 的名字和类型拿出来。如果类型是 Option
好,有了这个思路,来写代码。首先在 Cargo.toml 中引入一些依赖:
#![allow(unused)] fn main() { [dependencies] anyhow = "1" askama = "0.11" # 处理 jinjia 模板,模板需要放在和 src 平行的 templates 目录下 }
akama 要求模板放在和 src 平行的 templates 目录下,创建这个目录,然后写入 templates/builder.j2:
#![allow(unused)] fn main() { impl {{ name }} { pub fn builder() -> {{ builder_name }} { Default::default() } } #[derive(Debug, Default)] pub struct {{ builder_name }} { {% for field in fields %} {{ field.name }}: Option<{{ field.ty }}>, {% endfor %} } impl {{ builder_name }} { {% for field in fields %} pub fn {{ field.name }}(mut self, v: impl Into<{{ field.ty }}>) -> {{ builder_name }} { self.{{ field.name }} = Some(v.into()); self } {% endfor %} pub fn build(self) -> Result<{{ name }}, &'static str> { Ok({{ name }} { {% for field in fields %} {% if field.optional %} {{ field.name }}: self.{{ field.name }}, {% else %} {{ field.name }}: self.{{ field.name }}.ok_or("Build failed: missing {{ field.name }}")?, {% endif %} {% endfor %} }) } } }
然后创建 src/raw_builder.rs(记得在 lib.rs 中引入),写入代码,这段代码我加了详细的注释,你可以对着打印出来的 TokenStream和刚才的分析,相信不难理解。
#![allow(unused)] fn main() { use anyhow::Result; use askama::Template; use proc_macro::{Ident, TokenStream, TokenTree}; use std::collections::VecDeque; /// 处理 jinja 模板的数据结构,在模板中我们使用了 name / builder_name / fields #[derive(Template)] #[template(path = "builder.j2", escape = "none")] pub struct BuilderContext { name: String, builder_name: String, fields: Vec<Fd>, } /// 描述 struct 的每个 field #[derive(Debug, Default)] struct Fd { name: String, ty: String, optional: bool, } impl Fd { /// name 和 field 都是通过冒号 Punct 切分出来的 TokenTree 切片 pub fn new(name: &[TokenTree], ty: &[TokenTree]) -> Self { // 把类似 Ident("Option"), Punct('<'), Ident("String"), Punct('>) 的 ty // 收集成一个 String 列表,如 vec!["Option", "<", "String", ">"] let ty = ty .iter() .map(|v| match v { TokenTree::Ident(n) => n.to_string(), TokenTree::Punct(p) => p.as_char().to_string(), e => panic!("Expect ident, got {:?}", e), }) .collect::<Vec<_>>(); // 冒号前最后一个 TokenTree 是 field 的名字 // 比如:executable: String, // 注意这里不应该用 name[0],因为有可能是 pub executable: String // 甚至,带 attributes 的 field, // 比如:#[builder(hello = world)] pub executable: String match name.last() { Some(TokenTree::Ident(name)) => { // 如果 ty 第 0 项是 Option,那么从第二项取到倒数第一项 // 取完后上面的例子中的 ty 会变成 ["String"],optiona = true let (ty, optional) = if ty[0].as_str() == "Option" { (&ty[2..ty.len() - 1], true) } else { (&ty[..], false) }; Self { name: name.to_string(), ty: ty.join(""), // 把 ty join 成字符串 optional, } } e => panic!("Expect ident, got {:?}", e), } } } impl BuilderContext { /// 从 TokenStream 中提取信息,构建 BuilderContext fn new(input: TokenStream) -> Self { let (name, input) = split(input); let fields = get_struct_fields(input); Self { builder_name: format!("{}Builder", name), name: name.to_string(), fields, } } /// 把模板渲染成字符串代码 pub fn render(input: TokenStream) -> Result<String> { let template = Self::new(input); Ok(template.render()?) } } /// 把 TokenStream 分出 struct 的名字,和包含 fields 的 TokenStream fn split(input: TokenStream) -> (Ident, TokenStream) { let mut input = input.into_iter().collect::<VecDeque<_>>(); // 一直往后找,找到 struct 停下来 while let Some(item) = input.pop_front() { if let TokenTree::Ident(v) = item { if v.to_string() == "struct" { break; } } } // struct 后面,应该是 struct name let ident; if let Some(TokenTree::Ident(v)) = input.pop_front() { ident = v; } else { panic!("Didn't find struct name"); } // struct 后面可能还有若干 TokenTree,我们不管,一路找到第一个 Group let mut group = None; for item in input { if let TokenTree::Group(g) = item { group = Some(g); break; } } (ident, group.expect("Didn't find field group").stream()) } /// 从包含 fields 的 TokenStream 中切出来一个个 Fd fn get_struct_fields(input: TokenStream) -> Vec<Fd> { let input = input.into_iter().collect::<Vec<_>>(); input .split(|v| match v { // 先用 ',' 切出来一个个包含 field 所有信息的 &[TokenTree] TokenTree::Punct(p) => p.as_char() == ',', _ => false, }) .map(|tokens| { tokens .split(|v| match v { // 再用 ':' 把 &[TokenTree] 切成 [&[TokenTree], &[TokenTree]] // 它们分别对应名字和类型 TokenTree::Punct(p) => p.as_char() == ':', _ => false, }) .collect::<Vec<_>>() }) // 正常情况下,应该得到 [&[TokenTree], &[TokenTree]],对于切出来长度不为 2 的统统过滤掉 .filter(|tokens| tokens.len() == 2) // 使用 Fd::new 创建出每个 Fd .map(|tokens| Fd::new(tokens[0], &tokens[1])) .collect() } }
核心的就是 get_struct_fields() 方法,如果你觉得难懂,可以想想如果你要把一个 a=1,b=2 的字符串切成 [[a, 1], [b, 2]] 该怎么做,就很容易理解了。
好,完成了把 TokenStream 转换成 BuilderContext 的代码, 接下来就是在 proc_macro 中使用这个结构以及它的 render 方法。我们把 lib.rs 中的代码修改一下(注意添加相关的 use):
#![allow(unused)] fn main() { #[proc_macro_derive(RawBuilder)] pub fn derive_raw_builder(input: TokenStream) -> TokenStream { BuilderContext::render(input).unwrap().parse().unwrap() } }
保存后,你立刻会发现,VS Code 抱怨 examples/command.rs 编译不过,因为里面有重复的数据结构和方法的定义。我们把之前手工生成的代码全部删掉,只保留:
use macros::RawBuilder; #[allow(dead_code)] #[derive(Debug, RawBuilder)] pub struct Command { executable: String, args: Vec<String>, env: Vec<String>, current_dir: Option<String>, } fn main() { let command = Command::builder() .executable("cargo".to_owned()) .args(vec!["build".to_owned(), "--release".to_owned()]) .env(vec![]) .build() .unwrap(); assert!(command.current_dir.is_none()); let command = Command::builder() .executable("cargo".to_owned()) .args(vec!["build".to_owned(), "--release".to_owned()]) .env(vec![]) .current_dir("..".to_owned()) .build() .unwrap(); assert!(command.current_dir.is_some()); println!("{:?}", command); }
运行之,我们撰写的 RawBuilder 宏起作用了!代码运行一切正常!
小结
这一讲我们简单介绍了 Rust 宏编程的能力,并撰写了一个声明宏 my_vec! 和一个派生宏 RawBuilder。通过自己手写,核心就是要理解清楚宏做数据转换的方法:如何从 TokenStream 中抽取需要的数据,然后生成包含目标代码的字符串,最后再把字符串转换成 TokenStream。
在构建 RawBuilder 的过程中,我们还了解了 TokenStream 和 TokenTree,虽然这两个数据结构是 Rust 下的结构,但是 token stream / token tree 这样的概念是每个支持宏的语言共有的,如果你理解了 Rust 的宏编程,那么学习其他语言的宏编程就很容易了。
在手写的过程中,你可能会觉得宏编程过于繁琐,这是因为解析 TokenStream 是一个苦力活,要和各种各样的情况打交道,如果处理不好,就很容易出错。
那在Rust生态下有没有人已经做过这个苦力活了呢?我们下节课继续……
思考题
最后出个思考题给你练练手。工作中,有很多场景我们需要通过第三方的 schema 来生成 Rust 数据结构,比如 protobuf 的定义到 Rust struct/enum 的转换。这些转换如果手工撰写的话,是纯粹的体力活,我们可以通过宏来简化这个操作。
假设你的公司维护了大量的 openapi v3 spec,需要你通过它来生成 Rust 类型,比如这里的 schema 定义( 来源):
#![allow(unused)] fn main() { { "type": "object", "properties": { "id": { "type": "integer", "format": "int64" }, "petId": { "type": "integer", "format": "int64" }, "quantity": { "type": "integer", "format": "int32" }, "shipDate": { "type": "string", "format": "date-time" }, "status": { "type": "string", "description": "Order Status", "enum": [ "placed", "approved", "delivered" ] }, "complete": { "type": "boolean", "default": false } }, "xml": { "name": "Order" } } }
你可以试着使用今天所学内容,撰写一个 generate! 宏,接受一个包含 schema 定义的文件名,生成 schema。如果你遇到问题卡壳了,可以参考B站上我live coding的 视频。
欢迎在留言区讨论你的想法,如果觉得有收获,也欢迎你分享给身边的朋友,邀他一起讨论。我们下节课见。
加餐|宏编程(下):用 syn/quote 优雅地构建宏
你好,我是陈天。
上堂课我们用最原始的方式构建了一个 RawBuilder 派生宏,本质就是从 TokenStream 中抽取需要的数据,然后生成包含目标代码的字符串,最后再把字符串转换成 TokenStream。
说到解析 TokenStream 是个苦力活,那么必然会有人做更好的工具。 syn/ quote 这两个库就是Rust宏生态下处理 TokenStream 的解析以及代码生成很好用的库。
今天我们就尝试用这个 syn / quote工具,来构建一个同样的 Builder 派生宏,你可以对比一下两次的具体的实现,感受 syn / quote 构建过程宏的方便之处。
syn crate 简介
先看syn。 syn 是一个对 TokenStream 解析的库,它提供了丰富的数据结构,对语法树中遇到的各种 Rust 语法都有支持。
比如一个 Struct 结构,在 TokenStream 中,看到的就是一系列 TokenTree,而通过 syn 解析后,struct 的各种属性以及它的各个字段,都有明确的类型。这样,我们可以很方便地通过模式匹配来选择合适的类型进行对应的处理。
syn 还提供了对 derive macro 的特殊支持—— DeriveInput 类型:
#![allow(unused)] fn main() { pub struct DeriveInput { pub attrs: Vec<Attribute>, pub vis: Visibility, pub ident: Ident, pub generics: Generics, pub data: Data, } }
通过 DeriveInput 类型,我们可以很方便地解析派生宏。比如这样:
#![allow(unused)] fn main() { #[proc_macro_derive(Builder)] pub fn derive_builder(input: TokenStream) -> TokenStream { // Parse the input tokens into a syntax tree let input = parse_macro_input!(input as DeriveInput); ... } }
只需要使用 parse_macro_input!(input as DeriveInput),我们就不必和 TokenStream 打交道,而是使用解析出来的 DeriveInput。上一讲我们从 TokenStream 里拿出来 struct 的名字,都费了一番功夫,这里直接访问 DeriveInput 的 ident 域就达到同样的目的,是不是非常人性化。
Parse trait
你也许会问:为啥这个 parse_macro_input 有如此魔力?我也可以使用它做类似的解析么?
要回答这个问题,我们直接看代码找答案( 来源):
#![allow(unused)] fn main() { macro_rules! parse_macro_input { ($tokenstream:ident as $ty:ty) => { match $crate::parse_macro_input::parse::<$ty>($tokenstream) { $crate::__private::Ok(data) => data, $crate::__private::Err(err) => { return $crate::__private::TokenStream::from(err.to_compile_error()); } } }; ($tokenstream:ident with $parser:path) => { match $crate::parse::Parser::parse($parser, $tokenstream) { $crate::__private::Ok(data) => data, $crate::__private::Err(err) => { return $crate::__private::TokenStream::from(err.to_compile_error()); } } }; ($tokenstream:ident) => { $crate::parse_macro_input!($tokenstream as _) }; } }
结合上一讲的内容,相信你不难理解,如果我们调用 parse_macro_input!(input as DeriveInput),实际上它执行了 $crate::parse_macro_input::parse::<DeriveInput>(input)。
那么,这个 parse 函数究竟从何而来?继续看代码( 来源):
#![allow(unused)] fn main() { pub fn parse<T: ParseMacroInput>(token_stream: TokenStream) -> Result<T> { T::parse.parse(token_stream) } pub trait ParseMacroInput: Sized { fn parse(input: ParseStream) -> Result<Self>; } impl<T: Parse> ParseMacroInput for T { fn parse(input: ParseStream) -> Result<Self> { <T as Parse>::parse(input) } } }
从这段代码我们得知,任何实现了 ParseMacroInput trait 的类型 T,都支持 parse() 函数。进一步的, 任何 T,只要实现了 Parse trait,就自动实现了 ParseMacroInput trait。
而这个 Parse trait,就是一切魔法背后的源泉:
#![allow(unused)] fn main() { pub trait Parse: Sized { fn parse(input: ParseStream<'_>) -> Result<Self>; } }
syn 下面几乎所有的数据结构都实现了 Parse trait,包括 DeriveInput。所以,如果我们想自己构建一个数据结构,可以通过 parse_macro_input! 宏从 TokenStream 里读取内容,并写入这个数据结构, 最好的方式是为我们的数据结构实现 Parse trait。
关于 Parse trait 的使用,今天就不深入下去了,如果你感兴趣,可以看看 DeriveInput 对 Parse 的实现( 代码)。你也可以进一步看我们前几讲使用过的 sqlx 下的 query! 宏 内部对 Parse trait 的实现。
quote crate 简介
在宏编程的世界里, quote 是一个特殊的原语,它把代码转换成可以操作的数据(代码即数据)。看到这里,你是不是想到了Lisp,是的,quote 这个概念来源于 Lisp,在 Lisp 里, (+ 1 2) 是代码,而 ‘(+ 1 2) 是这个代码 quote 出来的数据。
我们上一讲在生成 TokenStream 的时候,使用的是最原始的把包含代码的字符串转换成 TokenStream 的方法。这种方法虽然可以通过使用模板很好地工作,但在构建代码的过程中,我们操作的数据结构已经失去了语义。
有没有办法让我们就像撰写正常的 Rust 代码一样,保留所有的语义,然后把它们转换成 TokenStream?
有的, 可以使用 quote crate。它提供了一个 quote! 宏,会替换代码中所有的 #(...),生成 TokenStream。比如要写一个 hello() 方法,可以这样:
#![allow(unused)] fn main() { quote! { fn hello() { println!("Hello world!"); } } }
这比使用字符串模板生成代码的方式更直观,功能更强大,而且保留代码的所有语义。
quote! 做替换的方式和 macro_rules! 非常类似,也支持重复匹配,一会在具体写代码的时候可以看到。
用 syn/quote 重写 Builder 派生宏
好,现在我们对 sync/quote 有了一个粗浅的认识,接下来就照例通过撰写代码更好地熟悉它们的功能。
怎么做,经过昨天的学习,相信你现在也比较熟悉了,大致就是 先从 TokenStream 抽取需要的数据,再通过模板,把抽取出来的数据转换成目标代码(TokenStream)。
由于 syn/quote 生成的 TokenStream 是 proc-macro2 的类型,所以我们还需要使用这个库,简单说明一下proc-macro2,它是对 proc-macro 的简单封装,使用起来更方便,而且可以让过程宏可以单元测试。
我们在上一讲中创建的项目中添加更多的依赖:
#![allow(unused)] fn main() { [dependencies] anyhow = "1" askama = "0.11" # 处理 jinjia 模板,模板需要放在和 src 平行的 templates 目录下 proc-macro2 = "1" # proc-macro 的封装 quote = "1" # 用于生成代码的 TokenStream syn = { version = "1", features = ["extra-traits"] } # 用于解析 TokenStream,使用 extra-traits 可以用于 Debug }
注意 syn crate 默认所有数据结构都不带一些基本的 trait,比如 Debug,所以如果你想打印数据结构的话,需要使用 extra-traits feature。
Step1:看看 DeriveInput 都输出什么?
在 lib.rs 中,先添加新的 Builder 派生宏:
#![allow(unused)] fn main() { use syn::{parse_macro_input, DeriveInput}; #[proc_macro_derive(Builder)] pub fn derive_builder(input: TokenStream) -> TokenStream { let input = parse_macro_input!(input as DeriveInput); println!("{:#?}", input); TokenStream::default() } }
通过 parse_macro_input!,我们得到了一个 DeriveInput 结构的数据。这里可以打印一下,看看会输出什么。
所以在 examples/command.rs 中,先为 Command 引入 Builder 宏:
#![allow(unused)] fn main() { use macros::{Builder, RawBuilder}; #[allow(dead_code)] #[derive(Debug, RawBuilder, Builder)] pub struct Command { executable: String, args: Vec<String>, env: Vec<String>, current_dir: Option<String>, } }
然后运行 cargo run --example command,就可以看到非常详尽的 DeriveInput 的输出:
- 对于 struct name,可以直接从 ident 中获取
- 对于 fields,需要从 data 内部的 DataStruct { fields } 中取。目前,我们只关心每个 field 的 ident 和 ty。
Step2:定义自己的用于处理 derive 宏的数据结构
和上一讲一样,我们需要定义一个数据结构,来获取构建 TokenStream 用到的信息。
所以对比着上一讲,可以定义如下数据结构:
#![allow(unused)] fn main() { struct Fd { name: Ident, ty: Type, optional: bool, } pub struct BuilderContext { name: Ident, fields: Vec<Fd>, } }
Step3:把 DeriveInput 转换成自己的数据结构
接下来要做的,就是把 DeriveInput 转换成我们需要的 BuilderContext。
所以来写两个 From trait 的实现,分别把 Field 转换成 Fd,DeriveInput 转换成 BuilderContext:
#![allow(unused)] fn main() { /// 把一个 Field 转换成 Fd impl From<Field> for Fd { fn from(f: Field) -> Self { let (optional, ty) = get_option_inner(f.ty); Self { // 此时,我们拿到的是 NamedFields,所以 ident 必然存在 name: f.ident.unwrap(), optional, ty, } } } /// 把 DeriveInput 转换成 BuilderContext impl From<DeriveInput> for BuilderContext { fn from(input: DeriveInput) -> Self { let name = input.ident; let fields = if let Data::Struct(DataStruct { fields: Fields::Named(FieldsNamed { named, .. }), .. }) = input.data { named } else { panic!("Unsupported data type"); }; let fds = fields.into_iter().map(Fd::from).collect(); Self { name, fields: fds } } } // 如果是 T = Option<Inner>,返回 (true, Inner);否则返回 (false, T) fn get_option_inner(ty: Type) -> (bool, Type) { todo!() } }
是不是简单的有点难以想象?
注意在从 input 中获取 fields 时,我们用了一个嵌套很深的模式匹配:
#![allow(unused)] fn main() { if let Data::Struct(DataStruct { fields: Fields::Named(FieldsNamed { named, .. }), .. }) = input.data { named } }
如果没有强大的模式匹配的支持,获取 FieldsNamed 会是非常冗长的代码。你可以仔细琢磨这两个 From 的实现,它很好地体现了 Rust 的优雅。
在处理 Option 类型的时候,我们用了一个还不存在的函数 get_option_inner(),这样一个函数是为了实现,如果是 T = Option,就返回 (true, Inner),否则返回 (false, T)。
Step4:使用 quote 生成代码
准备好 BuilderContext,就可以生成代码了。来写一个 render() 方法:
#![allow(unused)] fn main() { impl BuilderContext { pub fn render(&self) -> TokenStream { let name = &self.name; // 生成 XXXBuilder 的 ident let builder_name = Ident::new(&format!("{}Builder", name), name.span()); let optionized_fields = self.gen_optionized_fields(); let methods = self.gen_methods(); let assigns = self.gen_assigns(); quote! { /// Builder 结构 #[derive(Debug, Default)] struct #builder_name { (#optionized_fields,)* } /// Builder 结构每个字段赋值的方法,以及 build() 方法 impl #builder_name { (#methods)* pub fn build(mut self) -> Result<#name, &'static str> { Ok(#name { (#assigns,)* }) } } /// 为使用 Builder 的原结构提供 builder() 方法,生成 Builder 结构 impl #name { fn builder() -> #builder_name { Default::default() } } } } // 为 XXXBuilder 生成 Option<T> 字段 // 比如:executable: String -> executable: Option<String> fn gen_optionized_fields(&self) -> Vec<TokenStream> { todo!(); } // 为 XXXBuilder 生成处理函数 // 比如:methods: fn executable(mut self, v: impl Into<String>) -> Self { self.executable = Some(v); self } fn gen_methods(&self) -> Vec<TokenStream> { todo!(); } // 为 XXXBuilder 生成相应的赋值语句,把 XXXBuilder 每个字段赋值给 XXX 的字段 // 比如:#field_name: self.#field_name.take().ok_or(" xxx need to be set!") fn gen_assigns(&self) -> Vec<TokenStream> { todo!(); } } }
可以看到, quote! 包裹的代码,和上一讲在 template 中写的代码非常类似,只不过循环的地方使用了 quote! 内部的重复语法 #(...)*。
到目前为止,虽然我们的代码还不能运行,但完整的从 TokenStream 到 TokenStream 转换的骨架已经完成,剩下的只是实现细节而已,你可以试着自己实现。
Step5:完整实现
好,我们创建 src/builder.rs 文件(记得在 src/lib.rs 里引入),然后写入代码:
#![allow(unused)] fn main() { use proc_macro2::{Ident, TokenStream}; use quote::quote; use syn::{ Data, DataStruct, DeriveInput, Field, Fields, FieldsNamed, GenericArgument, Path, Type, TypePath, }; /// 我们需要的描述一个字段的所有信息 struct Fd { name: Ident, ty: Type, optional: bool, } /// 我们需要的描述一个 struct 的所有信息 pub struct BuilderContext { name: Ident, fields: Vec<Fd>, } /// 把一个 Field 转换成 Fd impl From<Field> for Fd { fn from(f: Field) -> Self { let (optional, ty) = get_option_inner(&f.ty); Self { // 此时,我们拿到的是 NamedFields,所以 ident 必然存在 name: f.ident.unwrap(), optional, ty: ty.to_owned(), } } } /// 把 DeriveInput 转换成 BuilderContext impl From<DeriveInput> for BuilderContext { fn from(input: DeriveInput) -> Self { let name = input.ident; let fields = if let Data::Struct(DataStruct { fields: Fields::Named(FieldsNamed { named, .. }), .. }) = input.data { named } else { panic!("Unsupported data type"); }; let fds = fields.into_iter().map(Fd::from).collect(); Self { name, fields: fds } } } impl BuilderContext { pub fn render(&self) -> TokenStream { let name = &self.name; // 生成 XXXBuilder 的 ident let builder_name = Ident::new(&format!("{}Builder", name), name.span()); let optionized_fields = self.gen_optionized_fields(); let methods = self.gen_methods(); let assigns = self.gen_assigns(); quote! { /// Builder 结构 #[derive(Debug, Default)] struct #builder_name { (#optionized_fields,)* } /// Builder 结构每个字段赋值的方法,以及 build() 方法 impl #builder_name { (#methods)* pub fn build(mut self) -> Result<#name, &'static str> { Ok(#name { (#assigns,)* }) } } /// 为使用 Builder 的原结构提供 builder() 方法,生成 Builder 结构 impl #name { fn builder() -> #builder_name { Default::default() } } } } // 为 XXXBuilder 生成 Option<T> 字段 // 比如:executable: String -> executable: Option<String> fn gen_optionized_fields(&self) -> Vec<TokenStream> { self.fields .iter() .map(|Fd { name, ty, .. }| quote! { #name: std::option::Option<#ty> }) .collect() } // 为 XXXBuilder 生成处理函数 // 比如:methods: fn executable(mut self, v: impl Into<String>) -> Self { self.executable = Some(v); self } fn gen_methods(&self) -> Vec<TokenStream> { self.fields .iter() .map(|Fd { name, ty, .. }| { quote! { pub fn #name(mut self, v: impl Into<#ty>) -> Self { self.#name = Some(v.into()); self } } }) .collect() } // 为 XXXBuilder 生成相应的赋值语句,把 XXXBuilder 每个字段赋值给 XXX 的字段 // 比如:#field_name: self.#field_name.take().ok_or(" xxx need to be set!") fn gen_assigns(&self) -> Vec<TokenStream> { self.fields .iter() .map(|Fd { name, optional, .. }| { if *optional { return quote! { name: self.#name.take() }; } quote! { name: self.#name.take().ok_or(concat!(stringify!(#name), " needs to be set!"))? } }) .collect() } } // 如果是 T = Option<Inner>,返回 (true, Inner);否则返回 (false, T) fn get_option_inner(ty: &Type) -> (bool, &Type) { // 首先模式匹配出 segments if let Type::Path(TypePath { path: Path { segments, .. }, .. }) = ty { if let Some(v) = segments.iter().next() { if v.ident == "Option" { // 如果 PathSegment 第一个是 Option,那么它内部应该是 AngleBracketed,比如 <T> // 获取其第一个值,如果是 GenericArgument::Type,则返回 let t = match &v.arguments { syn::PathArguments::AngleBracketed(a) => match a.args.iter().next() { Some(GenericArgument::Type(t)) => t, _ => panic!("Not sure what to do with other GenericArgument"), }, _ => panic!("Not sure what to do with other PathArguments"), }; return (true, t); } } } return (false, ty); } }
这段代码仔细阅读的话并不难理解,可能 get_option_inner() 拗口一些。你需要对着 DeriveInput 的 Debug 信息对应的部分比对着看,去推敲如何做模式匹配。比如:
#![allow(unused)] fn main() { ty: Path( TypePath { qself: None, path: Path { leading_colon: None, segments: [ PathSegment { ident: Ident { ident: "Option", span: #0 bytes(201..207), }, arguments: AngleBracketed( AngleBracketedGenericArguments { colon2_token: None, lt_token: Lt, args: [ Type( Path( TypePath { qself: None, path: Path { leading_colon: None, segments: [ PathSegment { ident: Ident { ident: "String", span: #0 bytes(208..214), }, arguments: None, }, ], }, }, ), ), ], gt_token: Gt, }, ), }, ], }, }, ), }
这本身并不难,难的是心细以及足够的耐心。如果你对某个数据结构拿不准该怎么匹配,可以在 syn 的文档中查找这个数据结构,了解它的定义。
好,如果你理解了这个代码,我们就可以更新 src/lib.rs 里定义的 derive_builder 了:
#![allow(unused)] fn main() { #[proc_macro_derive(Builder)] pub fn derive_builder(input: TokenStream) -> TokenStream { let input = parse_macro_input!(input as DeriveInput); builder::BuilderContext::from(input).render().into() } }
可以直接从 DeriveInput 中生成一个 BuilderContext,然后 render()。注意 quote 得到的是 proc_macro2::TokenStream,所以需要调用一下 into() 转换成 proc_macro::TokenStream。
在 examples/command.rs 中,更新 Command 的 derive 宏:
#![allow(unused)] fn main() { use macros::Builder; #[allow(dead_code)] #[derive(Debug, Builder)] pub struct Command { ... } }
运行之,你可以得到正确的结果。
one more thing:支持 attributes
很多时候,我们的派生宏可能还需要一些额外的 attributes 来提供更多信息,更好地指导代码的生成。比如 serde,你可以在数据结构中加入 #[serde(xxx)] attributes,控制 serde 序列化/反序列化的行为。
现在我们的 Builder 宏支持基本的功能,但用着还不那么特别方便,比如对于类型是 Vec 的 args,如果我可以依次添加每个 arg,该多好?
在 proc-macro-workshop 里 Builder 宏的第 7 个练习 中,就有这样一个需求:
#[derive(Builder)] pub struct Command { executable: String, #[builder(each = "arg")] args: Vec<String>, #[builder(each = "env")] env: Vec<String>, current_dir: Option<String>, } fn main() { let command = Command::builder() .executable("cargo".to_owned()) .arg("build".to_owned()) .arg("--release".to_owned()) .build() .unwrap(); assert_eq!(command.executable, "cargo"); assert_eq!(command.args, vec!["build", "--release"]); }
这里,如果字段定义了 builder attributes,并且提供了 each 参数,那么用户不断调用 arg 来依次添加参数。这样使用起来,直观多了。
分析一下这个需求。想要支持这样的功能,首先要能够解析 attributes,然后要能够根据 each attribute 的内容生成对应的代码,比如这样:
#![allow(unused)] fn main() { pub fn arg(mut self, v: String) -> Self { let mut data = self.args.take().unwrap_or_default(); data.push(v); self.args = Some(data); self } }
syn 提供的 DeriveInput 并没有对 attributes 额外处理,所有的 attributes 被包裹在一个 TokenTree::Group 中。
我们可以用上一讲提到的方法,手工处理 TokenTree/TokenStream,不过这样太麻烦,社区里已经有一个非常棒的库叫 darling,光是名字就听上去惹人喜爱,用起来更是让人爱不释手。我们就使用这个库,来为 Builder 宏添加对 attributes 的支持。
为了避免对之前的 Builder 宏的破坏,我们把 src/builder.rs 拷贝一份出来改名 src/builder_with_attr.rs,然后在 src/lib.rs 中引用它。
在 src/lib.rs 中,我们再创建一个 BuilderWithAttrs 的派生宏:
#![allow(unused)] fn main() { #[proc_macro_derive(BuilderWithAttr, attributes(builder))] pub fn derive_builder_with_attr(input: TokenStream) -> TokenStream { let input = parse_macro_input!(input as DeriveInput); builder_with_attr::BuilderContext::from(input) .render() .into() } }
和之前不同的是,这里多了一个 attributes(builder) 属性,这是告诉编译器,请允许代码中出现的 #[builder(...)],它是我这个宏认识并要处理的。
再创建一个 examples/command_with_attr.rs,把 workshop 中的代码粘进去并适当修改:
use macros::BuilderWithAttr; #[allow(dead_code)] #[derive(Debug, BuilderWithAttr)] pub struct Command { executable: String, #[builder(each = "arg")] args: Vec<String>, #[builder(each = "env", default="vec![]")] env: Vec<String>, current_dir: Option<String>, } fn main() { let command = Command::builder() .executable("cargo".to_owned()) .arg("build".to_owned()) .arg("--release".to_owned()) .build() .unwrap(); assert_eq!(command.executable, "cargo"); assert_eq!(command.args, vec!["build", "--release"]); println!("{:?}", command); }
这里,我们不仅希望支持 each 属性,还支持 default —— 如果用户没有为这个域提供数据,就使用 default 对应的代码来初始化。
这个代码目前会报错,因为并未为 CommandBuilder 添加 arg 方法。接下来我们就要实现这个功能。
在 Cargo.toml 中,加入对 darling 的引用:
#![allow(unused)] fn main() { [dependencies] darling = "0.13" }
然后,在 src/builder_with_attr.rs 中,添加用于捕获 attributes 的数据结构:
#![allow(unused)] fn main() { use darling::FromField; #[derive(Debug, Default, FromField)] #[darling(default, attributes(builder))] struct Opts { each: Option<String>, default: Option<String>, } }
因为我们捕获的是 field 级别的 attributes,所以这个数据结构需要实现 FromField trait(通过 FromTrait 派生宏),并且告诉 darling 要从哪个 attributes 中捕获(这里是从 builder 中捕获)。
不过先需要修改一下 Fd,让它包括 Opts,并且在 From 的实现中初始化 opts:
#![allow(unused)] fn main() { /// 我们需要的描述一个字段的所有信息 struct Fd { name: Ident, ty: Type, optional: bool, opts: Opts, } /// 把一个 Field 转换成 Fd impl From<Field> for Fd { fn from(f: Field) -> Self { let (optional, ty) = get_option_inner(&f.ty); // 从 Field 中读取 attributes 生成 Opts,如果没有使用缺省值 let opts = Opts::from_field(&f).unwrap_or_default(); Self { opts, // 此时,我们拿到的是 NamedFields,所以 ident 必然存在 name: f.ident.unwrap(), optional, ty: ty.to_owned(), } } } }
好,现在 Fd 就包含 Opts 的信息了,我们可以利用这个信息来生成 methods 和 assigns。
接下来先看 gen_methods 怎么修改。如果 Fd 定义了 each attribute,且它是个 Vec 的话,我们就生成不一样的代码,否则的话,像之前那样生成代码。来看实现:
#![allow(unused)] fn main() { // 为 XXXBuilder 生成处理函数 // 比如:methods: fn executable(mut self, v: impl Into<String>) -> Self { self.executable = Some(v); self } fn gen_methods(&self) -> Vec<TokenStream> { self.fields .iter() .map(|f| { let name = &f.name; let ty = &f.ty; // 如果不是 Option 类型,且定义了 each attribute if !f.optional && f.opts.each.is_some() { let each = Ident::new(f.opts.each.as_deref().unwrap(), name.span()); let (is_vec, ty) = get_vec_inner(ty); if is_vec { return quote! { pub fn #each(mut self, v: impl Into<#ty>) -> Self { let mut data = self.#name.take().unwrap_or_default(); data.push(v.into()); self.#name = Some(data); self } }; } } quote! { pub fn #name(mut self, v: impl Into<#ty>) -> Self { self.#name = Some(v.into()); self } } }) .collect() } }
这里,我们重构了一下 get_option_inner() 的代码,因为 get_vec_inner() 和它有相同的逻辑:
#![allow(unused)] fn main() { // 如果是 T = Option<Inner>,返回 (true, Inner);否则返回 (false, T) fn get_option_inner(ty: &Type) -> (bool, &Type) { get_type_inner(ty, "Option") } // 如果是 T = Vec<Inner>,返回 (true, Inner);否则返回 (false, T) fn get_vec_inner(ty: &Type) -> (bool, &Type) { get_type_inner(ty, "Vec") } fn get_type_inner<'a>(ty: &'a Type, name: &str) -> (bool, &'a Type) { // 首先模式匹配出 segments if let Type::Path(TypePath { path: Path { segments, .. }, .. }) = ty { if let Some(v) = segments.iter().next() { if v.ident == name { // 如果 PathSegment 第一个是 Option/Vec 等类型,那么它内部应该是 AngleBracketed,比如 <T> // 获取其第一个值,如果是 GenericArgument::Type,则返回 let t = match &v.arguments { syn::PathArguments::AngleBracketed(a) => match a.args.iter().next() { Some(GenericArgument::Type(t)) => t, _ => panic!("Not sure what to do with other GenericArgument"), }, _ => panic!("Not sure what to do with other PathArguments"), }; return (true, t); } } } return (false, ty); } }
最后,我们为 gen_assigns() 提供对 default attribute 的支持:
#![allow(unused)] fn main() { fn gen_assigns(&self) -> Vec<TokenStream> { self.fields .iter() .map(|Fd { name, optional, opts, .. }| { if *optional { return quote! { name: self.#name.take() }; } // 如果定义了 default,那么把 default 里的字符串转换成 TokenStream // 使用 unwrap_or_else 在没有值的时候,使用缺省的结果 if let Some(default) = opts.default.as_ref() { let ast: TokenStream = default.parse().unwrap(); return quote! { name: self.#name.take().unwrap_or_else(|| #ast) }; } quote! { name: self.#name.take().ok_or(concat!(stringify!(#name), " needs to be set!"))? } }) .collect() } }
如果你完成了这些改动,运行 cargo run --example command_with_attr 就会得到正确的结果。完整的代码,可以去 GitHub repo 上获取。
小结
这一讲我们使用 syn/quote 重写了 Builder 派生宏的功能。可以看到,使用 syn/quote 后,宏的开发变得简单很多,最后我们还用 darling 进一步提供了对 attributes 的支持。
虽然这两讲我们只做了派生宏和一个非常简单的函数宏,但是,如果你学会了最复杂的派生宏,那开发函数宏和属性宏也不在话下。另外,darling 对 attributes 的支持,同样也可以应用在属性宏中。
今天重写Builder中核心做的就是,我们定义了两个自己的 From
使用宏来生成代码虽然听上去很牛,写起来也很有成就感,但是切不可滥用。凡事都有两面,强大和灵活多变的对立面就是危险和难以捉摸。
因为虽然撰写宏并不困难,宏会为别人理解你的代码,使用你的代码带来额外的负担。由于宏会生成代码,大量使用宏会让你的代码在不知不觉中膨胀,也会导致二进制很大。另外,正如我们在使用中发现的那样,目前 IDE 对宏的支持还不够好,这也是大量使用宏的一个问题。我们看到像 nom 这样的工具,一开始大量使用宏,后来也都逐渐用函数取代。
所以在开发的时候,要非常谨慎地构建宏。多问自己:我非用宏不可么?可以使用别的设计来避免使用宏么?同样是 Web 框架,rocket 使用宏做路由,axum 完全不使用宏。
就像 unsafe 一样,我们要把宏编程作为撰写代码最后的手段。 当一个功能可以用函数表达时,不要用宏。不要过分迷信于编译时的处理,不要把它当成提高性能的手段。如果你发现某个设计似乎不得不使用宏,你需要质疑一下,自己设计上的选择是否正确。
思考题
学完了这两课,如果你还觉得不过瘾,可以继续完成 proc-macro-workshop 里Builder 以外的其它例子。这些例子你耐心地把它们全做一遍,一定会有很大的收获。
学习愉快,如果你觉得有收获,也欢迎你分享给你身边的朋友,邀他一起讨论。
结束语|永续之原:Rust学习,如何持续精进?
你好,我是陈天。
首先,恭喜你完成了这门课程!
六月底,我确定了自己会在极客时间上出这个 Rust 的专栏。
其实以前我对这样子的付费课程不是太感冒,因为自己随性惯了,写公众号自由洒脱,想写就写,想停就停,一个主题写腻了还可以毫无理由地切换到另一个主题上。但一旦写付费的专栏签下合同,就意味着品味、质量、内容以及更新的速度都不能随心所欲,得按照人家的要求来。
最要命的是更新的速度——我没有专职做过文字工作者,想来和代码工作者性质类似,一些开创性工作的开始特别需要灵感,非常依赖妙手偶得的那个契机。这种不稳定的输出模式,遇到进度的压力,就很折磨人。所以之前很多机会我都婉拒了。
但这次思来想去,我还是接下了 Rust 第一课这个挑战。
大部分原因是我越来越喜爱 Rust 这门语言,想让更多的人也能爱上它,于是之前在公众号和 B 站上,也做了不少输出。但这样的输出,左一块右一块的,没有一个完整的体系,所以有这样一个机会,来构建出我个人总结的Rust学习体系,也许对大家的学习会有很大的帮助。
另外一部分原因也是出于我的私心。自从 2016 年《途客圈创业记》出版后,我就没有正式出版过东西,很多口头答应甚至签下合同的选题,也都因为各种原因被我终止或者搁置了。我特别想知道,自己究竟是否还能拿起笔写下严肃的可以流传更广、持续更久的文字。
可是—— 介绍一门语言的文字可以有持久的生命力么?
你一定有这个疑问。
撰写介绍一门编程语言的文字,却想让它拥有持久的生命力,这听上去似乎是痴人说梦。现代编程语言的进化速度相比二十年前,可谓是一日千里。就拿 Rust 来说,稳定的六周一个版本,三年一个版次,别说是拥有若干年的生命力了,就算是专栏连载的几个月,都会过去两三个版本,也就意味着有不少新鲜的东西被加入到语言中。
不过好在 Rust 极其注重向后兼容,也就意味着我现在介绍的代码,只要是 Rust 语言或者标准库中稳定的内容,若干年后(应该)还是可以有效的。Rust 这种不停迭代却一直保持向后兼容的做法,让它相对于其它语言在教学上有一些优势,所以,撰写介绍 Rust 的文字,生命力会更加持久一些。
当然这还远远不够。让介绍一门编程语言的文字更持久的方式就是, 从本原出发,帮助大家理解语言表层概念背后的思想或者机理, 这也是这个专栏最核心的设计思路。
通用型计算机诞生后差不多七十年了,当时的冯诺依曼结构依然有效;从 C 语言诞生到现在也有快五十年了,编程语言处理内存的方式还是堆和栈,常用的算法和数据结构也还是那些。虽然编程语言在不断进化,但解决问题的主要手段还都是差不多的。
比如说,引用计数,你如果在之前学习的任何一门语言中弄明白了它的思路,那么理解 Rust 下的 Rc/Arc 也不在话下。所以,只要我们把基础知识夯实,很多看似难懂的问题,只不过是在同样本质上套了让人迷惑的外衣而已。
那么如何拨开迷雾抵达事物的本原呢?我的方法有两个: 一曰问,二曰切。对,就是中医“望闻问切”后两个字。
问就是刨根追底,根据已有的认知,发出直击要害的疑问,这样才能为后续的探索(切)叩开大门。比如你知道引用计数通行的实现方法,也知道 Rust 的单一所有权机制把堆内存的生命周期和栈内存绑定在一起,栈在值在,栈亡值亡。
那么你稍微思考一下就会产生疑问:Rc/Arc 又是怎么打破单一所有权机制,做到让堆上的内存跳脱了栈上内存的限制呢?问了这个问题,你就有机会往下“切”。
“切”是什么呢,就是深入查看源代码,顺着脉络找出问题的答案。初学者往往不看标准库的源码,实际上,看源代码是最能帮助你成长的。无论是学习一门语言,还是学习 Linux 内核或者别的什么,源码都是第一手资料。别人的分析讲得再好,也是嚼过的饭,受限于他的理解能力和表达能力,这口嚼过的饭还真不一定比你自己亲自上嘴更好下咽。
比如想知道上面Rc/Arc的问题,自然要看 Rc::new 的源码实现:
#![allow(unused)] fn main() { pub fn new(value: T) -> Rc<T> { // There is an implicit weak pointer owned by all the strong // pointers, which ensures that the weak destructor never frees // the allocation while the strong destructor is running, even // if the weak pointer is stored inside the strong one. Self::from_inner( Box::leak(box RcBox { strong: Cell::new(1), weak: Cell::new(1), value }).into(), ) } }
不看不知道,一看吓一跳。可疑的 Box::leak 出现在我们眼前。这个 Box::leak 又是干什么的呢?顺着这个线索追溯下去,我们发现了一个宝贵的金矿(你可以回顾生命周期的那一讲)。
思
在追溯本原的基础上,我们还要学会分析问题和解决问题的正确方法。我觉得编程语言的学习不应该只局限于学习语法本身,更应该在这个过程中,不断提升自己学习知识和处理问题的能力。
如果你还记得 HashMap 那一讲,我们先是宏观介绍解决哈希冲突的主要思路,它是构建哈希表的核心算法;然后使用 transmute 来了解 Rust HashMap 的组织结构,通过 gdb 查看内存布局,再结合代码去找到 HashMap 构建和扩容的具体思路。
这样 一层层剥茧抽丝,边学习,边探索,边总结,最终我们得到了对 Rust 哈希表非常扎实的掌握。这种掌握程度,哪怕你十年都不碰 Rust,十年后有人问你 Rust 的哈希表怎么工作的,你也能回答个八九不离十。
我希望你能够掌握这种学习的方式,这是终生受益的方式。2006 年,我在 Juniper 工作时,用类似的方式,把 ScreenOS 系统的数据平面的处理流程总结出来了,到现在很多细节我记忆犹新。
很多时候面试一些同学,详细询问他们三五年前设计和实现过的一些项目时,他们会答不上来,经常给出“这个项目太久了,我记不太清楚”这样的答复,让我觉得好奇怪。对我而言,只要是做过的项目、阅读过的代码,不管多久,都能回忆起很多细节,就好像它们是自己的一部分一样。
尽管快有 20 年没有碰,我还记得第一份工作中 OSPFv2 和 IGMPv3 协议的部分细节,知道 netlink 如何工作,也对 Linux VMM 管理的流程有一个基本印象。现在想来,可能就是我掌握了正确的学习方法而已。
所以,在这门介绍语言的课程中,我还夹带了很多方法论相关的私货,它们大多散落在文章的各个角落,除了刚刚谈到的分析问题/解决问题的方法外,还有阅读代码的方法、架构设计的方法、撰写和迭代接口的方法、撰写测试的方法、代码重构的方法等等。希望这些私货能够让你产生共鸣,结合你自己在职业生涯中总结出来的方法,更好地服务于你的学习和工作。
读
在撰写这个专栏的过程中,我参考了不少书籍。比如《Programming Rust》、《Designing Data-intensive Applications》以及《Fundamentals of Software Architecture》。可惜 Jon Gjengset 的《Rust for Rustaceans》姗姗来迟,否则这个专栏的水准可以更上一个台阶。
我们做软件开发的,似乎到了一定年纪就不怎么阅读,这样不好。毕加索说:“good artists copy; great artists steal.”当你从一个人身上学习时,你在模仿;当你从一大群人身上学习时,你自己就慢慢融会贯通,成为大师。
所以,不要指望学了这门Rust 第一课,就大功告成, 这门课仅仅是一个把你接引至 Rust 世界的敲门砖,接下来你还要进一步从各个方面学习和夯实更多的知识。
就像我回答一个读者的问题所说的:很多时候,我们缺乏的不是对 Rust 知识的理解,更多是对软件开发更广阔知识的理解。所以,不要拘泥于 Rust 本身,对你自己感兴趣的,以及你未来会涉猎的场景广泛阅读、深度思考。
行
伴随着学习,阅读,思考,我们还要广泛地实践。不要一有问题就求助,想想看,自己能不能构造足够简单的代码来帮助解决问题。
比如有人问:HTTP/2 是怎么工作的?这样的问题,你除了可以看 RFC,阅读别人总结的经验,还可以动动手,几行代码就可以获得很多信息。比如:
use tracing::info; use tracing_subscriber::EnvFilter; fn main() { tracing_subscriber::fmt::fmt() .with_env_filter(EnvFilter::from_default_env()) .init(); let url = "<https://www.rust-lang.org/>"; let _body = reqwest::blocking::get(url).unwrap().text().unwrap(); info!("Fetching url: {}", url); }
这段代码相信你肯定能写得出来,但你是否尝试过 RUST_LOG=debug 甚至 RUST_LOG=trace 来看看输出的日志呢?又有没有尝试着顺着日志的脉络,去分析涉及的库呢?
下面是这几行代码 RUST_LOG=debug 的输出,可以让你看到 HTTP/2 基本的运作方式,我建议你试试 RUST_LOG=trace(内容太多就不贴了),如果你能搞清楚输出的信息,那么 Rust 下用 hyper 处理 HTTP/2 的主流程你就比较明白了。
#![allow(unused)] fn main() { ❯ RUST_LOG=debug cargo run --quiet 2021-12-12T21:28:00.612897Z DEBUG reqwest::connect: starting new connection: <https://www.rust-lang.org/> 2021-12-12T21:28:00.613124Z DEBUG hyper::client::connect::dns: resolving host="www.rust-lang.org" 2021-12-12T21:28:00.629392Z DEBUG hyper::client::connect::http: connecting to 13.224.7.43:443 2021-12-12T21:28:00.641156Z DEBUG hyper::client::connect::http: connected to 13.224.7.43:443 2021-12-12T21:28:00.641346Z DEBUG rustls::client::hs: No cached session for DnsName(DnsName(DnsName("www.rust-lang.org"))) 2021-12-12T21:28:00.641683Z DEBUG rustls::client::hs: Not resuming any session 2021-12-12T21:28:00.656251Z DEBUG rustls::client::hs: Using ciphersuite Tls13(Tls13CipherSuite { suite: TLS13_AES_128_GCM_SHA256, bulk: Aes128Gcm }) 2021-12-12T21:28:00.656754Z DEBUG rustls::client::tls13: Not resuming 2021-12-12T21:28:00.657046Z DEBUG rustls::client::tls13: TLS1.3 encrypted extensions: [ServerNameAck, Protocols([PayloadU8([104, 50])])] 2021-12-12T21:28:00.657151Z DEBUG rustls::client::hs: ALPN protocol is Some(b"h2") 2021-12-12T21:28:00.658435Z DEBUG h2::client: binding client connection 2021-12-12T21:28:00.658526Z DEBUG h2::client: client connection bound 2021-12-12T21:28:00.658602Z DEBUG h2::codec::framed_write: send frame=Settings { flags: (0x0), enable_push: 0, initial_window_size: 2097152, max_frame_size: 16384 } 2021-12-12T21:28:00.659062Z DEBUG Connection{peer=Client}: h2::codec::framed_write: send frame=WindowUpdate { stream_id: StreamId(0), size_increment: 5177345 } 2021-12-12T21:28:00.659327Z DEBUG hyper::client::pool: pooling idle connection for ("https", www.rust-lang.org) 2021-12-12T21:28:00.659674Z DEBUG Connection{peer=Client}: h2::codec::framed_write: send frame=Headers { stream_id: StreamId(1), flags: (0x5: END_HEADERS | END_STREAM) } 2021-12-12T21:28:00.672087Z DEBUG Connection{peer=Client}: h2::codec::framed_read: received frame=Settings { flags: (0x0), max_concurrent_streams: 128, initial_window_size: 65536, max_frame_size: 16777215 } 2021-12-12T21:28:00.672173Z DEBUG Connection{peer=Client}: h2::codec::framed_write: send frame=Settings { flags: (0x1: ACK) } 2021-12-12T21:28:00.672244Z DEBUG Connection{peer=Client}: h2::codec::framed_read: received frame=WindowUpdate { stream_id: StreamId(0), size_increment: 2147418112 } 2021-12-12T21:28:00.672308Z DEBUG Connection{peer=Client}: h2::codec::framed_read: received frame=Settings { flags: (0x1: ACK) } 2021-12-12T21:28:00.672351Z DEBUG Connection{peer=Client}: h2::proto::settings: received settings ACK; applying Settings { flags: (0x0), enable_push: 0, initial_window_size: 2097152, max_frame_size: 16384 } 2021-12-12T21:28:00.956751Z DEBUG Connection{peer=Client}: h2::codec::framed_read: received frame=Headers { stream_id: StreamId(1), flags: (0x4: END_HEADERS) } 2021-12-12T21:28:00.956921Z DEBUG Connection{peer=Client}: h2::codec::framed_read: received frame=Data { stream_id: StreamId(1) } 2021-12-12T21:28:00.957015Z DEBUG Connection{peer=Client}: h2::codec::framed_read: received frame=Data { stream_id: StreamId(1) } 2021-12-12T21:28:00.957079Z DEBUG Connection{peer=Client}: h2::codec::framed_read: received frame=Data { stream_id: StreamId(1) } 2021-12-12T21:28:00.957316Z DEBUG reqwest::async_impl::client: response '200 OK' for <https://www.rust-lang.org/> 2021-12-12T21:28:01.018665Z DEBUG Connection{peer=Client}: h2::codec::framed_read: received frame=Data { stream_id: StreamId(1) } 2021-12-12T21:28:01.018885Z DEBUG Connection{peer=Client}: h2::codec::framed_read: received frame=Data { stream_id: StreamId(1), flags: (0x1: END_STREAM) } 2021-12-12T21:28:01.020158Z INFO http2: Fetching url: <https://www.rust-lang.org/> }
所以,很多时候,知识就在我们身边,我们写一写代码就能获取。
在这个过程中,你自己思考之后撰写的探索性的代码、你分析输出过程中付出的思考和深度的阅读,以及最后在梳理过程中进行的总结,都会让知识牢牢变成你自己的。
最后我们聊一聊写代码这个事。
学习任何语言,最重要的步骤都是用学到的知识,解决实际的问题。Rust 能不能胜任你需要完成的各种任务?大概率能。但你能不能用 Rust 来完成这些任务?不一定。每个十指俱全的人都能学习弹钢琴,但不是每个学弹钢琴的人都能达到十级的水平。这其中现实和理想间巨大的鸿沟就是“刻意练习”。
想要成为 Rust 专家,想让 Rust 成为你职业生涯中的一项重要技能,刻意练习必不可少,需要不断地撰写代码。的确,Rust 的所有权和生命周期学习和使用起来让人难于理解,所有权、生命周期,跟类型系统(包括泛型、trait),以及异步开发结合起来,更是障碍重重,但通过不断学习和不断练习,你一定会发现,它们不过是你的一段伟大旅程中越过的一个小山丘而已。
最后的最后,估计很多同学都是在艰难斗争、默默学习,在专栏要结束的今天,欢迎你在留言区留言,我非常希望能听到你的声音,听听你学习这个专栏的感受和收获,见到你的身影。 点这里 还可以提出你对课程的反馈与建议。
感谢你选择我的 Rust 第一课。感谢你陪我们一路走到这里。接下来,就看你的了。
“Go where you must go, and hope!”— Gandalf
期末测试|来赴一场满分之约!
你好,我是陈天。
专栏Rust编程第一课已经结课了。非常感谢你一直以来的认真学习和支持!
为了帮你检验自己的学习效果,我特意给你准备了一套结课测试题(可以重复体验:) )。这套测试题一共有 20 道多选,考点都来自我们前面讲到的重要知识。点击下面按钮开始测试吧!

最后,我还给你准备了一个 调查问卷。题目不多,大概两分钟就可以填完,主要是想听一下你对这门课的看法和建议。期待你的反馈!
特别策划|学习锦囊(一):听听课代表们怎么说
你好,我是专栏编辑叶芊。
马上要过年了,先预祝你新年快乐!毕竟很多同学可能已经在准备年后Rust的一、二、三……次入门了,多倍快乐正在路上。
因为专栏内容非常丰富,有很多特色的栏目,一直有新同学困惑到底怎么学才能更丝滑地上手:为什么我看了前6讲越看越懵?到底需要什么知识背景才能学Rust,才能学这个专栏?希望能提供专栏的食用手册,或者做相关背景知识整理之类的需求……
为了帮助你在新的一年更好地学习,我特地邀请了几位课代表来分享一下他们学习专栏、学习Rust语言的个人经验和方法,希望能给你一些参考和启发。
@newzai
你好,我是newzai,借这个机会跟你分享一下我的Rust学习过程。在学习Rust之前,我已经有了10年C++开发经验,4年Go开发经验。
我的学习之旅
我是在2019年开始尝试学Rust的,当时国内书籍不多,我也没有购买书籍,只是看 官方英文的书籍,发现前面几章节和其他编程语言差异不大,顺着官方安装指南(macos)和代码,边看边敲,基本没有遇到太多障碍。
直到遇到所有权和生命周期,我就基本搞不明白了,后面看到trait也能理解一部分,毕竟和Go 接口或者cpp虚类也有点类似,但是面对trait丰富的功能太抓狂了,实在学不下去,短暂放弃了。
2020年底,距离我第一次学习Rust失败也有一段时间了,由于Go项目遇到一些性能,并发安全等问题,Rust恰好可以解决这方面的不足,所以开始了第二次学习,不过这次主要结合中文书籍和极客时间张汉东的视频课程一起学。
主要以书籍为主,我把当时国内的中文书籍基本都各自从头到尾阅读了1-2遍,《设计 Rust权威指南》《深入浅出Rust》《Rust语言程序设计》《精通Rust(第二版)》(前面几本都是2015版,精通第二版当时比较新是2018版)。恰好《Rust编程之道》这本没看,因为购买了张汉东的视频课程,本着是同一个人出品没必要重复购买和阅读的想法就一直没看。
这么多书看完到21年6月份了。学到这个阶段,很多语法、知识我也基本了解,但是对生命周期以及怎么进行项目实践还是搞不定,特别是涉及多线程对象互相引用的情况,之前研究了个把月也一直没搞不明白。 毕竟学以致用是我们学习语言的最终目的。使用自己工作中熟悉的业务,用Rust来实现一遍是最好的方式,可以把自己日常零零散散的知识融会贯通。
因为我从事WebRTC SFU媒体服务器开发,一直在尝试用Rust重写SFU服务器。之前我用Go pion的webrtc库开发了公司的媒体服务器,而pion团队恰好也在用Rust重写Go版本的webrtc库,就一直关注webrtc-rs库beta版本的释放。
直到2021年9月份前后,webrtc rs的第一个0.1.0.0 版本释放了。这个时候正好我已经看完了张汉东的视频课程,也跟着学习陈天的Rust第一课有一段时间了,感觉积累得差不多,就着手自己写SFU服务器。
这个时候我知道不少第三方库了,主要还根据《精通Rust(第二版)》、极客时间张汉东视频课程,以及陈天Rust第一课中的推荐,基本上离不开这些库:tokio、anyhow、async-trait、prost、serde、axum等,如果你想自己用Rust写点什么,也可以重点掌握这些库,当然libs.rs网站也能给到很多其他资源。
我的项目实践过程
SFU服务需要提供WS和HTTP协议的服务能力,因此需要选择一个Web服务器框架。
刚开始根据网上的推荐选择的actix-web,由于它使用的tokio版本比较久,和新tokio库的配合有问题,一开始很多问题都搞不定,各种报错莫名其妙,最后使用RT全局方式自行桥接(定义一个全局的tokio::runtime对象,再actix的handler方法调用,后来知道有个库叫tokio-compat专门干这个事情) ,才把流程给跑起来了。
后来遇到axum后,就切换成了axum。切换也很丝滑,这得益于Rust trait的良好设计,就像陈天第一课中的KV服务的设计演进,替换协议、替换框架的代价都很低。
于是2021国庆期间,在之前累积的基础上,我用了5天的时间,实现了一个基本的SFU服务器,可以使用Janus gateway的H5作为客户端,进行视频会议的通信。虽然离在生产上运行的Go版本的功能还相差很多,但是,已经迈出了最重要的一步,后面就相对轻松多了。
最近大部分功能都已经完成,在做Rust SFU版本和Go SFU版本的性能指标压测,总体上能比Go有20%以上的提升,并发越高,差距越大。
寄语
今天重点分享了我自己学习和应用Rust的经历,我个人觉得,Rust值得我们投入时间去学习,从性能、安全、开发效率等方面,表现都很不错。而且我还发现随着自己对Rust的了解越多,收益越多。当然Rust目前也有一些不足,特别是编译时间、生态方面还比较弱,相信慢慢会改善。
世上没有两片相同的叶子,每个人有每个人自己的学习方法和成长路径,希望我的经验对各位有所帮助。
一门语言,如果只是为了糊口吃饭,学最流行的;如果是为了增长见识,增加自己的思维,可以多学几门, 每一门语言基本都有自己的设计哲学,多了解一些,对自己的主力语言的理解使有帮助的,不要进入思维局限。
Rust正在经历Go 2016-2017的发展过程,所以从这个角度看,目前进入Rust的投资学习时机还是比较适合的。
最后学Rust 建议一定要过语法,基础知识全盘过1-2遍,如果和其他语言一样,边学习边练习工程的这种习惯,想直接上手Rust,你可能会崩溃的。
@MILI
你好,我是MILI,很荣幸收到编辑的邀请分享下我的Rust学习经历。我是一名前端全干工程师,工作快5年了,由于工作需要,偶尔全干,偶尔切图,乐于探索、自主学习。
我怎么了解到Rust的,得从几年前说起了,那会我还是前端小菜鸡,想学习一门新的编程语言丰富自己的编程之路,由于JS 是弱类型语言,所以希望学习的编程语言具备:强类型、高性能、安全等特性。
2018年我了解到Rust语言,官方只有一个the book 文档,异步还没有,Boss 直聘上的岗位也只有字节和为数不多的区块链,半个巴掌可以数完。经过这几年的飞速发展,现在 Rust 成立了基金会,在各个领域开花,有的领域已经结果了,尤其是前端,在更多地采用Rust改进工具链。
我如何学习Rust
初期Rust学习资料稀少,后来遇到了汉东老师的书和视频,到现在陈天老师的课程,现在网上Rust 的学习资料也越来越丰富。这里我也分享一下自己学习Rust的过程。
- 阅读 the book——看懂了,手没懂;
- 阅读汉东老师的书和视频——很全,后来为了方便还特地买了电子版,在持续学习中(电子版还会更新修订);
- 练手 rustlings,小练习 可以让你习惯阅读和编写Rust代码——受打击,难受,做不动啊;
- 练手 exercism,编程语言在线学习网站,里面的导师都很棒,而且是免费的给你编程指导,收益良多——在线学习网站,通关了基础部分;
- 刷题 codewars,刷题网站,类似LeetCode——用Rust 语言升到了 5 KYU;
- 实战IM 系统——使用油条哥推出的 poem 和 tauri,结合陈天老师的Rust第一课,我开始做 IM在线聊天系统,专栏开始有很多例子,代码写的很棒,我借鉴了很多代码,学着学着感觉没那么困难了。不过年底因为工作关系,没有继续做下去,仍然收获很多;
- 力扣刷题——初级算法+每日一题,简单级别重拳出击;中等级别努力做完,看三叶题解;困难级别,看三叶题解。因为做链表题,有助于Rust所有权、借用、引用、可变借用的理解,我再结合陈天老师在专栏中的讲解反复练习。
- 学到这里,我回头重新做了 rustlings,实际花费了不到1天的时间,并且还想到了很多举一反三的情况。
从我这段学习经历里, 你也可以感受到我在反复入门,身为一名前端工程师,我的挫败感主要来自类型系统、所有权、生命周期等知识点,异步反而是一个优势,很好理解。
学习Rust的前期,可能非常不适应,会感觉Rust编译器一直在阻碍你编译完成,出现各种红色的报错,如果不去认真看报错会产生很大的挫败感,需要度过一个艰难的磨合期。
但当你熟悉之后,会特别希望编译器给你提示让你做的更好,因为Rust 编译器会重新教你编程的思考方式,围绕着内存安全,先将系统设计好,而不是编写边设计。这种体验目前也只有Rust 能做到。 我们要做的,不是和编译器对抗,而是了解编译器提出的错误以及给出的解决提示。
磨合期之后,剩下来的就是超多的基础知识需要掌握,毕竟 Rust 只是一门编程语言,我们最终还是要用它去创造应用。这个部分,学到什么深度,就要看每个人自己的取舍。
对我自己来说,JS是弱类型语言,在没有其他强类型语言的背景下,陈天老师课程中的很多概念,理解都需要一定的时间,我需要自己补上这方面的知识,而不是完全依赖课程本身。但是在课程中有超多相关知识的超链接,可以非常方便地补充学习。
寄语
推荐多动手,多看错误提示,多思考错误场景,多了解为什么是这样,善用cargo 等Rust工具链的相关工具;推荐多使用 Dash 软件查询Rust语言的API,chrome插件 Rust Search Extension 也可以,偶尔你还可以发现新大陆。
期待在新的一年,与你们共同进步,提前祝贺大家新年快乐!
这就是今天两名课代表同学的分享,如果你有自己的Rust学习故事,欢迎在下方留言区留言互相交流,互相映证,共同学习,共同进步。
第二辑见~
特别策划|学习锦囊(三):听听课代表们怎么说
你好,我是课程编辑叶芊。
为了帮助你在新的一年更好地学习Rust和学习这个专栏,特地邀请了几位课代表来分享一下他们学习专栏、学习Rust语言的个人经验和方法,希望能给你一些参考和启发。
今天是特邀课代表分享个人学习经验的第三辑。话不多说,我们直接看分享。
@Milittle
你好,我是Milittle。
2020年硕士毕业,研究生期间一直是用C++做项目,目前我在做IaaS开发,主力语言是Python和Go。我今年的目标就是拿下Rust这门硬通货。非常开心收到编辑的邀请来分享我自己的学习心得。每一个人的经历不同,也有属于自己的人生,这里我就自己目前的一些感悟聊一聊。
为什么想到来学Rust
第一次了解Rust,是在左耳朵耗子的CoolShell中看到对这门语言的描述:
如果你对Rust的概念认识的不完整,你完全写不出程序,哪怕就是很简单的一段代码。这逼着程序员必须了解所有的概念才能编码。但是,另一方面也表明了这门语言并不适合初学者……
我看到这句话的时候,非常好奇 这是一门什么样的语言,为什么会逼着程序员必须了解所有的概念才能编码?我们的编程语言不是为了解放程序员而发明的么?就去大致浏览了一些Rust Book的内容,不过当时刚工作也没有太深入地了解和学习。
因为我常年混迹在极客时间上学习,后来看到有陈天Rust第一课这门课程,刚好工作上每天也可以稍微抽出一些时间,就决定入手学一下。每次打开一讲,都是新知识涌现的过程。碰到了不熟悉的知识,我都会先自己借助Google一通操作,把能捕捉到的知识都先吃到自己的大脑里面,然后再回过头来看老师的专栏,这样能让我的知识叠的厚一点。
新知识确实很多,也很容易丧失学习的兴趣,被难题困住一阵就放弃了。我自己是用了两个方法: 持续学习、重复练习。
持续学习
在生活中,我自己是一个涉猎比较广的选手,自己学摄影,喜欢看电影,偶尔看看经济学的书籍,我觉得未来一定是留给持续学习、持续做准备的人。
所以相信自己,如果持续学习到今天,不能让你从Rust的难题中解脱出来,那就是你不够持续,还得再坚持下去不要放弃,说不定明天你就成功战胜了Rust难关。
而且持续学习,还可以用在那些不会立马给你回报的知识上,这样才能持续刺激自己学习的兴趣。
我在研究生期间有一个研究方向是借助机器学习视觉技术做一个基本的步态识别,虽然后来由于种种原因没有做下去,自己还是做了个小Demo,感兴趣可以到我的GitHub上瞧一瞧( 步态识别案例)。因为一直做视觉,对计算机视觉中的一些inference的技术感兴趣,我自己结合Nvidia官网的TensorRT,业余时间自己持续学习也做了一些Demo( TensorRT的案例)。
因为有这个习惯,学习Rust的时候,我每天都在思考怎么用它做点事情。正好20211202这一天是回文日,就想到可以搞一个算法题,输出所有已经过去的回文日,第二天立马上手用Rust试了一下,就写了这一段代码:
use std::collections::HashMap; fn main() { let mut valid_palindrome: Vec<String> = Vec::new(); let mut month_days = HashMap::from([ ("01", "31"), ("02", "28"), ("03", "31"), ("04", "30"), ("05", "31"), ("06", "30"), ("07", "31"), ("08", "31"), ("09", "30"), ("10", "31"), ("11", "30"), ("12", "31"), ]); for i in 1..=9999 { let full_year = format!("{:0width$}", i, width = 4).to_string(); let month = &full_year[2..].chars().rev().collect::<String>(); let day = &full_year[..2].chars().rev().collect::<String>(); if is_leap_year(full_year.parse::<i32>().unwrap()) { let value = month_days.get_mut("02").unwrap(); *value = "29"; } if is_valid(month, day, &month_days) { let s = format!("{} {}-{}", full_year.parse::<i32>().unwrap(), month, day); valid_palindrome.push(s); } let value = month_days.get_mut("02").unwrap(); *value = "28"; } println!("{:?}", valid_palindrome); } #[allow(dead_code)] fn is_valid(month: &str, day: &str, days: &HashMap<&str, &str>) -> bool { if month <= "12" && month != "00" { match days.get(month) { Some(&d) => { if day <= d && day != "00" { return true; } } _ => return false, } } false } fn is_leap_year(year: i32) -> bool { if (year % 4 == 0 && year % 100 != 0) || (year % 400 == 0) { return true; } false }
你可以运行一下,会惊奇的发现,从公元0001年到公元9999年,回文日总共是366天,仔细一想其实是非常直观合理的,但是如果之前没有写过或者思考过,一定不能脱口而出。这只是一个简单的小例子,当持续学习的劲头保持下去,你会发现更多有趣的事情。
这些都是一些小小的Demo,但是在促使着我不断学习、提升自己。到现在,我的GitHub有很多自己写的一些示例,虽然每一个Demo不一定能为自己带来很多的回报,但是在让自己保持学习的过程中,我一直都会感觉到非常兴奋、非常愉快。
重复练习
持续学习是一个长久的过程,但是面对困难的单个知识点,就要靠重复练习了。
重复是所有人学习的最终杀器。这个心得来自于我的高中老师,他说如果你学不会,就重复多次,一遍不会就来两遍,两遍不会就四遍,重复多看几次一定能看明白。当然,不是所有知识都是能通过重复练习来理解或者获取到的,但我相信绝大多数的知识是可以通过重复训练掌握的。
学习Rust,重复练习更是我做的最多的一件事情。比如我读完Rust Book,会回过头来看老师的专栏,再去找bilibili的课程去重复巩固,学习其他人的观点和思路。举我学习异步编程的例子吧,重复练习才让我理解的更深刻。
这是学习Rust异步小册子的一段代码,我稍微修改了一下:
async fn learn_song() -> f64 { let mut sum: f64 = 0.0; for _i in 0..10 { tokio::time::sleep(tokio::time::Duration::from_millis(1)).await; sum += 1 as f64; } sum } async fn sing_song() { println!("sing song"); } async fn dance() { tokio::time::sleep(tokio::time::Duration::from_nanos(2)).await; println!("dance"); } async fn learn_and_sing_song() { let learned = learn_song(); println!("i already learned song: {}", learned.await); sing_song().await; } async fn create_dir() { let beg = std::time::Instant::now(); tokio::fs::create_dir("./test").await; println!("create folder consume: {:?}", beg.elapsed().as_micros()); } async fn async_main() { let (_a, _b) = tokio::join!(dance(), create_dir()); } #[tokio::main] async fn main() { let now = tokio::time::Instant::now(); async_main().await; println!("{:?}", now.elapsed().as_micros()); }
通过对代码重复地练习和思考,我总结出了一些自己容易理解的点:
- async关键字,会把一个函数块或者代码块转换为一个Future,这个Future代表的是这个代码块想要运行的数据的步骤。
- 当我们想运行一个Future的时候,需要使用关键字await,这个关键字会使得编译器在代码处用一个loop{}来运行该Future。
- Future对象里面有poll方法,这个poll方法负责查看Future的状态机是否为Ready,如果不是Ready,则Pending;如果是Ready的话,就返回结果。如果为Pending的话,_task_context会通过yield,把该Future的线程交出去,让别的Future继续在这个线程上运行。
- 因为Future的底层对象是由Generator构成的,所以调用poll方法的时候,其实调用的是genrator的resume方法,这个方法会把Generator的状态机(Yielded、Completed)返回给poll。如果为Yielded,poll返回Pending;否则Completed返回Ready,当返回Ready的时候,loop就被跳出,这个Future不会被再次执行了。
这些结论就是自己在重复探索的时候,不断尝试展并且展开编译器编译后的代码才发现的知识点,希望这些可以给你一些学习Rust的启发:
#![allow(unused)] fn main() { // $cargo rustc -r -- -Zunpretty=hir -o test.txt // source code for learn_song async fn learn_song() -> f64 { let mut sum: f64 = 0.0; for _i in 0..10 { tokio::time::sleep(tokio::time::Duration::from_millis(1)).await; sum += 1 as f64; } sum } // expand hir for learn_song async fn learn_song() -> /*impl Trait*/ #[lang = "from_generator"] ( move |mut _task_context| { { let _t = { let mut sum: f64 =0.0; { let _t = match #[lang = "into_iter"](#[lang = "Range"]{start: 0, end: 10,}) { mut iter => loop { match #[lang = "next"](&mut iter) { #[lang = "None"] {} => break, #[lang = "Some"] { 0: _i } => { match #[lang = "into_future"](tokio::time::sleep(tokio::time::Duration::from_millis(1))) { mut pinned => loop { match unsafe { #[lang = "poll"](#[lang = "new_unchecked"](&mut pinned), #[lang = "get_context"](_task_context)) } { #[lang = "Ready"] { 0: result } => break result, #[lang = "Pending"] { } => { } } _task_context = (yield ()); }, }; sum += 1 as f64; } } }, }; _t }; sum }; _t } } ) }
其实在学习新知识的过程中, 谁也不能一次性把知识点吃透,都是在不断重复之前的知识,然后加上自己的思考,在这个过程中不断汲取,内化为自己的知识。这样通过多次的打怪升级,最后我们也一定会有自己独到的见解。
学习资料
最后,也整理了一些我学习的相关资料分享给你,希望对你有所帮助:
- Rust weekly,每个星期更新Rust的最新消息。
- Jon Gjengset Youtube,大神,不说了,自己品。
- Top 100 Rust Projects,这是GitHub的top 100的Rust项目。
- aync的一些例子,使用Rust实现一些异步的例子,包括epoll、kqueue、iocp这些的封装,还有Rust运行时的例子解释。
- Let’s Get Rusty,油管,出过Rust Cheatsheet,地址从油管主页可以获取。
- Databend的个人空间_哔哩哔哩_Bilibili,Databend社区持续有推出培训课程,本身他们的产品Databend就是使用Rust开发的。
- 软件工艺师的个人空间_哔哩哔哩_Bilibili,微软的一个大佬,里面还包括一些Go教程,手速王。
- 爆米花胡了的个人空间_哔哩哔哩_Bilibili,宏编程的打怪升级项目,中文教程top 1。
- Rust月刊,汉东老师出的月刊。
寄语
可能你的学习方法和我的不一样,但是只要你选择了这门课程,就不要后悔,一如既往地保持自己学习Rust的初心,以持续学习的心态,拿出重复多次学习的决心来战胜Rust编程第一课,不要抱怨,不要后悔,勇往直前。你可以的。
这是今天课代表Milittle同学的分享,如果你有自己的Rust学习故事,欢迎在下方留言区留言交流。
预祝你新年快乐,身体健康,学习进步~
特别策划|学习锦囊(二):听听课代表们怎么说
你好,我是Rust课程的编辑叶芊。今天是特邀课代表分享个人学习经验的第二辑。
一直有新同学困惑到底怎么学才能更丝滑地上手:为什么我看了前6讲越看越懵?到底需要什么知识背景才能学Rust,才能学这个专栏?希望能提供专栏的食用手册,或者做相关背景知识整理之类的需求……
为了帮助你在新的一年更好地学习,我特地邀请了几位课代表来分享一下他们学习专栏、学习Rust语言的个人经验和方法,希望能给你一些参考和启发。学习愉快。
@Marvichov
你好,我是Marvichov,是一名工龄5年的软件工程师。目前的工作领域是分布式机器学习,主力语言是Python。之前也有Cpp的工作经验,搞过两年半搜索引擎,也做过一年半 开源项目。平时也使用Java和Go进行个人项目开发和学习。
和大多数人一样,立了flag要好好学完这门课程,结果止步于aysnc。
学习一门语言,先要明白为什么要学。世界上的语言千千万万,学习英语不也挺香?对我来说学Rust的理由很简单,Rust的安全模型很有意思,确实能解决很多C/CPP的痛点。对于底层开发来说,安全越来越重要,有着比性能更高的优先级。
分享个同事的例子:自从项目从C转到Rust之后,他晚上能安心睡觉了。不会因为突如其来的Segfault半夜被叫醒。某些多线程bug,debug一个月是常态。现在,他可以安心merge新人的PR了,因为有compiler去阻断有安全隐患的代码。
不出意外的话,未来Rust会制霸底层。如果要搞底层开发的话,还是绕不开这座大山。
最开始学的时候,我先去读了官方 the book,算是对Rust有了一些初步、直观认识。然而,The book写得比较浅,各种知识点都是点到为止。尤其是最重要的lifetime和borrow check,the book没有讲得很深入,我看完还是不知道compiler是怎么计算lifetime的。更深入学习的话,还是要求助于 死灵书 和官方 reference。
后来遇到了Non-Lexical Lifetime ( NLL),深入到了compiler的实现细节,我愈加发现自己力不从心,钻语法的牛角尖。花了大量的时间钻研语言本身,而非积累实战项目经验。
这和我之前学习CPP的经历很相似:纠结各种语法特性,浪费了很多时间在死记硬背实战用不到的语法上。到头来,CPP还是靠不断在工作中做项目熟练掌握的。况且,大部分语法,实战中根本不会用。花了大量时间纸上谈兵。到头来不是在学习,而是在感动自己。
因此, 学习一门语言,我还是倾向于快速上手,直接撸项目。很多大神学习新语言的方法就是用新语言把自己熟悉的项目重新写一遍。
我记得耗子叔就在《听风》专栏讲过,他学语言就是看这个几个主要方面:内存管理、错误处理、类型系统等等,然后花一两天写个小项目就把一门语言掌握了。各个语言都是大同小异的,学习多了之后就能很快触类旁通。然而,我并没有什么端到端的项目经历,这种方法对我来说还是挺有难度的。
不过,对于大多数人包括我来说,熟悉语言还有一种快速上手的方法,就是刷题,把那些之前写过的算法,用Rust写一遍。
Leetcode对Rust的支持很一般,发生错误之后也没有stack trace。 我个人就选择用 exercism ,所有代码和测试都可以在本地跑,方便调试。我周围很多Rust工程师就是通过刷题快速上手Rust,然后被委任去重写一些Java项目。这个方法你也可以参考。
正好陈天老师的Rust专栏提供了很多动手的实战小项目,弥补了市面上各种Rust书籍的缺点,也避免了最后停留在学习语言本身的误区上。毕竟,语言是用来解决实际问题的。我们学习Rust也不是为了掉书袋,而是为了让程序创造价值。
其实,我当时很犹豫要不要买课,因为语法知识点在官方的the book和死灵书上都讲得很详细了。但是一看到第六讲的实战项目,就毫不犹豫下单了,我自己对compiler就很感兴趣,能手撸一个SQL解析器,还是用Rust,一石二鸟岂不美哉。
我是怎么学专栏的
在这里也分享一下我自己是怎么学习这门课的,希望能给你参考。
- 1-3讲 内存前置知识
如果想搞清楚内存是如何被管理的,或者想深入理解程序的address space,推荐上一上《Computer Systems: A Programmer’s Perspective》( CSAPP)。这门课的教授Dave说:“如果你的一生只上一门计算机系统基础,CSAPP就够了”。我后来补了一部分这个课,的的确确帮助我理解了许多系统底层原理。
简单来说,在机器码或者汇编层面,没有ownership一说,也没有lifetime,有的只是数据和一连串的指令。CPU只知道执行指令、数据传输、读写各种寄存器,以及内存,例如程序员视角的stack和heap。
Owership和lifetime只是high level语言层面的抽象,属于Rust语言的一部分,并不是计算机最后执行的机器码的一部分。就像算法里面的loop invariant一样,通过在高级语言语法层面的规则限制,保证最后编译出的代码不会在runtime出现导致内存安全的错误。
- 4-6讲 get hands dirty
我第一遍学的时候就快速过了一遍,不求完全理解语法细节。大概知道用Rust写项目很灵活、Rust支持很多domain就行了。这几节课的信息量有点大,很容易劝退新手,暂时搞不懂的就放在那里,等以后学到了,再回来过一遍。
- 7-14讲 Ownership & Containers
基础中的基础。首先了解ownership和lifetime,这是Rust相比于C要解决的核心问题:内存安全。这些课程的例子,我都是自己亲手一行一行打的。先把例子过一遍,然后自己写一遍。毕竟根据 学习金字塔 原理,动手实践的学习效果,比单纯只是阅读要强50%。之后,弄明白smart pointer和各种基础数据结构,才能更快上手项目,或者刷题。
- 18讲 错误处理
重点中的重点,也是Rust吸收其他语言优点的例子。built-in的语法支持,让Rust区别于其他主流语言,例如C/CPP、Java。错误处理的方式也可以窥见Rust的安全设计思想。
- 12-14、23-25 Traits
Rust的核心之一就是Traits,是Rust语言抽象的地基。熟悉面向接口编程的抽象风格,才能跟上课程里的各种项目。很多Traits必须熟练掌握,比如AsRef、From、Deref、Drop、Send/Sync等等。这些Traits就像构建Rust世界的基础元素。如果不熟悉,就很难读文档、设计接口。
- 21-22、26、36-37、41-42 KV server实操系列
这个系列第一遍学可以暂时放一下,等Rust知识点集齐了,再拉通一起学习更好。课程的安排是穿插学习KV server,中途不断补充新的知识点,然后不断用新的语法糖迭代这个项目。但是这个项目的代码量其实并不小,中途很容易忘记项目里面各种细节和上下文。我自己学的时候觉得拉通学习这个项目,趁热打铁,效果更好。
- 其他讲
剩下的基本上都是项目实战,主要是熟悉各种IO和接口、系统设计。除了跟着老师的思路一步一步敲代码,我想不出更好的办法。老师的项目实战经验很丰富,很多设计我都需要推敲很久,才能理解。越学到后面,跟上老师就越费劲,因为不仅要学习老师的设计思想,同时还要学习Rust的各种知识点。只能说一门课当两门课上,非常实惠。
我的学习方法
第一个方法是 画思维导图,一图胜千言。用自己的语言描述学过的知识点才能内化。老师在这方面真的是很好的榜样,每节课开头就是一张知识地图。
第二个方法就是 构建自己的知识体系,核心思想是 holisitic learning。你学的每个知识点都是一座岛屿,将它们能相互连接,你才能触类旁通,学过的知识就很难被忘记。
打个比方,如果各个知识点没有连接,就变成了孤岛,容易被人遗忘。当知识连接多了,孤岛就变成了城市。当你在城市迷路,很容易通过到新的导航达到目的地。但如果你在荒郊野岭迷路了,就需要付出相当大的代价才能达到目的地。很多时候,这样的代价是重头开始学。
我学习Rust的时候,就喜欢和C、CPP、Golang对比,把相似的知识点串联起来。
举个例子,CPP里面的template、RAII就和Rust里面的generics、Drop相对应;Golang里面的interface就和Rust的trait相似,都是interface oriented programming (面向接口编程)。Rust唯一和其他语言不同的就是安全模型。因此,我们在学习的时候,可以重点掌握owership、lifetime和thread safety。
第三点就是 勤动手。私以为,写代码99%都是熟练工,没有捷径,也不需要天赋,有高中的数理逻辑就可以。行业内,只有1%的人能做mathematical programming,也就是创造、研究、优化和编写核心算法。成为这1%的人,才需要谈天赋。
Rust之所以难,不是因为编码者天赋不够,而是因为它要求编码者有良好的底层基础、和对内存模型有很好的认识。学Rust遇到瓶颈学不下去了,不妨退一步,补一补基础。这里再推一下CSAPP。
第四点前面提过了, 除了跟着老师撸项目,还可以刷题。我在对刷题答案的时候,注意到很多同学喜欢通过函数式编程把复杂的逻辑揉成一行。这就像当年那些Python一行流,炫耀自己能一行刷一道题。Python这么写可以,因为没人会苛求Python代码有很好的性能。Rust这么写就不太合适了。
Rust语言,虽然其可表达性很强,同时也鼓励大家使用函数式,但是它还是一门底层语言。 底层语言最重要的特性就是可读性、可优化性。当你把很复杂的程序,压缩成一行或者一个statement时候,你很难看出哪里需要优化。周围一些Rust工程师也告诉我,实战中没人会那么写代码。大部分时候,他们采用的是最简单直接的API、一目了然的Generics、以及面向接口编程的设计理念。
最后一点就是 复盘。
往小了说,就是及时复习。老调重弹一下中学学过的 艾宾浩斯遗忘曲线。根据这个粗糙模型,一天不复习,就会忘70%。隔一周,忘77%。现在社会人比较忙,一周内抽空复习一下就好。不然学了、忘了,最后缓解了焦虑、感动了自己。
这里推荐一下大神Jon Gjengset分享的方法:上课的时候,他不会去记笔记,而是会全神贯注听,力求课上搞懂;课下的时候,他会使用 康奈尔笔记 法(Cornell Notes system)做笔记。这种笔记法专门为复习、抗遗忘而设计的。亲测有效。很多笔记软件都内置康奈尔笔记法模板。
往大了说,就是建立知识体系和方法论。课后,总结学到的知识点,通过前面提到的holistic learning的思路,将刚学的与之前学过的知识建立联系,顺便也复习之前的知识。
除了复盘知识点,也可以复盘自己的学习方法是否有效,学习计划安排得是否合理。复盘是一个非常自律的过程,我也在不断摸索。希望2022年和大家一起进步,不断成长。
学习资料
- Computer Systems: A Programmer’s Perspective, B站视频, 课件链接。可以通过这门课补各种底层知识,比如内存是怎么被程序管理的、如果写简单的汇编代码。
- lifetime misconceptions,常见lifetime误区与答疑。
- rustnomincon Rust死灵书,高级版的the book。
- Jon Gjengset, Crust of rust,作者是MIT神课 分布式系统6.824 的助教。他最近出的书《 rust for rustaceans》也可关注。
- baby steps,Niko Matsakis,Rust compiler开发者的博客,不定期会分享compiler内部实现细节。
- explaine.rs,Rust知识点可视化。当你遇到问题,但不知道问问题的方向时,可以考虑直接把代码放进去。
- too many linked list,挑战不违背safety rules的前提下,实现链表。
- https://fasterthanli.me/series,老一辈Rust布道者,blog质量很高。
- rust quiz,非常晦涩的语法题,作者是Rust大神 David Tolnay,anyhow和thiserror的作者及贡献者。
- rust book list,追踪了网上各种Rust书籍和学习资料。
- writing os in rust,采用Rust的OS底层学习教程。
- pingCAP talent plan,Rust网络编程,Golang的系列教程也相当精彩。
- rust forum,钻牛角尖,或者迷失学习方向的时候,上forum贴个帖子,会有很多热心大神免费答疑。 Reddit 也不错,经常也有高质量发言。
这是今天课代表Marvichov同学的分享,如果你有自己的Rust学习故事,欢迎在下方留言区留言互相交流,互相映证,共同学习,共同进步。
第三辑见~
特别策划|生成式AI:哪些开发环节可能被颠覆?
你好,我是编辑叶芊。
4月份,我们和Tubi 组织了一场坐标北京的线下meetup活动,陈天老师与来自各个领域的工程师交流了三大话题:了解和拥抱 AIGC、AI 2.0 时代下程序员的硬核技能需求描述和架构设计、Serverless Rust。
可能有同学未能参与,这里我简单整理了第一场AIGC分享的要点内容,你也可以看视频: 如何以更有准备的姿态拥抱 AIGC 新时代。如果你对其他话题更感兴趣,可以看文末的其他资料链接。
AIGC发展到现在,其实也就是最近三个月被 ChatGPT带火的, ChatGPT你可以理解为是所有AIGC的一个大脑,其他各种各样的model都是四肢,由 ChatGPT指挥,那目前被热议的GPT或者LLM,究竟是个什么东西?我们和它对话的时候到底发生了什么?作为程序员我们如何高效使用ChatGPT?
我们开始今天的交流。
LLM 或者 GPT究竟是什么?
GPT,generative pretrained transformer,预训练的大语言模型,GPT3.5是一个有1,700亿参数的模型,GPT4的模型大小OpenAI并没有公布,有人说可能是GPT3的100倍甚至更多,所以如果我们把一个参数看成一个神经元,GPT4已经接近人脑神经元的量级,而且按这个趋势看,未来GPT一定会超过人脑神经元的量级。所以如果真的把人类产生的所有知识都拿给GPT训练,能训练出一个什么样的怪物呢?我们谁也不知道。
其实,GPT1和2都不是特别成功,但在GPT3之后,同样的训练方法,只是训练的数据容量更大一些,却突然涌现了很多有意思的能力。
首先,GPT3 可以理解广泛并且复杂的指令。我们之前的AI像Amazon的Alexa,你需要专门写一个个的skill,Alexa能做的事情完全跟你提供了多少的skillset有关系,但是GPT的skill是无穷无尽的,我们给一些它没见过的东西,让它按指令做一些任务,它是可以顺着我们的思路做下去的。
第二个GPT 能理解例子,并且能举一反三。这个能力是非常强大的,其实我们人类学习已有的知识,也是通过理解并提炼出其中的套路,再把这个套路应用到新的场景下,GPT也有这种能力,你告诉它这是一个什么样的样例,然后输入是什么,输出是什么,让GPT按这种方式来做一些事情,它能理解这个例子。
最后GPT能按照要求 对复杂的任务进行分治。“分治”是我们程序员都有的一个非常基本的素养,面对一个复杂任务复杂问题的时候,我们会把它分解成不同的模块,各个击破。现在GPT也有这种能力,当你告诉他一步一步把中间过程写出来,你会发现他能把一个比较复杂的问题分拆,最终输出比较好的结果。
我们跟ChatGPT对话的时候究竟发生了什么?
其实整体的思路非常简单,就是 不停地根据上下文产生下一个token。token是 transformer里的一个概念,你可以理解为token是把语言切分后的最小的单元,大概两个token对应一个单词或者汉字。
看这里的例子,我们给一个context “beautiful is better”输给GPT之后,它会根据它所学的内容、掌握的套路,预测出一个它认为最符合上下文的词,比如输出一个“than”,然后把整个result作为一个新的context输入给自己,再去补全下一个词,就这样一路下来。所以你能看到,chatGPT跟你对话的时候是一个词一个词蹦出来的。
因为GPT的机制不是一下子找到question的解决方案一次性输出,而是,根据上文去预测下一个字是什么,逐渐输出,直到它认为要表达的意思表达完了,会终止。当然可能会有很多备选,但是它会选他认为概率最高的词,最终组合成答案。
但GPT因为是一个语言模型,机制是预测,预测是有概率的, 两次预测可能产生不同的结果,所以GPT的回答捉摸不定。如果你想让他做一件非常有确定性的事情,比如说期望每一次回答都是正确的,那这个场景可能并不适合用GPT来处理。
另外GPT记忆有限,对于输入和输出的token来讲,GPT3允许4K个Token,GPT4 32K的Token,因为GPT的自注意力模型,计算是做Token和Token之间的向量,最终的计算量是Token的平方,导致计算量和内存占用会随序列长度平方级增长,所以你可以想象,如果我们要做一个GPT这样的系统,并且让千百万的用户使用,一定要做一些限制,否则可能某一个用户把GPT所有的资源全部吃走了,就没办法serve其他的用户了。核心是效率、可用性、价格的权衡。
为什么ChatGPT能横空出世?
我觉得最主要的一点是 提供了非常高水平的问答服务,并且使用门槛基本降到奶奶辈儿。我们做互联网的经常说,如果说你做一个面向消费者的产品,你父母不会使用,有可能使用门槛有问题,但chatGPT使用门槛极低,这是让他成为史上最快用户过100million的consumer APP很重要的原因。
chatGPT还提供了 非常简单且低价的 API激发社区参与。GPT到目前为止是一个具有绝对垄断力的大语言模型,但是,它其实给出了非常便宜的API使用价格,这导致社区里有各种各样的SDK。它还提供了一个plugin的framework,虽然现在还没有确定对公众开放,不过社区在GPT API的基础上做了很多工具,解决掉一些GPT的短板,进一步降低使用门槛,比如langChain、Ilama-index、AutoGPT。最近比较火的AutoGPT,基本上,你可以认为等同一个虚拟的助理。
有了这些作为基础,就引发了GPT无限可能的场景。
现在创业市场最火热的就是ChatGPT + X,X可以是任何的SaaS服务、传统服务,比如ChatGPT + Legal,法律服务原来门槛很高,现在GPT可以帮你写诉状,承担一些原本你需要跟律师交流的事情,并且他还可以把法院的传票以一个7岁小孩都能听懂的方式,解释给你听,这就很非常厉害。
场景还有很多,我们生活中凡是跟语言、交流、信息的转换相关的,GPT都能很好地应用。
如何高效使用 ChatGPT?
首先你要能够使用GPT。可以访问后,很重要的一点就是你要 问对问题。清晰明了地表达你所问的问题,如果是一个比较复杂的问题,你要提供足够的上下文,比如精准的一步步指令,然后给一些典型的例子,这些都有助于GPT理解你想让它解决的应用场景,帮助你完成任务。
当然未来很可能会出现更好的AI,更好的工具,我们也不用写这些魔法一般的指令,但现在还不允许,那我们prompt engineering基础的技巧有哪些呢?
入门级的技巧就是五方面:Role、Context、Instruction、Example、Output。
- role,指定GPT是什么角色,比如you are playing a role of migration-bot。
- context,想干什么样的事情,给到充足的上下文。
- instruction,一步一步应该怎么去处理,规则详尽。
- instruction,给一些高质量的例子帮助GPT进一步理解。
- output,最后说明期待什么样的输出格式,比如希望给出的结果是一个对话、一个JSON。这很重要,尤其是你希望在程序中控制它,output需要是计算机可以继续处理的数据结构。
注意,有时候GPT会很跳脱,即便你告诉他output应该是一个JSON,它有时候还会多说两句废话,比如:“好的,JSON是这样子的,然后定义JSON”,但这不是我们希望的结果,如果无法直接转换成JSON,你可以试试用正则表达式,把里面的JSON部分拿出来,再去parse。所以你可能需要去做一些特定的处理。
具体可以参考: https://github.com/dair-ai/Prompt-Engineering-Guide。
这里强调一下,你指定一个角色后,GPT会安分守纪地在角色的知识体系中,这样可以避免一些噪音,比如说你指定它是database administrator,这时候你再问宫保鸡丁怎么做,它就会拒绝回答,它会认为自己不负责回答角色认知之外的内容。
在使用的过程中,我们也要 控制预期,了解大语言模型的限制,就像刚才说GPT基于预测机制的结果不确定性,不适合做deterministic的问题,更适合去做一些开创性的问题。
这可能跟很多人的想象不同,大家都觉得AI是个工具,像计算器一样,但实际上现在的AI更像是一个artist,有一定的creativity,不要认为它是一个scientist。因为它可能经常信口胡说,比如我问《资治通鉴》是如何评价陈天的,GPT真的能写跟资治通鉴一模一样的文本,还搞成文言文,所以当你想让GPT去做一些确定性很强的事情,要三思。

不要认为在智能领域我们无法替代,其实目前很多工作,GPT也可以辅助我们完成。GPT会给出一些我们没有想到的创意。
为什么能有这样的能力?因为GPT看了很多的知识,掌握了很多套路,很多不同的素材之间碰撞,找到一些所谓的经验就是套路。 所以GPT尤其适合在N个相关或者不相关的领域中,找到那些灰色的地带,而且灰色地带,往往是创新的源头。
现在有很多人用GPT来写文章、写论文,以往我们认为写论文是很具有开创性的,但是论文在写作过程中很大部分是要想选题、整理文献、找各种各样的参考资料,GPT完全可以做这些事情,尤其在选题这一块,你可以告诉几个你觉得可以发挥的领域,让GPT在这些领域中帮你找灰色地带。
Demo:No-SQL 查询 Postgres
这里分享一个No-SQL 查询 Postgres 的例子( demo视频、 源码)。
- 想法:用自然语言查询 SQL database
- 核心问题:如何提供数据库 context?
- 开发工具:openai + sqlalchmy + pandas
这个例子,其实我们没有涉及一个很重要的问题,如果你把GPT类比成人脑的话,它其实有自己的长期记忆和短期记忆。长期“记忆”就是预训练过程中”记”住的内容和学习到的套路,短期“记忆”是我们和它对话过程中的上下文 (4k or 32k tokens) 。
所以短期记忆非常有限,超过短期记忆窗口的内容就没办法处理了,如果我有一个很大的数据需要处理怎么办?主要有5种方法。
- 精简上下文,尽量用精简的语言进行 prompt。
- 摘要处理,对复杂的内容预先生成摘要。
- 分批处理,依次处理上下文片段,再汇总。
- 优先处理最近的上下文,滑动窗口思路,只使用最近5条对话。
- 使用离线存储,完整上下文储存在 vector db,根据需要调用相关内容放入“短期记忆”。
Demo:ChatPDF
这里分享一个ChatPDF 的例子( demo视频、 源码)。
- 想法:如何对大量 ChatGPT 没有学习过的非结构化内容进行问答?
- 核心问题:如何弥补短期记忆的不足?
- 工具:langchain + faiss
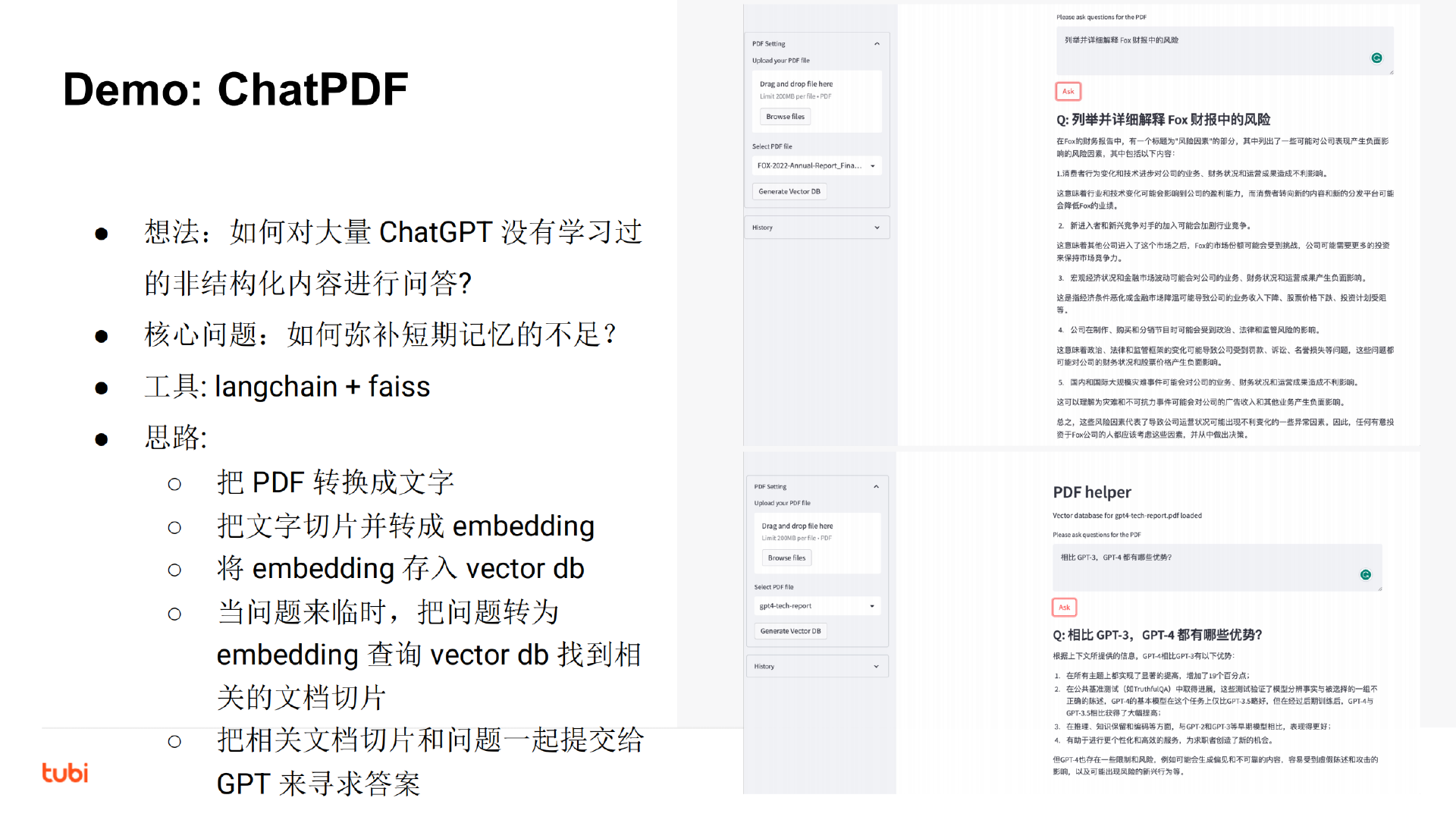
GPT对我们程序员的影响
我觉得很大的一个影响是,过去十几年的训练,我们都是作为一个程序员学习如何适应机器。之前,编程语言是这样子,语法是这样子,我们要按照语法去写。那未来会是什么样子呢?因为ChatGPT是一个语言模型,理论上说,我只要懂一门语言就可以了,只要懂我的母语,可以用ChatGPT帮我干任何和语言相关的事情。编程语言也是语言,我让它把我写的语言转换成编程语言,就像我们在demo中把语言转化成SQL一样。
当然这并不是说大家不用再学任何东西了,只是 未来可能我们更多想的是机器如何适应人,尤其是适应那些并不具备编程经验的人,让他们也可以做出一些有意思的东西。
GPT对我们程序员的具体影响,首先是开发团队的变化。
首先是团队规模。当然现有的开发团队可能不会有什么变化,但是未来,新公司的团队规模可能更倾向于小而美。因为文档、测试等等GPT都能帮我们解决了。原本1个小团队可能需要招5个人,但之后你自己+GPT 在初期就够用了,尤其现在AutoGPT这样的工具做得越来越好,价格越来越低廉。而且团队人越少,沟通的成本越少,这也很重要。
团队的人才构成也会变化,之后可能是少量的专才,尤其是某些具体领域不得不使用的专才,以及大量能和AI高效交流的通才。以后的程序员究竟会是什么样子?我不清楚,但我觉得以后的程序员一定是要非常懂怎么跟AI打交道,知道怎么用AI更高效地处理自己的任务,以及帮助自己成长。
团队组织方式可能也会改变。因为之后语言已经不是障碍,那么假设一个中国的团队找团队成员的时候,可以全世界找了。以后交流会有一个革命性的发展,因为交流往往会影响团队的组织方式。
团队的改变,当然还有更多的可能性,欢迎你留言分享自己的想法。开发流程也会有变化,在整个开发流程中,似乎每一个环节都能找到 GPT可以帮我们的地方。
比如基于自然语言的描述,自动生成代码;自动检测代码中的错误,并提供修复建议,帮助我们提高开发效率;作为一个编程助手提供实时的编程协助;审查代码,自动发现潜在的安全风险和性能问题;自动生成和维护项目文档,降低文档维护的成本和难度;根据开发者的水平和需求提供个性化的学习教程,提高效果等等。
甚至,我们可能有一个全新的代码开发环境。也许未来的开发界面就是我们把流程绘出来,代码就写好了。现在有很多创业公司在探索这个方向,究竟未来我们写代码是什么样的开发,来达到现在百倍千倍的生产力。
但面对如此多的可能性,很多同学一定会担心自己是否会被淘汰。
我觉得,我们程序员最不用担心的一件事情就是失业。如果说被淘汰的程序员,也是因为无法适应新的开发模式而被淘汰。
因为 当生产力发展了,更多需求一定会被激发出来,比如说现在的我们人类对APP的需求是一瓶水,以后对APP的需求可能是整个汪洋大海,大概是你的奶奶都需要100款完全为她定制的APP的程度。
就像高级语言时代终结的不是程序员,反而开拓了程序员的市场;Web 开发时代终结的也不是程序员,它让非科班出身的开发者也成为程序员;AIGC 时代,传统意义上的程序员会小众化,但更多的“程序开发”的需求会带来一个全民程序员的时代。而且这套东西,总需要人把需求描述出来,等GPT生成结果之后做精调等等,这些是程序员要做的事。
只是原来我们一周出的活,现在可能10分钟就出来了,这不意味着这一周剩下的39个小时50分钟,我们就可以摸鱼了,而是要完成更多需求。
当然GPT也会影响产品开发的各个方面,比如生成式 UI / 代码 / 测试、生成式设计 、产品冷启动和运营、无处不在的高仿真机器人、智能客服、知识库 / FAQ / 人工客服 2.0。
最后提一个值得思考的点,如果说我跟AI一直对话,我把从小到大所有经历的事情、所有掌握的知识经验,都跟AI分享,最后有没有可能 AI面对外界的时候表现的行为,完全跟我一模一样,那以后人是不是可以通过这种方式永生?欢迎留言脑洞。
拓展阅读
线下活动回顾:AI 时代下程序员的硬核技能,需求描述和架构设计,Serverless Rust